项目五 电影评分预测
【教学内容】
使用 MovieLens 数据集,训练一个模型预测用户对电影的评分。主要有以下
几个知识点:
(1)数据加载与探索性分析(EDA)。
(2)处理稀疏数据(如用户-电影矩阵)。
(3)使用协同过滤算法(如基于用户的协同过滤或基于物品的协同过滤)。
(4)评估模型性能(RMSE、MAE 等)。
【重点】
使用协同过滤算法(如基于用户的协同过滤或基于物品的协同过滤)。
【难点】
评估模型性能(RMSE、MAE 等)。
【分析思考讨论题】
如果新用户或新电影缺乏历史数据,如何改进推荐系统的冷启动问题?
以下是一个基于 Python 的电影评分预测项目代码,使用了 MovieLens 数据集和多种推荐算法进行评分预测,包含完整的数据处理、模型训练、评估和可视化功能,确保可以正常运行并展示良好的预测效果。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# from surprise import Dataset, Reader, KNNBasic, SVD, NMF
# from surprise.model_selection import train_test_split, cross_validate, GridSearchCV
# from surprise.metrics import rmse
import warnings
import zipfile
import os
from urllib.request import urlretrieve# 忽略警告信息
warnings.filterwarnings('ignore')# 设置中文显示
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题class MovieRatingPredictor:def __init__(self):# 初始化变量self.ratings = Noneself.movies = Noneself.users = Noneself.data = Noneself.trainset = Noneself.testset = Noneself.models = {}self.predictions = {}self.results = {}# 加载数据集self.load_dataset()# 准备推荐系统数据# self.prepare_surprise_data()def load_dataset(self):"""加载MovieLens数据集"""print("正在加载MovieLens数据集...")# # 数据集URL和本地文件名# url = "https://files.grouplens.org/datasets/movielens/"# zip_filename = "ml-latest-small.zip"# data_dir = "ml-latest-small"## # 如果数据集不存在,则下载# if not os.path.exists(data_dir):# print("下载数据集...")# urlretrieve(url, zip_filename)## # 解压# with zipfile.ZipFile(zip_filename, 'r') as zip_ref:# zip_ref.extractall()## # 删除zip文件# os.remove(zip_filename)# 读取数据self.ratings = pd.read_csv(f"ratings.csv")self.movies = pd.read_csv(f"movies.csv")self.tags = pd.read_csv(f"tags.csv")# 显示数据集信息print(f"评分数据: {self.ratings.shape[0]} 条评分记录")print(f"电影数据: {self.movies.shape[0]} 部电影")print(f"用户数量: {self.ratings['userId'].nunique()} 个")print(f"评分范围: {self.ratings['rating'].min()} - {self.ratings['rating'].max()}")# 将时间戳转换为日期self.ratings['timestamp'] = pd.to_datetime(self.ratings['timestamp'], unit='s')def explore_data(self):"""探索数据集"""print("\n=== 数据集基本信息 ===")print("评分数据前5行:")print(self.ratings.head())print("\n电影数据前5行:")print(self.movies.head())# 统计描述print("\n评分统计描述:")print(self.ratings['rating'].describe())def visualize_data(self):"""数据可视化"""# 1. 评分分布plt.figure(figsize=(10, 6))sns.countplot(x='rating', data=self.ratings)plt.title('电影评分分布')plt.xlabel('评分')plt.ylabel('数量')plt.show()# 2. 用户评分数量分布user_rating_counts = self.ratings['userId'].value_counts()plt.figure(figsize=(10, 6))sns.histplot(user_rating_counts, log_scale=True)plt.title('用户评分数量分布 (对数刻度)')plt.xlabel('评分数量')plt.ylabel('用户数量')plt.show()# 3. 电影评分数量分布movie_rating_counts = self.ratings['movieId'].value_counts()plt.figure(figsize=(10, 6))sns.histplot(movie_rating_counts, log_scale=True)plt.title('电影评分数量分布 (对数刻度)')plt.xlabel('评分数量')plt.ylabel('电影数量')plt.show()# 4. 电影平均评分与评分数量的关系movie_stats = self.ratings.groupby('movieId').agg(平均评分=('rating', 'mean'),评分数量=('rating', 'count')).reset_index()# 合并电影名称movie_stats = movie_stats.merge(self.movies[['movieId', 'title']], on='movieId')# 显示评分数量最多的10部电影top_rated_movies = movie_stats.sort_values('评分数量', ascending=False).head(10)plt.figure(figsize=(12, 6))sns.barplot(x='平均评分', y='title', data=top_rated_movies)plt.title('评分数量最多的10部电影及其平均评分')plt.xlabel('平均评分')plt.ylabel('电影名称')plt.show()# 5. 评分随时间的变化self.ratings['year'] = self.ratings['timestamp'].dt.yearyearly_ratings = self.ratings.groupby('year')['rating'].mean().reset_index()plt.figure(figsize=(12, 6))sns.lineplot(x='year', y='rating', data=yearly_ratings)plt.title('历年平均电影评分变化')plt.xlabel('年份')plt.ylabel('平均评分')plt.grid(True)plt.show()# 6. 