理解文件系统
我们知道文件可以分为磁盘文件和内存文件,内存文件前面我们已经谈过了,下面我们来谈谈磁盘文件。
目录
一、引入"块"概念
解析 stat demo.c 命令输出
基本信息
设备信息
索引节点信息
权限信息
时间戳
二、引入"分区"概念
1、在Linux系统中,可通过以下命令查看磁盘分区信息
2、磁盘实现分区
3、磁盘格式化
三、引入"inode"概念
解析 ls -l 命令输出内容
各字段详细解析
特殊情况的表示
解析 ls -li 命令输出
Inode号 (第1列)
注意
请注意
目前大家可能还存在两个疑问
一、引入"块"概念
硬盘是典型的"块"设备。操作系统在读取硬盘数据时,并非逐个扇区读取(这样效率太低),而是通过一次性连续读取多个扇区来实现,这个连续读取的单位称为"块"(block)。
每个硬盘分区都被划分为若干个"块"。"块"的大小在格式化时确定且不可更改,最常见的大小是4KB(即连续八个扇区组成一个"块")。"块"是文件存取的最小单位。
stat 文件名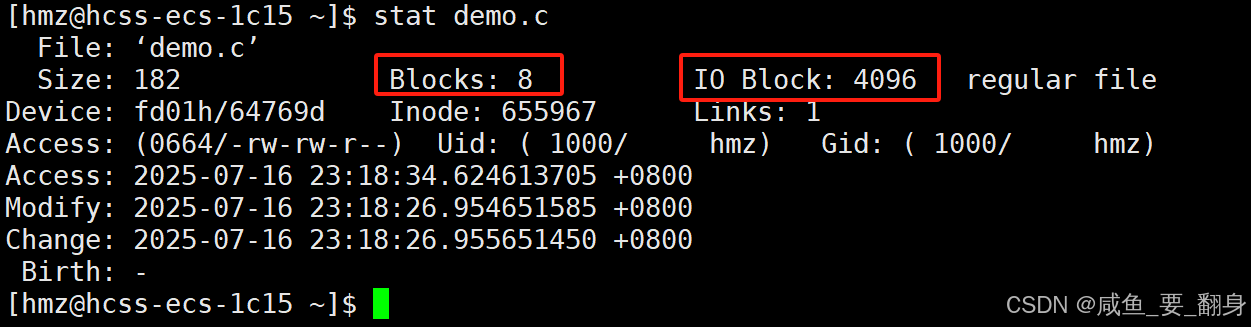
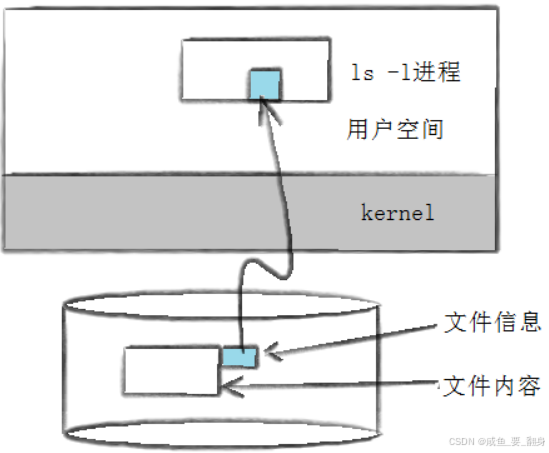
解析 stat demo.c 命令输出
stat 命令用于显示文件或文件系统的详细状态信息。以下是 demo.c 文件的详细信息解析:
基本信息
-
文件名: 'demo.c'
-
大小: 182 字节
-
占用块数: 8 个块 (通常每个块512字节,所以占用约4KB空间)
-
IO块大小: 4096 字节 (文件系统块大小)
-
类型: 普通文件 (regular file)
设备信息
-
设备号: fd01h/64769d (主设备号fd01h,次设备号64769d)
