
一、什么是 RTSP协议
1.1 RTSP 协议简介
RTSP,全称实时流传输协议(Real Time Streaming Protocol),是一种位于应用层的网络协议。它主要用于在流媒体系统中控制实时数据(如音频、视频等)的传输,并不直接负责媒体数据的传输,而是像一个 “遥控器”,通过发送一系列指令(如播放、暂停、快进、后退等)来对媒体流的传输过程进行管理和控制。
1.2 RTSP传输基本原理
我们所说的RTSP传输并不是只依靠RTSP协议,还要依赖RTP、RTCP、SDP协议共同实现媒体数据流的传输和控制。
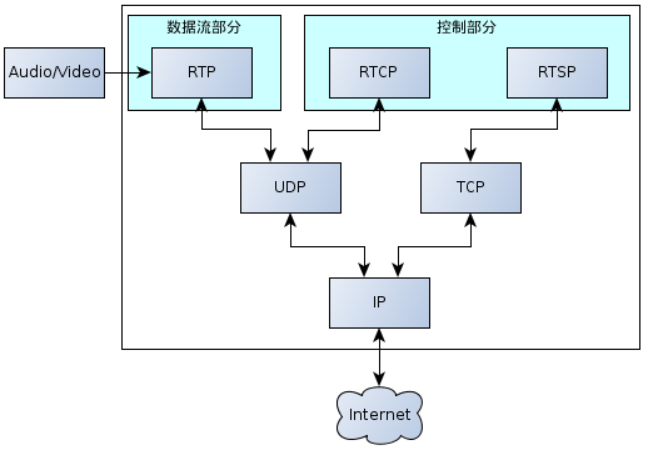
1.2.1 RTSP
- 作用:RTSP 主要负责对实时媒体流的传输进行控制,协调客户端和服务器之间的交互。它可以建立和终止媒体会话,以及对媒体流的播放状态进行控制。
- 传输方式:RTSP 本身通常使用 TCP 进行传输。这是因为 RTSP 的控制指令需要可靠的传输,确保指令能够准确无误地到达对方,避免因指令丢失或错误而导致的控制混乱。
1.2.2 RTP
- 作用:RTP(Real-time Transport Protocol,实时传输协议)主要负责实时媒体数据(如音频、视频)的实际传输,RTP包是音视频数据的载体。它能够为实时数据提供时间戳、序列号等信息,帮助接收端正确地重组和播放媒体数据。
- 传输方式:RTP 通常基于 UDP 进行传输。由于 UDP 具有传输速度快、延迟低的特点,能够很好地满足实时媒体数据对实时性的要求。虽然 UDP 不保证数据传输的可靠性,可能会出现数据包丢失的情况,但对于音频、视频等实时数据来说,少量的数据包丢失对播放效果的影响相对较小,而实时性更为重要。
1.2.3 RTCP
- 作用:RTCP(Real-time Transport Control Protocol,实时传输控制协议)与 RTP 配合使用,主要用于监控 RTP 数据传输的质量。它可以收集和反馈诸如数据包丢失率、延迟抖动、网络拥塞等信息,以便发送端和接收端根据这些信息调整传输策略,从而保证媒体流的传输质量。
- 传输方式:RTCP 一般也基于 UDP 进行传输,并且通常与 RTP 共享同一个端口对(RTCP使用对应的RTP端口号+1的端口,例如某一视频流RTP端口号31590,该视频流RTCP端口号31591),以便更好地与 RTP 协同工作,及时获取和反馈传输质量信息。
(注意!!! 音频和视频流的rtp与rtcp分开发送,假设一场直播中有一个音频流和一个视频流,那么音频RTP发送端口A,音频RTCP发送端口A+1,视频RTP发送端口B,视频RTCP发送端口B+1, A != B)
1.2.4 SDP
- 作用:SDP(Session Description Protocol,会话描述协议)用于描述媒体会话的相关信息,如媒体类型(音频、视频)、编码格式、传输地址、端口号等。它为通信双方提供了协商媒体会话参数的基础,让接收端能够了解如何正确接收和解析媒体数据。
- 传输方式:SDP 本身并不负责数据的传输,它通常作为其他协议( RTSP)消息的一部分进行传输。例如,在 RTSP 的会话建立过程中,服务器会通过 RTSP 消息将包含 SDP 信息的数据发送给客户端,客户端根据 SDP 信息来准备接收和播放媒体流。
1.3 TCP、UDP 传输区别
- 连接方式:TCP 是面向连接的协议,在数据传输之前需要通过三次握手建立连接,数据传输完成后需要通过四次挥手释放连接;而 UDP 是无连接的协议,通信双方在传输数据之前不需要建立连接,可以直接发送数据。
- 可靠性:TCP 具有可靠传输的特点,它通过序列号、确认应答、重传机制等确保数据能够准确、完整地到达接收端,并且数据传输的顺序与发送顺序一致;UDP 不提供可靠性保障,它不保证数据的到达,也不保证数据传输的顺序,可能会出现数据包丢失、重复或乱序的情况。
- 传输速度:由于 TCP 需要进行连接建立、确认应答、重传等操作,会增加额外的开销,因此传输速度相对较慢;UDP 不需要这些额外的操作,开销较小,传输速度更快,实时性更好。
- 适用场景:TCP 适用于对可靠性要求较高的场景,如文件传输、电子邮件、网页浏览等,这些场景中数据的准确性和完整性至关重要;UDP 适用于对实时性要求较高的场景,如音频、视频传输、实时游戏、视频会议等,这些场景中少量的数据丢失对整体效果影响不大,但对传输延迟有较高的要求。
下面对RTP,RTCP,RTSP,SDP分开详解
二、RTP 协议
2.1 RTP 报文头部
RTP 报文的核心设计目标是让实时媒体数据在网络中跑得又快又准。它的结构分为 固定头部(12 字节) 和 媒体数据负载,固定头部字段包括:
| 字段标识 | 位宽(bit) | 功能说明 |
|---|---|---|
| V(版本号) | 2 位 | RTP 的 “身份证”,目前通用版本是2(二进制10),确保大家用同一种规则通信。 |
| P(填充标志) | 1 位 | 特殊情况下加的 “填充物”,比如某些加密算法需要数据对齐时,末尾会补几个字节(但这些字节不算有效内容)。若 P=1,报文尾部会填充 1 个或多个额外字节。 |
| X(扩展标志) | 1 位 | 允许自定义 “插件” 字段,比如在直播中传递分辨率、帧率等额外信息。若 X=1,RTP 固定头部后会紧跟 自定义扩展报头(需协商格式,扩展元数据等)。 |
| CC(CSRC 计数器) | 4 位 | 指示后续 CSRC 标识符的数量(仅混音场景非零,最多 15 个)。 |
| M(标记位) | 1 位 | 语义由载荷类型定义: - 视频:标记一帧的结束(如关键帧边界); - 音频:标记一帧的开始(如会话切换点)。 |
| PT(有效载荷类型) | 7 位 | 定义载荷的媒体格式(视频/音频)。 - 比如 96=H.264视频,8=PCMA音频,这些编号不是固定的,需要在 SDP 协议中提前约定。 |
| 序列号 | 16 位 | 每发 1 个包序号 + 1(初始值随机): 接收端通过序号检测 丢包、乱序,并重建数据顺序。 |
| 时戳(Timestamp) | 32 位 | 标记载荷第一个字节的采样时刻: |
| SSRC(同步信源) | 32 位 | 区分不同数据流的 “名字”: |
除此之外还有贡献信源(CSRC)标识符(长度可变,所以不属于固定头部):每个CSRC标识符占32位,可以有0~15个。每个CSRC标识了包含在该RTP 报⽂有效载荷中的所有贡献信源。
对于Timestamp,SSRC和CSRC,这里详细解释一下:
时间戳(Timestamp):
想象你在录制一段视频:
- 每按下一次快门(采样),时间戳就增加一个固定值。比如 30fps 的视频,每帧增加
3000(90kHz 时钟下的单位),就像每过 33.3ms 给帧打个标记; - 接收端根据这些标记,就能知道帧该按什么顺序播放,以及如何与音频同步(比如说话的声音和嘴型同时出现)。
同步源(SSRC)
假设一场多人直播:
- 主播的摄像头(SSRC_A)和嘉宾的摄像头(SSRC_B)是两个独立的视频流;
- 即使它们通过同一个网络传输,接收端也能通过 SSRC_A 和 SSRC_B 把画面分开显示;
