文章目录
- 一、图像熵(Image Entropy)
- (1)基本原理
- (2)优势与局限
- (3)推荐策略
- 多指标联合推荐体系
- 噪声应对机制建议
- 二、项目实战 —— 通过图像熵评价序列图像,并提取最优图像
- (1)【先模拟,后计算】根据给定图像,模拟数据生成(亮度+对比度),生成序列图像
- (2)【先模拟,后计算】在序列图像中,提取图像熵最大的图像
- (3)根据给定图像,自动模拟亮度+对比度组合,提取图像熵最大的图像 —— 将前两个功能合并
- 三、熵值饱和 —— 存在多个最优值
- (1)为什么会出现熵值饱和?
- (2)如何应对熵值饱和现象?
一、图像熵(Image Entropy)
图像熵是一种源自信息论的度量指标,用于衡量图像中灰度分布的复杂性与信息量,常用于图像质量评价、对比度增强评估与自动参数选择。
熵值高:灰度分布复杂,细节丰富,信息量大;熵值低:灰度集中,图像可能存在模糊、过曝或过暗现象,结构信息有限。
图像熵(Image Entropy)和信息熵(Information Entropy)在理论本质上是一致的:图像熵是将信息熵应用于灰度图像像素分布的一种方式。
(1)基本原理
图像熵定义:
H=−∑i=0L−1pilog2piH = - \sum_{i=0}^{L-1} p_i \log_2 p_i \, H=−i=0∑L−1pilog2pi
- HHH 为图像熵,即整幅图像灰度概率分布的信息平均量;
- LLL 是灰度级数;
- pip_ipi 是灰度级为 iii 的像素概率分布,满足归一化条件 ∑i=0L−1pi=1\sum_{i=0}^{L-1} p_i = 1∑i=0L−1pi=1;
- 当 pi=0p_i = 0pi=0 时,定义 pilog2pi=0p_i \log_2 p_i = 0pilog2pi=0,以保证计算的连续性和数学合理性。
(2)优势与局限
熵值不能作为图像增强效果评价的唯一依据。
| 项目 | 描述 |
|---|---|
| ✅ 优势 | 对灰度分布变化敏感,适用于无监督图像增强场景,能反映增强后信息量变化趋势 |
| ⚠️ 局限1(熵值饱和) | 当增强超过一定阈值后,熵值可能不再增加甚至出现多个最大值重复,即“熵值饱和”,此时图像可能已过曝或细节损毁 |
| ⚠️ 局限2(噪声敏感) | 图像噪声会显著提升熵值,因为噪声本身会增加像素灰度的不确定性,从而产生误导性高熵,掩盖真实的结构细节变化 |
关于噪声的影响说明:
- 噪声使图像灰度分布变得更加“随机化”,从而人为抬高熵值;
- 在低对比度或高增益场景中,噪声贡献可能占主导;
- 特别是在电镜图像、医学影像等领域,高熵并不意味着高质量,而可能是噪声主导的“伪丰富”。
(3)推荐策略
为克服图像增强过程中的“熵值饱和”与“噪声误导”等问题,建议构建多指标联合评价机制,以实现增强参数的稳健选优。
多指标联合推荐体系
| 指标类型 | 主要衡量维度 | 功能说明 |
|---|---|---|
| 图像熵(Entropy) | 信息丰富度 | 反映图像灰度分布复杂程度 |
| 灰度标准差(Std) | 对比度变化程度 | 捕捉亮度范围扩展趋势 |
| 结构清晰度指标(如Laplacian方差) | 边缘/细节保留情况 | 评价图像纹理与边缘锐利度 |
| 主观/判别模型评分 | 任务适配性 | 用于特定场景的个性化调整 |
通过这些指标的联合判断,可有效规避熵值饱和陷阱,提升增强参数选择的判别性与稳定性。
噪声应对机制建议
为降低噪声对熵值的误导作用,推荐在增强流程中引入如下控制策略:
- 预处理降噪:对原始图像先执行如中值滤波或双边滤波,抑制高频噪声后再进行熵值计算;
- 可在图像增强管线中,集成结构敏感指标与熵值联合判定,形成更稳健的增强决策逻辑;
- 对于噪声主导的图像,建议优先考虑清晰度或纹理一致性指标替代纯熵值判断。
二、项目实战 —— 通过图像熵评价序列图像,并提取最优图像
(1)【先模拟,后计算】根据给定图像,模拟数据生成(亮度+对比度),生成序列图像
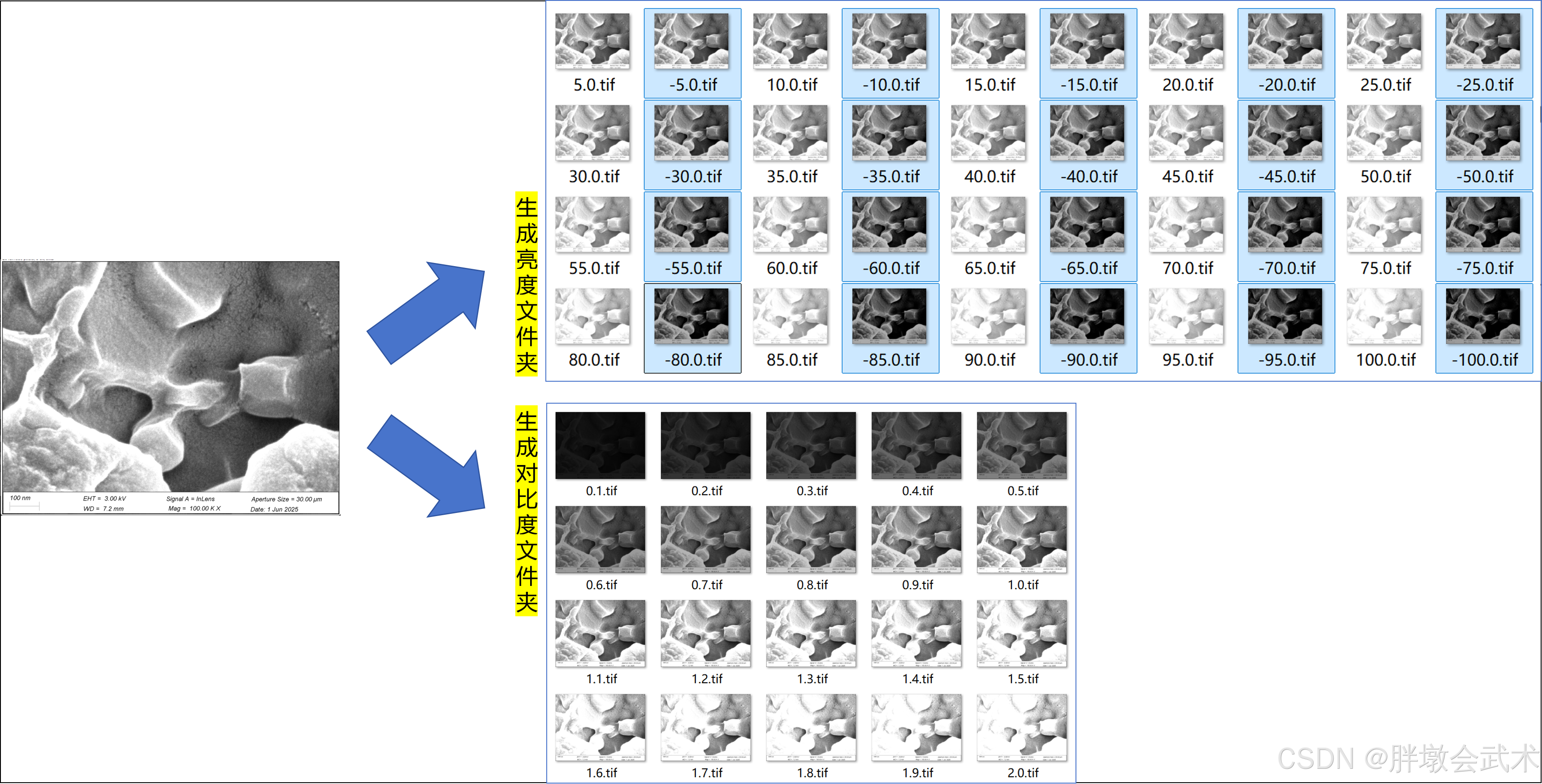
import cv2
import os
