文章目录
- 参考资料
- 说明
- 大模型微调入门
- 微调简介
- 微调步骤
- 数据准备
- 模型选择
- 训练方式
- 效果评估
- 模型部署
- 大模型微调(基于讯飞星辰Maas)
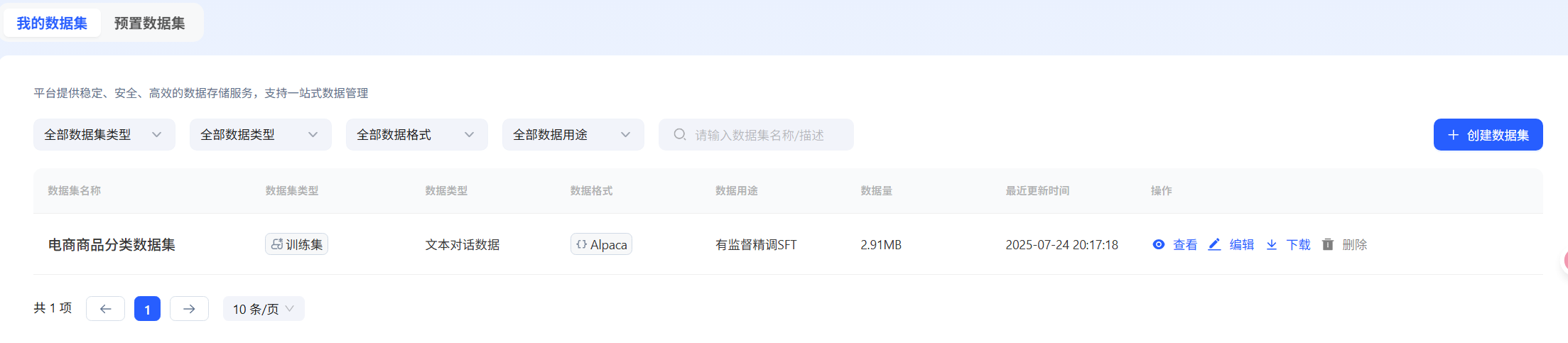
- 构建数据集
- 方法1:预置数据集
- 方法2:创建数据集
- 数据辅助工具
- 数据集划分
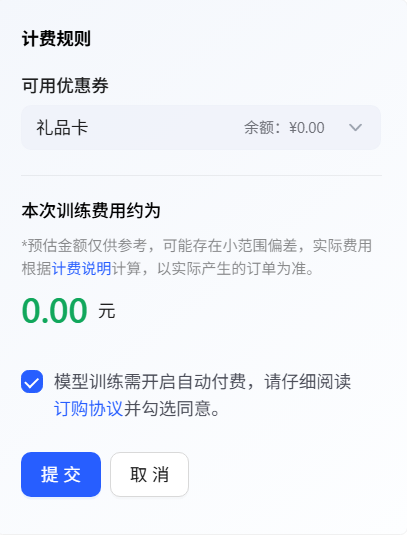
- 模型微调
- 数据配置
- 参数配置
- 模型部署和评估
- 发布服务
- 在线体验
- 批量处理
- 模型评估
- 诗词生成实践
- 商品分类任务数据集校验失败问题解决
参考资料
- 大模型微调基础入门
- 大模型微调平台介绍
- 实践分享
说明
- 本文仅供学习和交流使用,版权归原作者所有,请勿进行商业用途!
- 由于文本创作期间,模型未运行完成,文中部分图片借用官方图片,实际页面布局可能存在差异,请理解。
大模型微调入门
微调简介
- 大语言模型(LLM)是一种专注于处理语言数据的人工智能模型,通过分析和学习海量文本数据来掌握语言的语法、语义和上下文关系,从而实现自然语言的理解与生成。
- 在面对特定任务时,可能还需要进一步的调整和优化。这就是俗称的大模型微调。
- 大模型微调(Fine-Tuning)是在一个已经训练好的模型基础上,针对特定任务进行进一步训练,使其在该任务上表现更好。
微调步骤
- 微调模型通常需要经过几个步骤,每个步骤都非常重要,直接影响到最终模型的表现。
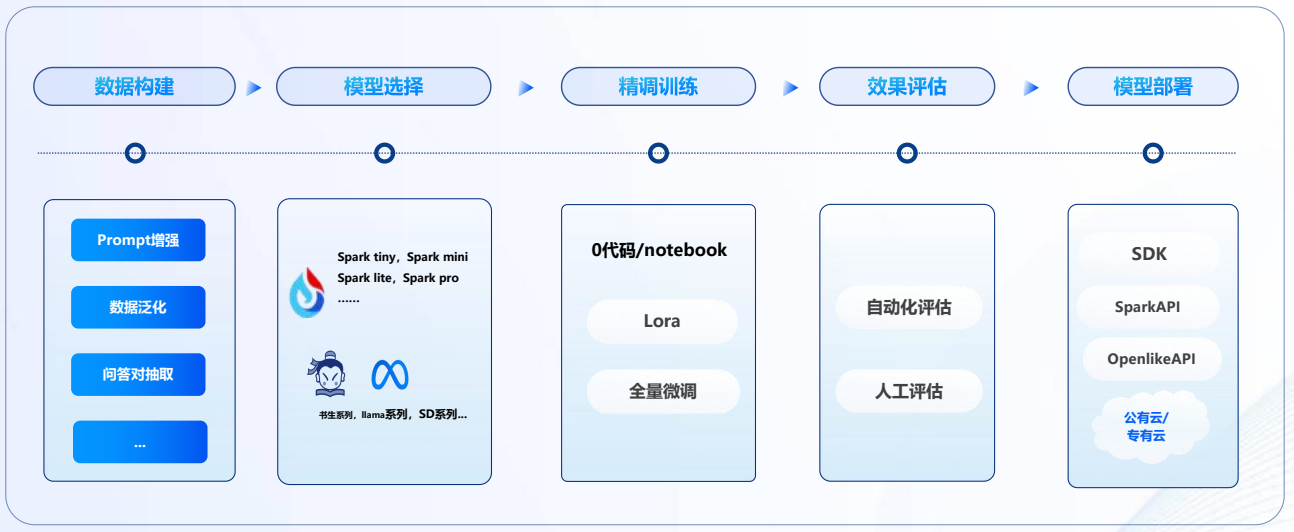
数据准备
- 数据准备:收集和整理与特定任务相关的数据集。数据集应该尽可能地多样化和全面,以便模型能够学习到各种不同的情况和模式。
- 数据构建常见的问题:只有文本数据,没有问答对数据、数据量不足、数据质量较低、数据集优化不足、数据积累困难。
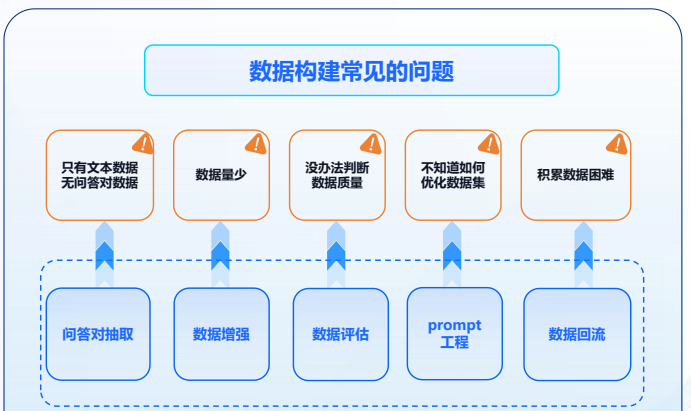
- 星辰MaaS针对不同场景提供多种数据构建功能,基于人机协作的工具可以大幅提升高质量数据集构建的效率。
模型选择
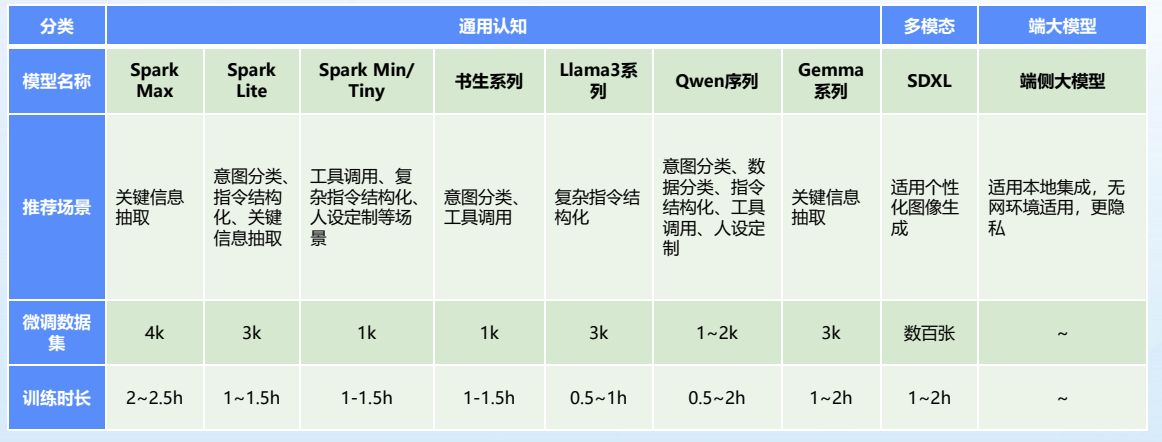
- 在数据准备好之后,需要选择一个合适的预训练模型进行微调。不同的任务可能需要不同的模型,需要根据具体情况来选择。例如:讯飞星辰MaaS平台以星火优质大模型为核心,扩展支持主流开源大模型,提供更多选择。
训练方式
- LoRA(Low-Rank Adaptation、低秩适配、部分参数微调):每次只会对模型新增的少量数据即可进行更新,旨在减少计算资源和存储需求,同时保持较高的性能,还减少过拟合的风险,所需数据和训练时长相对全量微调少很多。
- FFT(Full Fine-Tuning、全参数微调、全量微调):充分利用基础模型的表示能力,通过调整所有参数使其更好地适应特定任务,在全量微调过程中,所有模型参数都会被优化,这意味着模型的每一层都会根据特定任务的数据进行调整。
效果评估
- 训练完成后,需要对模型进行评估,以确定模型在特定任务上的表现,以此来判断是否需要持续迭代。
模型部署
- 星辰MaaS平台对微调后的模型可以按需发布为API/SDK服务,提供标准开放、即用即销模式,赋能创新。可以接入已有产品使用,可以开发创新产品,也可以在讯飞开放平台开放。
- 开源模型支持下载满足本地运行需求。
大模型微调(基于讯飞星辰Maas)
- 讯飞星辰MaaS微调平台:平台以星火认知大模型和优质开源大模型为基础,重点发力数据工程,数据构建质量形成竞争优势,围绕数据管理,模型微调、评估、托管,推理服务完善大模型全生命周期管理,覆盖内容创作、代码、逻辑推理等多场景,无需复杂调整或重新训练,甚至零代码也可以完成微调!
