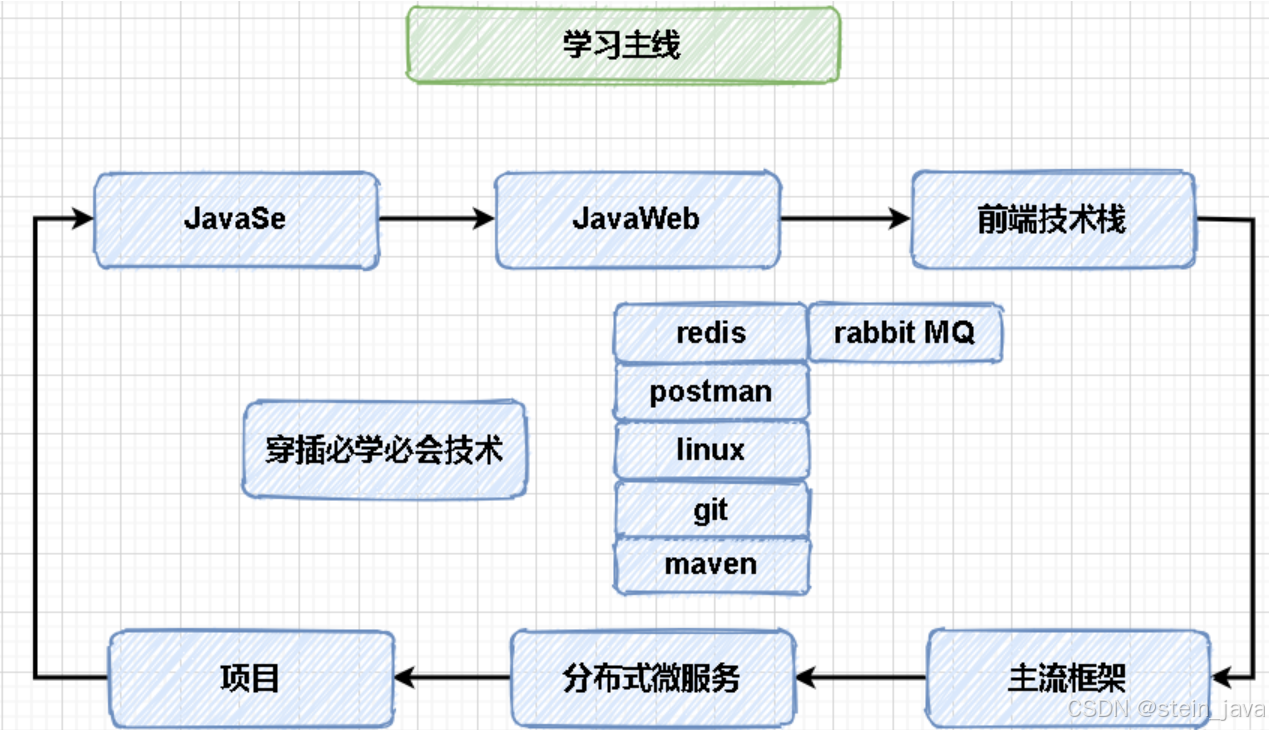
学习主线
必学必会属于优化的东西。
快速入门需求说明
要求:开发一个MyBatis项目,通过MyBatis的方式可以完成对monster表的crud操作
1.创建mybatis数据库-monster表
主键Primary Key默认非空Not null,就省略了
create database `mybatis`
use `mybatis`
create table `monster`(
`id` int AUTO_INCREMENT primary KEY,
`age` int not null,
`birthday` date default null,
`email` varchar(255) not null,
`gender` tinyint not null,
`name` varchar(255) not null,
`salary` double not null
)charset=utf82.创建Maven项目,方便项目需要jar包管理
父项目的配置
用父项目来管理子项目
我的IDEA版本:IntelliJ IDEA 2024.3.5
1)创建Maven项目,注意Archetype最好的quickstart类型,图片中这个目前也能用,毕竟src要删除
2)删除src目录
- 把mybatis的src目删除
- 将mybatis当做父项目/工程
- 创建新的Module作为子项目
- 这样子项目可以使用父项目的pom.xml引入
3)pom.xml导入依赖
框架的本质就是一些jar包,包含了一些.class文件
<!--加入依赖--><dependencies><!--mysql依赖--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.26</version><!--<version>5.1.49</version>演示用的旧版本--></dependency><!--mybatis依赖--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.7</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><!--scope作用域test,限定只能在test目录下生效--><scope>test</scope></dependency></dependencies>子项目的配置
1.选中父项目`mybatis`,右键点击新建,选择模块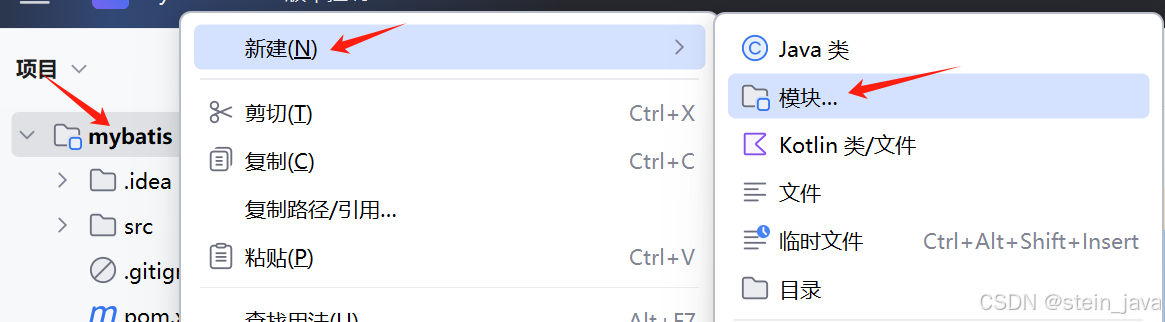
2.选择Maven,输入名称,注意检查这儿的父项,是不是我们刚刚点击右键那个父项目,下面选quickstart
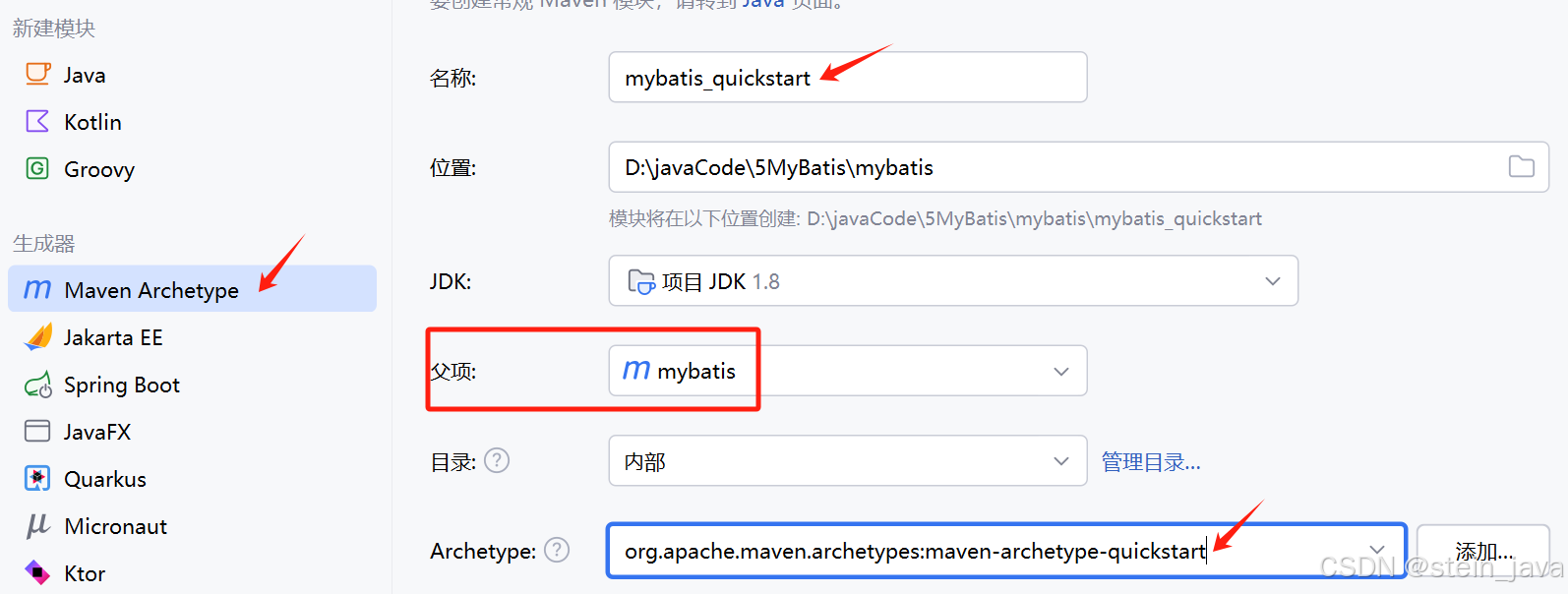
然后便可以看到新建的子项目

3.配置pom.xml
解读:
1.将mybatis作为父顶目管理多个子模块/子项目
2.父顶目的完整的坐标groupId【组织名】+artifactId【项目名】
3.后面该父顶目会管理多个子模块/子项目,将来父项目中的引入的依赖可以直接给子项目用, 这样开发简单,提高复用性,也便于管理
4.<packaging>pom<packaging>表示父项目以多个子模块/子项目管理工程
<groupId>com.stein</groupId><artifactId>mybatis</artifactId><version>1.0-SNAPSHOT</version><packaging>pom</packaging><!--解读:modules指定管理的哪些子模块--><modules><module>mybatis_quickstart</module></modules><!--加入依赖--><dependencies><!--mysql依赖--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.26</version><!--<version>5.1.49</version>演示用的旧版本--></dependency><!--mybatis依赖--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.7</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><!--scope作用域test,限定只能在test目录下生效--><scope>test</scope></dependency></dependencies>deepseek:关于<packaging>pom</packaging>作用的问题
