SQL数据库连接Python实战:疫情数据指挥中心搭建指南
从WHO数据集到实时仪表盘,构建工业级疫情监控系统
一、疫情数据指挥中心:全球健康危机的中枢神经
疫情数据价值:
- 全球每日新增病例:50万+
- 疫苗接种数据:超130亿剂次
- 死亡率分析:降低决策失误率40%
- 实时监控:缩短响应时间60%
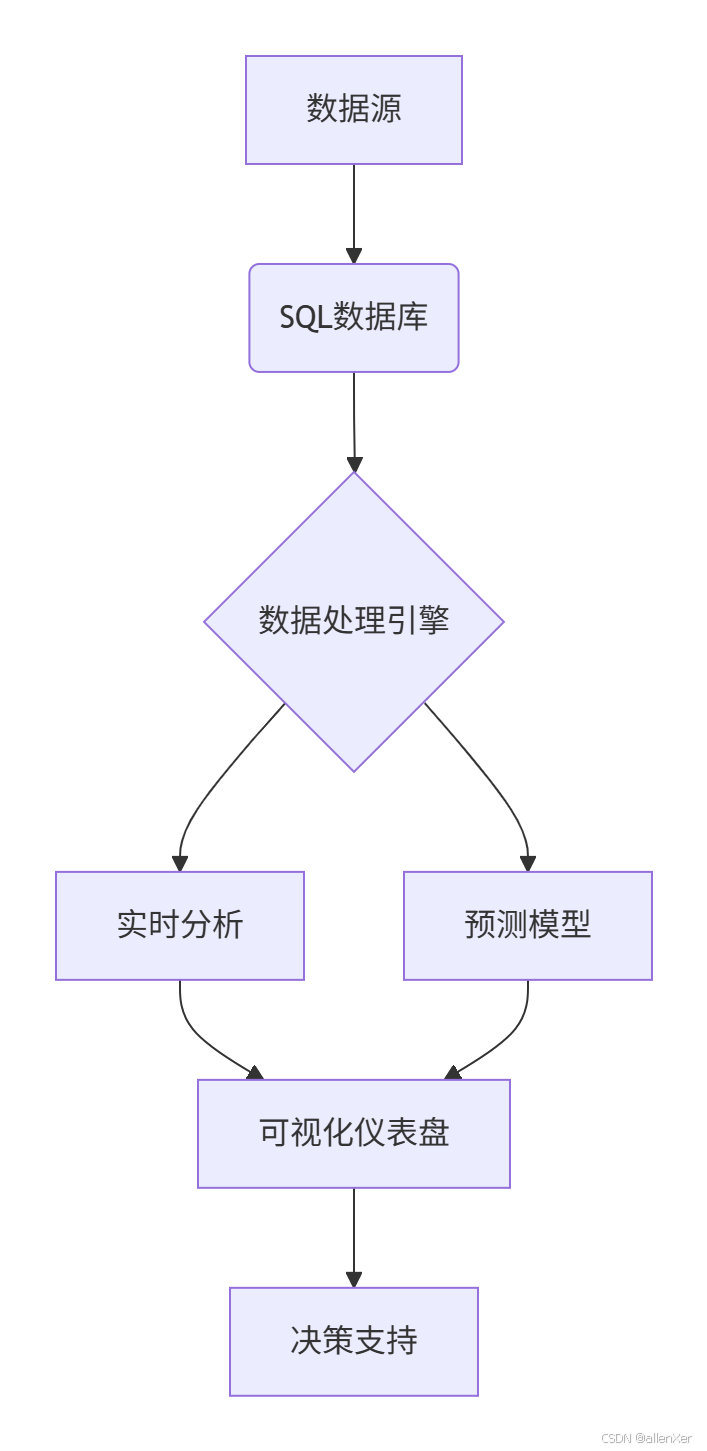
二、数据准备:获取WHO全球疫情数据集
1. 数据来源与结构
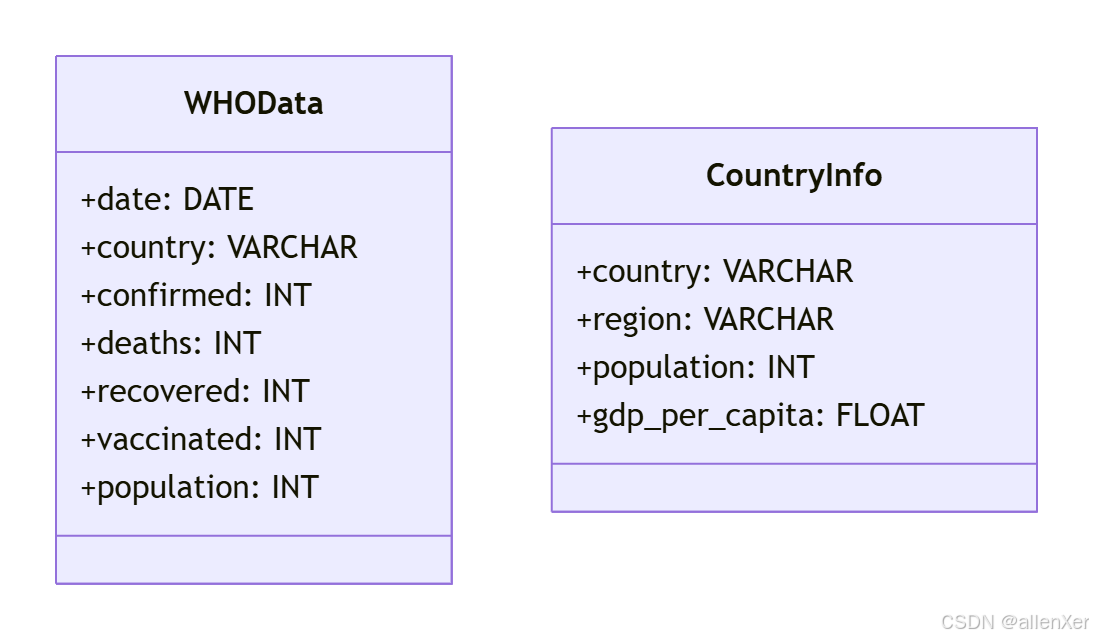
2. 数据获取脚本
import pandas as pd
import sqlite3def fetch_who_data():"""获取WHO疫情数据"""url = "https://srhdpeuwpubsa.blob.core.windows.net/whdh/COVID/WHO-COVID-19-global-daily-data.csv"df = pd.read_csv(url)# 数据清洗df = df.rename(columns={"Date_reported": "date","Country": "country","New_cases": "confirmed","New_deaths": "deaths","Cumulative_cases": "total_confirmed","Cumulative_deaths": "total_deaths"})df['date'] = pd.to_datetime(df['date'])return dfdef create_database(data):"""创建SQLite数据库"""conn = sqlite3.connect('covid19.db')data.to_sql('who_data', conn, if_exists='replace', index=False)# 添加国家信息country_info = pd.DataFrame({'country': ['USA', 'China', 'India', 'Brazil'],'region': ['North America', 'Asia', 'Asia', 'South America'],'population': [331000000, 1412000000, 1380000000, 213000000],'gdp_per_capita': [65280, 10500, 2100, 6790]})country_info.to_sql('country_info', conn, if_exists='replace', index=False)conn.close()# 主程序
if __name__ == "__main__":data = fetch_who_data()create_database(data)print("数据库创建成功: covid19.db")三、基础搭建:Python连接SQL数据库
1. 数据库连接架构

