
OneEval官网地址:http://OneEval.OpenKG.cn
OneEval文章链接:https://arxiv.org/abs/2506.12577
要点导读

今年4月,OpenKG发布“大模型+知识库”融合能力评估榜单OneEval v1.0。近期,OpenKG在此基础上,组织撰写了OneEval评测白皮书,并对OneEval榜单进行了升级和更新,包括新增GPT5, Claude4等多个新模型,并引入更多评测数据集。白皮书部分要点如下:
在需要结合外部知识进行深度推理时,大模型普遍「不及格」:即使是GPT-5、Claude-4等顶级模型,综合得分也仅有60%左右,在难题上的表现更是断崖式下跌至30%以下。
大模型在知识推理上集体「偏科」:在处理表格、代码等结构化知识时性能尚可,但一旦面对复杂的知识图谱、逻辑规则和专业文档,模型的能力会迅速失效。
被寄予厚望的GPT-5并未展现出突破性优势,其与前代版本的微小差距,暴露出GPT系列在知识增强路径上的优化仍面临重大挑战。
1. 引言
OneEval 是由OpenKG发起并组织的中立、公益、专业的大模型评测榜单。区别于多数聚焦于“LLM”基础能力评测的现有榜单,OneEval 更加侧重于 “大模型 + 知识库(LLM+KB)” 的融合能力评估,重点考察知识增强驱动下大模型的慢思维能力(即模型在复杂问题上的深度思考与分步推理能力)与神经符号混合推理能力(结合神经网络与符号逻辑的知识推理能力),助力大模型向“知识深、思维强”的方向持续演进。
随着大语言模型(LLMs)的快速发展,最新一代推理型模型在自然语言理解与推理任务中表现出显著进步。尽管已有多项研究[1-4]从不同维度对 LLM 能力展开评估,但这些评测体系主要集中在通用理解和基础推理层面,缺乏模型在处理多类型异构知识与跨领域复杂推理任务中的系统性评估。特别是在知识增强场景下,模型如何有效利用外部知识源进行高质量推理的能力评估仍是研究空白。
在此背景下,2025年4月,OpenKG 推出 OneEval V1.0,希望为知识增强场景下的大模型综合能力评估提供一个系统化框架。OneEval V1.0包含十个典型任务,涉及四类知识载体和六大关键领域,深入衡量大模型对多种知识形态与多领域语境中的知识理解、知识利用与知识推理能力。
在V1.0的基础上,OpenKG 现正式发布全面升级的 OneEval V1.1。新版本在评测的广度和深度上均实现了显著扩展:
1)模型更广:评测对象从16个翻倍至32个,新增包括GPT-5、Claude4在内的10个最新的大语言模型。
2)数据更深:评测数据集扩充至15个,新增了包括税务推理、知识冲突、学术理解等任务的高质量数据集。
OneEval V1.1 致力于更全面、及时地追踪大模型在知识增强领域的前沿能力,为行业发展提供更具时效性与参考价值的评测基准。整体评测框架如图1所示。
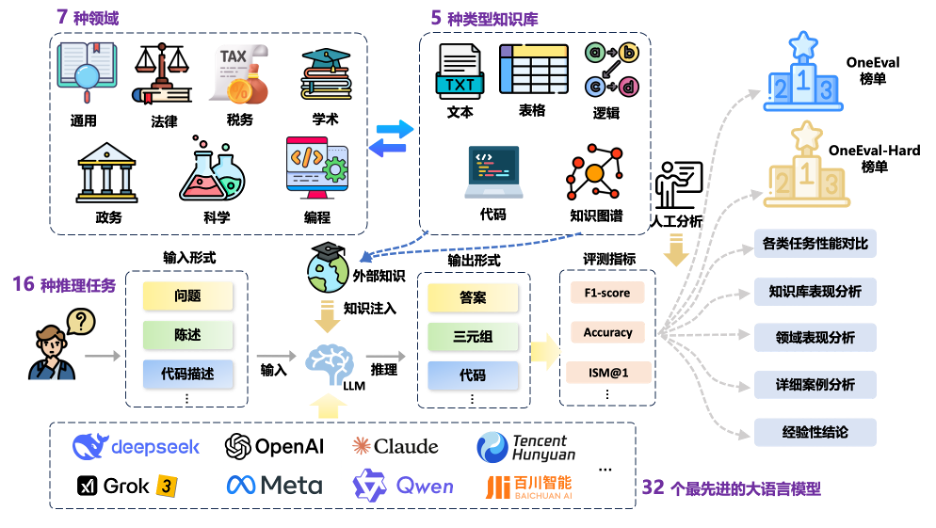
图1 OneEval评测框架示意图
OneEval 由 OpenKG SIGEval 工作组持续维护,评测数据与结果将定期更新,评测流程也将逐步引入多元防作弊机制,包括样本变体生成、模型输出标准化、多次采样验证、时效性验证以及对抗性问题构建等技术手段,并在可行范围内公开评测细节,努力保障评测的科学性、透明性与公平性。
2. 相关工作
在LLM的能力评估方面,已有许多国内外基准测试和排行榜对广泛的任务进行了探索与测试。大多数现有的基准测试可以被分为四个类别:(1) 知识考察型:以客观选择题和问答题等形式测试模型的学科知识掌握水平,包括MMLU[1]、CMMLU[2]、CEval[3]、AGIEval[4]等。(2) 指令遵循型:以问答等形式评估模型对用户指令的遵循能力,包括LLMBAR[5]、Flan[6]、NaturalInstructions[7]等基准测试。(3) 聊天对话型:使用多轮交互的问答数据测试模型的上下文理解和对话能力,包括CoQA[8]、MMDialog[9]、MT-Bench[10]和OpenAssistant[11]等。(4) 安全风险型:以选择题和问答题等形式评估模型的安全与幻觉风险,例如DecodingTrust[12]、AdvGLUE[13]、StrongReject[14]、HarmBench[15]等。