<packaging>pom</packaging>,它表示该项目本身不会生成任何实质性的构件(如 JAR 包、WAR 包等),而是作为一个“项目对象模型(POM)容器”或“聚合器”。
packaging=pom其实承担了双重角色:既作为聚合模块的标记(module标签的容器),又作为继承关系的源头(parent标签的指向对象)。
需要强调只有packaging=pom的项目才能同时包含modules和dependencyManagement等特殊配置段,普通jar项目是不允许的——这是Maven的强制约定。
它主要包含一个
<modules>列表,列出了它管理的所有子模块(子项目)的目录名或相对路径。
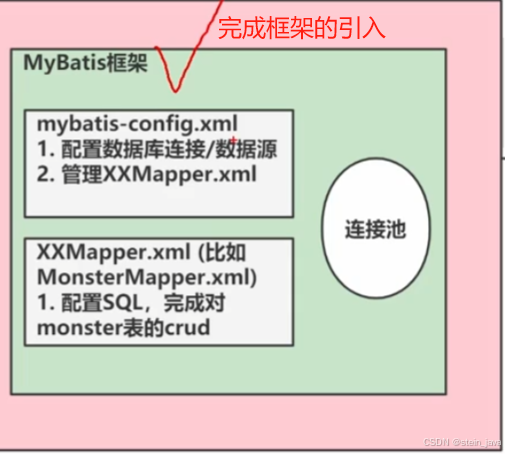
4.配置mybatis-config.xml——核心组件
这个资源文件的存放位置有要求,放到对应子项目src中
1)新建resources文件夹。 我们的maven子项目,没有resources文件夹,需要自己创建一个。
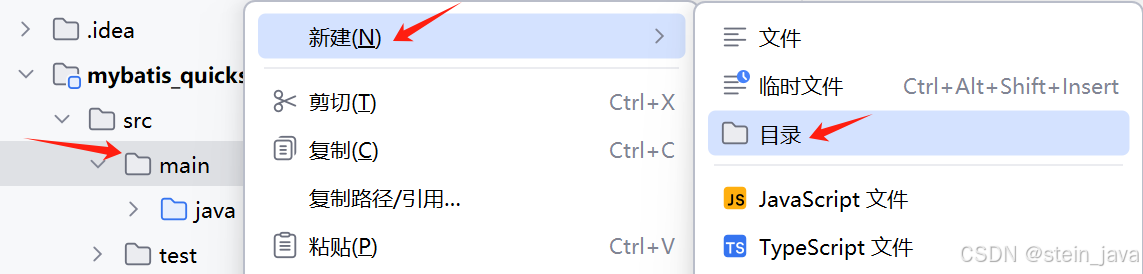
选择下面已有的resources即可
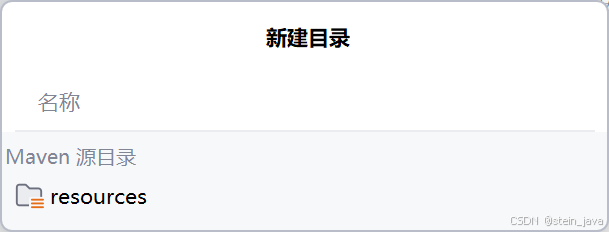
2)创建src/main/resources/mybatis-config.xml。文件名是可以自定义的
配置文件的内容,不用背,可以参考文档:入门_MyBatis中文网
官方模版:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><environments default="development"><environment id="development"><transactionManager type="JDBC"/><dataSource type="POOLED"><property name="driver" value="${driver}"/><property name="url" value="${url}"/><property name="username" value="${username}"/><property name="password" value="${password}"/></dataSource></environment></environments><mappers><mapper resource="org/mybatis/example/BlogMapper.xml"/></mappers>
</configuration>内容解读:
注意 XML 头部的声明,它用来验证 XML 文档的正确性。environment 元素体中包含了事务管理和连接池的配置。mappers 元素则包含了一组映射器(mapper),这些映射器的 XML 映射文件包含了 SQL 代码和映射定义信息。
<configuration><environments default="development"><environment id="development"><!--配置事务管理器--><transactionManager type="JDBC"/><!--配置数据源--><dataSource type="POOLED"><!--默认引用的外部文件--><!--<property name="driver" value="${driver}"/>--><!--<property name="url" value="${url}"/>--><!--<property name="username" value="${username}"/>--><!--<property name="password" value="${password}"/>--><!--配置驱动,这儿简化,直接写入--><property name="driver" value="com.mysql.jdbc.Driver"/><!