一、Netty的零拷贝机制
零拷贝的基本理念:避免在用户态和内核态之间拷贝数据,从而降低 CPU 占用和内存带宽的消耗除了系统层面的零拷贝。
1、FileRegion 接口
FileRegion 是 Netty 提供的用于文件传输的接口,它通过调用操作系统的 sendfile 函数实现文件的零拷贝传输。sendfile 函数可以将文件数据直接从文件系统发送到网络接口,而无需经过用户态内存拷贝。
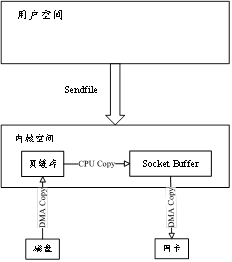
2、ByteBuf
ByteBuf提供了直接缓冲区(Direct Buffer)和堆缓冲区(Heap Buffer)两种类型
- HeapBuffer: 网络 IO、文件 IO 这种系统调用时,需要从 JVM 堆内存拷贝一次到内核态(socket buffer 或page cache); 即:JVM堆内 → JVM堆外(临时内存) → 内核内存
- DirectBuffer: JVM 分配的堆外内存可以直接暴露给内核,系统调用时 省了一次 JVM 内存 →内核的拷贝。即:JVM堆外(直接可用) → 内核内存
DirectBuffer 的好处是“避免 JVM 内存到内核内存的拷贝”
3、CompositeByteBuf
它是 Netty 提供的一种组合缓冲区,它可以将多个 ByteBuff 实例组合成一个逻辑上的缓冲区,而不需要实际拷贝数据。这种方式可以避免内存拷贝,提高内存使用效率。
没有 CompositeByteBuf 的话,我要合并三段数据(无论堆内还是 DirectBuffer)都得 拷贝 3 次字节;
有了 CompositeByteBuf,就可以 0 拷贝地把三段数据拼成一个整体,只在 最终 write 到 socket 时拷贝一次!
4、内存映射文件(Memory-Mapped File)
Netty 支持使用内存映射文件来实现文件的零拷贝。通过 MappedByteBuffer,文件可以被映射到内存中,并直接进行读取和写入操作,而不需要额外的内存拷贝。
MappedByteBuffer 是一种“把文件变成内存”的操作方式,它不是真正读了文件,而是借助操作系统提供的“内核页缓存 + 页面调度机制”来让你用内存方式读写文件内容,从而跳过传统 IO 调用,提升性能,减少拷贝,即减少了传统 read() IO 中“从内核态拷贝到用户态”的那一步内存拷贝。
传统文件读取流程:read() 的拷贝路径
磁盘 →(DMA)→ 内核页缓存(Page Cache) → memcpy → 用户空间 byte[]
1️、磁盘读取文件数据,用 DMA 拷贝到 Page Cache(内核态)
2️、系统调用 read() 把 Page Cache 中的数据 memcpy 一份给用户传进来的 byte[](用户态)
这一步会发生一次额外的数据拷贝:内核态 → 用户态
MappedByteBuffer 是怎么优化的?
磁盘 →(DMA)→ 内核页缓存(Page Cache)→ 直接映射到你的虚拟地址空间
1、把 Page Cache 的那块物理内存直接映射到你的进程的虚拟地址空间中
2、你访问这块内存时,系统不会再复制数据,而是让你直接读取那块 Page Cache 中的物理页
所以,数据是:
• 从磁盘 → Page Cache(依然是必要的!)
