近年来,DeepSeek 团队在大语言模型(LLM)领域持续发力,围绕模型架构、专家路由、推理效率、训练方法等方面不断优化,推出了一系列性能强劲的开源模型。本文对 DeepSeek 系列的关键论文进行了梳理,帮助大家快速了解其技术演进路径与核心创新。

1. DeepSeek LLM: Scaling Open-Source Language Models with Longtermism(2024年1月)
作为 DeepSeek 系列的首个基础模型,DeepSeek LLM 基于 Transformer 架构,并在推理效率和训练调度上做出优化:
- 引入 分组查询注意力(GQA),有效降低推理成本;
- 支持 多步学习率调度器,提升训练效率;
- 在预训练和对齐阶段提出创新方法,为后续模型打下基础。
2. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models(2024年1月)
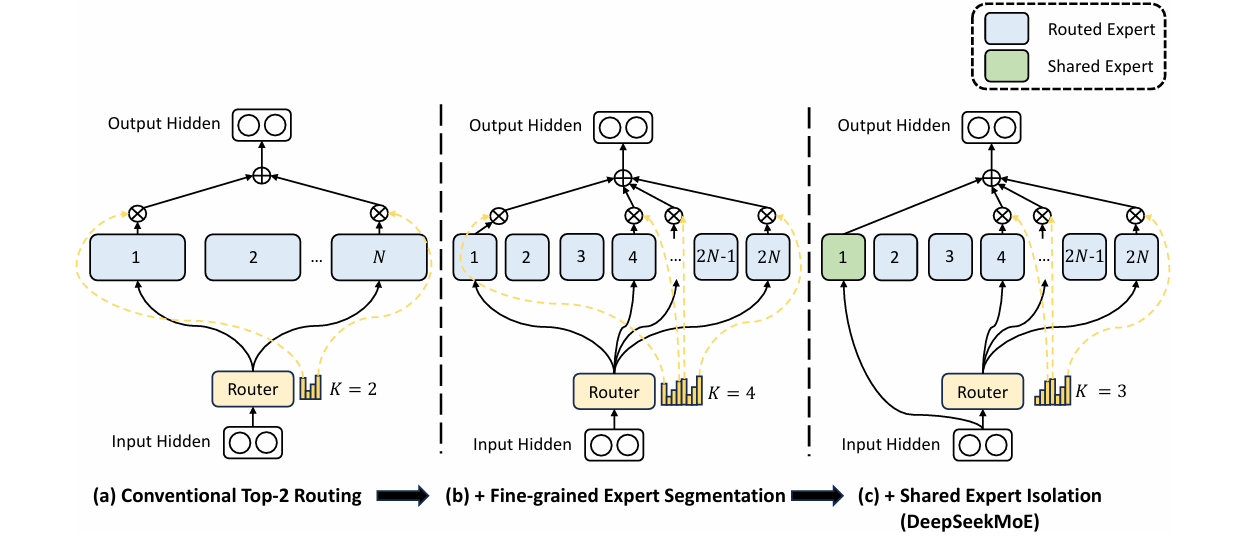
