很多同学问:波段/特征一多就“维度灾难”,训练慢、过拟合,且很难解释“哪些特征最关键”。本篇用 sklearn 给出一套能跑、可视化、可比较的最小工作流,并配上方法论速记,帮助你在高光谱/多特征任务里做出稳健筛选。
🎯 你将学到
- 三大范式的特征选择:Filter / Wrapper / Embedded
- 为什么有效:统计相关性 vs. 子集搜索 vs. 模型内置重要性
- 如何落地:一段精简代码完成选择→训练→可视化→对比
🧠 方法论速记
-
Filter(过滤法):先验统计量直接筛特征,不依赖具体模型,速度快。
- 例:Chi2/卡方检验,衡量特征与标签的独立性(需要非负特征)。
- 适用:快速粗筛,移除无信息/弱相关特征。
-
Wrapper(包裹法):把“选特征”当搜索问题,用模型性能做打分,通常更准但更慢。
- 例:RFE(递归特征消除):训练模型→按重要性剔除最差→重复,直到剩 K 个。
- 适用:样本量中小、追求更优子集、可接受计算成本。
-
Embedded(嵌入法):使用带稀疏/重要性机制的模型,边训练边选择。
- 例:随机森林特征重要性(基于分裂增益/不纯度减少)。
- 适用:想要可解释、稳健的一次性重要性排序。
实战建议:Filter 粗筛 → Embedded 排序 → Wrapper 精修。多法交叉,关注一致入选的“关键波段”。
💻 一键可跑代码(简洁版)
仅需把
DATA_DIR = "your_path"改成你的数据目录(包含KSC.mat与KSC_gt.mat)。
# -*- coding: utf-8 -*-
"""
Sklearn案例⑦:特征选择与重要性分析(简洁可跑)
方法:Chi2 / RFE(Logistic) / RF-Importance
可视化:重要性曲线、入选热图、精度对比
"""import os, numpy as np, scipy.io as sio, matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.feature_selection import SelectKBest, chi2, RFE
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# ===== 路径与参数 =====
DATA_DIR = "your_path" # ← 修改为你的数据文件夹
TRAIN_RATIO= 0.3
SEED = 42
K_SELECT = 30 # 目标特征数# ===== 1) 载入有标注像素 =====
X_cube = sio.loadmat(os.path.join(DATA_DIR, "KSC.mat"))["KSC"].astype(np.float32)
Y_map = sio.loadmat(os.path.join(DATA_DIR, "KSC_gt.mat"))["KSC_gt"].astype(int)
coords = np.argwhere(Y_map != 0)
X_all = X_cube[coords[:,0], coords[:,1]] # (N, B)
y_all = Y_map[coords[:,0], coords[:,1]] - 1 # 0-basedX_train, X_test, y_train, y_test = train_test_split(X_all, y_all, train_size=TRAIN_RATIO, stratify=y_all, random_state=SEED
)# ===== 2) 预处理:MinMax 到 [0,1](Chi2 需非负;其余方法也可用)=====
scaler = MinMaxScaler().fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
B = X_train.shape[1]# ===== 3) 三种选择法 =====
# 3.1 Filter: Chi2(统计相关性,快)
chi2_sel = SelectKBest(chi2, k=K_SELECT).fit(X_train, y_train)
mask_chi2 = chi2_sel.get_support()# 3.2 Wrapper: RFE(Logistic)(用性能做打分,精细但慢)
# 收敛稳健:用 saga + 充分迭代,避免 lbfgs 收敛告警
lr = LogisticRegression(solver="saga", penalty="l2", C=1.0,max_iter=5000, n_jobs=-1, random_state=SEED)
rfe = RFE(estimator=lr, n_features_to_select=K_SELECT).fit(X_train, y_train)
mask_rfe = rfe.support_# 3.3 Embedded: RF-Importance(模型内置重要性,一次性排序)
