目录
1.回文链表
分析:
代码:
2.相交链表
分析:
代码:
3.环形链表
分析:
代码:
面试提问:
4.环形链表II
分析1:
分析2:
代码:
5.随机链表的复制
分析:
代码:
6.对链表进行插入排序
分析:
代码:
7.删除排序链表中的重复元素 II
分析:
代码:
1.回文链表
限制时间复杂度是O(n),空间复杂度为O(1);
给定一个链表的 头节点 head ,请判断其是否为回文链表。
如果一个链表是回文,那么链表节点序列从前往后看和从后往前看是相同的。
示例 1:

输入: head = [1,2,3,3,2,1] 输出: true
示例 2:

输入: head = [1,2] 输出: false
提示:
- 链表 L 的长度范围为
[1, 105] 0 <= node.val <= 9
分析:
先找到中间位置,从中间位置到末尾的链表进行逆置,将逆置完毕的链表和开始位置到中间位置的链表进行比对,若相同那么就是回文链表。
1.找到链表的中间位置
这里使用快慢指针,对于快指针一次走两步,慢指针一次走一步;
如果链表元素个数是偶数那么快指针走到NULL停止,如果链表元素个数是奇数,快指针走到链表最后一个元素停止,停止的条件是:fast->next == NULL || fast == NULL,那么继续的条件就是取反:fast->next != NULL && fast != NULL;
如此以来循环结束之后,slow指针指向的就是链表的中间位置。
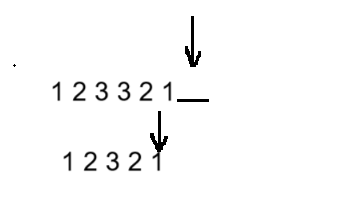
2.逆置链表
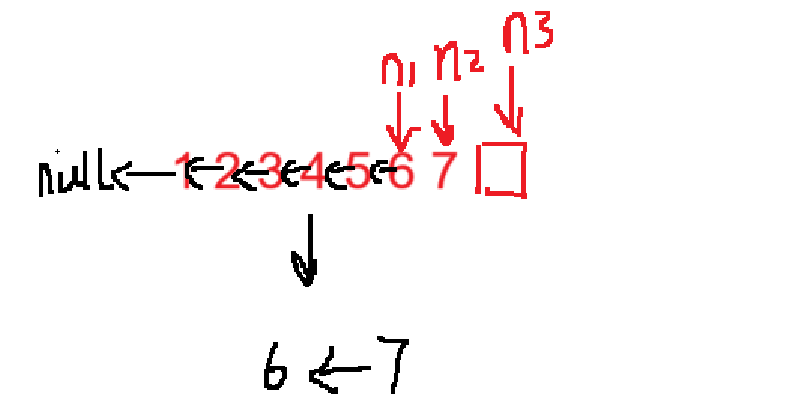
使用三个指针,分别指向NULL,head,head->next,这里需要在程序之前判断链表元素的个数为0或者1直接返回头结点。
n2指向n1,n1更新为n2,n2更新为n3,n3更新为n3->next,当n3为空的时候,终止循环,此时链表的最后两个节点没有完成逆置,所以需要手动进行逆置。
逆置完毕之后,n2就是逆置之后的链表的头结点。
3.衔接的问题
当链表是偶数的时候,逆置中间的元素,那么此时需要将中间元素的前一个元素的指针进行断开,奇数也是如此。
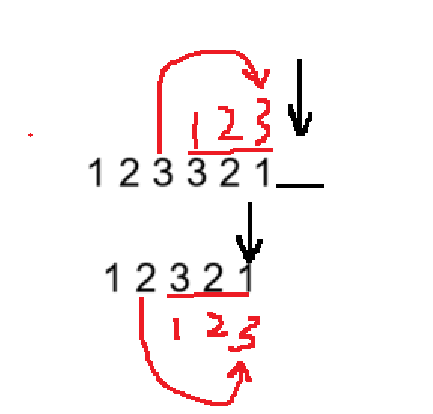
想要断开与中间节点的连接,这里还需要知道中间节点的前一个节点,在求中间节点的时候可以设置变量记录下来,然后使其指向NULL,这样一来就断开与中间节点的连接了;