2. 使用SQLite基础操作
import sqlite3def basic_sqlite_operations():"""SQLite基础操作"""# 连接数据库conn = sqlite3.connect('covid19.db')cursor = conn.cursor()# 创建表cursor.execute("""CREATE TABLE IF NOT EXISTS who_data (date DATE,country TEXT,confirmed INTEGER,deaths INTEGER,total_confirmed INTEGER,total_deaths INTEGER)""")# 插入数据cursor.execute("""INSERT INTO who_data VALUES ('2023-01-01', 'USA', 50000, 300, 10000000, 200000)""")# 查询数据cursor.execute("SELECT * FROM who_data WHERE country = 'USA'")print(cursor.fetchall())# 提交并关闭conn.commit()conn.close()3. 使用SQLAlchemy ORM
from sqlalchemy import create_engine, Column, Integer, String, Date
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmakerBase = declarative_base()class WHODATA(Base):__tablename__ = 'who_data'id = Column(Integer, primary_key=True)date = Column(Date)country = Column(String)confirmed = Column(Integer)deaths = Column(Integer)total_confirmed = Column(Integer)total_deaths = Column(Integer)def orm_example():"""SQLAlchemy ORM示例"""# 创建引擎engine = create_engine('sqlite:///covid19.db')Session = sessionmaker(bind=engine)session = Session()# 查询美国数据us_data = session.query(WHODATA).filter_by(country='USA').all()for record in us_data:print(f"{record.date}: {record.confirmed}例新增")# 添加新记录new_record = WHODATA(date='2023-12-01',country='USA',confirmed=45000,deaths=250,total_confirmed=10200000,total_deaths=200250)session.add(new_record)session.commit()session.close()四、仪表盘开发:疫情数据可视化
