前言
Tensorboard最初是tensorflow的可视化工具,被用于机器学习实验的可视化,后来也适配了pytorch。Tensorboard是一个前端web界面,,能够从文件里面读取数据并展示它(比如损失、准确率、网络图)。具体使用可以参考。
tensorboard安装使用教程![]() https://zhuanlan.zhihu.com/p/420943896
https://zhuanlan.zhihu.com/p/420943896
Tensorboard的安装比较简单,这里我使用conda安装:
conda install tensorboard
tensorboard --version
# 2.19.01. 常用操作
1.1 导入库文件和生成对象
我们的第一个任务就是 将我们想可视化的数据写入到tensorboard可以读取的文件中,这可以通过下面来实现:
from torch.utils.tensorboard import SummaryWriter # 导入库文件
writer = SummaryWriter('./tensorboard') # 生成tensorboard对象
# ...
writer.close()1.2 数字 (scalar)
writer.add_scalar(tag, scalar_value, global_step=None, walltime=None) # tag (string): 曲线名称 。
# scalar_value (float): 数字常量值 。
# global_step (int, optional): 训练的当前步数。
# walltime (float, optional): 记录发生的时间,默认为 time.time()1.3 图像 (image)
writer.add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')# tag (string): 图像名称。
# img_tensor (torch.Tensor / numpy.array): 图像数据。
# global_step (int, optional): 训练的当前步数。
# walltime (float, optional): 记录发生的时间,默认为 time.time()
# dataformats (string, optional): 图像数据的格式,默认为 'CHW',即C:Channel。H:Height。W:Width。还可以是 'HWC' 或 'HW' 。1.4 直方图 (histogram)
writer.add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)# tag (string): 数据名称(名称相同,多次存入图片,可以形成视频效果)。
