引言:时序数据管理的挑战与机遇
在工业4.0与物联网技术深度融合的今天,全球设备产生的时序数据量正以指数级增长。据IDC预测,到2025年物联网设备产生的数据将达79.4ZB,其中60%为时序数据。这类数据具有高频采集(毫秒级)、维度丰富(单设备数百监测点)、严格有序(时间戳为核心)等特性,传统关系型数据库在处理时面临写入吞吐不足、存储成本高企、查询效率低下等痛点。
本文从大数据视角出发,结合国际权威测试数据,系统解析时序数据库选型的核心维度,并重点阐述Apache IoTDB如何通过技术创新成为工业场景的首选解决方案。

文章目录
- 引言:时序数据管理的挑战与机遇
- 选型核心维度:性能、成本与生态的三重考量
- 1. 写入性能:工业场景的生命线
- 2. 存储效率:压缩比决定TCO
- 3. 查询响应:毫秒级决策的关键
- 4. 成本效益:每一美元的价值
- IoTDB技术架构解析:专为工业场景而生
- 1. 存储引擎创新
- 2. 计算引擎优势
- 3. 分布式架构设计
- 行业应用实践:从中国制造到全球标杆
- 1. 能源电力场景
- 2. 智能制造场景
- 3. 轨道交通创新
- 选型实践建议:从需求到落地的完整路径
- 1. 需求分析阶段
- 2. POC验证要点
- 3. 部署策略
- 未来演进方向:时序数据与AI的深度融合
- 立即体验IoTDB
选型核心维度:性能、成本与生态的三重考量
1. 写入性能:工业场景的生命线
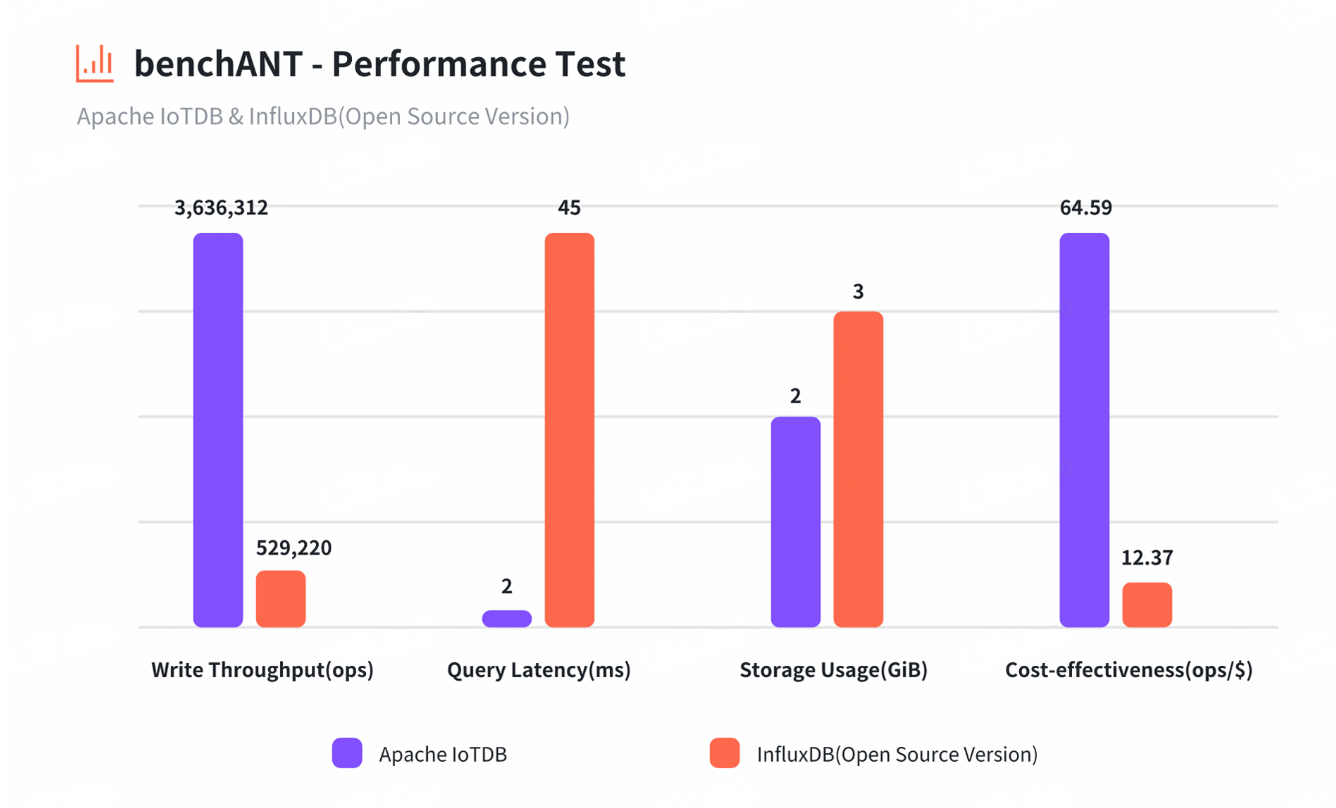
工业监控系统要求数据库具备百万级数据点/秒的单节点写入能力。根据德国benchANT测试机构的权威报告,IoTDB在AWS云环境中实现:
- xSmall集群:142万点/秒写入吞吐,超InfluxDB 5.4倍
- Small集群:363万点/秒写入吞吐,超QuestDB 1.4倍
2. 存储效率:压缩比决定TCO
IoTDB自研的TsFile存储格式通过自适应编码算法实现惊人压缩比:
- 某风电企业采用后存储空间降至原方案的1/20
- benchANT测试显示存储占用仅2GiB,超TimescaleDB 35倍
3. 查询响应:毫秒级决策的关键
在"1设备1测点1小时聚合查询"场景中:
- IoTDB实现2ms级查询延迟,超InfluxDB 96.5倍
- 支持百亿级数据量的亚秒级响应
4. 成本效益:每一美元的价值
通过AWS硬件成本测算,IoTDB的单位美元操作数(Operations Per Cost)指标:
- 超VictoriaMetrics 22.2倍
- 超TimescaleDB 1.4倍
IoTDB技术架构解析:专为工业场景而生
1. 存储引擎创新
TsFile三级存储架构:
- 元数据层:设备树状结构管理,支持百万级设备节点
- 数据层:时间分区+自适应索引,实现冷热数据智能分层
- 索引层:动态构建查询模式匹配索引
-- 示例:IoTDB设备建模
CREATE TIMESERIES root.factory.d1.sensor1 WITH DATATYPE=FLOAT, ENCODING=RLE
CREATE TIMESERIES root.factory.d1.sensor2 WITH DATATYPE=INT32, ENCODING=TS_2DIFF
2. 计算引擎优势
- 流批一体:相同SQL支持历史数据查询与实时流处理
- 内置时序函数:提供滑动窗口、异常检测等100+专用函数