与单一基准测试不同,现有的知名排行榜通过整合多个评测任务、整理广泛评估场景,采用多维度、多任务的评估方法,构建更全面的大模型能力画像。HuggingFace 的 Open LLM Leaderboard 整合了 MMLU-Pro、GPQA、MuSR、MATH、IFEval 和 BBH 等六个基准测试,综合考核模型在知识理解、推理、数学解题、信息抽取和复杂任务处理等方面的能力。上海AI Lab的OpenCompass(司南)[17]构建了包括考试、知识、语言、理解、推理和安全六个维度的评测框架,通过引入动态更新的评测数据集确保评估的时效性和广度。来自北京智源的FlagEval(天秤)整合了30多项能力维度与30个基准测试,构建了超10万条评测样本的大规模评测库,包含文本、图像、音频等多模态信息。除基于标准化数据集的评测外,基于人类偏好的比较性评测近年来也获得广泛关注。来自UCB的Chatbot Arena Leaderboard(聊天竞技场)[18]创新性地采用众包+Elo排名机制,让人类评估者对模型回复质量进行两两比较,累积得出模型间的相对实力排名。斯坦福大学的AlpacaEval[19]则引入“LLM-as-a-Judge”方法,利用大模型作为评判,通过比较待测模型与参考模型回复的优劣,将相对胜率作为排名依据,大幅提升了评测的规模与效率[20]。
然而,现有的基准测试体系仍存在一些不足:1) 缺乏对复杂知识库推理能力的评估;2)知识载体单一,尚未全面涵盖如知识图谱、代码、表格结构化知识的测试维度。针对上述问题,OneEval 首次构建了统一的跨知识源、多领域复杂知识库推理任务评测框架,力求在评估大模型知识增强能力方面实现更高的覆盖性与科学性。
3. OneEval评测数据集
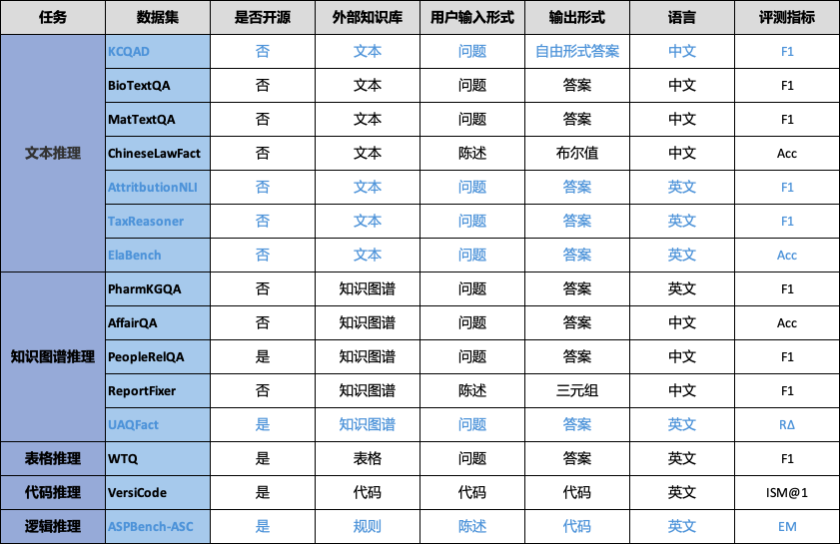
OneEval主要基于OpenKG自建或整理的公开数据资源,并将周期性增加和更新。OneEval V1.1 包含15个面向多类型知识库的推理评测数据集,覆盖结构化与非结构化、显性与隐性等多种知识形态,具有更高的知识特异性与任务复杂度。其中每个数据集包含约200条推理问题,相较于 MMLU、BigBench 等侧重通识能力的评测基准,OneEval 更聚焦于大模型在多源异构知识库中的深层理解与综合推理能力评估,以更贴近真实应用场景的方式推动知识增强型模型能力评测。评测数据集来源信息如表1所示。
表1 OneEval评测数据集来源信息
数据集 | 来源 |
BioTextQA | OpenKG自建,数据来源自biorxiv,生物学 |
MatTextQA | OpenKG自建,数据来源自arxiv,材料学 |
ChineseLawFact | OpenKG自建,数据来源真实中国法律文书 |
PharmKGQA | https://pubmed.ncbi.nlm.nih.gov/33341877/ |
AffairQA | OpenKG自建,源自浙大政务知识图谱 |
PeopleRelQA | https://tianchi.aliyun.com/competition/entrance/532196/ |
ReportFixer | OpenKG自建,源自内部研报数据 |
WTQ | https://arxiv.org/abs/1508.00305 |
VersiCode | OpenKG成员发布,版本敏感的代码生成,https://arxiv.org/abs/2406.07411 |
UAQFact | 根据Wikidata中抽样事实三元组作为事实知识构建 |
TaxReasoning | 基于中国税法政策文件构建,用于评测模型的数学推理与逻辑规则推理能力 |
ElaBench | OpenKG自建,根据AI领域顶会顶刊论文进行人工标注,涉及的细粒度学术知识 |
ASPBench-ASC | OpenKG成员发布,答案集编程,https://arxiv.org/abs/2507.19749 |
AttritbutionNLI | OpenKG成员发布,https://arxiv.org/abs/2401.14640,评测模型回答问题的归因能力 |
KCQAD | OpenKG自建,评测模型在面临知识冲突时的推理能力 |
3.1 评测任务
给定用户查询 Q 和可访问的知识库 S,目标是利用 S 中的信息生成所需答案 A。形式化地,任务是让一个大模型 f_θ 计算 A = f_θ(Q, S)。这里,查询 Q 可以以多种格式呈现,包括自然语言的问题、陈述、描述或代码片段。知识库 S 来自一组预先定义的不同类型(下面的小节将详细说明)。答案 A 应当是基于所给 Q 和 S 的有效推导或推理,其格式可以多样,涵盖自由形式文本、像三元组这样的结构化输出、布尔值或代码片段。
3.2 知识库类型
OneEval V1.1 基准涉及以下5种类型的知识库,后续还将增强更多的知识库类型:
文本知识库:涵盖非结构化文献与文档,测试模型在文本型知识的理解,以及复杂语境下的语义建构、信息抽取等能力。
表格知识库:以结构化表格数据为基础,考查模型在结构化知识的理解,以及对数值、分类与层级信息的处理、比较与逻辑计算能力。
知识图谱:基于实体-关系三元组构建的结构化语义网络,评估模型在图结构知识的理解,以及多跳推理、实体对齐与关系识别等任务中的表现。
代码知识库:包含函数文档、源代码与API说明,聚焦模型在程序型知识的理解,以及代码补全、自然语言到代码生成等能力。