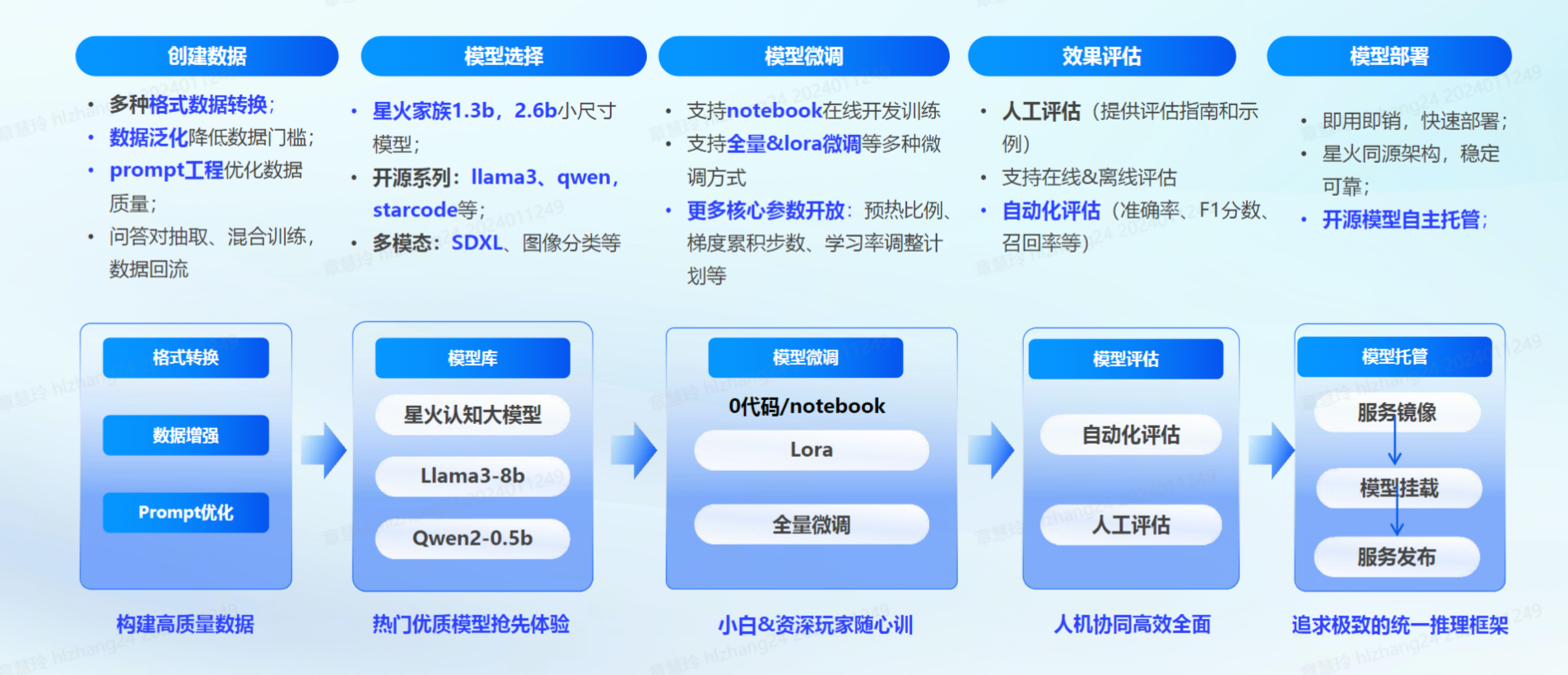
构建数据集
- 在进行微调训练前需要明确目标任务和数据需求,并准备好相关训练数据,星辰MaaS微调平台提供丰富的 【预置数据集】可供用户直接用于训练,也可以选择【创建数据集】,平台提供【问答对抽取】、【数据增强】、【prompt工程】 三种辅助工具来优化数据,进一步提高数据质量。
数据集的获取有两种主要途径:
-
依据特定业务需求自行定义数据集 确保数据与业务场景紧密贴合,从而提升模型在实际应用中的表现。
-
利用公开数据集 公开数据集丰富多样且涵盖广泛的领域,能够满足许多常见任务的基础数据需求。
-
平台为提供预制数据集(数据集管理-预置数据集),可直接用于模型训练;同时配备问答对抽取功能,我们只需导入文本文件或网站链接,系统便能自动切分问答对,快速生成训练所需的数据。
方法1:预置数据集
- 平台提供的预置数据集包括多个行业领域,可以选择相应领域的数据集进行模型微调,但「预置数据集」本身不支持用户更改转化。例如,可以直接选择平台预置数据集里的“sentiment_predict”开源数据用于训练情感分类。
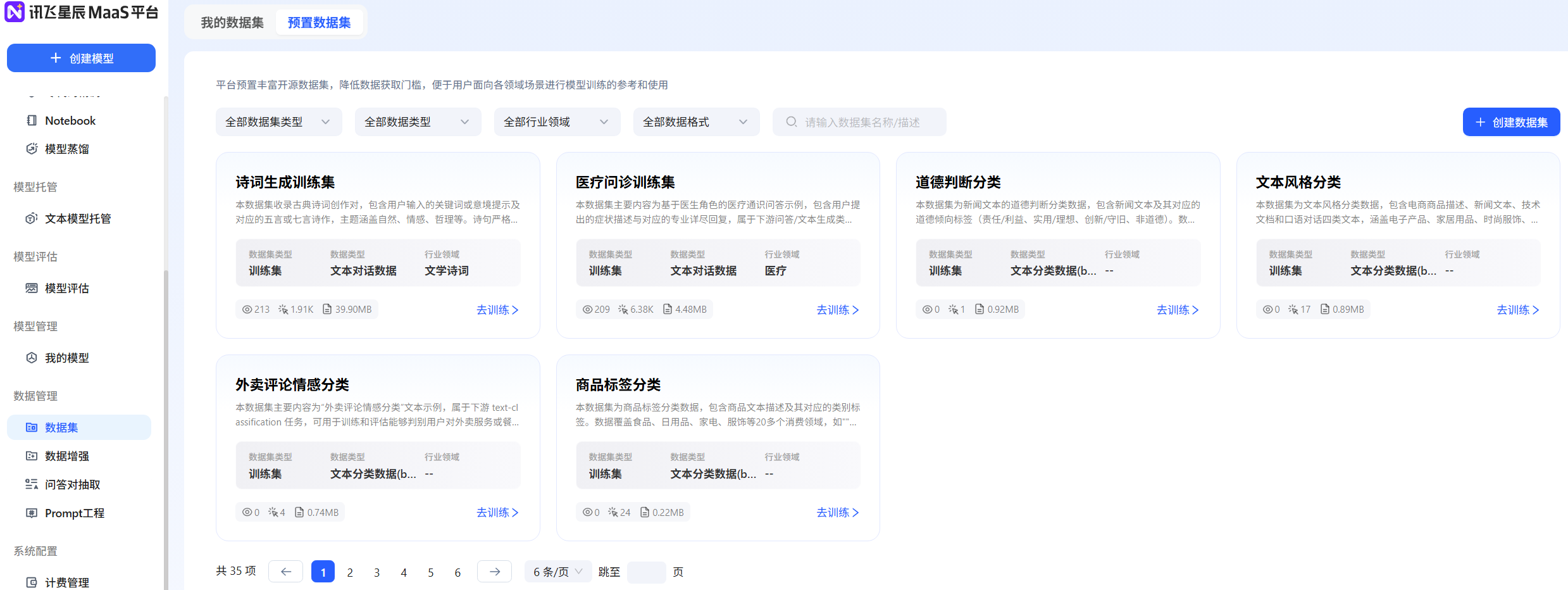
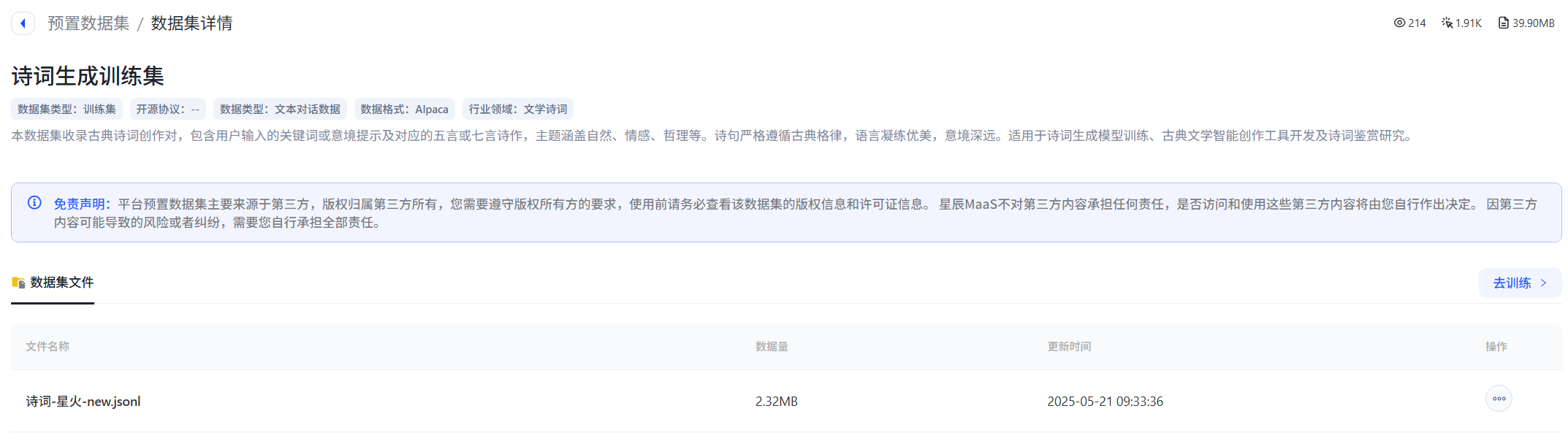
方法2:创建数据集
- 也可以通过创建数据集来上传自己的训练数据,目前仅支持导入json、jsonl、csv格式的单个文件,具体可参照模型微调数据集格式 (opens new window)说明。
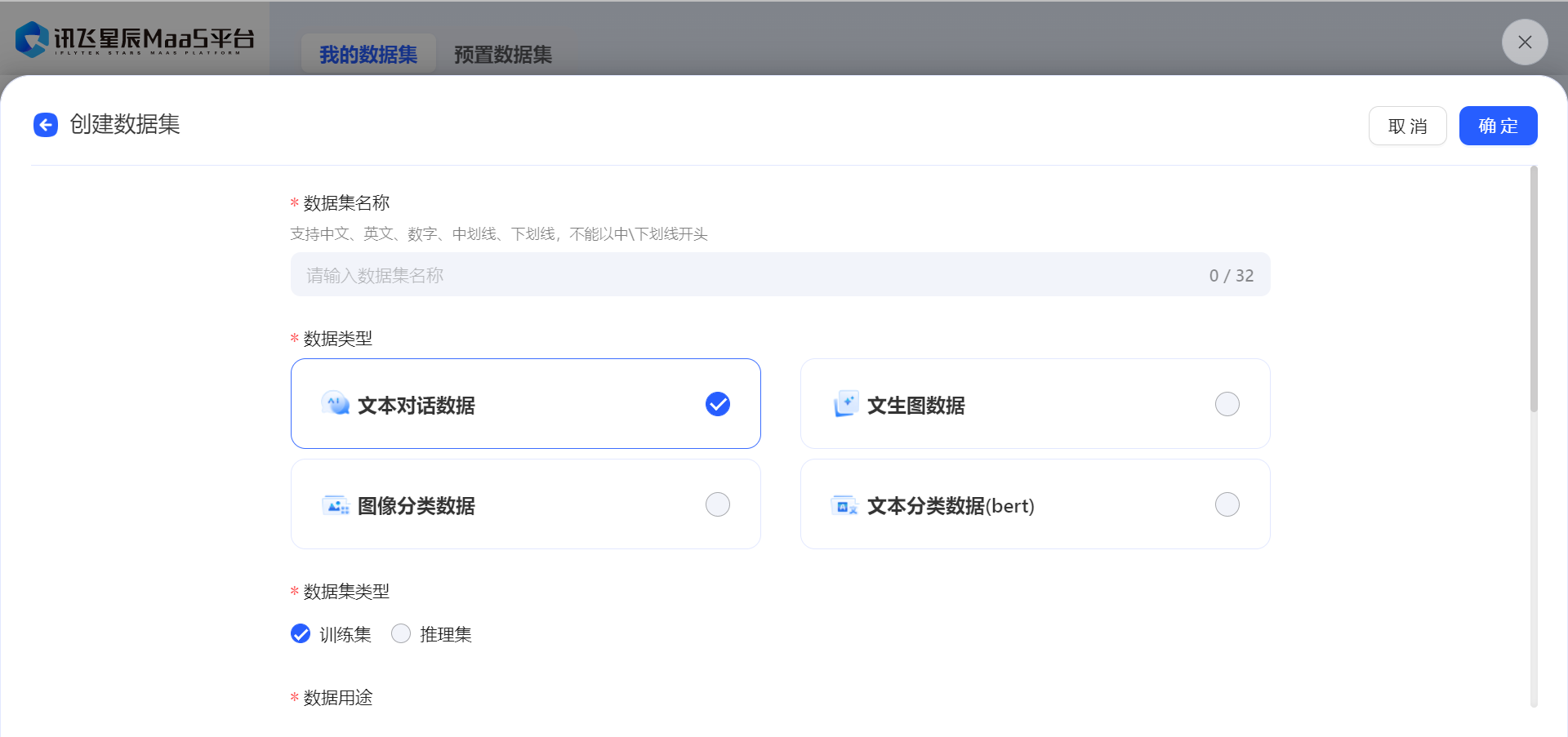
数据辅助工具
- 问答对抽取:只有文本数据,无问答对数据,【问答对抽取】功能,选择导入txt等格式文本文件或网站链接,平台能够自动切分问答对,也支持自定义切分分隔符,自动抽取问答对数据。
