
引言:时序数据管理的时代挑战
随着工业4.0和物联网技术的快速发展,全球时序数据呈现爆炸式增长。据IDC预测,到2025年,全球物联网设备产生的数据量将达到79.4ZB,其中超过60%为时序数据。这类数据具有显著特征:高频采集(毫秒级)、维度丰富(单设备数百个监测指标)、严格有序(时间戳为核心维度)、价值密度低(仅少量异常片段具分析价值)。传统关系型数据库在处理这类数据时面临三大困境:写入吞吐量不足、存储成本高昂、查询效率低下。这促使专门优化的时序数据库(TSDB)成为技术市场的刚需。
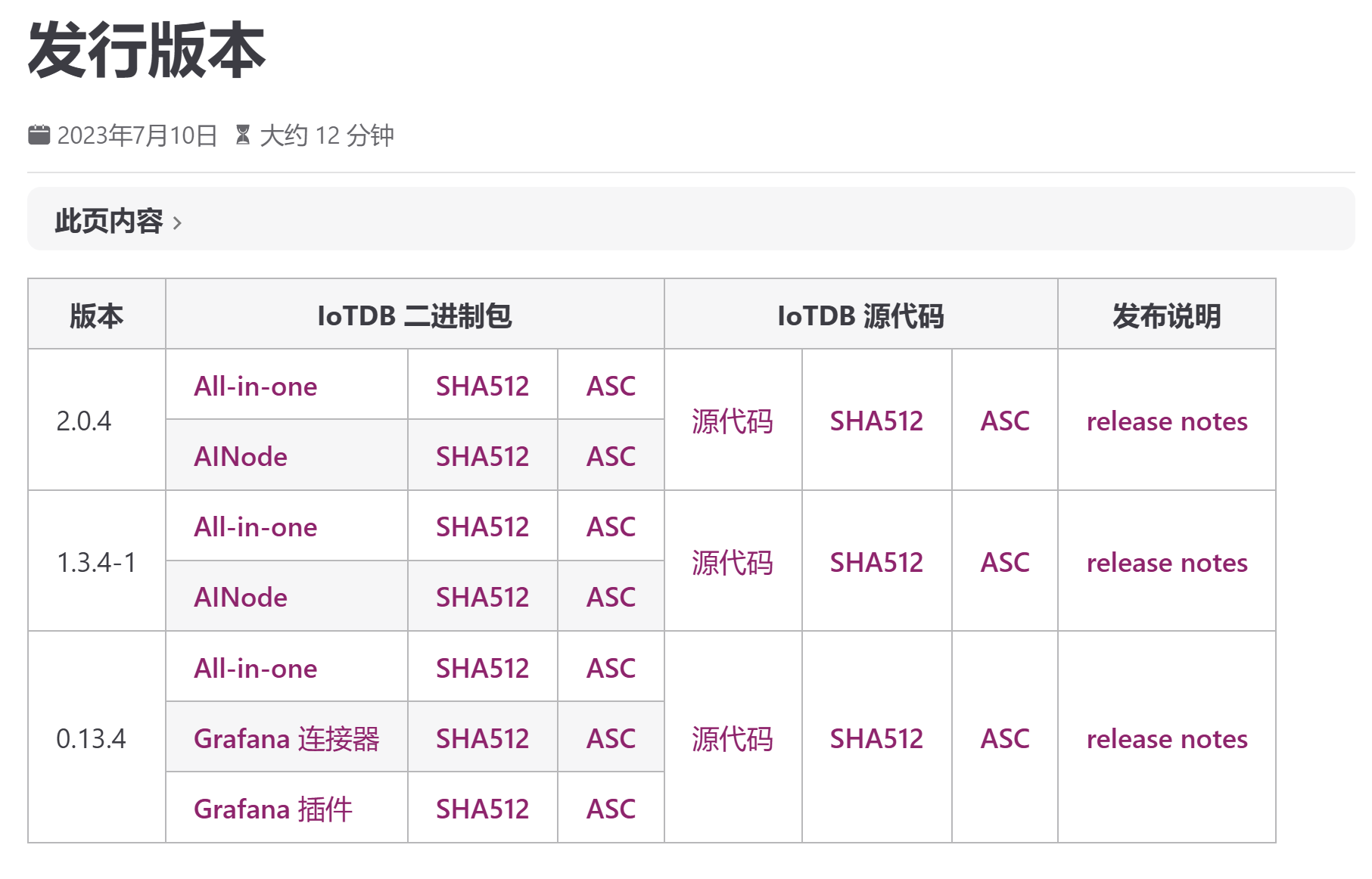
发行版本
一、时序数据库选型的六大核心维度
1. 数据模型设计:贴合工业层级结构
工业场景中,设备数据通常呈现"集团-厂站-产线-设备-传感器"的多层级结构。优秀时序数据库需提供符合这种层级管理的建模能力:
- IoTDB采用树形时序数据模型,通过"设备-测点"的层级结构天然匹配工业设备管理体系。示例建模语句:
CREATE TIMESERIES root.factory.d1.sensor1 WITH DATATYPE=FLOAT, ENCODING=RLE
CREATE TIMESERIES root.factory.d1.sensor2 WITH DATATYPE=INT32, ENCODING=TS_2DIFF- 对比InfluxDB的Tag-Set模型,IoTDB的树状结构更贴近设备管理实际,且支持多层级权限控制(如为集团级、工厂级数据设置不同访问权限)。
2. 写入与查询性能:工业场景的硬指标
工业监控对性能有严苛要求:
- 写入吞吐:单节点需达到百万级数据点/秒
- 查询延迟:简单查询应在毫秒级响应
- 实测数据:IoTDB在标准硬件环境(16C32G)下实现:
- 单机写入:150万数据点/秒
- 集群写入:线性扩展至千万级
- 时间窗口查询:百亿数据亚秒响应
3. 存储效率:压缩比决定TCO
时序数据压缩能力直接影响总拥有成本(TCO)。IoTDB通过三项技术创新实现超高压缩比:
- 自适应编码算法:RLE(游程编码)、Gorilla(浮点数专用)、TS_2DIFF(整型专用)
- 列式存储结构:按列存储提升压缩效率
- 多级压缩策略:原始数据→编码→Snappy压缩→TsFile格式
某风电企业案例显示,使用IoTDB后存储空间仅为原方案的1/20,年节省存储成本超300万元。
4. 系统扩展性:端边云协同架构
现代企业需要从边缘到云端的全场景支持。IoTDB提供独特的"端-边-云"协同架构:
[边缘设备] --低延迟--> [边缘IoTDB] --异步同步--> [云端IoTDB集群] |
这种架构既保证现场控制的实时性,又满足中心化分析需求。对比Druid、ClickHouse等方案,IoTDB在工业断网场景下具有显著优势。
5. 生态兼容性:无缝集成现有技术栈
IoTDB提供完善的生态支持:
- 大数据生态:Hadoop、Spark、Flink连接器
- 可视化工具:Grafana、Superset原生支持
- 工业协议:OPC UA、Modbus、MQTT适配器
6. 运维复杂度:降低技术门槛
调研显示60%的时序数据库项目失败源于运维复杂度。IoTDB通过三项设计降低门槛:
- 类SQL语法:降低工程师学习成本
- 一体化监控平台:内置300+监控指标
- 智能调参工具:自动优化内存/线程配置
二、IoTDB技术架构深度解析
1. 存储引擎创新:TsFile的突破
IoTDB独创的TsFile格式实现存储效率突破:
- 分层存储:热数据(SSD)/冷数据(HDD)自动迁移
- 自适应索引:根据查询模式动态调整索引策略
- 时间分区:支持按年/月/日自动分区
三级存储结构(元数据层+数据层+索引层)使某省级电网实现:
- 采集点规模:200万+
- 日新增数据:50TB
- 故障追溯:从小时级降至秒级。
2. 计算引擎优势:流批一体处理
IoTDB的计算引擎实现三大突破:
- 流批一体:相同SQL既可查询历史数据,也能处理实时流
- 原生计算:内置100+时序专用函数(滑动窗口、趋势分析等)
- AI集成:支持在库内执行时序预测、异常检测
在风电故障预测场景中,通过SQL直接调用预测算法:
SELECT forecast(temperature) FROM sensors实现提前30分钟识别故障,准确率达92%。
3. 分布式架构设计:3C3D架构
IoTDB集群采用独特的3C3D架构:
- ConfigNode:负责元数据管理(3节点确保高可用)
- DataNode:处理数据存储与查询(可线性扩展)
对比InfluxDB的Sharding方案,IoTDB的架构更易管理;对比TimescaleDB的PG扩展方案,性能更高。
三、行业解决方案对比

