文章目录
- 前言
- 一、案例
- 二、破解流程
- 1.原理
- 2.找到woff文件
- 3.分析woff文件
- 4.代码实现
- 1.转化woff文件
- 2.绘图并ocr识别
- 3.映射数据
- 三、总结
前言
有时我们在进行网页抓取采集数据时,有些重要的数据比如说价格,数量等信息会进行加密,通过复制或者简单的采集是无法采集到编码后的文字内容的,现在貌似有不少网站都有采用这种反爬机制,作为爬虫工程师,还是要了解甚至掌握这个技巧的。
一、案例

在某网站商品价格展示,打开F12 ,数字和符号是做了替换,显示为ȜŽŏŏŕŏŏ,所以如果我们想获取所看到的价格就要花些功夫。
二、破解流程
1.原理
其实这就是CSS反爬,CSS字体反爬是一种通过使用自定义字体和字符映射来保护页面内容的技术。在这类技术中,网页上的文本并非直接展示为标准字符,而是通过特殊设计的字体显示。这样,即使爬虫抓取到页面源代码,获得的却是字体文件的引用,而不是实际的字符内容。
通常,这些字体文件是通过 JavaScript 动态加载的,而且在字体文件中,每个字符与其对应的可视形态之间存在一个映射关系。只有浏览器能够正确渲染这些映射,爬虫则无法直接读取到有效的文本内容,需要我们间接获取解析处理。
2.找到woff文件
第一种方法,通过标签class的属性值,例如上图中class值:fontf04dfc98 全局搜索:

第二种方法:也是全局搜索font-face,也是同样的效果
3.分析woff文件
把上图带有woff字样的链接下载到本地,使用FontEditor打开woff文件,链接地址:https://font.qqe2.com/index.html?src=www.jspoo.com

发现这上面的字符串跟网页的ȜŽŏŏŕŏŏ不一样,那我们尝试点击预览按钮,切换eot字体如下图:

会弹出另一个窗口,两个窗口内容进行比较

我们是不是已经发现了网页的不规范数字1对应Ȝ,这是不是就对应上了,接下来就是代码实现这个流程的问题
4.代码实现
1.转化woff文件
from fontTools.ttLib import TTFont
font = TTFont('tansoole.woff')
font.saveXML('tansoole.xml')
运行代码并打开部分标签,如图:
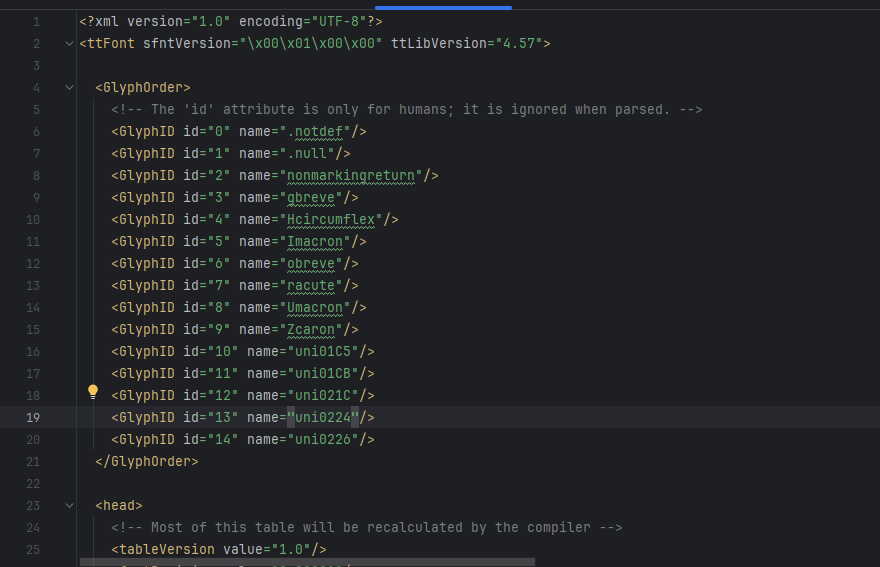
# 可以转化获取name值def extract_font_data_from_woff(woff_file_path):font = TTFont(woff_file_path)cmap = font.getBestCmap()code_to_name = {}for code, name in cmap.items():code_to_name[code] = namereturn code_to_namewoff_file_path = 'tansoole.woff'unicode_mapping = extract_font_data_from_woff(woff_file_path)print(unicode_mapping)#打印信息# {0: '.null', 29: '.null', 287: 'gbreve', 292: 'Hcircumflex', 298: 'Imacron', 335: 'obreve', 341: 'racute', 362: 'Umacron', 381: 'Zcaron', 453: 'uni01C5', 459: 'uni01CB', 540: 'uni021C', 548: 'uni0224', 550: 'uni0226'}# 转化对应eot对应关系
Mapping_tables = {}
for code, mapping in unicode_mapping.items():character_key = chr(code)character_value = mappingMapping_tables[character_key] = character_value
print(Mapping_tables)
# 打印信息
# {'\x00': '.null', '\x1d': '.null', 'ğ': 'gbreve', 'Ĥ': 'Hcircumflex', 'Ī': 'Imacron', 'ŏ': 'obreve', 'ŕ': 'racute', 'Ū': 'Umacron', 'Ž': 'Zcaron', 'Dž': 'uni01C5', 'Nj': 'uni01CB', 'Ȝ': 'uni021C', 'Ȥ': 'uni0224', 'Ȧ': 'uni0226'}2.绘图并ocr识别
import os
import timeimport ddddocrfrom fontTools.ttLib.ttFont import TTFont
from fontTools.pens.svgPathPen import SVGPathPen
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.path import Path
import matplotlib._color_data as mcddef ttf_to_char(font_file, glyph_set_name=None, temp_png_path="./"):# %matplotlib inline# 加载字体font = TTFont(font_file)# 7.1 生成PNG图片# 7.1.1 第一步提取绘制命令语句# 获取包含字形名称和字形对象的--字形集对象glyphsetglyphset = font.getGlyphSet()# print(glyphset.keys())# 获取pen的基类pen = SVGPathPen(glyphset)# 查找"马"的字形对象glyph = glyphset[glyph_set_name]# 绘制"马"的字形对象glyph.draw(pen)# 提取"马"的绘制语句commands = pen._commands# print(commands)total_commands = []command = []for i in commands:# 每一个命令语句if i == 'Z':# 以闭合路径指令Z区分不同轮廓线command.append(i)total_commands.append(command)command = []else:command.append(i)# 从'head'表中提取所有字形的边界框xMin = font['head'].xMinyMin = font['head'].yMinxMax = font['head'].xMaxyMax = font['head'].yMax# print("所有字形的边界框: xMin = {}, xMax = {}, yMin = {}, yMax = {}".format(xMin, xMax, yMin, yMax))# 所有字形的边界框: xMin = -12, xMax = 264, yMin = -47, yMax = 220preX = 0.0preY = 0.0# 笔的起始位置startX = 0.0startY = 0.0# 所有轮廓点total_verts = []# 所有指令total_codes = []# 转换命令for i in total_commands:# 每一条轮廓线verts = []codes = []for command in i:# 每一条轮廓线中的每一个命令code = command[0] # 第一个字符是指令vert = command[1:].split(' ') # 其余字符是坐标点,以空格分隔# M = 路径起始 - 参数 - 起始点坐标 (x y)+if code == 'M':codes.append(Path.MOVETO) # 转换指令verts.append((float(vert[0]), float(vert[1]))) # 提取x和y坐标# 保存笔的起始位置startX = float(vert[0])startY = float(vert[1])# 保存笔的当前位置(由于是起笔,所以当前位置就是起始位置)preX = float(vert[0])preY = float(vert[1])# Q = 绘制二次贝塞尔曲线 - 参数 - 曲线控制点和终点坐标(x1 y1 x y)+elif code == 'Q':codes.append(Path.CURVE3) # 转换指令verts.append((float(vert[0]), float(vert[1]))) # 提取曲线控制点坐标codes.append(Path.CURVE3) # 