rf = RandomForestClassifier(n_estimators=200, random_state=SEED, n_jobs=-1).fit(X_train, y_train)
importances = rf.feature_importances_
topk_idx = np.argsort(importances)[::-1][:K_SELECT]
mask_rf = np.zeros(B, dtype=bool); mask_rf[topk_idx] = True# ===== 4) 评估:统一用RF在子集上测OA =====
def eval_mask(mask, name):clf = RandomForestClassifier(n_estimators=200, random_state=SEED, n_jobs=-1)clf.fit(X_train[:,mask], y_train)acc = accuracy_score(y_test, clf.predict(X_test[:,mask]))return name, acc*100results = [eval_mask(np.ones(B, dtype=bool), "All"),eval_mask(mask_chi2, "Chi2"),eval_mask(mask_rfe, "RFE"),eval_mask(mask_rf, "RF-TopK")
]# ===== 5) 可视化 A:随机森林重要性曲线 =====
plt.figure(figsize=(8,3))
plt.plot(importances, marker='o', linewidth=1.2)
plt.title("A) 随机森林特征重要性")
plt.xlabel("波段索引"); plt.ylabel("重要性")
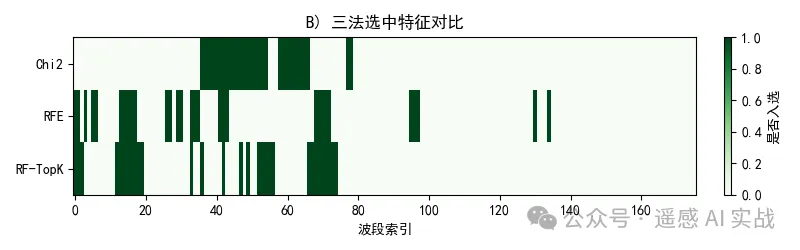
plt.grid(alpha=0.3); plt.tight_layout(); plt.show()# ===== 6) 可视化 B:三法入选热图(方法 × 波段)=====
select_mat = np.vstack([mask_chi2, mask_rfe, mask_rf]).astype(int)
plt.figure(figsize=(8,2.5))
plt.imshow(select_mat, aspect='auto', cmap='Greens')
plt.yticks([0,1,2], ["Chi2","RFE","RF-TopK"])
plt.xlabel("波段索引"); plt.title("B) 三法选中特征对比(1=入选)")
plt.colorbar(label="是否入选", fraction=0.05, pad=0.04)
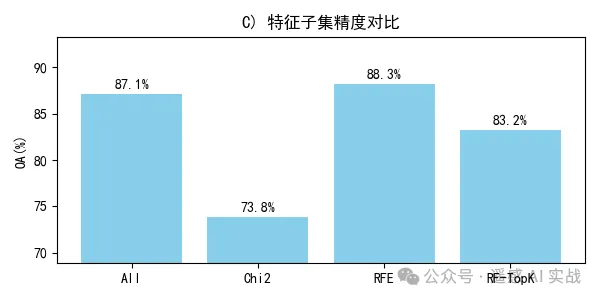
plt.tight_layout(); plt.show()# ===== 7) 可视化 C:特征子集精度对比 =====
names, accs = zip(*results)
plt.figure(figsize=(6,3))
plt.bar(names, accs)
for i,a in enumerate(accs): plt.text(i, a+0.6, f"{a:.1f}%", ha='center')
plt.ylabel("OA(%)"); plt.title("C) 子集精度对比(统一RF评估)")
plt.ylim(min(accs)-5, min(100, max(accs)+6))
plt.grid(axis='y', alpha=0.25, linestyle='--')
plt.tight_layout(); plt.show()print("\n=== 精度汇总 ===")
for n,a in results: print(f"{n:8s}: {a:.2f}%")
🔍 如何读图与用图
-
重要性曲线(A):波段层面的“贡献度”直观谱型;峰值对应的波段往往很关键。
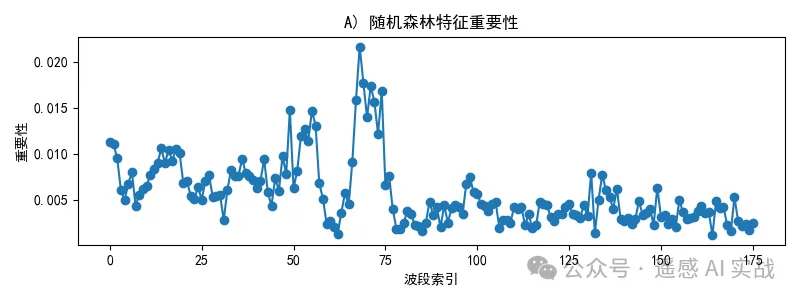
-
入选热图(B):对比不同方法的“共识带”,交集/高频入选波段通常是稳健特征。
-
精度对比(C):用统一评估器(RF)衡量不同子集的有效性;若精选子集与全特征接近或更好,说明筛选成功。
✅ 实战建议
- 先快后准:用 Chi2 快速减容,再用 RF 排序抓关键,再用 RFE 小范围“打磨”。
- 关注共识特征:多法一致入选的波段,优先保留。
- 结合业务知识:把选出的关键波段与地物机理对照(吸收峰、红边等),提升解释力。
- 稳定性检查:换划分/种子,观察被选特征的一致性。
欢迎大家关注下方我的公众获取更多内容!






和噪点(随机分布的干扰像素),比如电路的方法 计算机视觉)









)