逻辑知识库:逻辑库是对一个领域进行概念化的形式化、显式规范。它通常包括三项内容:概念集(即类),属性集(即概念间的关系),以及一组用于定义约束和逻辑关系的公理或规则。
表2 OneEval评测数据集任务类型与统计信息
3.3 领域类别
OneEval V1.1 覆盖通用、政务、科学、法律,编程,税务,学术六大关键知识领域,重点强调多源异构知识的广泛性与专业性,系统性评估LLM在复杂知识驱动任务中的推理与应用能力。具体类别信息如图2所示。
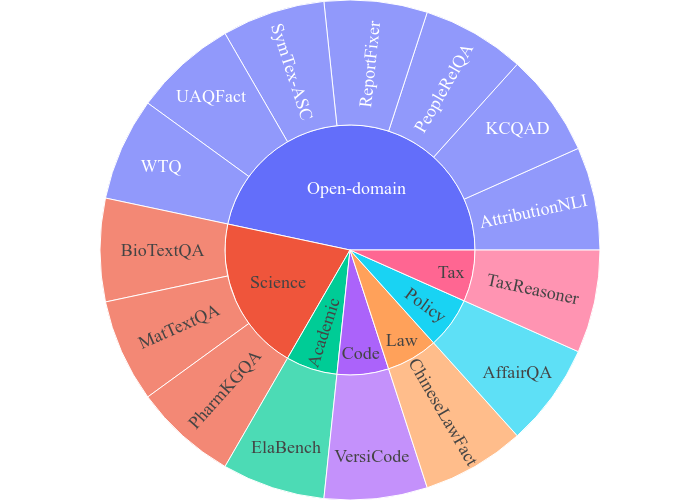
图2 OneEval评测数据集领域信息
通用(Open-domain):基于百科全书与综合性知识资源,涵盖来自各类百科知识库的开放领域知识,考察模型对跨主题背景知识的理解与迁移能力。
政务(Politics):基于中文政务文件与政府官网信息,聚焦政策条文、行政流程等结构化与半结构化知识,考验模型对规章制度的精准解析与政策应用能力。
科学(Science):整合来自生物、材料科学公开文献及生物医药知识图谱的专业知识,涵盖实验事实、领域术语与科学推理模式,测试模型的科学推理与知识整合能力。
法律(Law):源自真实法律文书,包含判决书、裁定书等法律事实与规则,突出模型对法律条文逻辑与案例事实的结合推理能力。
编程(Code):来自GitHub的海量开源代码库,跨越300+依赖库和2000+ API 版本,强调模型对程序语言、函数接口及语义执行的深入理解与生成能力。
税务(Tax):基于中国税法政策文件构建,用于评测模型的数学推理与逻辑规则推理能力。
学术(Academic):收集来自AI领域的顶会顶刊论文,组织拥有论文发表经验的硕士和博士生根据论文提出具有迷惑性的选择题,考验模型对细粒度的专业知识的理解、推理和判断能力。
3.4 OneEval-Hard
为更精准地评估LLM在高难度推理场景下的表现,我们基于多轮筛选和专家评审人工构建了一个困难样本子集——OneEval-Hard,其中每个数据集选择约50个样本,专门聚焦于模型在多步推理、隐式知识关联和跨域知识整合等推理任务中的薄弱环节。该子集不仅具备更高的判别性和难度,也为深入剖析LLM的知识盲区与推理瓶颈提供了重要测试依据,有助于推动更有针对性的LLM优化与能力提升。
4. OneEval评测框架
OneEval 评测框架(见图1)旨在系统化评估LLM在借助外部知识库完成推理任务时的表现,重点考察模型对各类知识库的理解能力及其有效运用方式。整个评测过程保持 LLM 参数不变,通过结合用户输入与检索到的外部知识构建提示,引导模型进行推理并按照任务的目标形式生成答案。
4.1 外部知识检索范式
由于本评测框架重点在于评估LLM在对各种类型的知识理解和运用能力,而非检索知识的能力,因此,对于涉及外部知识的任务,采用统一的检索范式,获取与测试样本相关的上下文信息。具体而言,基于Dense Retrieval的思路,其核心在于按用户输入与知识片段(文本片段、代码片段、三元组子图等)的稠密向量(q,K)之间的相似度S进行排序,选取top-k知识片段作为知识上下文。S的计算公式如下:
S(q, K) = cos(q, K)
其中,q和K分别表示由SentenceBERT模型编码得到的用户输入向量和知识向量。需要注意的是,通过上述方式检索获得的外部知识上下文中可能包含噪声。这种设置更贴近真实应用场景,为评估模型在面对不完美或冗余知识时的鲁棒性提供了有效的测试环境。
4.2 评测对象
本次版本的评测选择了多个国内外领先的研究团队和企业,涵盖开源与闭源、不同参数规模及不同技术路线的代表性LLM,详细信息如表3所示(按首字母排序)。新发布的 OneEval V1.1 版本进一步扩展了评测阵容,新增了 18 个最新或备受关注的大模型,其中包括 GPT-5、Qwen-3 和 Claude-4 等前沿模型。详细的模型列表请参见表3(按首字母排序),其中新增模型已用蓝色标出。
表3 评测对象统计信息
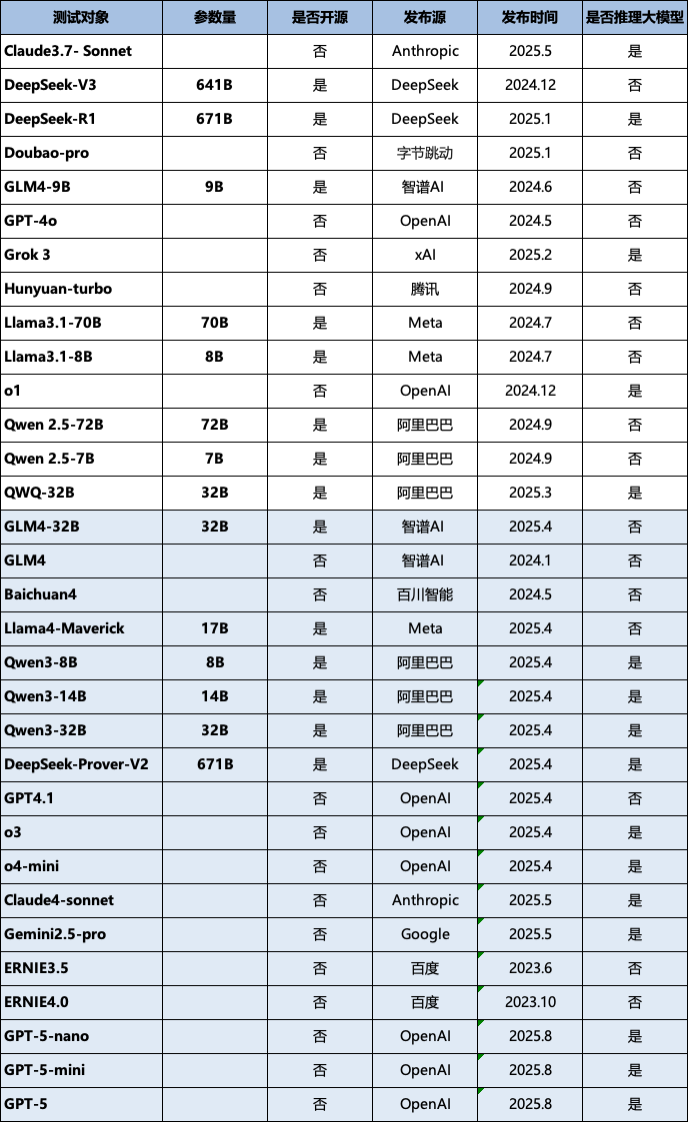
鉴于评测资源与时间成本的限制,目前仍有部分表现优异的大语言模型尚未纳入 OneEval 榜单。随着 OneEval 评测工作的持续推进,未来将逐步覆盖更多主流及前沿的大语言模型,从而实现更全面、系统的性能对比与能力分析。
4.3 评测指标
评测采用多维度指标体系,包括:
各任务评测指标:准确率(Accuracy,用于分类任务)、F1分数(平衡精确率与召回率,用于抽取和生成任务)、ISM@1(Identifier Sequence Match,用于代码生成任务),R∆(衡量模型在面对无法回答的问题时的能力)。具体指标分配详见表2。
综合评分:为了均衡考虑模型在不同任务上的综合表现,我们规定:一个模型的总体评分(Overall Score)为该模型在每个评测数据集得分的平均值。
4.4 总体评分
表4 OneEval总体榜单
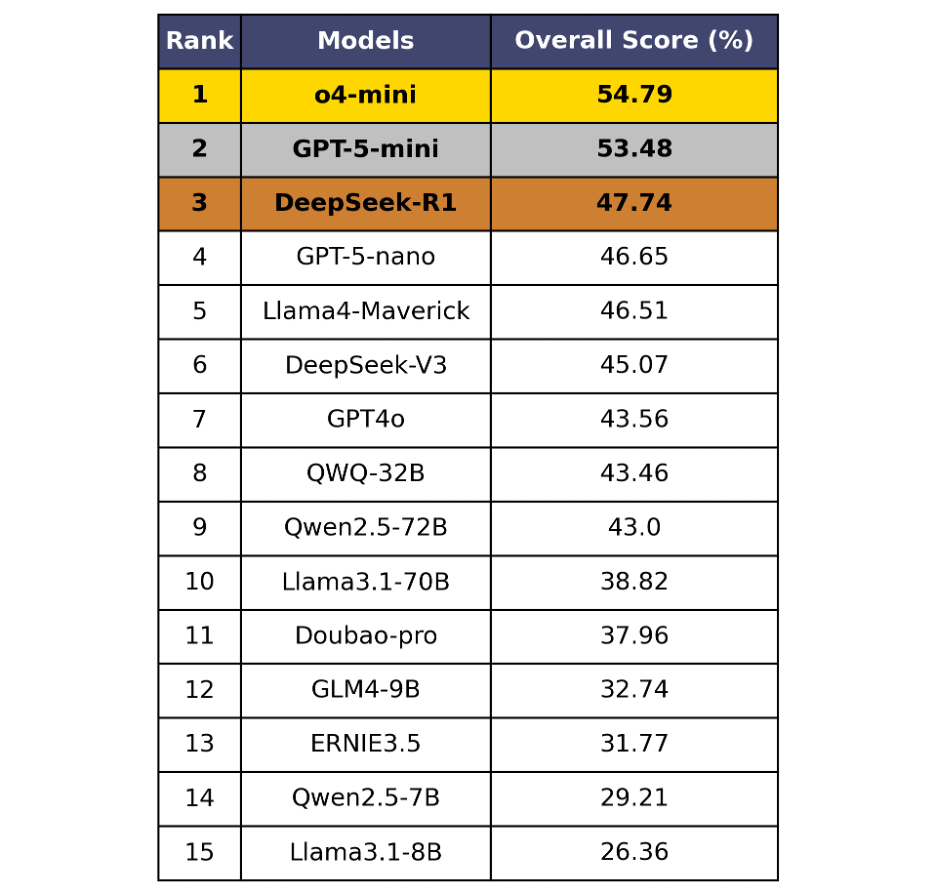
