文章目录
- 一、DepGraph剪枝
- (1)项目准备
- 1)剪枝基础知识
- 2)DepGraph剪枝论文解读1
- 2)DepGraph剪枝论文解读2
- 3)YOLO目标检测系列发展史
- 4)YOLO网络架构
- (2)项目实战(YOLOv8应用DepGraph剪枝+finetune)
- 1)安装软件环境(基础环境、Pytorch、YOLOv8)Windows
- 1)安装软件环境(基础环境、Pytorch、YOLOv8)Linux(略)
- 2)准备数据集和修改配置(YOLO版本8.1033)
- 3)训练数据集、测试训练的网络测试和性能评估
- 4)DepGraph剪枝训练YOLOv8
- 5)剪枝训练后网络测试和性能评估
- (3)代码解析
- 1)Torch Pruning工具包介绍(安装、普通剪枝示例、扫描分组、根据通道剪枝的高级剪枝器、全局剪枝、依赖图中不必要的权重更新的稀疏训练、交互式剪枝、)
- 2)yolov8_pruning脚本代码解析(代码针对yolov8 8.1.33)
- 3)额外代码注释补充:
- 二、Network Slimming剪枝
- (1)项目准备
- 1)Network Slimming剪枝原理
- 2)YOLO目标检测系列发展史
- 3)YOLOv8网络架构
- (2)项目实战
- 1)安装基础环境、安装Pytorch、安装YOLOv8
