知识点回顾:
- 不同CNN层的特征图:不同通道的特征图
- 什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。
- 通道注意力:模型的定义和插入的位置
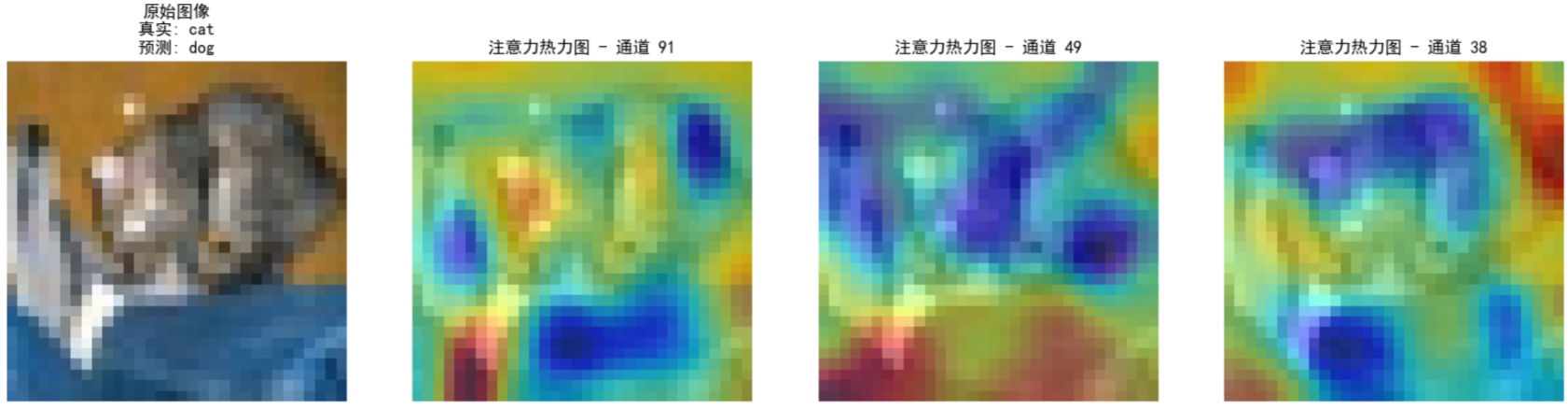
- 通道注意力后的特征图和热力图
内容参考
作业:
- 今日代码较多,理解逻辑即可
- 对比不同卷积层特征图可视化的结果(可选)
一、 什么是注意力
其中注意力机制是一种让模型学会「选择性关注重要信息」的特征提取器,就像人类视觉会自动忽略背景,聚焦于图片中的主体(如猫、汽车)。
transformer中的叫做自注意力机制,他是一种自己学习自己的机制,他可以自动学习到图片中的主体,并忽略背景。我们现在说的很多模块,比如通道注意力、空间注意力、通道注意力等等,都是基于自注意力机制的。
从数学角度看,注意力机制是对输入特征进行加权求和,输出=∑(输入特征×注意力权重),其中注意力权重是学习到的。所以他和卷积很像,因为卷积也是一种加权求和。但是卷积是 “固定权重” 的特征提取(如 3x3 卷积核)--训练完了就结束了,注意力是 “动态权重” 的特征提取(权重随输入数据变化)---输入数据不同权重不同。
问:为什么需要多种注意力模块?
答:因为不同场景下的关键信息分布不同。例如,识别鸟类和飞机时,需关注 “羽毛纹理”“金属光泽” 等特定通道的特征,通道注意力可强化关键通道;而物体位置不确定时(如猫出现在图像不同位置),空间注意力能聚焦物体所在区域,忽略背景。复杂场景中,可能需要同时关注通道和空间(如混合注意力模块 CBAM),或处理长距离依赖(如全局注意力模块 Non-local)。
问:为什么不设计一个万能注意力模块?