- SSRC 是随机生成的,如果两个设备不巧生成了相同的 SSRC,就像两个人进了同一间房,需要重新分配(冲突概率极低)。
贡献源(CSRC)
想象一个在线合唱比赛:
- 每个歌手的麦克风都是独立的 SSRC(SSRC1、SSRC2、SSRC3);
- 混音器把他们的声音合并成一个流(新的 SSRC_M),并在 CSRC 列表中记录原始的 SSRC1、SSRC2、SSRC3;
- 听众收到这个合并流时,通过查看CSRC就能知道每个声音来自谁。
RTP 之所以要设计这些头部字段就是为了:
- 序列号解决顺序问题(包是否丢失或乱序);
- 时间戳解决时间问题(媒体数据何时该播放);
- SSRC解决来源问题(数据是谁发的);
- CSRC解决混音问题(合并后的数据来自哪里)。
这种设计让 RTP 在 UDP 上实现了低延迟、高可控性的实时传输,即使网络不稳定,也能通过 RTCP 反馈(见下文)动态调整,确保音视频流畅。
2.2 RTP 报文有效载荷
2.2.1 H264裸码流封包解包
(一)H.264 码流的基本结构:NALU
H.264 视频流的核心单元是NALU(Network Abstraction Layer Unit),它像快递包裹一样包含视频数据和元信息。每个 NALU 由两部分组成(不考虑startcode):
- NALU 头(1 字节):
- F(1 位):错误标志,通常为 0(正常传输);
- NRI(2 位):重要性等级(00 = 可丢弃,11 = 最高优先级),比如 I 帧的 NRI 通常为 11;
- Type(5 位):标识 NALU 类型(如
5=IDR帧,7=SPS参数集)。
- NALU 负载:实际的视频数据(如 I 帧像素、P 帧残差等)。
关于NALU详细可以参考:万字长文详解 H.264 编码原理与 NALU 格式:走进视频压缩世界_h264-CSDN博客
关键问题:
- 一个 NALU 可能非常大(如 1080P 的 I 帧可达 200KB),而 UDP 包最大负载约 1500 字节(MTU限制),必须分片传输;
- 多个小 NALU(如 SPS、PPS、SEI)可以合并成一个 RTP 包,减少传输开销。
(二)RTP 封包策略
RTP 封装 H.264 的核心是将 NALU 适配到网络传输单元,主要有三种模式:
1. 单一 NALU 模式(Single NALU Packet)
- 适用场景:NALU 大小 ≤ 1400 字节(如 P 帧、B 帧、SPS/PPS)。
- 封包结构:
RTP头(12字节) + NALU头(1字节) + NALU负载- 示例:SPS(25 字节)直接封装为一个 RTP 包,RTP 头的PT
取H.264 负载类型。
- 示例:SPS(25 字节)直接封装为一个 RTP 包,RTP 头的PT
- 优势:简单高效,接收端无需重组;
- 局限:无法处理大 NALU(如 I 帧)。
2. 组合包模式(Aggregation Packet)
将多个小 NALU 合并到一个 RTP 包中,分为两种类型:
- STAP-A(单时间聚合包):
- 适用场景:同一时间生成的多个小 NALU(如 SPS+PPS+SEI)。
- 封包结构:
RTP头 + STAP-A头(1字节) + [NALU长度(2字节) + NALU头 + NALU负载] × N- STAP-A 头:
Type=24,保留 F 和 NRI 与第一个 NALU 一致。
- STAP-A 头:
- 示例:WebRTC 中常将 SPS 和 PPS 封装在一个 STAP-A 包中,减少首帧延迟(WebRTC实际数据流传输也是RTP包)。
- MTAP(多时间聚合包):
- 适用场景:不同时间生成的 NALU(如跨帧的 SEI)。
- 复杂点:需记录每个 NALU 的时间戳偏移(如 MTAP16 用 16 位存储偏移量)。
3. 分片模式(Fragmentation Unit)
将大 NALU 拆分为多个 RTP 包,核心是FU-A 分片单元:
- 适用场景:NALU > 1400 字节(如 1080P 的 I 帧)。
- 封包结构:
RTP头 + FU指示符(1字节) + FU头(1字节) + NALU分片负载- FU 指示符:
- 前 3 位保留 F 和 NRI,与原始 NALU 头一致;
Type=28(FU-A 类型)。
- FU 头:
- S(1 位):分片开始标志(仅第一个包为 1);
- E(1 位):分片结束标志(仅最后一个包为 1);
- R(1 位):保留位(0);
- Type(5 位):原始 NALU 的 Type(如
5=IDR帧)。
- FU 指示符:
- 分片示例:
- 一个 200KB 的 IDR 帧被拆分为 145 个 RTP 包,第一个包
S=1,E=0,最后一个包S=0,E=1。
- 一个 200KB 的 IDR 帧被拆分为 145 个 RTP 包,第一个包
这里对FU指示符和FU头展开解释一下:
FU指示符(FU indication)
+---------------+
|0|1|2|3|4|5|6|7|
+-+-+-+-+-+-+-+-+
|F|NRI| Type |
+---------------+这⾥⾯的的F和NRI就是NALU的Header中的F和NRI,即NALU头的前⾯三个bit位,后⾯的 TYPE就是NALU的FU-A类型28,这样在RTP固定头后⾯第⼀字节的后⾯5bit提取出来就确认了该 RTP包承载的不是⼀个完整的NALU,是其⼀部分。 那么问题来了,⼀个NALU切分成多个RTP包传输,那么到底从哪⼉开始哪⼉结束呢?可能有⼈说RTP包固定头不是有mark标记么,注意区分那个是以帧图像的结束标记,这⾥要确定是NALU结束的标记,其次NALU的类型呢?那么就需要RTP固定12字节后⾯的Fu Header来进⾏区分。
FU头(FU header)
+---------------+
|0|1|2|3|4|5|6|7|
+-+-+-+-+-+-+-+-+
|S|E|R| Type |
+---------------+字段解释:
S: 1 bit 当设置成1,开始位指示分⽚NAL单元的开始。当跟随的FU荷载不是分⽚NAL单元荷载的开 始,开始位设为0。
E: 1 bit 当设置成1, 结束位指示分⽚NAL单元的结束,即, 荷载的最后字节也是分⽚NAL单元的最后 ⼀个字节,当跟随的FU荷载不是分⽚NAL单元的最后分⽚,结束位设置为0。也就是说⼀个NALU切⽚时,第⼀个切⽚的SE是10,然后中间的切⽚是00,最后⼀个切⽚时11。
R: 1 bit 保留位必须设置为0,接收者必须忽略该位。
Type: 5 bits 此处的Type就是NALU头中的Type,取1-23的那个值,表示 NAL单元荷载类型定义。
总结一下:
当一个大 NALU(如 IDR 帧)被拆分为多个 RTP 包传输时,如何让接收端知道 “分片从哪开始、到哪结束,以及原 NALU 是什么类型” 成为核心问题。这里的关键是 RTP 负载中的「FU 指示符」和「FU 头」,而非 RTP 固定头的M标记 ——
1. 字段分工:谁来标记 NALU 的边界?