表5 OneEval-Hard总体榜单
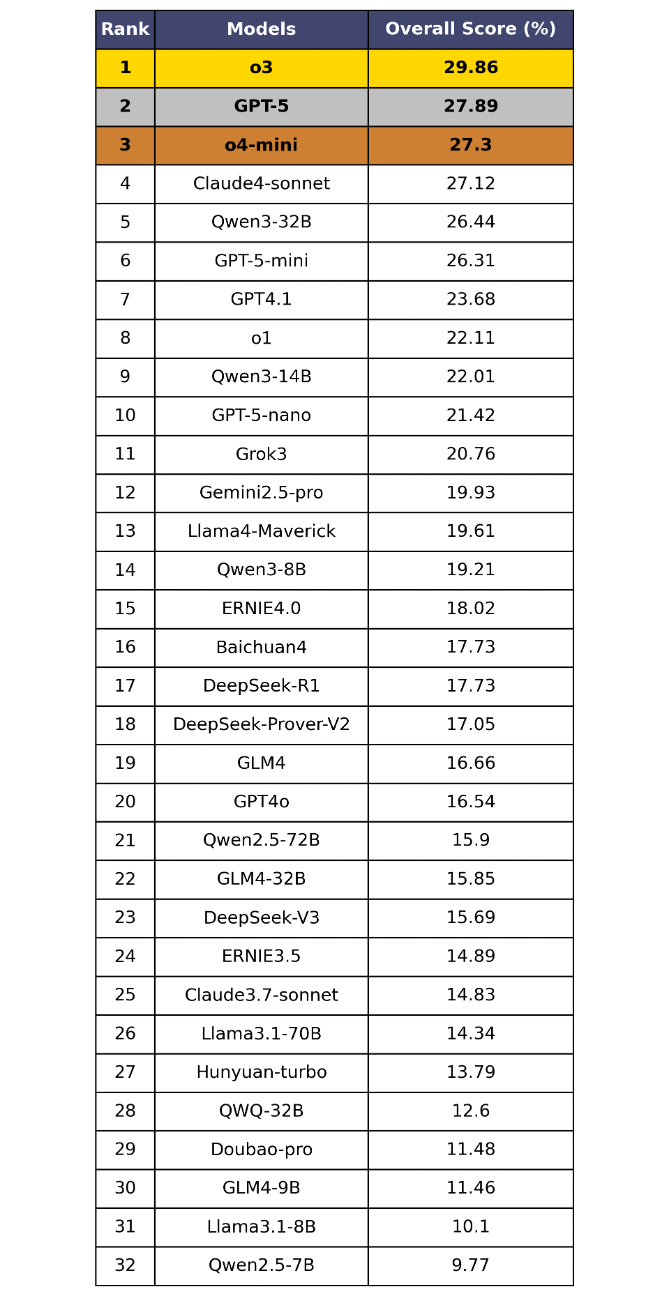
OneEval V1.1 的总体评测结果(表4和表5)清晰地揭示了当前大模型在知识增强推理场景下的能力现状与核心挑战,从中可以发现:
当前的LLM普遍在知识增强场景下的推理能力不足,离实用化差距巨大。在标准的OneEval评测中,即便是GPT-5、o4-mini等顶尖模型,得分也仅徘徊在50%左右,未能及格。这表明将大模型与知识库(LLM+KB)融合以解决复杂问题的能力,远未达到成熟和实用的水平。在更能体现深度思考能力的OneEval-Hard难题集上,性能更是出现断崖式下跌,榜首模型得分不足30%,暴露了当前LLM技术的严重短板。
GPT-5并未展现突破性优势,知识增强场景下的推理能力演进停滞。备受瞩目的GPT-5及其系列模型,在OneEval评测中并未展现出与市场预期相符的统治力,其与前代版本的得分差距极小。这强烈暗示,单纯依赖扩大模型规模和通用语料的路径,在提升模型真实的知识应用与推理能力方面已进入瓶颈期。GPT系列在OneEval所考验的知识增强任务上,演进幅度十分有限。
“小模型”表现亮眼,参数规模并非唯一解。评测结果显示,部分“mini”版本或经过特定优化的模型(如o4-mini)在总榜上的排名甚至超越了更大规模的通用模型。这说明在知识增强这类任务上,高效的知识调用与整合能力,其重要性不亚于模型的参数规模。这为行业指明了一条更具潜力的技术路径:优化模型与知识的协同方式,可能比无尽的“堆参数”更有效。
OneEval-Hard成为“慢思维”试金石,可以有效筛选深度推理模型。OneEval-Hard难题集极大地改变了模型的排名。o3、GPT-5等在底层推理上更具潜力的模型排名跃升,而一些在OneEval上表现尚可的模型(如DeepSeek-R1)则排名大幅下滑。这种显著分化证明了OneEval-Hard能有效地区分出模型的“快思考”(依赖模式匹配)与“慢思维”(依赖深度推理),成功筛选出在复杂问题上具备更强鲁棒性和深度思考潜力的模型,指明了“知识深、思维强”的演进方向。
4.5 各类知识库推理性能对比
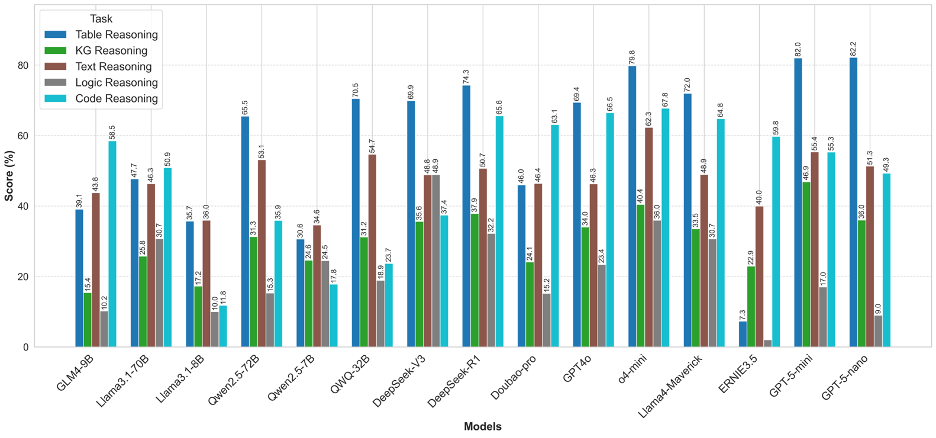
图3 OneEval不同类型知识库推理性能对比
OneEval的评测结果清晰地描绘了当前大模型在不同知识形态上的能力图谱。模型普遍在表格推理(Table Reasoning)和代码推理(Code Reasoning)上表现出较好的性能,以GPT-5系列和o4-mini为代表的顶尖模型在这些任务上能够达到70%-80%的高分。这表明,对于结构化或半结构化、规则相对明确的知识载体,现有模型架构已具备较强的理解和应用能力。相比之下,知识图谱推理(KG Reasoning)和逻辑推理(Logic Reasoning)则构成了所有模型的共同短板,得分普遍偏低。这揭示了一个核心挑战:模型虽然擅长处理序列化的文本和数据,但在需要进行多跳符号推理(KG)或遵循严格形式化公理(Logic)时,其能力显著不足,反映出当前模型在深度、抽象推理方面仍有巨大的提升空间。
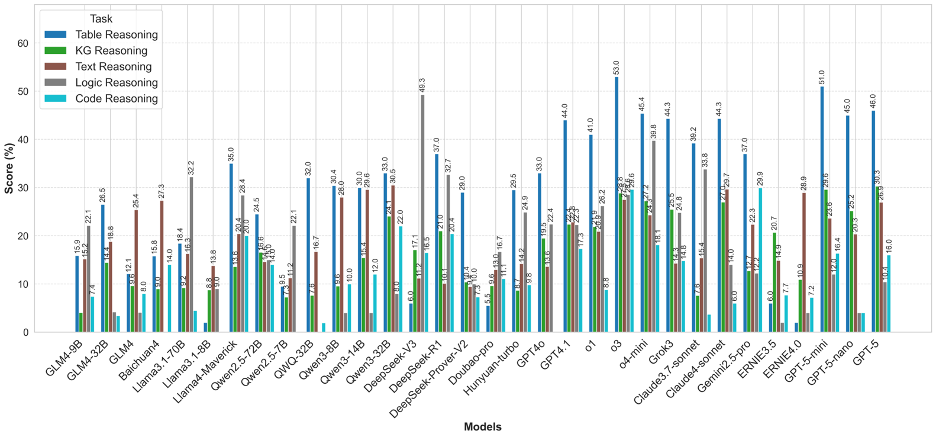
图4 OneEval-Hard不同类型知识库推理性能对比
OneEval-Hard的分析则如同一面“放大镜”,将模型在复杂任务中的能力边界和内在缺陷暴露无遗。首先,最显著的特征是所有模型在所有知识库类型上的性能都出现了断崖式下跌,这有力地证明了深度、多步推理是当前技术的普遍瓶颈。其次,能力分化变得更为极端:在知识图谱和文本推理上,绝大多数模型的性能几乎崩溃,得分趋近于零,说明当推理链条变长、语义语境变复杂时,模型的推理能力会迅速失效。在逻辑推理任务上,DeepSeek系列模型(尤其是DeepSeek-V3)展现出不错的性能。
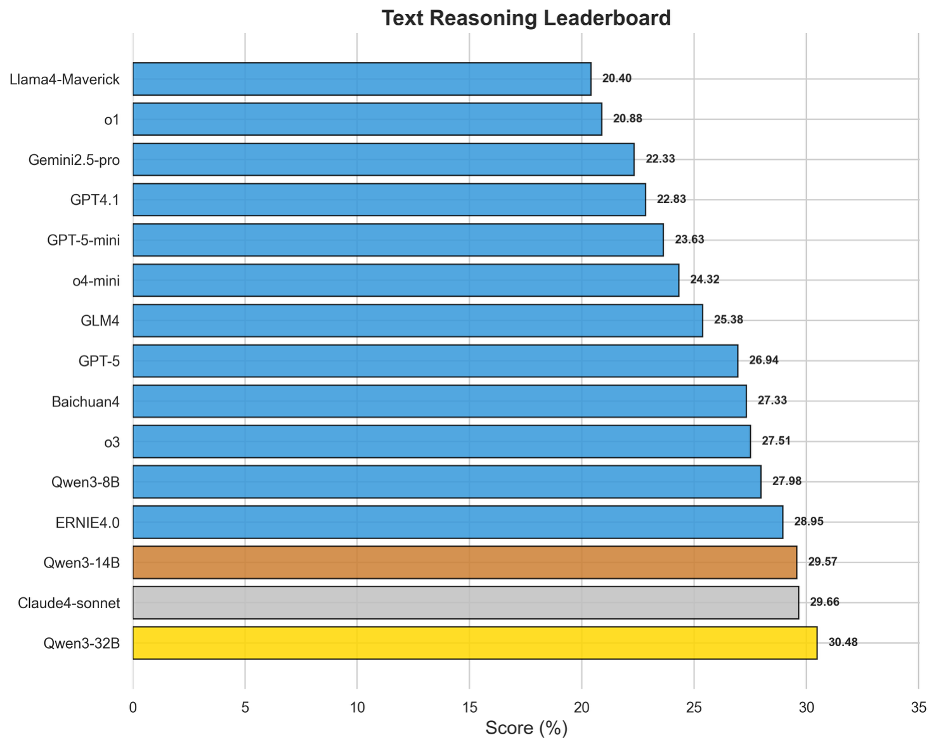
图5 OneEval-Hard文本推理表现排名
尽管文本是LLM的“母语”,但基于文本知识库的深度推理得分却普遍偏低,榜首Qwen3-32B的得分仅为30.48%。这有力地证明了OneEval评测的深度:它考察的并非简单的信息检索或摘要,而是对复杂文档(如学术论文、法律文书)进行深度语义建构和上下文推理的能力。榜单顶部模型非常密集,Qwen系列、Claude4-sonnet、ERNIE4.0和o3等模型得分十分接近,这表明在深度文本理解这个核心任务上,各类旗舰模型竞争异常激烈,但尚未有任何一家取得决定性优势,如何让模型真正“读懂、想透”复杂文本,依然是LLM发展的根本性课题。
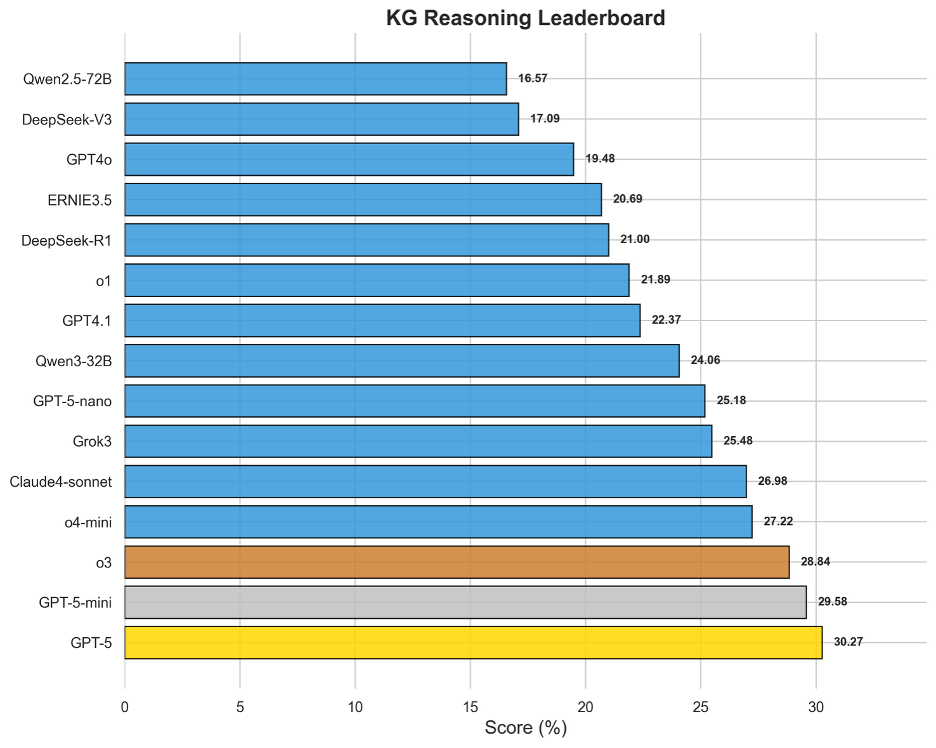
图6 OneEval-Hard知识图谱推理表现排名