答:主要受效率和灵活性限制。专用模块针对特定需求优化计算,成本更低(如通道注意力仅需处理通道维度,无需全局位置计算);不同任务的核心需求差异大(如医学图像侧重空间定位,自然语言处理侧重语义长距离依赖),通用模块可能冗余或低效。每个模块新增的权重会增加模型参数量,若训练数据不足或优化不当,可能引发过拟合。因此实际应用中需结合轻量化设计(如减少全连接层参数)、正则化(如 Dropout)或结构约束(如共享注意力权重)来平衡性能与复杂度。
通道注意力(Channel Attention)属于注意力机制(Attention Mechanism)的变体,而非自注意力(Self-Attention)的直接变体。可以理解为注意力是一个动物园算法,里面很多个物种,自注意力只是一个分支,因为开创了transformer所以备受瞩目。我们今天的内容用通道注意力举例。
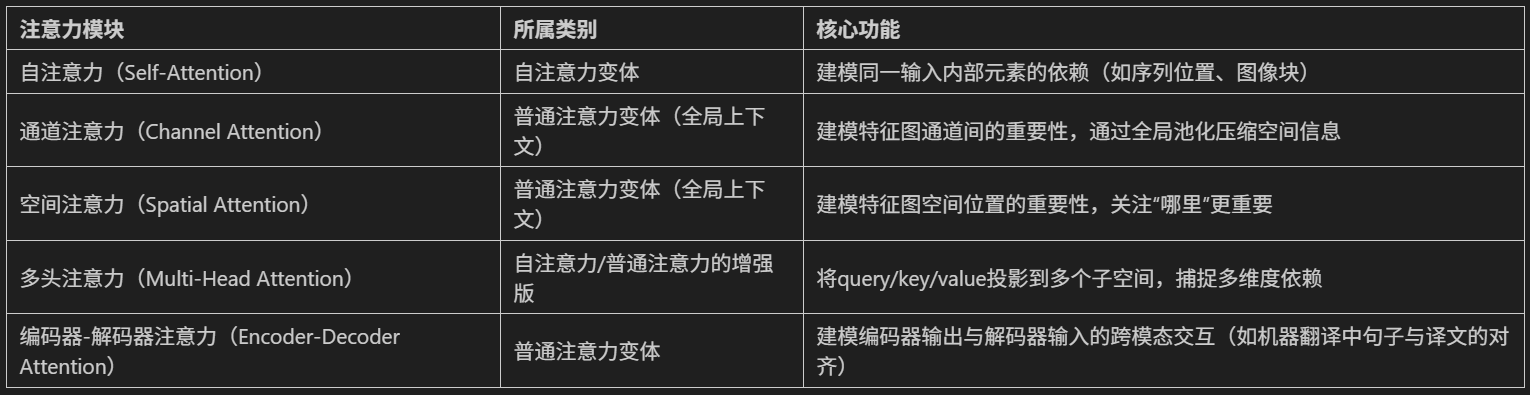
常见注意力模块的归类如下
二、 特征图的提取
2.2 特征图可视化
1.初始化设置:将模型设为评估模式,准备类别名称列表(如飞机、汽车等)。
2.数据加载与处理:
①从测试数据加载器中获取图像和标签。
②仅处理前 num_images 张图像(如2张)。
3.注册钩子捕获特征图:
①为指定层(如 conv1, conv2, conv3)注册前向钩子。
②钩子函数将这些层的输出(特征图)保存到字典中。
4.前向传播与特征提取:
①模型处理图像,触发钩子函数,获取并保存特征图。
②移除钩子,避免后续干扰。
5.可视化特征图:
对每张图像
①恢复原始像素值并显示。
②为每个目标层创建子图,展示前 num_channels 个通道的特征图(如9个通道)。
③每个通道的特征图以网格形式排列,显示通道编号。
关键细节
①特征图布局:原始图像在左侧,各层特征图按顺序排列在右侧。
②通道选择:默认显示前9个通道(按重要性或索引排序)。
③显示优化:
使用 inset_axes 在大图中嵌入小网格,清晰展示每个通道;
层标题与通道标题分开,避免重叠;
反标准化处理恢复图像原始色彩。
def visualize_feature_maps(model, test_loader, device, layer_names, num_images=3, num_channels=9):"""可视化指定层的特征图(修复循环冗余问题)参数:model: 模型test_loader: 测试数据加载器layer_names: 要可视化的层名称(如['conv1', 'conv2', 'conv3'])num_images: 可视化的图像总数num_channels: 每个图像显示的通道数(取前num_channels个通道)"""model.eval() # 设置为评估模式class_names = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']# 从测试集加载器中提取指定数量的图像(避免嵌套循环)images_list, labels_list = [], []for images, labels in test_loader:images_list.append(images)labels_list.append(labels)if len(images_list) * test_loader.batch_size >= num_images:break# 