索引节点信息
-
Inode号: 655967
-
硬链接数: 1 (表示没有其他硬链接指向此文件)
权限信息
-
访问权限: 0664 (-rw-rw-r--)
-
所有者(hmz): 读写权限(rw-)
-
所属组(hmz): 读写权限(rw-)
-
其他用户: 只读权限(r--)
-
-
所有者: UID 1000 (用户名hmz)
-
所属组: GID 1000 (组名hmz)
时间戳
-
最后访问时间(Access): 2025-07-16 23:18:34.624613705 +0800
-
最后修改时间(Modify): 2025-07-16 23:18:26.954651585 +0800 (文件内容最后修改时间)
-
最后状态变更时间(Change): 2025-07-16 23:18:26.955651450 +0800 (文件元数据如权限等最后变更时间)
-
创建时间(Birth): - (不支持或未记录)
注意:
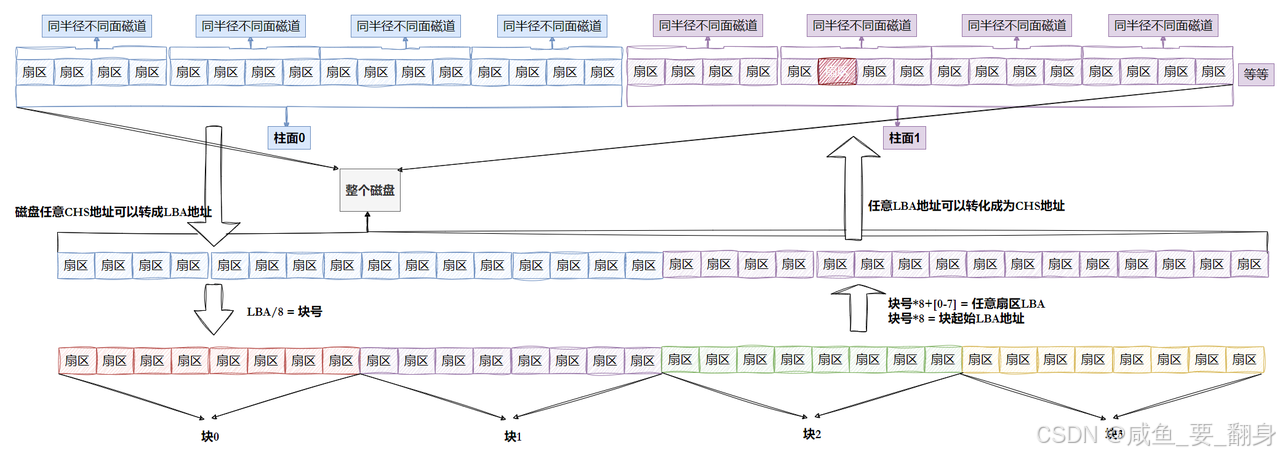
- 磁盘可视为一个三维数组,我们将其抽象为一维数组处理,数组下标对应LBA(Logical Block Address),每个元素代表一个扇区
- 每个扇区都有对应的LBA地址,8个扇区组成一个块,可以根据LBA计算出块地址
- LBA与块号的转换关系:
- 已知LBA求块号:块号 = LBA / 8
- 已知块号求LBA:LBA = 块号 * 8 + n(n表示块内扇区序号)
二、引入"分区"概念
磁盘作为典型的块设备,通常以512字节的扇区为基本单位。以512GB磁盘为例,其包含超过十亿个扇区。