知识图谱推理能力是衡量模型结构化知识理解与多步推理能力的关键。评测结果显示,这对于当前所有大模型都是一个显著的挑战,榜首模型GPT-5的得分也仅为30.27%。这一普遍偏低的表现,直接反映出在图结构数据中进行多跳推理、识别复杂关系和路径发现的内在困难。领先的模型如GPT-5、GPT-5-mini和o3在该榜单上占据前列,表明强大的通用推理核心是驾驭知识图谱的基础。然而,整体得分不高也预示着,如何让模型从本质上理解并高效导航符号化的语义网络,而非仅仅进行表面上的文本匹配,是“LLM+KG”融合技术亟待突破的瓶颈。
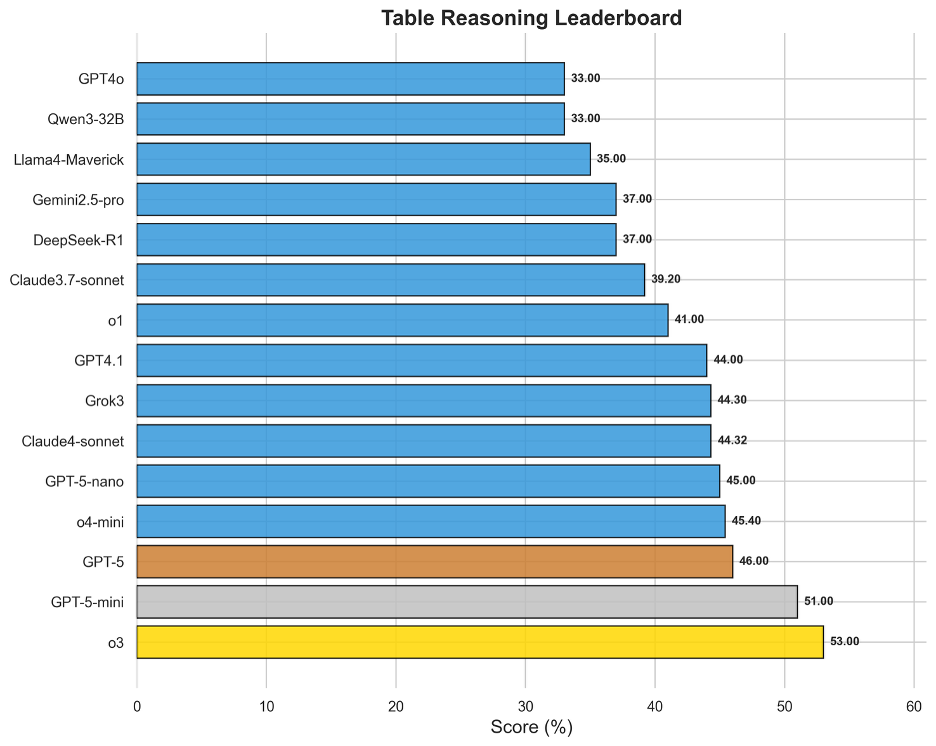
图7 OneEval-Hard表格推理表现排名
在所有知识库类型中,表格推理是当前大模型表现最为成熟的领域。o3以53.00%的得分夺魁,成为唯一在单项知识库评测中突破50%大关的模型。表格作为一种融合了自然语言(表头、单元格文本)和结构化数据(行列、数值)的知识载体,似乎与现有LLM的“世界模型”更为契合。榜单上,o3、GPT-5系列、o4-mini等顶级模型的得分普遍较高且差距不大,说明领先模型已基本掌握了在表格上进行查找、比较、排序和简单计算的能力。
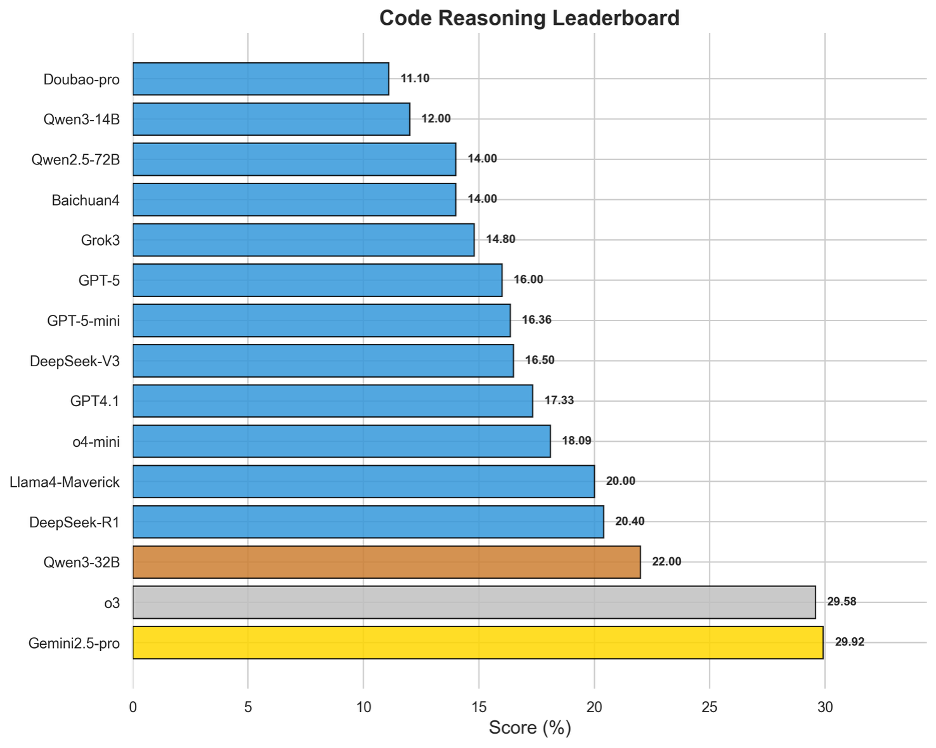
图8 OneEval-Hard代码推理表现排名
代码作为一种形式化的、逻辑严谨的知识库,其深度推理能力评测结果揭示了模型的另一块“硬骨头”。榜单呈现出清晰的“断层”现象:Gemini2.5-pro(29.92%)与o3(29.58%)以微弱差距共同领跑,并与后续模型拉开了显著距离。这表明顶尖的代码推理能力(如理解复杂算法逻辑、API依赖关系等)是少数顶尖模型的专属优势。整体得分与知识图谱同样处于低位,这说明模型将自然语言指令精确转化为程序逻辑,并对现有代码库进行深度分析和调试的能力还未成熟,是模型在专业化、高精度应用场景中的核心短板。
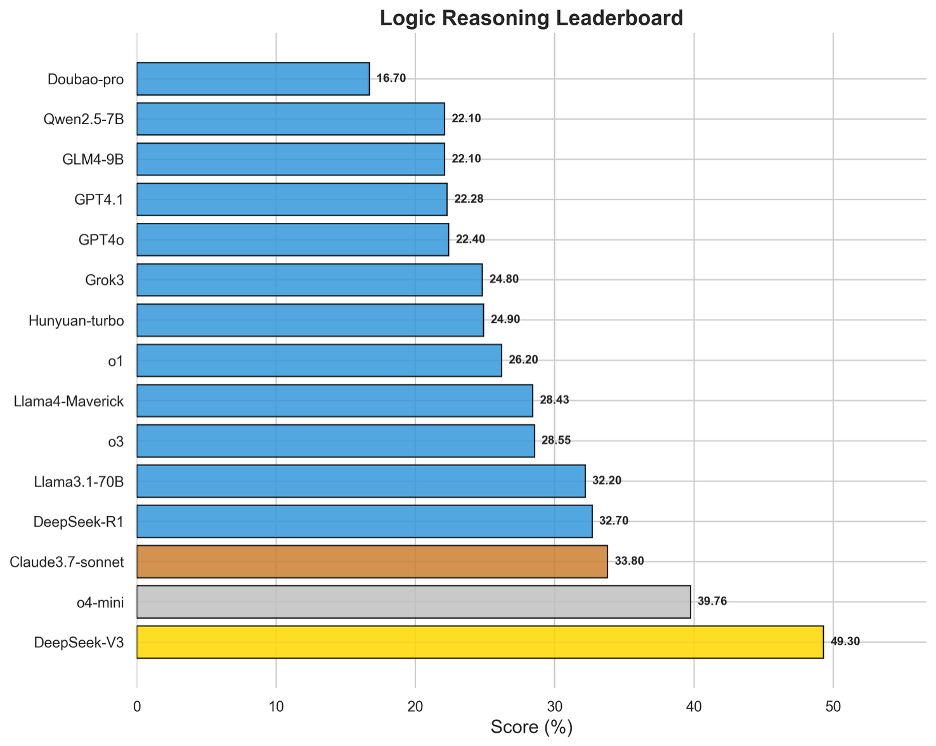
图9 OneEval-Hard逻辑推理表现排名
逻辑推理榜单的结果比较出人意料。DeepSeek-V3以49.30%领先,与第二名o4-mini(39.76%)拉开了近10个百分点的巨大差距。这表明,在遵循形式化、显式规则进行推演这一特定能力上,新模型并没有具备更强的推理性能。DeepSeek-V3的逻辑推理性能,很可能源于其在架构设计或预训练阶段对符号推理和逻辑规则的特定强化。
4.6 不同领域推理性能对比
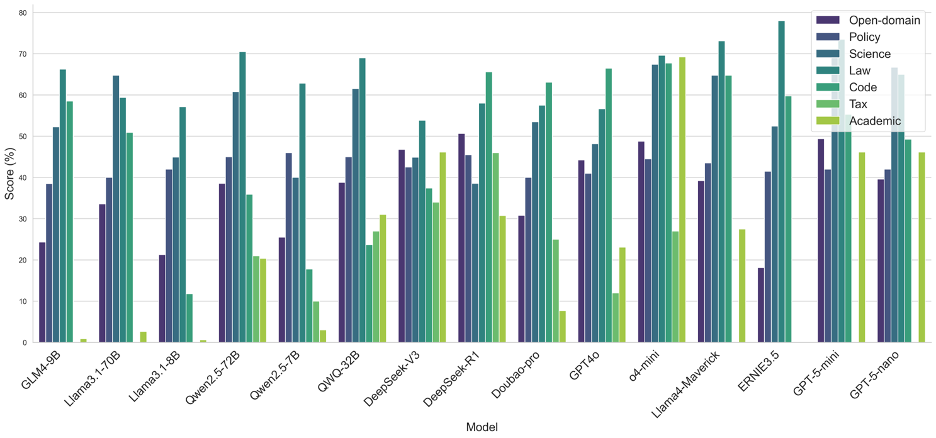
图10 OneEval不同领域的模型表现性能对比
从OneEval的领域性能分布来看,当前大模型的能力呈现出明显的领域偏向性。绝大多数模型在法律(Law)、代码(Code)和科学(Science)领域表现突出,这表明模型对于结构化、逻辑性强、事实明确的知识领域具有更强的理解和应用能力,这可能得益于预训练语料中该类数据的高质量和大规模覆盖。相比之下,几乎所有模型在学术(Academic)和政务(Policy)领域的表现均显著偏低。从中可以看出,模型在处理需要深度、专业领域知识解读(学术文献)或涉及复杂社会背景与细微语义理解(政策文件)的任务时,能力尚有不足。
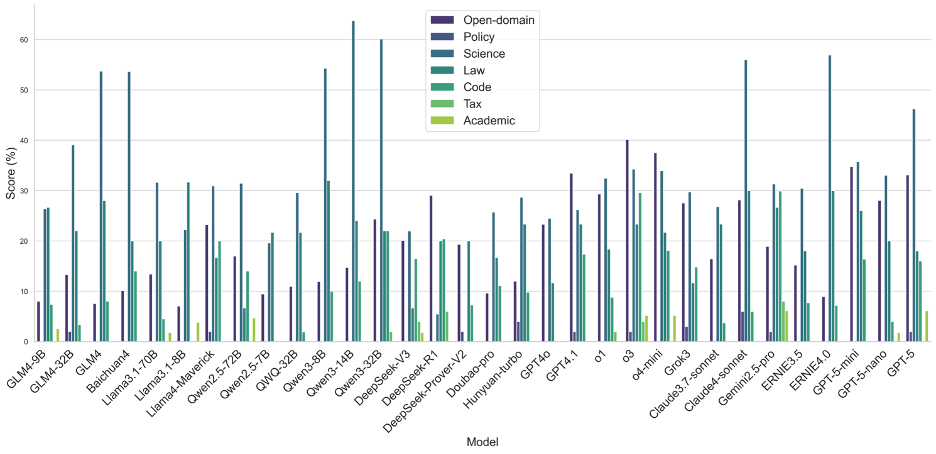
图11 OneEval-Hard不同领域的模型表现性能对比
OneEval-Hard的领域分析则更深刻地揭示了模型在深度推理任务中的“能力短板”。与Full Set相比,OneEval-Hard上各模型在所有领域的性能均大幅下降,且领域的强弱分化愈发极端。在学术(Academic)和税务(Tax)这两个知识密集且推理链条长的领域,绝大多数模型的性能几乎崩溃,得分趋近于零,这证明了在面对真正复杂的知识推理挑战时,现有模型架构的鲁棒性严重不足。一个值得注意的现象是,在Hard Set中,政务(Policy)和通用域(Open-domain)成为了少数顶尖模型(如Qwen-32B, o3)的相对优势领域。这可能说明,这些领先模型具备了更强的抽象推理和复杂信息整合能力,使其在处理逻辑判断而非纯粹知识检索的难题时,能更好地维持其性能,这也反映了OneEval评测体系在筛选具有“慢思维”潜质模型方面的有效性。
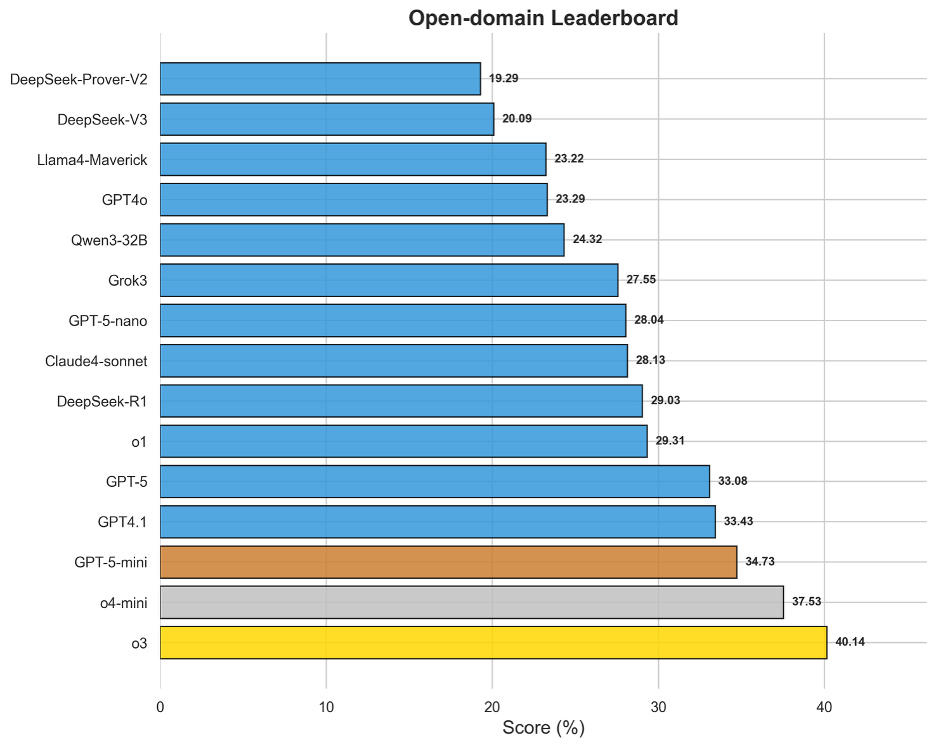
图12 OneEval-Hard通用领域模型排名
通用域的评测结果有效地衡量了模型在无特定领域限制下的通用复杂推理能力。该榜单的领先模型,如o3(40.14%)、o4-mini(37.53%)和GPT-5-mini(34.73%),普遍是那些在行业内被认为具备强大底层逻辑和“慢思维”潜力的模型。值得注意的是,即便对于榜首的o3,其得分也刚过40%,表明在处理需要多步推演、信息整合和创造性问题解决的通用难题时,所有模型仍有提升空间。
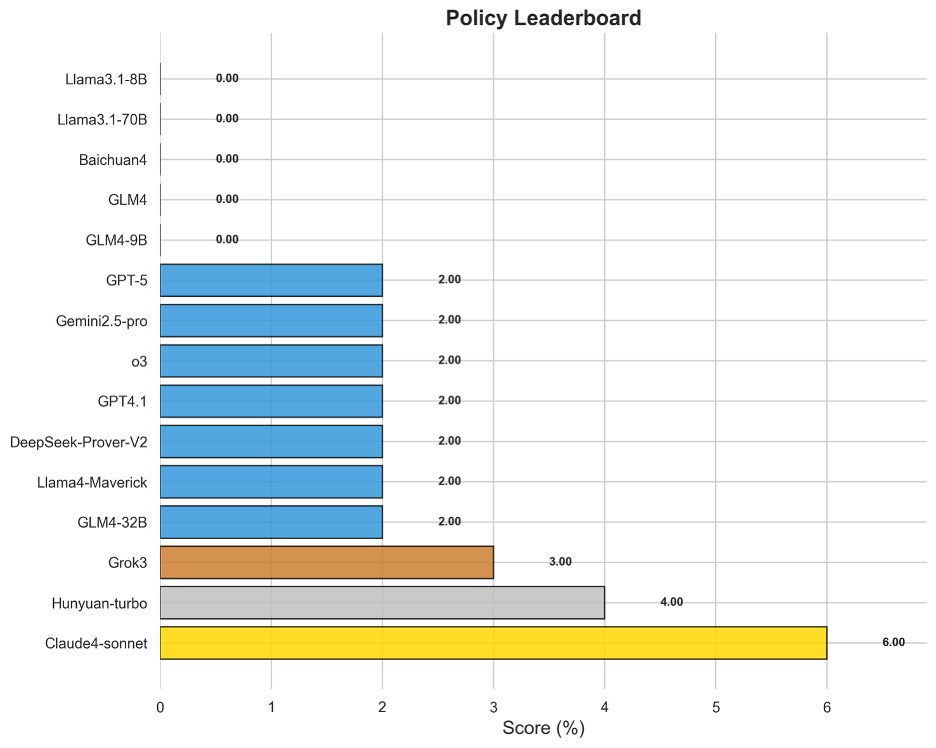