DeepSeekMoE 聚焦于混合专家(MoE)结构的高效利用,提出了两个关键策略:
- 细粒度专家分割(Fine-Grained Expert Segmentation):提高专家模块的可组合性;
- 共享专家隔离(Shared Expert Isolation):提升专家之间的独立性,避免干扰;
在不增加计算开销的前提下,实现了更灵活、高性能的专家调用方式。

3. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model(2024年5月)
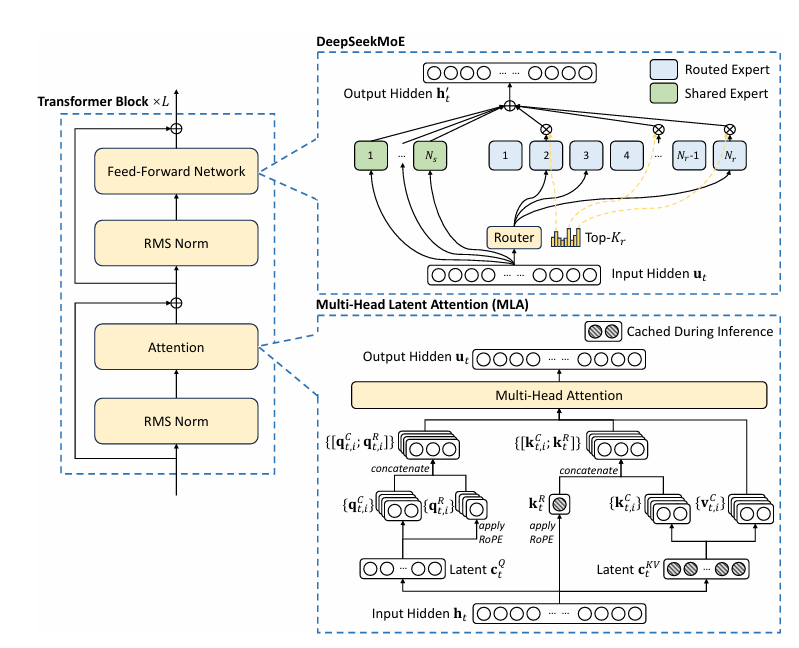
DeepSeek-V2 在 DeepSeekMoE 的基础上进一步优化性能与成本:
- 创新引入 多头潜在注意力(MLA),大幅减少推理过程中的 KV 缓存;
- 延续 MoE 架构优势,在推理效率显著提升的同时,降低整体训练成本。
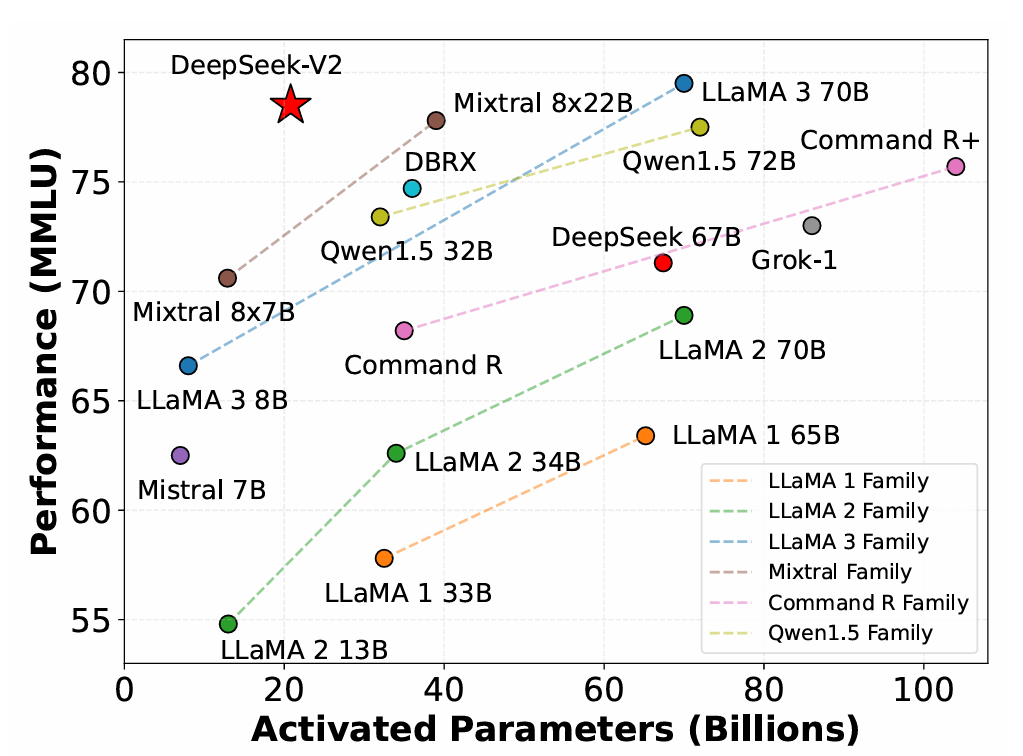