-- 配置连接mysql的url"jdbc:mysql:"是协议;mysql是其中的子协议,用于选择连接到数据库的具体驱动程序localhost:3306,是要连接的数据库的ip地址和端口;127.0.0.1:3306这样写也可以mybatis,是要连接的数据库名称useSSL=true,使用安全连接,Secure Sockets Layer安全套接字协议;默认是不使用的,需要手动设置& ,实体引用,表示&字符,防止解析错误useUnicode=true,表示使用unicode字符集,防止乱码产生。这是基础字符集声明,但不指定具体编码方式。characterEncoding=utf-8,明确指定Unicode字符的具体编码格式为UTF-8(而非UTF-16等)不用背,下次直接引用--><property name="url" value="jdbc:mysql://localhost:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=utf-8"/><!--输入你自己的用户名和密码--><property name="username" value="root"/><property name="password" value="root"/><!--解决jdbc8.0驱动报错的配置--><property name="driver" value="com.mysql.cj.jdbc.Driver"/></dataSource></environment></environments><!--后面完善--><!--<mappers>--><!-- <mapper resource="org/mybatis/example/BlogMapper.xml"/>--><!--</mappers>-->
</configuration>
5.创建src/main/java/com/stein/entity/Monster.java
//1.一个普通的Pojo类
//2.使用原生态的sgl语句查询结果还是要封装成对象
//3.要求大家这里的实体类属性名和表名宇段保特一致。
public class Monster {private Integer id;private Integer age;private Date birthday;private String email;private Byte gender;//测试一下行不行,不行就换回Integerprivate String name;private Double salary;
}构造器,getter and setter...6.配置Mapper.xml
通过java接口,在xml文件进行实现implement,完成对mysql语句的映射
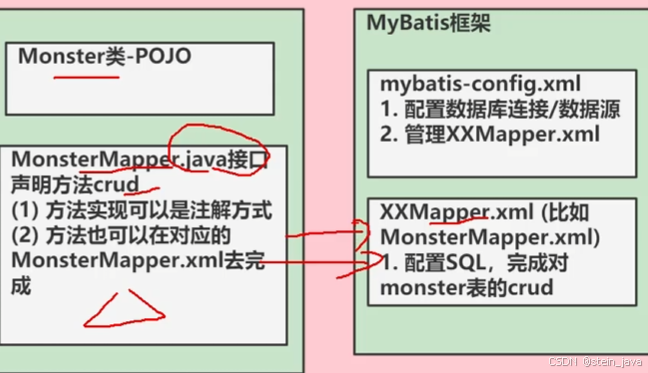
1)创建接口com/stein/mapper/MonsterMapper.java
2)创建文件com/stein/mapper/MonsterMapper.xml
下面是格式模版,探究已映射的 SQL 语句
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.mybatis.example.BlogMapper"><select id="selectBlog" resultType="Blog">select * from Blog where id = #{id}</select>
</mapper>接下来将修改为自己的配置文件
7.将Mapper.xml文件交给mybatis-config.xml文件管理
完善mybatis-config.xml
<!--现在完善--><!--1.这里我门配置需要关联Mapper.xml--><!--2.这里我们可以通过菜单Path from source root--><!--注意分隔符是/,因为你可以去文件直接复制来自源根的路径(Path From Source Root)--><mappers><mapper resource="com/stein/mapper/MonsterMapper.xml"/></mappers>复制文件根路径的方法:
1)英文版
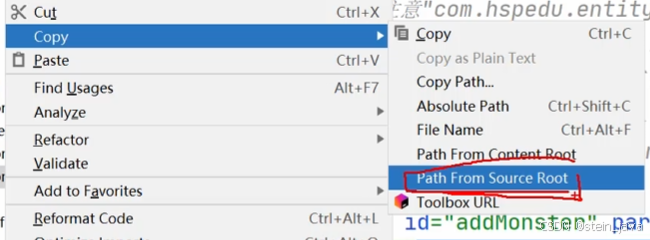
2)中文版

Java代码操作DB
1.增加/插入
将下图中的第2、3步组合,写一个工具类

1. 创建com/stein/util/MybatisUtils.java
/*** 工具类,可以得到SqlSession*/