- 2)准备数据集、修改配置文件、训练数据集
- 3)测试训练处的网络和性能统计
- 4)稀疏化训练
- 5)网络剪枝
- 6)剪枝后微调
- (3)代码解析
- 1)修改代码文件解析
- 2)新增代码文件解析
一、DepGraph剪枝
(1)项目准备
- 基础知识背景
①稀疏:在模型剪枝(Model Pruning)中,稀疏表示(Sparsity)是指通过某种方式使模型的参数或结构中出现大量的零值(或接近零的值),从而让模型的表示变得 “稀疏”
②为什么要剪枝而不是去训练小网络:因为彩票事件效应,去小网络是很难学习成功的
彩票效应:大模型有很多小网络,如果有一个子网络训练成功则可以看做大模型训练成功
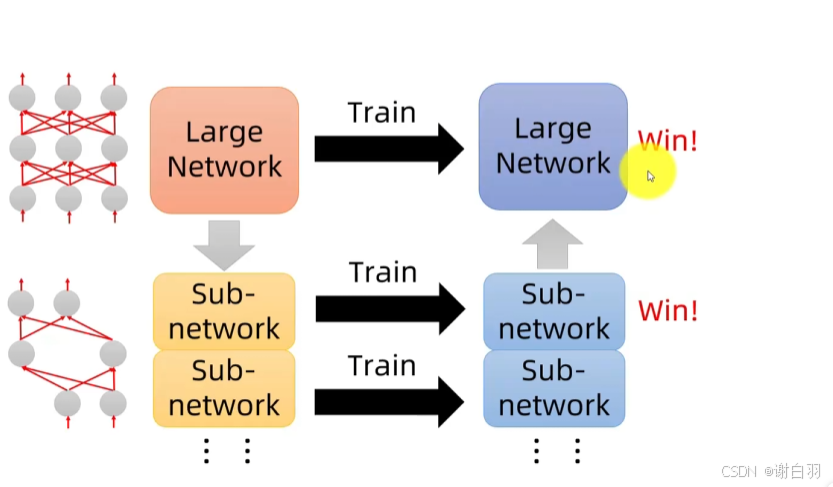
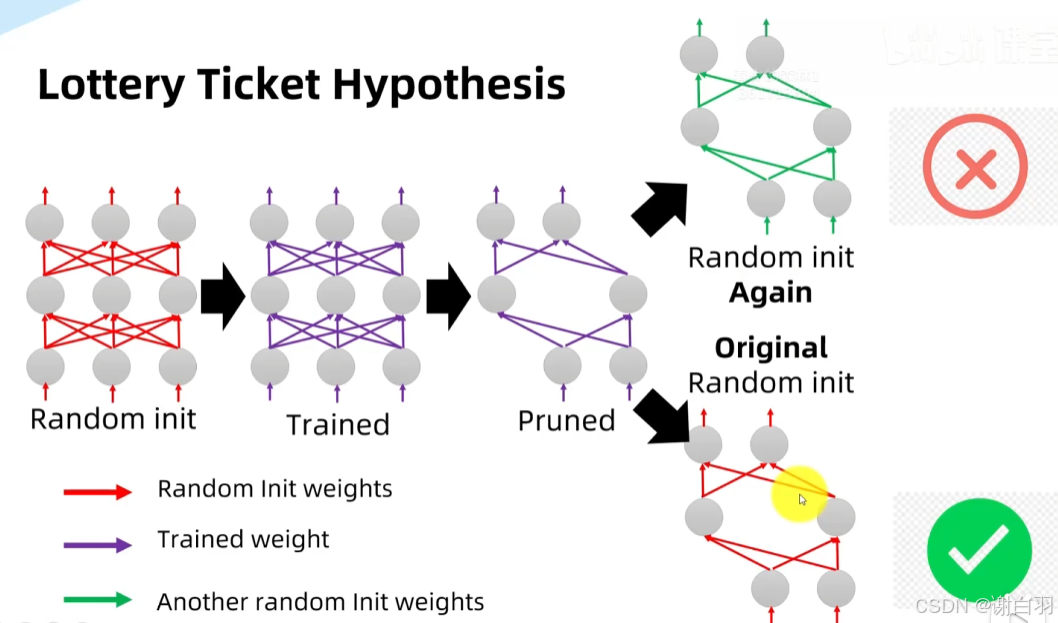
把模型随机初始化后训练,剪枝后如果再次随机初始化权重是很难训练成功的,但是如果用原先第一次随机初始化的权重训练的话就成功,这就说明中奖了
1)剪枝基础知识
之前我有写过博客
CUDA与TensorRT学习四:模型部署基础知识、模型部署的几大误区、模型量化、模型剪枝、层融合
①剪枝分类
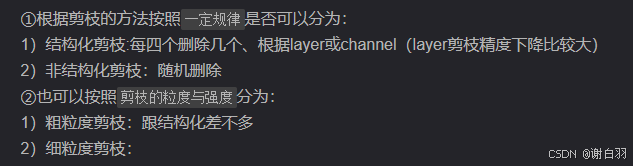
②粗粒度剪枝和细粒度剪枝对比
粗粒度