import numpy as npdef enhance_image(img, brightness=0.0, contrast=1.0):"""使用线性变换增强图像:output = input × contrast + brightness"""img = img.astype(np.float32)enhanced = img * contrast + brightnessenhanced = np.clip(enhanced, 0, 255).astype(np.uint8)return enhanceddef process_separately(input_dir, brightness_list, contrast_list):"""分别对每张图像进行亮度增强与对比度增强。每个图像创建一个子目录,其中包含 brightness/ 和 contrast/ 两个子目录。"""tif_files = [f for f in os.listdir(input_dir) if f.lower().endswith(".tif")]for filename in tif_files:import timestart = time.time()filepath = os.path.join(input_dir, filename)img = cv2.imread(filepath, cv2.IMREAD_GRAYSCALE)if img is None:print(f"⚠ 无法读取文件: {filename}")continuename = os.path.splitext(filename)[0]save_root = os.path.join(input_dir, name)brightness_dir = os.path.join(save_root, "brightness")contrast_dir = os.path.join(save_root, "contrast")os.makedirs(brightness_dir, exist_ok=True)os.makedirs(contrast_dir, exist_ok=True)# 亮度增强(固定对比度为1.0)for b in brightness_list:enhanced = enhance_image(img, brightness=b, contrast=1.0)save_path = os.path.join(brightness_dir, f"{b:.1f}.tif")cv2.imwrite(save_path, enhanced)# 对比度增强(固定亮度为0.0)for c in contrast_list:enhanced = enhance_image(img, brightness=0.0, contrast=c)save_path = os.path.join(contrast_dir, f"{c:.1f}.tif")cv2.imwrite(save_path, enhanced)print(f"✅ [分开处理] 已处理: {filename},耗时 {time.time() - start:.2f} 秒")def process_combined(input_dir, brightness_list, contrast_list):"""对每张图像进行亮度+对比度组合增强。每张图像创建一个子目录,所有增强图像统一保存在该目录中。命名格式为:<contrast>_at_<brightness>.tif,例如 1.2_at_-5.0.tif"""tif_files = [f for f in os.listdir(input_dir) if f.lower().endswith(".tif")]for filename in tif_files:import timestart = time.time()filepath = os.path.join(input_dir, filename)img = cv2.imread(filepath, cv2.IMREAD_GRAYSCALE)if img is None:print(f"⚠ 无法读取文件: {filename}")continuename = os.path.splitext(filename)[0]save_dir = os.path.join(input_dir, name)os.makedirs(save_dir, exist_ok=True)for b in brightness_list:for c in contrast_list:enhanced = enhance_image(img, brightness=b, contrast=c)save_name = f"b_{b:.1f}_and_c_{c:.1f}.tif"save_path = os.path.join(save_dir, save_name)cv2.imwrite(save_path, enhanced)print(f"✅ [组合处理] 已处理: {filename},耗时 {time.time() - start:.2f} 秒")# 模拟数据生成:遍历文件夹下的所有文件,对每张图像进行亮度+对比度组合增强 huo 分别对每张图像进行亮度增强与对比度增强。
if __name__ == "__main__":input_dir = r"D:\py\BC\25052757812\demo"brightness_list = [round(float(b), 1) for b in np.arange(-100, 100.1, 5)]contrast_list = [round(float(c), 1) for c in np.arange(0.1, 2.1, 0.1)]print(f"亮度范围: {brightness_list}")print(f"对比度范围: {contrast_list}")# 使用其中一种处理方式process_separately(input_dir, brightness_list, contrast_list) # 分开处理# process_combined(input_dir, brightness_list, contrast_list) # 合并处理
(2)【先模拟,后计算】在序列图像中,提取图像熵最大的图像
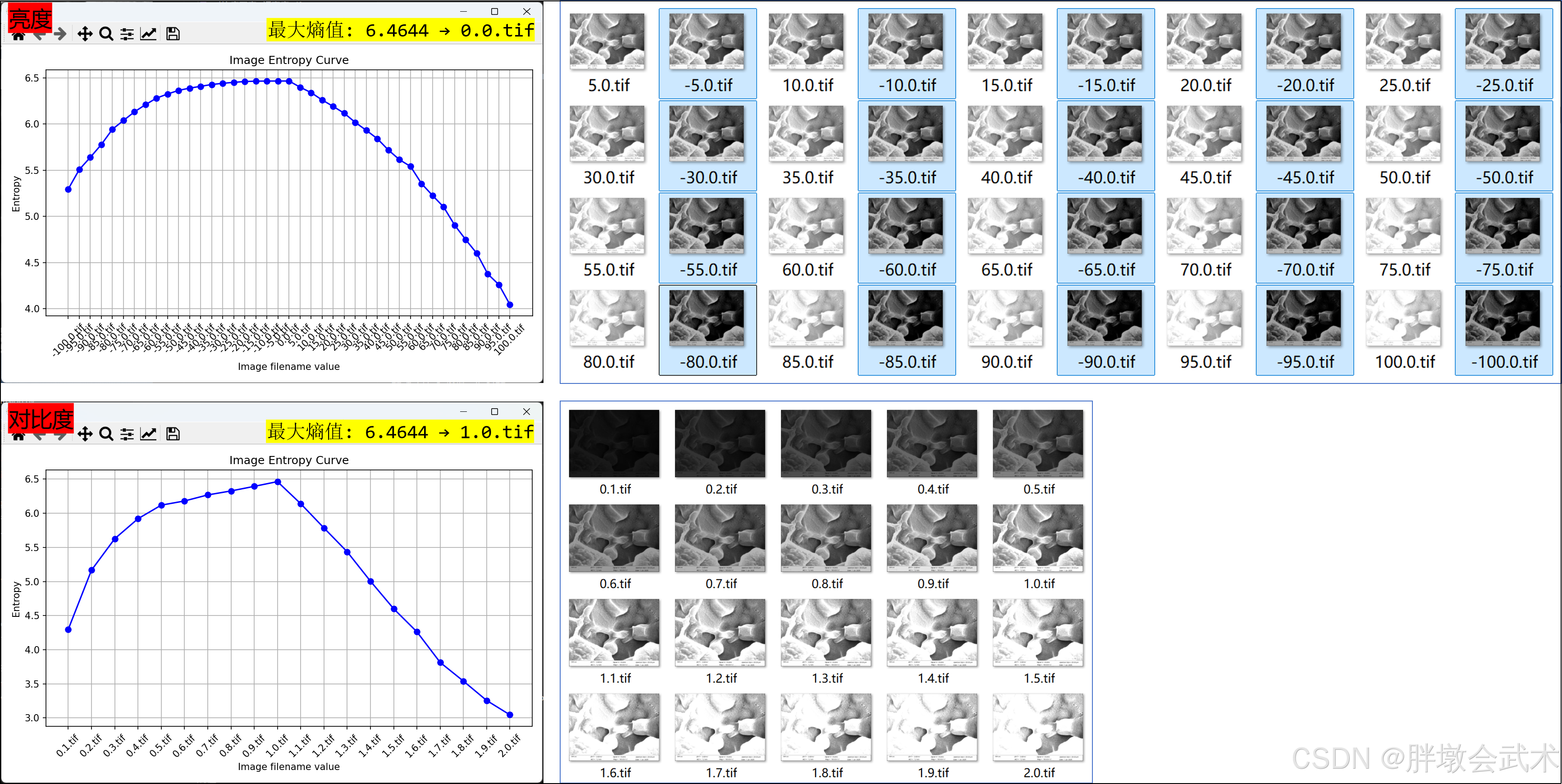
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
import redef compute_entropy(image):"""计算图像熵"""hist = cv2.calcHist([image], [0], None, [256], [0, 256])hist = hist.ravel() / hist.sum()hist = hist[hist > 0]entropy = -np.sum(hist * np.log2(hist))return entropydef extract_number(filename):"""提取文件名中的数字(用于排序与x轴)"""match = re.search(r"[-+]?\d*\.\d+|\d+", filename)return float(match.group()) if match else float('inf')def show_image_entropy_curve(folder_path):"""遍历图像,计算熵值并绘制熵值曲线(支持多最大值)"""entropy_list = []x_vals = []best_entropy = -1best_images = []files = sorted([f for f in os.listdir(folder_path) if f.lower().endswith(".tif")],key=extract_number)for filename in files:img_path = os.path.join(folder_path, filename)img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)if img is None:continueentropy = compute_entropy(img)entropy_list.append(entropy)x_vals.append(filename)print(f"{filename} - 