拼接并截取到目标数量images = torch.cat(images_list, dim=0)[:num_images].to(device)labels = torch.cat(labels_list, dim=0)[:num_images].to(device)with torch.no_grad():# 存储各层特征图feature_maps = {}# 保存钩子句柄hooks = []# 定义钩子函数,捕获指定层的输出def hook(module, input, output, name):feature_maps[name] = output.cpu() # 保存特征图到字典# 为每个目标层注册钩子,并保存钩子句柄for name in layer_names:module = getattr(model, name)hook_handle = module.register_forward_hook(lambda m, i, o, n=name: hook(m, i, o, n))hooks.append(hook_handle)# 前向传播触发钩子_ = model(images)# 正确移除钩子for hook_handle in hooks:hook_handle.remove()# 可视化每个图像的各层特征图(仅一层循环)for img_idx in range(num_images):img = images[img_idx].cpu().permute(1, 2, 0).numpy()# 反标准化处理(恢复原始像素值)img = img * np.array([0.2023, 0.1994, 0.2010]).reshape(1, 1, 3) + np.array([0.4914, 0.4822, 0.4465]).reshape(1, 1, 3)img = np.clip(img, 0, 1) # 确保像素值在[0,1]范围内# 创建子图num_layers = len(layer_names)fig, axes = plt.subplots(1, num_layers + 1, figsize=(4 * (num_layers + 1), 4))# 显示原始图像axes[0].imshow(img)axes[0].set_title(f'原始图像\n类别: {class_names[labels[img_idx]]}')axes[0].axis('off')# 显示各层特征图for layer_idx, layer_name in enumerate(layer_names):fm = feature_maps[layer_name][img_idx] # 取第img_idx张图像的特征图fm = fm[:num_channels] # 仅取前num_channels个通道num_rows = int(np.sqrt(num_channels))num_cols = num_channels // num_rows if num_rows != 0 else 1# 创建子图网格layer_ax = axes[layer_idx + 1]layer_ax.set_title(f'{layer_name}特征图 \n')# 加个换行让文字分离上去layer_ax.axis('off') # 关闭大子图的坐标轴# 在大子图内创建小网格for ch_idx, channel in