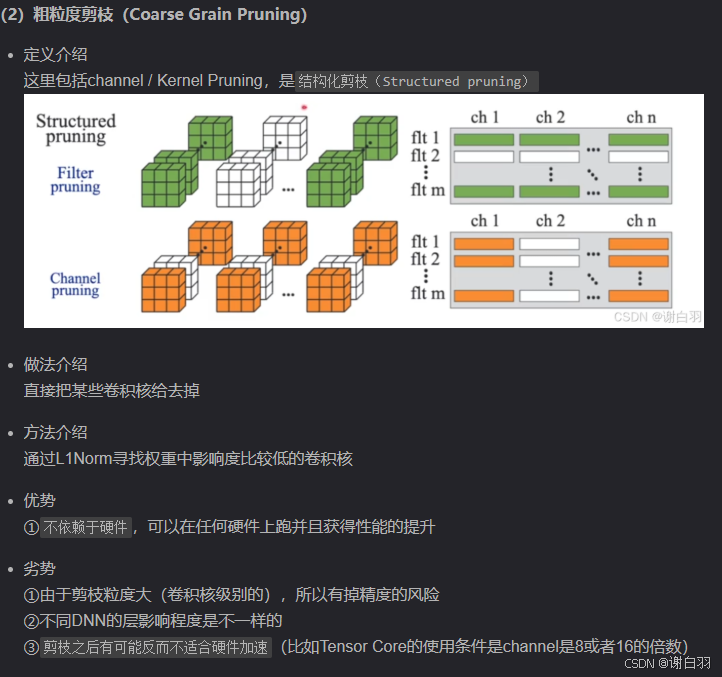
细粒度剪枝

③基础知识
1)神经网络通常都是过度参数化,权重数很多都是多余的
2)剪枝颗粒度
(1)权重剪枝
权重剪枝,剪枝之后就变成非规则,缺点是难以实现,难以加速
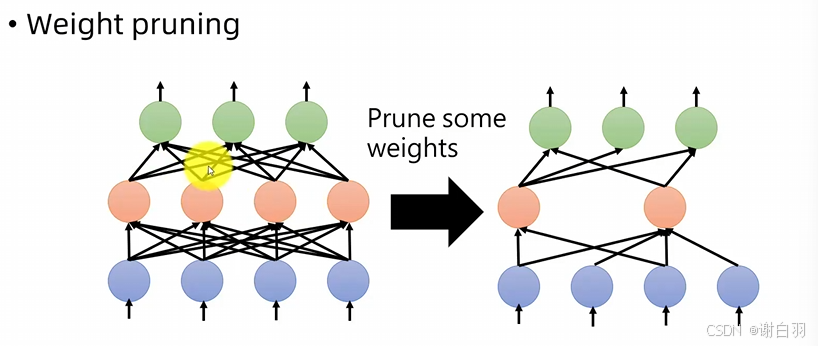
(2)神经元剪枝
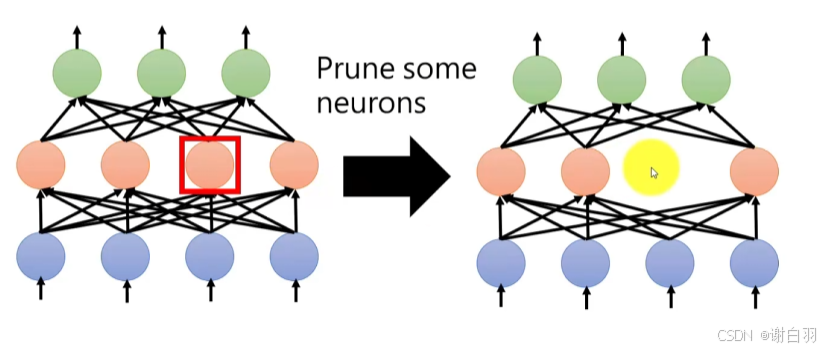
- 补充
还有不同颗粒度剪枝