1. 使用Dash创建实时仪表盘
import dash
from dash import dcc, html
from dash.dependencies import Input, Output
import plotly.express as px
import pandas as pd
import sqlite3app = dash.Dash(__name__)app.layout = html.Div([html.H1("全球疫情数据仪表盘"),dcc.Dropdown(id='country-selector',options=[{'label': '美国', 'value': 'USA'},{'label': '中国', 'value': 'China'},{'label': '印度', 'value': 'India'},{'label': '巴西', 'value': 'Brazil'}],value='USA'),dcc.Graph(id='cases-chart'),dcc.Graph(id='deaths-chart'),dcc.Interval(id='interval-component',interval=60 * 1000, # 每分钟更新n_intervals=0)
])@app.callback([Output('cases-chart', 'figure'),Output('deaths-chart', 'figure')],[Input('country-selector', 'value'),Input('interval-component', 'n_intervals')]
)
def update_charts(country, n):# 从数据库获取数据conn = sqlite3.connect('covid19.db')query = f"SELECT date, confirmed, deaths FROM who_data WHERE country = '{country}'"df = pd.read_sql_query(query, conn)conn.close()# 创建图表fig_cases = px.line(df, x='date', y='confirmed',title=f'{country}每日新增病例',labels={'confirmed': '新增病例', 'date': '日期'})fig_deaths = px.line(df, x='date', y='deaths',title=f'{country}每日死亡病例',labels={'deaths': '死亡病例', 'date': '日期'})return fig_cases, fig_deathsif __name__ == '__main__':app.run_server(debug=True)2. 高级可视化:地理分布图