| 层级 | 字段 | 作用 | 误区提醒 |
|---|---|---|---|
| RTP 固定头 | M(标记位) | 标记一帧图像的边界(如整帧视频的结束),而非单个 NALU 的边界。 | 若一帧包含多个 NALU(如 I 帧含多个 Slice),M无法标记 NALU 的结束。 |
| RTP 负载头 | FU 指示符 | 第 1 字节,前 3 位继承原 NALU 的F(错误标志)和NRI(优先级),后 5 位置为28(标识这是FU-A 分片包)。 | 告诉接收端:“我不是完整 NALU,是分片的一部分。” |
| RTP 负载头 | FU 头 | 第 2 字节,用S(开始)、E(结束)、Type(原 NALU 类型)回答三个问题:- 这是该 NALU 的第几个分片?( S=1→开头,E=1→结尾)- 原 NALU 是什么类型?(如 Type=5→IDR 帧) | 承载 NALU 的 “身份信息” 和 “位置信息”。 |
2. 分片标记的工作流程
以一个 200KB 的 IDR 帧(原 NALU Type=5,NRI=11,F=0)为例:
-
拆分时:
- 将 NALU 拆分为
N个 RTP 包,每个包的负载结构为:[FU指示符] + [FU头] + [分片数据]; - FU 指示符:前 3 位是
0 11(F=0,NRI=11),后 5 位是11100(Type=28,标识 FU-A); - FU 头:
- 第一个分片:
S=1, E=0, Type=5(告诉接收端:“我是这个 IDR 帧的开头,原类型是 5”); - 中间分片:
S=0, E=0, Type=5(“我是中间部分”); - 最后一个分片:
S=0, E=1, Type=5(“我是结尾,拼完我就完整了”)。
- 第一个分片:
- 将 NALU 拆分为
-
重组时:
- 接收端先检查 RTP 负载的第一个字节(FU 指示符):若 Type=28,判定为分片包;
- 提取 FU 头的
S和E位,按序列号顺序收集分片:- 当
S=1时,创建新的 NALU 缓存,记录原 NALU 的F(0)和NRI(11); - 持续拼接分片数据,直到遇到
E=1的包; - 最后,用缓存的
F+NRI(0 11) + FU 头的Type(5),还原出完整的 NALU 头(0x65,即二进制0 11 0101),再拼接负载,得到原始 NALU。
- 当
3. 为什么不用 RTP 的M位标记 NALU 结束?
- 场景冲突:
M位是帧级标记(如 H.264 的一帧可能包含多个 NALU,比如 I 帧由 SPS、PPS、IDR Slice 等多个 NALU 组成)。若用M标记 NALU 结束,会导致一帧内的多个 NALU 被错误分割。 - 粒度不足:NALU 是 H.264 的基本单元,
M位的语义由 payload type 定义(不同编码可能不同),而 FU 头的S/E是专为 NALU 分片设计的精准标记,逻辑更内聚。
通过 FU 指示符和 FU 头的分工,RTP 完美解决了 “大 NALU 拆分后如何传递边界和类型信息” 的问题。这种设计让分片和重组过程既高效又精准,确保即使网络分片,接收端也能还原出完整的 NALU 供解码器处理。
2.2.2 AAC裸码流封包解包
(一)AAC码流存储格式:ADTS 帧
AAC 音频流的核心单元是ADTS(Audio Data Transport Stream)帧,它包含音频数据和元信息。每个 ADTS 帧由两部分组成:
- ADTS 头(7 字节):
- 同步字(12 位):固定为
0xFFF,用于快速定位帧起始位置,类似快递单号的唯一标识; - MPEG 版本(2 位):
0表示 MPEG-4,1表示 MPEG-2; - 保护位(1 位):
0表示无 CRC 校验,1表示有校验(实际中很少使用); - Profile(2 位):标识 AAC 类型(如
01=LC,11=HE-AAC); - 采样率索引(4 位):对应实际采样率(如
0x06=24kHz); - 声道配置(4 位):
0x02= 立体声,0x03=5.1 声道; - 帧长度(13 位):整个 ADTS 帧的字节数(包括头和负载),类似包裹总重量;
- 缓冲器状态(11 位):通常设为
0x7FF表示码率可变。
- 同步字(12 位):固定为
- ADTS 负载:实际的音频数据(如 PCM 采样的压缩结果)。
关于ADTS详细可以参考:
深入探索 AAC 编码原理与 ADTS 格式:音频世界的智慧结晶_aac编码原理-CSDN博客
关键问题:
- ADTS 头的冗余性:每个帧都包含相同的配置信息(如采样率),导致带宽浪费;
- 实时性要求:音频帧需快速传输,避免播放延迟。
(二)RTP 封装策略
RTP 封装 AAC 的核心是将 ADTS 帧适配到网络传输单元,主要有两种模式:
1. 单一 AU 模式(Single AU Packet)
- 适用场景:ADTS 帧较小(如 48kHz 立体声每帧约 1024 字节),且网络 MTU 足够大(如 1500 字节)。
- 封包结构:
RTP头(12字节) + AU头(2字节) + ADTS负载- AU 头:
- 高 13 位表示 ADTS 负载长度(不包括头,单位bit);
- 低 3 位保留(通常为 0)。
- 示例:一个 1024 字节的 ADTS 负载封装为 RTP 包,RTP 头的
PT为AAC 负载类型,Marker=1标识帧开始。
- AU 头:
- 优势:简单高效,接收端无需重组;
- 局限:若 ADTS 帧超过 MTU 需分片(但实际中 AAC 帧通常较小)。
2. 组合 AU 模式(Aggregation Packet)
将多个 ADTS 帧合并到一个 RTP 包中,减少包头开销:
- 适用场景:连续的小 ADTS 帧(如语音聊天中的短帧)。
- 封包结构:
RTP头 + AU头长度(2字节) + AU头(2字节)× N + padding bits + ADTS负载 × N- AU 头长度:头两个字节表示au-header的⻓度,单位是bit。 ⼀个AU-header⻓度是两个字节(16bit)因为可以有多个au-header所以AU-headers-length的值是 16的倍数,⼀般⾳频都是单个⾳频数据流的发送,所以AU-headers-length的值是16;
- AU 头:每个 ADTS 帧对应一个 AU 头,指示负载长度。
- 示例:4 个 256 字节的 ADTS 帧合并成一个 RTP 包,AU 头长度为
0x0010(16 字节),每个 AU 头指示 256 字节负载。
(三)封包解包流程
-
发送端处理流程:
- 步骤 1:解析 ADTS 头,提取采样率、声道数等参数;
- 步骤 2:
- 若 ADTS 帧 ≤ 1400 字节 → 单一 AU 模式;
- 若多个连续 ADTS 帧总大小 ≤ 1400 字节 → 组合 AU 模式;
- 步骤 3:填充 RTP 头字段:
- 序列号:每包递增 1,用于检测丢包;
- 时间戳:基于采样率计算(如 44.1kHz 时,每帧 1024 采样点的时间戳增量为
(1024 × 90000) / 44100 ≈ 2097); - SSRC:唯一标识音频流(如麦克风设备 ID)。
-
冗余控制:
- ADTS 头冗余优化:通过 SDP 传递配置信息(如采样率、声道数),RTP 包中仅保留必要字段;
- 负载类型选择:
PT=97对应mpeg4-generic,PT=101对应AMR-WB,需在 SDP 中声明。
(四)解包还原:从 RTP 包到 ADTS 帧的逆向工程
接收端的核心任务是将碎片化的 RTP 包还原为可解码的 ADTS 帧,流程如下:
1. RTP 头解析
- 序列号检查:
- 维护接收窗口(如最近 1024 个包),检测连续序列号缺失(丢包);
- 若丢包率超过阈值(如 3%),触发 FEC(前向纠错)或 RTX 重传。
- 时间戳同步:
- 基于时间戳计算播放延迟(如当前时间戳与参考时间戳的差值);
- 若延迟超过缓冲区容量(如 50ms),丢弃旧包以避免卡顿。
2. 组合包拆分与错误处理
- AU 头解析:
- 读取 RTP 负载的前 2 字节,获取 AU 头长度;
- 根据 AU 头长度遍历每个 AU 头,提取 ADTS 负载长度;
- 按顺序拼接 ADTS 负载,恢复完整的 ADTS 帧。
