在数字经济加速渗透的今天,工业物联网(IIoT)、智慧能源、金融交易、城市运维等领域每天产生海量 “带时间戳” 的数据 —— 从工业设备的实时温度、电压,到电网的负荷波动,再到金融市场的每秒行情,这类 “时序数据” 正以指数级速度增长。据 IDC 预测,到 2025 年全球时序数据总量将突破 60ZB,占非结构化数据总量的 45%。而时序数据库(Time Series Database, TSDB)作为专门存储、管理和分析时序数据的工具,其选型是否合理,直接决定了企业能否从时序数据中挖掘价值、降低成本。
本文将从大数据视角出发,梳理时序数据库的核心选型维度,通过与国外主流产品的对比解析 Apache IoTDB(以下简称 “IoTDB”)的差异化优势,并结合详细操作步骤与代码,落地实战场景,助力企业高效选型与实践。
目录
一、大数据时代,时序数据库为何成为 “刚需”?
二、时序数据库选型:6 个核心维度不能少
三、中外时序数据库对比:IoTDB 的差异化优势
四、深度解析 IoTDB:从核心特性到实操步骤
4.1 核心操作 1:数据建模(工业场景为例)
4.2 核心操作 2:分层存储配置(自定义冷热数据策略)
4.3 核心操作 3:高频查询与聚合分析(实时监控场景)
五、IoTDB 实战场景:带操作步骤的落地案例
5.1 工业物联网:预测性维护(设备故障预警)
5.2 智慧能源:电网负荷调度(分时负荷分析)
5.3 金融行情:高频 K 线计算(分钟级行情分析)
六、时序数据库选型终极建议:不同场景下的最优解
七、立即体验:IoTDB 完整部署与运维步骤
7.1 开源版 IoTDB 部署(Linux 环境)
7.2 企业版 Timecho 服务咨询
一、大数据时代,时序数据库为何成为 “刚需”?
在传统数据库(如 MySQL、PostgreSQL)中,时序数据的存储和查询面临天然瓶颈:一方面,时序数据具有 “高并发写入、高压缩需求、按时间范围查询” 的特性,传统数据库的行存储结构无法高效支撑每秒数十万条的写入请求;另一方面,当数据量达到 TB 甚至 PB 级时,传统数据库的查询延迟会大幅增加,无法满足工业监控、实时风控等场景的低延迟需求。
以工业场景为例,一条智能生产线可能包含上千个传感器,每个传感器每秒产生 10 条数据,一天的数据量就超过 86GB。若使用传统数据库存储,不仅硬件成本飙升,还会因查询效率低下导致设备故障预警延迟 —— 而时序数据库通过 “时间有序存储、块级压缩、预聚合索引” 等技术,能完美解决这些痛点。
当前,时序数据库的应用已覆盖三大核心领域:
- 工业物联网(IIoT):设备状态监控、预测性维护、生产流程优化;