- 【问答对抽取】得到问答对数据集满足大模型微调数据集所需格式,正确率可达90%,覆盖率不低于75%,可以下载生成的数据集用于微调。
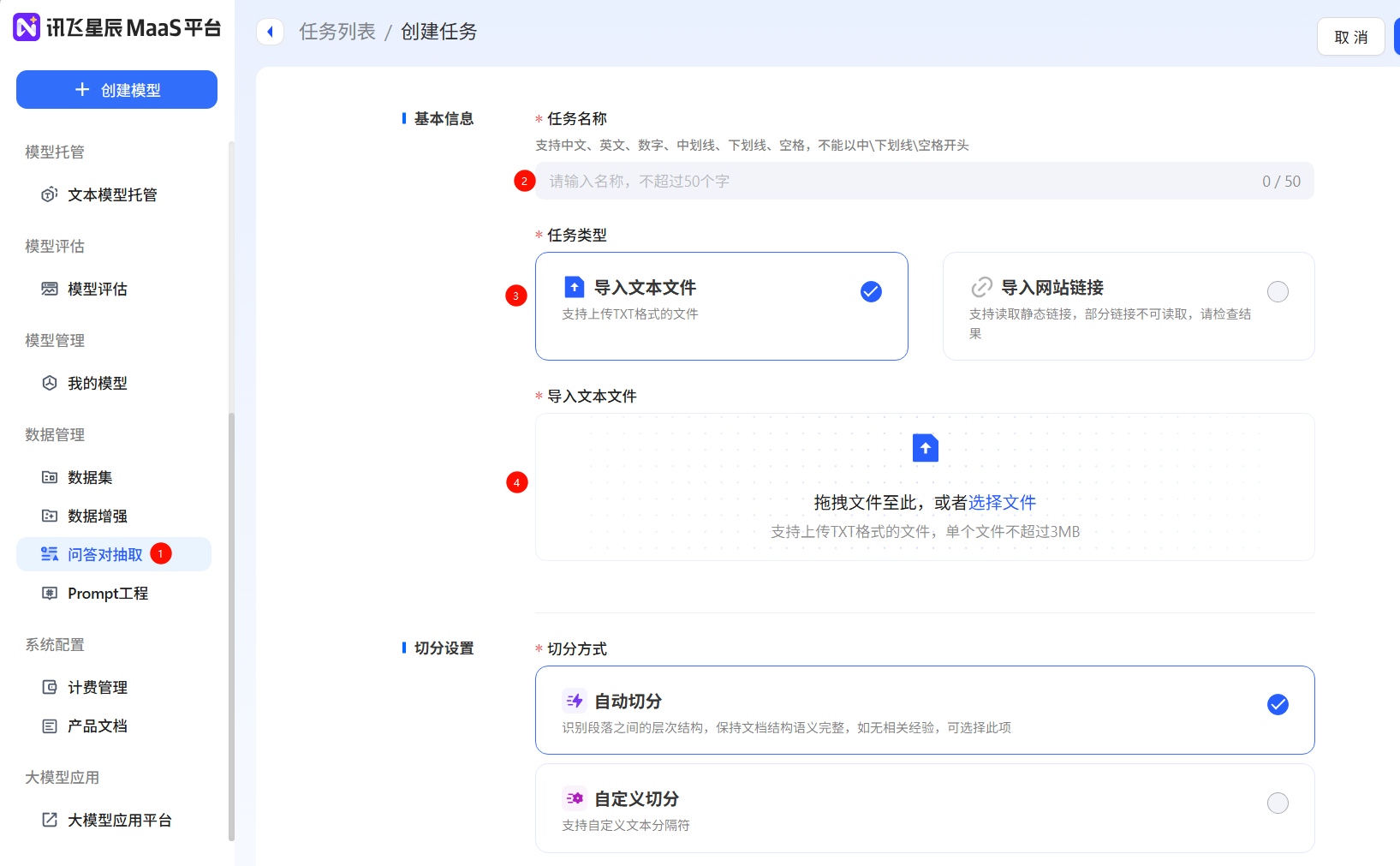
- 数据增强:如果原本的数据量过少可以对常见文本生成、理解、知识问答数据泛化,扩展数据集数量。在【数据增强】板块,可以通过【创建任务】实现批量增强,支持选择增强倍数和质量等方式,也可以通过【在线增强】和【在线优化】来查看单条数据增强的效果。
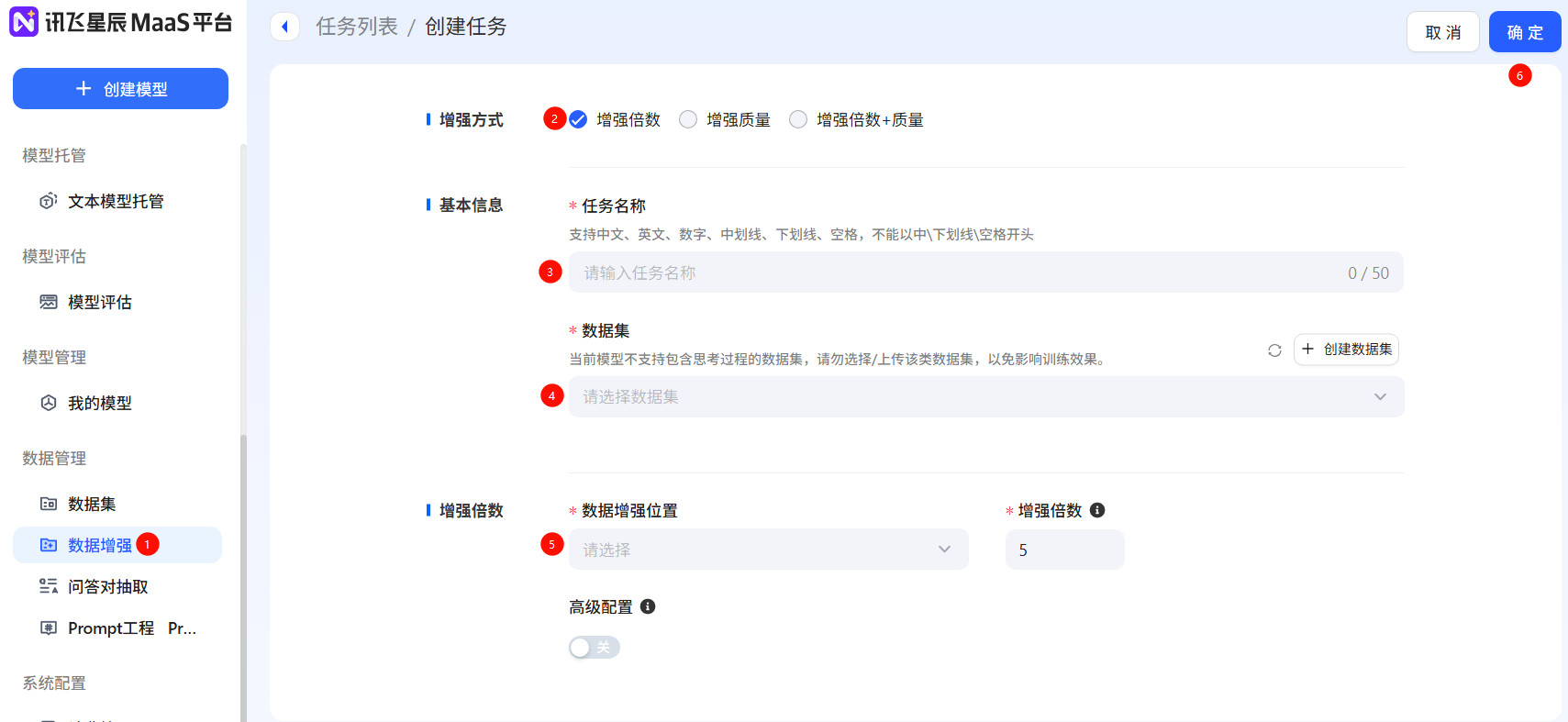
- prompt工程:平台支持基于prompt工程的数据集构建优化,提供50+常见prompt模板,满足多种类型数据需求。
- 根据训练集数据格式要求调整数据集对应成instruction、input、output里的内容,经过处理,最终形成的一条完整数据格式应该如下所示:
{"instruction": "你是一个情感分析助手,目标是辨别推文的情感倾向,情感倾向分为积极和消极。接下来,我会给你推文的内容,请你告诉我情感分析的答案",
"input": "一百多和三十的也看不出什么区别,包装精美,质量应该不错",
"output": "积极"}
数据集划分
- SFT(Supervised Fine-Tuning,监督微调)是大模型训练流程中的关键环节,指在预训练模型基础上,通过有标签的特定任务数据调整模型参数,使其快速适配下游应用需求的技术。其核心思想是基于迁移学习,利用预训练阶段习得的通用知识(如语言理解、特征提取能力),在少量标注数据上优化模型,实现任务定制化。
- 在进行SFT(Supervised Fine-Tuning,监督微调)时,为了确保模型评估的公正性,通常需要将数据集划分为训练集、验证集和测试集,常见的划分比例为 70% 训练集、15% 验证集、15% 测试集。
- 训练集:用于训练模型的主要数据集。