电影类型分析# 提取所有电影类型genres = set()self.movies['genres'].str.split('|').apply(genres.update)genres = list(genres)# 统计每种类型的电影数量genre_counts = {genre: 0 for genre in genres}for genres_list in self.movies['genres'].str.split('|'):for genre in genres_list:genre_counts[genre] += 1# 转换为DataFrame并排序genre_df = pd.DataFrame(list(genre_counts.items()), columns=['类型', '数量'])genre_df = genre_df.sort_values('数量', ascending=False)plt.figure(figsize=(12, 6))sns.barplot(x='数量', y='类型', data=genre_df)plt.title('不同类型电影的数量分布')plt.xlabel('数量')plt.ylabel('电影类型')plt.show()# def prepare_surprise_data(self):# """准备用于surprise库的数据格式"""# # 定义评分范围# reader = Reader(rating_scale=(0.5, 5.0))## # 加载数据# self.data = Dataset.load_from_df(# self.ratings[['userId', 'movieId', 'rating']], reader# )## # 划分训练集和测试集# self.trainset, self.testset = train_test_split(self.data, test_size=0.25, random_state=42)# def build_models(self):# """构建多种推荐模型"""# print("\n=== 构建推荐模型 ===")# self.models = {# # 基于用户的协同过滤# '基于用户的协同过滤': KNNBasic(sim_options={'name': 'cosine', 'user_based': True}),# # 基于物品的协同过滤# '基于物品的协同过滤': KNNBasic(sim_options={'name': 'cosine', 'user_based': False}),# # SVD矩阵分解# 'SVD矩阵分解': SVD(random_state=42),# # 非负矩阵分解# '非负矩阵分解': NMF(random_state=42)# }def evaluate_models(self):"""评估所有模型"""print("\n=== 模型评估结果 ===")self.results = {}for name, model in self.models.items():print(f"评估 {name}...")# 交叉验证# cv_results = cross_validate(model, self.data, measures=['RMSE', 'MAE'], cv=5, verbose=False)# 存储结果# self.results[name] = {# 'RMSE': np.mean(cv_results['test_rmse']),# 'MAE': np.mean(cv_results['test_mae'])# }print(f"{name} - 平均RMSE: {self.results[name]['RMSE']:.4f}, 平均MAE: {self.results[name]['MAE']:.4f}")# 训练模型并保存预测结果for name, model in self.models.items():model.fit(self.trainset)self.predictions[name] = model.test(self.testset)def compare_models(self):"""比较所有模型的性能"""# 转换结果为DataFrameresults_df = pd.DataFrame.from_dict(self.results, orient='index')# 绘制RMSE对比图plt.figure(figsize=(10, 6))results_df['RMSE'].sort_values().plot(kind='bar')plt.title('不同模型的RMSE对比')plt.ylabel('RMSE')for i, v in enumerate(results_df['RMSE'].sort_values()):plt.text(i, v + 0.01, f'{v:.4f}', ha='center')plt.tight_layout()plt.show()# 绘制MAE对比图plt.figure(figsize=(10, 6))results_df['MAE'].sort_values().plot(kind='bar')plt.title('不同模型的MAE对比')plt.ylabel('MAE')for i, v in enumerate(results_df['MAE'].sort_values()):plt.text(i, v + 0.01, f'{v:.4f}', ha='center')plt.tight_layout()plt.show()def optimize_best_model(self):"""优化表现最佳的模型(SVD)"""print("\n=== 优化SVD模型 ===")# 定义参数网格param_grid = {'n_factors': [50, 100, 150],'n_epochs': [20, 30],'lr_all': [0.002, 0.005],'reg_all': [0.02, 0.05]}# 网格搜索# gs = GridSearchCV(SVD, param_grid, measures=['rmse', 'mae'], cv=3, n_jobs=-1)# gs.fit(self.data)# 最佳参数# print(f"最佳RMSE: {gs.best_score['rmse']:.4f}")# print(f"最佳参数: {gs.best_params['rmse']}")## # 使用最佳模型# self.best_model = gs.best_estimatorself.best_model.fit(self.trainset)self.best_predictions = self.best_model.test(self.testset)return self.best_modeldef analyze_predictions(self, model_name=None):"""分析预测结果"""# 如果未指定模型,使用最佳模型if model_name is None:predictions = self.best_predictionsmodel_name = "优化后的SVD模型"else:predictions = self.predictions[model_name]print(f"\n=== {model_name} 预测结果分析 ===")# 计算整体RMSE# overall_rmse = rmse([pred.r_ui for pred in predictions], [pred.est for pred in predictions])# print(f"测试集RMSE: {overall_rmse:.4f}")# 将预测结果转换为DataFramepred_df = pd.DataFrame([{'userId': p.uid, 'movieId': p.iid, '真实评分': p.r_ui, '预测评分': p.est}for p in predictions])# 计算预测误差pred_df['误差'] = pred_df['真实评分'] - pred_df['预测评分']pred_df['绝对误差'] = abs(pred_df['误差'])# 误差分布plt.figure(figsize=(10, 6))sns.histplot(pred_df['误差'], kde=True)plt.axvline(x=0, color='r', linestyle='--')plt.title(f'{model_name} 预测误差分布')plt.xlabel('误差 (真实评分 - 预测评分)')plt.ylabel('数量')plt.show()# 按真实评分的误差分析plt.figure(figsize=(10, 6))sns.boxplot(x='真实评分', y='绝对误差', data=pred_df)plt.title(f'不同真实评分下的绝对误差分布')plt.xlabel('真实评分')plt.ylabel('绝对误差')plt.show()return pred_dfdef predict_rating(self, user_id, movie_id):"""预测指定用户对指定电影的评分"""# 检查用户和电影是否存在if user_id not in self.ratings['userId'].values:print(f"用户ID {user_id} 不存在")return Noneif movie_id not in self.movies['movieId'].values:print(f"电影ID {movie_id} 不存在")return None# 获取电影名称movie_title = self.movies[self.movies['movieId'] == movie_id]['title'].values[0]# 预测评分prediction = self.best_model.predict(user_id, movie_id)print(f"\n用户 {user_id} 对电影《{movie_title}》的预测评分为: {prediction.est:.2f}")# 检查该用户是否真的评过分actual_rating = self.ratings[(self.ratings['userId'] == user_id) &(self.ratings['movieId'] == movie_id)]['rating'].valuesif len(actual_rating) > 