- 错误处理:
- 若 AU 头长度无效(如非 16 的倍数),丢弃整个 RTP 包;
- 若 ADTS 负载长度与实际数据不符,触发错误隐藏(如静音或重复前一帧)。
3. ADTS 头重建
- 配置信息复用:
- 若 SDP 已传递采样率、声道数等参数,重建 ADTS 头时复用这些信息;
- 仅保留同步字、帧长度等必要字段,减少冗余。
总结一下:
RTP 封装 AAC 的本质是将音频数据适配到网络传输的最小单元,通过两种模式的灵活组合解决了以下问题:
- 高效传输:组合包模式减少包头冗余,提升带宽利用率;
- 实时性保障:时间戳和序列号共同构建了音频帧的同步和顺序控制机制;
- 兼容性扩展:SDP 协商和负载类型声明确保跨设备互通。
通过这种设计,AAC 音频流得以在 UDP 上实现低延迟、高容错的实时传输,支撑了语音通话、在线音乐等核心场景。
三、RTCP协议
RTCP(Real-time Transport Control Protocol,实时传输控制协议)是 RTP 的 “孪生兄弟”——RTP 负责 “送货”(传输媒体数据),RTCP 则负责 “监控物流”(反馈质量、同步时钟、管理会话)。RTCP与RTP联合⼯作,RTP实施实际数据的传输,RTCP则负责将控制包送⾄参与中的每个⼈。其主要功能是就RTP正在提供的服务质量做出反馈。
要注意的是,RTCP 不直接描述单个 RTP 包,它描述的是整个发送方或接收方的状态以及一段时间内的统计信息。关联性通过 SSRC 和 时间窗口 来实现。

| 字段名 | 长度(bit) | 通俗解释 |
|---|---|---|
| Version(V) | 2 | RTP 协议的版本号,目前通用版本是 2(双方必须用同一版本才能正常通信)。 |
| Padding(P) | 1 | 若 P=1,报文末尾会额外塞几个字节,用来适配加密算法或底层传输的固定长度要求。 |
| Item count(IC) | 5 | 记录分组里有多少个小条目(比如谁在说话、网络质量报告),最多存 31 个;如果用不到条目,IC 可以设 0 或被 “借去干别的”。 |
| Packet type(PT) | 8 | 标记这是啥类型的 RTCP 分组,比如: - 200= 发送方汇报数据(SR)- 201= 接收方反馈质量(RR)- 还有身份信息(SDES)、退出通知(BYE)、自定义消息(APP)。 |
| Length(M) | 16 | 分组总长度,每 1 个单位等于 4 字节(比如 Length=1 → 代表 4 字节);这个长度不含前面固定的 4 字节头部。(也就是说length为0也是合理的,说明只有4字节的头部(这种情况IC也是0))。 |
(一)RTCP 的核心功能
RTCP 的设计目标是为 RTP 传输提供 “双向沟通机制”,核心功能可概括为四类:
- 质量反馈:接收端通过 RTCP 向发送端报告丢包率、延迟抖动等数据,发送端据此调整码率或重传策略(比如视频会议中卡顿后自动降低清晰度)。
- 时钟同步:通过 NTP(网络时间协议)时间戳将不同媒体流(如音频、视频)对齐到同一时间轴,解决 “唇音不同步” 问题。
- 会话管理:标识参与者身份(如用户名、设备 ID),并处理加入 / 离开会话的通知(比如直播中观众退出时发送信号)。
- 扩展能力:支持自定义消息(如传输额外的元数据),为特殊场景(如 VR 直播的姿态数据)预留扩展空间。
传输特性:RTCP 与 RTP 共用 UDP 端口对,RTCP 端口固定为 “RTP 端口 + 1”(如 RTP 用 5004,则 RTCP 用 5005)。
(二) RTCP 报文类型
RTCP 通过 5 种报文类型实现上述功能,每种报文都有统一的头部格式和专属的 payload 结构:
| 报文类型 | 缩写 | PT 值 | 核心作用 | 发送方 |
|---|---|---|---|---|
| 发送方报告 | SR | 200 | 发送端汇报发送统计(如总发包数、时钟信息) | 媒体发送者(如摄像头、麦克风) |
| 接收方报告 | RR | 201 | 接收端反馈接收质量(如丢包率、抖动) | 媒体接收者(如播放器、浏览器) |
| 源描述报告 | SDES | 202 | 传递参与者信息(如用户名、邮箱) | 所有会话参与者 |
| 离开通知 | BYE | 203 | 告知其他参与者自己退出会话 | 即将离开的参与者 |
| 应用自定义 | APP | 204 | 传输自定义数据(如私有协议扩展) | 按需由应用发送 |
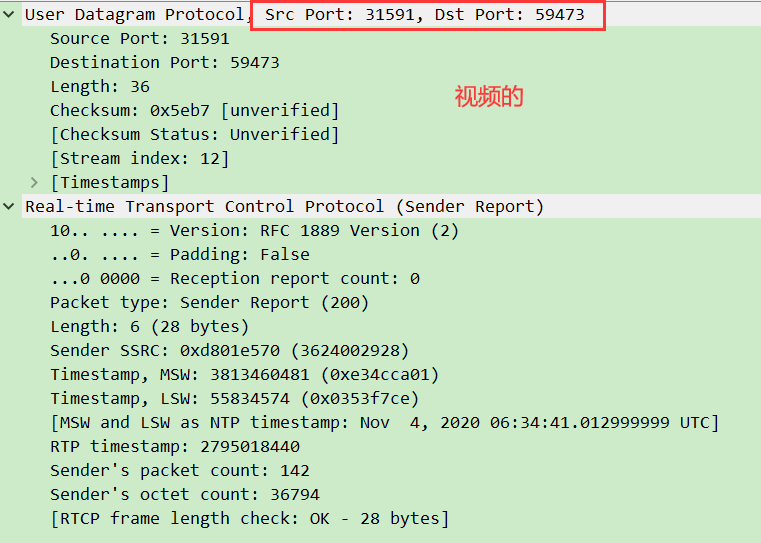
1. 发送方报告(SR)
SR 由媒体发送端(如摄像头)定期发送,包含自身的发送统计和时钟信息,是同步音视频的关键。
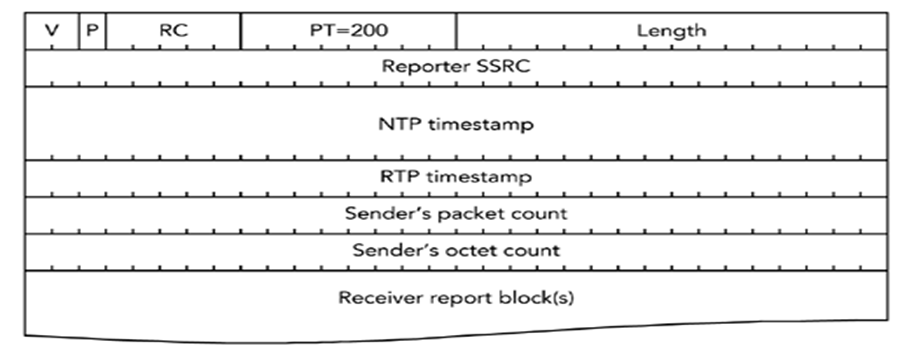
结构解析(共 28 字节起):
- 固定头部:版本(V=2)、填充位(P)、报告数(RC,最多 31 个);
- 核心字段:
- NTP 时间戳(64 位⽆符号整数):当前(报告发出)的绝对时间(如
2024-05-20 12:00:00.123),用于跨设备同步(该时间戳的⾼32 bites以NTP格式表示,从1900年1⽉1⽇开始计数,以秒为单位。低32 bites表示秒后⾯的⼩数。如果需要转化Unix时间到NTP时间,在Unix时间加上2,208,988,800即可。); - RTP 时间戳(32 位):与 RTP 包中时间戳同源(如视频 90kHz 时钟下的计数);
- 时间戳 (
NTP Timestamp,RTP Timestamp) 在 SR 中协同工作,提供媒体时钟与挂钟时间的映射关系。 - 发送统计:表示这个同步源从这个会话开始到现在总发包数、总字节数(用于计算码率)。
- NTP 时间戳(64 位⽆符号整数):当前(报告发出)的绝对时间(如
实例:某摄像头的 SR 显示 “NTP 时间 = 1629408000.123,RTP 时间 = 12345678,总发包数 = 1000”,接收端可据此计算 “1 个 RTP 时间单位≈多少毫秒”,实现时钟对齐。
2. 接收方报告(RR)
RR 由媒体接收端(如播放器)发送,反馈 RTP 包的接收质量,帮助发送端调整策略。
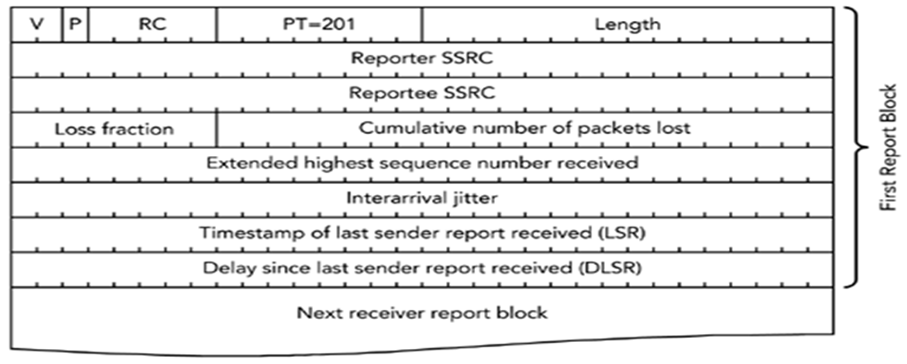
结构解析(共 24 字节起):
- 固定头部:与 SR 相同,RC 表示反馈的发送源数量;
- 报告块(每个 32 字节):
- 丢包率(8 位):0~255 表示 0~100%(如 64=25% 丢包);
- 累计丢包数(24 位):从会话开始至今丢失的总包数;
- 抖动(32 位):网络延迟波动的统计值(值越大,画面越可能卡顿);
- 最后接收的 SR 时间(LSR):用于计算往返延迟。
实例:播放器发送 RR,丢包率 = 128(50%),抖动 = 100ms,发送端收到后可能降低码率或启用 FEC(前向纠错)。
3. 源描述报告(SDES)
SDES 用于传递会话参与者的元信息,确保多方通信时能识别彼此。
必选字段:
- CNAME(规范名):唯一且永久的标识(如
user123@domain.com),即使设备重启(SSRC 变化)也能关联到同一用户; - 可选字段:NAME(昵称)、EMAIL(邮箱)、PHONE(电话)等。
实例:视频会议中,SDES 报文携带 “CNAME=alice@company.com,NAME=Alice”,其他参与者能在界面显示 “Alice 正在发言”。
4. 离开通知(BYE)
当设备退出会话(如关闭播放器、断网),BYE 报文会通知其他参与者 “我已离开”,避免资源浪费。
结构:包含退出的 SSRC 列表,可选 “离开原因”(如 “用户主动退出”)。
注意:BYE 可能丢失(如网络中断),接收端需通过 “超时未收到 RTP/RTCP” 判断对方离线。
5. 应用自定义(APP)
APP 允许应用自定义消息格式,用于标准 RTCP 未覆盖的场景(如 VR 直播中的设备姿态同步)。
结构:4 字节 ASCII 标识(如 “VRTP”)+ 自定义数据,接收端不认识的 APP 报文会被忽略。
四、总结一下RTP和RTCP如何协同
(一)RTCP 如何“描述” RTP 数据?