public class MybatisUtils {private static SqlSessionFactory sqlSessionfactory;//编写静态代码,初始化sqlSessionFactorystatic{try {String resource = "mybatis-config.xml";//SqlSessionFactoryBuilder ,SqlSessionFactory, SqlSession的获得顺序//获取到配置文件mybatis-config.xml对应的inputStream//说明:加载文件时,默认到resources目录=>运行后的工作目录classesInputStream resourceAsStream = Resources.getResourceAsStream(resource);//无法从 static 上下文引用非 static 字段怎么解决的?也用static?确实sqlSessionfactory = new SqlSessionFactoryBuilder().build(resourceAsStream);} catch (IOException e) {throw new RuntimeException(e);}}//编写方法,返回SqlSessionpublic static SqlSession getSqlSession(){return sqlSessionfactory.openSession();}
}-
Builder->Factory->Session清晰地划分了这三个不同生命周期的阶段。
总结:
SqlSessionFactoryBuilder的存在是为了:
隔离复杂性: 将重量级、一次性的配置解析和初始化逻辑从
SqlSessionFactory中剥离出来。明确职责: 让
SqlSessionFactoryBuilder专注于构建,让SqlSessionFactory专注于提供会话。灵活配置: 支持多种配置来源的加载方式。
管理资源: 负责构建过程中临时资源(如文件流)的正确开闭。
清晰生命周期: 标识出构建过程 (
Builder) 是一个短暂的、一次性的阶段,与长生命周期的工厂 (Factory) 和短生命周期的会话 (Session) 区分开。遵循设计原则: 更好地实践了单一职责原则和建造者模式,提高代码的可读性、可维护性和灵活性。
2.创建com/stein/MonsterMapperTest.java
public class MonsterMapperTest {private SqlSession sqlSession;private MonsterMapper monsterMapper;//在每一个@Test方法执行前都执行一次,获取一次sqlSession@Beforepublic void init(){sqlSession= MybatisUtils.getSqlSession();//获取到MonsterMapper对象?实际是代理对象 class com.sun.proxy.$Proxy9//底层是使用了动态代理机制MonsterMapper mapper = sqlSession.getMapper(MonsterMapper.class);System.out.println("mapper的运行类型是:"+mapper.getClass());}@Testpublic void test01(){System.out.println("方法f1()已调用");}@Testpublic void test02(){System.out.println("方法f2()已调用");}
}代码报错:
Caused by: java.io.IOException: Could not find resource com/stein/mapper/MonsterMapper.xml
原因是这个xml文件不会自动生成到TargetClasses目录下,导致找不到该文件,可以通过pom.xml文件进行设置生成。注意设置在父工程的pom.xml文件里,这样每个子工程都可以统一。
3.完善pom.xml
<build><resources><resource><directory>src/main/java</directory><includes><include>**/*.xml</include></includes></resource><resource><directory>src/main/resources</directory><includes><include>**/*.xml</include><include>**/*.properties</include></includes></resource></resources></build>