# values (torch.Tensor, numpy.array, or string/blobname): 直方图的数据(训练参数,注意力分数等)。
# global_step (int, optional): 训练的当前步数。
# bins (string, optional): 取值有 ‘tensorflow’、‘auto’、‘fd’ 等, 表示元素个数。
# walltime (float, optional): 记录发生的时间,默认为 time.time()。
# max_bins (int, optional): 表示元素最大个数。1.5 模型结构图 (graph)
writer.add_graph(model, input_to_model=None, verbose=False, **kwargs)# model (torch.nn.Module): 网络模型。
# input_to_model (torch.Tensor or list of torch.Tensor, optional): 模型输入参数1.6 嵌入向量 (embedding)
writer.add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='default', metadata_header=None)# mat (torch.Tensor or numpy.array): 数据点,shape:NxHxW。
# metadata (list or torch.Tensor or numpy.array, optional): 分类标签,长度=N。
# label_img (torch.Tensor, optional): shape:Nx1xHxW 的张量。
# global_step (int, optional): 训练的当前步数。
# tag (string, optional): 数据名称。1.7 打开web端展示结果
# 命令行输入:
tensorboard --logdir=tensorboard
2. Tensorboard 示例
2.1 代码示例
我们在上一个博客中的CNN训练代码中,补充tensorboard对应的部分,去记录并可视化训练过程中的训练数据、损失/精确度变化、权重/梯度变化等等。
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torch.utils.data import DataLoader
from CNN_network import Network,train_set
from torch.utils.tensorboard import SummaryWriterdef get_num_correct(preds, labels):return preds.argmax(dim=1).eq(labels).sum().item()network = Network()
train_loader = DataLoader(train_set, batch_size=100, shuffle=True)