实际上,磁盘可以被划分为多个分区(partition)。分区编辑器将磁盘划分为若干逻辑区域,不同分区可存储特定类型的目录和文件。分区越多,文件分类管理就越细致。以Windows系统为例,你可能有一块物理磁盘并将其划分为C、D、E盘,这些盘符就代表不同的分区。从本质上说,分区就是对硬盘进行格式化的一种方式。
1、在Linux系统中,可通过以下命令查看磁盘分区信息
ls /dev/vda* -l
2、磁盘实现分区
在Linux系统中,所有设备都以文件形式存在,那么如何实现分区呢?分区的最小单位是柱面,我们可以通过指定柱面编号来进行分区,具体操作就是设置每个分区的起始和结束柱面编号。
为了更直观地理解,我们可以将硬盘上的柱面(分区)展开,想象成一个平面示意图,如下图所示:

注意:
当满足以下条件时:
-
所有柱面大小一致(即每个柱面包含相同数量的磁道)
-
每个磁道的扇区数相同(即"扇区个位一致")
那么计算分区大小和LBA地址可以简化为:
-
分区大小计算:
分区大小 = (结束柱面号 - 起始柱面号 + 1) × 每柱面扇区数 × 扇区大小 -
LBA计算:
某位置的LBA = 起始柱面的LBA + (柱面偏移 × 每柱面扇区数) + 磁头偏移 × 每磁道扇区数 + 扇区偏移 - 1

3、磁盘格式化
在完成磁盘分区后,还需要进行格式化操作。格式化是对磁盘分区进行初始化的过程,这一操作会清除分区内所有现有文件。
简而言之,格式化就是在各个分区中写入相应的管理信息。
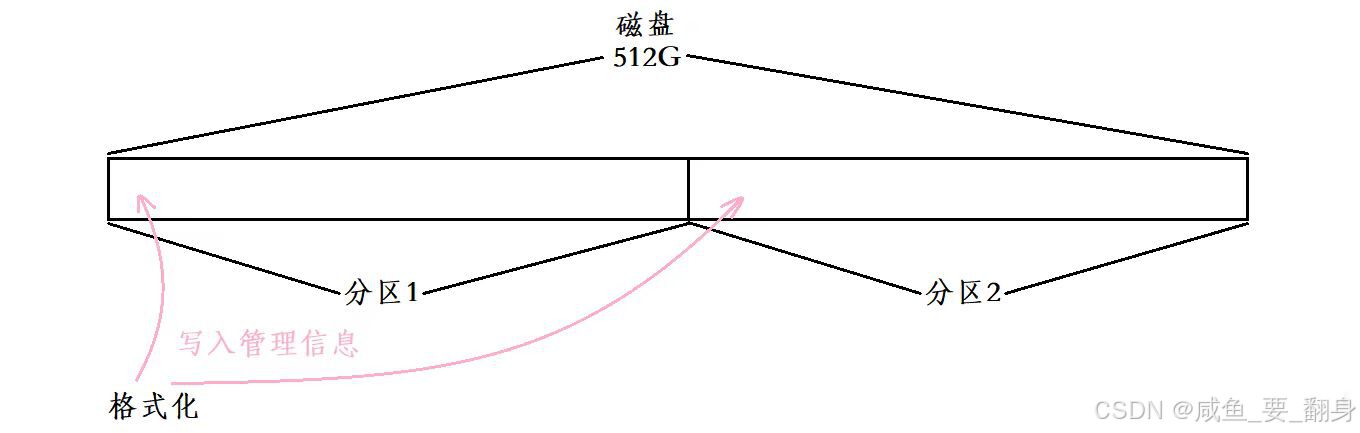
其中,写入的管理信息是什么是由文件系统决定的,不同的文件系统格式化时写入的管理信息是不同的,常见的文件系统有EXT2、EXT3、XFS、NTFS等。 会在后面的博客中进行讲解!