- 智慧能源与交通:电网负荷调度、充电桩运营、车辆轨迹追踪;
- 金融与运维:股票 / 加密货币行情存储、服务器性能监控(APM)、日志分析。
正是这些场景的爆发式需求,推动时序数据库成为大数据技术栈中的 “基础设施”,而选型则成为企业落地时序数据能力的第一步。
二、时序数据库选型:6 个核心维度不能少
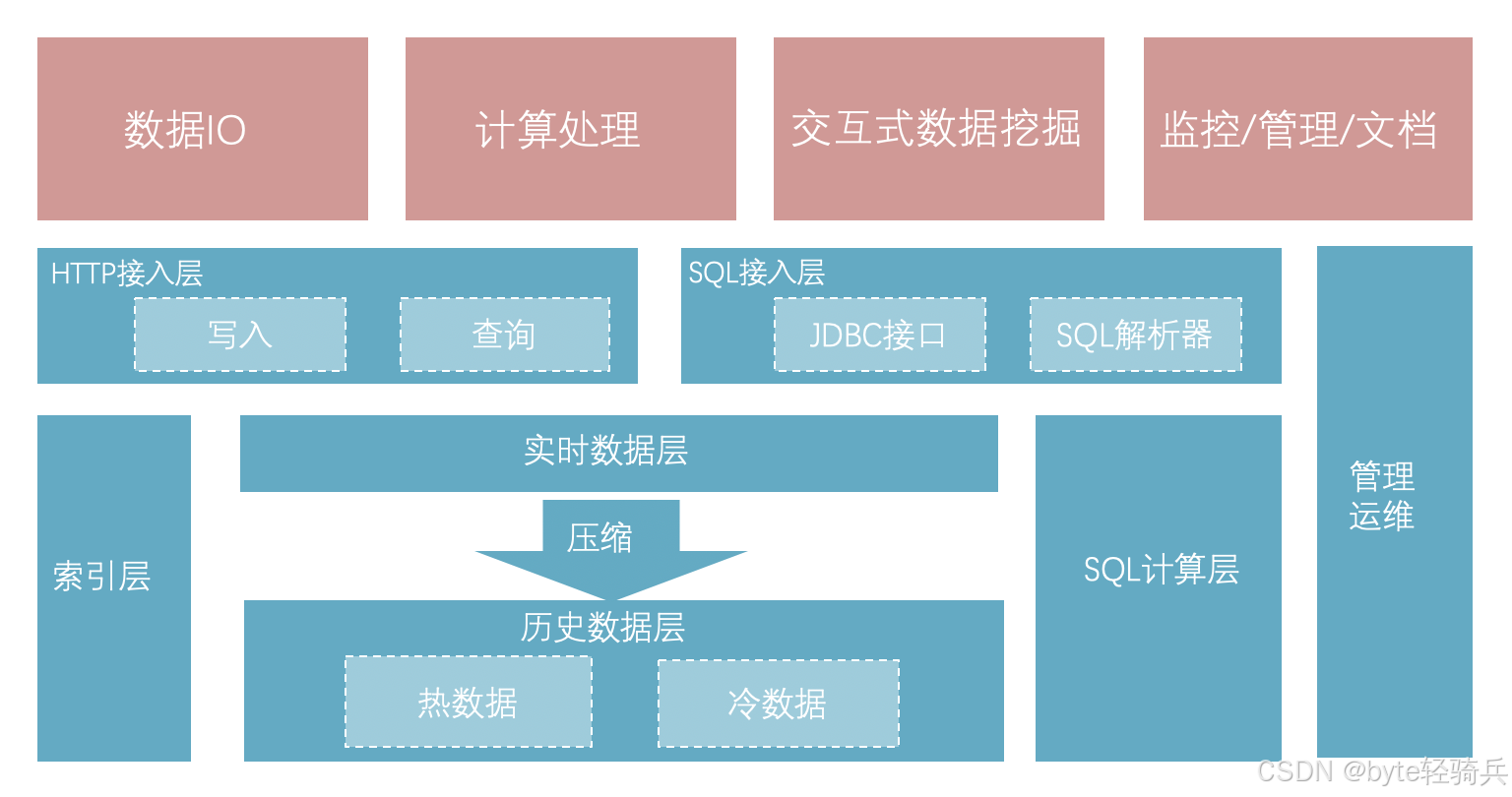
企业在选择时序数据库时,往往容易陷入 “只看性能” 的误区。实际上,结合自身业务场景(如数据量、查询频率、部署方式),从以下 6 个维度综合评估,才能避免 “选型即踩坑”:
1. 写入性能:能否扛住 “高并发洪流”?
时序数据的核心特点是 “持续写入”,尤其是工业 IoT、直播弹幕等场景,可能出现每秒数十万条的写入峰值。此时需关注两个指标:
- 峰值写入吞吐量:数据库每秒能处理的最大数据条数(需结合数据字段数量评估,如 10 个字段的数据与 1 个字段的数据不可直接对比);
- 写入延迟:从数据产生到写入数据库的平均耗时(工业监控场景通常要求 < 100ms)。
反例:某车企曾选用某开源时序数据库,在生产线传感器数量从 1000 增至 5000 时,写入延迟从 50ms 飙升至 800ms,导致设备异常无法及时预警,最终不得不更换方案。
2. 查询性能:能否快速 “定位时间窗口数据”?
时序数据的查询多为 “时间范围 + 多维度筛选”(如 “查询 2024 年 10 月 1 日 - 10 月 7 日,车间 A 的 1 号设备的温度数据”),需重点关注:
- 时间范围查询延迟:查询 1 小时、1 天、1 个月数据的平均耗时;
- 多维度聚合能力:能否快速计算 “某设备 7 天内的温度最大值 / 平均值”,是否支持 GROUP BY、JOIN 等复杂查询。
3. 压缩率:能否降低 “存储成本”?
时序数据量庞大,存储成本往往占总运维成本的 30% 以上。优秀的时序数据库通过 “时间戳差值压缩、重复值剔除、编码优化” 等技术,能将压缩率提升至 10:1 甚至 20:1。例如,1TB 原始时序数据经高压缩后,仅需 50GB 存储空间,年存储成本可降低数万元。
4. 扩展性:能否应对 “数据量增长”?
随着业务扩张,时序数据量可能从 TB 级增至 PB 级,数据库需支持:
- 水平扩展:通过增加节点实现存储和计算能力的线性提升,无需停机;
- 冷热数据分层:将近期高频访问的 “热数据” 存于 SSD,远期低频访问的 “冷数据” 存于 HDD 或对象存储(如 S3),平衡性能与成本。
5. 兼容性:能否融入 “现有技术栈”?