4. DeepSeek-V3 Technical Report(2024年12月)
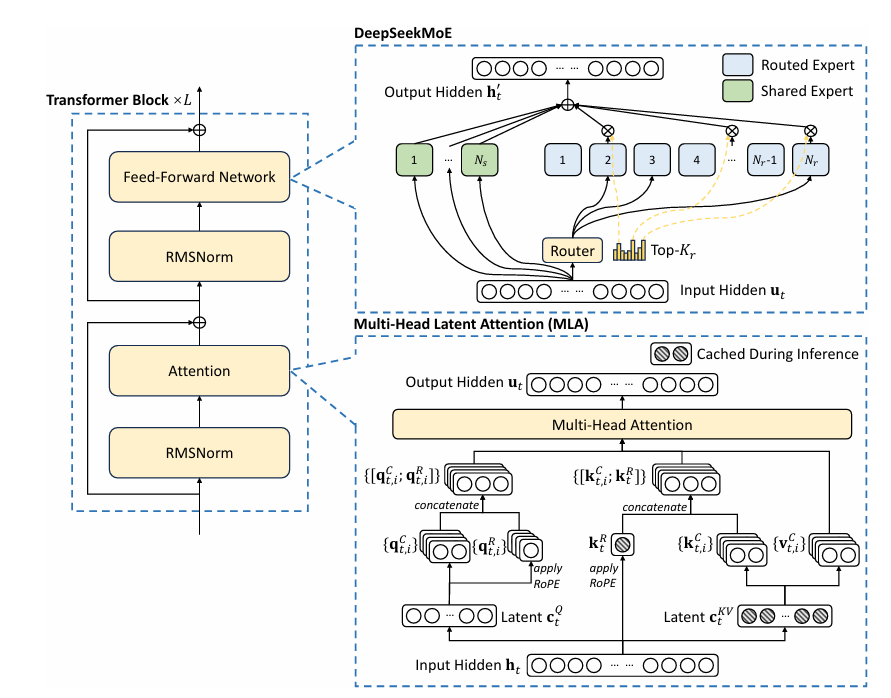
DeepSeek-V3 是目前该系列中规模最大、性能最强的模型:
- 总参数量达 671B,每个 token 激活 37B 参数;
- 采用 无辅助损失的负载均衡策略 和 多令牌预测(MTP) 训练目标;
- 支持 FP8 混合精度训练,在保证性能的同时大幅降低训练资源消耗。
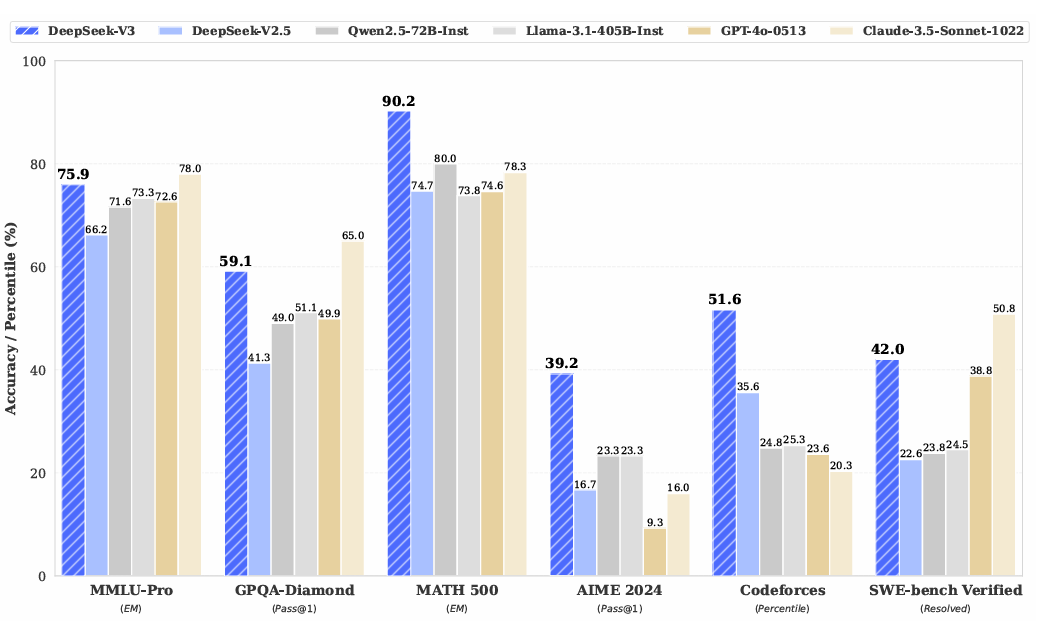
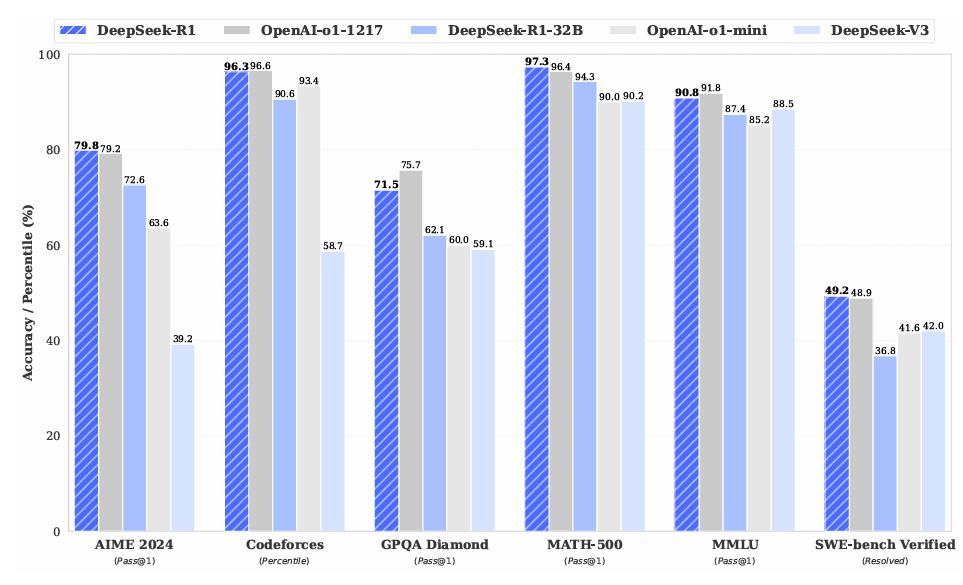
5. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning(2025年1月)
DeepSeek-R1 旨在进一步提升模型的推理能力,核心策略包括:
- 基于 DeepSeek-V3-Base 进行强化学习优化;
- 引入 冷启动数据集 和 多阶段训练流程;
- 显著提升模型在复杂任务中的可读性与逻辑性。
6. Distilling Reasoning Capabilities from DeepSeek-R1 to Smaller Models(2025年1月)
为降低大模型使用门槛,团队发布了基于 DeepSeek-R1 的蒸馏模型:
- 推理能力被成功迁移至更小模型,如 Qwen、LLaMA 等;
- 蒸馏后的模型在多个评测任务中超越同类开源模型,在保持轻量的同时具备强大推理性能。
结语
DeepSeek 系列不仅在大模型架构上持续创新,还在高效推理、专家分配、推理能力增强等方面提出了系统性的解决方案。从基础模型到混合专家,再到强化学习与知识蒸馏,展现了一个完整的大模型演进路径,为开源社区带来了极具参考价值的技术成果。
如果你正在研究大语言模型,DeepSeek 系列无疑是值得深入学习与关注的重要项目。


)









)

到 mapMulti())


)