- AI集成:支持库内执行机器学习模型推理
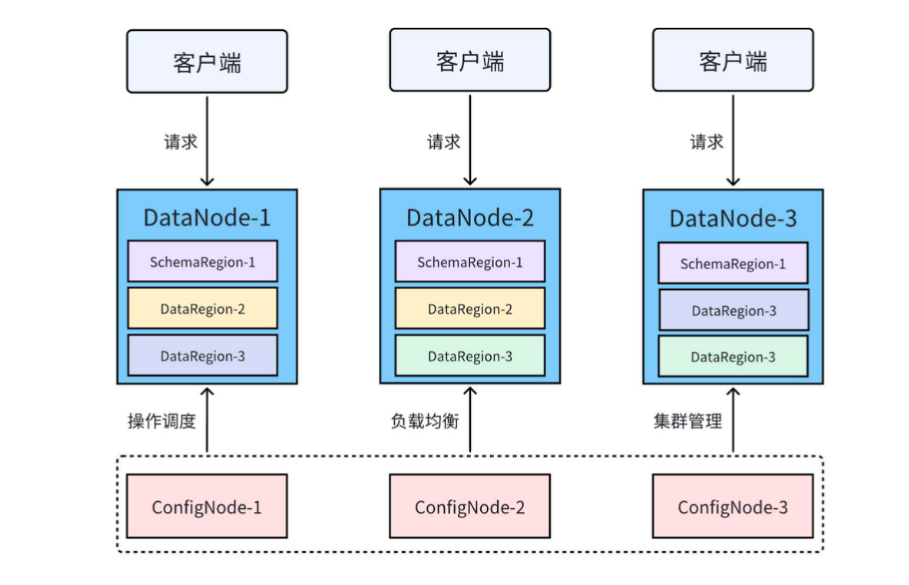
3. 分布式架构设计
3C3D独特架构:
- ConfigNode集群:元数据管理(3节点高可用)
- DataNode集群:数据存储与计算(线性扩展)
- 自动负载均衡:支持动态扩缩容与故障转移
行业应用实践:从中国制造到全球标杆
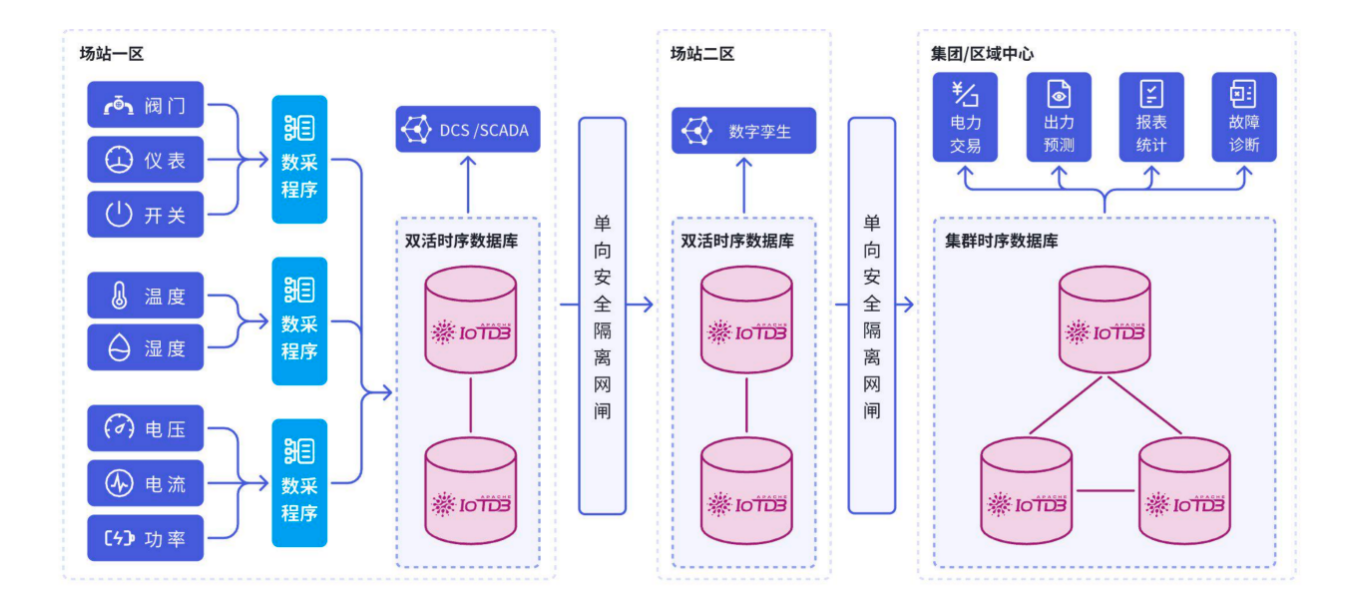
1. 能源电力场景
某省级电网采用IoTDB构建:
- 200万+采集点,日新增数据50TB
- 故障追溯时间从小时级降至秒级
- 网闸穿透等工业特性保障数据安全
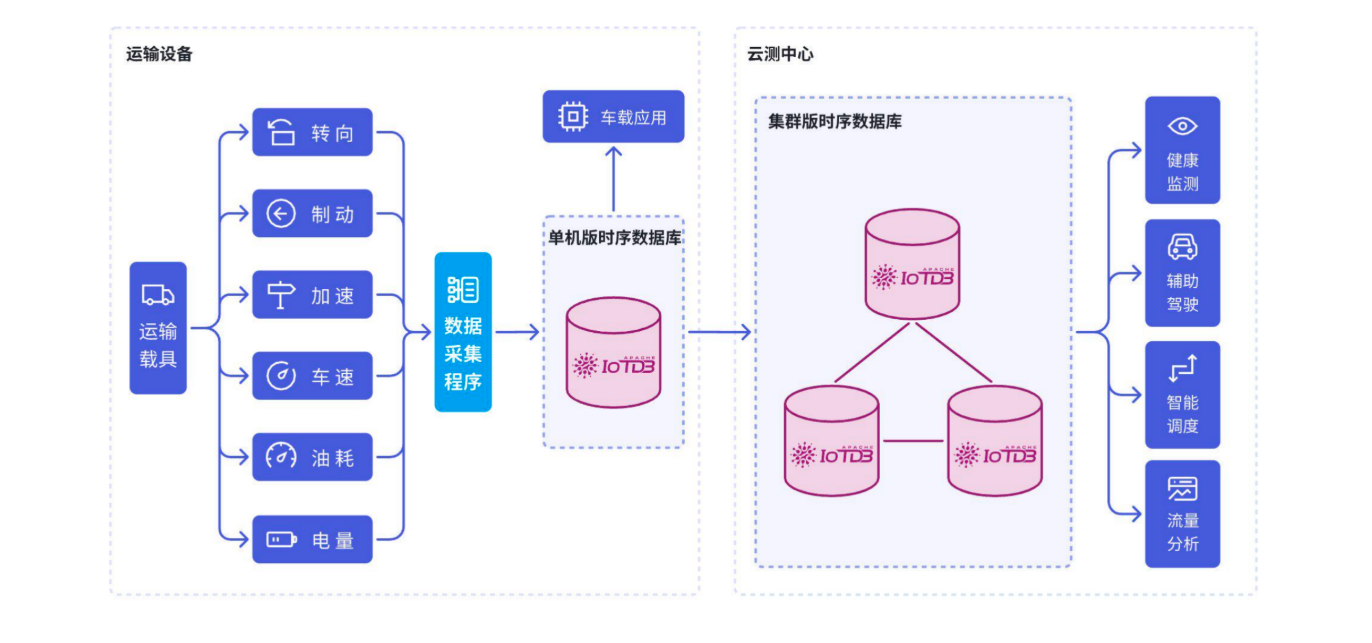
2. 智能制造场景
汽车工厂应用案例:
- 5000+设备,100ms采样频率
- 存储成本降低82%
- 边缘预处理减少90%网络传输
3. 轨道交通创新
德国铁路BZ-NEA项目:
- 燃料电池系统实时监控,满足KRITIS数据保护法规
- OpenID Token授权机制实现细粒度权限控制
选型实践建议:从需求到落地的完整路径
1. 需求分析阶段
- 数据规模评估:设备数×测点数×采样频率
- 查询模式定义:实时监控(亚秒级)vs 历史分析(批量查询)
- SLA要求:可用性(99.99%)、延迟容忍度
2. POC验证要点
# 示例:IoTDB压力测试代码
from iotdb import SessionPool