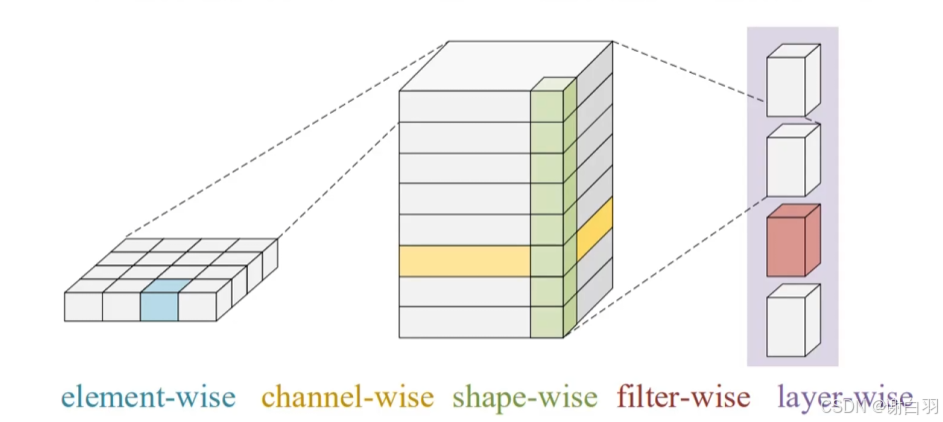
)element wise包括了权重和神经元剪枝,可能会导致非结构化剪枝,得不到GPU加速
)其他四个是结构化剪枝,能得到GPU加速是研究重点
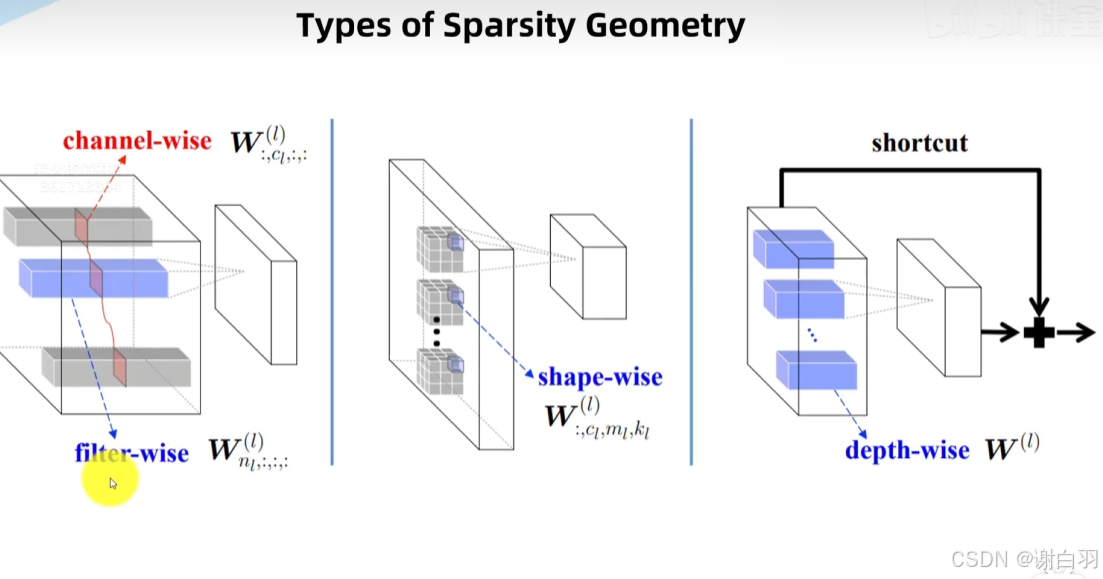
channel:通道剪枝
filter:滤波器剪枝
shape:若干个高度和宽度的神经元剪枝
depth:某个深度方向的神经元都剪枝掉
2)DepGraph剪枝论文解读1
①论文截图