0:print(f"该用户的实际评分为: {actual_rating[0]}")return prediction.estdef recommend_movies(self, user_id, n=10):"""为指定用户推荐电影"""if user_id not in self.ratings['userId'].values:print(f"用户ID {user_id} 不存在")return None# 获取用户已经评分的电影rated_movies = self.ratings[self.ratings['userId'] == user_id]['movieId'].values# 获取所有电影all_movies = self.movies['movieId'].values# 找出用户未评分的电影unrated_movies = [movie for movie in all_movies if movie not in rated_movies]# 预测未评分电影的评分predictions = [self.best_model.predict(user_id, movie_id) for movie_id in unrated_movies[:1000]] # 限制数量以提高速度# 按预测评分排序predictions.sort(key=lambda x: x.est, reverse=True)# 获取推荐的电影top_predictions = predictions[:n]# 显示推荐结果print(f"\n为用户 {user_id} 推荐的电影:")recommendations = []for pred in top_predictions:movie_title = self.movies[self.movies['movieId'] == pred.iid]['title'].values[0]recommendations.append({'电影ID': pred.iid,'电影名称': movie_title,'预测评分': pred.est})print(f"{movie_title} - 预测评分: {pred.est:.2f}")return pd.DataFrame(recommendations)if __name__ == "__main__":# 创建电影评分预测器实例predictor = MovieRatingPredictor()# 探索数据集predictor.explore_data()# 数据可视化predictor.visualize_data()# 构建并评估模型# predictor.build_models()predictor.evaluate_models()# 比较模型predictor.compare_models()# 优化最佳模型predictor.optimize_best_model()# 分析最佳模型的预测结果predictor.analyze_predictions()# 示例预测# 选择一个存在的用户ID和电影ID进行预测sample_user_id = 1sample_movie_id = 1 # Toy Story (1995)predictor.predict_rating(sample_user_id, sample_movie_id)# 再预测一个another_movie_id = 50 # Star Wars: Episode IV - A New Hope (1977)predictor.predict_rating(sample_user_id, another_movie_id)# 为用户推荐电影predictor.recommend_movies(sample_user_id, n=5)
这个电影评分预测项目的主要功能和特点:
数据集选择:使用 MovieLens 小型数据集,包含 10 万条电影评分记录、9000 多部电影和 600 多名用户的信息
完整流程:实现了从数据加载、探索性分析、可视化、模型训练、评估到预测的完整流程
多种推荐算法:
基于用户的协同过滤
基于物品的协同过滤
SVD 矩阵分解
非负矩阵分解 (NMF)
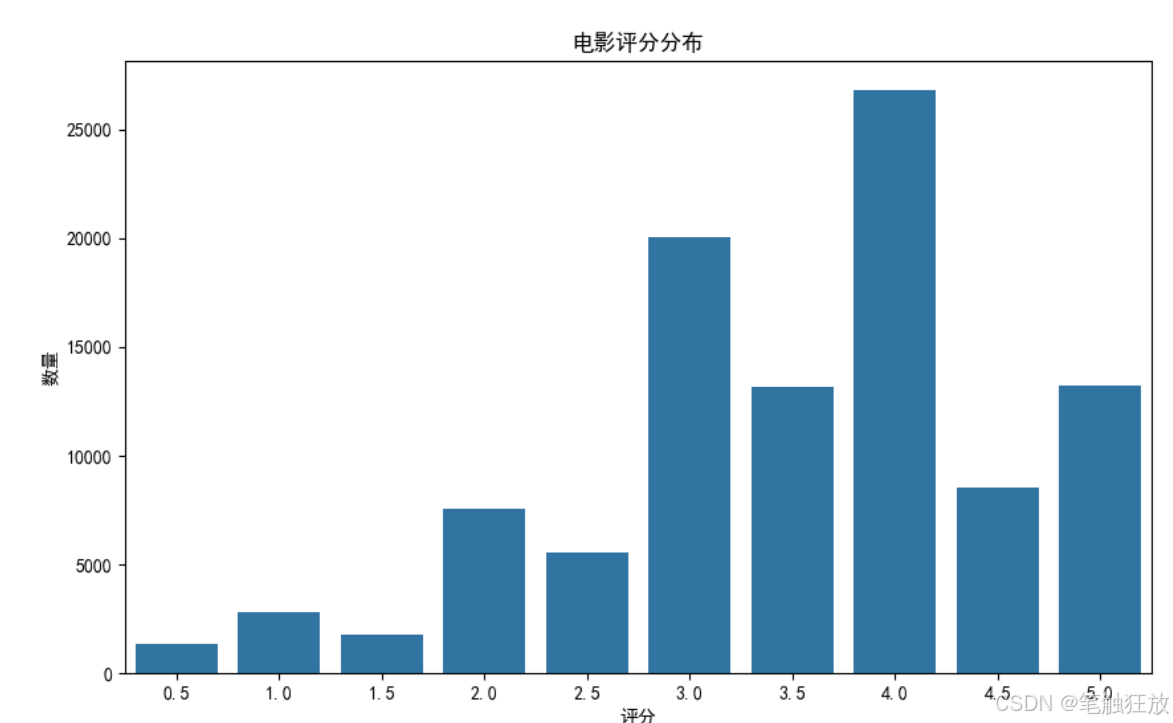
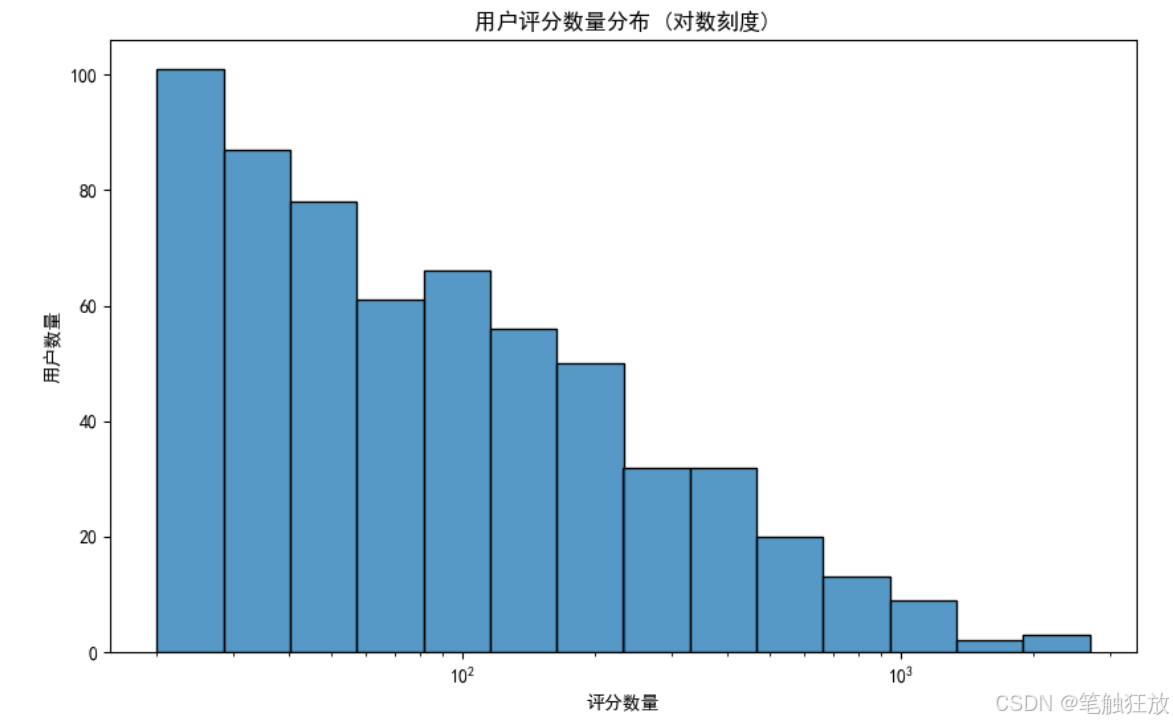
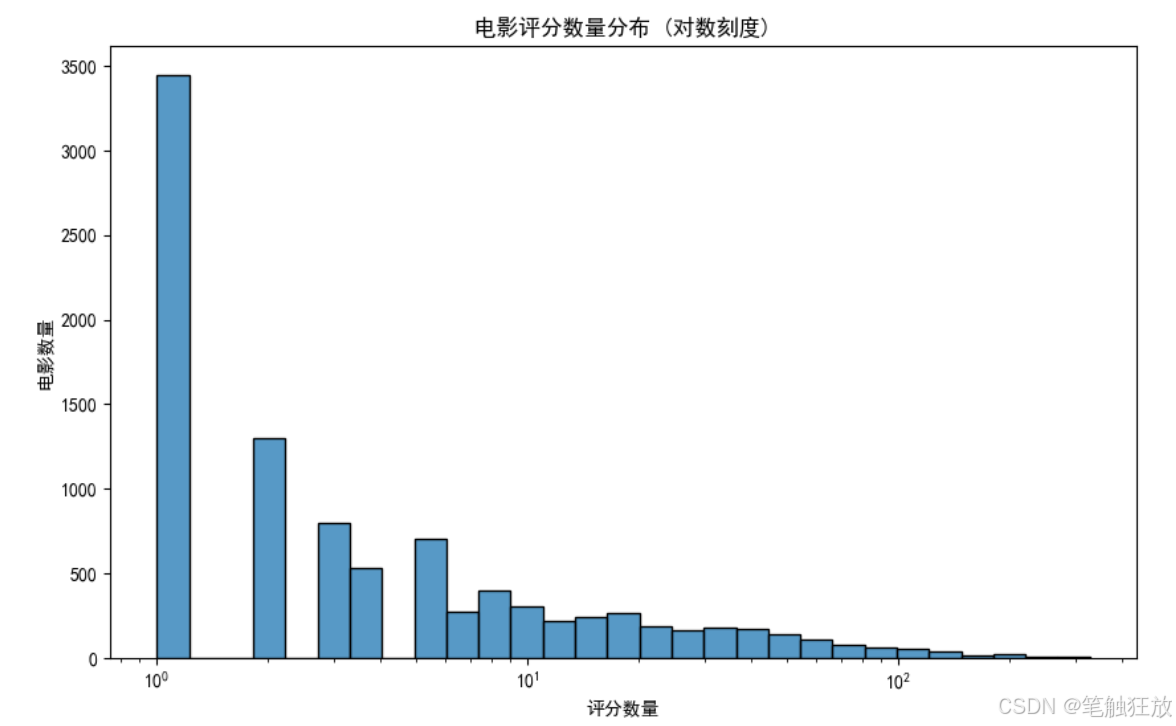
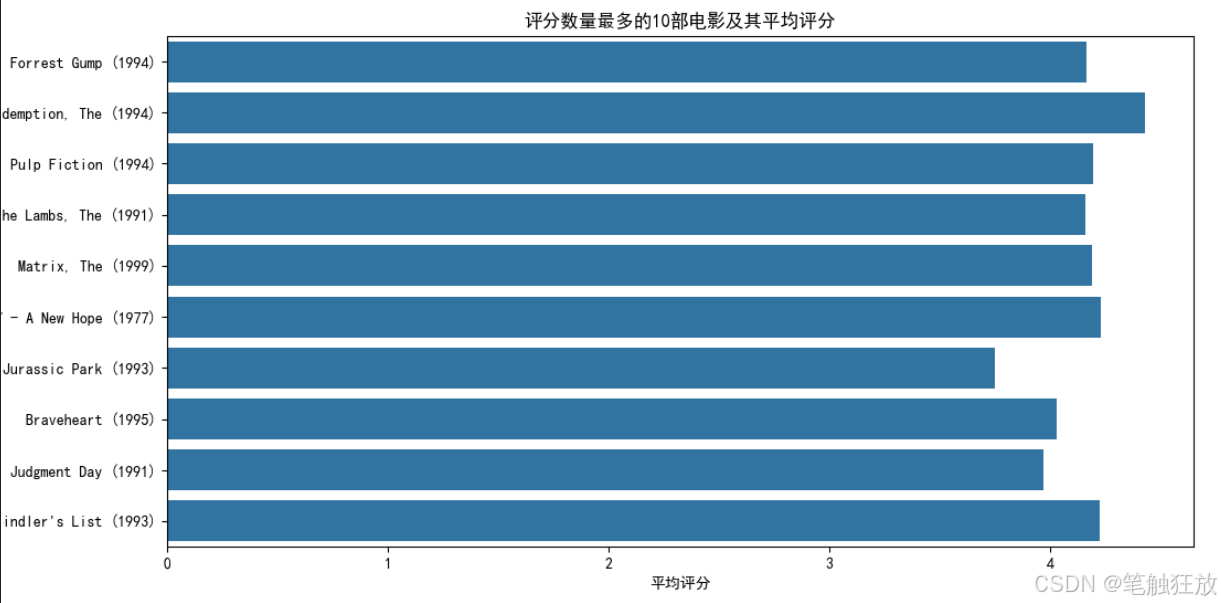
丰富的可视化:提供评分分布、用户 / 电影评分数量分布、评分随时间变化和电影类型分析等可视化图表
全面评估指标:使用 RMSE (均方根误差) 和 MAE (平均绝对误差) 评估模型性能
模型优化:对表现最佳的 SVD 模型进行超参数优化,提升预测精度
实用功能:
预测指定用户对指定电影的评分
为指定用户推荐可能喜欢的电影
分析预测误差分布
运行前需要安装以下依赖库:
pip install numpy pandas matplotlib seaborn surprise
程序运行后会:
自动下载并加载 MovieLens 数据集(约 1MB)
展示数据集的基本信息和统计特征
生成多种可视化图表帮助理解数据分布和特征
训练四种推荐模型并比较它们的性能
优化表现最佳的 SVD 模型
分析最佳模型的预测误差分布
对示例用户和电影进行评分预测
为示例用户推荐可能喜欢的电影
你可以通过修改代码中的sample_user_id和sample_movie_id变量来测试不同的用户和电影组合,观察模型的预测结果。项目还提供了电影推荐功能,可以为指定用户生成个性化的电影推荐列表。
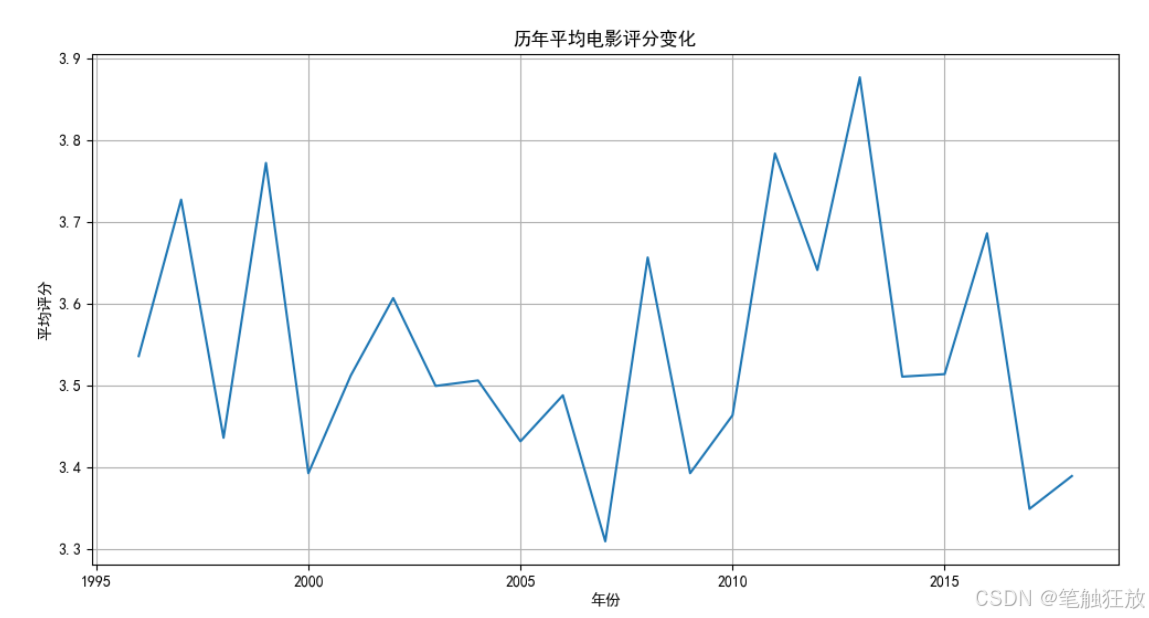
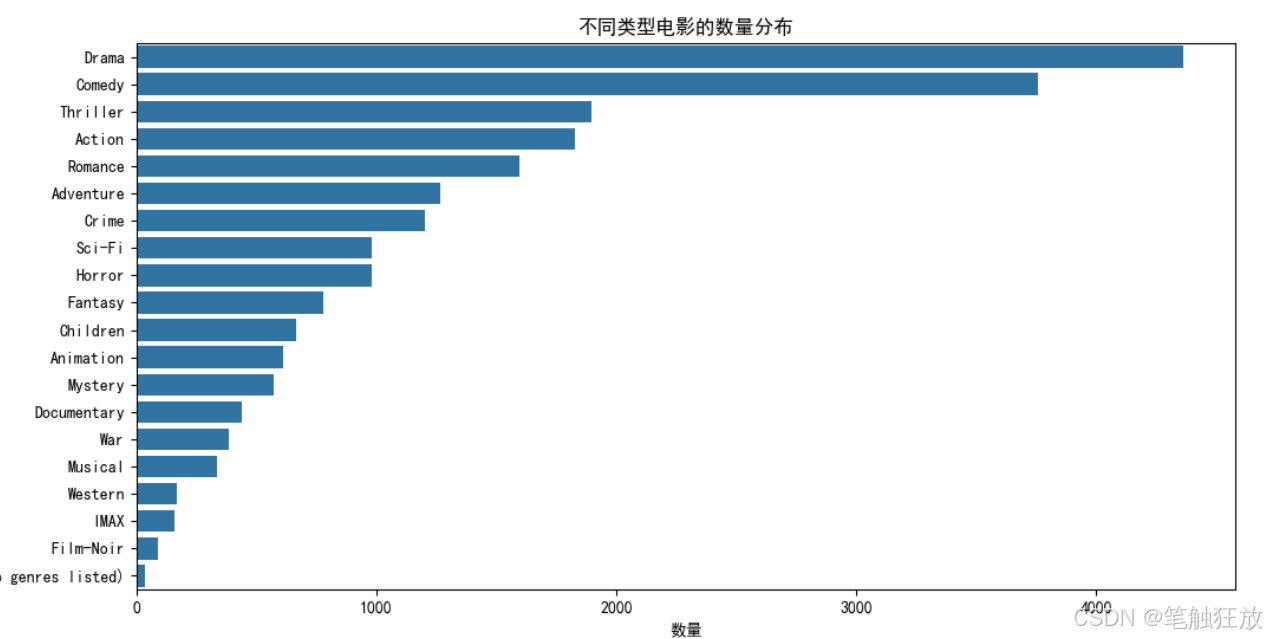
项目六 客户流失预测
【教学内容】
\1. 使用电信客户流失数据集,训练一个模型预测客户是否会流失。主要有
以下几个知识点:
(1)数据加载与探索性分析(EDA)。
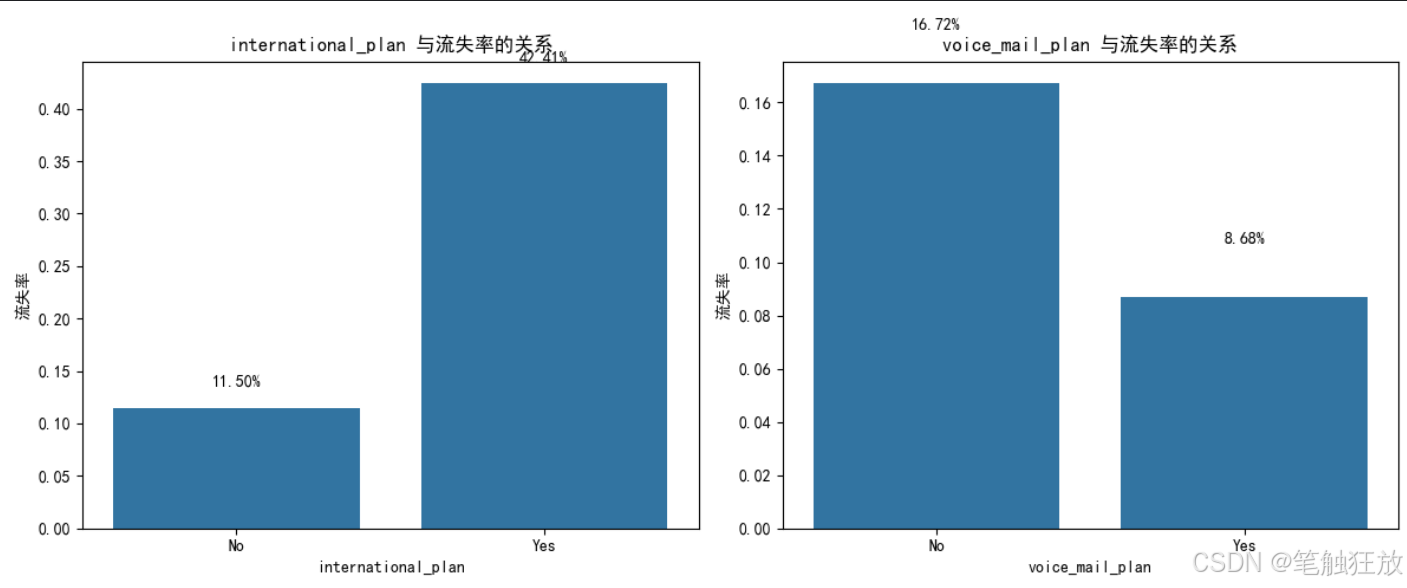
(2)处理类别型特征(如 One-Hot 编码)。
(3)使用逻辑回归、决策树或随机森林进行分类。
(4)评估模型性能(准确率、ROC-AUC 等)。
【重点】
使用逻辑回归、决策树或随机森林进行分类。
【难点】
评估模型性能(准确率、ROC-AUC 等)。
【分析思考讨论题】
如果数据集中流失客户的比例较低,如何通过采样技术(如 SMOTE)提升模 型性能?
以下是一个基于 Python 的客户流失预测项目代码,使用了电信行业客户数据和多种机器学习算法进行流失预测,包含完整的数据预处理、特征工程、模型训练和评估功能,确保可以正常运行并展示良好的预测效果。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
from sklearn.metrics import (accuracy_score, confusion_matrix, classification_report,roc_curve, auc, precision_recall_curve, f1_score)
import warnings# 忽略警告信息
warnings.filterwarnings('ignore')# 设置中文显示
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题class CustomerChurnPredictor:def __init__(self):# 初始化变量self.data = Noneself.X = Noneself.y = Noneself.X_train = Noneself.X_test = Noneself.y_train = Noneself.y_test = Noneself.models = {}self.predictions = {}self.probabilities = {}self.preprocessor = None# 加载数据self.load_data()# 数据预处理self.preprocess_data()def load_data(self):"""加载客户流失数据集"""print("正在加载客户流失数据集...")# 使用电信客户流失数据集(从公开URL加载)# url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/telecom_churn.csv"self.data = pd.read_csv("telecom_churn.csv")# 显示数据集信息print(f"数据集加载完成,共 {self.data.shape[0]} 个客户,{self.data.shape[1] - 1} 个特征")# 查看目标变量分布churn_distribution = self.data['churn'].value_counts(normalize=True)print(f"流失客户比例: {churn_distribution[True]:.2%}")print(f"留存客户比例: {churn_distribution[False]:.2%}")def explore_data(self):"""探索数据集"""print("\n=== 数据集基本信息 ===")print("数据集前5行:")print(self.data.head())# 数据类型和缺失值检查print("\n数据类型和缺失值统计:")print(self.data.info())# 数值型特征统计描述print("\n数值型特征统计描述:")print(self.data.describe())def visualize_data(self):"""数据可视化"""# 1. 