enumerate(fm):ax = layer_ax.inset_axes([ch_idx % num_cols / num_cols, (num_rows - 1 - ch_idx // num_cols) / num_rows, 1/num_cols, 1/num_rows])ax.imshow(channel.numpy(), cmap='viridis')ax.set_title(f'通道 {ch_idx + 1}')ax.axis('off')plt.tight_layout()plt.show()# 调用示例(按需修改参数)
layer_names = ['conv1', 'conv2', 'conv3']
visualize_feature_maps(model=model,test_loader=test_loader,device=device,layer_names=layer_names,num_images=5, # 可视化5张测试图像 → 输出5张大图num_channels=9 # 每张图像显示前9个通道的特征图
)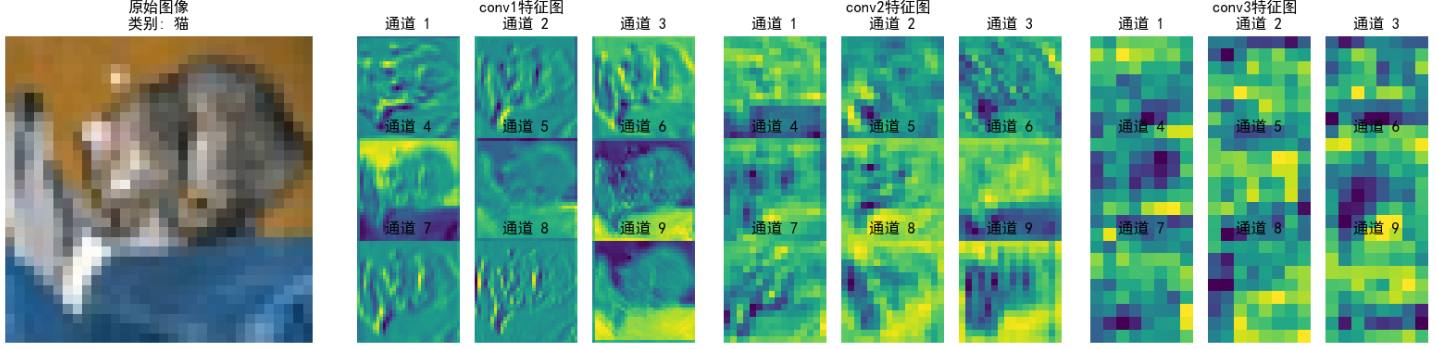
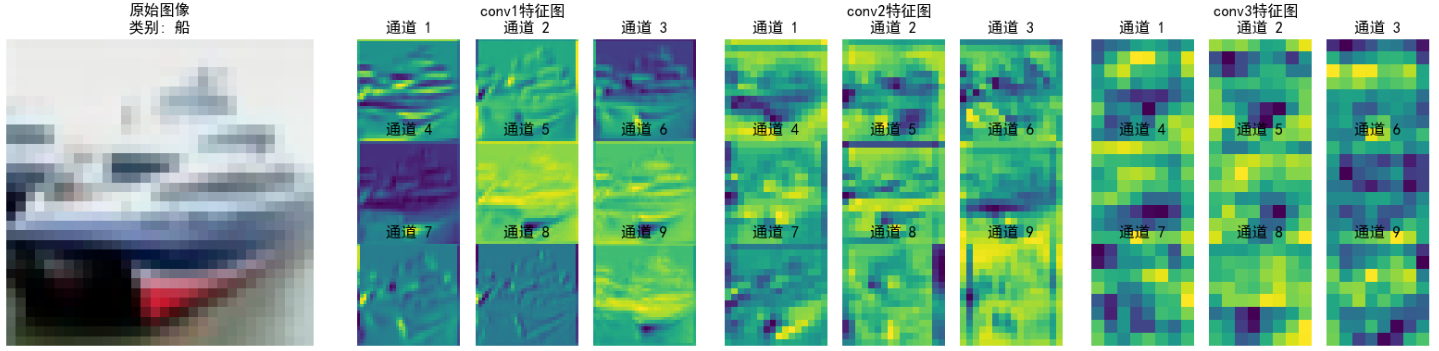
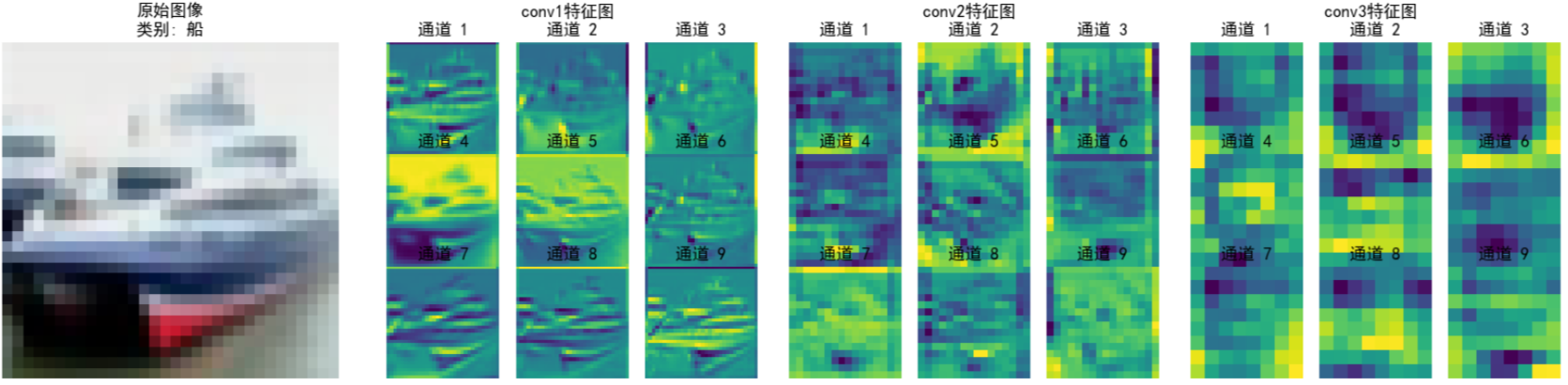
上面的图为提取CNN不同卷积层输出的特征图,我们以第五张图片-青蛙 进行解读。
由于经过了不断的下采样,特征变得越来越抽象,人类已经无法理解。
核心作用
通过可视化特征图,可直观观察:
①浅层卷积层(如 conv1)如何捕获边缘、纹理等低级特征。
②深层卷积层(如 conv3 )如何组合低级特征形成语义概念(如物体部件)。
③模型对不同类别的关注区域差异(如鸟类的羽毛纹理 vs. 飞机的金属光泽)。
conv1 特征图(浅层卷积)
特点:
①保留较多原始图像的细节纹理(如植物叶片、青蛙身体的边缘轮廓)。
②通道间差异相对小,每个通道都能看到类似原始图像的基础结构(如通道 1 - 9 都能识别边缘、纹理)。
意义:
①提取低级特征(边缘、颜色块、简单纹理),是后续高层特征的“原材料”。
②类似人眼初步识别图像的轮廓和基础结构。
conv2 特征图(中层卷积)
特点:
①空间尺寸(高、宽)比 conv1 更小(因卷积/池化下采样),但语义信息更抽象。
②通道间差异更明显:部分通道开始聚焦局部关键特征(如通道 5、8 中黄色高亮区域,可能对应青蛙身体或植物的关键纹理)。
意义:
①对 conv1 的低级特征进行组合与筛选,提取中级特征(如局部形状、纹理组合)。
②类似人眼从“边缘轮廓”过渡到“识别局部结构”(如青蛙的身体块、植物的叶片簇)。
conv3 特征图(深层卷积)
特点:
①空间尺寸进一步缩小,抽象程度最高,肉眼难直接对应原始图像细节。
②通道间差异极大,部分通道聚焦全局语义特征(如通道 4、7 中黄色区域,可能对应模型判断“青蛙”类别的关键特征)。
意义:
①对 conv2 的中级特征进行全局整合,提取高级语义特征(如物体类别相关的抽象模式)。
②类似人眼最终“识别出这是青蛙”的关键依据,模型通过这些特征判断类别。

三、通道注意力
3.1 通道注意力的定义