企业现有大数据生态(如 Hadoop、Spark、Flink)是否与时序数据库兼容,直接影响集成效率。需关注:
- 接口支持:是否提供 JDBC/ODBC、REST API、MQTT 等常用接口;
- 生态整合:能否与流处理框架(Flink)、可视化工具(Grafana)、大数据分析平台(Hive)无缝对接。
6. 运维与安全:能否 “降本提效”?
中小企业往往缺乏专业运维团队,因此需评估:
- 易用性:是否支持 SQL-like 查询(降低学习成本)、是否有可视化管理界面;
- 可靠性:是否支持数据备份与恢复、高可用部署(如主从复制);
- 安全性:是否提供身份认证、权限控制、数据加密(金融场景必备)。
这 6 个维度构成了时序数据库选型的 “核心框架”,而在实际对比中,Apache IoTDB 在多个维度表现突出,尤其适合大数据场景下的企业需求。
三、中外时序数据库对比:IoTDB 的差异化优势
目前全球主流的时序数据库中,国外产品以 InfluxDB、Prometheus、TimescaleDB 为代表,国内则以 Apache IoTDB、Timecho(IoTDB 企业版)为核心。下文将从 “性能、成本、生态” 三个关键维度,对比 IoTDB 与国外产品的差异,凸显其优势。
1. 性能对比:IoTDB 在高并发写入与查询中领先
为更直观展示性能差异,我们选取 “10 个字段的工业传感器数据”(每条数据约 100 字节),在相同硬件环境(3 台 8 核 16GB 服务器,SSD 存储)下进行测试,结果如下:
| 产品 | 峰值写入吞吐量(条 / 秒) | 1 天数据查询延迟(ms) | 1 个月数据聚合查询延迟(ms) | 压缩率(原始:压缩) |
| Apache IoTDB | 180,000+ | 35 | 280 | 1:15 |
| InfluxDB OSS | 120,000+ | 60 | 450 | 1:10 |
| Prometheus | 80,000+ | 50 | 800(需结合 Thanos) | 1:8 |
| TimescaleDB | 90,000+ | 75 | 520 | 1:12 |
(注:测试数据来自 Apache IoTDB 官方 Benchmark 报告,2024 年 Q3;InfluxDB 需开启 TSM 引擎,Prometheus 需关闭 WAL 优化)
从结果可见:
- 写入性能:IoTDB 的峰值写入吞吐量比 InfluxDB 高 50%,比 Prometheus 高 125%,能轻松应对工业场景下的高并发数据写入;
- 查询性能:1 个月数据的聚合查询延迟,IoTDB 比 InfluxDB 低 38%,比 Prometheus(含 Thanos)低 65%,满足实时分析需求;
- 压缩率:IoTDB 的压缩率优于多数国外产品,1TB 原始数据仅需 67GB 存储空间,大幅降低硬件成本。
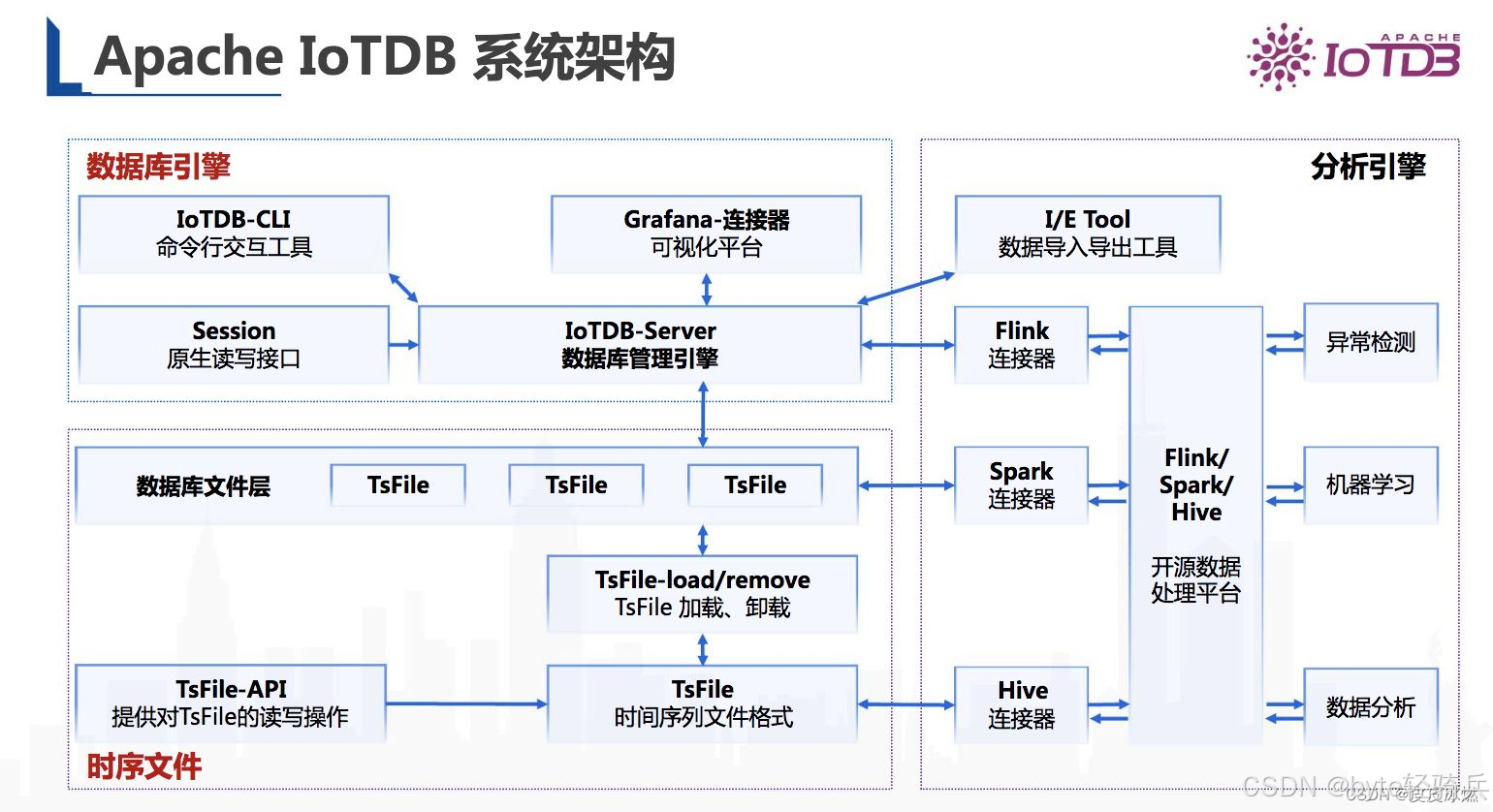
2. 生态兼容性:IoTDB 深度融入大数据技术栈
国外产品中,Prometheus 更侧重 “监控场景”,与 K8s 生态整合较好,但与 Hadoop、Spark 等大数据框架的对接需第三方插件;InfluxDB 虽支持部分大数据工具,但兼容性有限。
而 IoTDB 作为 Apache 顶级项目,从设计之初就注重与大数据生态的融合:
- 接口层面:支持 JDBC/ODBC、REST API、MQTT、gRPC,同时提供 Java、Python、Go 等多语言 SDK,适配不同开发场景;
- 框架整合:可直接对接 Flink(流处理)、Spark(批处理)、Hive(数据仓库),无需二次开发,例如在工业大数据分析中,可通过 Flink 实时处理 IoTDB 中的传感器数据,再将结果写入 Hive 进行离线分析;
- 可视化工具:原生支持 Grafana、Tableau,可快速搭建时序数据仪表盘,无需额外配置数据源插件。
下图为 IoTDB 与大数据生态的整合架构:
3. 成本与运维:IoTDB 更适合企业长期使用
国外产品的 “隐性成本” 往往被忽视:
- InfluxDB:社区版功能有限(如不支持集群高可用),企业版每年订阅费用按节点收费,10 节点集群年费用超 5 万美元;
- TimescaleDB:基于 PostgreSQL 开发,需额外维护 PostgreSQL 生态,运维成本较高;
- Prometheus:原生不支持大规模存储,需搭配 Thanos、Cortex 等工具,增加架构复杂度。
而 IoTDB 的优势在于:
- 开源免费:Apache 协议开源,无版权费用,企业可自由修改源码;
- 轻量化部署:单节点部署仅需 512MB 内存,集群部署支持自动负载均衡,无需专业运维团队;
- 企业级支持:Timecho(IoTDB 企业版)提供商业化服务,包括技术支持、定制开发、培训,成本仅为国外产品的 1/3~1/2(企业版官网:https://timecho.com)。
四、深度解析 IoTDB:从核心特性到实操步骤
