目录
一、什么是 TF-IDF?
1.语料库概念理解
二、TF-IDF 的计算公式
1. 词频(TF)
2. 逆文档频率(IDF)
3. TF-IDF 值
三、关键词提取之中文分词的实现
四、TF-IDF简单案例实现
(1)数据集展示及解释
(2)代码实现
1.调库读取文件
2.实例化,并调用fit_transform()
3.为了方便观察数据,将tfidf的值转化为稀疏矩阵
4.对df数据集进行排序,我们可以利用pd的特性,利用索引一列一列的取出排序
五、TF-IDF 的优势与适用场景
六、总结
在自然语言处理(NLP)领域,如何将文本数据转化为计算机可理解的数值特征是一个核心问题。TF-IDF 作为一种经典的文本加权技术,因其简单高效的特性,被广泛应用于文本分类、信息检索、关键词提取等任务中。本文将从理论原理到代码实现,全面解析 TF-IDF 的工作机制。
一、什么是 TF-IDF?
TF-IDF(Term Frequency-Inverse Document Frequency,词频 - 逆文档频率)是一种用于评估一个词对一个文档集或语料库中某个文档重要性的统计方法。其核心思想是:
- 一个词在文档中出现的次数越多,对文档的重要性越高(词频 TF);
- 一个词在整个语料库的文档中出现的次数越少,对区分文档的重要性越高(逆文档频率 IDF)。
- 最终,一个词的 TF-IDF 值为TF 值 × IDF 值,值越高则该词对当前文档的代表性越强。
1.语料库概念理解
(1)语料库中存放的是在语言的实际使用中真实出现过的语言材料。
(2)语料库是以电子计算机为载体承载语言知识的基础资源。
(3)真实语料需要经过加工(分析和处理),才能成为有用的资源。
举例理解:假设有一个文件夹,文件夹里面有2000篇文章,想要提取出每篇文章中的关键词。
这里的文件夹内的文件就是一个语料库 ,而关键词要具有代表性,能够作为本文章与其他文章之间区分开来
二、TF-IDF 的计算公式
1. 词频(TF)
词频表示某个词在当前文档中出现的频率,计算公式为:

例如:一篇文档总共有 100 个词,其中 “苹果” 出现了 5 次,则 “苹果” 在该文档中的 TF 值为 (5/100 = 0.05)。
2. 逆文档频率(IDF)
逆文档频率衡量词的普遍重要性,计算公式为:

- 分母加 1 是为了避免 “包含词 w 的文档数为 0” 时出现除以 0 的错误(平滑处理);
- 若一个词在多数文档中都出现(如 “的”“是” 等停用词),其 IDF 值会很低;
- 若一个词仅在少数文档中出现,其 IDF 值会很高。
例如:语料库有 1000 篇文档,其中 “苹果” 出现在 100 篇文档中,则 “苹果” 的 IDF 值为 ![]()
3. TF-IDF 值
最终,词w在文档d中的 TF-IDF 值为两者的乘积:
![]()
三、关键词提取之中文分词的实现
英文每个单词之间都有空格分开,中文之间则不存在这样的分隔符。
jieba分词的原理:
jieba是一个人工智能算法,jieba是基于隐马尔可夫链实现的,jieba分词的内部有点像辞海,分词的原理(以“我们在学Python办公自动化”为例)先找到’我‘,然后找到’我们’,其中'自动'和‘自动化都可以是一个词’。
lcut():jieba库里的一个方法,用来分词;cut_all是lcut中的一个参数,将参数设置为True,则函数会返回某一个句子的所有可能的切分结果。
add_word():向jieba的辞海中添加新的词,那么,我们下次进行分词时就能将句子中的词按照你添加的词进行分词。
load_userdict():将词库文件加载到jieba的辞海中,对文件的要求是一个词在文件中占一行,函数的参数是需要添加词库文件的路径。
lcut()方法:分词的结果
![]()
cut():分词的结果
![]()
四、TF-IDF简单案例实现
(1)数据集展示及解释
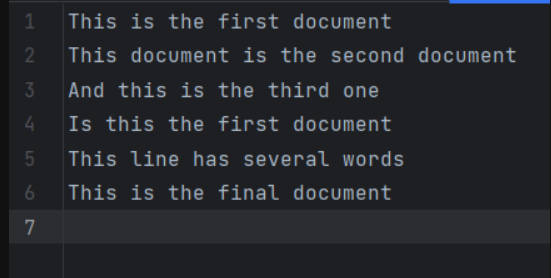
数据集总共有6行数据,整个数据集(即遮条数据)可以看成一个语料库,每一行可以看成一篇文章,每篇文章中有若干个词。
调用TF-IDF包,来计算每一行的关键词的TF-IDF的值,最终目标是实现把所有文章中的关键词都进行排序,并将排名前五的关键词都打印出来
(2)代码实现
1.调库读取文件
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
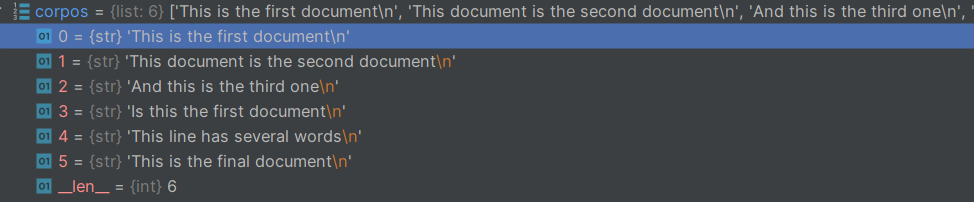
inFile = open(r"task2_1.txt", "r")
corpos = inFile.readlines()cospos的数据类型及数据展示
2.实例化,并调用fit_transform()
fit _transform作用:
fit 步骤:此步骤会分析输入的文本语料库(即 corpos),从中学习词汇表以及每个词的逆文档频率(IDF)值。词汇表涵盖了语料库中所有不同的词,而 IDF 值体现了每个词在整个语料库中的重要程度。
transform 步骤:在学习到词汇表和 IDF 值之后,该步骤会把输入的文本语料库转换为 TF-IDF 特征矩阵。TF-IDF 是一种衡量词在文档中重要性的统计方法,它综合考虑了词在文档中的出现频率(TF)以及词在整个语料库中的稀有程度(IDF)。
vectorizer=TfidfVectorizer()
tfidf=vectorizer.fit_transform(corpos)#打印tfidf的值
print(tfidf)get_feature_names() 方法的作用就是返回这些特征(词汇)的名称,即这个数据集中所有单词,去重后的词汇集合
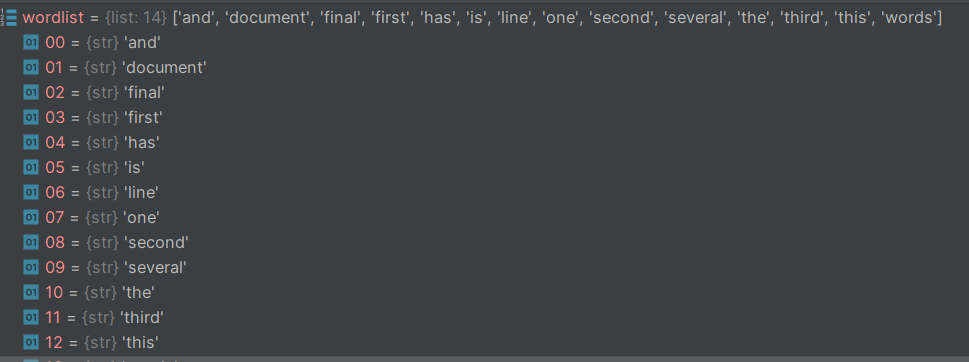
wordlist=vectorizer.get_feature_names()
print(wordlist)wordlist的值,这里可以看出,它以列表的形式存储了所有词