• 正省掉的是 “Page Cache → JVM堆内存”这一步;
FileRegion和ByteBuf功能上的区别
FileRegion 是为了解决 “文件发送”时避免拷贝(sendfile);
ByteBuf 是为了处理 内存中动态字节数据的读写、拼接、编码、解析。
两者职责完全不同,不是你用上 FileRegion,ByteBuf 就没用了,而是:
• 要发的是文件,就用 FileRegion
• 要发的是内存里的消息、请求体、序列化数据、协议帧,那就必须用 ByteBuf
| 功能 | FileRegion | ByteBuf | MappedByteBuffer |
|---|---|---|---|
| 定位用途 | **高效“文件→网络”**发送 | 内存中动态字节操作 | 直接把文件映射到内存操作 |
| 适用场景 | 大文件下载、文件转发 | 普通的内存字节处理(协议解析、缓存) | 大文件读写、随机访问、内存级文件解析 |
| 是否省拷贝 | ✅ sendfile 内核实现,零拷贝,省 内核态→用户态 | ❌ IO 时还是要经历 内核态 → 用户态 | ✅ mmap 机制,省 内核态 → 用户态 拷贝 |
| 是否跨内核和用户态 | 直接文件 → socket,用户态不介入 | 用户态玩数据,涉及 IO 时交互频繁 | 虽然你用的是用户态地址,但指向的是 Page Cache |
| 写操作友好性 | ❌ 不可修改,只是数据“搬运工” | ✅ 任意读写内存 | ⚠️ 写入时会 脏页同步到 Page Cache → 文件,有刷盘成本 |
| 核心优势 | 零拷贝、文件转发超快 | 灵活读写、内存拼接、操作方便 | 直接访问文件内容、适合大文件,访问就像数组一样快 |
| 底层依赖 | sendfile() 系统调用 | JVM堆或 DirectBuffer | mmap() 系统调用 |
二、 Netty如何解决粘包拆包问题?
Netty 提供了丰富的自带解码器为我们解决粘包和拆包的问题,也可以让我们自定义序列化解码器。
Netty 自带的解码器
1、DelimiterBasedFrameDecoder:分隔符解码器,使用特定分隔符来分割消息。
2、FixedLengthFrameDecoder:固定长度的解码器,可以按照指定长度对消息进行拆包,如果长度不够的话,可以使用空格进行补全,适用于每个消息长度固定的场景。
3、LengthFieldBasedFrameDecoder:可以根据接收到的消息的长度实现消息的动态切分解码,适用于消息头包含表示消息长度的字段的场景。
4、LineBasedFrameDecoder:发送端发送数据包的时候,数据包之间使用换行符进行分割,LineBasedFrameDecoder就是直接遍历 ByteBuf中的可读字节,根据换行符进行数据分割。
三、 介绍一下Reactor线程模型
Reactor 是服务端在网络编程时的一个编程模式,主要由一个基于 Selector (底层是select/poll/epoll)的死循环线程,也称为 Reactor 线程
基于事件驱动,将 I/0 操作抽象成不同的事件,每个事件都配置对应的回调函数,由Selector 监听连接上事件的发生,再进行分发调用相应的回调函数进行事件的处理。
Reactor 线程模型分为三种,分别为单 Reactor 单线程模型、单 Reactor 多线程模型、主从 Reactor 多线程模型。
1)单 Reactor 单线程模型:所有的操作都是由一个 I/O 线程处理。
·优点:对系统资源消耗较少
·缺点:没办法支持高并发场景。
2)单 Reactor 多线程模型:一个线程负责接收建连事件和后续的连接 I/0 处理(read
send等),线程池处理具体业务逻辑。
·优点:可以很好地应对大部分的场景,也提高了事件的处理效率。
·缺点:并发量大的时候,一个线程可能没办法接收所有的事件请求,可能导致性能瓶颈。
3)主从 Reactor 多线程模型:主 Reactor 线程负责接收建连事件,从 Reactor 线程负责处理建连后的后续连接 I/0 处理(read、send等),线程池处理具体业务逻辑
·优点:解决海量并发请求。
·缺点:相对而言,实现复杂度较高,对系统资源的管理要求会高一点
Reactor 模式的核心意义
Reactor 的核心在于“对事件作出反应”。用一个线程(或少量线程)来监听多个连接上的事件,根据事件类型分发调用相应的处理逻辑,从而避免为每个连接都分配一个线程。与传统模型对比,传统阻塞 I/0 是一个线程对应一个连接,资源浪费严重;而 Reactor 模式能实现一对多的映射,更适合高并发场景。
四、 有几种I/O模型?