熵值: {entropy:.4f}")if entropy > best_entropy:best_entropy = entropybest_images = [filename]elif entropy == best_entropy:best_images.append(filename)# 打印最优图像列表print(f"\n✅ 最大熵值: {best_entropy:.4f}")print("📌 最优图像文件列表:")for fname in best_images:print(f" → {fname}")# 绘制曲线图save_path = os.path.join(folder_path, "entropy_curve.png")plt.figure(figsize=(8, 5))plt.plot(x_vals, entropy_list, marker='o', linestyle='-', color='blue')plt.title("Image Entropy Curve")plt.xlabel("Image filename value")plt.ylabel("Entropy")plt.grid(True)plt.xticks(rotation=45)plt.tight_layout()plt.savefig(save_path, dpi=300)plt.show()# 在序列图像中,提取图像熵最大的图像(若有多个最大值,则同时列出)
if __name__ == "__main__":folder = r"D:\py\BC\25052757812\1-01"show_image_entropy_curve(folder)# ✅ (对比度)最大熵值: 6.4644 → 1.0.tif# ✅ (亮度度)最大熵值: 6.4644 → -5.0.tif → 0.0.tif
(3)根据给定图像,自动模拟亮度+对比度组合,提取图像熵最大的图像 —— 将前两个功能合并
import os
import cv2
import numpy as np
import matplotlib.pyplot as pltdef enhance_image(img, brightness=0.0, contrast=1.0):"""使用线性变换增强图像:output = input × contrast + brightness"""img = img.astype(np.float32)enhanced = img * contrast + brightnessenhanced = np.clip(enhanced, 0, 255).astype(np.uint8)return enhanceddef compute_entropy(image):"""计算图像的熵值(衡量信息量)"""hist = cv2.calcHist([image], [0], None, [256], [0, 256])hist = hist.ravel() / hist.sum()hist = hist[hist > 0]entropy = -np.sum(hist * np.log2(hist))return entropydef find_best_brightness_contrast(image_path, brightness_range, contrast_range, save_dir):"""对单张图像进行亮度+对比度组合增强,计算每一张增强图像的熵值,找出熵值最大的组合,并输出最佳增强图像"""os.makedirs(save_dir, exist_ok=True)img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)if img is None:raise FileNotFoundError(f"❌ 无法读取图像: {image_path}")entropy_list = []label_list = []best_entropy = -1best_params = (0.0, 1.0)best_image = Nonefor b in