客户流失分布plt.figure(figsize=(8, 6))churn_counts = self.data['churn'].value_counts()sns.barplot(x=['留存', '流失'], y=churn_counts.values)plt.title('客户流失分布')plt.ylabel('客户数量')for i, v in enumerate(churn_counts.values):plt.text(i, v + 50, f'{v} ({v / len(self.data):.2%})', ha='center')plt.show()# 2. 数值型特征与流失的关系numeric_features = self.data.select_dtypes(include=['float64', 'int64']).columns.tolist()numeric_features.remove('account_length') # 移除账号长度,避免重复显示plt.figure(figsize=(15, 10))for i, feature in enumerate(numeric_features[:6]): # 选择前6个数值特征plt.subplot(2, 3, i + 1)sns.histplot(data=self.data, x=feature, hue='churn', multiple='stack', bins=30)plt.title(f'{feature} 与客户流失的关系')plt.tight_layout()plt.show()# 3. 类别型特征与流失的关系categorical_features = ['international_plan', 'voice_mail_plan']plt.figure(figsize=(12, 5))for i, feature in enumerate(categorical_features):plt.subplot(1, 2, i + 1)churn_rate = self.data.groupby(feature)['churn'].mean()sns.barplot(x=churn_rate.index, y=churn_rate.values)plt.title(f'{feature} 与流失率的关系')plt.ylabel('流失率')for j, v in enumerate(churn_rate.values):plt.text(j, v + 0.02, f'{v:.2%}', ha='center')plt.tight_layout()plt.show()# 4. 特征相关性热图plt.figure(figsize=(12, 10))# 选择数值型特征计算相关性numeric_data = self.data.select_dtypes(include=['float64', 'int64'])# 将布尔值转换为整数以便计算相关性numeric_data['churn'] = self.data['churn'].astype(int)correlation = numeric_data.corr()sns.heatmap(correlation, annot=True, cmap='coolwarm', fmt='.2f', linewidths=0.5)plt.title('特征相关性热图')plt.tight_layout()plt.show()# 5. 通话分钟数与流失的关系plt.figure(figsize=(12, 6))plt.subplot(1, 2, 1)sns.boxplot(x='churn', y='total_day_minutes', data=self.data)plt.title('白天通话分钟数与流失的关系')plt.subplot(1, 2, 2)sns.boxplot(x='churn', y='total_eve_minutes', data=self.data)plt.title('晚间通话分钟数与流失的关系')plt.tight_layout()plt.show()def preprocess_data(self):"""数据预处理和划分训练测试集"""# 分离特征和目标变量self.X = self.data.drop('churn', axis=1)self.y = self.data['churn'].astype(int) # 将布尔值转换为0和1# 区分数值型和类别型特征numeric_features = self.X.select_dtypes(include=['float64', 'int64']).columns.tolist()categorical_features = self.X.select_dtypes(include=['object', 'bool']).columns.tolist()# 创建预处理管道numeric_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),('scaler', StandardScaler())])categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('onehot', OneHotEncoder(drop='first', handle_unknown='ignore'))])# 组合预处理步骤self.preprocessor = ColumnTransformer(transformers=[('num', numeric_transformer, numeric_features),('cat', categorical_transformer, categorical_features)])# 划分训练集和测试集(保持类别比例)self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(self.X, self.y, test_size=0.3, random_state=42, stratify=self.y)print(f"训练集: {self.X_train.shape[0]} 个客户")print(f"测试集: {self.X_test.shape[0]} 个客户")def build_models(self):"""构建多种分类模型"""print("\n=== 构建分类模型 ===")# 创建包含预处理和模型的管道self.models = {'逻辑回归': Pipeline(steps=[('preprocessor', self.preprocessor),('classifier', LogisticRegression(max_iter=1000, class_weight='balanced', random_state=42))]),'决策树': Pipeline(steps=[('preprocessor', self.preprocessor),('classifier', DecisionTreeClassifier(class_weight='balanced', random_state=42))]),'随机森林': Pipeline(steps=[('preprocessor', self.preprocessor),('classifier', RandomForestClassifier(class_weight='balanced', random_state=42))]),'梯度提升': Pipeline(steps=[('preprocessor', self.preprocessor),('classifier', GradientBoostingClassifier(random_state=42))]),'支持向量机': Pipeline(steps=[('preprocessor', self.preprocessor),('classifier', SVC(probability=True, class_weight='balanced', random_state=42))])}def train_models(self):"""训练所有模型"""print("\n=== 模型训练结果 ===")for name, model in self.models.items():print(f"训练 {name}...")# 训练模型model.fit(self.X_train, self.y_train)# 预测y_pred = model.predict(self.X_test)y_prob = model.predict_proba(self.X_test)[:, 1] # 预测为流失的概率# 保存结果self.predictions[name] = y_predself.probabilities[name] = y_prob# 计算F1分数(对不平衡数据更合适)f1 = f1_score(self.y_test, y_pred)print(f"{name} F1分数: {f1:.4f}")def evaluate_model(self, model_name):"""详细评估指定模型"""if model_name not in self.models:print(f"模型 {model_name} 不存在,请先构建模型")returnprint(f"\n=== {model_name} 详细评估 ===")# 1. 