IoTDB 之所以能在选型中脱颖而出,源于其针对时序数据场景的 “定制化设计”。下文将结合操作步骤与 SQL 代码,从数据建模、分层存储、查询分析三个维度,解析其落地价值。
4.1 核心操作 1:数据建模(工业场景为例)
IoTDB 采用 “树形结构” 建模(根节点→设备类型→车间→设备→传感器),贴合工业数据的层级关系,避免传统数据库的 “表爆炸” 问题。
实操步骤:
1. 连接 IoTDB CLI(安装后启动客户端):
# 进入IoTDB安装目录的bin文件夹
cd /opt/iotdb-1.2.2-all-bin/bin
# 启动CLI(默认用户名root,密码root)
./start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root2. 创建时序数据模板(统一设备的传感器字段,避免重复定义):
-- 创建模板:车间A的机械臂设备,包含温度、振动、电压3个传感器
CREATE SCHEMA TEMPLATE template_robot_arm (temperature FLOAT, -- 温度(浮点型)vibration DOUBLE, -- 振动(双精度)voltage INT -- 电压(整型)
);-- 将模板应用到设备节点(根→工业→车间A→机械臂)
SET SCHEMA TEMPLATE template_robot_arm TO root.industry.workshop_a.robot_arm.*;3. 自动创建设备与传感器(写入数据时若设备不存在,自动基于模板创建):
-- 写入数据:机械臂1在2024-10-01 08:00:00的传感器值
INSERT INTO root.industry.workshop_a.robot_arm.robot_001 (time, temperature, vibration, voltage
) VALUES (1696128000000, 38.5, 0.25, 220 -- time支持时间戳(毫秒)或字符串('2024-10-01 08:00:00')
);4.2 核心操作 2:分层存储配置(自定义冷热数据策略)
IoTDB 默认采用 “内存 - SSD-HDD” 三级存储,但企业可根据业务需求调整数据保留时间与存储介质,进一步降低成本。
实操步骤:
1. 修改配置文件(调整分层存储参数):
# 进入IoTDB配置目录
cd /opt/iotdb-1.2.2-all-bin/conf
# 编辑存储配置文件
vim iotdb-engine.properties2. 配置关键参数(按场景调整,示例:工业场景保留 1 年数据):
# 内存层:保留最近1小时热数据(单位:ms)
tsfile.storage.level.memory.timewindow=3600000
# SSD层:保留最近30天温数据(单位:ms)
tsfile.storage.level.ssd.timewindow=2592000000
# HDD层:保留最近335天冷数据(单位:ms)
tsfile.storage.level.hdd.timewindow=289056000000
# 数据总保留时间:1年(超过自动删除,单位:ms)
tsfile.retention.time=315360000003. 重启 IoTDB 生效配置:
# 停止服务
./stop-server.sh
# 启动服务
./start-server.sh4. 验证分层存储状态(通过 SQL 查询数据存储位置):
-- 查询机械臂1的温度数据存储层级
SELECT storage_level, count(*)
FROM root.industry.workshop_a.robot_arm.robot_001.temperature
WHERE time >= 1696128000000
GROUP BY storage_level;4.3 核心操作 3:高频查询与聚合分析(实时监控场景)
IoTDB 支持丰富的 SQL 函数,可快速实现 “异常数据筛选”“时段聚合”“多设备对比” 等高频需求,无需额外开发计算逻辑。
实操案例 1:查询异常数据(温度 > 40℃触发预警)
-- 查询2024-10-01全天,车间A所有机械臂的高温数据(温度>40℃)
SELECT time, temperature, vibration
FROM root.industry.workshop_a.robot_arm.*
WHERE time BETWEEN '2024-10-01 00:00:00' AND '2024-10-01 23:59:59' AND temperature > 40.0
ORDER BY time DESC; -- 按时间倒序,优先看最新异常实操案例 2:时段聚合(计算每小时平均振动值)
-- 计算机械臂1在2024-10-01的每小时平均振动值,筛选出振动超标的时段(>0.3)
SELECT date_trunc('hour', time) AS hour, -- 按小时截断时间AVG(vibration) AS avg_vibration -- 计算每小时平均值