②网络架构中可按照不同层数分配在各个组中,按组来剪枝(同一组有依赖关系)
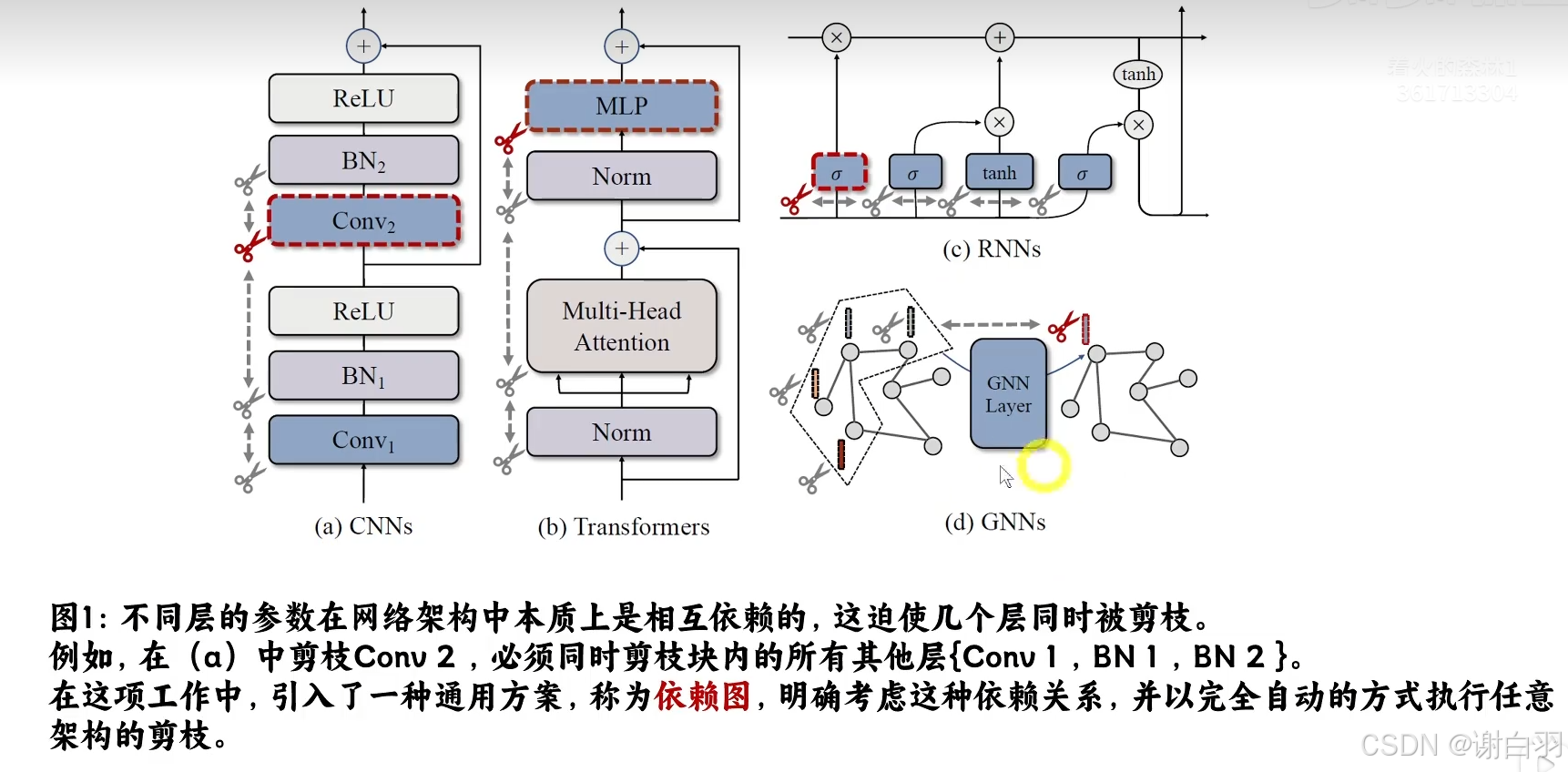
如图所示 CNNS、Transformer、RNNs、 GNNs都可以剪枝。在图中如果剪枝了CNNs的Con v2,那就必须删除同组中的{ Conv1、BN1、 BN2} ,从而引入了依赖图,明确依赖图来自动化剪枝
③算法核心:利用相邻层的局部依赖关系,递归地推导出需要的分组矩阵G
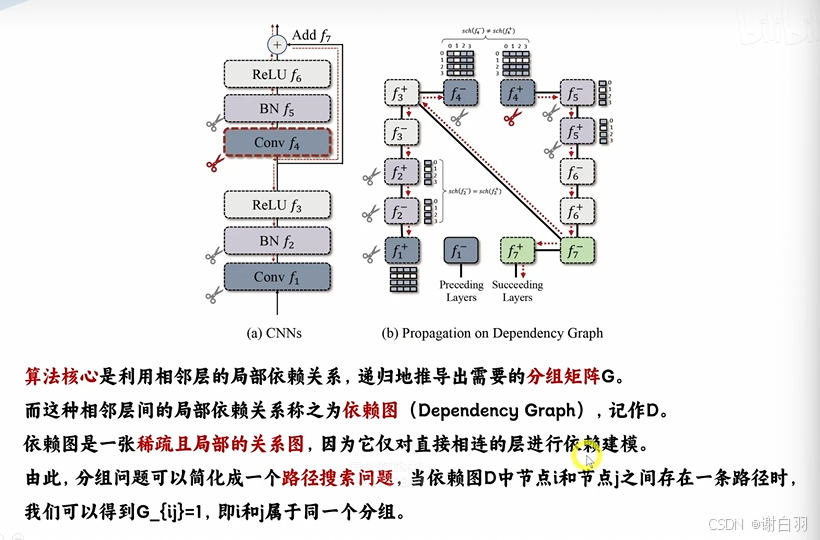
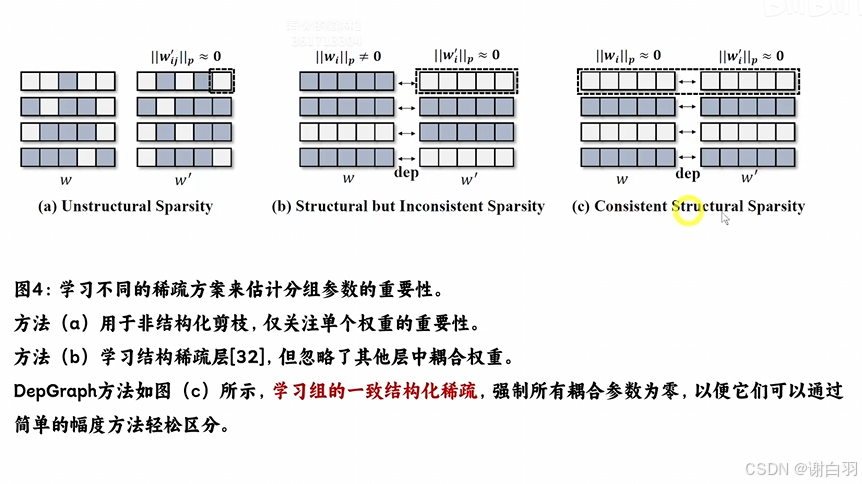
如下图,a是非结构化剪枝仅仅关注了权重的重要性,b学习结构稀疏层,但是w比w‘耦合权重更多是不稀疏的,也不考虑剪枝掉,唯有c组是学习组的一致结构稀疏,表示的是要剪枝掉的组里面w和w’都是稀疏的