- 验证集:在微调过程中用于调优超参数和选择最优模型。
- 测试集:用于最终评估模型性能,确保微调后的模型在未见数据上的表现。
模型微调
-
在进行基础数据的获取和优化后,可以选择基础模型、上传训练集进行模型微调训练。
-
根据任务的复杂程度和场景需求,评估平台上提供的各种模型的尺寸和特性,选择最匹配的模型来完成任务。首先,需要明确任务类型,例如是文本生成、对话、图像分类、逻辑推理等;其次,选择模型尺寸。
- 轻量级模型:适合简单的文本生成、对话等任务,如 Spark Mini、Spark Mini Instruct,这些模型资源消耗少,训练速度快,适用于日常的内容创作和对话系统。
- 中等复杂任务:如知识问答、情感分析等,选择 Spark Lite、Spark Lite Patch,它们在性能与资源需求之间提供了良好的平衡,适合一般的应用场景。
- 相对复杂任务:对于要求高度精准和复杂任务(如工业自动化中的指令处理或智能家居控制),选择 Spark Max 等更大尺寸的模型,以满足高计算需求和精确度要求。
-
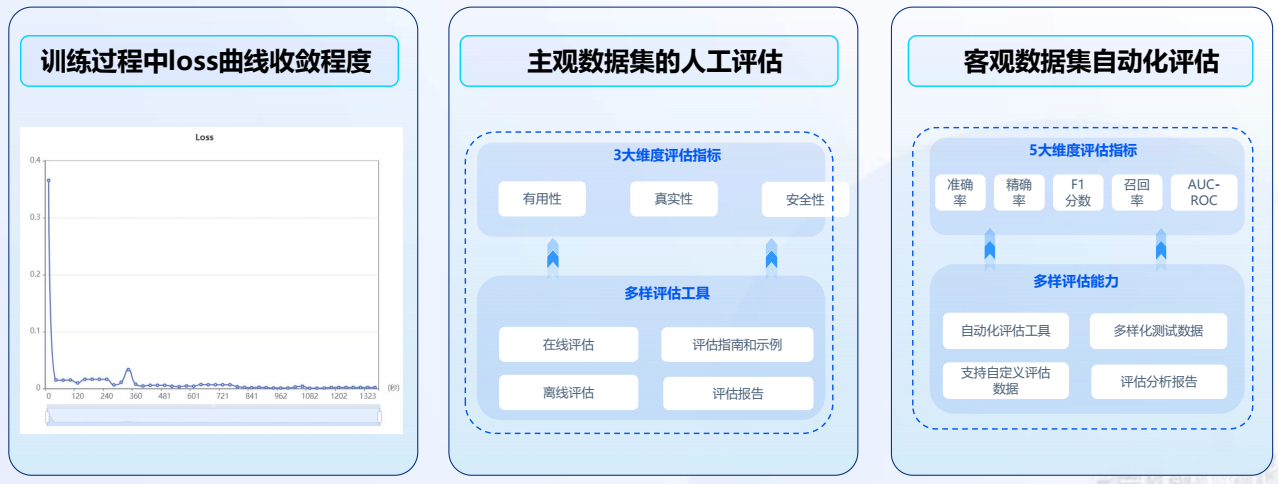
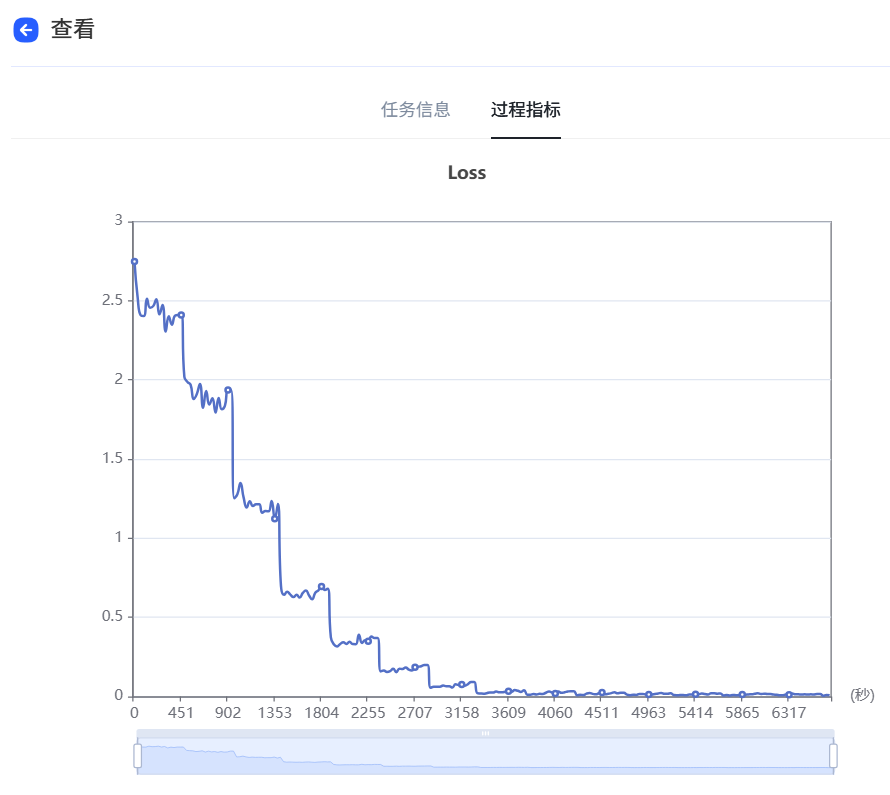
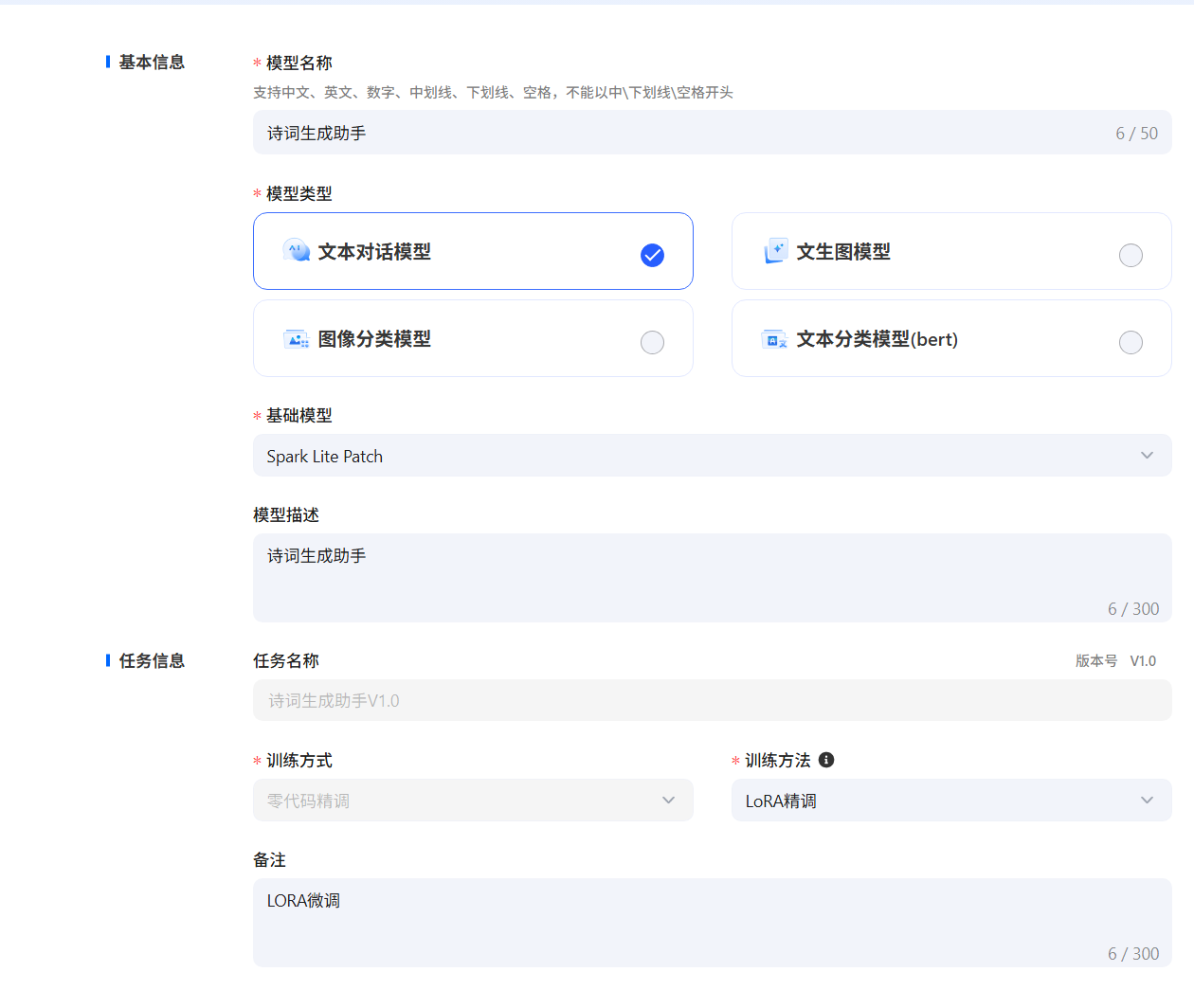
例如,选择“Spark Lite Patch”模型,填写模型名称等信息。训练参数可以按照默认,也支持用户自由调节,点击提交,当任务状态变为运行成功后,即微调任务完成,支持查看loss曲线过程指标等微调信息,loss曲线越收敛微调效果越好,随时评估模型效果。
-
创建模型,填写模型信息(这里只支持零代码微调),如果希望使用notebook实时查看loss曲线,需要在Notebook中创建任务,训练方式为Notebook微调
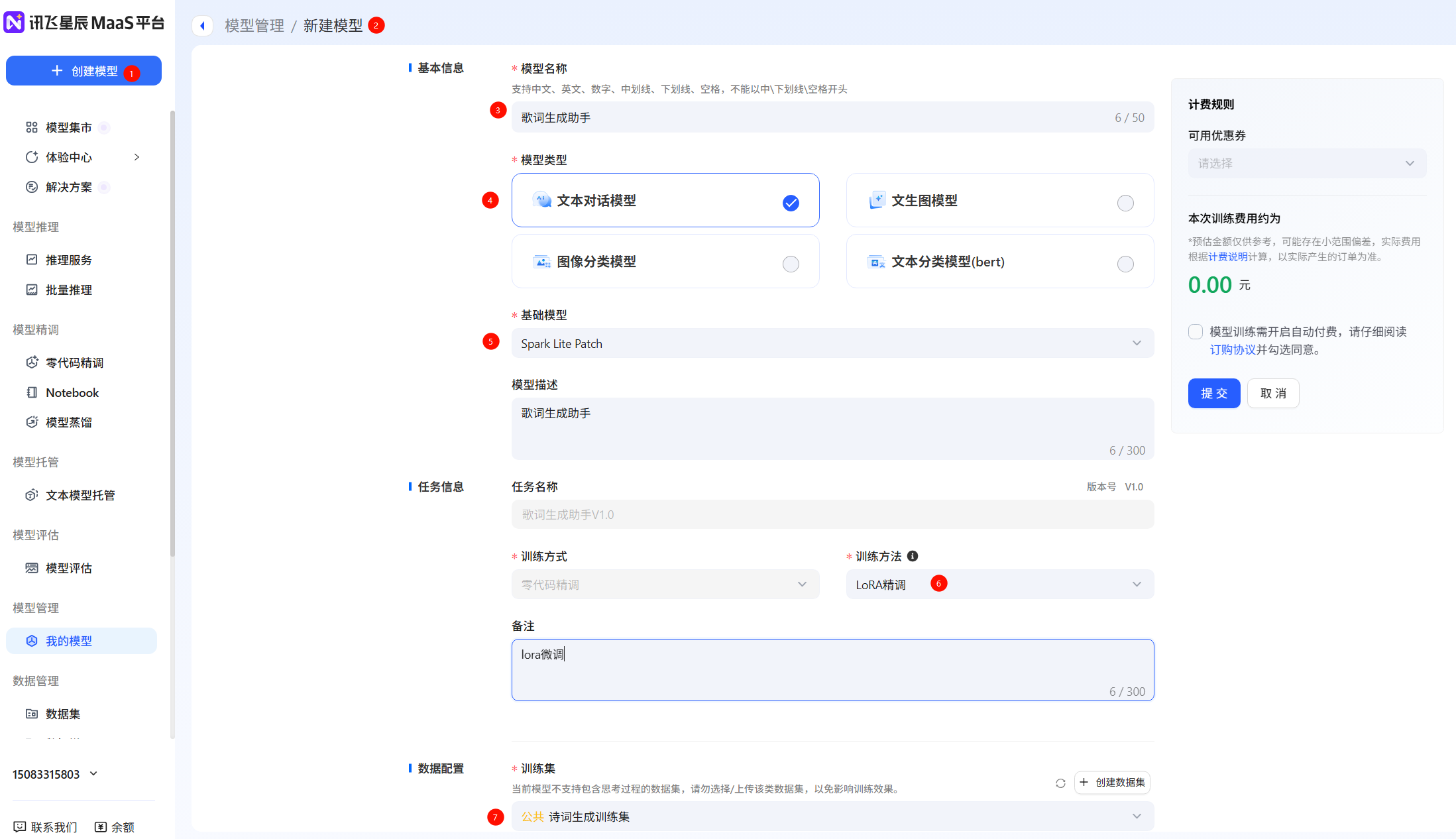