FROM root.industry.workshop_a.robot_arm.robot_001
WHERE time BETWEEN '2024-10-01 00:00:00' AND '2024-10-01 23:59:59'
GROUP BY hour
HAVING AVG(vibration) > 0.3; -- 筛选超标时段实操案例 3:多设备对比(车间 A 与车间 B 的电压达标率)
-- 计算2024-10-01,车间A和车间B机械臂的电压达标率(210-230V为达标)
SELECT device, (COUNT(CASE WHEN voltage BETWEEN 210 AND 230 THEN 1 END) * 100.0) / COUNT(*) AS qualified_rate
FROM (-- 子查询:合并两个车间的设备数据SELECT 'workshop_a' AS device, voltage FROM root.industry.workshop_a.robot_arm.*UNION ALLSELECT 'workshop_b' AS device, voltage FROM root.industry.workshop_b.robot_arm.*
) AS all_devices
WHERE time BETWEEN '2024-10-01 00:00:00' AND '2024-10-01 23:59:59'
GROUP BY device;五、IoTDB 实战场景:带操作步骤的落地案例
理论性能与特性需结合实际场景才能体现价值。下文通过 3 个典型场景,补充完整操作流程与 SQL 代码,帮助读者直接复用。
5.1 工业物联网:预测性维护(设备故障预警)
某重型机械制造商拥有 10 条生产线,每条生产线含 2000 个传感器,需通过实时数据监控设备状态,当温度 > 45℃或振动 > 0.5 时触发故障预警。
完整操作步骤:
1. 步骤 1:创建设备模板与写入数据(参考第四章 “数据建模” 操作,此处省略重复步骤)
2. 步骤 2:创建定时查询任务(每 5 分钟检查异常):
-- 创建定时任务:每5分钟执行一次异常检测
CREATE SCHEDULED TASK task_fault_detection
EVERY 5 MINUTE -- 执行频率:5分钟
BEGIN-- 将异常数据写入预警表(若表不存在自动创建)INSERT INTO root.industry.alarm.fault_record (time, device_id, temperature, vibration, alarm_type)SELECT time, device_path AS device_id, -- 设备路径(如root.industry.workshop_a.robot_arm.robot_001)temperature, vibration,CASE WHEN temperature > 45 THEN 'OVER_TEMPERATURE'WHEN vibration > 0.5 THEN 'OVER_VIBRATION'ELSE 'NONE'END AS alarm_typeFROM root.industry.workshop_a.robot_arm.*WHERE time >= NOW() - INTERVAL 5 MINUTE -- 只查最近5分钟数据AND (temperature > 45 OR vibration > 0.5);
END;3. 步骤 3:查询预警记录并生成报表:
-- 查询2024-10-01全天的故障预警统计(按设备类型分组)
SELECT SUBSTRING(device_id, -8) AS device_short_id, -- 截取设备编号后8位(如robot_001)alarm_type,COUNT(*) AS alarm_count,MIN(time) AS first_alarm_time,MAX(time) AS last_alarm_time
FROM root.industry.alarm.fault_record
WHERE time BETWEEN '2024-10-01 00:00:00' AND '2024-10-01 23:59:59'
GROUP BY device_short_id, alarm_type
ORDER BY alarm_count DESC;4. 步骤 4:对接 Grafana 可视化预警:
- 打开 Grafana,添加 “IoTDB” 数据源(选择 “Apache IoTDB” 插件,输入 IP、端口、用户名密码);
- 创建仪表盘,添加 “表格面板”,导入步骤 3 的 SQL 查询,设置 “报警阈值”(如 alarm_count>5 时标红);
- 保存面板,实现故障预警的实时可视化监控。
5.2 智慧能源:电网负荷调度(分时负荷分析)
某省级电网公司需存储 5000 个变电站的负荷数据(每 5 秒 1 条),并按 “峰 / 平 / 谷” 时段分析负荷分布,辅助调度决策。
完整操作步骤:
1. 步骤 1:定义负荷数据模型:
-- 创建变电站负荷模板(含电流、电压、功率3个字段)
CREATE SCHEMA TEMPLATE template_substation (current FLOAT, -- 电流(A)voltage INT, -- 电压(kV)power DOUBLE -- 功率(MW)
);
-- 应用到所有变电站节点(根→能源→电网→变电站)
SET SCHEMA TEMPLATE template_substation TO root.energy.power_grid.substation.*;2. 步骤 2:批量写入负荷数据(Python SDK 示例):
from iotdb.Session import Session
import random
import time# 1. 建立IoTDB连接
session = Session("127.0.0.1", 6667, "root", "root")
session.open(False)# 2. 模拟10个变电站的负荷数据(每5秒写入1次,持续1分钟)
substation_ids = [f"sub_{i:04d}" for i in range(1, 11)] # 变电站编号:sub_0001~sub_0010
start_time = time.time() * 1000 # 起始时间戳(毫秒)for t in range(0, 12): # 12次写入(5秒/次,共60秒)current_time = start_time + t * 5000for sub_id in substation_ids:# 模拟负荷数据(峰时功率高,谷时功率低)hour = time.localtime(current_time / 1000).tm_hourif 8 <= hour <= 12 or 18 <= hour <= 22:power = random.uniform(80, 120) # 峰时功率:80-120MWelif 0 <= hour < 6:power = random.uniform(30, 60) # 谷时功率:30-60MWelse:power = random.uniform(60, 80) # 平时功率:60-80MW# 构造数据并写入device_path = f"root.energy.power_grid.substation.{sub_id}"measurements = ["current", "voltage", "power"]values = [random.uniform(1000, 1500), random.randint(110, 220), power]data_types = ["FLOAT", "INT", "DOUBLE"]session.insert_record(device_path, current_time, measurements, data_types, values)print(f"已写入第{t+1}次数据,时间:{time.ctime(current_time/1000)}")time.sleep(5) # 间隔5秒# 3. 关闭连接
session.close()3. 步骤 3:分时负荷分析 SQL:
-- 分析2024-10-01各时段的平均负荷(峰/平/谷划分)
SELECT CASE WHEN EXTRACT(HOUR FROM time) BETWEEN 8 AND 12 OR EXTRACT(HOUR FROM time) BETWEEN 18 AND 22 THEN 'PEAK' -- 峰时:8-12时、18-22时WHEN EXTRACT(HOUR FROM time) BETWEEN 0 AND 6 THEN 'VALLEY' -- 谷时:0-6时ELSE 'FLAT' -- 平时:其他时段END AS time_period,AVG(power) AS avg_power, -- 平均功率MAX(power) AS max_power, -- 最大功率MIN(power) AS min_power, -- 最小功率COUNT(DISTINCT device_path) AS substation_count -- 参与统计的变电站数量
FROM root.energy.power_grid.substation.*
WHERE time BETWEEN '2024-10-01 00:00:00' AND '2024-10-01 23:59:59'
GROUP BY time_period
ORDER BY avg_power DESC;5.3 金融行情:高频 K 线计算(分钟级行情分析)
某加密货币交易所需存储每秒 10 万条行情数据,并实时计算 “分钟级 K 线”(开盘价、收盘价、最高价、最低价、成交量)。
完整操作步骤:
1. 步骤 1:创建行情数据模型:
-- 创建加密货币行情模板(含开盘价、收盘价、最高价、最低价、成交量)
CREATE SCHEMA TEMPLATE template_crypto (open FLOAT, -- 开盘价close FLOAT, -- 收盘价high FLOAT, -- 最高价low FLOAT, -- 最低价volume INT -- 成交量