# ===================== 新增:通道注意力模块(SE模块) =====================
class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_ratio=16):"""参数:in_channels: 输入特征图的通道数reduction_ratio: 降维比例,用于减少参数量"""super(ChannelAttention, self).__init__()# 全局平均池化 - 将空间维度压缩为1x1,保留通道信息self.avg_pool = nn.AdaptiveAvgPool2d(1)# 全连接层 + 激活函数,用于学习通道间的依赖关系self.fc = nn.Sequential(# 降维:压缩通道数,减少计算量nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),nn.ReLU(inplace=True),# 升维:恢复原始通道数nn.Linear(in_channels // reduction_ratio, in_channels, bias=False),# Sigmoid将输出值归一化到[0,1],表示通道重要性权重nn.Sigmoid())def forward(self, x):"""参数:x: 输入特征图,形状为 [batch_size, channels, height, width]返回:加权后的特征图,形状不变"""batch_size, channels, height, width = x.size()# 1. 全局平均池化:[batch_size, channels, height, width] → [batch_size, channels, 1, 1]avg_pool_output = self.avg_pool(x)# 2. 展平为一维向量:[batch_size, channels, 1, 1] → [batch_size, channels]avg_pool_output = avg_pool_output.view(batch_size, channels)# 3. 通过全连接层学习通道权重:[batch_size, channels] → [batch_size, channels]channel_weights = self.fc(avg_pool_output)# 4. 重塑为二维张量:[batch_size, channels] → [batch_size, channels, 1, 1]channel_weights = channel_weights.view(batch_size, channels, 1, 1)# 5. 将权重应用到原始特征图上(逐通道相乘)return x * channel_weights # 输出形状:[batch_size, channels, height, width]3.2 模型的重新定义(通道注意力的插入)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # ---------------------- 第一个卷积块 ----------------------self.conv1 = nn.Conv2d(3, 32, 3, padding=1)self.bn1 = nn.BatchNorm2d(32)self.relu1 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca1 = ChannelAttention(in_channels=32, reduction_ratio=16) self.pool1 = nn.MaxPool2d(2, 2) # ---------------------- 第二个卷积块 ----------------------self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca2 = ChannelAttention(in_channels=64, reduction_ratio=16) self.pool2 = nn.MaxPool2d(2) # ---------------------- 第三个卷积块 ----------------------self.conv3 = nn.Conv2d(64, 128, 3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca3 = ChannelAttention(in_channels=128, reduction_ratio=16) self.pool3 = nn.MaxPool2d(2) # ---------------------- 全连接层(分类器) ----------------------self.fc1 = nn.Linear(128 * 4 * 4, 512)self.dropout = nn.Dropout(p=0.5)self.fc2 = nn.Linear(512, 10)def forward(self, x):# ---------- 卷积块1处理 ----------x = self.conv1(x) x = self.bn1(x) x = self.relu1(x) x = self.ca1(x) # 应用通道注意力x = self.pool1(x) # ---------- 卷积块2处理 ----------x = self.conv2(x) x = self.bn2(x) x = self.relu2(x) x = self.ca2(x) # 应用通道注意力x = self.pool2(x) # ---------- 卷积块3处理 ----------x = self.conv3(x) x = self.bn3(x) x = self.relu3(x) x = self.ca3(x) # 应用通道注意力x = self.pool3(x) # ---------- 展平与全连接层 ----------x = x.view(-1, 128 * 4 * 4) x = self.fc1(x) x = self.relu3(x) x = self.dropout(x) x = self.fc2(x) return x # 重新初始化模型,包含通道注意力模块
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)# 训练模型(复用原有的train函数)
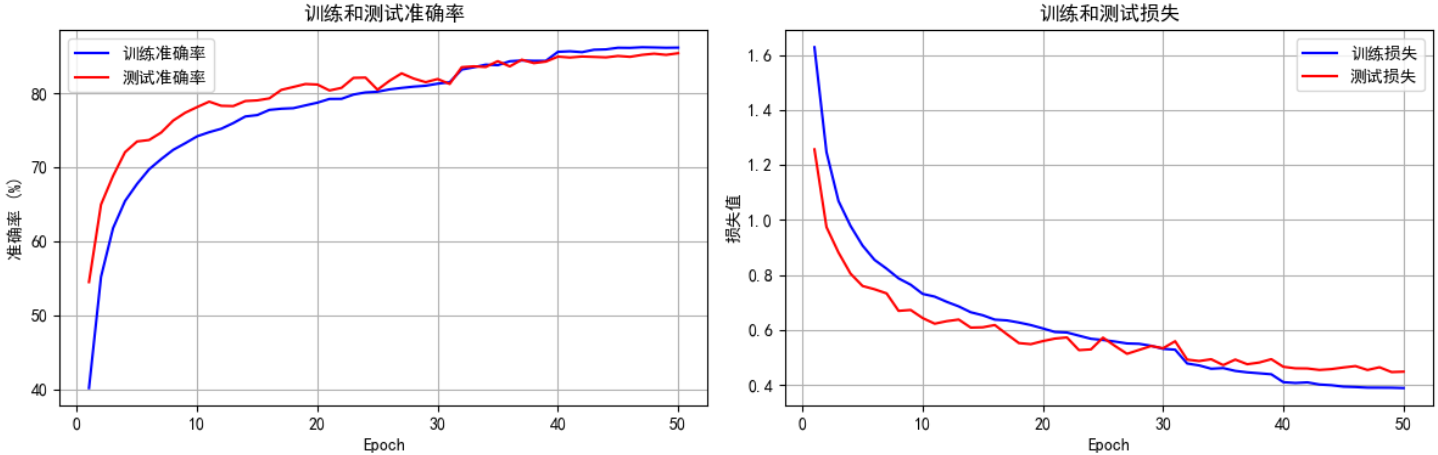
print("开始训练带通道注意力的CNN模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs=50)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
@浙大疏锦行



)


)









)