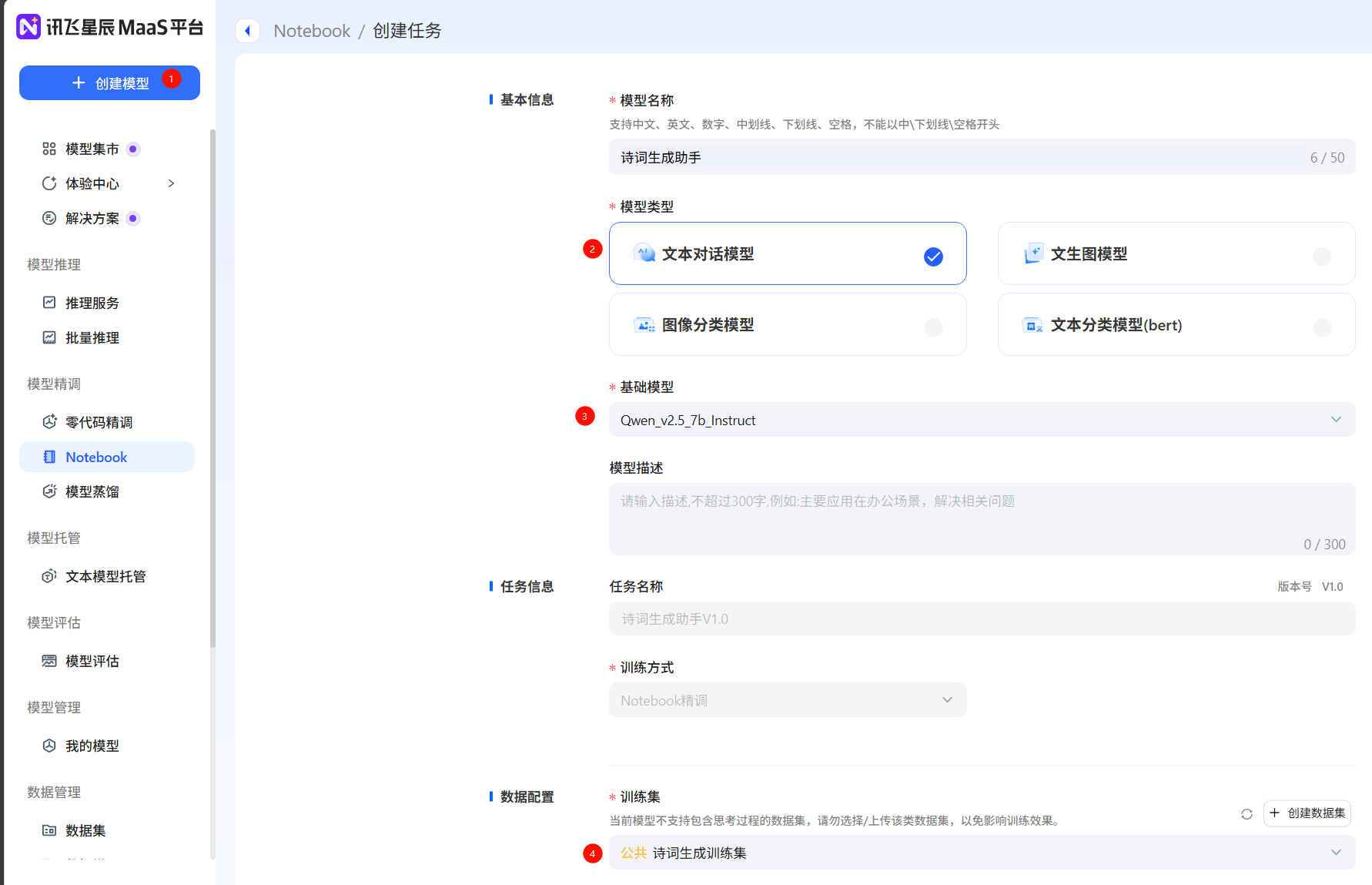
-
点击运行,等待运行,查看微调配置。

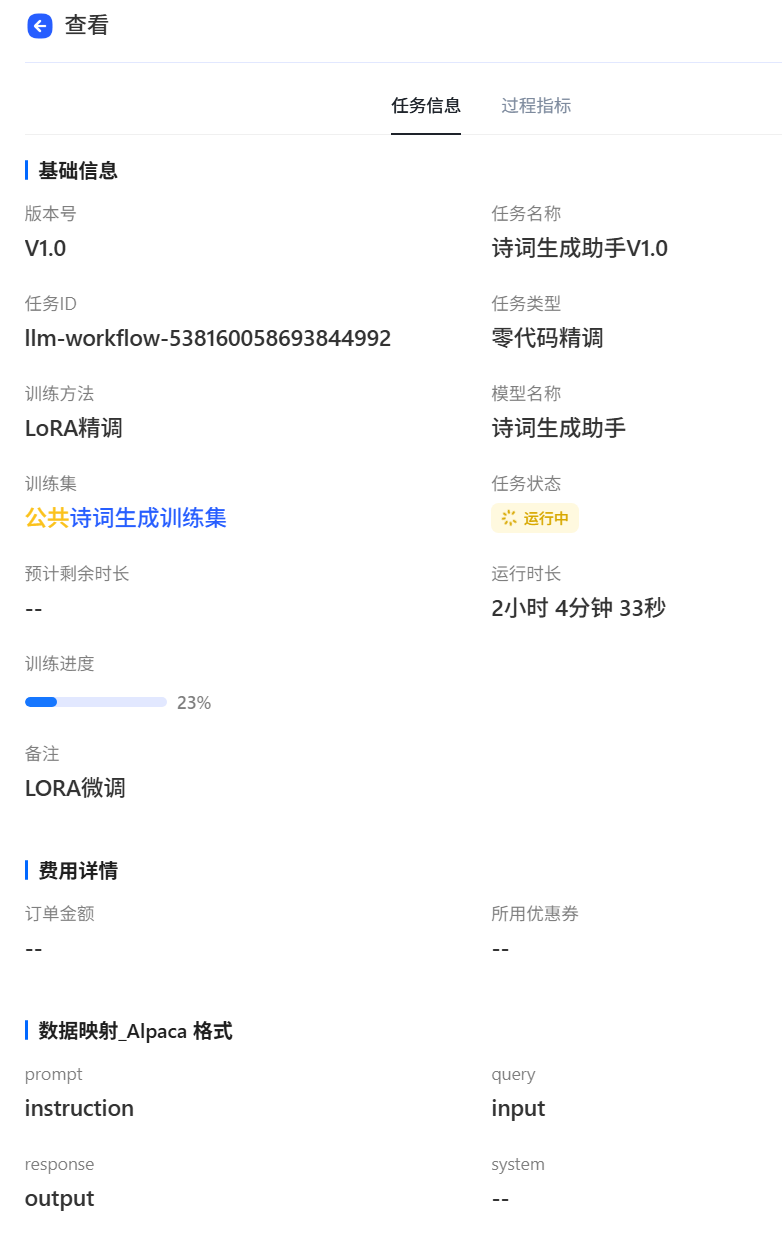
-
loss曲线
数据配置
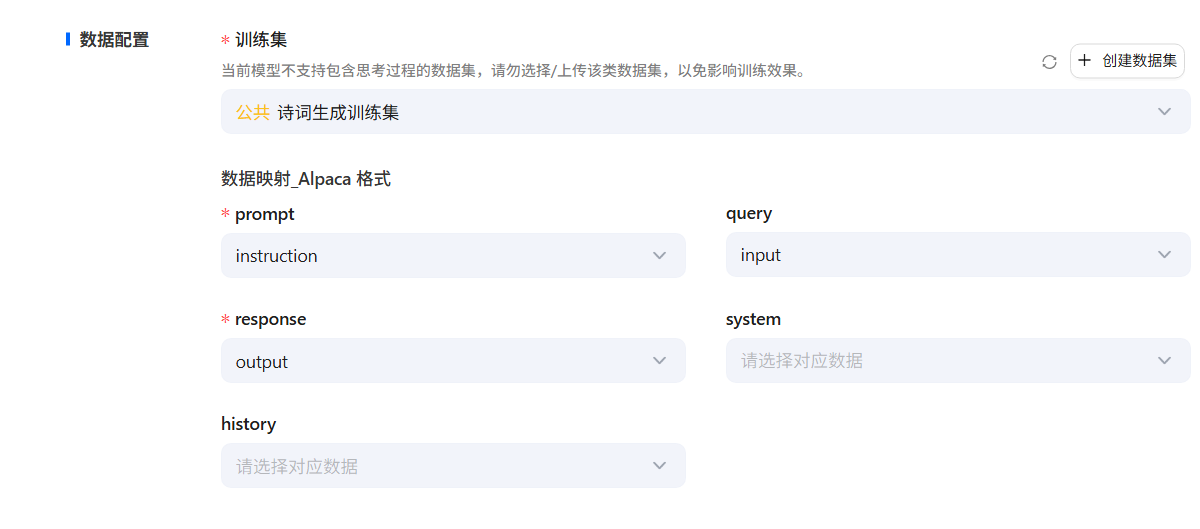
- 在创建模型页面选择训练集,进一步进行数据配置工作,明确各个数据字段之间的对应关系。
在平台中,Alpaca格式的训练由以下5个字段组成:
- instruction:将与
input内容拼接,形成模型的输入指令。最终的模型输入指令格式为instruction\input。 - output:包含模型的期望输出,是训练过程中模型要生成的回答。
- system:如果勾选相关选项,此列的内容将作为系统提示词提供给模型,以便在任务中引入额外的上下文信息。
- history :包含多个字符串二元组,代表对话历史中的指令与回答,有助于模型理解上下文,提升对话生成的准确性。
- 根据此前构建的商品分类数据集格式,数据映射关系如下:
prompt -> instruction text -> input label -> output
参数配置
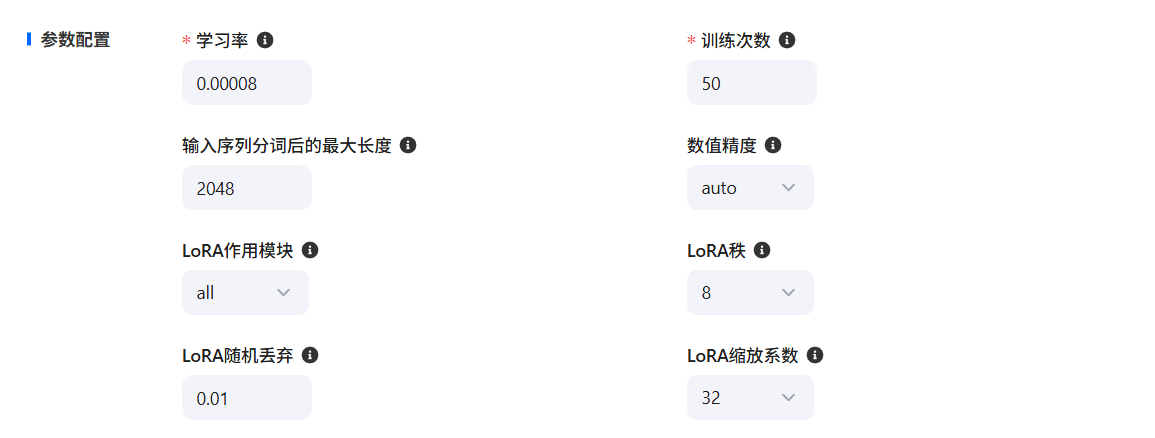
- 在参数配置板块,可以通过调整参数,控制模型训练效果。常见参数包括:学习率、训练次数、分词最大长度、数值精度、LoRA秩、LoRA随机丢弃、LoRA缩放系数。
- 学习率:学习率是模型训练过程中调整权重的步长大小。
- 训练次数:训练次数指的是模型在整个训练数据集上进行迭代训练的次数。
- 分词最大长度:规定了输入序列在进行分词处理后允许的最大长度。
- 数值精度:数值精度通常涉及到模型计算中所使用的数据类型(如 float32、float16 等)。
- LoRA秩:决定了微调过程中引入的低秩矩阵的复杂度。