④相关工具:基于DepGraph算法,作者开发Pytorch结构化剪枝框架Torch-Pruning,与torch.nn.utils.prune最大的差别在于:它会物理地移除参数,同时自动裁剪其他依赖层,而后者只能把参数置为0
④DepGraph剪枝+fine效果展示:
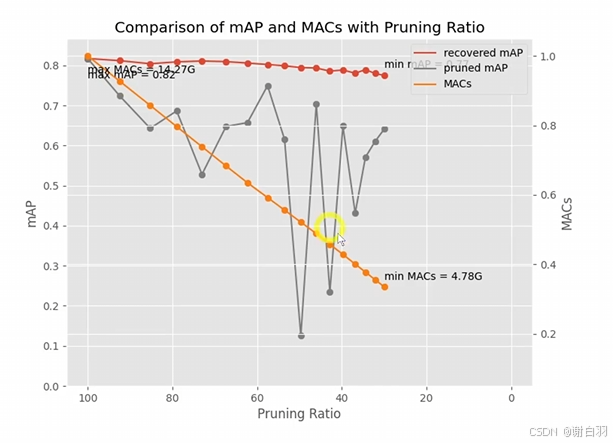
可以看到横轴往右随着剪枝越多,计算量MACs越低,pruned mAP掉点越跳跃,而fine-tune后的模型精度基本变化不大
1)MACs
MACs(Multiply - Accumulate Operations,乘累加操作次数 )代表计算量。它用于衡量模型在推理过程中执行乘法和累加操作的总数,是评估模型计算复杂度的重要指标
2)pruned mAP
表示剪枝后的模型精度
3)recovered mAP
剪枝后的模型微调后的精度
2)DepGraph剪枝论文解读2
(1)问题点-现有的剪枝存在问题:算法实现和网络结构强绑定,需要为不同模型分别开发专用且复杂的剪枝程序