brightness_range:for c in contrast_range:enhanced = enhance_image(img, brightness=b, contrast=c)entropy = compute_entropy(enhanced)label = f"{c:.1f}_at_{b:.1f}"entropy_list.append(entropy)label_list.append(label)if entropy > best_entropy:best_entropy = entropybest_params = (b, c)best_image = enhanced.copy()print(f"{label}.tif - 熵值: {entropy:.8f}")# 保存最优增强图像best_filename = f"best_{best_params[1]:.1f}_at_{best_params[0]:.1f}.tif"best_path = os.path.join(save_dir, best_filename)cv2.imwrite(best_path, best_image)print(f"\n✅ 最优组合:亮度={best_params[0]:.1f},对比度={best_params[1]:.1f},最大熵={best_entropy:.8f}")print(f"📌 最优图像已保存至: {best_path}")# # 绘制熵值曲线图# curve_path = os.path.join(save_dir, "entropy_curve.png")# plt.figure(figsize=(10, 5))# plt.plot(label_list, entropy_list, marker='o', linestyle='-', color='blue')# plt.title("Entropy Curve for Brightness+Contrast Variations")# plt.xlabel("contrast_at_brightness")# plt.ylabel("Entropy")# plt.xticks(rotation=60)# plt.grid(True)# plt.tight_layout()# plt.savefig(curve_path, dpi=300)# plt.show()# 绘制前后对比图plt.subplots(1, 2, figsize=(10, 5))plt.subplot(1, 2, 1), plt.imshow(img, cmap='gray', vmin=0, vmax=255), plt.title("Original Image"), plt.axis('off')plt.subplot(1, 2, 2), plt.imshow(best_image, cmap='gray', vmin=0, vmax=255), plt.title(f"Best Image\nBrightness={best_params[0]:.1f}, Contrast={best_params[1]:.1f}"), plt.axis('off')plt.tight_layout()plt.show()def find_best_sequentially(image_path, brightness_range, contrast_range, save_dir):"""分阶段寻找最优亮度与对比度:1. 在原图上逐个亮度值增强,选择熵值最高者;2. 在最优亮度图上,逐个对比度增强,选择熵值最高者;3. 返回最终增强图像并保存。"""