-
SSRC(Synchronization Source Identifier) 是核心纽带:-
每个 RTP 流(通常来自一个源,如摄像头或麦克风)在 RTP 会话中被分配一个唯一的 32 位
SSRC标识符。 -
这个
SSRC值出现在每个属于该流的 RTP 包的头部。 -
关键的关联点: RTCP 数据包(特别是 Sender Report - SR 和 Receiver Report - RR)也包含这个
SSRC标识符。 -
因此,接收端收到一个 RTCP SR 包时,它看到包里的
SSRC = X,就知道这个报告描述的是所有SSRC = X的 RTP 包的发送方状态(在 SR 中)或者接收方对该流的接收状态(在 RR 中)。
-
-
时间窗口:
-
RTCP 报告(SR/RR)不是为单个 RTP 包生成的。它们周期性地发送(通常每 5 秒左右,或至少占会话带宽的 5%)。
-
SR 报告包含发送方在上一个报告间隔期间发送的所有 RTP 包的累积统计信息(发送的包总数、发送的字节总数)。
-
RR 报告包含接收方在上一个报告间隔期间接收到的来自特定
SSRC(在 RR 块中指定)的所有 RTP 包的累积统计信息(如丢包数、累计丢包数、最高接收序列号、抖动等)。
-
-
序列号 (
sequence number) 的作用:-
每个 RTP 包都有一个单调递增的 16 位序列号。
-
RTCP RR 报告中包含
extended highest sequence number received(接收到的最高序列号的扩展形式)和cumulative number of packets lost(累计丢包数)。 -
接收端通过比较预期应接收到的序列号范围(基于之前的最高序列号和包间隔)和实际接收到的序列号,可以计算出在报告间隔内的丢包情况。虽然报告是累积的,但结合序列号信息,接收端能知道在哪个大致的序列号范围内发生了丢包。
-
-
总结关联性: RTCP 通过共享
SSRC将报告与特定的 RTP 流关联起来。报告提供的是该流在前一个时间窗口内的整体发送或接收性能的统计摘要,而不是针对单个 RTP 包。接收端利用序列号信息可以推断出大致的丢包位置。
(二) RTCP 和 RTP 中的事件戳如何协同控制音视频同步?
建立媒体时间与真实时间的映射关系
音视频同步的本质是:让属于同一时刻采集的音频样本和视频帧,在播放端也于同一时刻播放出来。问题在于:
-
音频和视频是独立的 RTP 流:它们有各自独立的
SSRC、独立的 RTP 序列号、独立的 RTP 时间戳序列(基于各自的采样率)。 -
RTP 时间戳是相对的:音频时间戳基于音频采样率(如 48000 Hz,每样本时间戳增量为 1),视频时间戳基于视频时钟频率(如 90000 Hz,每帧时间戳增量取决于帧率)。两者单位不同,无法直接比较。
-
设备时钟不同步:发送端和接收端的系统时钟(挂钟时间)可能不同步,且各自存在漂移。
RTCP SR 包 (NTP Timestamp + RTP Timestamp) 解决了这个问题! 它为每个独立的媒体流提供了一个将自身媒体时间戳 (RTP Timestamp) 映射到绝对真实世界时间 (NTP Timestamp) 的基准点。
协同控制音视频同步的步骤:
假设有一个视频会议场景,包含一个音频流 (SSRC_A) 和一个视频流 (SSRC_V)。
-
发送端捕获与标记
-
当发送端决定为音频流
SSRC_A发送一个 SR 包时:-
原子性操作: 它瞬间同时完成以下动作:
-
捕获当前 NTP 时间 (
NTP_TS_A): 获取精确的挂钟时间(理想情况下与 NTP 服务器同步)。 -
捕获当前音频 RTP 时间戳 (
RTP_TS_A): 读取此刻音频采样时钟计数器的值。这个值代表了捕获设备在NTP_TS_A这个绝对时间点正在处理的音频样本的时间戳。
-
-
-
同样,当为视频流
SSRC_V发送 SR 包时:-
原子性操作: 瞬间同时捕获:
-
捕获当前 NTP 时间 (
NTP_TS_V)。 (注意:NTP_TS_A和NTP_TS_V可能不同,因为 SR 发送时间不同) -
捕获当前视频 RTP 时间戳 (
RTP_TS_V)。
-
-
-
-
发送端打包 SR:
-
对于音频 SR (
SSRC_A): 将NTP_TS_A和RTP_TS_A打包进 SR 包发送。 -
对于视频 SR (
SSRC_V): 将NTP_TS_V和RTP_TS_V打包进 SR 包发送。
-
-
接收端接收与计算映射关系
-
接收端收到音频流的 SR (
SSRC_A):-
记录
NTP_TS_A(发送端在发送此 SR 时的绝对时间)。 -
记录
RTP_TS_A(在NTP_TS_A时刻,音频流的媒体时间戳)。 -
建立音频流映射:
RTP_TS_A(音频时间) <==>NTP_TS_A(绝对时间)
-
-
接收端收到视频流的 SR (
SSRC_V):-
记录
NTP_TS_V。 -
记录
RTP_TS_V。 -
建立视频流映射:
RTP_TS_V(视频时间) <==>NTP_TS_V(绝对时间)
-
-
关键点: 接收端现在知道如何把音频时间戳转换成绝对时间,也知道如何把视频时间戳转换成绝对时间。绝对时间 (
NTP Timestamp) 成为了一个公共的、统一的时间轴!