(2)解决方法-依赖图:自动方式去分组

(3)原理解析:利用相邻层的局部关系递归式分组


3)YOLO目标检测系列发展史
①重大分水岭在2012年,2012年之前是传统检测方法,2012年后是基于深度学习检测方法
②2012年后有两种发展方式:单阶段检测、双阶段检测,两者区别是双阶段检测器提出了候选框阶段然后得出物体的预测框
③单阶段检测框:yolo、SSD、Retina-Net,双阶段检测框:RCNN、SPPNet、Fast RCNN、Faster RCNN、Pyramid Networks

④yolo发展

4)YOLO网络架构
- 网络架构简图

①input:输入图片
②Backbone:骨干网络,深度学习的神经网络
③由于没有候选框,所以单阶段检测有密集的预测,而多阶段检测有候选框所以是稀疏的预测

④proposal-free表示没有候选框
⑤yolo主要思想:分框对落入其中的目标进行检测,一次性预测所有格子所含目标的边界框、定位置信度、以及所有类别概率向量

Non-max suppression:NMS,非极大抑制,比较多个预测框的IOU

⑥yolo基础思想:
1、划分网格
2、通过网格得到物体的边界框 bounding boxes+置信度得分 confidence + class probility map类别概率图
3、最终的检测结果
4、以下图的B表示有多少尺度边界框的预测,现在再看是有三个尺度的边界框,然后用FPN多尺度的融合划分预测(13x13\26x26\52x52)


5、Anchor锚框机制:预先设置边界框的大小,每个尺度上都可以有若干个Anchor(下图每种颜色有三个锚框)

6、不同anchor对比


(2)项目实战(YOLOv8应用DepGraph剪枝+finetune)
1)安装软件环境(基础环境、Pytorch、YOLOv8)Windows
①准备基础环境
基础环境
1)windows 10
2)cuda 11.8
3)cudnn 8.9
4)vs 2022
5)下载安装显卡驱动
2)下载cuda 11.8


安装cuda


3)cudnn 8.9 下载


安装cudnn

cuda安装测试


4)vs 2022安装

5)下载安装显卡驱动



②安装PyTorch
这里是用的Anaconda进行安装
1)安装Anaconda
2)安装pytorch
1)安装Anaconda

2)安装pytorch

在环境下面安装pytorch

再安装cudnn

③克隆和安装YOLOv8
1)克隆yolov8并安装
2)下载yolov8预训练权重文件
3)安全测速
1)克隆yolov8并安装
先安装git

安装git后克隆yolov8项目

2)下载yolov8预训练权重文件

这里选用的yolov8s,这里使用的训练集是coco,下图是coco数据集上性能的表现

3)安全测速

单次预测图片

打开文件夹

可以看到检测图片

摄像头实时动态预测:


预测文本的结果:命令如下

最左边:类别的编号–5是bug,0是person
后面四位小数:预测物体在图片上的位置(进行了归一化所以是小数)

1)安装软件环境(基础环境、Pytorch、YOLOv8)Linux(略)
①准备基础环境
②安装PyTorch
③克隆和安装YOLOv8
2)准备数据集和修改配置(YOLO版本8.1033)

①进入ultraiyics解压目录输入 ,安装好后进入上面安装测试的步骤
pip install -e .

①testfile下面的图片是测试图片
②VOC2007下面是图片和图片对应的标注信息和图片信息

执行这个脚本是划分数据集和验证集
TRAIN_RATIO表示80%划分到训练集,20%验证集

4)修改配置文件

①这里的目录images是相对路径,相当于vocdevkit目录下
②name下面是类别的名称
3)训练数据集、测试训练的网络测试和性能评估
1)训练数据集命令(利用预训练的权重来在自己的数据集上进行训练,也可称为微调)

断点续训练:因断电或其他原因导致的中断训练,可以接着训练


训练结果(train是训练中的变化,val是验证中的变化,metric是训练中的指标)

2)训练结果查看

- 测试训练出的网络模型

性能统计

conf:置信度阈值
iou:非极大抑制阈值
4)DepGraph剪枝训练YOLOv8

+参数说明

触发掉点20%才会终止迭代
- 训练后 ultralytics/runs/detect文件夹下

- 结果

5)剪枝训练后网络测试和性能评估

-
验证安装onnx-runtime

-
注意
非pytorch模型,batch在检测性能的时候会变成1

-
性能评估
①可以看到剪枝后mAP50为0.966,mAP(50~95)为0.775
②微调后的数据mAP50为0.985,mAP(50~95)为0.821,明显是比只剪枝精度高的

③可以从图中看到,在剪枝比例50%附近掉点事最严重的,但是经过微调也能恢复到与刚开始mAP差不多的精度

④linux下在做对比

1)从图片可以看到只剪枝后对比只微调精度在mAP指标上有下降,从0.983下降到0.879大概掉点11%
2)接下来的步骤是先剪枝,结果保存在step_0_pre_val
3)再继续进行30个epoch的微调(可以30以上的epoch效果会更好),再查看精度(在最好的权重文件best.pt里面),结果保存在step_post_val