图13 OneEval-Hard政务领域模型排名
中文政务领域的评测结果最为严峻,堪称当前大模型能力的“试金石”。绝大多数模型在此项得分接近于零,即便是表现最好的Claude4-sonnet也仅获得6.00%的得分。这毁灭性的结果有力地证明,模型在理解充满社会背景、微妙语气和复杂条件的政策文本方面存在根本性缺陷。政策推理不仅需要文本理解,更需要对意图、影响和潜在冲突进行高阶解读,这种高度依赖中文语境和常识的“软”推理能力,是当前模型架构最薄弱的环节。
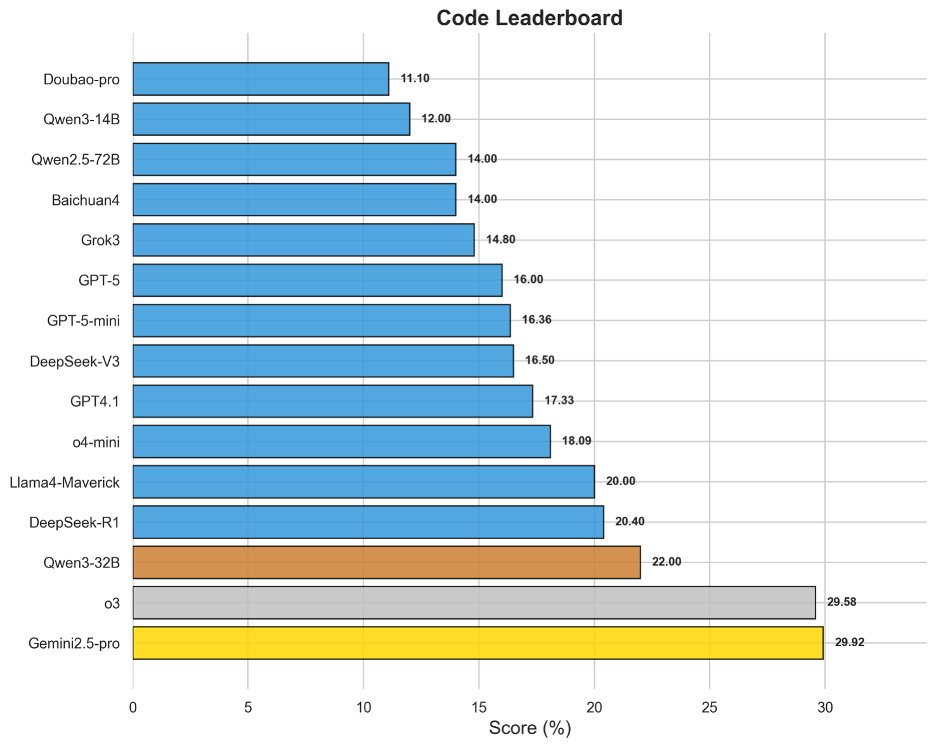
图14 OneEval-Hard编程领域模型排名
代码领域专注于评估模型在复杂算法理解、逻辑调试和代码库层面的推理能力,尤其注重模型理解各种代码版本的细微差异,难度远超简单的代码生成。Gemini2.5-pro(29.92%)和o3(29.58%)以显著优势位居榜首,与后续模型拉开了较大差距。Gemini系列在代码领域的传统优势与o3的强大通用推理能力在此得到共同验证。该领域榜单整体得分较低,说明将代码作为一种形式化语言进行深度理解和操作,仍然是当前大模型技术的一大瓶颈。
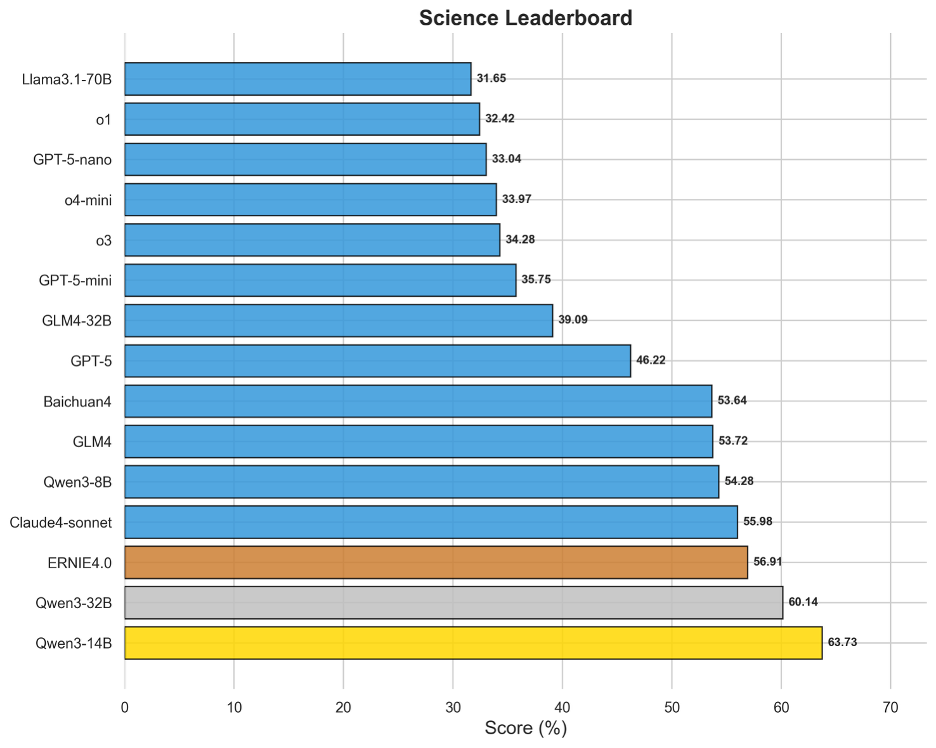
图15 OneEval-Hard科学领域模型排名
与政策、税务等领域形成鲜明对比,科学领域是Hard Set中模型表现最好的部分。Qwen3-14B(63.73%)和Qwen3-32B(60.14%)等模型取得了超过60%的高分,展现出强大的实力。这表明,对于基于事实、数据和严谨逻辑的科学问题,即使难度很高,当前领先的模型也已具备较强的解决能力。这可能得益于预训练语料中海量的科学文献、教科书和数据集,使得模型在理解材料学、生物学概念等定律进行推理时更为可靠。
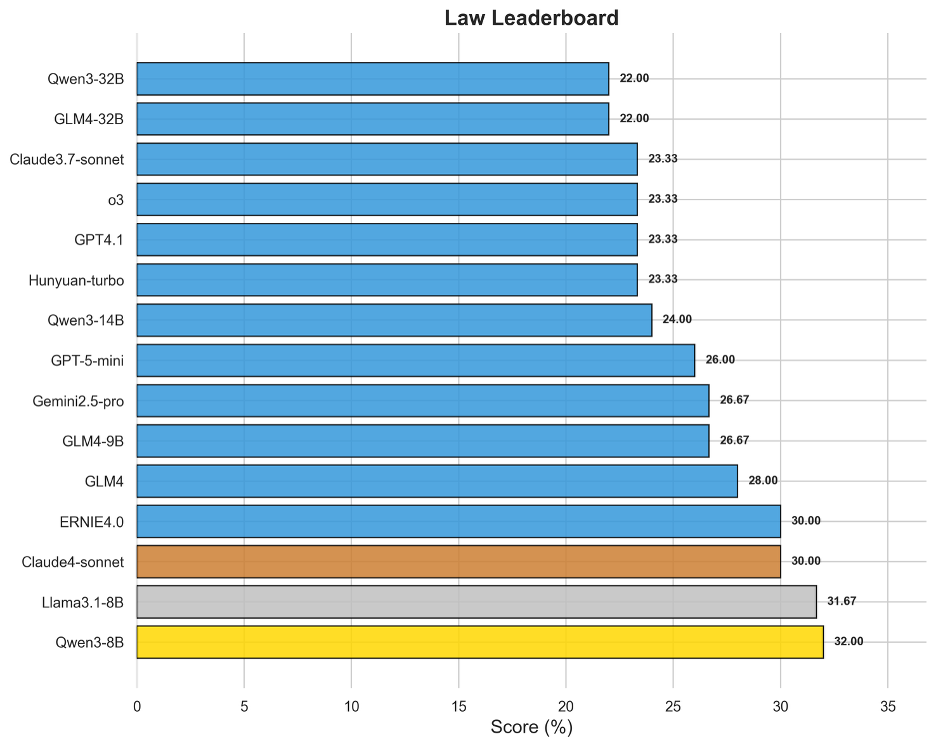
图16 OneEval-Hard法律领域模型排名
法律领域的Hard Set评测揭示了模型在处理复杂法律条文、案例情景和逻辑悖论时的能力极限。出人意料的是,Qwen3-8B(32.00%)和Llama3.1-8B(31.67%)等规模相对较小的模型在此领域表现突出,甚至超越了许多更大规模的旗舰模型。这一现象可能表明,对于法律这种高度结构化、规则明确的领域,模型对特定语料的精深理解和对逻辑关系的精准捕捉,其重要性超过了单纯的参数规模。榜单上分数普遍不高(最高仅32%)且模型间差距较小,说明深度法律推理对所有模型都是一个普遍性难题。
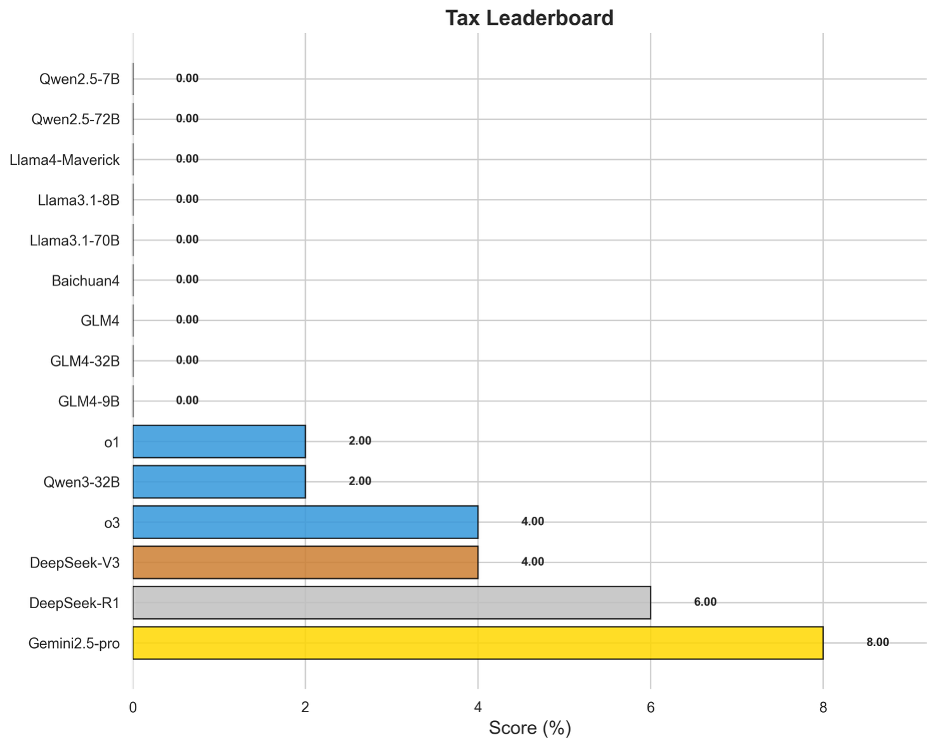
图17 OneEval-Hard税务领域模型排名
税务领域的评测结果与政策领域类似,揭示了模型的另一个重大短板。榜首的Gemini2.5-pro得分仅为8.00%,而绝大多数模型无法得分。税务任务要求模型将法律条文般的精确规则与具体的数值计算相结合,并处理大量的例外条款和前提条件。这种神经符号混合推理(结合文本理解与符号计算)的失败表明,模型难以在长推理链中稳定地、精确地应用一个复杂的规则系统,这是未来模型发展需要攻克的核心技术难题。
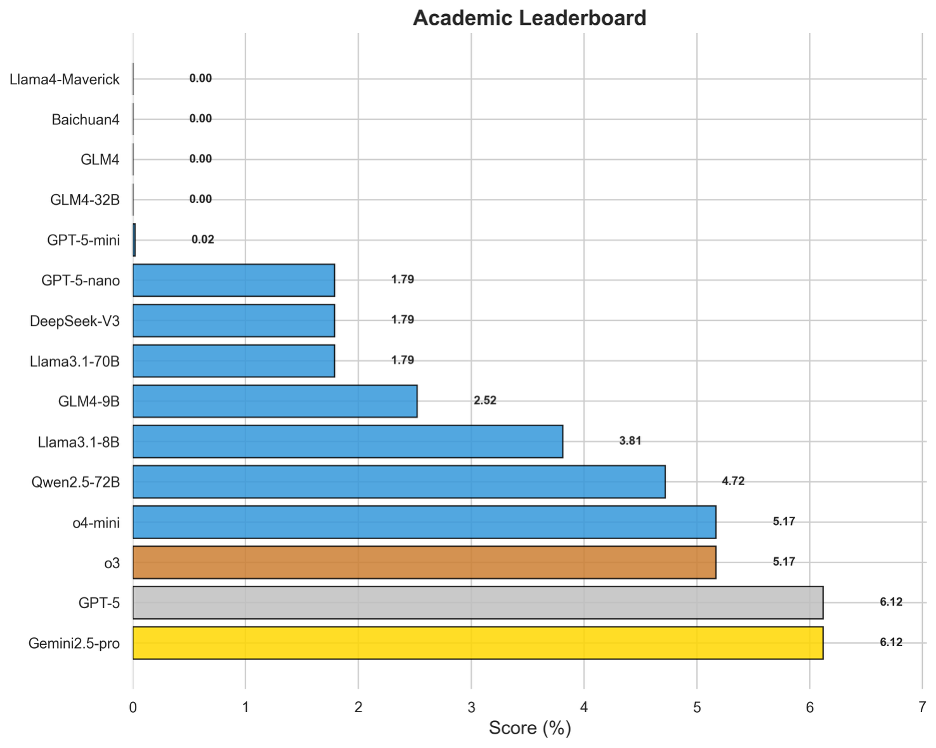
图18 OneEval-Hard学术领域模型排名
学术领域的评测旨在考察模型对前沿、高度专业化知识的理解和推理能力。与税务和政策领域相似,该领域的得分也极低,Gemini2.5-pro和GPT-5以6.12%并列第一。这说明,当面对最新研究论文中提出的新概念、复杂实验和精微论证时,模型无法像人类专家那样进行有效的“即时学习”和深度思辨。它们更多地依赖于预训练知识的“召回”,而非真正的“理解”与“推理”,这限制了它们在科研创新辅助等前沿场景中的应用潜力。
4.7 GPT-5系列模型性能对比
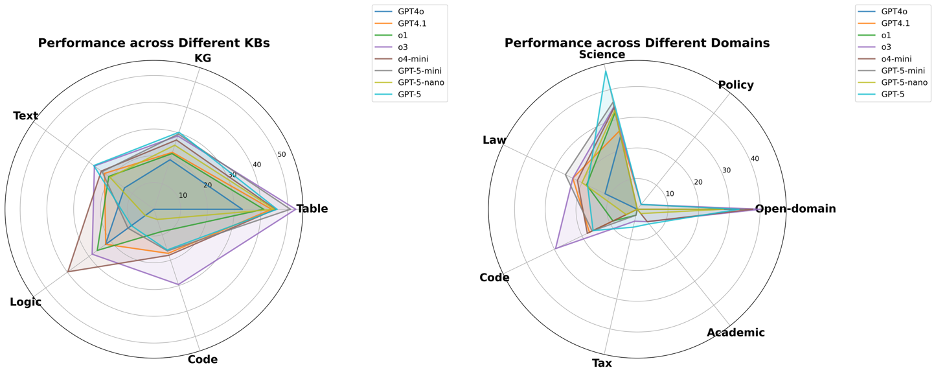
图19 GPT系列模型性能对比
从图19中可以看出,GPT-5系列(GPT-5, GPT-5-mini, GPT-5-nano)展现了清晰的家族化特征,即它们的性能轮廓(相对强弱项)高度相似,仅在整体能力半径上有所区别。
GPT-5性能呈现非均衡性,并未在所有知识类型上取得领先。雷达图显示,旗舰模型GPT-5(浅蓝色线)在文本(Text)和知识图谱(KG)推理任务上,确实达到了OpenAI系列中的领先水平。然而,这种优势并未延续到所有知识类型。在逻辑(Logic)、代码(Code)和表格(Table)推理上,其表现并未显示出决定性优势,尤其是在逻辑和代码知识库的评测中,其得分甚至低于GPT-4o等部分早期版本。这表明GPT-5的能力提升并非全面性的,而是在特定推理类型上有所侧重。
专业知识领域的“能力黑洞”揭示行业共同瓶颈。一个跨模型的普遍性短板是,在政务(Policy)、税务(Tax)和学术(Academic)三个专业领域,几乎所有顶尖模型(包括GPT-5系列)的得分都极低。这一现象揭示了当前大模型技术的共同瓶颈:即便是参数规模庞大的顶尖模型,在处理需要深度理解社会语境、遵循复杂规则进行精确演算,或对前沿专业知识进行细粒度解读的任务时,其能力仍显不足。