三、引入"inode"概念
在Linux系统中,文件内容与元数据是分开存储的。这种存储元数据的结构称为inode。由于系统中可能存在大量文件,每个文件属性集都需要一个唯一标识符,即inode编号。
简而言之,inode就是文件属性的集合。Linux系统中几乎所有文件都拥有自己的inode。为了有效区分系统中的众多inode,每个inode都被分配了唯一的编号。
正如之前所述,文件由数据和属性两部分组成。当我们使用ls -l命令时,不仅能看到文件名,还能查看文件的元数据(即属性信息)。
ls -l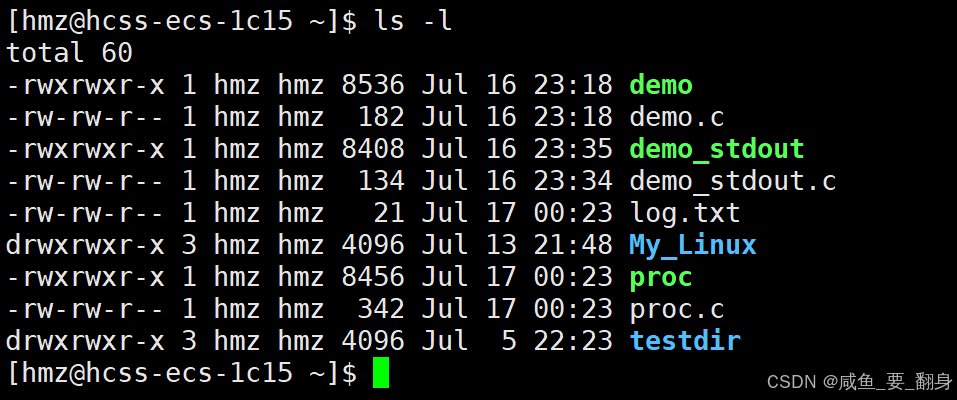
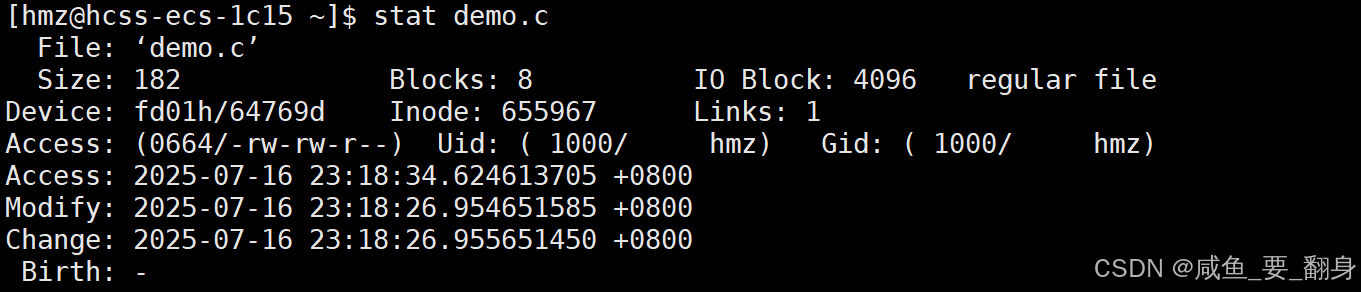
解析 ls -l 命令输出内容
ls -l 是 Linux/Unix 系统中常用的命令,用于以长格式显示文件和目录的详细信息。以下是典型输出的解析:
各字段详细解析
-
文件类型和权限(第1列)
由10个字符组成,例如-rwxr-xr--:-
第1个字符:文件类型
标识符 文件类型 说明 -普通文件 常规文件,如文本、二进制文件等 d目录 文件夹,包含其他文件或子目录 l符号链接 快捷方式,指向另一个文件或目录(如 link -> target)c字符设备文件 按字符流访问的设备(如终端 /dev/tty)b块设备文件 按数据块访问的设备(如硬盘 /dev/sda)s套接字文件 进程间通信的套接字文件(如 MySQL 的 /var/run/mysqld/mysqld.sock)p命名管道文件 先进先出(FIFO)管道,用于进程间通信(如 mkfifo创建的文件) -
第2-4字符:所有者权限(u)
-
第5-7字符:组权限(g)
-
第8-10字符:其他用户权限(o)
-
权限字符:
字符 权限类型 说明 r读权限 允许查看文件内容(文件)或列出目录内容(目录) w写权限 允许修改文件内容(文件)或在目录中创建/删除文件(目录) x执行权限 允许执行文件(程序/脚本)或进入目录(目录) sSUID/SGID SUID(所有者位置):以文件所有者权限执行
SGID(组位置):以文件所属组权限执行或继承父目录的组权限t粘滞位 仅对目录有效,用户只能删除自己拥有的文件(如 /tmp目录)
-
-
硬链接数(第2列)
显示指向该文件/目录的硬链接数量。目录通常至少有2个链接(自身和.)。 -