optimizer = optim.Adam(network.parameters(), lr=0.01)# -生成对象(1.1),写入图像(1.3)和模型结构图(1.5)----------------------------------------
images, labels = next(iter(train_loader)) # get图像和标签
grid = torchvision.utils.make_grid(images) # 将一个包含多张图像的batch tensor,转换成一个可视化的图像网格writer = SummaryWriter('./tensorboard')writer.add_image('images', grid)
writer.add_graph(network, images)
# ---------------------------------------------------------------------------------for epoch in range(10):total_loss = 0total_correct = 0for batch in train_loader: # Get batchimages, labels = batchpreds = network(images) # Pass batchloss = F.cross_entropy(preds, labels) # calculate lossoptimizer.zero_grad() # 梯度归零loss.backward() # caculate gradientsoptimizer.step() # updata weighttotal_loss += loss.item()total_correct += get_num_correct(preds, labels)# -写入标量(1.2)和直方图(1.4)---------------------------------------------------------# 记录每个epoch的相应值,分别画曲线图和直方图writer.add_scalar('loss', total_loss, epoch)writer.add_scalar('accuracy', total_correct/len(train_loader), epoch)writer.add_scalar('number correct', total_correct/len(train_loader), epoch)writer.add_histogram('conv1.bias', network.conv1.bias, epoch)writer.add_histogram('conv1.weight', network.conv1.weight, epoch)writer.add_histogram('conv1.weight.grad', network.conv1.weight.grad, epoch)