“大”不等于“强”,规模优势在知识增强场景的推理任务上未能完全体现。一个值得关注的现象是,规模较小的GPT-5-mini在某些任务上的表现反超了旗舰级的GPT-5。具体而言,在处理逻辑(Logic)、表格(Table)、代码(Code)等类型的知识库,以及在法律(Law)等特定领域中,GPT-5-mini取得了更高的分数。这表明,GPT-5的巨大参数规模和通用能力,并不能直接等同于在所有专业和复杂的知识增强任务上的性能优势。这一结果进一步佐证,提升模型的真实推理能力可能需要超越单纯增加模型规模的路径,而更需要在模型架构或训练范式上进行更具针对性的创新。
5. 总结与展望
OneEval是一个侧重于“大模型 + 知识库(LLM+KB)”融合能力评估的评测体系。本次发布的V1.1 版本涵盖了五种知识库类型和七大关键领域,旨在全面衡量大模型的知识增强推理能力。
不同于那些一旦发布就内容固定的静态评测集(如高考、资格考试等),大模型可以通过针对性的数据“刷题”来提升分数,OneEval从根本上挑战了这种“应试”模式。我们的核心优势在于评测体系的多维度动态性,这使得模型无法通过简单的记忆或数据覆盖来“背答案”,从而更精准地“照”出其真实的推理能力瓶颈。
展望未来,OneEval将致力于打造一个与技术发展同步演进的“活”的评测基准(Living Benchmark),其动态性主要体现在以下三个方面:
1)数据集数量的动态增加:我们将持续纳入由OpenKG及社区自主研发的新评测数据集,不断扩展评测的广度与维度。
2)存量数据集的动态更新:我们将对现有数据集进行周期性的内容迭代与刷新,引入新的案例、数据和问题变体,确保评测的时效性。
3)基于知识图谱的动态生成:我们将引入从大规模知识图谱中动态采样和生成评测样本的机制。这意味着评测问题本身就是实时演化的,从根本上杜绝了模型“刷题”的可能性。
这种多层次的动态设计,将迫使大模型从“记忆知识”转向“理解和运用知识”,真正考验其在知识增强驱动下的慢思维与神经符号混合推理能力。我们期望通过这一努力,支持大模型向“知识深、思维强”的方向不断演进。
当然,构建一个完全客观、公正、可重复的大模型评测榜单本身就是一项极具挑战的工作。我们充分意识到当前评测框架仍有很多不足,并在防作弊策略等方面有待进一步完善。我们期待未来能与更多研究者携手,共同推进评测体系的持续优化,促进大模型在知识增强与推理能力方面不断进步。
6. 评测组织
OneEval 评测由 OpenKG.SIGEval(官网:http://openkg.cn/sigeval/)组织发起,参与单位包括东南大学认知智能研究所、浙江大学知识引擎实验室、同济大学知识计算实验室以及苏州大学自然语言处理实验室、东南大学未来法治与数智技术创新实验室。详细人员列表如下所示:
组织人:
漆桂林 教授 东南大学
陈华钧 教授 浙江大学
王昊奋 教授 同济大学
陈文亮 教授 苏州大学
主要评测人员:
陈永锐 博士后 东南大学
丁科炎 研究员 浙江大学
王奕淞 硕士 同济大学
评测报告校对人:
吴天星 副教授 东南大学
张文 副教授 浙江大学
毕胜 讲师 东南大学
技术支持与维护:
邓鸿杰 浙江大学
数据贡献与实验:
刘治强 浙江大学
喻靖 浙江大学
吴桐桐 Monash University
胡楠 东南大学
戴鑫邦 东南大学
任林 东南大学
康家溱 东南大学
刘佳俊 东南大学
谈川源 苏州大学
参考文献
[1] Hendrycks D, Basart S, MuJavidy M, et al. Measuring Massive Multitask Language Understanding[C]// ICLR. 2021.
[2] Li H, Zhang Z, Zhang B, et al. CMMLU: Measuring massive multitask language understanding in Chinese[C]// ACL. 2023.
[3] Huang Y, Yue Y, Yuan Z, et al. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models[C]// NeurIPS. 2023.
[4] Zhong W, Zhou S, Yao J, et al. AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models[C]// NAACL. 2024.
[5] Zeng Z, Shen K, Liu Z, et al. Evaluating Large Language Models at Evaluating Instruction Following[C]// ICLR. 2024.