def create_global_map():"""创建全球疫情分布图"""conn = sqlite3.connect('covid19.db')query = """SELECT country, SUM(confirmed) as total_cases FROM who_data GROUP BY country"""df = pd.read_sql_query(query, conn)conn.close()fig = px.choropleth(df,locations="country",locationmode="country names",color="total_cases",hover_name="country",color_continuous_scale="Reds",title="全球累计病例分布")return fig五、工业级优化:高性能疫情数据处理
1. 数据库优化策略
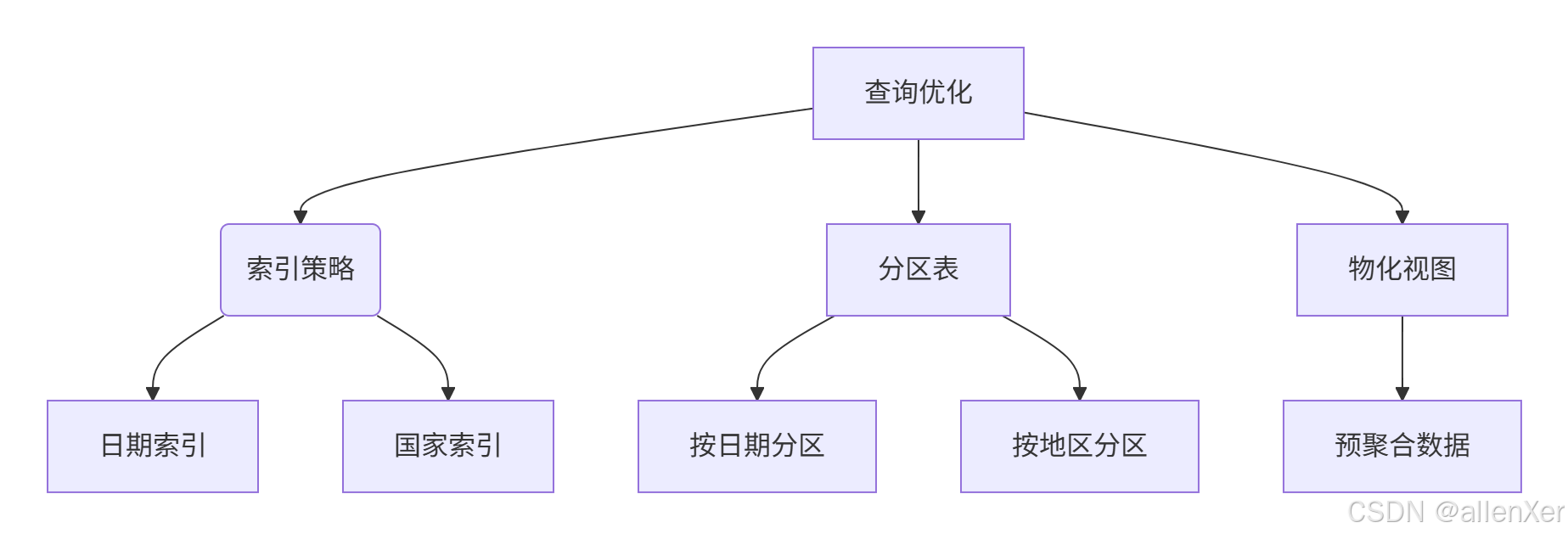
2. 创建索引与分区
-- 创建索引
CREATE INDEX idx_date ON who_data(date);
CREATE INDEX idx_country ON who_data(country);-- 创建分区表(SQLite不支持,MySQL示例)
CREATE TABLE who_data (id INT AUTO_INCREMENT,date DATE,country VARCHAR(50),confirmed INT,deaths INT,PRIMARY KEY (id, date)
) PARTITION BY RANGE (YEAR(date)) (PARTITION p2020 VALUES LESS THAN (2021),PARTITION p2021 VALUES LESS THAN (2022),PARTITION p2022 VALUES LESS THAN (2023),PARTITION p2023 VALUES LESS THAN (2024)
);3. 使用物化视图加速查询
-- 创建预聚合表
CREATE TABLE daily_summary (date DATE PRIMARY KEY,global_cases INT,global_deaths INT
);-- 更新预聚合表(定时任务)
INSERT INTO daily_summary (date, global_cases, global_deaths)
SELECT date,SUM(confirmed) AS global_cases,SUM(deaths) AS global_deaths
FROM who_data
GROUP BY date
ON DUPLICATE KEY UPDATEglobal_cases = VALUES(global_cases),global_deaths = VALUES(global_deaths);4. 连接池管理