# ---------------------------------------------------------------------------------print('epoch:', epoch, 'total_loss:', total_loss, 'total_correct:', total_correct)writer.close()执行上述代码后,我们会在./tensorboard文件夹中生成一个记录文件,我们可以通过执行下述命令,会返回一个网站,点击即可打开tensorboard web端查看
tensorboard --logdir=tensorboard
2.2 web可视化结果展示
点击进入后,首页大致是下面这样,这里蓝色方框里就对应刚刚在代码里添加的 标量图、直方图等等
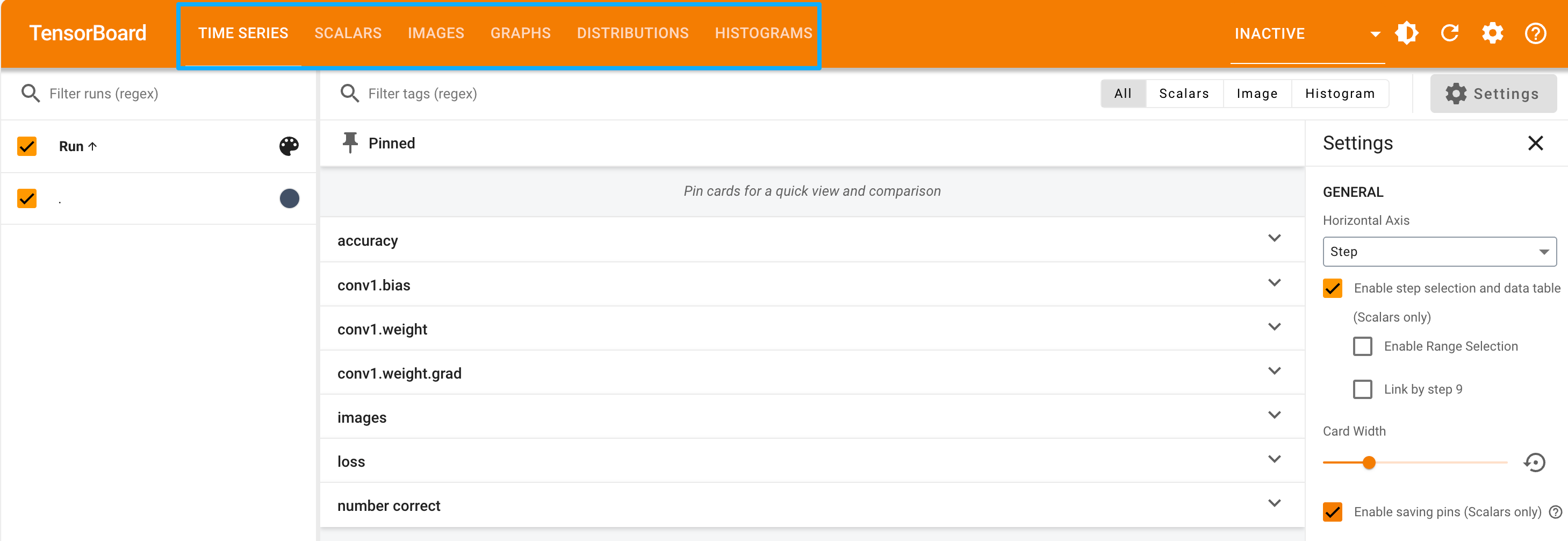
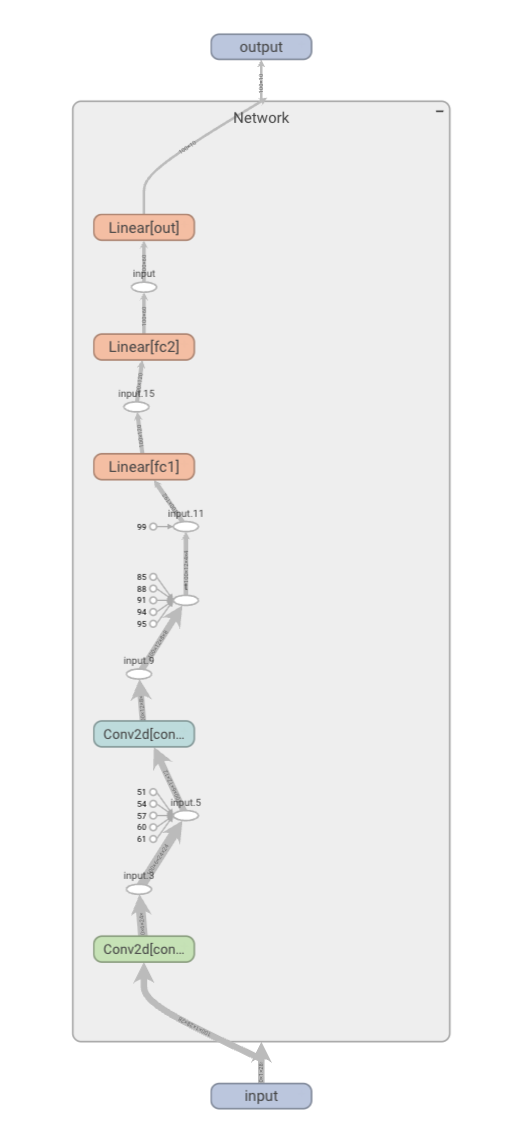
- 数据图像及模型结构图:

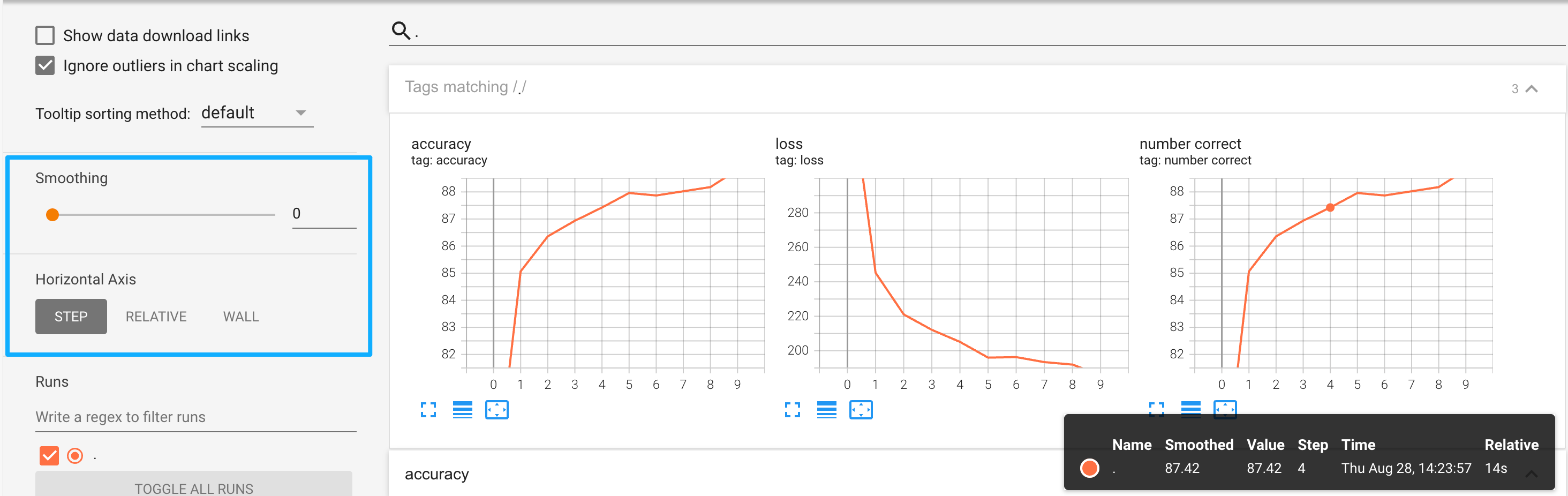
- 标量图:纵轴为我们记录的数据,横轴为epoch,也可以在左边蓝色方框位置修改线的平滑度以及横轴
- 直方图:纵轴为epoch,横轴为tensor的值,每个直方图代表训练过的9个epoch中的1个,显示了 tensor权重/梯度等 倾向于集中在哪个区域的信息,用于发现异常。
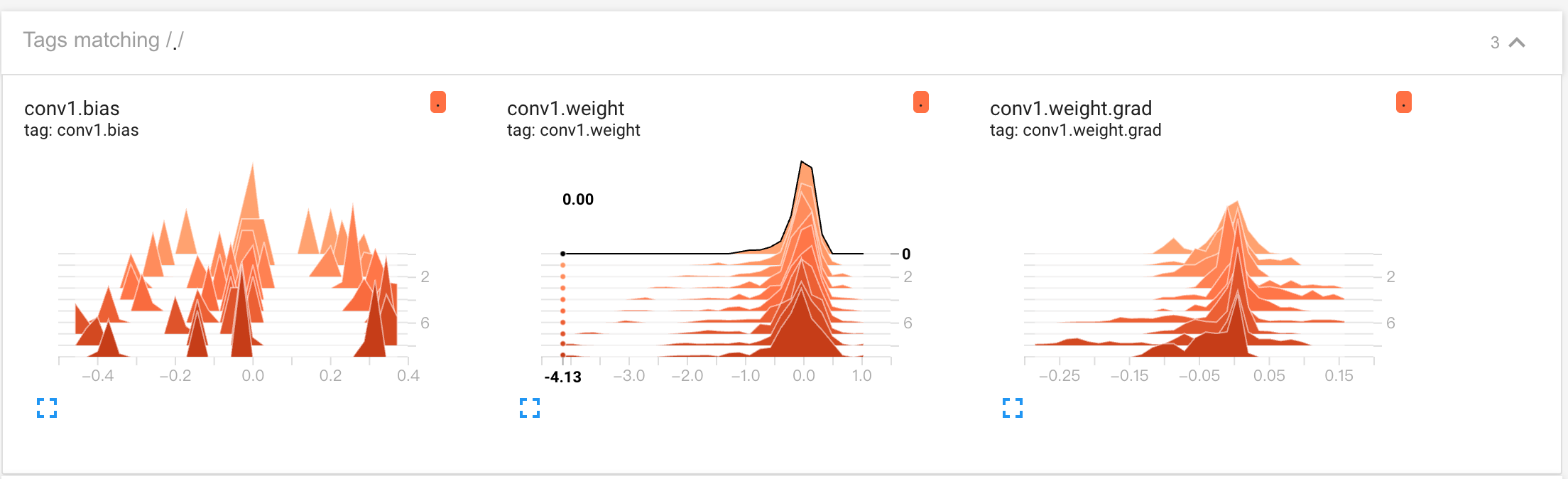
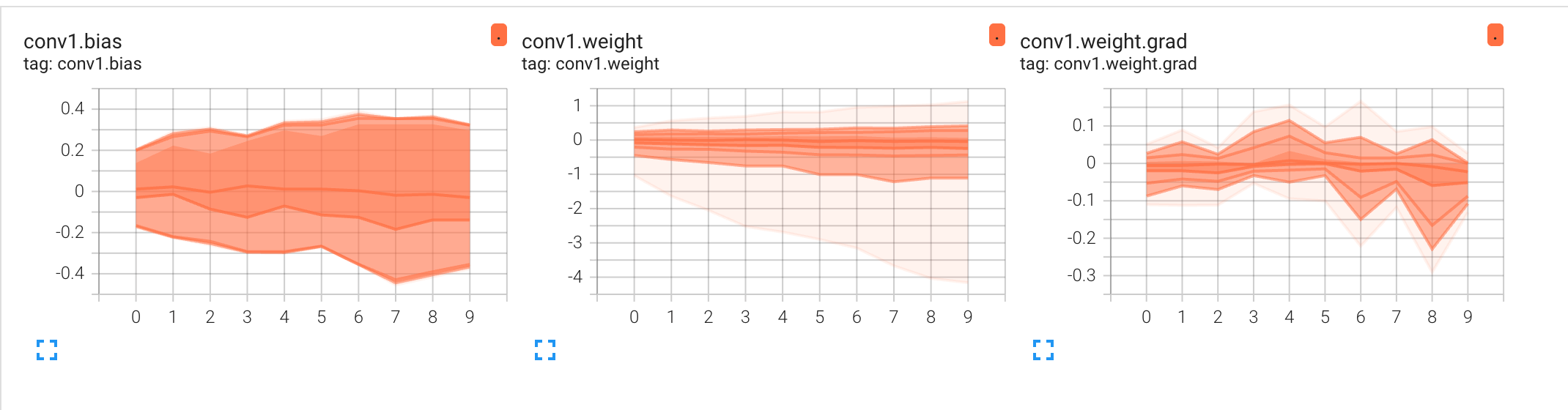
- 分布图:分布图会随同直方图一起出现,纵轴为tensor的值,横轴为epoch,分布图显示了这些tensor如何随着训练的进行而变化。 较暗的区域显示值在某个区域停留了更长的时间, 如果担心模型权重在每个epoch 都没有正确更新,可以使用此选项发现这些问题。
3. 快速对批量超参数进行实验
在上面的案例中,这些操作我们通过Python或者R也可以实现,Tensorboard真正强大的地方在于可以批量对不同组合的超参数进行实验分析。
同样拿上面的例子,我们想对 学习率分别取0.1,0.01,0.001,对batch_size分别取100,1000,10000,并对以上两者作笛卡尔积两两组合,看看哪种组合效果最好。下面首先在3.1和3.2补充两个细节点。
3.1 如何避免多层循环做笛卡尔积
常规我们做组合一般是这样:
batch_size_list = [100,1000,10000] lr_list = [0.01,0.001,0.0001]for batch_size in batch_size_list:for lr in lr_list:xxx但是一般如果组合选项特别多,就会出现多层for循环嵌套,因此我们可以改进这一点