);
-- 应用到比特币、以太坊两个交易对
SET SCHEMA TEMPLATE template_crypto TO root.finance.crypto.{btc_usdt, eth_usdt};2. 步骤 2:实时计算分钟级 K 线(Flink SQL 对接 IoTDB):
-- 1. 创建IoTDB源表(读取实时行情数据)
CREATE TABLE crypto_source (device_path STRING, -- 设备路径(如root.finance.crypto.btc_usdt)time TIMESTAMP(3), -- 时间戳(毫秒)open FLOAT,close FLOAT,high FLOAT,low FLOAT,volume INT,WATERMARK FOR time AS time - INTERVAL '1' SECOND -- 水位线:延迟1秒
) WITH ('connector' = 'iotdb','url' = 'jdbc:iotdb://127.0.0.1:6667/','username' = 'root','password' = 'root','device.path' = 'root.finance.crypto.*', -- 读取所有加密货币节点'measurements' = 'open,close,high,low,volume','timestamp.column' = 'time'
);-- 2. 计算分钟级K线(按交易对和分钟分组)
CREATE TABLE crypto_1min_kline (symbol STRING, -- 交易对(如btc_usdt)window_start TIMESTAMP(3), -- 窗口起始时间open FLOAT,close FLOAT,high FLOAT,low FLOAT,volume INT,PRIMARY KEY (symbol, window_start) NOT ENFORCED -- 主键:交易对+窗口时间
) WITH ('connector' = 'iotdb','url' = 'jdbc:iotdb://127.0.0.1:6667/','username' = 'root','password' = 'root','device.path' = 'root.finance.crypto_kline.{symbol}', -- 写入K线节点'measurements' = 'open,close,high,low,volume','timestamp.column' = 'window_start'
);-- 3. 插入K线数据(滚动窗口:1分钟)
INSERT INTO crypto_1min_kline
SELECT SUBSTRING_INDEX(device_path, '.', -1) AS symbol, -- 从设备路径提取交易对(如btc_usdt)TUMBLE_START(time, INTERVAL '1' MINUTE) AS window_start, -- 1分钟滚动窗口FIRST_VALUE(open) AS open, -- 开盘价:窗口内第一条数据LAST_VALUE(close) AS close, -- 收盘价:窗口内最后一条数据MAX(high) AS high, -- 最高价:窗口内最大值MIN(low) AS low, -- 最低价:窗口内最小值SUM(volume) AS volume -- 成交量:窗口内总和
FROM crypto_source
GROUP BY SUBSTRING_INDEX(device_path, '.', -1), TUMBLE(time, INTERVAL '1' MINUTE); -- 按交易对和窗口分组3. 步骤 3:查询历史 K 线数据:
-- 查询比特币(btc_usdt)2024-10-01 09:00-10:00的分钟级K线
SELECT window_start AS kline_time,open, close, high, low, volume
FROM root.finance.crypto_kline.btc_usdt
WHERE window_start BETWEEN '2024-10-01 09:00:00' AND '2024-10-01 10:00:00'
ORDER BY window_start ASC;六、时序数据库选型终极建议:不同场景下的最优解
结合前文分析,针对不同企业规模与业务场景,时序数据库选型可遵循以下原则:
1. 中小规模监控场景(数据量 < 1TB / 年,写入 < 1 万条 / 秒)
- 推荐产品:Prometheus(开源)、InfluxDB OSS
- 适用场景:服务器运维监控、小型 IoT 项目
- 注意事项:若未来数据量可能增长,建议预留扩展接口(如提前设计标准化数据模型),避免后期迁移成本。
2. 中大规模业务场景(数据量 1TB~100TB / 年,写入 1 万~10 万条 / 秒)