1. 能源电力场景:省级电网实践
某省级电网采用IoTDB后实现:
- 采集点规模:200万+
- 日新增数据:50TB
- 查询性能:故障追溯从小时级降至秒级
- 关键优势:网闸穿透、断点续传等工业特性
2. 智能制造场景:汽车工厂应用
汽车工厂应用案例显示:
- 设备数量:5000+
- 采样频率:100ms
- 存储成本:降低82%
- 核心价值:边缘预处理减少90%网络传输
3. 对比国外产品:性能碾压
| 维度 | InfluxDB | TimescaleDB | IoTDB |
|---|---|---|---|
| 压缩比 | 5-10x | 3-5x | 15-20x |
| 单机写入 | 50万点/秒 | 30万点/秒 | 150万点/秒 |
| 工业协议支持 | 需插件 | 需插件 | 原生支持 |
| 国产化认证 | 无 | 无 | 全栈适配 |
四、选型实践建议
需求分析阶段
- 评估数据规模:设备数×测点数×频率
- 明确查询模式:实时监控/历史分析
- 确定SLA要求:可用性、延迟指标
概念验证(POC)要点
- 测试真实数据集的压缩率
- 模拟峰值写入压力
- 验证关键查询性能
部署策略
- 小规模试点→逐步扩展
- 建立多级存储:热数据(SSD)、温数据(SATA)、冷数据(对象存储)
- 规划备份恢复:跨机房备份、TTL自动转存
长期演进
- 关注时序数据分析需求
- 预留AI集成能力
- 考虑多云部署可能性
五、应用编程示例
Java示例
javpackage org.apache.iotdb;
import org.apache.iotdb.isession.SessionDataSet;
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
import org.apache.iotdb.session.Session;
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
import java.util.ArrayList;
import java.util.List;public class SessionExample {
private static Session session;
public static void main(String[] args) throws IoTDBConnectionException, StatementExecutionException {
session = new Session.Builder()
.host("172.0.0.1")
.port(6667)
.username("root")
.password("root")
.build();
session.open(false);List<MeasurementSchema> schemaList = new ArrayList<>();
schemaList.add(new MeasurementSchema("s1", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("s2", TSDataType.FLOAT));Tablet tablet = new Tablet("root.db.d1", schemaList, 10);
tablet.addTimestamp(0, 1);
tablet.addValue("s1", 0, 1.23f);
tablet.addValue("s2", 0, 1.23f);session.insertTablet(tablet);try (SessionDataSet dataSet = session.executeQueryStatement("SELECT ** FROM root.db")) {
while (dataSet.hasNext()) {
System.out.println(dataSet.next());
}
}
session.close();
}
}Python示例
from iotdb.Session import Session
from iotdb.utils.IoTDBConstants import TSDataType
from iotdb.utils.Tablet import Tabletip = "127.0.0.1"
port = "6667"
username = "root"
password = "root"session = Session(ip, port, username, password)
session.open(False)measurements = ["s_01", "s_02", "s_03"]
data_types = [TSDataType.BOOLEAN, TSDataType.INT32, TSDataType.FLOAT]
values = [
[False, 10, 1.1],
[True, 100, 1.25],
[False, 100, 188.1]
]
timestamps = [1, 2, 3]tablet = Tablet("root.db.d_03", measurements, data_types, values, timestamps)
session.insert_tablet(tablet)with session.execute_statement("SELECT ** FROM root.db") as session_data_set:
while session_data_set.has_next():
print(session_data_set.next())
session.close()六、未来发展趋势