import numpy as npwith SessionPool(host='localhost', port=6667) as session:for _ in range(1000):timestamps = np.arange(1609459200000, 1609459200000+3600*1000, 1000)values = np.random.randn(len(timestamps))session.insert("root.factory.d1",{"sensor1": values},timestamps)
3. 部署策略
- 边缘-云端协同:边缘节点实时处理,云端集中分析
- 多级存储规划:热数据(SSD)+ 温数据(HDD)+ 冷数据(对象存储)
- 灾备方案:双活部署+跨区域同步
未来演进方向:时序数据与AI的深度融合
IoTDB企业版(TimechoDB)已实现:
- 时序预测:LSTM模型集成,支持设备健康度预测
- 异常检测:基于统计与深度学习的混合算法
- 知识图谱:与COVESA数据服务平台集成,实现语义推理
立即体验IoTDB
访问官方网站下载最新版本:
- 开源版:https://iotdb.apache.org/zh/Download/
- 企业版:https://timecho.com
通过本文解析可见,Apache IoTDB凭借其在工业场景的深度优化、超越国际竞品的性能表现,以及完整的生态整合能力,已成为时序数据库选型的标杆解决方案。无论是能源、制造还是交通领域,IoTDB都在帮助企业实现从数据采集到智能决策的全链路升级。
)
)






:指令与过滤器)


)


日志系统原理以及k8s集群日志采集过程)
 复杂度分析笔记)
![【光照】Unity中的[经验模型]](http://pic.xiahunao.cn/【光照】Unity中的[经验模型])

)