-
-
接收端同步播放:
-
假设接收端要播放一个音频包:
-
该音频包有自己的 RTP 时间戳
audio_ts。 -
接收端利用音频流的映射关系 (
RTP_TS_A<==>NTP_TS_A),计算出audio_ts对应的绝对时间target_ntp_audio。计算原理:-
计算音频时间差:
delta_audio_ts = audio_ts - RTP_TS_A -
计算对应的绝对时间差 (基于音频采样率):
delta_ntp = delta_audio_ts / audio_sample_rate(例如audio_sample_rate = 48000) -
目标绝对时间:
target_ntp_audio = NTP_TS_A + delta_ntp
-
-
-
假设接收端要播放一个视频帧:
-
该视频帧有自己的 RTP 时间戳
video_ts。 -
接收端利用视频流的映射关系 (
RTP_TS_V<==>NTP_TS_V),计算出video_ts对应的绝对时间target_ntp_video。计算原理:-
计算视频时间差:
delta_video_ts = video_ts - RTP_TS_V -
计算对应的绝对时间差 (基于视频时钟频率):
delta_ntp = delta_video_ts / video_clock_rate(例如video_clock_rate = 90000) -
目标绝对时间:
target_ntp_video = NTP_TS_V + delta_ntp
-
-
-
同步决策:
-
播放器有一个统一的播放时间轴,基于接收端本地估算的 NTP 时间 (接收端本地时钟最好也同步到 NTP)。
-
播放器计算当前本地估算的 NTP 时间
current_ntp_local。 -
对于即将播放的音频样本和视频帧:
-
它计算音频样本的目标绝对时间
target_ntp_audio。 -
它计算视频帧的目标绝对时间
target_ntp_video。 -
播放准则: 当
current_ntp_local达到或略晚于target_ntp_audio时,播放该音频样本;当current_ntp_local达到或略晚于target_ntp_video时,播放该视频帧。
-
-
效果: 因为
target_ntp_audio和target_ntp_video都是根据发送端同一个物理时刻(分别由各自的 SR 捕获)映射出来的绝对时间,所以原本在发送端同一物理时刻采集的音频和视频,它们的target_ntp值会非常接近(理想情况下相等)。播放器在相同的current_ntp_local时间播放它们,就实现了音画同步!
-
-
想象两个跑步者(音频流和视频流)在不同的跑道上(不同的时间戳序列)。裁判(发送端)在特定时刻(NTP_TS_A/V)分别记录下他们各自跑了多远(RTP_TS_A/V)。在终点(接收端),另一个裁判根据这些记录,可以推算出两个跑步者在裁判记录的那个共同时刻各自的位置。这样,终点裁判就能知道,当第一个跑步者到达某个位置时(某个音频时间戳),第二个跑步者应该在哪里(对应的视频时间戳),从而判断他们是否“齐头并进”(音画同步)。
五、RTSP协议
(一)RTSP 是什么:不止于 “传输” 的控制协议
RTSP 是一种基于文本的应用层协议,语法类似 HTTP,但专为实时媒体控制设计。它的核心作用是:
- 协调会话:让客户端(如播放器)和服务器(如直播服务器)达成共识(如媒体格式、传输方式);
- 控制流传输:通过 “播放”“暂停”“录制” 等指令管理 RTP 流(音视频数据由 RTP 实际传输);
- 维护状态:全程跟踪会话进度(如当前播放位置、传输端口),类似打电话时保持通话状态。
一句话总结:RTSP 是 “指挥官”,RTP 是 “运输兵”,前者发号施令,后者运送数据。
(二)RTSP 与 HTTP:看似相似,实则不同
RTSP 常被比作 “HTTP 的亲戚”,但两者在核心机制上有本质区别:
| 对比维度 | RTSP | HTTP |
|---|---|---|