os.makedirs(save_dir, exist_ok=True)img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)if img is None:raise FileNotFoundError(f"❌ 无法读取图像: {image_path}")# 阶段一:亮度优化max_entropy_brightness = -1best_brightness = 0.0img_after_brightness = Nonefor b in brightness_range:temp = enhance_image(img, brightness=b, contrast=1.0)entropy = compute_entropy(temp)print(f"[亮度阶段] brightness={b:.1f} → 熵值: {entropy:.8f}")if entropy > max_entropy_brightness:max_entropy_brightness = entropybest_brightness = bimg_after_brightness = temp.copy()# 阶段二:对比度优化(基于最优亮度图像)max_entropy_contrast = -1best_contrast = 1.0best_image = Nonefor c in contrast_range:temp = enhance_image(img_after_brightness, brightness=0.0, contrast=c)entropy = compute_entropy(temp)print(f"[对比度阶段] contrast={c:.1f} → 熵值: {entropy:.8f}")if entropy > max_entropy_contrast:max_entropy_contrast = entropybest_contrast = cbest_image = temp.copy()# 保存最优图像best_filename = f"best_seq_{best_contrast:.1f}_at_{best_brightness:.1f}.tif"best_path = os.path.join(save_dir, best_filename)cv2.imwrite(best_path, best_image)print(f"\n✅ 最优组合(分阶段):亮度(0.0)={best_brightness:.1f},对比度(1.0)={best_contrast:.1f}")print(f"📌 最终图像已保存至: {best_path}")# 可视化# cv2.imshow('image', img)# cv2.imshow("Best Sequential", best_image)# cv2.waitKey(0)# cv2.destroyAllWindows()# plt.figure(figsize=(10, 5))# plt.subplot(1, 2, 1)# plt.imshow(img, cmap='gray', vmin=0, vmax=255)# plt.title("Original Image")# plt.axis('off')# plt.subplot(1, 2, 2)# plt.imshow(best_image, cmap='gray', vmin=0, vmax=255)# plt.title(f"Best Sequential\nBrightness={best_brightness:.1f}, Contrast={best_contrast:.1f}")# plt.axis('off')# plt.tight_layout()# plt.show()# 可视化增强前后图像fig, axs = plt.subplots(2, 2, figsize=(12, 8))# 原图axs[0, 0].imshow(img, cmap='gray', vmin=0, vmax=255)axs[0, 0].set_title("Original Image")axs[0, 0].axis('off')# 最优增强图像axs[0, 1].imshow(best_image, cmap='gray', vmin=0, vmax=255)axs[0, 1].set_title(f"Best Sequential\nBrightness={best_brightness:.1f}, Contrast={best_contrast:.1f}")axs[0, 1].axis('off')# 亮度熵曲线brightness_entropy_curve = []for b in brightness_range:temp = enhance_image(img, brightness=b, contrast=1.0)entropy = compute_entropy(temp)brightness_entropy_curve.append(entropy)axs[1, 0].plot(brightness_range, brightness_entropy_curve, marker='o', color='orange')axs[1, 0].set_title("Entropy vs Brightness")axs[1, 0].set_xlabel("Brightness")axs[1, 0].set_ylabel("Entropy")axs[1, 0].grid(True)# 对比度熵曲线contrast_entropy_curve = []for c in contrast_range:temp = enhance_image(img_after_brightness, brightness=0.0, contrast=c)entropy = compute_entropy(temp)contrast_entropy_curve.append(entropy)axs[1, 1].plot(contrast_range, contrast_entropy_curve, marker='o', color='blue')axs[1, 1].set_title("Entropy vs Contrast")axs[1, 1].set_xlabel("Contrast")axs[1, 1].set_ylabel("Entropy")axs[1, 1].grid(True)plt.tight_layout()plt.show()# 根据给定图像,自动模拟最优亮度+对比度组合,最终输出适宜参数对应的图像
if __name__ == "__main__":image_path = r"D:\py\BC\25052757812\1-01\b_25.0_and_c_1.3.tif"save_dir = r"D:\py\BC\best_result"brightness_list = [round(b, 1) for b in np.arange(-100, 50.1, 10)]contrast_list = [round(c, 1) for c in np.arange(0.1, 2, 0.1)]find_best_sequentially(image_path, brightness_list, contrast_list, save_dir)# find_best_brightness_contrast(image_path, brightness_list, contrast_list, save_dir)"""熵值饱和现象:[亮度阶段] brightness=-100.0 → 熵值: 6.03479862[亮度阶段] brightness=-90.0 → 熵值: 6.21303177[亮度阶段] brightness=-80.0 → 熵值: 6.29660273[亮度阶段] brightness=-70.0 → 熵值: 6.34630442[亮度阶段] brightness=-60.0 → 熵值: 6.38321447[亮度阶段] brightness=-50.0 → 熵值: 6.39664936[亮度阶段] brightness=-40.0 → 熵值: 6.39753246[亮度阶段] brightness=-30.0 → 熵值: 6.39753246[亮度阶段] brightness=-20.0 → 熵值: 6.39753246[亮度阶段] brightness=-10.0 → 熵值: 6.39753246[亮度阶段] brightness=0.0 → 熵值: 6.39753246[亮度阶段] brightness=10.0 → 熵值: 6.25879717[亮度阶段] brightness=20.0 → 熵值: 6.08924246[亮度阶段] brightness=30.0 → 熵值: 5.83966589[亮度阶段] brightness=40.0 → 熵值: 5.61335611[亮度阶段] brightness=50.0 → 熵值: 5.31231403"""