1)同步阻塞I/O(Blocking I/O,BIO)
线程调用 read 时,如果数据还未到来,线程会一直阻塞等待;数据从网卡到内核,再从内核拷贝到用户空间,这两个拷贝过程都为阻塞操作。
·优点:实现简单,逻辑直观;调用后直接等待数据就绪
·缺点:每个连接都需要一个线程,即使没有数据到达,线程也会被占用,导致资源浪费,不适合高并发场景。
2)同步非阻塞I/0(Non-blocking I/O,NIO)在非阻塞模式下,read 调用如果没有数据就绪会立即返回错误(或特定状态),不会阻塞线程;应用程序需要不断轮询判断数据是否就绪,但当数据拷贝到用户空间时依然是阻塞的。
·优点:线程不会长时间阻塞,可以在无数据时执行其他任务;适用于部分实时性要求较高的场景。
·缺点:轮询方式会频繁进行系统调用,上下文切换开销较大,CPU占用率较高,不适合大规模连接。
3)I/0 多路复用
通过一个线程(或少量线程)使用 select、等系统调用,监控多个连接的poll ,epoll状态;只有当某个连接的数据就绪时,系统才通知应用程序,再由应用程序调用read 进行数据读取(读取时仍为阻塞操作)。
·优点:大大减少了线程数量和上下文切换,能高效处理大量并发连接;资源利用率高。
·缺点:依赖系统内核的支持,不同的多路复用实现(如 select vs epoll)有各自局限。
4)信号驱动 I/O
由内核在数据就绪时发出信号通知应用程序,应用程序收到信号后再调用read(依然阻塞)
·优点:理论上可以避免轮询,数据就绪时由内核主动通知。
·缺点:对于 TCP 协议,由于同一个信号可能对应多种事件,难以精确区分(所以实际应用中使用较少)。
五、 Netty应用场景
Netty 的应用场景主要有以下几个:许多框架底层通信的实现,比如说 RocketMQ、Dubbo、Elasticsearch、Cassandra等,底层都使用到了 Netty。
游戏行业,在游戏服务器开发中,Netty 用于处理大量并发的游戏客户端连接,提供低延迟的网络通信能力
实现一个通讯系统,比如聊天室、IM 等,处理高并发的实时消息传输。
物联网即 IOT 场景,Netty 可用于设备与服务器之间的通信,处理设备数据的收集和命令下发。
六、 为什么不使用原生的NIO而选择Netty?
使用 Netty 的优势:
1)Netty 封装了 NIO 的复杂 API,提供了更简单、直观的编程接口,使开发者更容易上手和维护。
2)Netty 提供了优化的多线程模型(如 Reactor 模型),可以更高效地处理 //O 事件和任务调度,提升并发处理能力。
3)Netty 支持多种传输协议(http、dns、tcp、udp 等等),并且有自带编码器,解决了 TCP 粘包和拆包的问题。
4)在原生 NIO 的基础上解决了 Selector 空轮询 Bug 的问题,且准备内部的细节做了优化,例如 JDK 实现的 selectedKeys 是 Set 类型,Netty 使用了数组来替换这个类型,相比 Set 类型而言,数组的遍历更加高效,其次数组尾部添加的效率也高于 Set,毕竟 Set还可能会有 Hash 冲突,这是 Netty 为追求底层极致优化所做的。
5)采用了零拷贝机制,避免不必要的拷贝,提升了性能。
七、 Netty性能高的原因
Netty 性能高的主要原因如下:
非阻塞 I/O 模型(如何监听事件):Netty 底层使用了 NIO 非阻塞模型,并且利用IO多路复用,通过 Selector 监听多个 Channel的 IO 事件,使得系统资源得到了充分利用,减少了线程开销。
优秀的线程模型(事件来了由谁处理):Netty 底层有很多优秀的线程模型,比如 Reactor 模型、主从Reactor 模型、多线程模型等,可以高效地发挥系统资源的优势,减少锁冲突,实现无锁串行,针对不同业务场景的诉求,可以自定灵活控制线程,提高系统的并发处理能力。
零拷贝(数据传输):DirectBuffer 减少堆内外的拷贝、CompositeBuffer 减少数据拼接时的拷贝、FileRegion 减少文件传输时的拷贝。
高效的内存操作与内存池设计:ByteBuf提供了丰富的功能,如动态扩展、复合缓冲区等,能高效地进行内存操作,并使用内存池技术来优化 ByteBuf的分配和回收,减少频繁的内存分配和释放操作,提高性能。
八、 Netty如何解决NIO中的空轮询BUG?