最后就是比较回文了,我们发现回文链表有可能是奇数也有可能是偶数,如果是偶数就不用担心比较的方法,如果是奇数,则这里需要按照前半段的链表(较短)来比较。
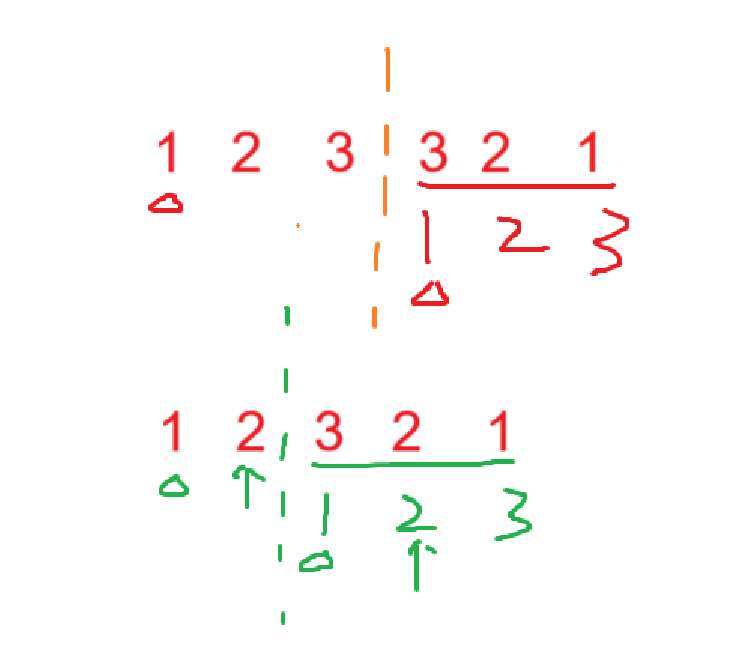
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode;
ListNode* reverseList(ListNode* head) {// 如果0、1个节点,返回自身if (head == NULL || head->next == NULL) {return head;}// 定义三个指针ListNode* p1 = NULL;ListNode* p2 = head;ListNode* p3 = head->next;while (p3) {p2->next = p1;p1 = p2;p2 = p3;p3 = p3->next;}// n3为空的时候,最后一次反转还没开始p2->next = p1;return p2;
}
bool isPalindrome(struct ListNode* head) {ListNode* fast = head;ListNode* slow = head;ListNode* prev = head; // 中间节点的前一个节点// 链表个数为偶数,fast会在NULL,链表个数为奇数,fast会在最后一个元素while (fast != NULL && fast->next != NULL) {prev = slow; // 记录中间节点的前一个节点fast = fast->next->next;slow = slow->next;}prev->next = NULL; // 断开后半部分ListNode* scHead = reverseList(slow); // 翻转之后的头结点// 进行比较,如果是奇数那么两边的链表长度不一致,所以循环按照前半部分链表while (head) {if (head->val == scHead->val) {head = head->next;scHead = scHead->next;}else{return false;break;}}return true;}2.相交链表
给定两个单链表的头节点 headA 和 headB ,请找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
图示两个链表在节点 c1 开始相交:
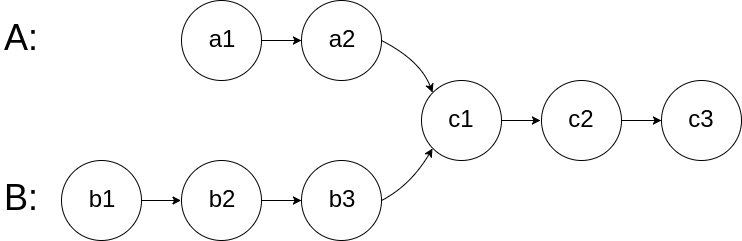