所有者(第3列)
文件/目录的属主用户名。 -
所属组(第4列)
文件/目录的属组名。 -
大小(第5列)
-
普通文件:显示字节大小
-
目录:显示目录元数据占用的空间(通常4096字节)
-
-
最后修改时间(第6-8列)
显示文件/目录的最后修改时间,格式通常为:-
月份(如Jun)
-
日期(如12)
-
时间(如14:30)
-
如果文件修改时间超过6个月,会显示年份而非时间
-
-
文件名(最后一列)
文件或目录名称。如果是符号链接,会显示linkname -> targetname。
特殊情况的表示
-
SUID/SGID权限:
-
rwsr-xr-x(所有者x位置变为s表示SUID) -
rwxr-sr-x(组x位置变为s表示SGID)
-
-
粘滞位:
-
rwxr-xr-t(其他用户x位置变为t)
-
-
大小时单位显示:
使用-lh选项时会以K/M/G等易读单位显示大小
ls -l 用于读取磁盘上的文件信息并显示详细列表:
除了通过这种方式读取信息,还可以使用 stat 命令查看更详细的内容:
这里我们需要思考一个问题:既然文件数据都存储在"块"中,那么显然还需要一个地方来存储文件的元信息(属性信息),比如创建者、创建日期、文件大小等。这个存储文件元信息的区域就叫做inode,中文译名为"索引节点"。
ls -li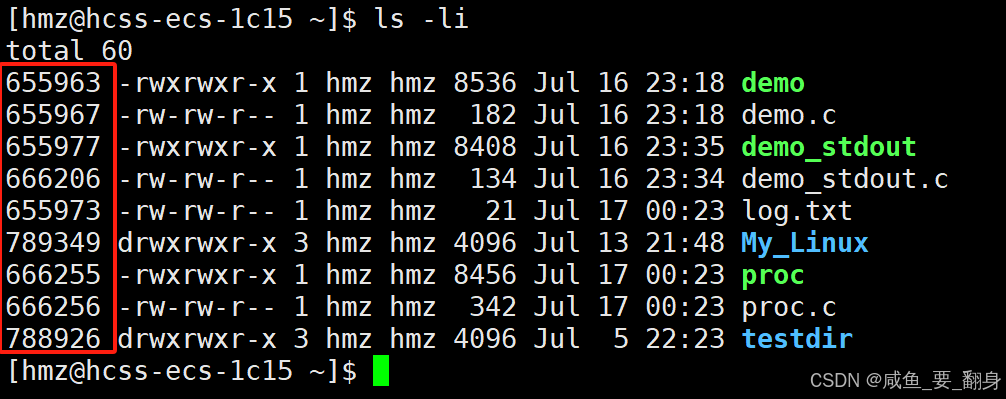
解析 ls -li 命令输出
ls -li 命令结合了 -i (显示inode号) 和 -l (长格式) 选项,提供比普通 ls -l 更详细的信息。以下是完整解析:
Inode号 (第1列)
-
唯一标识文件系统内的文件
-
示例:
1234567 -
特点:
-
每个文件/目录有唯一inode号
-
硬链接共享相同inode号
-
删除文件实际上是减少inode的链接计数
-
每个文件都对应一个inode,其中存储着该文件的相关信息。要理解inode的概念,我们需要先深入了解文件系统的工作原理。
注意
- Linux系统中文件采用属性与内容分离的存储机制
- Linux通过inode结构存储文件属性,每个文件对应一个独立的inode
- inode中包含唯一的标识符,称为inode号
一个文件的 inode 属性具体是什么样呢?我们来到源码中看看对应的结构:
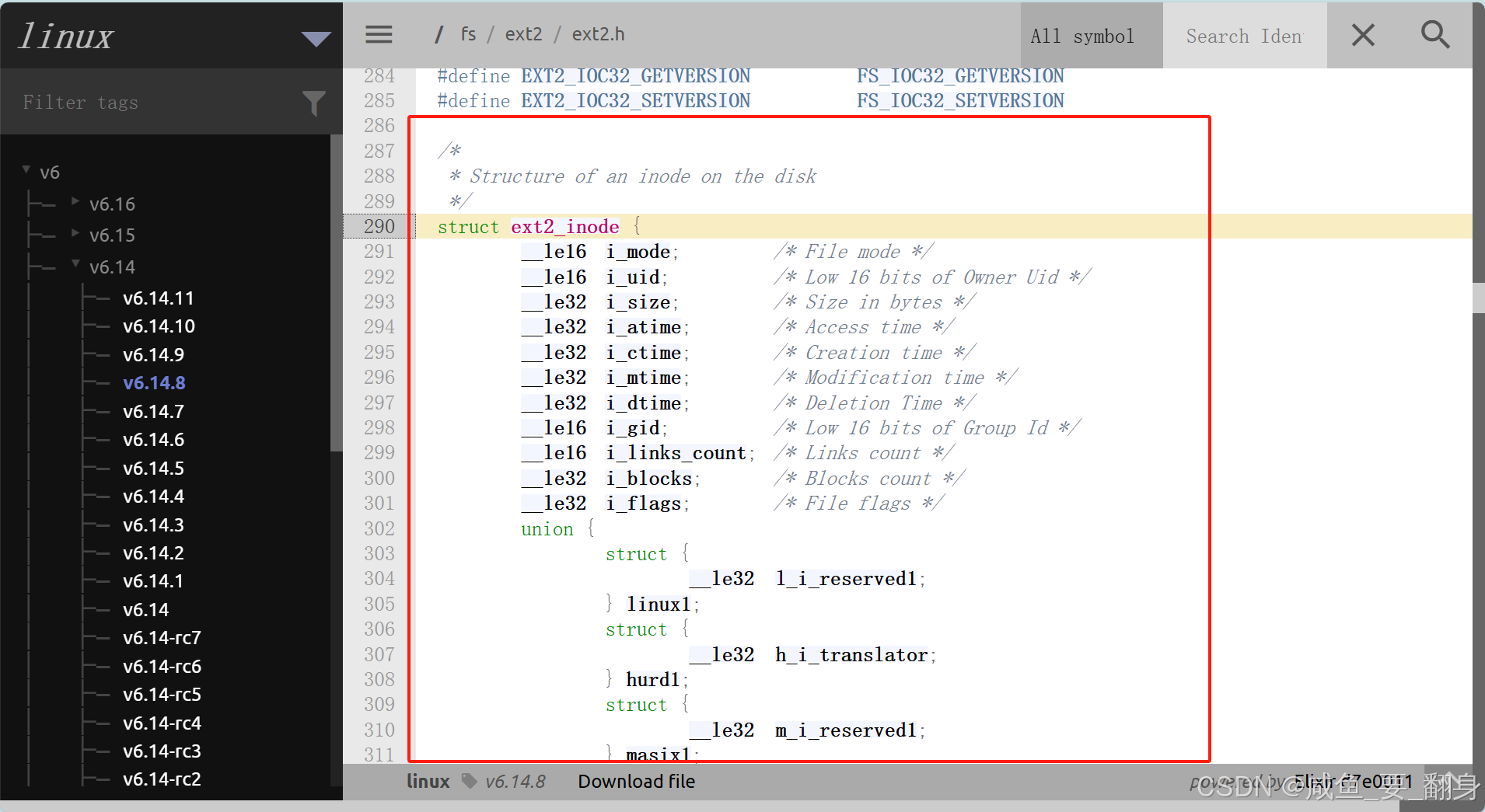
/** Structure of an inode on the disk (ext2文件系统的磁盘inode结构)*/
struct ext2_inode {/* 基础信息 */__le16 i_mode; /* 文件类型和权限 (rwx) */__le16 i_uid; /* 所有者UID低16位 */__le32 i_size; /* 文件大小(字节) *//* 时间戳(Unix时间戳格式) */__le32 i_atime; /* 最后访问时间 */__le32 i_ctime; /* 创建时间 */__le32 i_mtime; /* 最后修改时间 */__le32 i_dtime; /* 删除时间 *//* 所有权信息 */__le16 i_gid; /* 所属组GID低16位 */__le16 i_links_count; /* 硬链接计数 */__le32 i_blocks; /* 占用块数(512字节为单位) */__le32 i_flags; /* 文件标志(如不可修改、压缩等) *//* 操作系统特定数据1 */union {struct {__le32 l_i_reserved1;} linux1;struct {__le32 h_i_translator;} hurd1;struct {__le32 m_i_reserved1;} masix1;} osd1;/* 数据块指针 */__le32 i_block[EXT2_N_BLOCKS]; /* 直接/间接块指针(共15个) *//* 扩展属性 */__le32 i_generation; /* 文件版本(用于NFS) */__le32 i_file_acl; /* 文件ACL块指针 */__le32 i_dir_acl; /* 目录ACL块指针 */__le32 i_faddr; /* 碎片地址 *//* 操作系统特定数据2 */union {struct {__u8 l_i_frag; /* 碎片编号 */__u8 l_i_fsize; /* 碎片大小 */__u16 i_pad1;__le16 l_i_uid_high; /* 所有者UID高16位 */__le16 l_i_gid_high; /* 所属组GID高16位 */__u32 l_i_reserved2;} linux2;struct {__u8 h_i_frag;__u8 h_i_fsize;__le16 h_i_mode_high;__le16 h_i_uid_high;__le16 h_i_gid_high;__le32 h_i_author;} hurd2;struct {__u8 m_i_frag;__u8 m_i_fsize;__u16 m_pad1;__u32 m_i_reserved2[2];} masix2;} osd2;
};/** 数据块相关常量*/
#define EXT2_NDIR_BLOCKS 12 /* 直接块数量 */
#define EXT2_IND_BLOCK (EXT2_NDIR_BLOCKS) /* 一级间接块索引 */
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) /* 二级间接块索引 */
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1) /* 三级间接块索引 */
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1) /* 总块指针数(15个) */查看源码后,我们可以知道inode这个数据结构中包含了很多很多的文件属性!!!
请注意
- 文件名属性不包含在inode数据结构中
- inode大小通常为128字节或256字节,后续讨论中将统一采用128字节
- 不同文件的内容大小可以各不相同,但其属性大小始终相同
目前大家可能还存在两个疑问
-
我们已经知道硬盘是典型的"块"设备,操作系统读取硬盘数据的基本单位是"块"。这些"块"作为硬盘分区下的结构,它们是如何在分区上有序分布的?系统又是如何快速定位到这些"块"的呢?
-
前面提到的存储文件属性的inode,它们又是如何被组织存放的?
文件系统正是为了解决这些问题而设计的!后面将会讲解文件系统的相关知识!!!

虚拟专用网 VPN 和网络地址转换 NAT)









![Nordic打印RTT[屏蔽打印中的<info> app]](http://pic.xiahunao.cn/Nordic打印RTT[屏蔽打印中的<info> app])

:开发规范、组件开发方法介绍,快速上手组件开发,创造各种有趣的UI组件!)

与filter()对比)
 概述与分类)