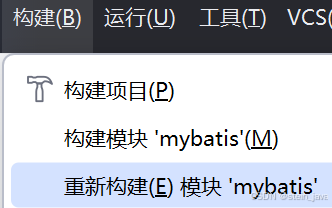
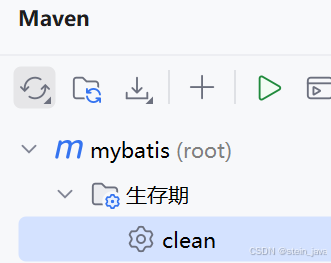
刷新列表的三种方法:
1)然后在 Build/构建 选择-> rebuild project/重新构建模块 进行重构。
2)或者在maven里面clean
3)实在不行,就来回切换一下maven目录吧
快速入门-代码实现
1.增加/插入-insert
1.添加com/stein/MonsterMapperTest.java
public class MonsterMapperTest {private SqlSession sqlSession;private MonsterMapper monsterMapper;//在每一个@Test方法执行前都执行一次,获取一次sqlSession@Beforepublic void init(){sqlSession= MybatisUtils.getSqlSession();//获取到MonsterMapper对象?实际是代理对象 class com.sun.proxy.$Proxy9//底层是使用了动态代理机制monsterMapper = sqlSession.getMapper(MonsterMapper.class);System.out.println("monsterMapper的运行类型是:"+monsterMapper.getClass());}@Testpublic void test01(){System.out.println("方法f1()已调用");}@Testpublic void test02(){System.out.println("方法f2()已调用");}@Testpublic void insertMonster(){for (int i = 0; i < 2; i++) {Monster monster = new Monster();monster.setAge(10+i);//设置为当前时间monster.setBirthday(new Date());monster.setEmail("94595892@qq.com");monster.setGender((byte) (i/2));monster.setSalary(5000d+i*1000);monster.setName("大象精No."+i);//monsterMapper.insertMonster(monster);//返回自动生成的主键值//System.out.println("monsterId="+monster.getId());}if (sqlSession != null) {//如果是增删改的操作,需要提交,才能生效sqlSession.commit();System.out.println("添加monster操作成功");//是将连接放回连接池,不是真的关闭sqlSession.close();}}
运行报错:
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
解决办法:
原因是jdbc8.0的驱动类名,由com.mysql.jdbc.Driver改成了com.mysql.cj.jdbc.Driver
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
2.关于返回主键的设置。MonsterMapper.xml
useGeneratedKeys 使用DB生成的主键,设置成true
keyProperty 设置成对应的字段名
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--解读
它的核心作用是将 XML 映射文件与 Mapper 接口进行绑定
-->