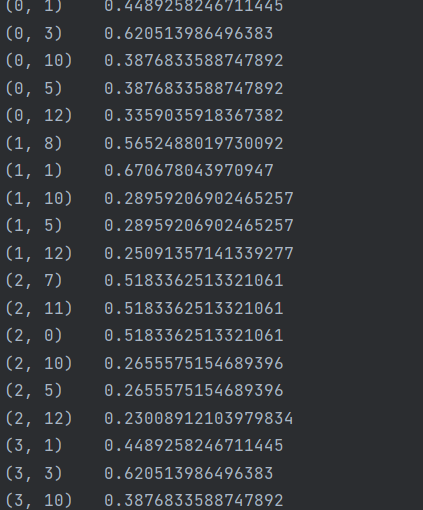
tfidf值数据如下:
解释其含义:
![]()
以这个为例,(0,1)其中0是指这个词在数据集中处于那个文章中,这里是代表数据集的第一条数据“This is the first document”,这里的1是指在关键词列表(即wordlist)中的位置,可见这里的1对应word list中的第二个值document,0.4489258246711445这个数则是document的TF-IDF的值,表示这个词的重要程度。
3.为了方便观察数据,将tfidf的值转化为稀疏矩阵
df=pd.DataFrame(tfidf.T.todense(),index=wordlist)
print(df)效果如下
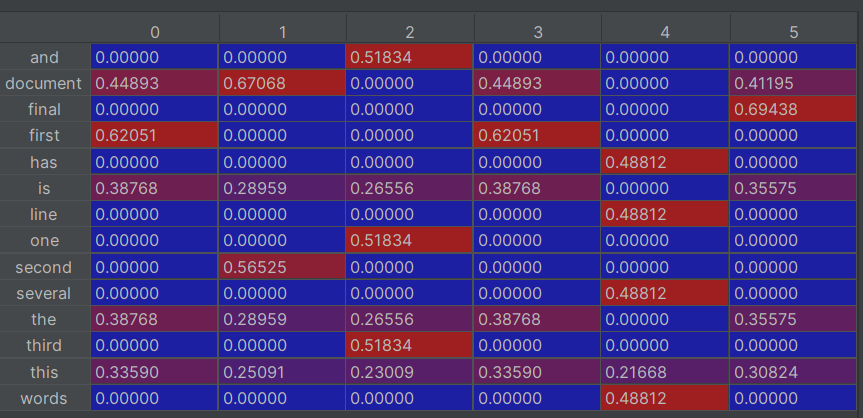
这里的行是指每个单词,列是指这个单词位于那个文章中。
4.对df数据集进行排序,我们可以利用pd的特性,利用索引一列一列的取出排序
df.sort_value()排序,pandas类型数据排序,对值进行排序,因为pandas的数据有索引列
for i in range(len(corpos)):featurelist=df[[i]]feature_rank=featurelist.sort_values(by=i,ascending=False) #对featurelist按数值排序,降序print(feature_rank.head(5))
#打印前五行的内容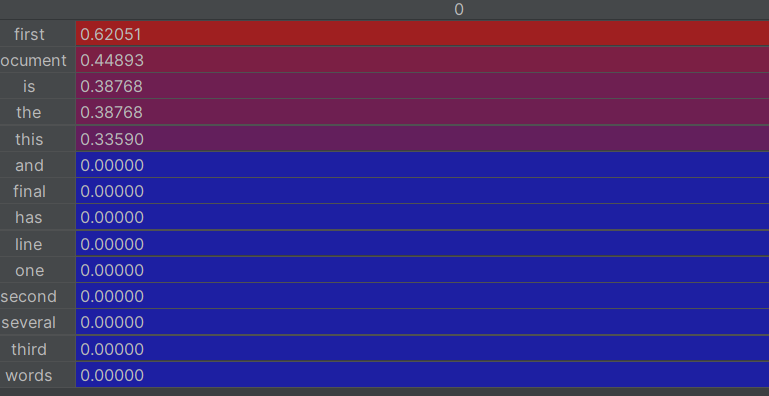
这样就实现了对关键词进行排序,输出每篇文章前五的关键词
五、TF-IDF 的优势与适用场景
优势:
- 简单直观:原理易于理解,计算成本低;
- 效果稳定:在文本分类、关键词提取等任务中表现可靠;
- 可解释性强:权重直接反映词对文档的重要性。
适用场景:
- 文本分类、情感分析;
- 信息检索(如搜索引擎排序);
- 关键词提取(如文章摘要生成);
- 文档相似度计算。
六、总结
TF-IDF 作为一种经典的文本特征提取方法,以其简单高效的特点在 NLP 领域经久不衰。它通过词频和逆文档频率的加权,有效突出文档中的关键信息,为后续的文本分析任务奠定基础。
尽管近年来词向量(如 Word2Vec)、预训练模型(如 BERT)在语义理解上表现更优,但 TF-IDF 在轻量化场景、可解释性要求高的任务中仍不可替代。掌握 TF-IDF 的原理和实现,是入门文本处理的重要一步。
希望本文能帮助你理解 TF-IDF 的核心思想,欢迎在实际项目中尝试并优化这一方法!
)






(超详细!)Vscode+espidf 摄像头拍摄视频实时传输到LCD,文末附源码)
)
)
|变量、函数与控制流)
![【渲染流水线】[几何阶段]-[图元装配]以UnityURP为例](http://pic.xiahunao.cn/【渲染流水线】[几何阶段]-[图元装配]以UnityURP为例)