| 核心功能 | 控制媒体流(播放、录制等) | 传输静态资源(网页、文件等) |
| 状态管理 | 有状态(保持会话 Session) | 无状态(每次请求独立) |
| 请求方向 | 客户端和服务器可双向发送请求 | 仅客户端发送请求,服务器被动响应 |
| 数据传输 | 媒体数据通过 RTP “带外” 传输(独立通道) | 数据通过 HTTP 报文 “带内” 传输 |
| 特有方法 | 支持 PLAY、RECORD、SETUP 等指令 | 主要用 GET、POST、PUT 等 |
举例:用 RTSP 看直播时,你可以随时发送 “暂停” 指令,服务器会记住当前播放位置;而用 HTTP 下载视频,暂停后需重新请求,服务器不会保留你的进度。
(三)推流流程:如何把视频 “上传” 到服务器?
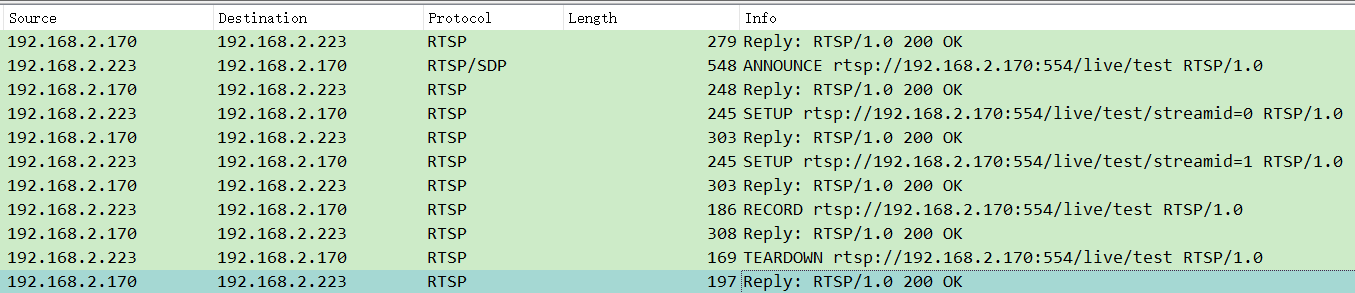
推流(如主播直播)是将本地音视频通过 RTSP 发送到服务器的过程,核心步骤分六步:
1. 第一步:OPTIONS——“问问服务器支持啥功能”
- 客户端→服务器:发送
OPTIONS请求,询问服务器支持哪些操作(如能否录制、能否暂停)。
- 服务器→客户端:回复
Public字段,列出支持的方法(如OPTIONS, DESCRIBE, RECORD等)。

- 作用:避免客户端发送服务器不支持的指令,浪费资源。
2. 第二步:ANNOUNCE——“告诉服务器我要发啥”
- 客户端→服务器:发送
ANNOUNCE请求,携带 SDP(会话描述协议)信息,说明要推的媒体格式(如视频用 H.264、音频用 AAC)、采样率等。
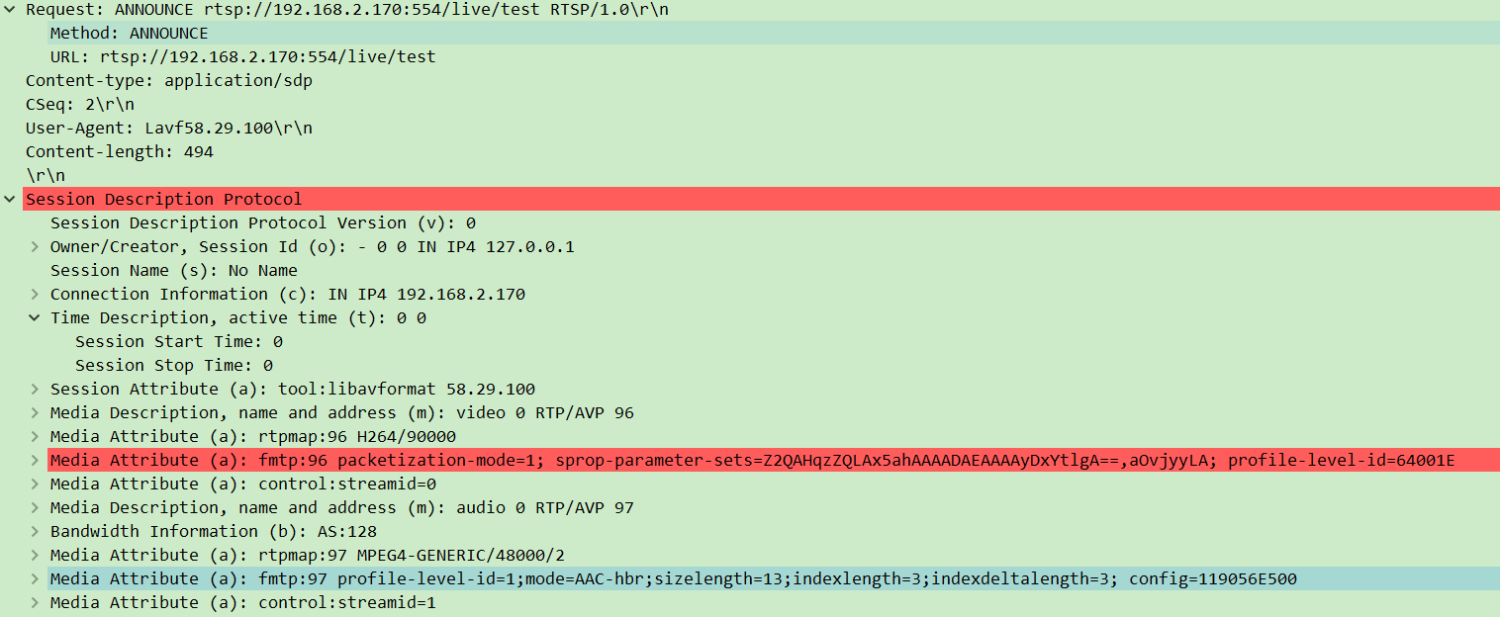
- 服务器→客户端:回复确认,并返回
Session ID(会话标识,后续操作需携带)。
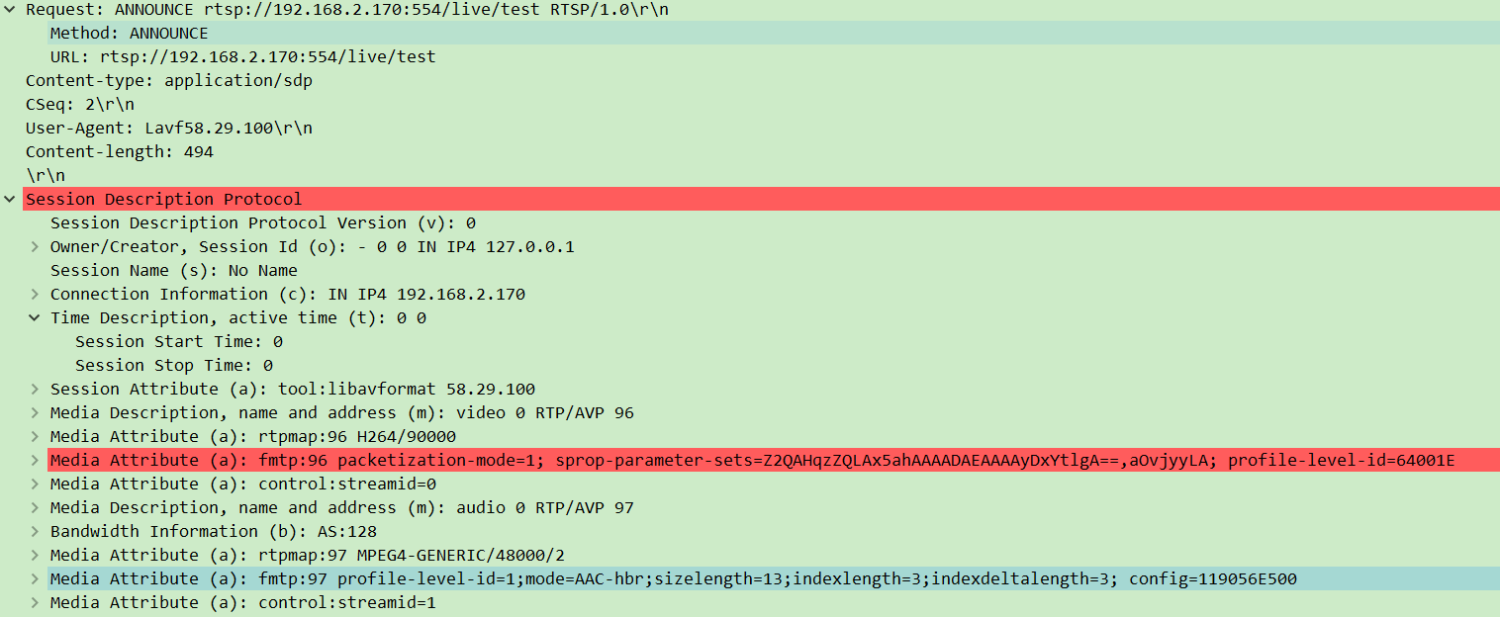
- 作用:让服务器提前准备好接收特定格式的媒体流。
3. 第三步:SETUP——“约定传输通道”
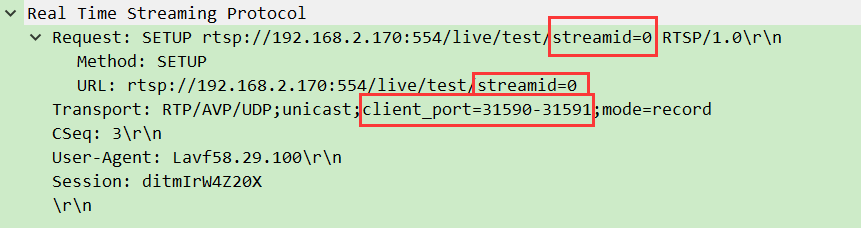
- 客户端→服务器:发送
SETUP请求,指定传输方式(如 UDP)和客户端端口(如 RTP 用 31590,RTCP 用 31591)。
- 服务器→客户端:回复确认,告知服务器端口(如 RTP 用 59472),并绑定
Session ID。
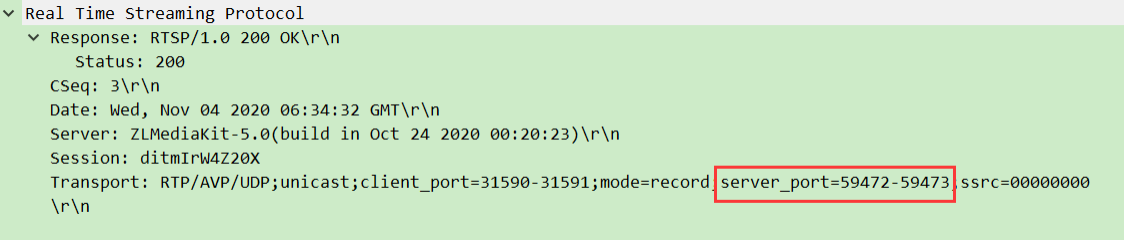
- 细节:如果推流包含视频和音频,需分别
SETUP(各自用独立端口)。 - 作用:打通客户端和服务器的 “数据高速公路”,确保 RTP 流能准确传输。
4. 第四步:RECORD——“推流开始”
- 客户端→服务器:发送
RECORD请求,指令服务器开始接收 RTP 流。
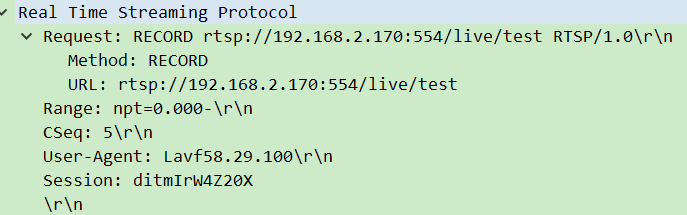
- 服务器→客户端:回复确认,开始等待 RTP 数据。

- 作用:正式启动推流,此时客户端会通过 RTP 端口发送音视频数据。
5. 第五步:RTP 传输 ——“数据真正开始流动”
- 客户端通过
SETUP约定的 UDP 端口,持续发送 RTP 包(视频用一个端口,音频用另一个)。
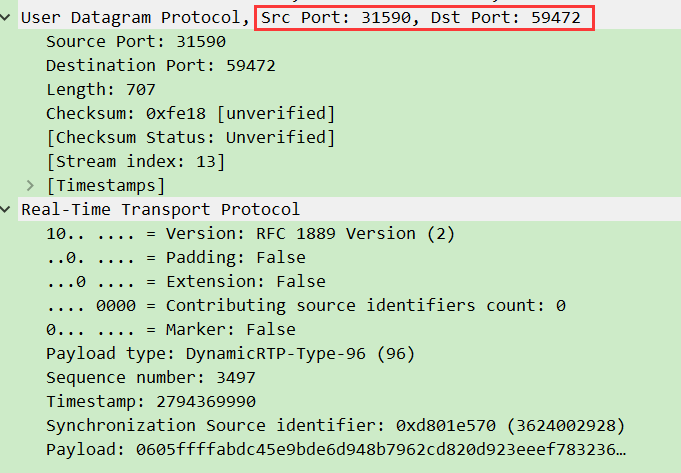
- 同时定时发送 RTCP 包反馈传输质量(如丢包率),服务器据此调整策略。
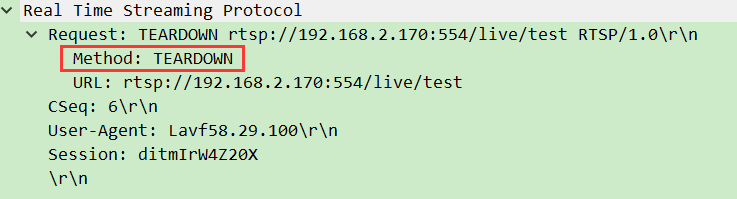
6. 第六步:TEARDOWN——“结束会话”
- 客户端→服务器:发送
TEARDOWN请求,告知 “推流结束”。
- 服务器→客户端:回复确认,释放端口和会话资源。
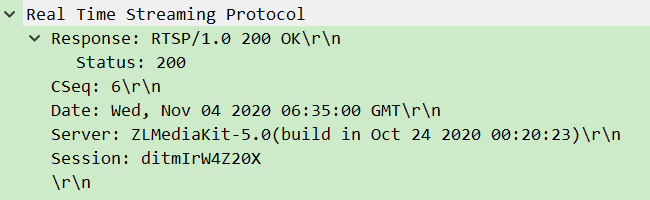
- 作用:优雅关闭连接,避免资源浪费。
总结:
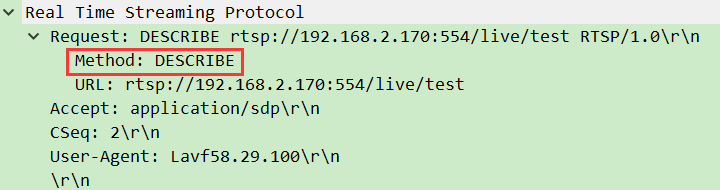
(四)拉流流程:如何从服务器 “拉取” 视频?