- LoRA随机丢弃:这个参数通常用于防止过拟合。
- LoRA缩放系数:定义LoRA适应的学习率缩放因子。
| 参数名称 | 参数大小影响 |
|---|---|
| 学习率 | 较小的学习率意味着模型在训练时权重更新较为缓慢,可以使模型更稳定地收敛,但可能需要更多的训练迭代次数。 |
| 训练次数 | 每次迭代都会更新模型的权重,训练次数越多,模型越有可能充分学习数据中的模式,但也可能导致过拟合。 |
| 输入序列分词后的最大长度 | 如果输入序列超过这个长度,可能需要进行截断或其他处理。 |
| 数值精度 | “auto” 可能表示系统会自动选择合适的数值精度。 |
| lora 作用模块 | 选择模型的全部或特定模块层进行微调优化。 |
| LoRA 秩 | 较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| Lora 随机丢弃 | Lora 随机丢弃以一定概率随机丢弃神经元的输出,这里 0.01 表示 1% 的概率。 |
| LoRA 缩放系数 | 参数过高,可能会导致模型的微调过度,失去原始模型的能力;改参数过低,可能达不到预期的微调效果。 |
模型部署和评估
发布服务
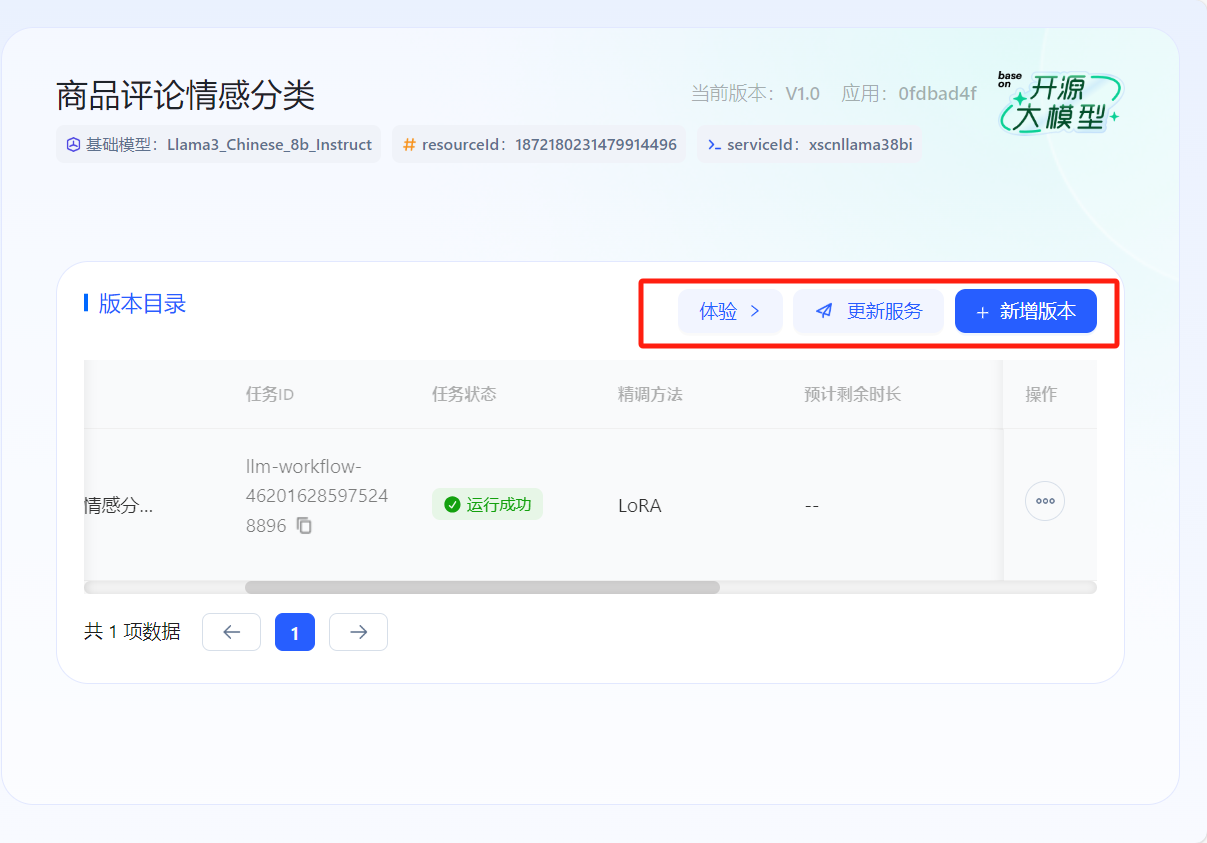
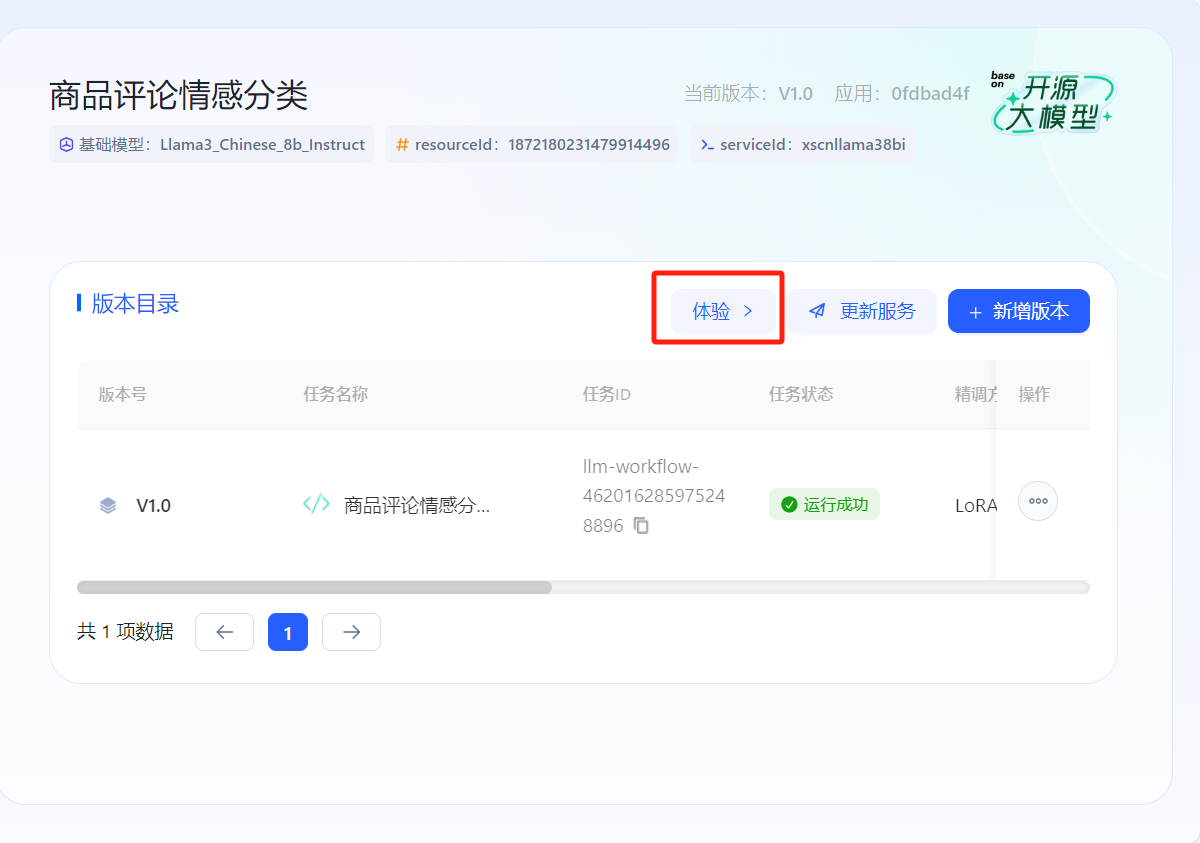
- 首先在开放平台-控制台中创建应用,在模型管理中选择相应任务点击【发布为服务】,将其授权至所创建的应用完成发布。发布成功后可以点击【体验】,获得在线体验,也可以点击【新增版本】继续微调模型获得性能更佳的模型。
- 注意:微调后的需要再次【更新服务】选择最新版本才可体验最新效果。
- 点击创建应用
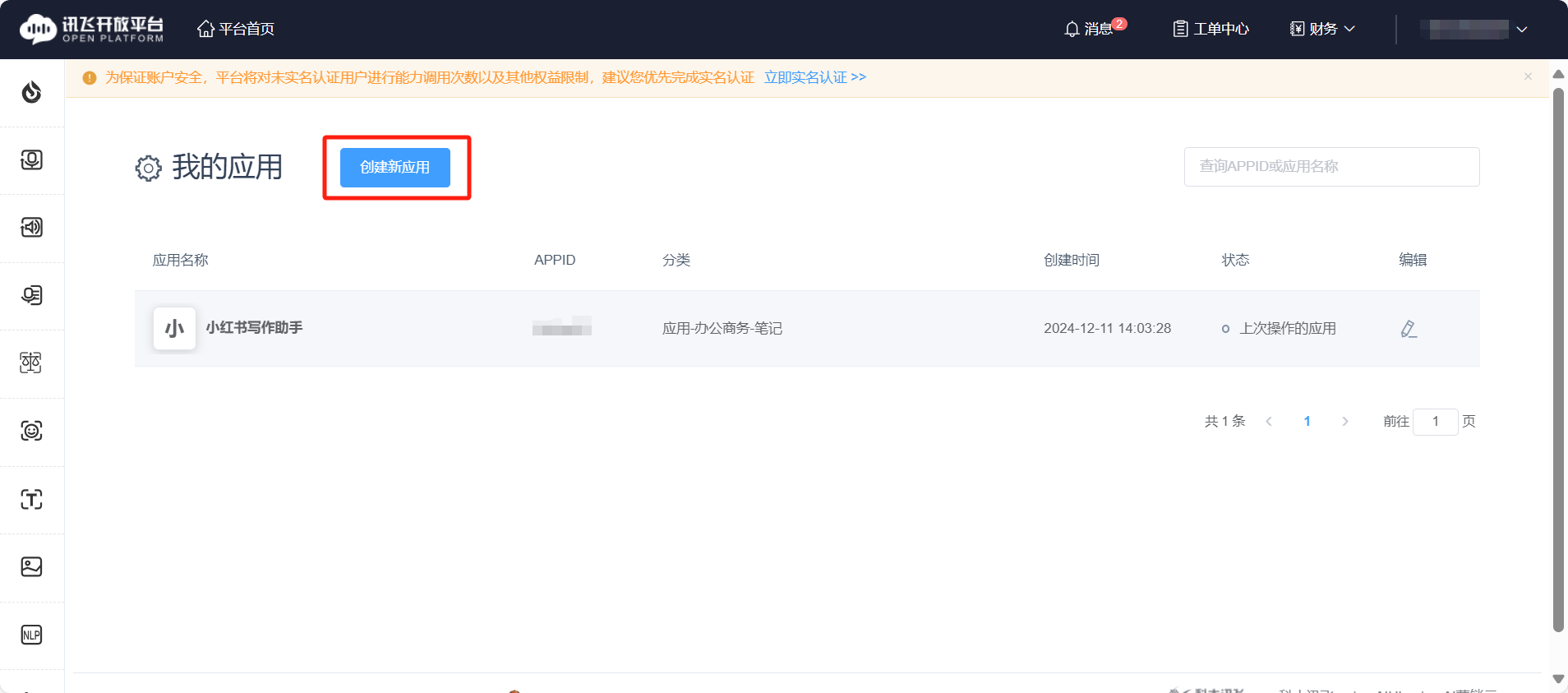
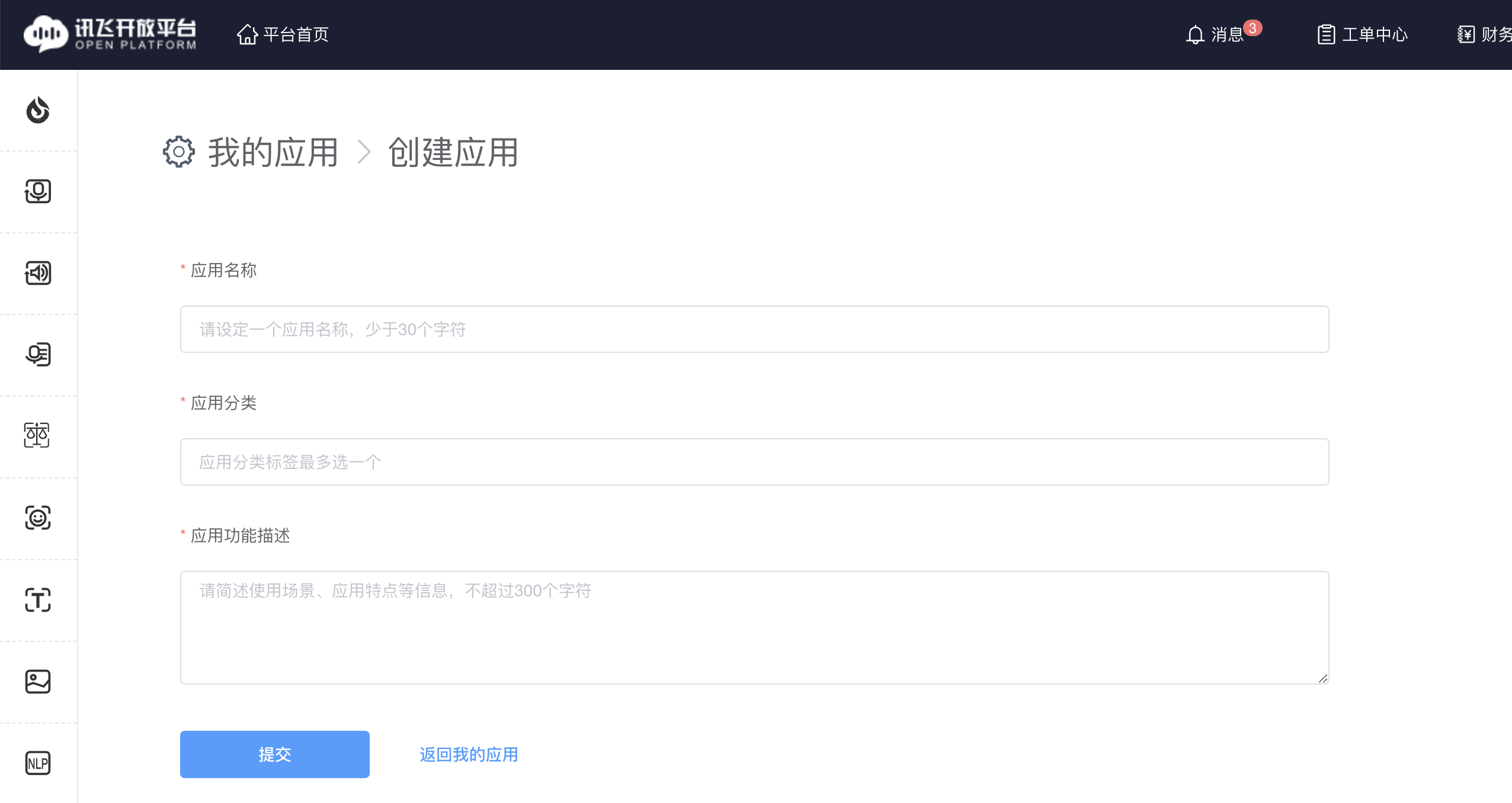