Netty 实际上并没有解决 JDK 原生 NIO 中空轮询 bug,而是通过其他途径绕开了这个错误。
具体操作如下:
1、统计空轮询次数:Netty 通过 selectCnt 计数器来统计连续空轮询的次数。每次执行Selector.select()方法后,如果发现没有 I/O 事件,selectCnt 就会递增,
2、设置阈值:Netty 定义了一个阈值 SELECTOR AUTO REBUILD THRESHOLD,默认值为 512。当空轮询次数达到这个值时,Netty 会触发重建 Selector 的操作。
3、重建 Selector:当达到空轮询的阈值时,Netty 会创建一个新的 Selector,并将所有注册的 Channel 从旧的 Selector 转移到新的 Selector 上。这一过程涉及到取消旧日 Selector上的注册,并在新 Selector 上重新注册 Channel。
4、关闭旧的 Selector:在成功重建 Selector 并将Channel 重新注册后,Netty 会关闭旧的 Selector,从而避免继续在旧的 Selector 上发生空轮询。总结来看,就是通过 selectCnt 统计没有 I/0 事件的次数来判断当前是否发生了空轮询如果发生了就重建一个 Selector 替换之前出问题的 Selector,所以说 Netty 实际上没解决空轮询的 bug,只是绕开了这个问题。
空轮询 bug 原因:
当连接的 Socket 被突然中断(如对端异常关闭)时,epoll 会将该 Socket 的事件标记为EPOLLHUP 或 EPOLLERR,导致 Selector 被唤醒。然而,SelectionKey 并未定义处理这些异常事件的类型,导致 Selector 被唤醒后,无法处理这些异常事件,从而进入空轮询状态,导致 CPU 占用率过高。
Selector 底层其实用的是 epoll(Linux):
• epoll_wait() 支持监听几万个 fd(也就是 SocketChannel)
• 这些 fd 上注册的事件一般是:
• EPOLLIN → 对应 Java 的 OP_READ
• EPOLLOUT → 对应 Java 的 OP_WRITE
• 还有 EPOLLHUP(挂起) / EPOLLERR(错误)这两种“系统级”异常事件
⚠ 问题点:异常事件虽然会唤醒 epoll,但 Java 层不处理,Selector 会调用 native epoll_wait,被 EPOLLHUP、EPOLLERR 唤醒没问题。但是,Java 的 SelectionKey 只支持处理 OP_READ / OP_WRITE / OP_ACCEPT / OP_CONNECT。它没有暴露“这个 key 是因为异常唤醒的”这种能力,所以唤醒后,我们调用 selectedKeys(),结果是空的!这就等于:“你闹钟响了我就醒了,但你根本没安排任务,那我只能干站着,反复被吵醒”
🚨 所以空轮询本质就是:
Selector 被异常唤醒,但 Java 应用层没有能力识别这个异常事件,也没法处理它,导致不断 select → 空 → select → 空,形成死循环 + 高 CPU。
为啥重建 Selector 就能好?
大多数空轮询 bug 触发的根因是:
• 某些 fd(Socket)状态不干净
• 或某个 selector 对象在 native epoll 里状态乱了
所以重建 selector + 重新注册 Channel的过程,相当于:
✨重新 clean 一遍所有状态,把原来 epoll 里的鬼影都清除掉了。
🛠 重建 Selector 的关键步骤:
- 创建一个新的 Selector
- 遍历旧 Selector 中的所有 SelectionKey
- 对每个 key:
o 取出 channel 和监听事件(interestOps)
o 尝试用 channel.register(newSelector, interestOps, attachment) 重新注册
o 如果注册成功 → 加入新 Selector
o 如果注册失败(一般就是异常 socket) →
✅ 从旧的 Selector 中 cancel
✅ 手动关闭 Channel
✅ 打印警告日志






封装、继承和多态)
)