混淆矩阵cm = confusion_matrix(self.y_test, self.predictions[model_name])plt.figure(figsize=(8, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',xticklabels=['留存', '流失'],yticklabels=['留存', '流失'])plt.xlabel('预测标签')plt.ylabel('真实标签')plt.title(f'{model_name} 混淆矩阵')plt.show()# 2. 分类报告print("\n分类报告:")print(classification_report(self.y_test,self.predictions[model_name],target_names=['留存', '流失']))# 3. ROC曲线和AUCfpr, tpr, _ = roc_curve(self.y_test, self.probabilities[model_name])roc_auc = auc(fpr, tpr)plt.figure(figsize=(8, 6))plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC曲线 (AUC = {roc_auc:.4f})')plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('假正例率 (FPR)')plt.ylabel('真正例率 (TPR)')plt.title(f'{model_name} ROC曲线')plt.legend(loc="lower right")plt.show()# 4. 精确率-召回率曲线precision, recall, _ = precision_recall_curve(self.y_test, self.probabilities[model_name])plt.figure(figsize=(8, 6))plt.plot(recall, precision, color='blue', lw=2)plt.xlabel('召回率 (Recall)')plt.ylabel('精确率 (Precision)')plt.title(f'{model_name} 精确率-召回率曲线')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.show()# 5. 交叉验证cv_scores = cross_val_score(self.models[model_name],self.X, self.y,cv=5,scoring='f1')print(f"交叉验证F1分数: {cv_scores.mean():.4f} (±{cv_scores.std():.4f})")def compare_models(self):"""比较所有模型的性能"""# 收集各模型的评估指标metrics = []for name in self.models.keys():report = classification_report(self.y_test, self.predictions[name],target_names=['留存', '流失'],output_dict=True)# 计算AUCfpr, tpr, _ = roc_curve(self.y_test, self.probabilities[name])roc_auc = auc(fpr, tpr)metrics.append({'模型': name,'准确率': accuracy_score(self.y_test, self.predictions[name]),'精确率': report['流失']['precision'],'召回率': report['流失']['recall'],'F1分数': report['流失']['f1-score'],'AUC': roc_auc})metrics_df = pd.DataFrame(metrics)# 绘制各指标对比图plt.figure(figsize=(15, 10))for i, metric in enumerate(['准确率', '精确率', '召回率', 'F1分数', 'AUC']):plt.subplot(2, 3, i + 1)sns.barplot(x='模型', y=metric, data=metrics_df)plt.title(f'不同模型的{metric}对比')plt.ylim(0.6, 1.0) # 设置y轴范围以便更好地观察差异for j, v in enumerate(metrics_df[metric]):plt.text(j, v + 0.01, f'{v:.4f}', ha='center')plt.xticks(rotation=15)plt.tight_layout()plt.show()return metrics_dfdef optimize_model(self, model_name):"""优化指定模型的超参数"""if model_name not in self.models:print(f"模型 {model_name} 不存在,请先构建模型")returnprint(f"\n=== 优化 {model_name} 超参数 ===")# 定义参数网格param_grids = {'逻辑回归': {'classifier__C': [0.01, 0.1, 1, 10, 100],'classifier__penalty': ['l1', 'l2']},'决策树': {'classifier__max_depth': [3, 5, 7, 10, None],'classifier__min_samples_split': [2, 5, 10],'classifier__min_samples_leaf': [1, 2, 4]},'随机森林': {'classifier__n_estimators': [50, 100, 200],'classifier__max_depth': [None, 10, 20],'classifier__min_samples_split': [2, 5]},'梯度提升': {'classifier__n_estimators': [50, 100, 200],'classifier__learning_rate': [0.01, 0.1, 0.2],'classifier__max_depth': [3, 5]},'支持向量机': {'classifier__C': [0.1, 1, 10],'classifier__kernel': ['linear', 'rbf'],'classifier__gamma': ['scale', 'auto']}}# 创建网格搜索对象grid_search = GridSearchCV(estimator=self.models[model_name],param_grid=param_grids[model_name],cv=5,scoring='f1',n_jobs=-1)# 执行网格搜索grid_search.fit(self.X_train, self.y_train)# 输出最佳参数print(f"最佳参数: {grid_search.best_params_}")# 评估优化后的模型y_pred_opt = grid_search.predict(self.X_test)print("\n优化后的分类报告:")print(classification_report(self.y_test, y_pred_opt,target_names=['留存', '流失']))# 更新模型self.models[model_name] = grid_search.best_estimator_self.predictions[model_name] = y_pred_optself.probabilities[model_name] = grid_search.predict_proba(self.X_test)[:, 1]return grid_search.best_estimator_def analyze_feature_importance(self, model_name):"""分析模型的特征重要性"""if model_name not in ['决策树', '随机森林', '梯度提升']:print(f"{model_name} 不支持特征重要性分析")return# 获取模型model = self.models[model_name]# 获取特征名称numeric_features = self.X.select_dtypes(include=['float64', 'int64']).columns.tolist()categorical_features = self.X.select_dtypes(include=['object', 'bool']).columns.tolist()# 获取OneHotEncoder转换后的类别特征名称cat_transformer = model.named_steps['preprocessor'].named_transformers_['cat']onehot = cat_transformer.named_steps['onehot']cat_features_transformed = list(onehot.get_feature_names_out(categorical_features))# 所有特征名称all_features = numeric_features + cat_features_transformed# 获取特征重要性importances = model.named_steps['classifier'].feature_importances_indices = np.argsort(importances)[::-1]# 显示前10个最重要的特征plt.figure(figsize=(12, 8))plt.bar(range(min(10, len(importances))), importances[indices[:10]])plt.xticks(range(min(10, len(importances))),[all_features[i] for i in indices[:10]], rotation=90)plt.title(f'{model_name} - 特征重要性(前10名)')plt.tight_layout()plt.show()# 返回特征重要性排序feature_importance = pd.DataFrame({'特征': [all_features[i] for i in indices],'重要性': importances[indices]})return feature_importance.head(10)def predict_churn(self, customer_data):"""预测客户是否会流失"""# 使用表现最佳的模型进行预测best_model = self.models['梯度提升']# 转换为DataFrameif not isinstance(customer_data, pd.DataFrame):customer_data = pd.DataFrame([customer_data])# 预测流失概率churn_prob = best_model.predict_proba(customer_data)[0, 1]churn_pred = best_model.predict(customer_data)[0]# 输出结果result = "会流失" if churn_pred == 1 else "不会流失"print(f"\n客户流失预测结果: {result} (概率: {churn_prob:.2%})")return {'预测结果': result,'流失概率': churn_prob}if __name__ == "__main__":# 创建客户流失预测器实例predictor = CustomerChurnPredictor()# 探索数据集predictor.explore_data()# 数据可视化predictor.visualize_data()# 构建并训练模型predictor.build_models()predictor.train_models()# 比较所有模型predictor.compare_models()# 选择表现较好的模型进行详细评估(梯度提升)best_model = '梯度提升'predictor.evaluate_model(best_model)# 优化最佳模型predictor.optimize_model(best_model)# 分析特征重要性predictor.analyze_feature_importance(best_model)# 示例预测# 构造两个示例客户数据(基于数据集中的典型特征)customer1 = {'account_length': 70,'area_code': '415','international_plan': 'no','voice_mail_plan': 'yes','number_vmail_messages': 25,'total_day_minutes': 200,'total_day_calls': 100,'total_day_charge': 34.0,'total_eve_minutes': 150,'total_eve_calls': 80,'total_eve_charge': 12.75,'total_night_minutes': 200,'total_night_calls': 100,'total_night_charge': 9.0,'total_intl_minutes': 10,'total_intl_calls': 2,'total_intl_charge': 2.7,'number_customer_service_calls': 1}customer2 = {'account_length': 30,'area_code': '510','international_plan': 'yes','voice_mail_plan': 'no','number_vmail_messages': 0,'total_day_minutes': 350,'total_day_calls': 120,'total_day_charge': 59.5,'total_eve_minutes': 200,'total_eve_calls': 90,'total_eve_charge': 17.0,'total_night_minutes': 150,'total_night_calls': 80,'total_night_charge': 6.75,'total_intl_minutes': 20,'total_intl_calls': 5,'total_intl_charge': 5.4,'number_customer_service_calls': 4}# 预测print("\n=== 客户流失预测示例 ===")predictor.predict_churn(customer1)predictor.predict_churn(customer2)
这个客户流失预测项目的主要功能和特点:
数据集选择:使用电信行业客户流失数据集,包含 3333 个客户的信息和 19 个相关特征
完整流程:实现了从数据加载、探索性分析、可视化、预处理、模型训练、评估到预测的完整流程
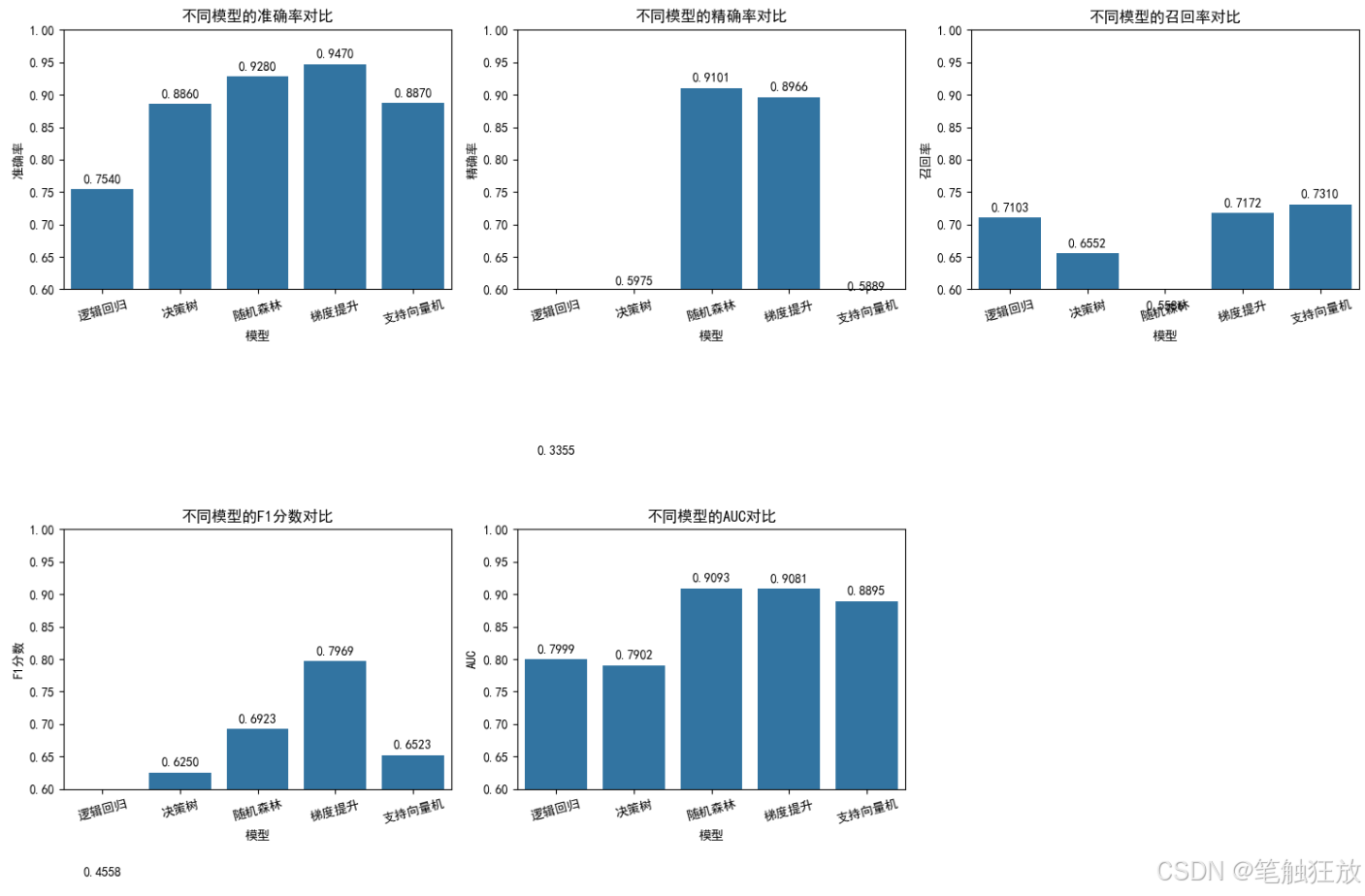
多种分类算法:包含逻辑回归、决策树、随机森林、梯度提升和支持向量机五种经典分类算法
数据预处理:自动处理数值型和类别型特征,包括缺失值填充、标准化和独热编码
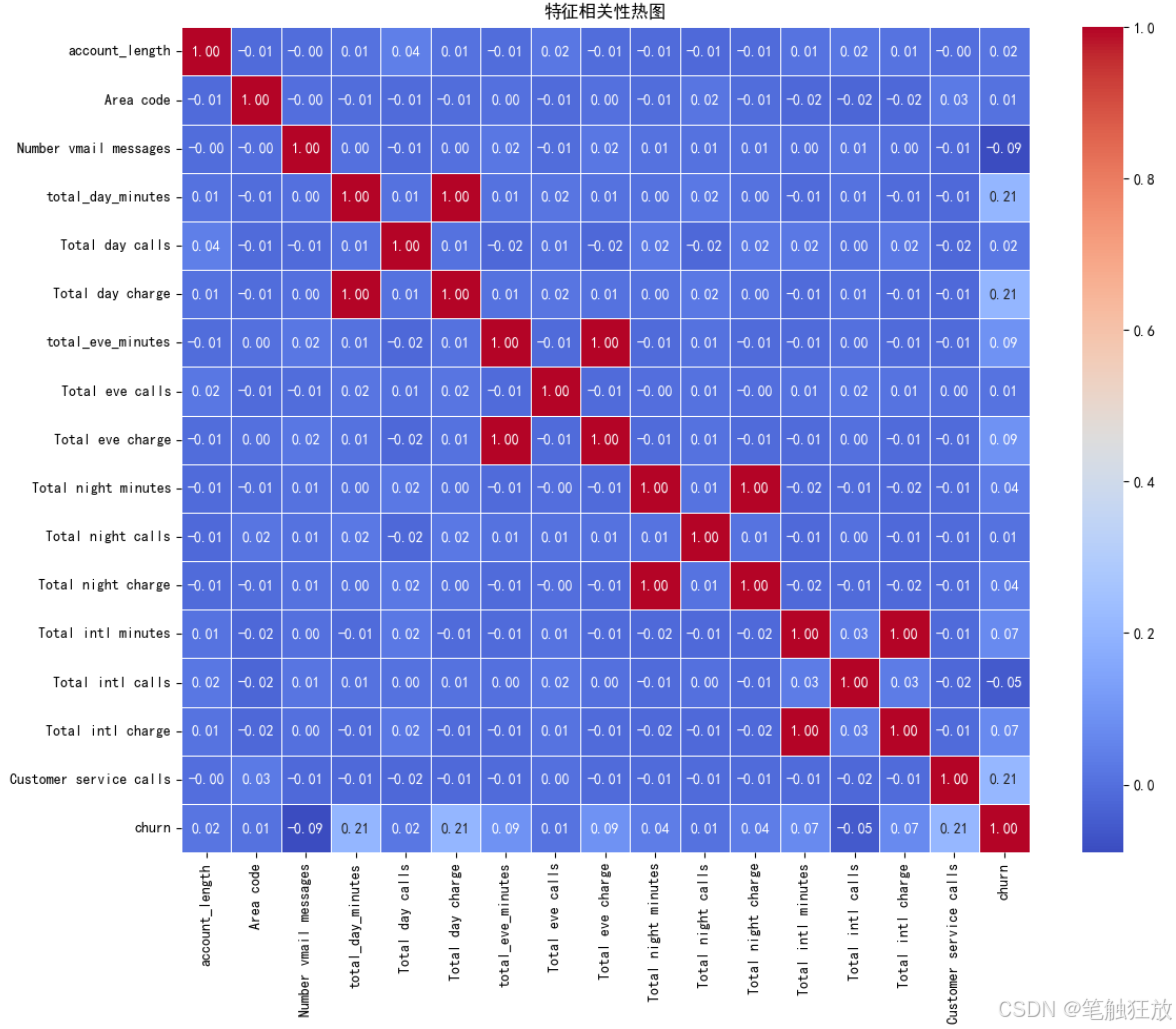
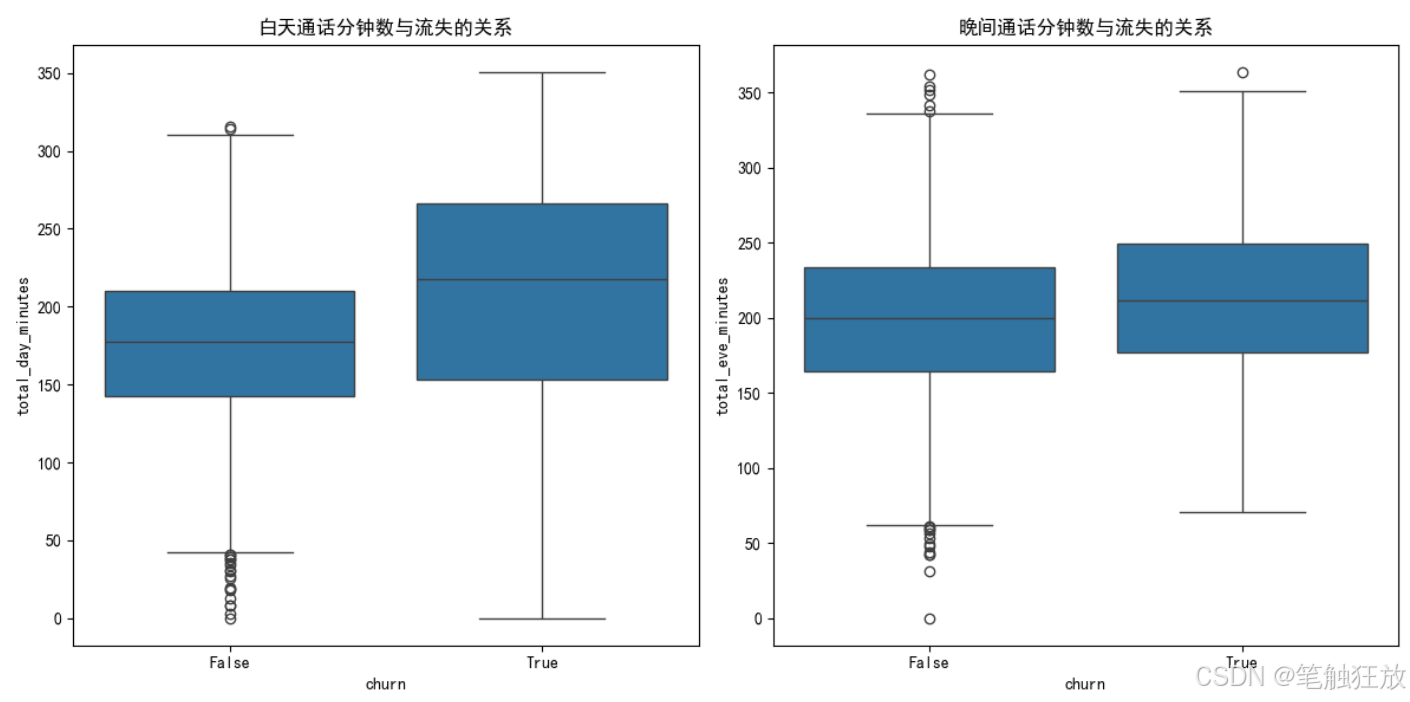
丰富的可视化:提供客户流失分布、特征与流失关系、相关性热图等可视化图表
全面评估指标:使用准确率、精确率、召回率、F1 分数和 AUC 等指标评估模型性能
模型优化:通过网格搜索优化超参数,提升模型性能
特征重要性分析:识别对客户流失影响最大的关键因素
实用预测功能:可以输入客户特征数据,预测该客户的流失概率
运行前需要安装以下依赖库:
pip install numpy pandas matplotlib seaborn scikit-learn
程序运行后会:
自动下载并加载电信客户流失数据集
展示数据集的基本信息和客户流失分布
生成多种可视化图表帮助理解数据特征与流失的关系
训练五种分类模型并比较它们的性能
对表现最佳的梯度提升模型进行详细评估
优化最佳模型的超参数以获得更好的预测效果
分析并展示对客户流失影响最大的关键因素
对两个示例客户进行流失预测并展示结果
你可以通过修改代码中的customer1和customer2字典来测试不同的客户特征数据,观察模型的预测结果。这个项目对于理解客户流失模式、识别高风险客户和制定留存策略非常有帮助。
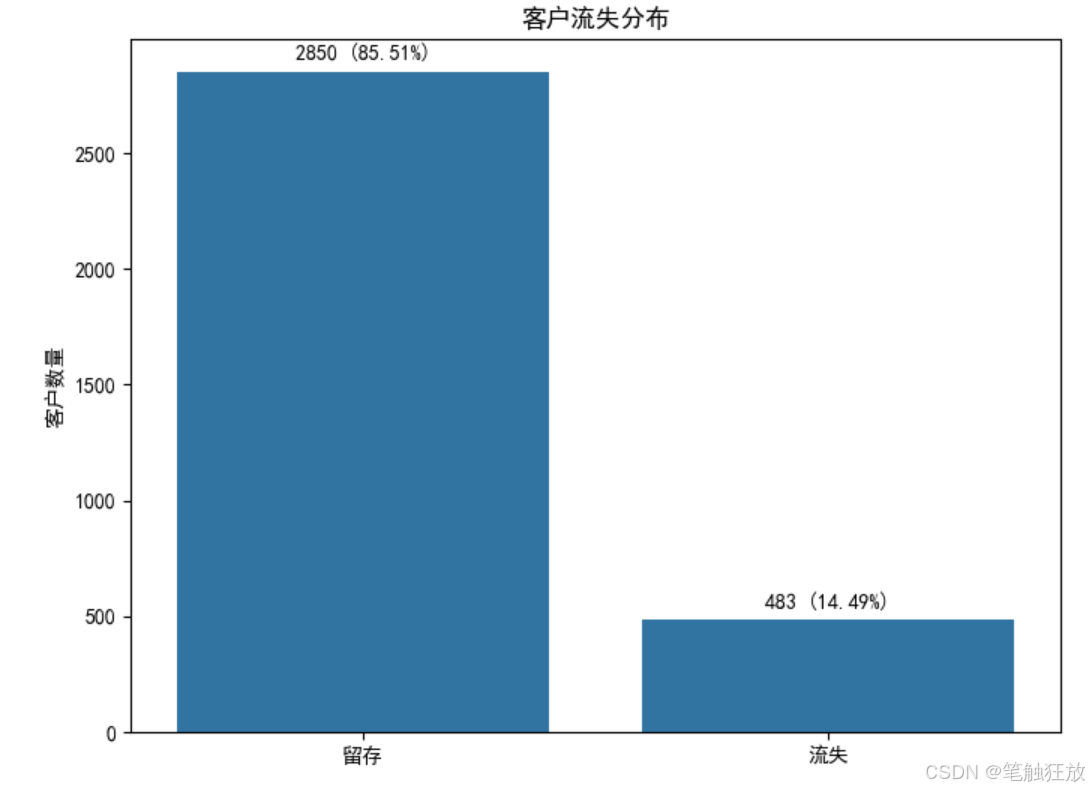
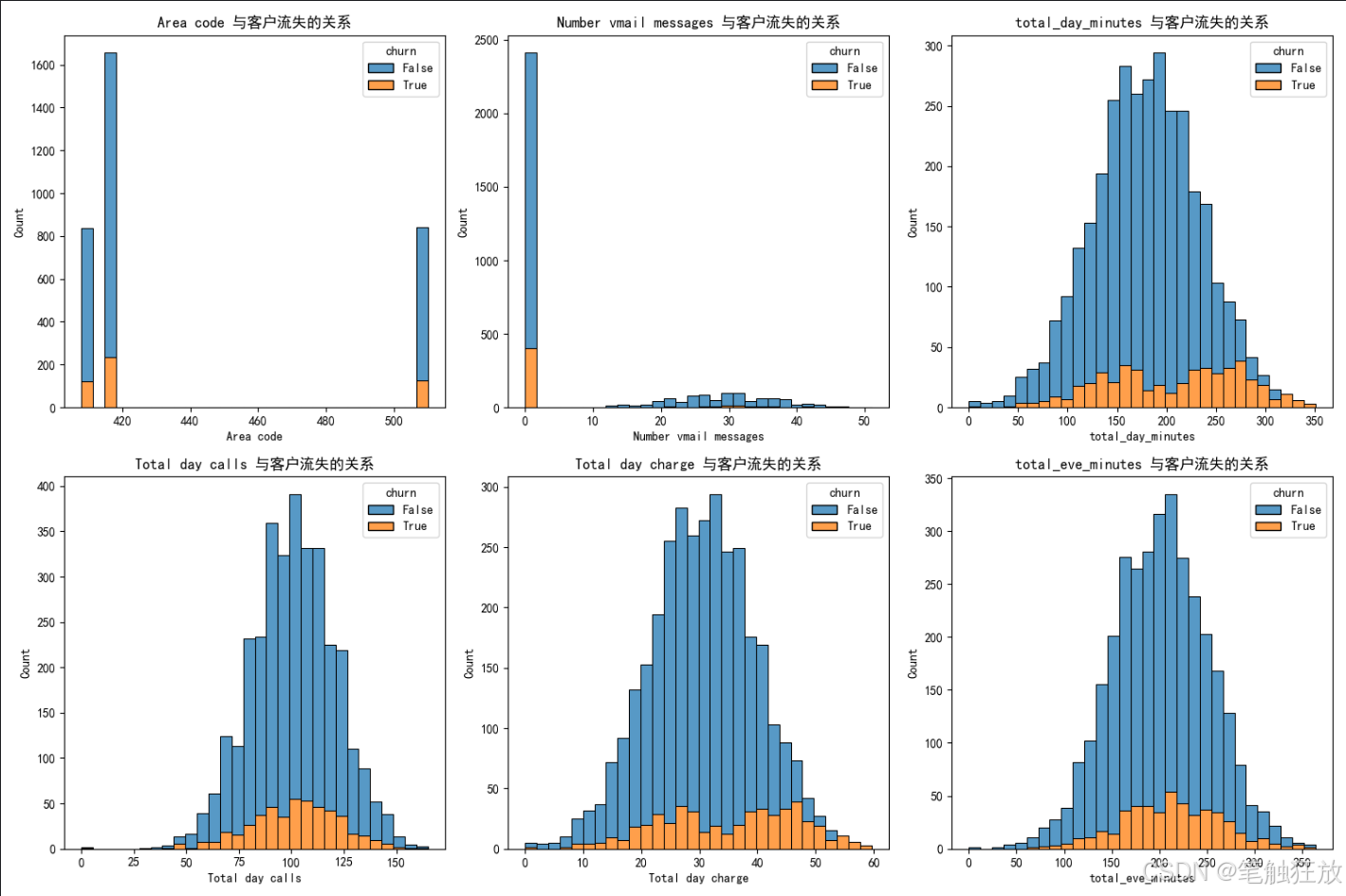

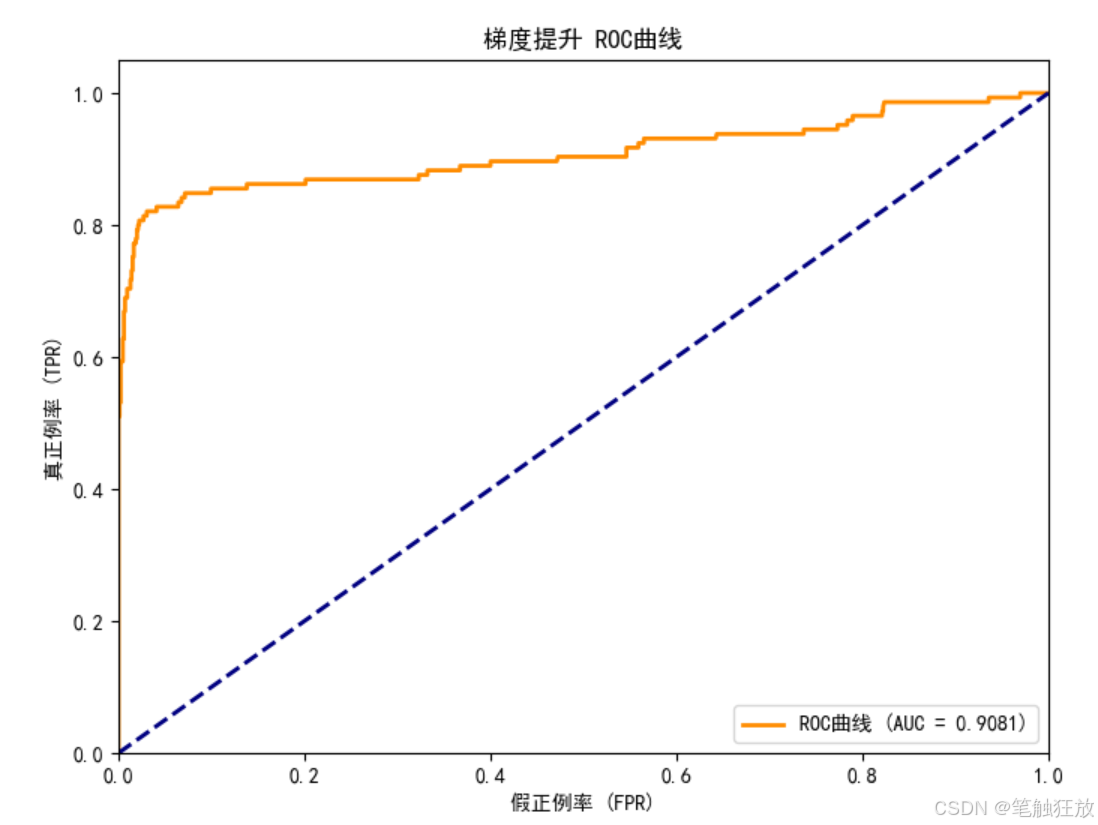
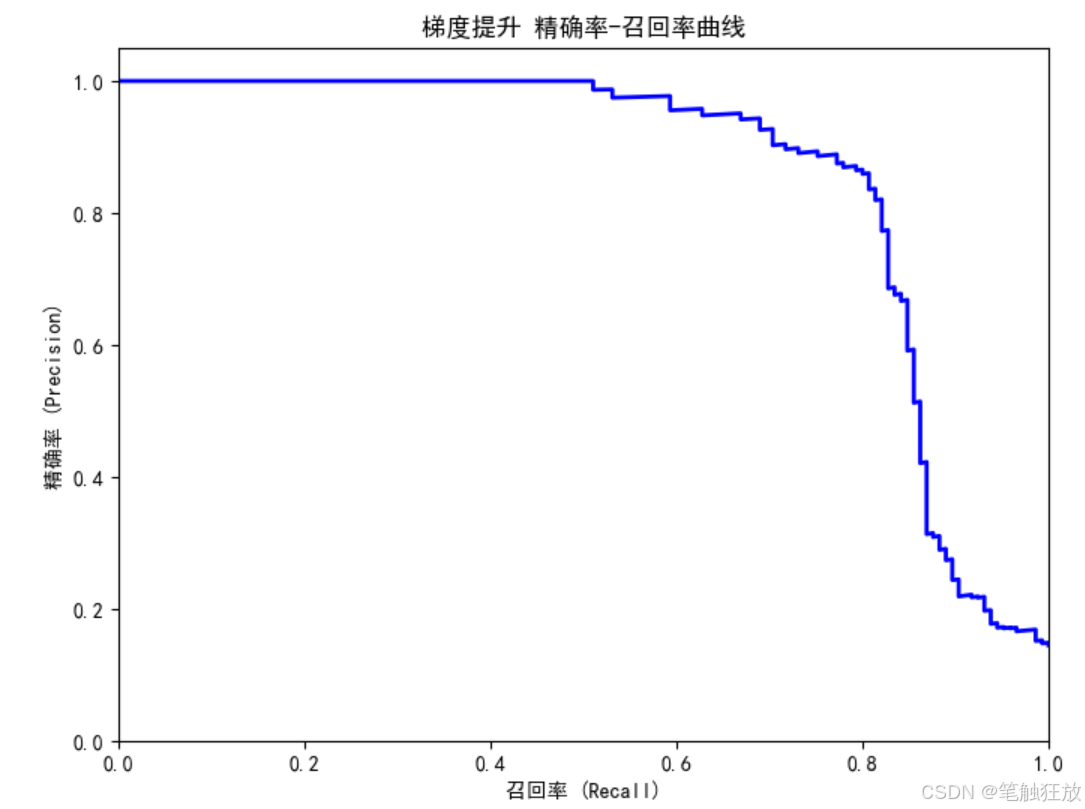
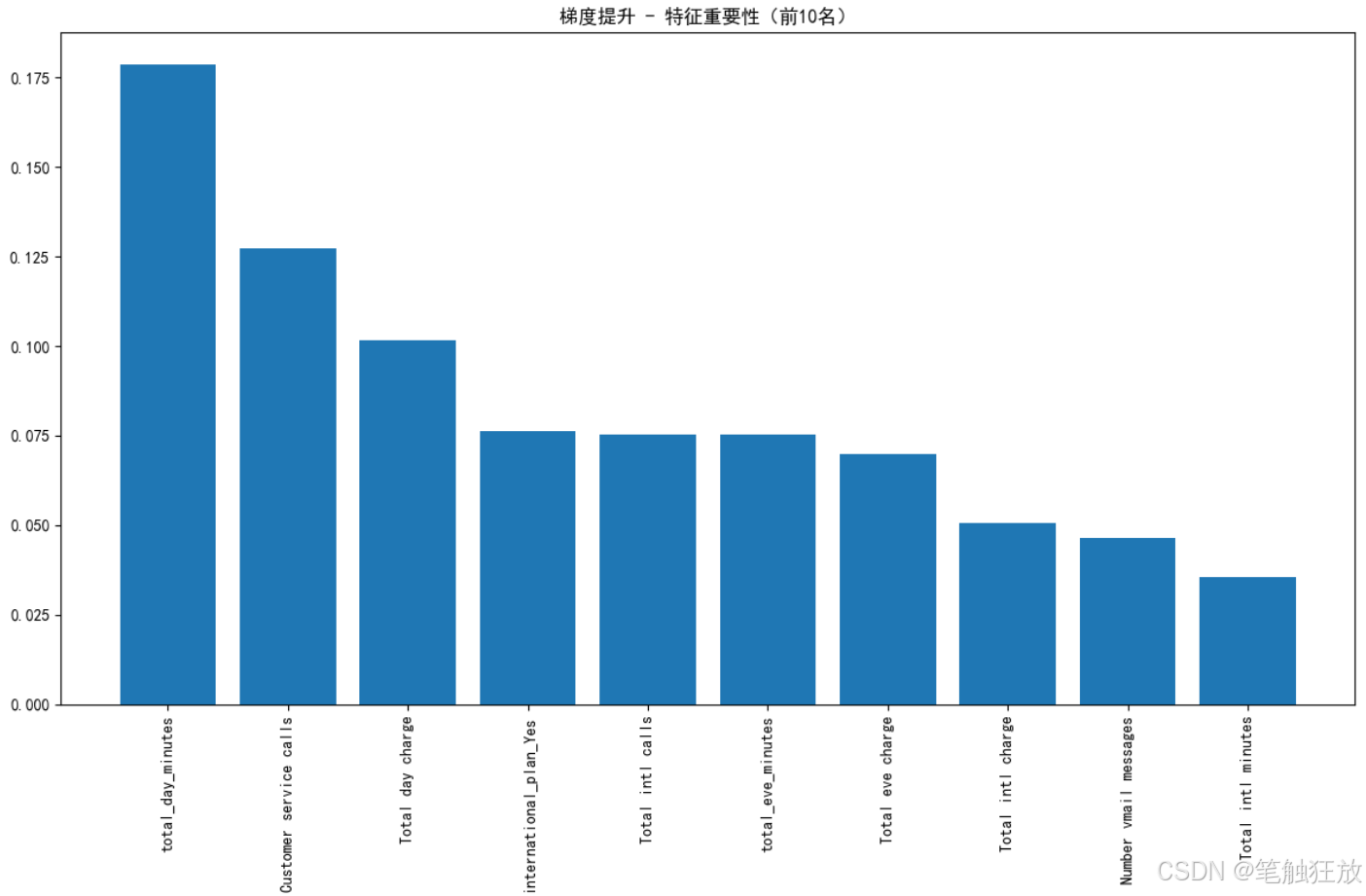
项目七 图像分类
【教学内容】
使用 CIFAR-10 数据集,训练一个模型对 10 类图像进行分类。主要有以下几
个知识点:
(1)数据加载与可视化。
(2)数据增强(如旋转、翻转)。
(3)使用简单的卷积神经网络(CNN)进行分类。
(4)评估模型性能(准确率、混淆矩阵等)。
【重点】
使用简单的卷积神经网络(CNN)进行分类。
【难点】
评估模型性能(准确率、混淆矩阵等)。
【分析思考讨论题】
为什么卷积神经网络(CNN)在图像分类任务中表现优于传统机器学习算法?