- 填写信息
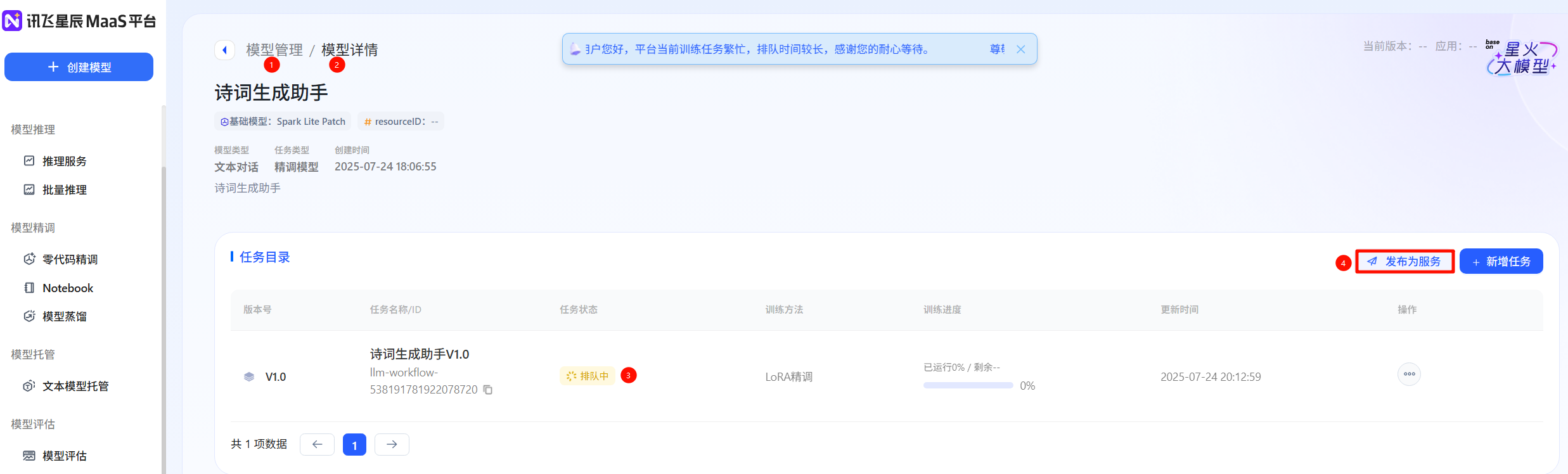
- 等待模型运行成功,发布服务
- 体验或继续优化
在线体验
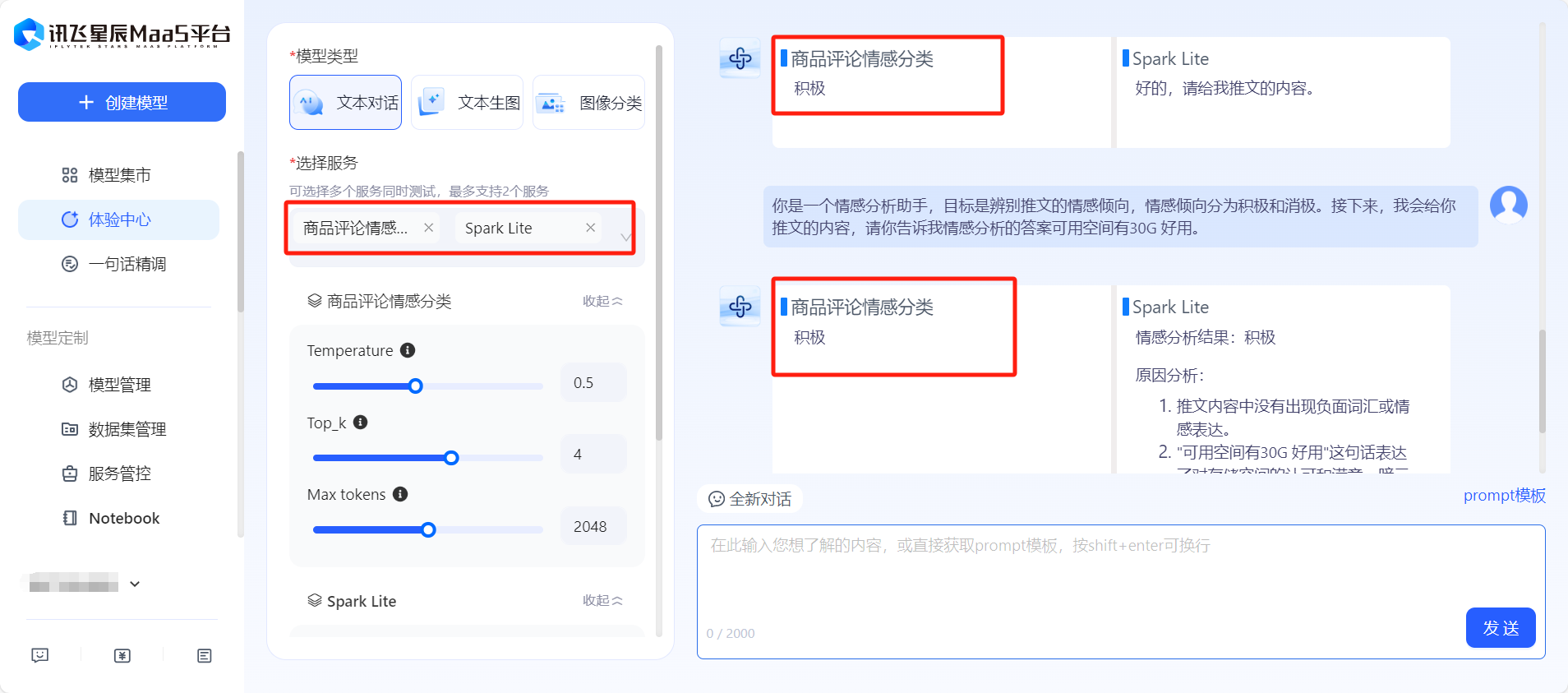
- 在【体验中心】页面的【我的服务】,可以看到已经微调出一个商品情感分类模型。
批量处理
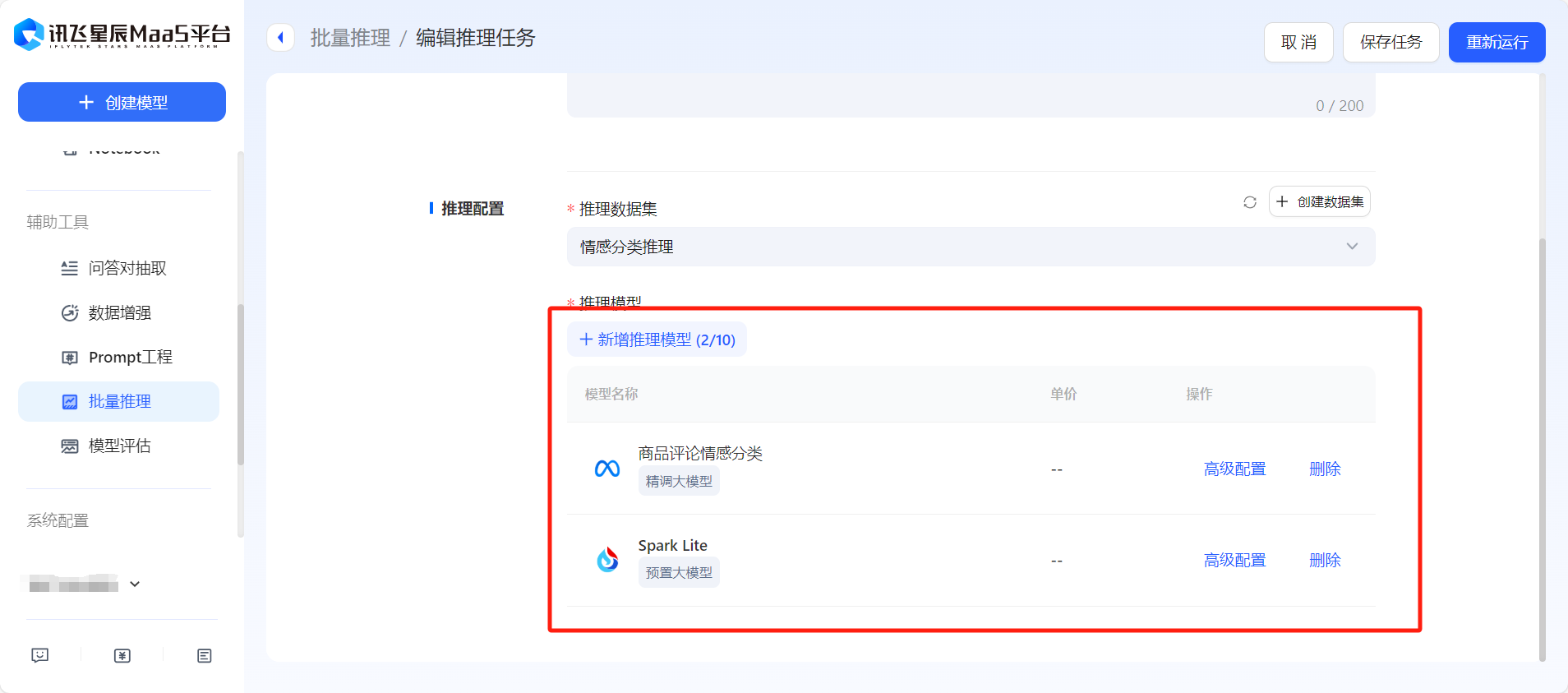
- 在【批量推理】板块,创建或发起模型批量推理,选择推理数据集,可支持多个模型同时推理。
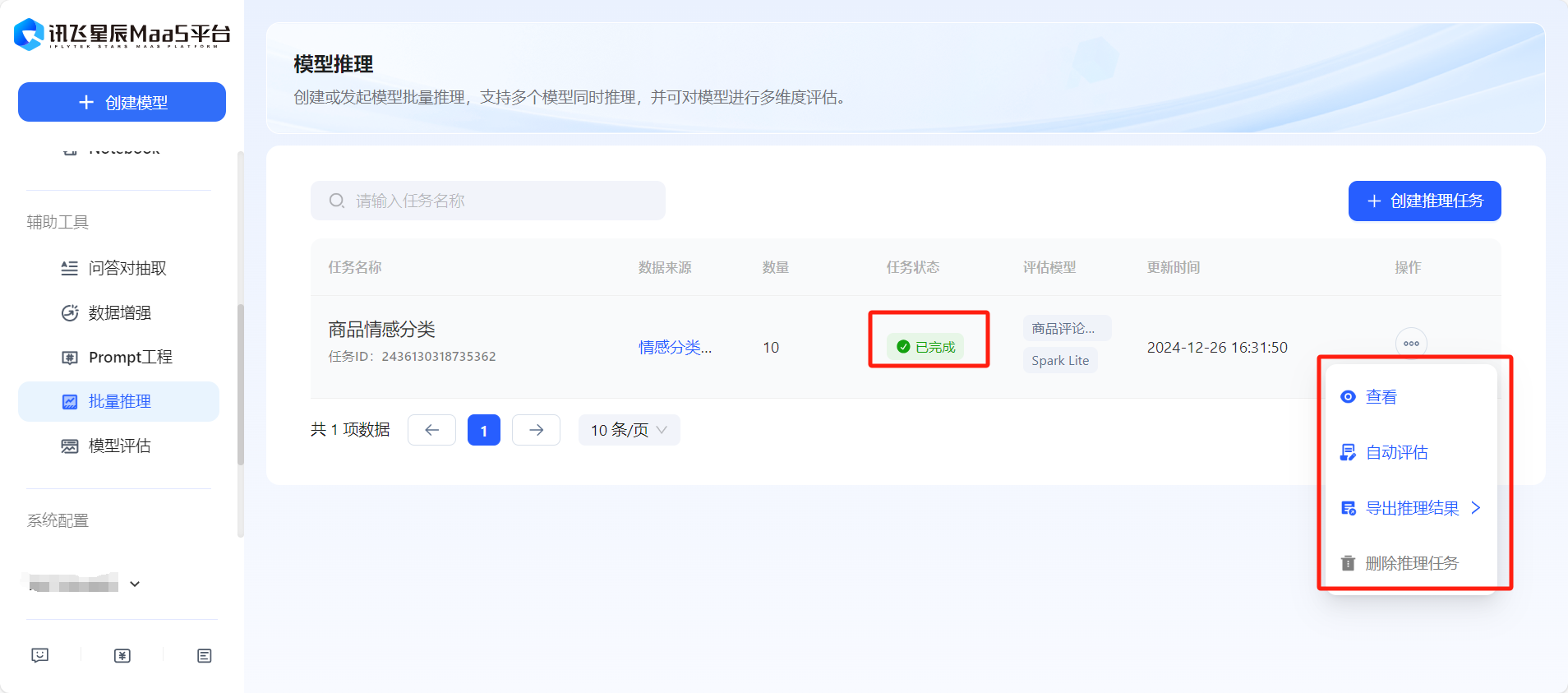
- 在任务状态变为已完成后,可以选择查看评估报告或导出评估结果已得到微调前后效果对比。
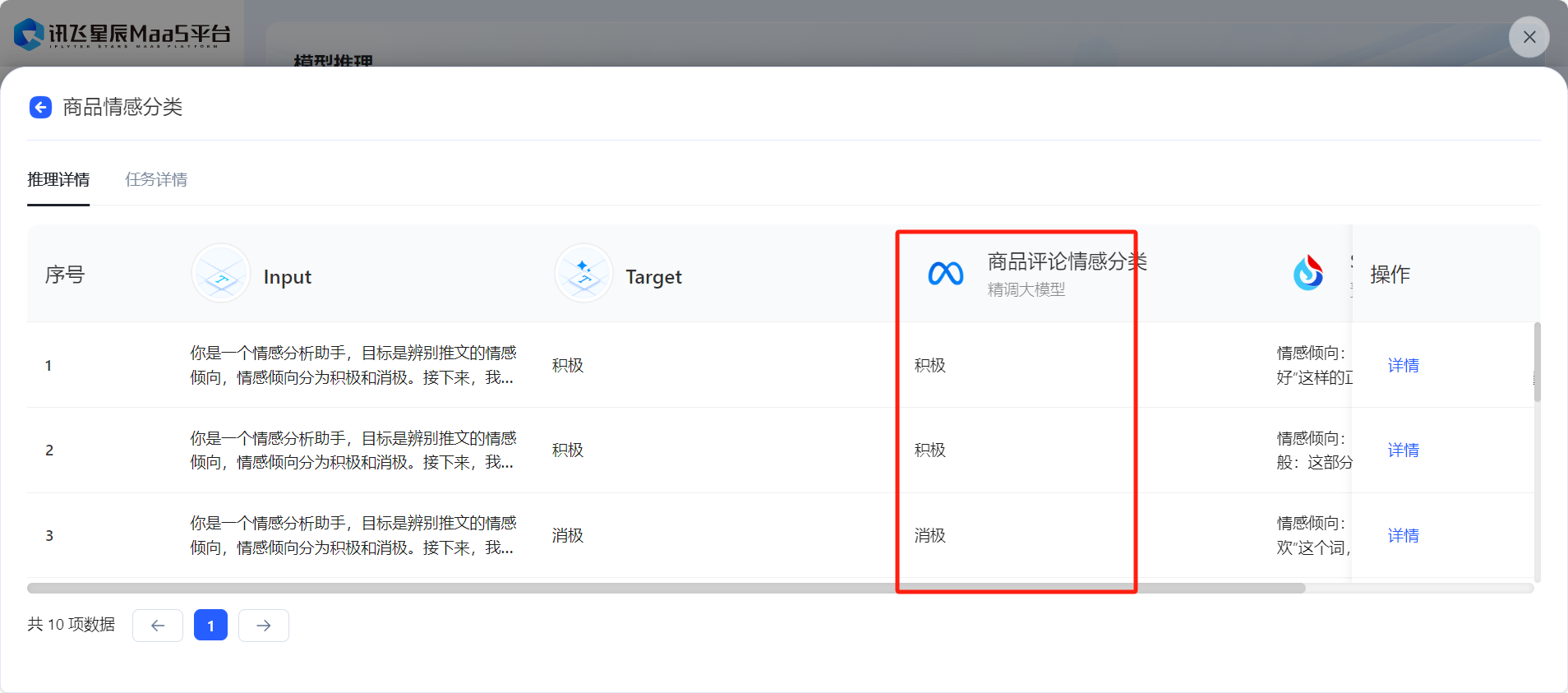
模型评估
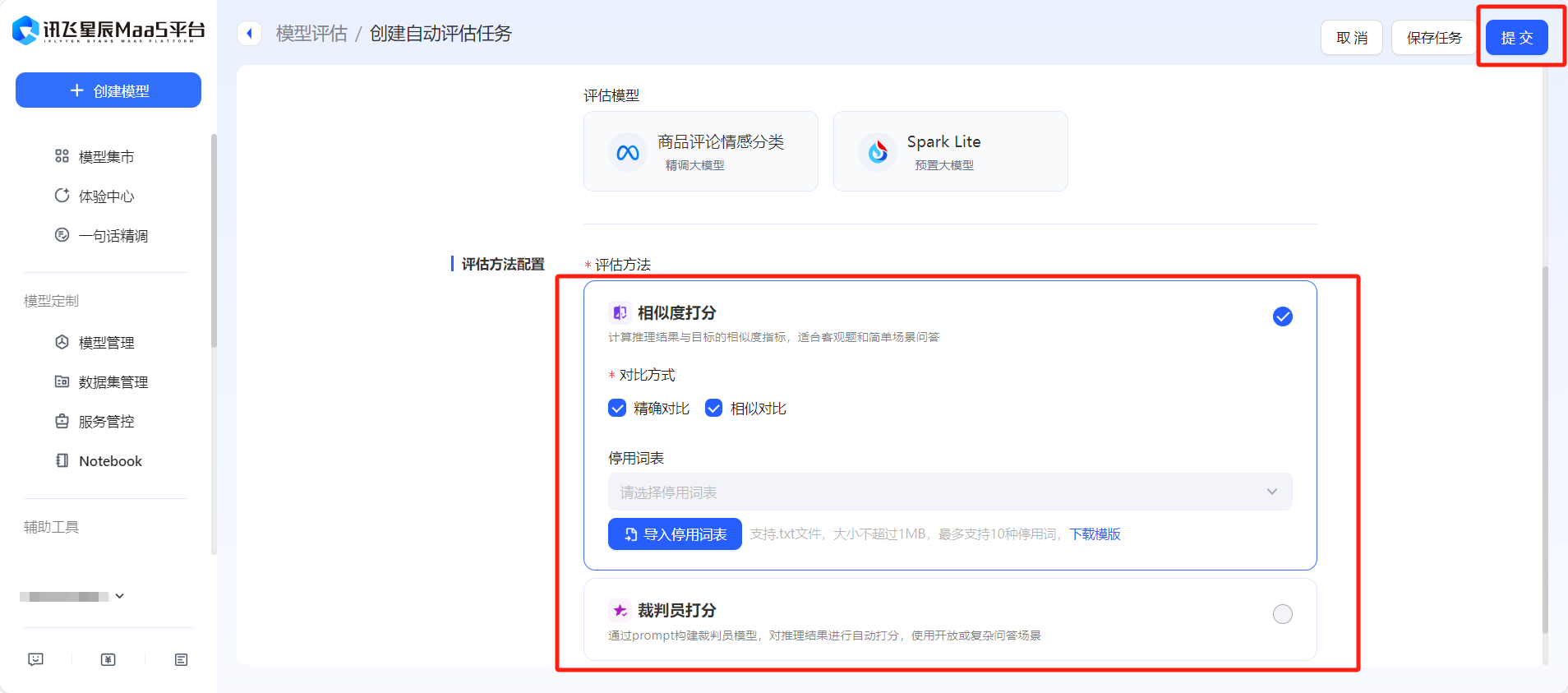
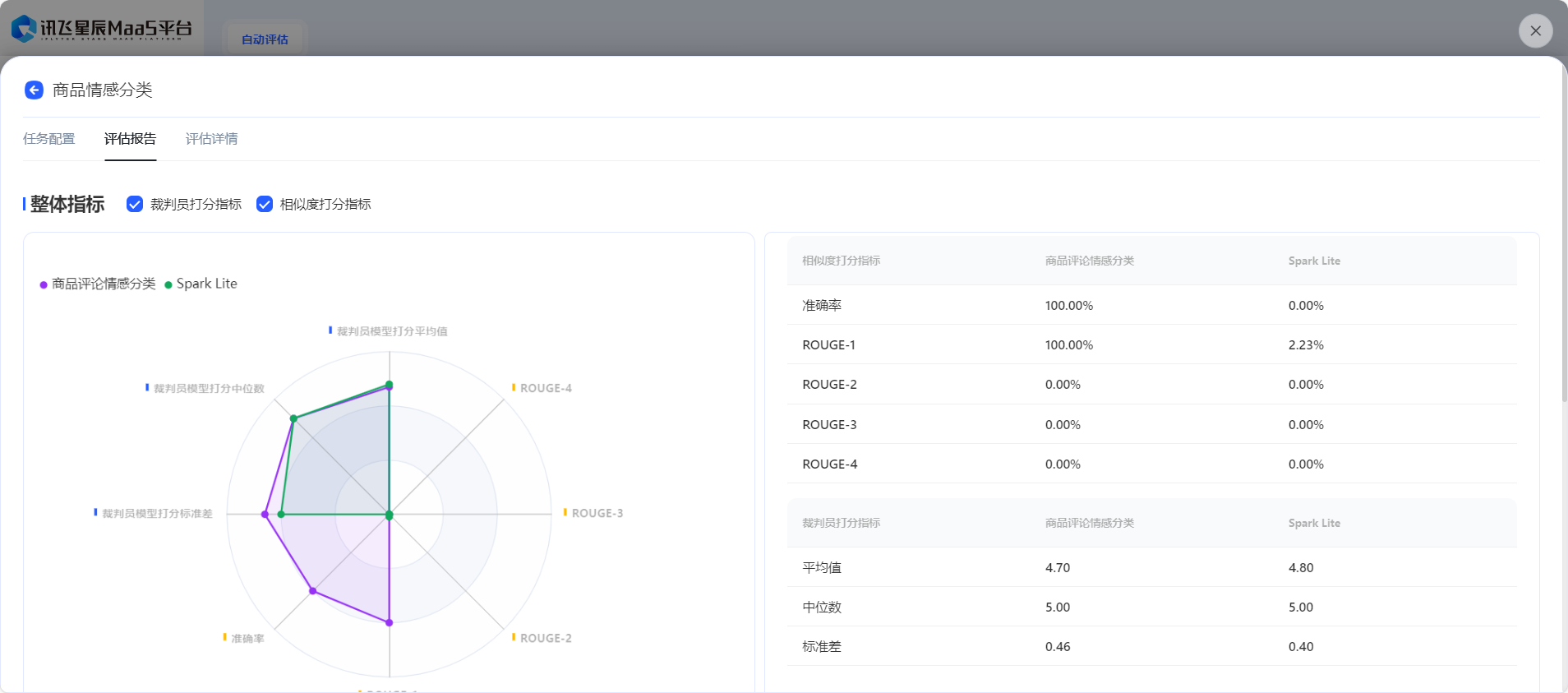
- 在【模型评估】板块,可以基于批量推理结果对模型的输出效果进行全方位评价,提供相似度打分和裁判员打分两种方式,可以根据任务类型进行选择。
诗词生成实践

商品分类任务数据集校验失败问题解决
- 优秀实践分享-学习者手册版
- 原数据集标签(校验失败)
{"prompt": "你是一个专业的商品分类助手,需要依据给定的30种商品分类标准,对输入的商品名称进行精准分类。这30种分类分别为:家居、家电、健康、服饰内衣、玩具、鞋靴箱包、香烟、粮油速食、酒饮冲调、美妆、清洁、餐饮、母婴、个护、蔬菜、休闲食品、办公、水产、肉禽蛋、宠物、乳品、礼品、3C数码、健康食品、汽车用品、水果、钟表配饰、鲜花绿植、运动。当接收到商品名称后,请仔细分析商品的功能、用途、材质以及所属行业等特征,将其归入最合适的分类中。在分类过程中,如果遇到难以判断的商品名称,可结合常见的生活常识、市场主流分类方式以及你所学习到的知识进行综合考量。现在,请对以下商品名称进行分类,直接输出类型标签,不需要解释:",