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
示例 1:
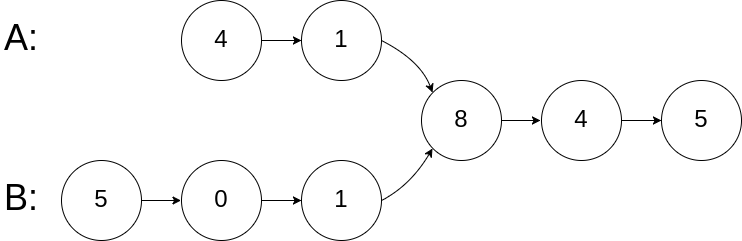
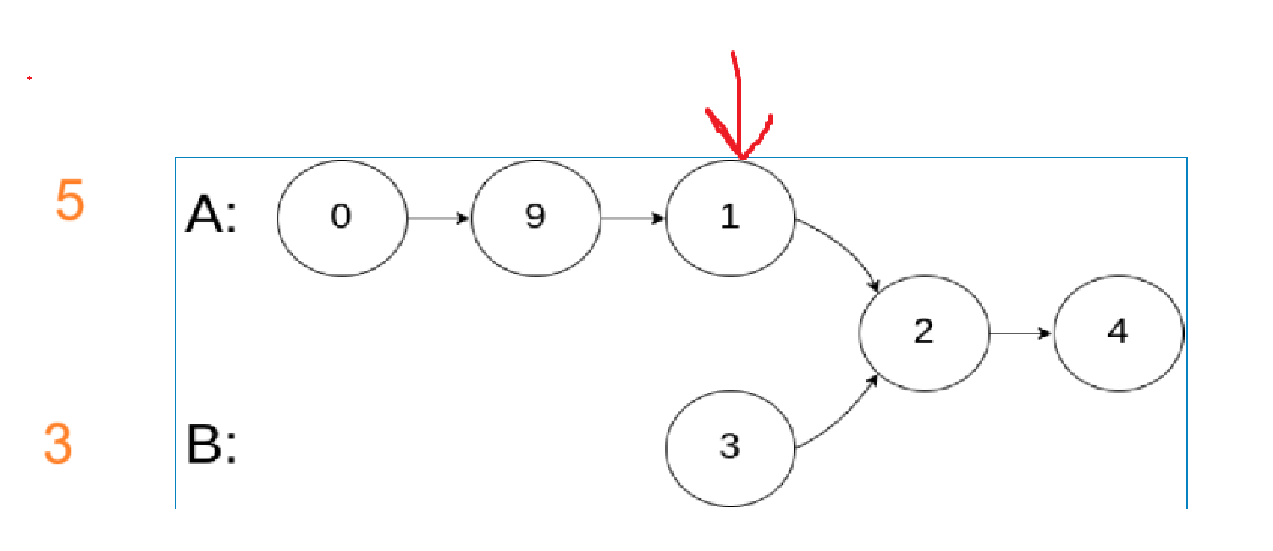
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3 输出:Intersected at '8' 解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。 从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。 在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
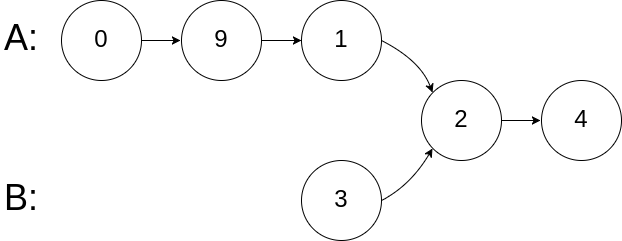
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1 输出:Intersected at '2' 解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。 从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。 在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
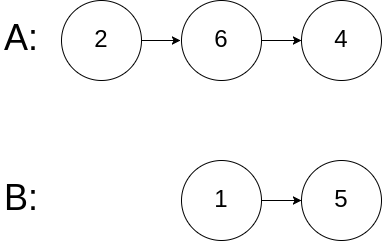
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2 输出:null 解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。 由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。 这两个链表不相交,因此返回 null 。
提示:
listA中节点数目为mlistB中节点数目为n0 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= n- 如果
listA和listB没有交点,intersectVal为0 - 如果
listA和listB有交点,intersectVal == listA[skipA + 1] == listB[skipB + 1]
进阶:能否设计一个时间复杂度 O(n) 、仅用 O(1) 内存的解决方案?