from itertools import product# 定义一个参数字典 hyperparam = dict(lr = [.01,.001],batch_size = [100,1000],shuffle = [True,False] )# 返回字典中 每个键值对 对应的 值 来获取参数列表 param_values = [v for v in hyperparam.values()] print(param_values) # [[0.01, 0.001], [100, 1000], [True, False]]# 将参数传递给 product(),构建笛卡尔积 # *用于将列表中的每个值作为一个参数,而不是将列表本身用作参数 for lr,batch_size,shuffle in product(*param_values):print(lr,batch_size,shuffle)# 0.01 100 True # 0.01 100 False # 0.01 1000 True # 0.01 1000 False # 0.001 100 True # 0.001 100 False # 0.001 1000 True # 0.001 1000 False
3.2 Tensorboard文件的命名修改
SummaryWriter的构造函数通常是:SummaryWriter(log_dir=None, comment='', filename_suffix='')# log_dir: 指定存储 TensorBoard 日志文件的目录路径。 # comment: 可选的字符串,会附加到自动生成的日志目录名后面(如果你没有指定 log_dir) # filename_suffix: 可选的字符串后缀,会添加到生成的事件文件名的末尾。可用来进一步区分同一目录下的不同日志文件Tensorboard文件的命名逻辑(如果不指定log_dir):
# PyTorch version 1.1.0 SummaryWriter class if not log_dir:import socketfrom datetime import datetimecurrent_time = datetime.now().strftime('%b%d_%H-%M-%S')log_dir = os.path.join('runs', current_time + '_' + socket.gethostname() + comment) self.log_dir = log_dir
3.3 完整代码
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torch.utils.data import DataLoader
from CNN_network import Network,train_set
from torch.utils.tensorboard import SummaryWriter