"label": "家居",
"text": "樱之歌蓝色之恋5件套日式釉下彩纯手绘家用餐具套装陶瓷器碗盘碗碟微波炉可用"}
- 新数据集标签(符合要求)
{"instruction": "你是一个专业的商品分类助手,需要依据给定的30种商品分类标准,对输入的商品名称进行精准分类。这30种分类分别为:家居、家电、健康、服饰内衣、玩具、鞋靴箱包、香烟、粮油速食、酒饮冲调、美妆、清洁、餐饮、母婴、个护、蔬菜、休闲食品、办公、水产、肉禽蛋、宠物、乳品、礼品、3C数码、健康食品、汽车用品、水果、钟表配饰、鲜花绿植、运动。当接收到商品名称后,请仔细分析商品的功能、用途、材质以及所属行业等特征,将其归入最合适的分类中。在分类过程中,如果遇到难以判断的商品名称,可结合常见的生活常识、市场主流分类方式以及你所学习到的知识进行综合考量。现在,请对以下商品名称进行分类,直接输出类型标签,不需要解释:",
"output": "家居",
"input": "樱之歌蓝色之恋5件套日式釉下彩纯手绘家用餐具套装陶瓷器碗盘碗碟微波炉可用"}
- 解决方法,使用文档编辑器或其他工具将json格式的标签进行替换。
prompt->instruction
label->output
text->input
- 经验证,可以正常上传使用。
![[CSS]让overflow不用按shift可以滚轮水平滚动(纯CSS)](http://pic.xiahunao.cn/[CSS]让overflow不用按shift可以滚轮水平滚动(纯CSS))


)
)

)


![[java 常用类API] 新手小白的编程字典](http://pic.xiahunao.cn/[java 常用类API] 新手小白的编程字典)