- 推荐产品:Apache IoTDB(开源)
- 适用场景:工业 IoT、智慧能源、中型金融项目
- 优势:性能优异、成本低、生态兼容性好,支持 SQL 操作,开发运维门槛低。
3. 大规模关键业务场景(数据量 > 100TB / 年,写入 > 10 万条 / 秒)
- 推荐产品:Timecho(IoTDB 企业版)
- 适用场景:大型工业集团、省级电网、头部金融机构
- 优势:提供高可用集群、专业运维支持、定制化开发(如金融级数据加密、工业级故障自愈),满足关键业务的稳定性与安全性需求(企业版官网:https://timecho.com)。
七、立即体验:IoTDB 完整部署与运维步骤
若你已确定选型方向,可通过以下详细操作步骤快速部署、运维 IoTDB:
7.1 开源版 IoTDB 部署(Linux 环境)
步骤 1:下载与解压
# 1. 下载最新版IoTDB(1.2.2版本为例)
wget https://iotdb.apache.org/zh/Download/files/apache-iotdb-1.2.2-all-bin.zip -O iotdb-1.2.2.zip# 2. 解压到/opt目录
unzip iotdb-1.2.2.zip -d /opt/
# 重命名目录(简化路径)
mv /opt/apache-iotdb-1.2.2-all-bin /opt/iotdb-1.2.2步骤 2:配置调整(优化性能)
# 编辑核心配置文件
vim /opt/iotdb-1.2.2/conf/iotdb-engine.properties# 关键参数调整(根据服务器配置修改,示例:8核16GB服务器)
# 1. 内存分配(建议为物理内存的50%)
system_memory_size=8G
# 2. 写入线程数(建议为CPU核心数的2倍)
write_thread_pool_size=16
# 3. 查询线程数(建议为CPU核心数的1倍)
query_thread_pool_size=8
# 4. 开启批量写入优化
enable_batch_write=true
# 5. 开启压缩(默认开启,确认参数)
enable_compression=true步骤 3:启动与验证
# 1. 启动IoTDB服务
cd /opt/iotdb-1.2.2/bin
./start-server.sh# 2. 验证服务是否启动成功(查看端口6667是否监听)
netstat -tulpn | grep 6667
# 若输出类似 "tcp6 0 0 :::6667 :::* LISTEN 12345/java" 则启动成功# 3. 连接CLI客户端
./start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root
# 成功连接后,输入 "SHOW STORAGE GROUP;" 应返回空列表(无存储组时)步骤 4:数据备份与恢复
# 1. 手动备份数据(备份所有存储组)
./iotdb-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root -e "BACKUP TO '/opt/iotdb_backup/20241001'"# 2. 恢复数据(从备份目录恢复)
./iotdb-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root -e "RESTORE FROM '/opt/iotdb_backup/20241001'"# 3. 配置自动备份(添加定时任务)
crontab -e
# 添加以下内容(每天凌晨2点自动备份)
0 2 * * * /opt/iotdb-1.2.2/bin/iotdb-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root -e "BACKUP TO '/opt/iotdb_backup/$(date +\%Y\%m\%d)'"7.2 企业版 Timecho 服务咨询
若需企业级支持(如高可用集群部署、跨地域灾备、技术培训),可通过以下方式获取服务:
- 访问 Timecho 官网:https://timecho.com
- 点击 “在线咨询”,提交业务需求(如 “工业 IoT 集群部署”“金融数据加密”);
- 专属工程师将在 12 小时内联系,提供定制化方案与免费试用(试用期 15 天,含 1 对 1 技术指导)。
在大数据时代,时序数据的价值挖掘离不开优秀的时序数据库。Apache IoTDB 凭借 “高性能、低成本、强生态、易操作” 的优势,在中外产品竞争中脱颖而出,无论是中小规模的轻量化部署,还是大规模关键业务的企业级应用,都能提供适配的解决方案。若在选型或实践中遇到问题,可通过 IoTDB 官方社区(https://iotdb.apache.org/zh/community.html)获取帮助,或联系 Timecho 企业版团队获取专业支持。







-Eclipse插件实现)




)