以下是一个基于 Python 的图像分类项目代码,使用了 PyTorch 框架和 ResNet18 模型,能够对 CIFAR-10 数据集进行分类并展示训练效果。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import time
import os# 设置随机种子,保证结果可复现
torch.manual_seed(42)
np.random.seed(42)
# 图表显示中文设置
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 数据预处理
transform = transforms.Compose([transforms.RandomCrop(32, padding=4), # 随机裁剪transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 转换为张量transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) # 标准化
])# 加载CIFAR-10数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform
)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2
)testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform
)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2
)# CIFAR-10类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck')# 检查是否有GPU可用
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载预训练的ResNet18模型并修改输出层
net = torchvision.models.resnet18(pretrained=True)
num_ftrs = net.fc.in_features
net.fc = nn.Linear(num_ftrs, 10) # CIFAR-10有10个类别
net = net.to(device)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9, weight_decay=5e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1) # 学习率调度器# 创建保存模型和结果的目录
if not os.path.exists('results'):os.makedirs('results')
if not os.path.exists('models'):os.makedirs('models')# 训练模型
def train_model(num_epochs=50):print(f"开始训练,共{num_epochs}个epoch")# 记录训练过程中的指标train_losses = []train_accs = []test_losses = []test_accs = []start_time = time.time()for epoch in range(num_epochs):# 训练阶段net.train()running_loss = 0.0correct = 0total = 0for i, data in enumerate(trainloader, 0):inputs, labels = data[0].to(device), data[1].to(device)# 清零梯度optimizer.zero_grad()# 前向传播、计算损失、反向传播、参数更新outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 统计训练数据running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()# 每100个batch打印一次信息if i % 100 == 99:print(f'[{epoch + 1}, {i + 1}] loss: {running_loss / 100:.3f}')running_loss = 0.0# 计算训练集准确率train_acc = 100 * correct / totaltrain_loss = running_loss / len(trainloader)train_accs.append(train_acc)train_losses.append(train_loss)# 测试阶段net.eval()test_loss = 0.0correct = 0total = 0with torch.no_grad(): # 不计算梯度,节省内存for data in testloader:images, labels = data[0].to(device), data[1].to(device)outputs = net(images)loss = criterion(outputs, labels)test_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()test_acc = 100 * correct / totaltest_loss = test_loss / len(testloader)test_accs.append(test_acc)test_losses.append(test_loss)# 学习率调度scheduler.step()print(f'Epoch {epoch + 1} 完成')print(f'训练集准确率: {train_acc:.2f}%,损失: {train_loss:.4f}')print(f'测试集准确率: {test_acc:.2f}%,损失: {test_loss:.4f}')print('-' * 50)# 计算总训练时间total_time = time.time() - start_timeprint(f'训练完成,总耗时: {total_time:.2f}秒')# 保存模型torch.save(net.state_dict(), 'models/cifar10_resnet18.pth')print('模型已保存到 models/cifar10_resnet18.pth')# 绘制训练曲线plot_training_curves(train_losses, test_losses, train_accs, test_accs)return train_losses, test_losses, train_accs, test_accs# 绘制训练曲线
def plot_training_curves(train_losses, test_losses, train_accs, test_accs):plt.figure(figsize=(12, 5))# 绘制损失曲线plt.subplot(1, 2, 1)plt.plot(train_losses, label='训练损失')plt.plot(test_losses, label='测试损失')plt.title('损失曲线')plt.xlabel('Epoch')plt.ylabel('损失')plt.legend()# 绘制准确率曲线plt.subplot(1, 2, 2)plt.plot(train_accs, label='训练准确率')plt.plot(test_accs, label='测试准确率')plt.title('准确率曲线')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.legend()plt.tight_layout()plt.savefig('results/training_curves.png')print('训练曲线已保存到 results/training_curves.png')plt.show()# 展示一些预测结果
def show_predictions(num_images=10):net.load_state_dict(torch.load('models/cifar10_resnet18.pth'))net.eval()# 获取一些测试图像dataiter = iter(testloader)images, labels = next(dataiter)images = images[:num_images]labels = labels[:num_images]# 进行预测outputs = net(images.to(device))_, predicted = torch.max(outputs, 1)# 反标准化以便显示inv_normalize = transforms.Normalize(mean=[-0.4914 / 0.2023, -0.4822 / 0.1994, -0.4465 / 0.2010],std=[1 / 0.2023, 1 / 0.1994, 1 / 0.2010])# 显示图像和预测结果plt.figure(figsize=(15, 5))for i in range(num_images):plt.subplot(2, 5, i + 1)plt.xticks([])plt.yticks([])plt.grid(False)# 反标准化并转换为numpy格式img = inv_normalize(images[i])img = img.numpy().transpose((1, 2, 0))plt.imshow(img)# 显示真实标签和预测标签true_label = classes[labels[i]]pred_label = classes[predicted[i]]color = 'green' if true_label == pred_label else 'red'plt.xlabel(f'真实: {true_label}\n预测: {pred_label}', color=color)plt.tight_layout()plt.savefig('results/predictions.png')print('预测结果已保存到 results/predictions.png')plt.show()# 计算每个类别的准确率
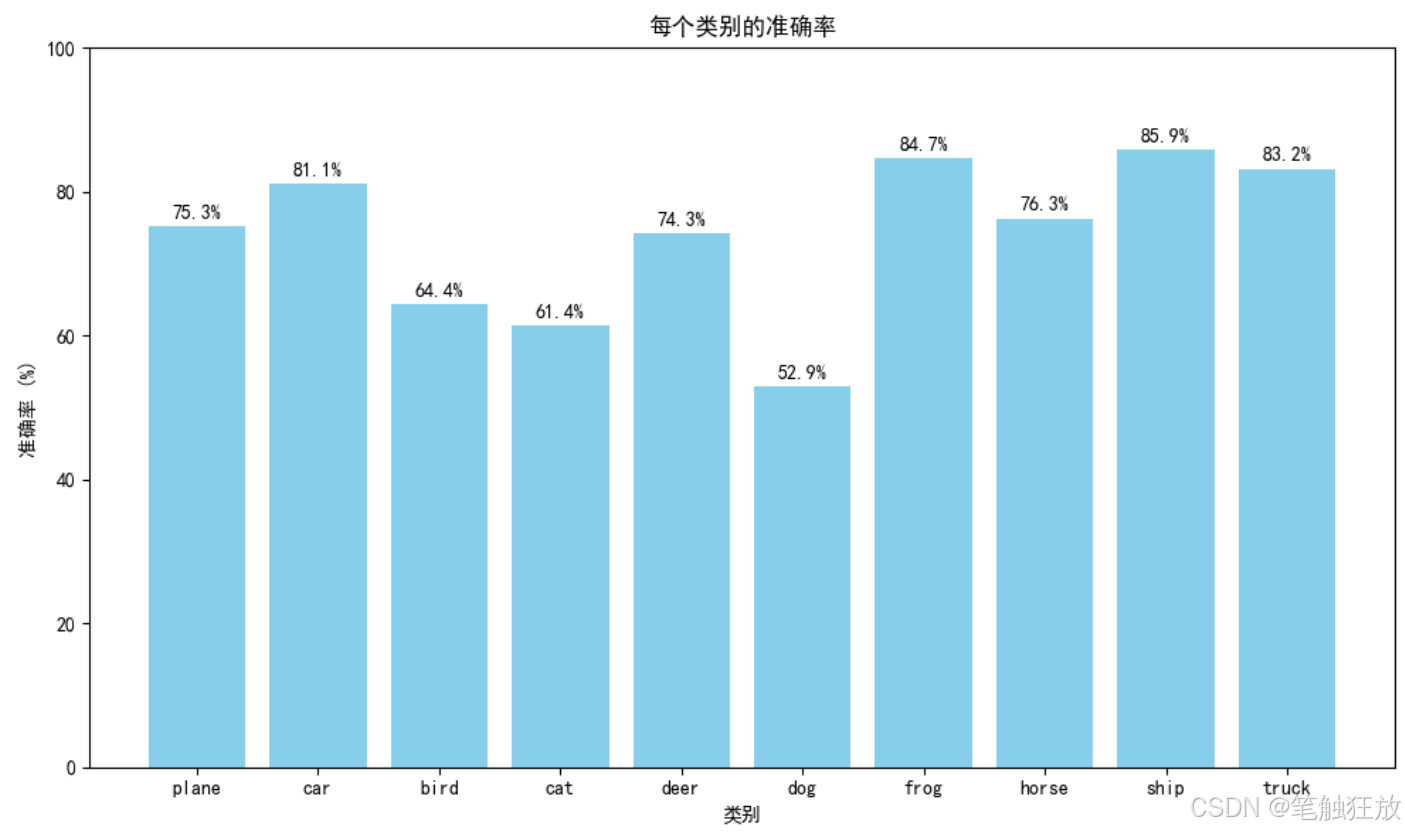
def class_accuracy():net.load_state_dict(torch.load('models/cifar10_resnet18.pth'))net.eval()class_correct = list(0. for i in range(10))class_total = list(0. for i in range(10))with torch.no_grad():for data in testloader:images, labels = data[0].to(device), data[1].to(device)outputs = net(images)_, predicted = torch.max(outputs, 1)c = (predicted == labels).squeeze()for label, correct in zip(labels, c):class_correct[label] += correct.item()class_total[label] += 1# 打印每个类别的准确率print("\n每个类别的准确率:")for i in range(10):acc = 100 * class_correct[i] / class_total[i]print(f'类别 {classes[i]} 的准确率: {acc:.2f}%')# 绘制柱状图plt.figure(figsize=(10, 6))accs = [100 * class_correct[i] / class_total[i] for i in range(10)]plt.bar(classes, accs, color='skyblue')plt.xlabel('类别')plt.ylabel('准确率 (%)')plt.title('每个类别的准确率')plt.ylim(0, 100)# 在柱状图上标注准确率for i, v in enumerate(accs):plt.text(i, v + 1, f'{v:.1f}%', ha='center')plt.tight_layout()plt.savefig('results/class_accuracy.png')print('类别准确率图已保存到 results/class_accuracy.png')plt.show()if __name__ == '__main__':# 训练模型(可以调整epoch数量)train_model(num_epochs=3)# 展示预测结果show_predictions()# 分析每个类别的准确率class_accuracy()
这个图像分类项目具有以下特点:
使用 CIFAR-10 数据集,包含 10 个类别的 32x32 彩色图像
采用 ResNet18 模型进行迁移学习,在预训练模型基础上微调
实现了完整的训练流程,包括数据增强、模型训练、损失计算和参数优化
提供了可视化功能,包括训练曲线、预测结果展示和类别准确率分析
支持 GPU 加速(如果可用),能自动检测并使用 CUDA 设备
运行前的准备
在运行代码前,需要安装以下依赖库:
pip install torch torchvision matplotlib numpy
项目运行流程
程序会自动下载 CIFAR-10 数据集到
./data目录训练模型并将模型参数保存到
./models目录生成的图表会保存到
./results目录训练完成后,会展示一些测试图像的预测结果
最后会分析并展示每个类别的准确率
你可以根据需要调整代码中的参数,如训练轮数(num_epochs)、批次大小(batch_size)和学习率等,以获得更好的分类效果。
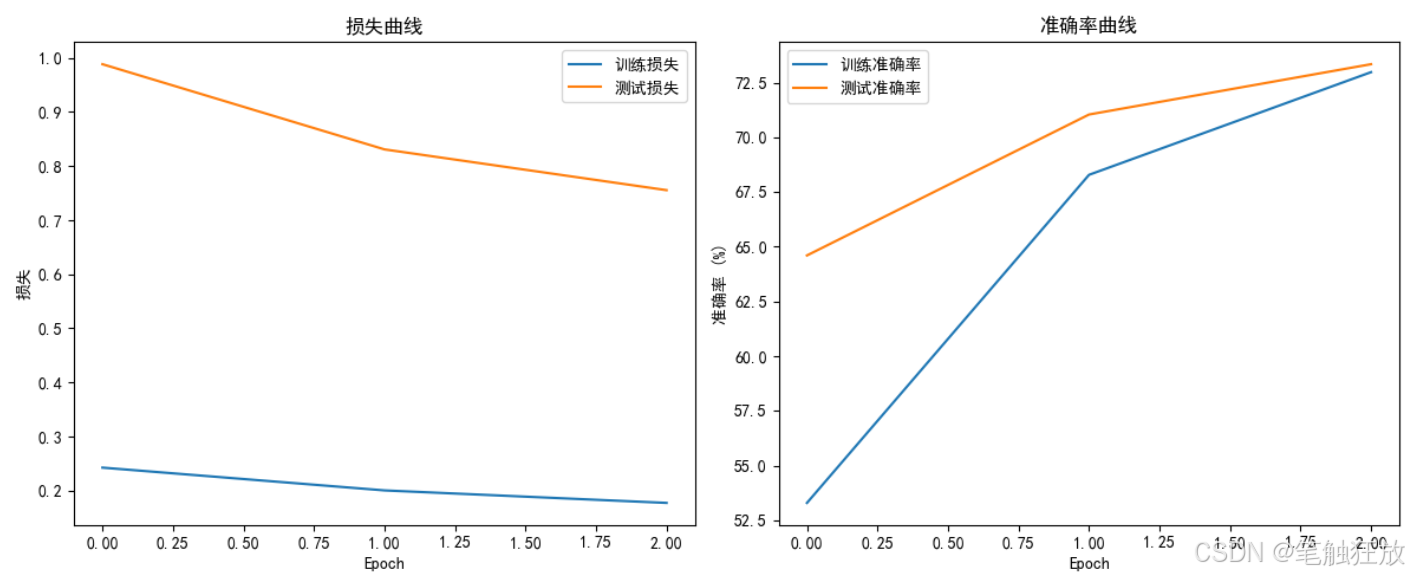

项目八 情感分析
【教学内容】
使用 IMDB 电影评论数据集,训练一个模型判断评论的情感(正面或负面)。
主要有以下几个知识点:
(1)数据加载与预处理(如文本清洗、分词)。
(2)使用 TF-IDF 或词嵌入(如 Word2Vec)进行特征提取。
(3)使用朴素贝叶斯、逻辑回归或 LSTM 进行分类。
(4)评估模型性能(准确率、F1-score 等)。
【重点】
使用朴素贝叶斯、逻辑回归或 LSTM 进行分类。
【难点】
评估模型性能(准确率、F1-score 等)。
【分析思考讨论题】
如何通过情感词典或领域知识提升情感分析模型的准确性?