<mapper namespace="com.stein.mapper.MonsterMapper"><!--配置insertMonster1.id="insertMonster",就是要实现的接口的方法名2.parameterType="com.stein.entity.Monster",参数类型,表示实现方法的入参/形参的类型,3.名称唯一的时候(仅java类库),可以不使用全限定名,但还是建议使用全限定名。自定义的类型要简写,需要配置类别名TypeAliases4.要写入的sql语句,现在sql里面测试一下,再复制进来5.(`age`,`birthday`,`email`,`gender`,`name`,`salary`)表的字段6.(#{age},#{birthday},#{email},#{gender},#{name},#{salary})是传入monster对象属性名7.这里#{age} 对应monster.age对象的属性名,其它一样--><insert id="insertMonster" parameterType="com.stein.entity.Monster" useGeneratedKeys="true" keyProperty="id"><!--<insert id="insertMonster" parameterType="Monster">要报错-->INSERT INTO `monster`(`age`,`birthday`,`email`,`gender`,`name`,`salary`)--values(#{age},#{birthday},#{email},#{gender},#{name},#{salary})</insert>3.添加显示返回值,MonsterMapperTest.insertMonster()
monsterMapper.insertMonster(monster);//返回自动生成的主键值System.out.println("monsterId="+monster.getId());成功显示
monsterId=8
monsterId=9
添加monster操作成功
2.删除-delete
1.接口中添加方法,MonsterMapper.java
//根据id删除monstervoid delMonster(Integer monsterId);2.配置/实现方法,MonsterMapper.xml
<!--parameterType表示参数类型,当它是Java类库时,可以省略,比如java.lang.Integer省略为Integer.下面这两句居然也行delete from monster where id=#{monsterId}delete from monster where id=#{xyz}--><delete id="delMonster" parameterType="Integer">delete from monster where id=#{id}</delete>这儿测试了一下,发现Mybatis的容错率高得吓人。我把语句写成了如下两种,跟实际形参名称完全不一致,都能通过测试,原因估计是参数唯一。但是不建议。
delete from monster where id=#{monsterId}
delete from monster where id=#{xyz}
然后删除了配置里面的parameterType="Integer",依然可以正常运行。
3.测试代码。com/stein/MonsterMapperTest.java
@Testpublic void delMonster(){monsterMapper.delMonster(7);if (sqlSession != null) {//如果是增删改的操作,需要提交,才能生效sqlSession.commit();System.out.println("删除monsterId=7的操作成功");//是将连接放回连接池,不是真的关闭sqlSession.close();}}正确删除了对应的行。
3.修改-update
1.MonsterMapper.java添加接口方法
//修改monstervoid updateMonster(Monster monster);2.MonsterMapper.xml配置/实现接口方法
<!--还是先在DB测试好语句再复制进来用--><update id="updateMonster" parameterType="com.stein.entity.Monster">update monsterset `age`=#{age},`birthday`=#{birthday},`email`=#{email},`gender`=#{gender},`name`=#{name},`salary`=#{salary}where `id`=#{id}</update>3.测试代码。com/stein/MonsterMapperTest.java