4)再做一次pruning剪枝,然后在做30个epoch的微调

可以看到再次微调后mAP只跌到0.78,而mAP(50~95)还是0.96附近

5)打开结果可以看到第二次剪枝后微调,mAP50在30个epoch后还在持续上升

(3)代码解析
1)Torch Pruning工具包介绍(安装、普通剪枝示例、扫描分组、根据通道剪枝的高级剪枝器、全局剪枝、依赖图中不必要的权重更新的稀疏训练、交互式剪枝、)
①可以给很多网络剪枝

②安装步骤

③演示DepGraph进行基本修剪流程,目标层是resnet.conv1,找出与conv1分为同一组的其他层,统一剪枝

④扫描模型所有的分组

⑤高级剪枝器:通过指定所需的通道修剪比例,修剪器将扫描所有可修剪的组并预估重要性从而修剪整个模型,并使用自己的训练代码进行微调
代码备注:分类层别剪枝,分类层是跟类别数相关的


⑥全局剪枝:根据各层的全局重要性分配自适应稀疏性,但会存在过度剪枝风险

⑦稀疏训练:减少依赖图中不必要的权重更新

⑧交互类剪枝:要求了解那些层可以拿来剪枝,要求非常了解网络架构

⑨软剪枝:将参数归零而不是移除

⑩组级剪枝

十一、低级剪枝功能:指定那些层来剪枝

2)yolov8_pruning脚本代码解析(代码针对yolov8 8.1.33)
-
主体思想
函数中使用了 torch-pruning(tp)库进行剪枝操作,通过 GroupNormPruner 对象基于 L2 范数的重要性对模型的卷积层进行剪枝。剪枝后,通过微调训练来恢复模型的性能。在每次迭代中,函数记录了剪枝前后的 MACs、参数数量和 mAP,并绘制性能图表,以便观察剪枝对模型性能的影响。如果 mAP 下降超过指定阈值,函数会提前停止剪枝过程。最后,函数将剪枝后的模型导出为 ONNX 格式,并将最终的剪枝和微调后的模型保存为 .pt 文件,以便后续使用。 -
注意点
需要注意的是,该函数依赖于其他函数和类,如 train_v2 、 replace_c2f_with_c2f_v2 、initialize_weights 等,以及 torch-pruning 库的相关功能。 -
代码步骤
①main函数设置读取配置规则:
②进行多次迭代的剪枝和微调:
③将剪枝后的模型导出为 ONNX 格式
④将最终的剪枝和微调后的模型保存为 .pt 文件 -
具体
①main函数设置读取配置规则:
创建一个 argparse.ArgumentParser 对象 parser ,用于定义和解析命令行参数
if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument('--model', default='D:/ultralytics/runs/detect/train/weights/best.pt', help='Pretrained pruning target model file')parser.add_argument('--cfg', default='default.yaml',help='Pruning config file.'' This file should have same format with ultralytics/ultralytics/cfg/default.yaml')parser.add_argument('--iterative-steps', default=16, type=int, help='Total pruning iteration step')parser.add_argument('--target-prune-rate', default=0.5, type=float, help='Target pruning rate')parser.add_argument('--max-map-drop', default=0.2, type=float, help='Allowed maximum map drop after fine-tuning')parser.add_argument('--data', type=str, default='VOC-ball.yaml',help='Path to the dataset configuration file')parser.add_argument('--epochs', type=int, default=30, help='Number of epochs for fine-tuning each pruning iteration step')args = parser.parse_args()prune(args)
这段代码是一个 Python 脚本的主程序部分,它使用 argparse 模块来解析命令行参数,并调用 prune 函数来
执行模型剪枝。
参数解释如下:

-》调用 parser.parse_args() 方法解析命令行参数,并将解析结果存储在 args 变量中
-》调用 prune 函数,并将 args 作为参数传递给该函数,开始执行模型剪枝过程
-》当用户在命令行中运行该脚本时,可以使用以下格式指定参数:
python yolov8_pruning.py --model last.pt --cfg default.yaml --iterative-steps 16 --
target-prune-rate 0.5 --max-map-drop 0.2 --data VOC-ball.yaml --epochs 30
②进行多次迭代的剪枝和微调:
for i in range(args


基础解析与python实例:训练稳定倒立摆)

)







)


)


