本篇摘要
- 本篇将以最通俗易懂的语言,形象的讲述为什么很多情境下,我们优先考虑的
使用指针而不是对象本身,本篇将给出你答案!

一.从一个生活例子说起,形象秒懂
想象一下,你去图书馆借书,下面你有两种选择:
-
把整本书复印一份带回家,但是,书很厚,复印要时间,占地方,还容易丢。
-
只拿一张“借书卡”,上面写着书名和位置,而且, 轻便、快速、随时可以查。
此时我们大多数人就会直接选择第二种方案了,主打一个通透!
在编程中:
“复印书” = 直接定义对象
Book book; // 在函数里定义,函数结束就没了
“借书卡” = 指针
Book* ptr = new Book(); // 拿个“卡”,书在别处(堆上)
指针就像“借书卡”——它不存对象本身,只存对象的“地址”。
二·那为啥不直接“看书”,非要用“借书卡”呢(也就是为什么选择用指针而不是对象呢)?
可以这么认为因为有时候,“直接看书”根本做不到!
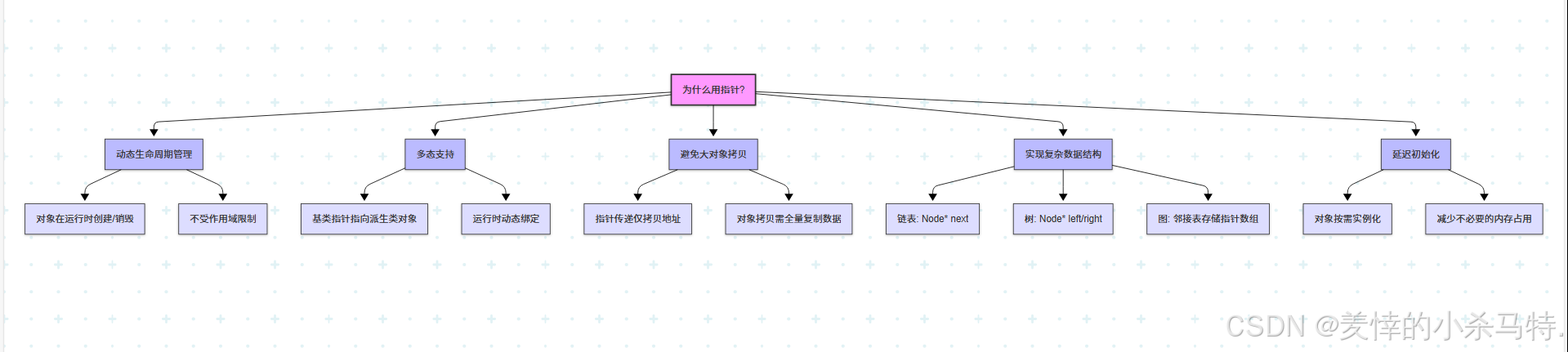
下面我们经常下面几个方面展开叙述:
| 原因 | 简要说明 |
|---|---|
| 动态生命周期管理 | 对象可以在运行时创建/销毁,不受作用域限制 |
| 多态 | 基类指针可以指向派生类对象 |
| 避免大对象拷贝 | 指针传递比对象拷贝更高效 |
| 实现复杂数据结构 | 如链表、树、图等需要指针连接节点 |
| 延迟初始化 | 对象可以在需要时才创建 |
流程图效果:
动态生命周期管理
下面举个通俗易懂例子:
// 对象在栈上,函数结束就销毁
void badExample() {MyClass obj;// obj 在函数返回时自动析构
}// 指针可以控制对象生命周期
MyClass* ptr = new MyClass();
delete ptr; // 手动控制销毁
-
可以看出这里如果使用指针的生命周期是由我们自己控制的,不受作用域限制!
-
适用于:数据库连接、网络套接字、单例等需要跨函数/模块存在的对象。
多态
下面从我们最熟悉的继承多态来分析下:
- 比如我们如果想写代码的时候,当描述的对象有些相似的特征,我们就会考虑到进行继承多态来简化操作,便于管理,因此这里的基类指针就是我们必不可少的了!
#include<iostream>
using namespace std;
class Animal {
public:virtual void speak() = 0;
};class Dog : public Animal { void speak() override { cout << "我是一只狗,我要叫了:"<<"汪\n"; } };
class Cat : public Animal { void speak() override { cout << "我是一只猫,我要叫了:"<<"喵\n"; } };int main(){
// 基类指针可以指向任意派生类
Animal* animals[2];
animals[0] = new Dog();
animals[1] = new Cat();for (int i = 0; i < 2; ++i) {animals[i]->speak();
}}
效果展示:

-
看到这就是我们非常亲切的多态效果了!
-
这是直接定义对象无法实现的!
避免大对象拷贝
这里,我们回忆下,通常比如函数传参的时候用的要么是对象,指针,引用,而这里我们重点看对象和指针的区别。
下面先看下例子:
class BigObject
{char data[1024 * 1024]; // 1MB
};// 每次传参都会拷贝 1MB 内存
void process1(BigObject obj)
{cout << "对象" << endl;
};// 指针只传 8 字节地址
void process(BigObject *ptr)
{cout << "指针" << endl;
};void process2(BigObject&a){
cout << "引用" << endl;}int main()
{BigObject *p = nullptr;int s1=clock();process(p); // 指针int e1=clock();BigObject b;int s2=clock();process1(b); // 对象int e2=clock();int s3=clock();process2(b);int e3=clock();cout<<"指针耗时:"<<e1-s1<<" 消耗内存: "<<sizeof( BigObject *)<<endl;cout<<"对象耗时:"<<e2-s2<<" 消耗内存: "<<sizeof( BigObject )<<endl;cout<<"引用耗时:"<<e3-s3<<endl;}
运行效果:

当然这里每次时间可能不同,这里忽视,我们可以看到对象耗时是最长的,其次是指针,而引用达到了最快。
下面解释下原因:
- 对象:需要拷贝构造,消耗一个对象大小,故耗时耗内存。
- 指针:需要构建指针,故消耗指针大小。
- 引用:直接起别名,几乎不占内存,由编译器在编译期处理别名关系。
因此,这里如果条件符合,一定是选择指针比较优的(如果对象特别大,对象的话,这不就是自己给自己找麻烦)!
实现复杂数据结构
想做个“链表”或“树”,比如图论的一些算法等具有连接关系的模型,都是需要指针来解围的(这里顺便推荐下博主的图论专栏,讲的超级详细:图论专栏)。
比如你要做微信好友关系链:
struct Person {string name;Person* friend; // 指向下一个好友
};
没有指针,你怎么表示“张三的好友是李四”?
这里我们经常设置进去的是指针来表示这种关系,似乎都已经成为常态了!
延迟初始化
#include <iostream>
#include <ctime>
using namespace std;
class Animal
{
public:virtual void speak() = 0;
};class Dog : public Animal
{void speak() override { cout << "我是一只狗,我要叫了:" << "汪\n"; }
};
class Cat : public Animal
{void speak() override { cout << "我是一只猫,我要叫了:" << "喵\n"; }
};class Player
{
public:Animal *Animaler = nullptr;void start(){Animaler = new Dog(); // 按需创建}
};
int main()
{Player p;//此时没有Animaler指向的对象,也就是没有对象产生p.start();//此时才构造处对象p.Animaler->speak();
}效果展示:

- 对象只在真正需要时才分配内存。,真正做到了方便,节省资源!
四·直接定义对象的优势
下面看下优势总结:
| 优点 | 说明 |
|---|---|
| 自动管理内存 | RAII,作用域结束自动析构 |
| 性能更高 | 无间接访问开销 |
| 更安全 | 不会空指针、内存泄漏(如果不用 new) |
比如:
void goodExample() {MyClass obj; obj.doWork();
} // 自动调用 ~MyClass()
-
当我们使用对象的时候(非new),它会自己出了作用域自动析构,安全感拉满,但是new了就需要手动delete否则内存泄漏!
-
能用栈对象就用栈对象!
五· 普通指针的坏处
指针有没有坏处?当然有!指针就像“双刃剑”:
- 优点:灵活、高效、支持多态 。
- 缺点:容易空指针、内存泄漏、野指针。
存在隐患:
非法访问:
Book* ptr = nullptr;
ptr->read(); // 空指针崩溃!段错误!
忘记手动释放:
Book* ptr = new Book();
// 忘了 delete ptr; // 内存泄漏!
六· 现代C++怎么解决这些问题?——“智能指针”
别怕,C++11 以后有了“智能指针”,它像“自动还书机”:
#include <memory>
// 自动管理内存,不用手动 delete
unique_ptr<Book> ptr = make_unique<Book>();
ptr->read(); // 正常使用
// 函数结束,自动释放内存,安全又省心
-
这就类似我们普通指针,赋能添加了自动delete工作!
-
有了智能指针,从此麻麻再也不怕我用指针操作,忘记delete了!
七· 何时使用指针 vs 直接定义对象?
下面基于上文所有的举例以及博主总结得到下面的使用推荐方法:
| 场景 | 推荐方式 | 备注 |
|---|---|---|
| 小对象,函数内使用 | MyClass obj; | 栈分配,自动管理生命周期 |
| 需要多态(猫/狗) | Base* ptr = new Derived(); | 需配合delete手动释放 |
| 大对象,避免拷贝 | func(Object* ptr) | 指针传递避免拷贝开销 |
| 动态结构(链表) | Node* next | 典型指针链接结构 |
| 现代C++项目 | unique_ptr/shared_ptr | 优先使用智能指针管理资源 |
八· 总结
用指针不是因为“高级”,而是因为“需要”,指针不是“炫技”,而是为了解决实际问题而存在的工具。
记住:
能不用指针就不用,要用就用智能指针。
如果你觉得这篇文章帮你理清了思路,欢迎点赞、收藏、转发!
欢迎在评论区留言:
“我以前一直搞不懂指针,现在终于明白了!”










的核心过滤器详解)



——资料分析、数量(强化训练))
![Agents-SDK智能体开发[3]之多Agent执行流程](http://pic.xiahunao.cn/Agents-SDK智能体开发[3]之多Agent执行流程)