@Testpublic void updateMonster(){Monster monster = new Monster();monster.setAge(60);//设置为当前时间monster.setBirthday(new Date());monster.setEmail("94595892@qq.com");monster.setGender((byte)0);monster.setSalary(8000d);monster.setName("小鸡仔");monster.setId(9);monsterMapper.updateMonster(monster);if (sqlSession != null) {//如果是增删改的操作,需要提交,才能生效sqlSession.commit();System.out.println("修改Monster的操作成功");//是将连接放回连接池,不是真的关闭sqlSession.close();}}成功修改
4.查询
1.MonsterMapper.java添加接口方法
1)情况1:返回一个Monster结果
//通过id查询monsterMonster selectMonsterById(Integer monsterId);2)情况2:返回集合
//查询返回所有是一个集合List<Monster> selectAllMonster();插入知识点:
类型别名的配置:类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写。
src/main/resources/mybatis-config.xml在这个配置文件里面设置
<configuration><!--放在配置的靠前的位置--><typeAliases><typeAlias type="com.stein.entity.Monster" alias="Monster" /></typeAliases>...</configuration>2.MonsterMapper.xml配置/实现接口方法
没有配置参数类型,自动配置了
1)返回一个
<select id="selectMonsterById" resultType="Monster">select * from `monster` where id=#{id}</select>2)如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身的类型。
<!--注意,返回的结果是一个集合,但是返回类型依然要写集合所包含的类型Monster,而不是集合本身的类型List--><select id="selectAllMonster" resultType="Monster">select * from `monster`</select>3.测试代码。com/stein/MonsterMapperTest.java
1)返回一个
@Testpublic void selectMonsterById(){Monster monster = monsterMapper.selectMonsterById(9);System.out.println("monster="+monster);if (sqlSession != null) {//这儿是查询,不是增删改的操作,就不需要提交了//sqlSession.commit();System.out.println("查询Monster的操作成功");//是将连接放回连接池,不是真的关闭sqlSession.close();}}2)返回集合
@Testpublic void selectAllMonster(){List<Monster> monsters = monsterMapper.selectAllMonster();for (Monster monster : monsters) {System.out.println("monster="+monster);}if (sqlSession != null) {//这儿是查询,不是增删改的操作,就不需要提交了//sqlSession.commit();System.out.println("查询所有Monsters的操作成功");//是将连接放回连接池,不是真的关闭sqlSession.close();}}测试结果成功
日志输出-查看SQL
看一个需求:
1.在开发MyBatis程序时,比如执行测试方法,程序员往往需要查看程序底层发给MySQL的SQL语句,到底长什么样,怎么办?