[6] Longpre S, Hou L, Beever A, et al. The flan collection: Designing data and methods for effective instruction tuning[C]// ICML PMLR. 2023.
[7] Mishra S, Khashabi D, Baral C, et al. Cross-Task Generalization via Natural Language Crowdsourcing Instructions[C]// ACL. 2022.
[8] Reddy S, Chen D, Manning C D. Coqa: A conversational question answering challenge[J]. TACL. 2019.
[9] Feng J, Zhang Z, Li X, et al. MMDialog: A Large-scale Multi-turn Dialogue Dataset Towards Multi-modal Open-domain Conversation[C]// ACL. 2023.
[10] Zheng L, Chiang W, Ying H, et al. Judging llm-as-a-judge with mt-bench and chatbot arena[C]// NeurIPS. 2023.
[11] Köpf A, Kilcher Y, von Werra L, et al. Openassistant conversations-democratizing large language model alignment[C]// NeurIPS. 2023.
[12] Wang B, Chen H, Zhang Z, et al. DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models[C]// NeurIPS. 2023.
[13] Wang B, Chen H, Xu C, et al. Adversarial GLUE: A Multi-Task Benchmark for Robustness Evaluation of Language Models[C]// NeurIPS. 2023.
[14] Souly A, Sreedhar K, Das S. A StrongREJECT for Empty Jailbreaks[C]// ICLR Workshop. 2024.
[15] Mazeika M, Phan L, Stoker A, et al. HarmBench: a standardized evaluation framework for automated red teaming and robust refusal[C]// ICML. 2024.
[16] Fourrier, Clémentine, et al. Open LLM Leaderboard v2. 2024, Hugging Face,https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard.
[17] OpenCompass Contributors. OpenCompass: A Universal Evaluation Platform for Foundation Models. 2023, https://github.com/open-compass/opencompass.
[18] Chiang, Wei-Lin, et al. "Chatbot arena: An open platform for evaluating llms by human preference." ICML. 2024.
[19] Dubois, Yann, et al. "Length-controlled alpacaeval: A simple way to debias automatic evaluators." arXiv preprint arXiv:2404.04475 (2024).
[20] Li, Yijiang, et al. "Core knowledge deficits in multi-modal language models." arXiv preprint arXiv:2410.10855 (2024).
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。




技术支持高速串行数据传输,支持1080p/60Hz高分辨率传输)


)
 ——通用端口)



=>UAC+STM32 ADC+PWM实现录音和播放)
)




)