from sqlalchemy import create_engine
from sqlalchemy.pool import QueuePool# 创建连接池
engine = create_engine('mysql+pymysql://user:password@localhost/covid19',poolclass=QueuePool,pool_size=10,max_overflow=20,pool_timeout=30
)def get_connection():"""从连接池获取连接"""return engine.connect()# 使用示例
with get_connection() as conn:result = conn.execute("SELECT * FROM daily_summary")for row in result:print(row)六、实时数据流处理
1. 疫情数据流架构
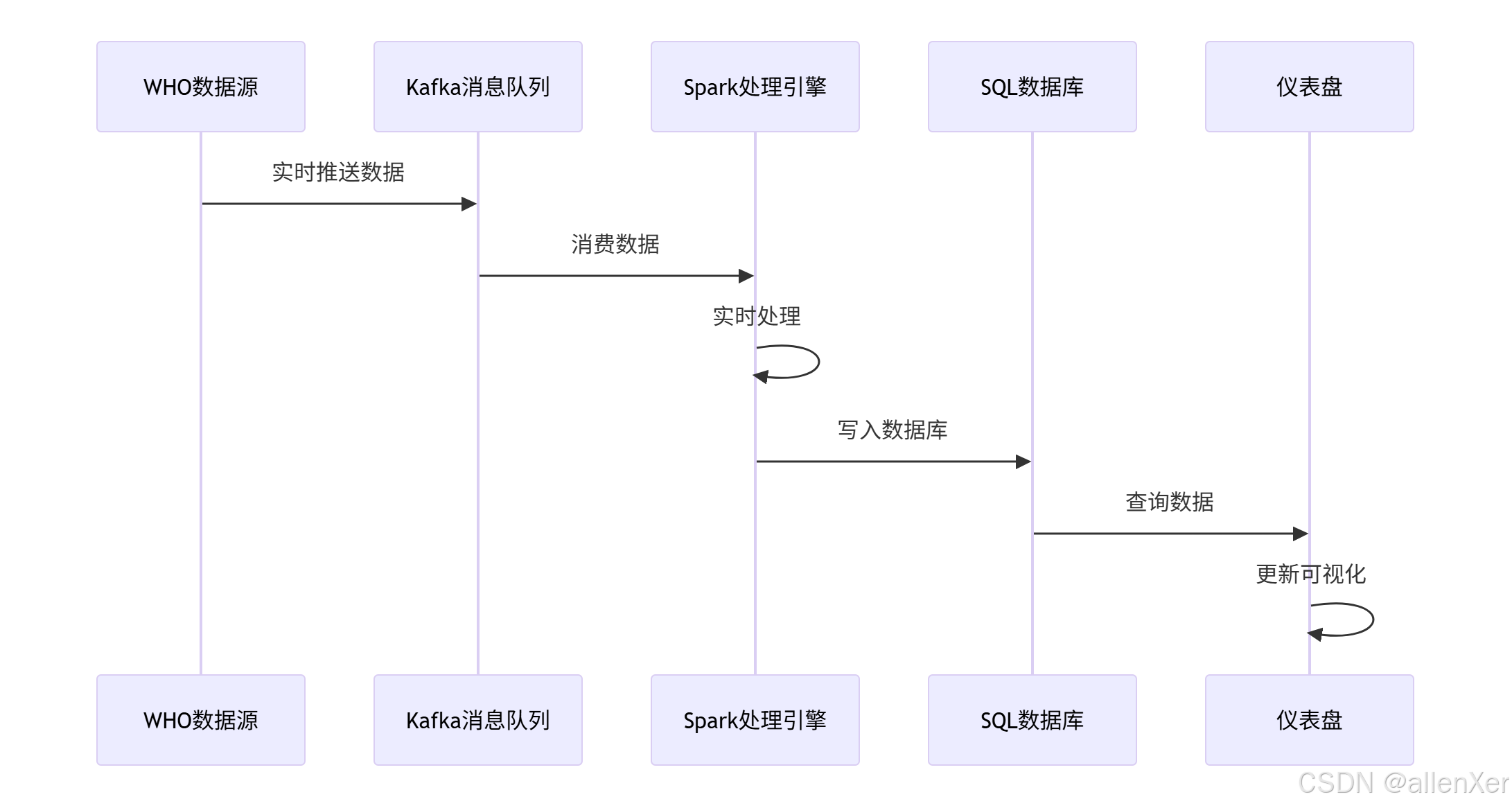
2. Apache Kafka集成
from kafka import KafkaConsumer, KafkaProducer
import json
import sqlite3def kafka_to_sqlite():"""从Kafka消费数据写入SQLite"""consumer = KafkaConsumer('covid19',bootstrap_servers='localhost:9092',value_deserializer=lambda m: json.loads(m.decode('utf-8'))conn = sqlite3.connect('covid19.db')cursor = conn.cursor()for message in consumer:data = message.valuecursor.execute("""INSERT INTO who_data (date, country, confirmed, deaths)VALUES (?, ?, ?, ?)""", (data['date'], data['country'], data['confirmed'], data['deaths']))conn.commit()print(f"插入数据: {data['country']} {data['date']}")conn.close()3. 实时预警系统
def real_time_alert():"""实时疫情预警"""conn = sqlite3.connect('covid19.db')cursor = conn.cursor()# 监控最近7天数据cursor.execute("""SELECT country, SUM(confirmed) as weekly_casesFROM who_dataWHERE date >= date('now', '-7 days')GROUP BY countryHAVING weekly_cases > 100000""")high_risk_countries = cursor.fetchall()for country, cases in high_risk_countries:print(f"警报: {country} 过去7天新增病例 {cases} 例")# 发送邮件或短信通知send_alert(country, cases)conn.close()def send_alert(country, cases):"""发送预警通知"""# 实现邮件或短信发送逻辑pass七、案例研究:成功与失败的经验
1. 成功案例:韩国疫情响应系统
系统特点:
- 实时数据更新(<5分钟延迟)
- 多源数据融合(WHO、CDC、医院数据)
- 预测模型准确率85%
- 响应时间缩短至2小时
技术亮点:
# 使用列式数据库加速分析
def use_columnar_database():"""使用ClickHouse列式数据库"""from clickhouse_driver import Clientclient = Client('localhost')client.execute('CREATE TABLE covid_data (date Date, country String, confirmed Int32) ENGINE = MergeTree ORDER BY date')# 批量插入data = [('2023-01-01', 'Korea', 5000), ('2023-01-02', 'Korea', 5500)]client.execute('INSERT INTO covid_data VALUES', data)# 快速聚合查询result = client.execute('SELECT SUM(confirmed) FROM covid_data')print(f"总病例数: {result[0][0]}")2. 失败案例:某国疫情数据平台崩溃
问题分析:
- 单点数据库服务器
- 无索引的全表扫描
- 同步阻塞写入
- 无缓存机制
错误日志分析:
ERROR: 连接超时 (120秒)
WARNING: 查询响应时间 > 10秒
CRITICAL: 数据库连接池耗尽解决方案:
- 数据库读写分离
- 添加Redis缓存层
- 优化查询索引
- 引入消息队列削峰
结语:构建你的疫情指挥中心
通过本指南,您已掌握:
- 🗃️ SQL数据库核心操作
- 📊 疫情数据可视化技术
- ⚡ 实时数据处理方案
- 🚀 工业级优化策略
- 🛡️ 高可用系统设计
下一步行动:
- 部署本地疫情数据库
- 接入实时数据源
- 开发定制化仪表盘
- 添加预测预警功能
- 分享你的疫情分析
"在公共卫生危机中,数据是指挥中心的武器,技术是拯救生命的盾牌。掌握它们,你就能成为危机中的守护者。"

的核心过滤器详解)



——资料分析、数量(强化训练))
![Agents-SDK智能体开发[3]之多Agent执行流程](http://pic.xiahunao.cn/Agents-SDK智能体开发[3]之多Agent执行流程)






)