拉流(如观众看直播)是客户端从服务器获取媒体流的过程,步骤与推流类似,但部分关键指令不同:
| 步骤 | 拉流操作 | 与推流的核心区别 |
|---|---|---|
| 1. OPTIONS | 同推流(查询服务器支持的方法) | 无 |
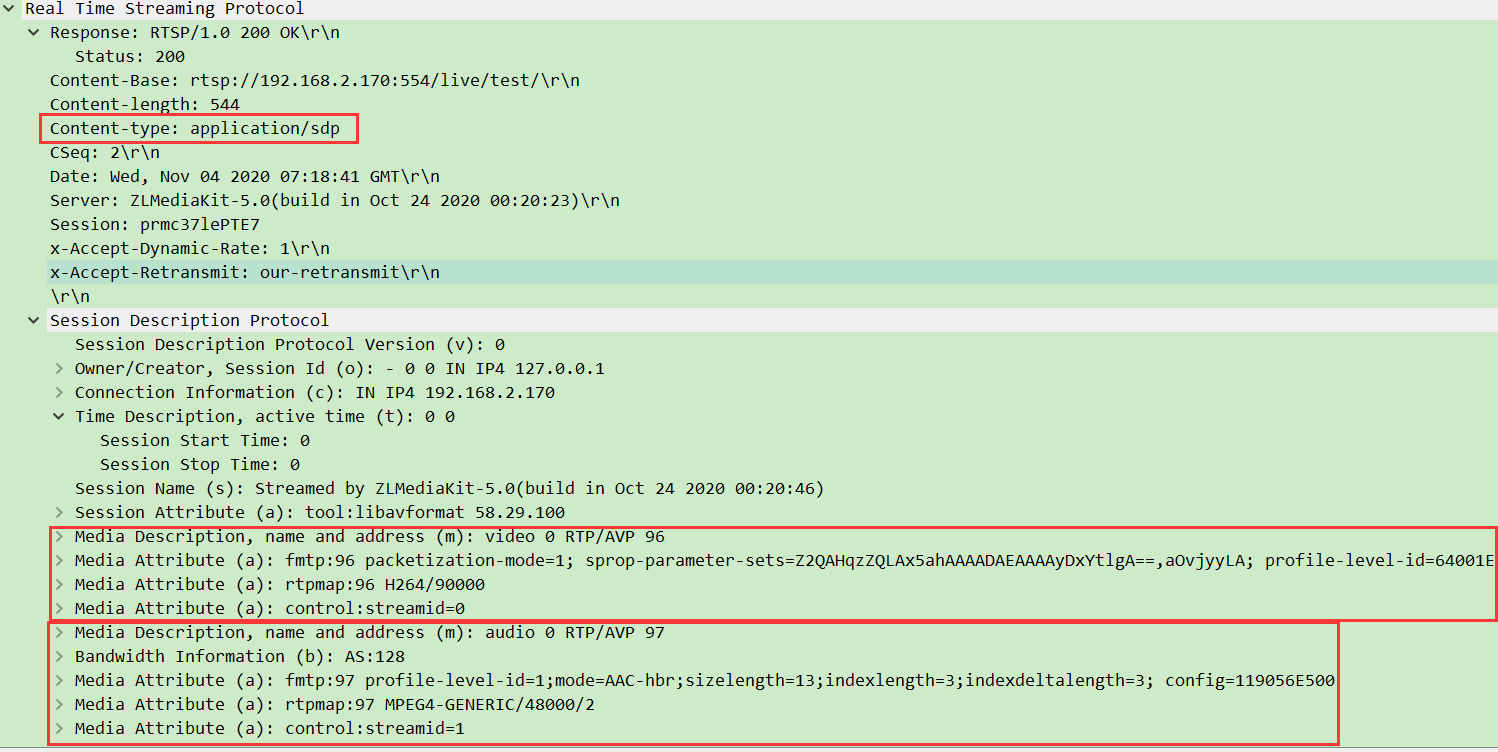
| 2. DESCRIBE | 客户端请求服务器发送 SDP(媒体描述) | 推流用 ANNOUNCE(客户端主动告知),拉流用 DESCRIBE(客户端主动查询) |
| 3. SETUP | 同推流(约定传输端口) | 无 |
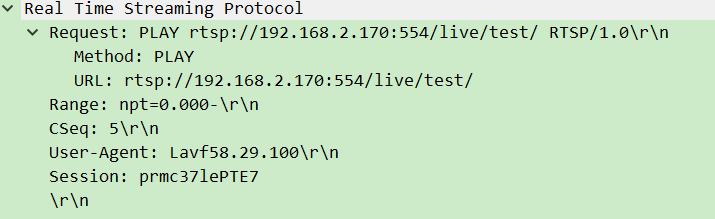
| 4. PLAY | 客户端指令服务器开始发送 RTP 流 | 推流用 RECORD(客户端发数据),拉流用 PLAY(服务器发数据) |
| 5. RTP 传输 | 服务器通过 RTP 发送音视频数据到客户端 | 数据方向相反(服务器→客户端) |
| 6. TEARDOWN | 同推流(关闭会话) | 无 |
举例:拉流时,DESCRIBE就像观众问 “你这有什么节目?”,服务器用 SDP 回复 “有 H.264 视频和 AAC 音频”;PLAY则像说 “开始播放吧”,服务器随后通过 RTP 发送数据。

(五)总结
1. Session ID:
- 由服务器在
ANNOUNCE或SETUP时生成(如ditmIrW4Z20X),后续所有操作必须携带。 - 作用:服务器通过它识别 “哪个客户端在操作哪个流”,避免混淆。
2. Transport 字段:
格式示例:Transport: RTP/AVP/UDP;unicast;client_port=31590-31591;server_port=59472-59473
RTP/AVP:用 RTP 传输,采用 AVP(音频视频配置文件);unicast:单播(一对一传输);client_port/server_port:客户端和服务器的 RTP/RTCP 端口对(RTP 用前一个,RTCP 用后一个)。- 作用:明确数据走哪条 “路”,用什么 “规则” 传输。
3. CSeq:
- 每个 RTSP 请求 / 响应都有一个递增的序列号(如
CSeq: 1、CSeq: 2)。 - 作用:匹配请求和响应(避免混乱),比如客户端发
CSeq:3的请求,服务器必须用CSeq:3回复。
4. SDP协议作用(key-value):
- 包含媒体类型(视频 / 音频)、编码格式(H.264/AAC)、采样率等关键信息。
- 推流时由客户端通过
ANNOUNCE发送,拉流时由服务器通过DESCRIBE返回。 - 作用:让双方对 “要传输的媒体是什么样的” 达成共识。


)


)
——滤波器)


)



通讯--tcp客户端)

)



)