转换指令verts.append((float(vert[2]), float(vert[3]))) # 提取曲线终点坐标# 保存笔的当前位置--曲线终点坐标x和ypreX = float(vert[2])preY = float(vert[3])# C = 绘制三次贝塞尔曲线 - 参数 - 曲线控制点1,控制点2和终点坐标(x1 y1 x2 y2 x y)+elif code == 'C':codes.append(Path.CURVE4) # 转换指令verts.append((float(vert[0]), float(vert[1]))) # 提取曲线控制点1坐标codes.append(Path.CURVE4) # 转换指令verts.append((float(vert[2]), float(vert[3]))) # 提取曲线控制点2坐标codes.append(Path.CURVE4) # 转换指令verts.append((float(vert[4]), float(vert[5]))) # 提取曲线终点坐标# 保存笔的当前位置--曲线终点坐标x和ypreX = float(vert[4])preY = float(vert[5])# L = 绘制直线 - 参数 - 直线终点(x, y)+elif code == 'L':codes.append(Path.LINETO) # 转换指令verts.append((float(vert[0]), float(vert[1]))) # 提取直线终点坐标# 保存笔的当前位置--直线终点坐标x和ypreX = float(vert[0])preY = float(vert[1])# V = 绘制垂直线 - 参数 - 直线y坐标 (y)+elif code == 'V':# 由于是垂直线,x坐标不变,提取y坐标x = preXy = float(vert[0])codes.append(Path.LINETO) # 转换指令verts.append((x, y)) # 提取直线终点坐标# 保存笔的当前位置--直线终点坐标x和ypreX = xpreY = y# H = 绘制水平线 - 参数 - 直线x坐标 (x)+elif code == 'H':# 由于是水平线,y坐标不变,提取x坐标x = float(vert[0])y = preYcodes.append(Path.LINETO) # 转换指令verts.append((x, y)) # 提取直线终点坐标# 保存笔的当前位置--直线终点坐标x和ypreX = xpreY = y# Z = 路径结束,无参数elif code == 'Z':codes.append(Path.CLOSEPOLY) # 转换指令verts.append((startX, startY)) # 终点坐标就是路径起点坐标# 保存笔的当前位置--起点坐标x和ypreX = startXpreY = startY# 有一些语句指令为空,当作直线处理else:codes.append(Path.LINETO) # 转换指令verts.append((float(vert[0]), float(vert[1]))) # 提取直线终点坐标# 保存笔的当前位置--直线终点坐标x和ypreX = float(vert[0])preY = float(vert[1])# 整合所有指令和坐标total_verts.append(verts)total_codes.append(codes)color_list = list(mcd.CSS4_COLORS)# 获取所有的轮廓坐标点total_x = []total_y = []for contour in total_verts:# 每一条轮廓曲线x = []y = []for i in contour:# 轮廓线上每一个点的坐标(x,y)x.append(i[0])y.append(i[1])total_x.append(x)total_y.append(y)if total_x == [[186.0, 186.0, 391.0, 391.0, 186.0]]:return '.'if total_x == [[0.0, 425.0, 569.0, 145.0, 0.0]]:return '/'# 创建画布窗口fig, ax = plt.subplots()# 按照'head'表中所有字形的边界框设定x和y轴上下限ax.set_xlim(xMin, xMax)ax.set_ylim(yMin, yMax)# 设置画布1:1显示ax.set_aspect(1)# 添加网格线# ax.grid(alpha=0.8,linestyle='--')# 画图# print(f"{glyph_set_name}======绘制图片=======")for i in range(len(total_codes)):# (1)绘制轮廓线# 定义路径path = Path(total_verts[i], total_codes[i])# 创建形状,无填充,边缘线颜色为color_list中的颜色,边缘线宽度为2patch = patches.PathPatch(path, facecolor='none', edgecolor=color_list[i + 10], lw=2)# 将形状添到图中ax.add_patch(patch)# (2)绘制轮廓点--黑色,点大小为10# ax.scatter(total_x[i], total_y[i], color='black',s=10)# 保存图片temp_path = f"{temp_png_path}/temp{int(time.time()*100000)}.png"plt.savefig(temp_path)plt.close()# print(f"{glyph_set_name}======保存图片=======")with open(temp_path, "rb") as f:content = f.read()# print(f"{glyph_set_name}=====DdddOcr开始识别文字=======")dddd = ddddocr.DdddOcr(show_ad=False)text = dddd.classification(content)if os.path.exists(temp_path):os.remove(temp_path)return textif __name__ == '__main__':# glyph_set_name 就是上图中的name值 这样映射关系都对应上了res = ttf_to_char('tansoole.woff',glyph_set_name='gbreve')print(res)
3.映射数据
最后将上图代码流程已经结果字典映射对应就有了我们所看到的值,如图所示:

三、总结
在字体反爬的路还有很长的路要走,本文也是笔者一些经验和不成熟的见解,也欢迎跟各位大佬一起交流学习!







)


的使用规范)







)
特别推荐)