分析:
首先需要计算出每一个链表的长度,再计算长度的差值,需要让长一点的指针走差值那么多步,使得两个指针处于同一起跑线上,此时同时再进行遍历,直到两个指针相同(不是值相同),需要在循环中判断如果任意一方(因为同步走)的指针是NULL,说明没有交点,返回空,否则就继续循环,退出循环的条件是两个指针不同,如果没有提前return,说明循环正常结束,那么就直接返回任意一个指针即可。
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode;
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {ListNode* p1 = headA;ListNode* p2 = headB;// 先计算出各自链表的长度,链表长的可以先走几步,保证指针在同一个位置int la = 0;int lb = 0;int between = 0;while(p1){p1 = p1->next;la++;}while(p2){p2 = p2->next;lb++;}// 保持同步if(la > lb){between = la - lb;while(between--){headA = headA->next;}}else{between = lb - la;while(between--){headB = headB->next;}}// 同时走while(headA != headB){headA = headA->next;headB = headB->next;if(headA ==NULL){return NULL;}}return headA;
}3.环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:
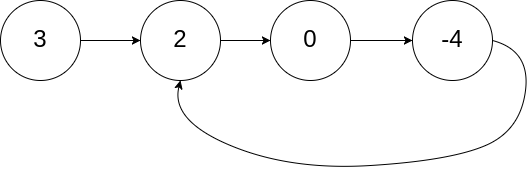
输入:head = [3,2,0,-4], pos = 1 输出:true 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
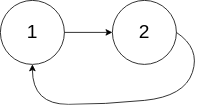
输入:head = [1,2], pos = 0 输出:true 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1 输出:false 解释:链表中没有环。
提示:
- 链表中节点的数目范围是
[0, 104] -105 <= Node.val <= 105pos为-1或者链表中的一个 有效索引 。
进阶:你能用 O(1)(即,常量)内存解决此问题吗?
分析:
带环链表最恶心的地方是在于不能遍历,这里可以用快慢指针来实现。
快指针先进环,慢指针后进环,如果有环,那么快指针一定能追上慢指针,一旦追上就判定有环。
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode;
bool hasCycle(struct ListNode *head) {ListNode* fast = head;ListNode* slow = head;while(fast != NULL && fast->next != NULL){fast = fast->next->next;slow = slow->next;if(fast == slow){return true;}}return false;
}面试提问:
请正面快指针如何追上慢指针?为什么快指针的步长是2步,3步行不行,n步行不行?
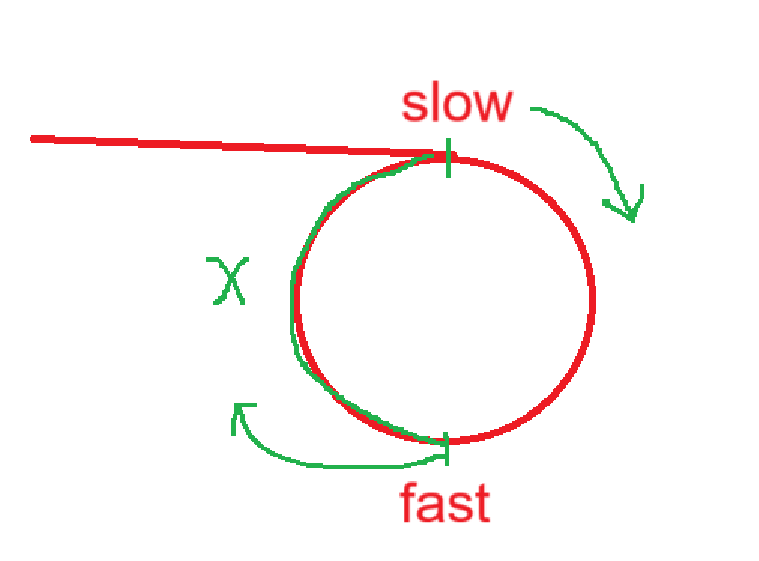
假设两个指针进环以后他们之间的距离是x,那么slow每走一步,fast就走两步,那么它们之间的距离就会是x、x-1、x-2.......0
那么如果fast指针一次走3步,那么他们之间的距离是x-2、x-4、x-6,此时x如果是奇数那么快慢指针就会永不相遇。
4.环形链表II
给定一个链表,返回链表开始入环的第一个节点。 从链表的头节点开始沿着 next 指针进入环的第一个节点为环的入口节点。如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意,pos 仅仅是用于标识环的情况,并不会作为参数传递到函数中。
说明:不允许修改给定的链表。
示例 1:
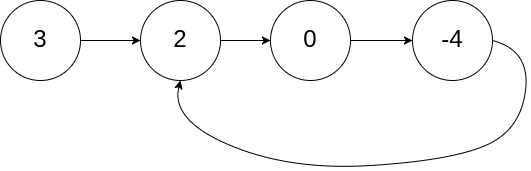
输入:head = [3,2,0,-4], pos = 1 输出:返回索引为 1 的链表节点 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
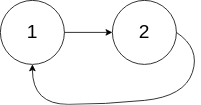
输入:head = [1,2], pos = 0 输出:返回索引为 0 的链表节点 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1 输出:返回 null 解释:链表中没有环。
提示:
- 链表中节点的数目范围在范围
[0, 104]内 -105 <= Node.val <= 105pos的值为-1或者链表中的一个有效索引
进阶:是否可以使用 O(1) 空间解决此题?