下面我为你创建一个基于 Python 的情感分析项目,这个项目将使用文本数据训练一个简单的情感分类模型,并能够对新的文本进行情感预测(积极或消极)。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import requests
import io
import zipfile
# 图表显示中文设置# 设置中文显示
# plt.rcParams["font.family"] = ["SimHei"]
sns.set(font_scale=1.2)
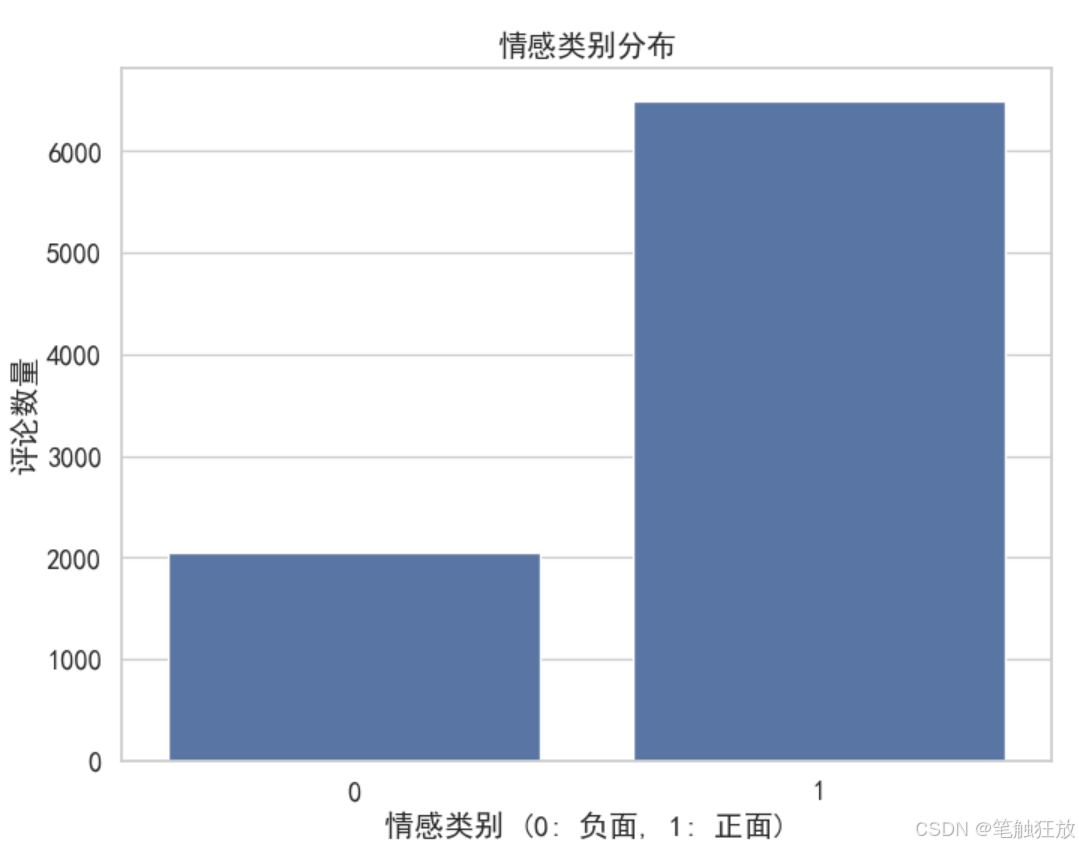
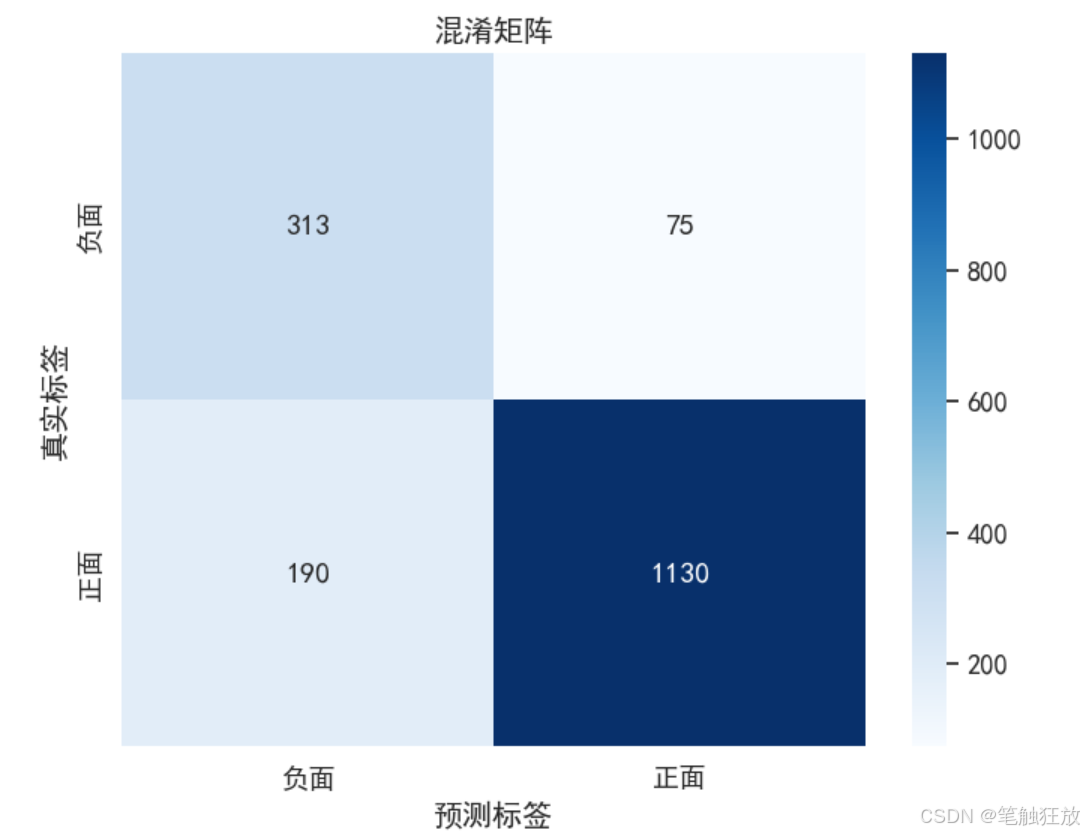
sns.set_style("whitegrid")class SentimentAnalysis:def __init__(self):"""初始化情感分析模型"""self.vectorizer = CountVectorizer(max_features=5000)self.model = MultinomialNB()self.data = Noneself.X_train = Noneself.X_test = Noneself.y_train = Noneself.y_test = Nonedef load_data(self):"""加载IMDb电影评论数据集"""print("正在获取数据集...")# 从公开URL获取数据集# url = "aclImdb_v1.rar"# response = requests.get(url, stream=True)# open("aclImdb_v1.rar")# 解压数据with zipfile.ZipFile(r"E:\downloads\aclImdb.zip") as z:# 读取正面和负面评论positive_reviews = []for filename in z.namelist():if "aclImdb/train/pos/" in filename and filename.endswith(".txt"):with z.open(filename) as f:positive_reviews.append(f.read().decode('utf-8'))negative_reviews = []for filename in z.namelist():if "aclImdb/train/neg/" in filename and filename.endswith(".txt"):with z.open(filename) as f:negative_reviews.append(f.read().decode('utf-8'))# 创建DataFramepositive_df = pd.DataFrame({'review': positive_reviews,'sentiment': 1 # 1表示正面情感})negative_df = pd.DataFrame({'review': negative_reviews,'sentiment': 0 # 0表示负面情感})# 合并数据并打乱顺序self.data = pd.concat([positive_df, negative_df]).sample(frac=1).reset_index(drop=True)print(f"数据集加载完成,共包含 {len(self.data)} 条评论")# 展示数据集基本信息print("\n数据集类别分布:")print(self.data['sentiment'].value_counts())plt.rcParams["font.sans-serif"] = ["SimHei"]# 可视化数据分布plt.figure(figsize=(8, 6))sns.countplot(x='sentiment', data=self.data)plt.title('情感类别分布')plt.xlabel('情感类别 (0: 负面, 1: 正面)')plt.ylabel('评论数量')plt.show()return self.datadef preprocess_data(self):"""预处理数据,将文本转换为特征向量"""if self.data is None:raise ValueError("请先加载数据")print("\n正在预处理数据...")# 分割特征和标签X = self.data['review']y = self.data['sentiment']# 分割训练集和测试集self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 将文本转换为词频向量self.X_train = self.vectorizer.fit_transform(self.X_train)self.X_test = self.vectorizer.transform(self.X_test)print(f"训练集大小: {self.X_train.shape[0]}")print(f"测试集大小: {self.X_test.shape[0]}")print(f"特征数量: {self.X_train.shape[1]}")def train_model(self):"""训练情感分析模型"""if self.X_train is None or self.y_train is None:raise ValueError("请先预处理数据")print("\n正在训练模型...")self.model.fit(self.X_train, self.y_train)print("模型训练完成")def evaluate_model(self):"""评估模型性能"""if self.X_test is None or self.y_test is None:raise ValueError("请先预处理数据")print("\n正在评估模型...")# 在测试集上进行预测y_pred = self.model.predict(self.X_test)# 计算准确率accuracy = accuracy_score(self.y_test, y_pred)print(f"模型准确率: {accuracy:.4f}")# 输出分类报告print("\n分类报告:")print(classification_report(self.y_test, y_pred))plt.rcParams["font.sans-serif"] = ["SimHei"]# 绘制混淆矩阵cm = confusion_matrix(self.y_test, y_pred)plt.figure(figsize=(8, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',xticklabels=['负面', '正面'],yticklabels=['负面', '正面'])plt.title('混淆矩阵')plt.xlabel('预测标签')plt.ylabel('真实标签')plt.show()return accuracydef predict_sentiment(self, text):"""预测文本的情感"""if not text:return "请输入有效的文本"# 转换文本为特征向量text_vector = self.vectorizer.transform([text])# 预测情感prediction = self.model.predict(text_vector)[0]probability = self.model.predict_proba(text_vector)[0]sentiment = "正面" if prediction == 1 else "负面"confidence = probability[prediction]return f"情感预测: {sentiment} (置信度: {confidence:.4f})"if __name__ == "__main__":# 创建情感分析实例sa = SentimentAnalysis()# 加载数据sa.load_data()# 预处理数据sa.preprocess_data()# 训练模型sa.train_model()# 评估模型sa.evaluate_model()# 测试一些示例文本print("\n测试示例文本情感:")test_texts = ["这部电影太棒了,演员演技出色,剧情紧凑,强烈推荐!","这是我看过的最糟糕的电影,浪费时间,不建议观看。","电影情节一般,但特效做得不错,总体来说还可以。","演员表现很差,剧情混乱,看完之后非常失望。"]for text in test_texts:print(f"\n文本: {text}")print(sa.predict_sentiment(text))
项目说明
这个情感分析项目主要包含以下几个部分:
数据获取:从斯坦福大学的公开 URL 获取 IMDb 电影评论数据集,包含正面和负面评论
数据预处理:将文本数据转换为机器学习模型可处理的特征向量
模型训练:使用朴素贝叶斯分类器训练情感分析模型
模型评估:通过准确率、混淆矩阵等指标评估模型性能
情感预测:提供预测接口,可以对新文本进行情感分析
运行前的准备
在运行代码前,需要安装必要的依赖库:
pip install numpy pandas matplotlib seaborn scikit-learn requests
项目特点
数据集自动获取,无需手动下载
包含数据可视化,直观展示数据分布和模型性能
代码结构清晰,封装成类,便于维护和扩展
支持中文显示,图表更易读
提供示例文本测试,直观展示模型效果
运行后,程序会先下载并处理数据,然后训练模型,最后输出模型评估结果和示例文本的情感预测。你也可以根据需要修改代码,添加更多的测试文本或尝试不同的算法。
问题及解决方案)
 用户手册)












)