2.解决方案:日志输出
具体操作:
1.查看文档。配置 -> 设置 -> 设置名

2.配置文件src/main/resources/mybatis-config.xml
参考文档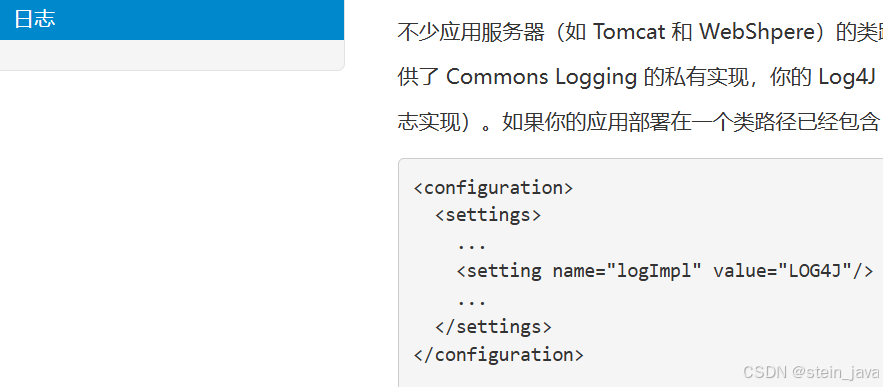
配置自己的文件:
<configuration><!--要放在前面,对位置有要求,否则报红--><settings><setting name="logImpl" value="STDOUT_LOGGING"/></settings>...</configuration>3.测试之前代码,可以看到具体SQL语句,便于调试

课后练习
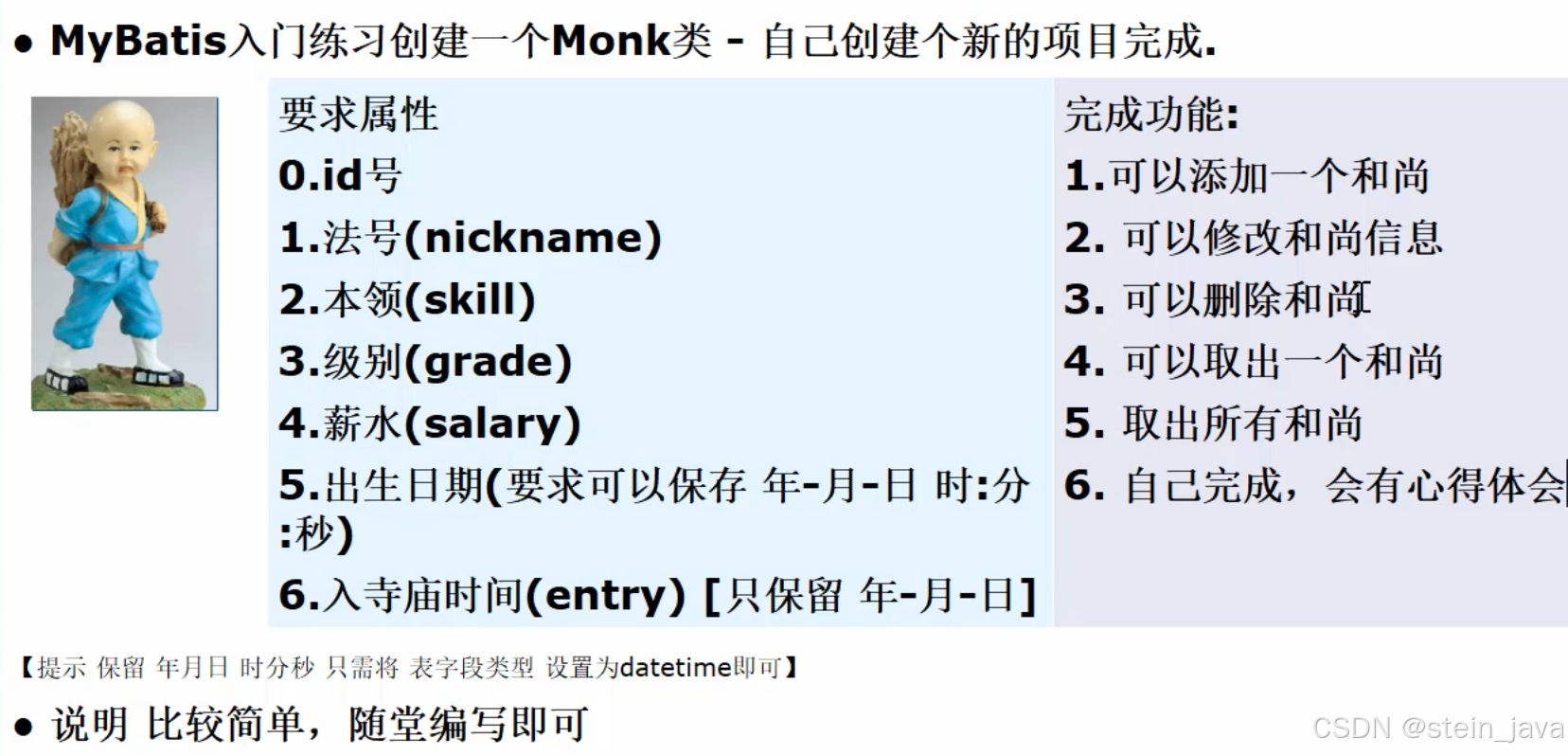
1.先创建数据库表格
2.再配置Mybatis










)




)