三、熵值饱和 —— 存在多个最优值
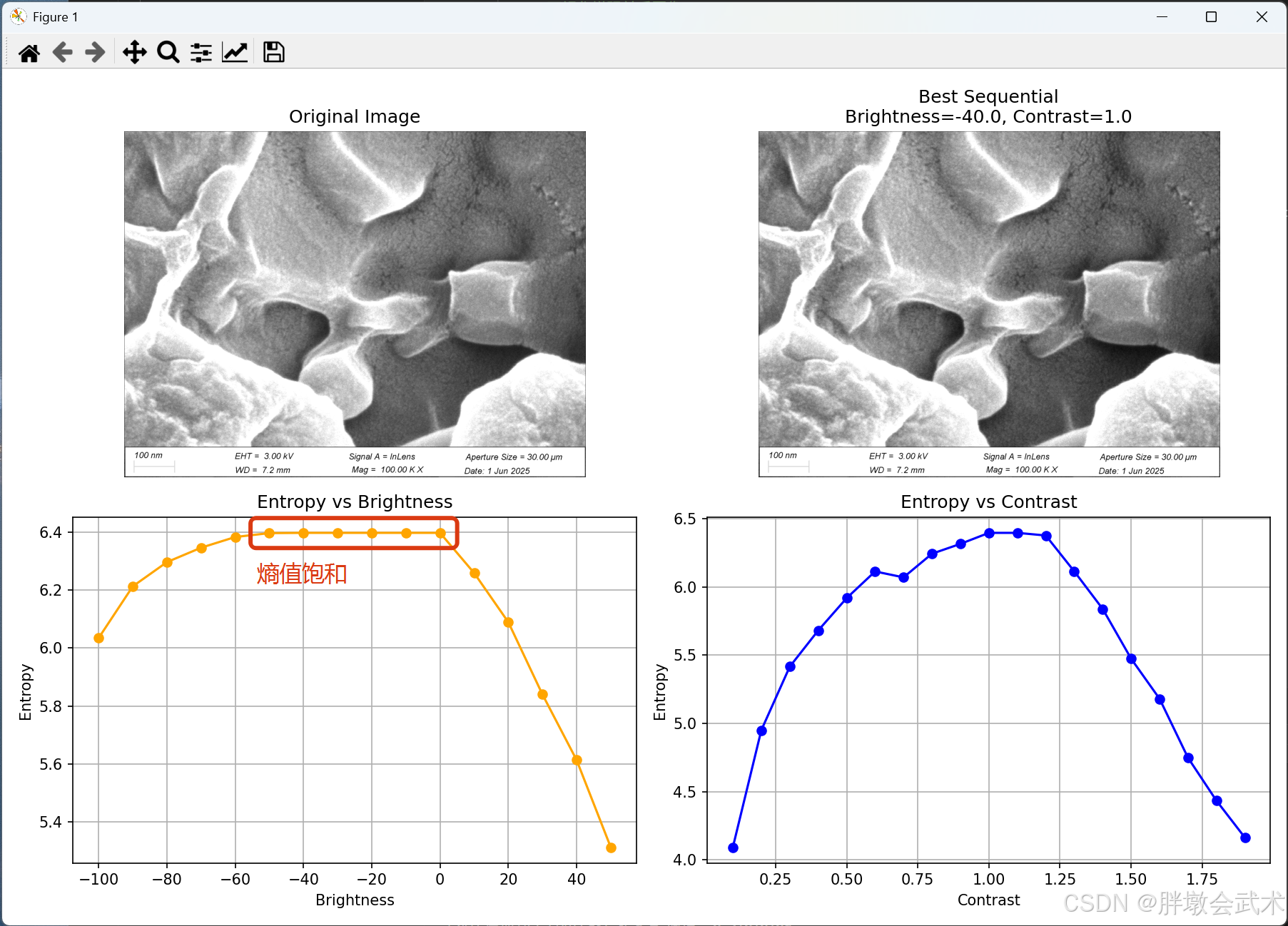
当对图像施加一系列亮度或对比度变换时,熵值通常具有如下变化趋势:
| 阶段 | 熵值行为 | 图像变化特征与分析 |
|---|---|---|
| 初始阶段 | 显著上升 | 图像增强改善了灰度分布,细节变得丰富,整体信息量增加。熵值对增强操作敏感。 |
| 过渡阶段 | 逐渐趋稳 | 图像逐步接近灰度均衡状态,信息冗余开始增加,熵值增长幅度减缓。 |
| 饱和阶段 | 进入平台期 | 图像熵值达到局部最大,多组参数组合产生相同(或近似)最大熵,熵值不再上升。此时图像可能已出现过曝或细节损失。 |
特征表现:
- 熵值随着增强强度增加,在某个范围后趋于饱和不变,即“熵值饱和”;
- 多个不同参数组合(如不同亮度或对比度)可能对应相同的最大熵;
- 此时图像视觉质量可能并未提升甚至下降,但熵值仍维持高位;
- 熵值曲线常表现为**“增长—平缓—平台”**的结构,平台区为关键判断区域。
例如:当 brightness = - 40.0 开始,熵值已达平台期。
"""熵值饱和现象:
[亮度阶段] brightness=-100.0 → 熵值: 6.03479862
[亮度阶段] brightness=-90.0 → 熵值: 6.21303177
[亮度阶段] brightness=-80.0 → 熵值: 6.29660273
[亮度阶段] brightness=-70.0 → 熵值: 6.34630442
[亮度阶段] brightness=-60.0 → 熵值: 6.38321447
[亮度阶段] brightness=-50.0 → 熵值: 6.39664936[亮度阶段] brightness=-40.0 → 熵值: 6.39753246
[亮度阶段] brightness=-30.0 → 熵值: 6.39753246
[亮度阶段] brightness=-20.0 → 熵值: 6.39753246
[亮度阶段] brightness=-10.0 → 熵值: 6.39753246
[亮度阶段] brightness=0.0 → 熵值: 6.39753246[亮度阶段] brightness=10.0 → 熵值: 6.25879717
[亮度阶段] brightness=20.0 → 熵值: 6.08924246
[亮度阶段] brightness=30.0 → 熵值: 5.83966589
[亮度阶段] brightness=40.0 → 熵值: 5.61335611
[亮度阶段] brightness=50.0 → 熵值: 5.31231403
"""
(1)为什么会出现熵值饱和?
- 数学原因:熵的本质是灰度分布的“均匀度”,不是图像结构的好坏;
- 图像本质:熵不能识别纹理、边缘、清晰度,仅统计灰度直方图;
- 在图像过度增强(亮度过亮、对比度过大)时,熵可能“虚高”,称为伪信息上升;
- 此时虽然熵高,但信息质量低,表现为“信息泛滥、结构丢失”。
| 原因类别 | 说明 |
|---|---|
| 灰度分布已饱和 | 图像经过增强后灰度直方图已近似均匀,信息增量趋于0 |
| 噪声主导 | 当细节放大到一定程度后,熵值更多由噪声贡献,失去了评价意义 |
| 熵函数特性 | 熵是统计平均指标,非局部敏感,不能细分纹理结构或形状变化 |
| 图像对比度极限 | OpenCV图像灰度范围为[0,255],增强超限后像素值截断、饱和,导致图像内容变得“平整” |
(2)如何应对熵值饱和现象?
在图像增强任务中,熵值虽是一个良好的全局评价指标,但并非万能。推荐如下做法:
- 多指标融合判断:
熵值:衡量信息量;灰度标准差:衡量对比度;局部方差或梯度均值:衡量局部细节清晰度;SNR/BRISQUE等图像质量评价指标。- 设置 " 首次最大值 " 策略:一旦熵值达到历史最大并进入平台段,可提前停止增强或使用其他指标继续判断;















--(六)--loss)