from itertools import product
import osdef get_num_correct(preds, labels):return preds.argmax(dim=1).eq(labels).sum().item()# ----------------------------------------------------------------------------------------------------------
hyperparam = dict(lr = [.01,.001],batch_size = [100,1000],shuffle = [True,False]
)
param_values = [v for v in hyperparam.values()]
# ----------------------------------------------------------------------------------------------------------for lr,batch_size,shuffle in product(*param_values):network = Network()train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=shuffle)# train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=shuffle, drop_last=True) # 丢弃最后一个batchoptimizer = optim.Adam(network.parameters(), lr=lr)# -生成对象(1.1),写入图像(1.3)和模型结构图(1.5)images, labels = next(iter(train_loader)) # get图像和标签grid = torchvision.utils.make_grid(images) # 将一个包含多张图像的batch tensor,转换成一个可视化的图像网格# ---------------------------------------------------------------main_log_dir = './tensorboard' # 主目录os.makedirs(main_log_dir, exist_ok=True)comment = f'batch_size={batch_size}, shuffle={shuffle}, lr={lr}'run_log_dir = os.path.join(main_log_dir, comment)writer = SummaryWriter(log_dir=run_log_dir)# ---------------------------------------------------------------writer.add_image('images', grid)writer.add_graph(network, images)for epoch in range(10):total_loss = 0total_correct = 0for batch in train_loader: # Get batchimages, labels = batchpreds = network(images) # Pass batchloss = F.cross_entropy(preds, labels) # calculate lossoptimizer.zero_grad() # 这里十分重要!!! pytorch会累加梯度,所以在每个循环时,都必须先将梯度归零loss.backward() # caculate gradientsoptimizer.step() # updata weight# 作相应修改------------------------------------------# 训练集不一定恰巧被batch平均分配,可以丢弃最后一个batch,或者使用每个batch第一个轴的长度代替batch_size# total_loss += loss.item() * batch_sizetotal_loss += loss.item() * images.shape[0]total_correct += get_num_correct(preds, labels)# 写入标量(1.2)和直方图(1.4)# 记录每个epoch的相应值,分别画曲线图和直方图writer.add_scalar('loss', total_loss/100, epoch)writer.add_scalar('accuracy', total_correct/len(train_set), epoch)writer.add_scalar('number correct', total_correct, epoch)for name, weight in network.named_parameters():writer.add_histogram(name, weight, epoch)writer.add_histogram(f'{name}.grad', weight.grad, epoch)print('epoch:', epoch, 'total_loss:', total_loss, 'total_correct:', total_correct)writer.close()
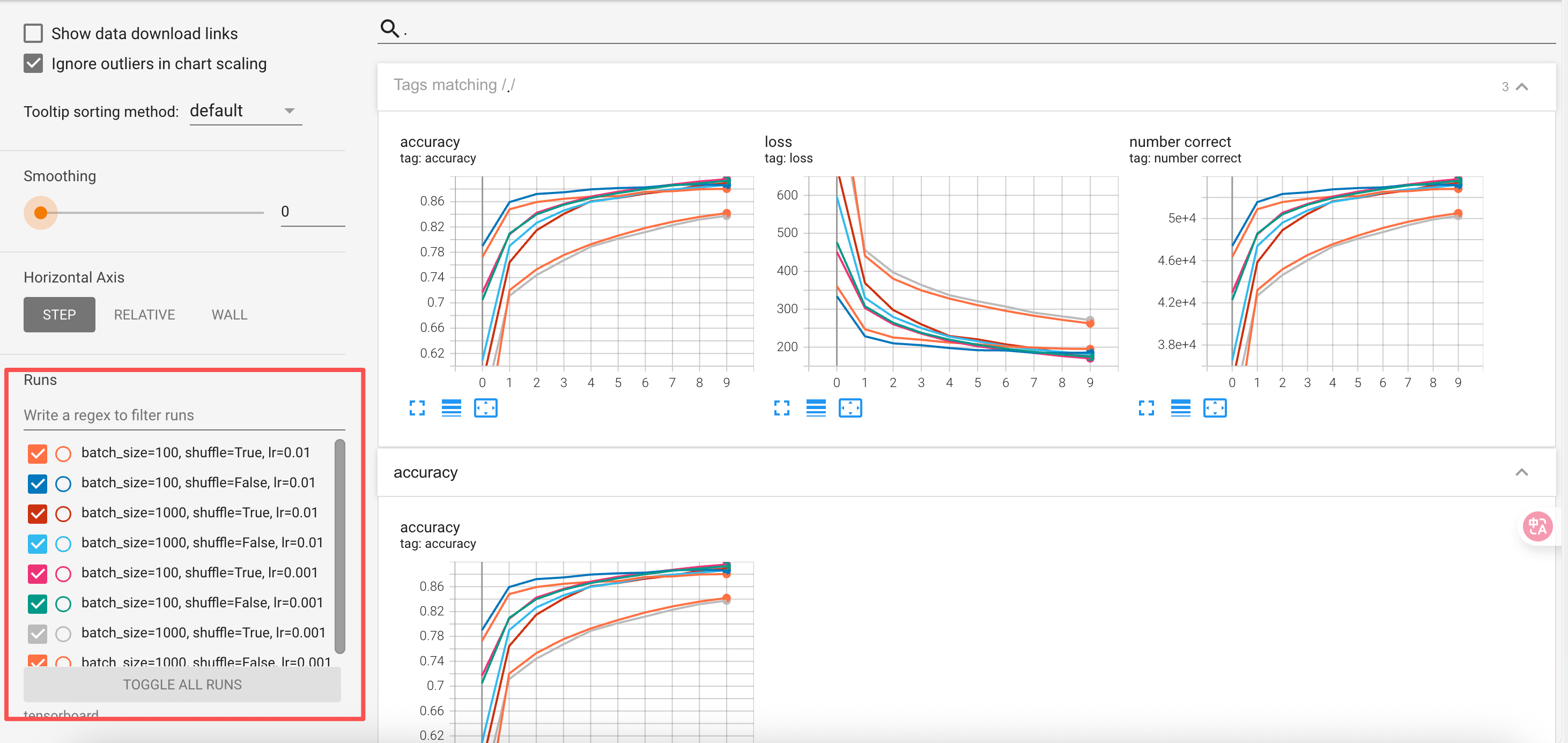
我们可以从左下角红色方框处看到所有的组合,从图中可明显看出,当batch_sizes设为1000,学习率为0.001时,建模效果比较差
)



 的必会知识点汇总)
 详解)

)







)
)


)