时序数据库技术正在向三个方向演进:
- 智能化:内置时序预测、根因分析等AI能力
- 一体化:融合事务处理与实时分析(HTAP)
- 云原生化:深度整合K8s、Serverless等云技术
IoTDB在这些方向已取得突破:
- 最新版本集成TensorFlow/PyTorch运行时
- 支持混合负载隔离执行
- 提供K8s Operator简化云部署
结语:选型决策指南
时序数据库选型是数字化转型的关键决策。通过本文分析可见,IoTDB凭借其原生物联网设计、卓越的存储效率、完整的生态体系,已成为工业场景的理想选择。特别是其商业版TimechoDB提供的企业级特性,如双活部署、多级存储、可视化工具等,能够进一步降低运维复杂度,保障生产系统稳定运行。
建议企业在实际选型中:
- 优先考虑IoTDB的场景:
- 工业物联网:设备层级复杂、协议多样的工厂环境
- 边缘计算:资源受限的嵌入式或移动场景
- 成本敏感型:PB级数据长期存储的预算控制
- 国产化要求:适配麒麟OS、鲲鹏芯片等信创生态
- 避坑建议:
- 避免高基数操作:单设备测点不宜超过1万
- 冷热分离策略:对历史数据启用TTL自动转存对象存储
- 写入缓冲配置:网络不稳定时启用本地缓存防数据丢失
- 集群分片规划:按物理区域划分数据分片,减少跨网查询
立即体验:
- 开源版下载:发行版本 | IoTDB Website
- 企业版试用:https://timecho.com
建议企业在实际选型中,既要考虑当前需求,也要预留技术演进空间,选择像IoTDB这样兼具创新性和实用性的时序数据库解决方案。


![洛谷 P1077 [NOIP 2012 普及组] 摆花-普及-](http://pic.xiahunao.cn/洛谷 P1077 [NOIP 2012 普及组] 摆花-普及-)

)
)






:指令与过滤器)


)


日志系统原理以及k8s集群日志采集过程)
 复杂度分析笔记)