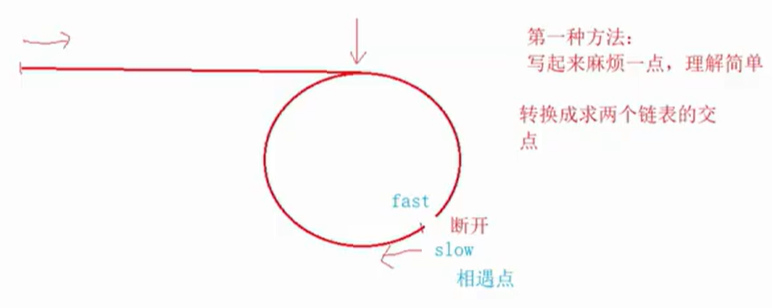
分析1:
快指针走两步,慢指针走一步,总会在环中相遇,在相遇的节点中断开,作为头结点;
此时非环的链表和断开的链表分别作为头结点,查找单链表的交点,那么这个交点就是入环的第一个节点。
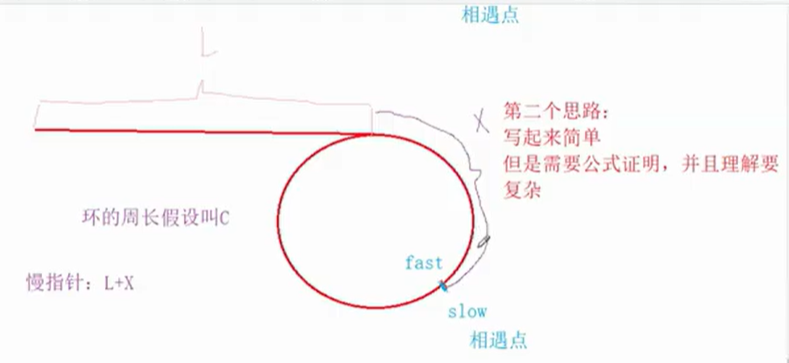
分析2:
快慢指针进圈之后:假如圈前的长度是L,圈的周长是C,圈开始的地方距离快慢指针相遇点的距离是X。
慢指针走的距离:L+X
快指针走的距离:L + C + X
由于快指针走的距离是慢指针的两倍就有:
稍微化简一下:
即:
那么我们可以这样做:一个指针从起点出发,一个指针从快慢指针的相遇处出发,两个指针会走相同的步数L 或者C -X,循环结束后两个指针会相遇,最后返回任意一个节点即可。
有没有例外的情况,这种情况是快指针刚好只走了1圈,那么当圈为2的时候,慢指针走一步,快指针走一圈,这样的情况,上面的推论就不成立,我们可以再进行推算。

当慢指针入圈之前,快指针可能走了N圈。
慢指针走的距离:L+X
快指针走的距离:L + N*C + X
由于快指针走的距离是慢指针的两倍就有:
稍微化简一下:
即:
也就是说上面的情况,只是一种特殊的情况,即N=1。
那么我们可以从快慢相遇点开始、从链表的头开始,当链表头指针走了L的时候,相遇点指针可能走了N圈,具体走了几圈,我们不关心,我们只需要知道这两个指针走的路程是一样的,当这两个指针。
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
typedef struct ListNode ListNode;
struct ListNode* detectCycle(struct ListNode* head) {ListNode* fast = head;ListNode* slow = head;// 1.由于是环,所以快指针慢指针必定重合while(fast != NULL && fast->next != NULL){fast = fast->next->next;slow = slow->next;if(fast == slow)// 后判断,不然循环开始就跳出了{break;}}// 循环退出有两种可能// 如果是指针相等退出,这是我们想要的,如果不是,那么说明fast本身为空,或者fast->next为空if(fast == NULL || fast->next == NULL){ // 根本不是环return NULL;}// 2.head和交接点同时出发while(head != fast){head = head->next;fast = fast->next;}//3.此时fast走了若干圈,head走了L的距离相遇,这个节点就是入圈点return head;
}5.随机链表的复制
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
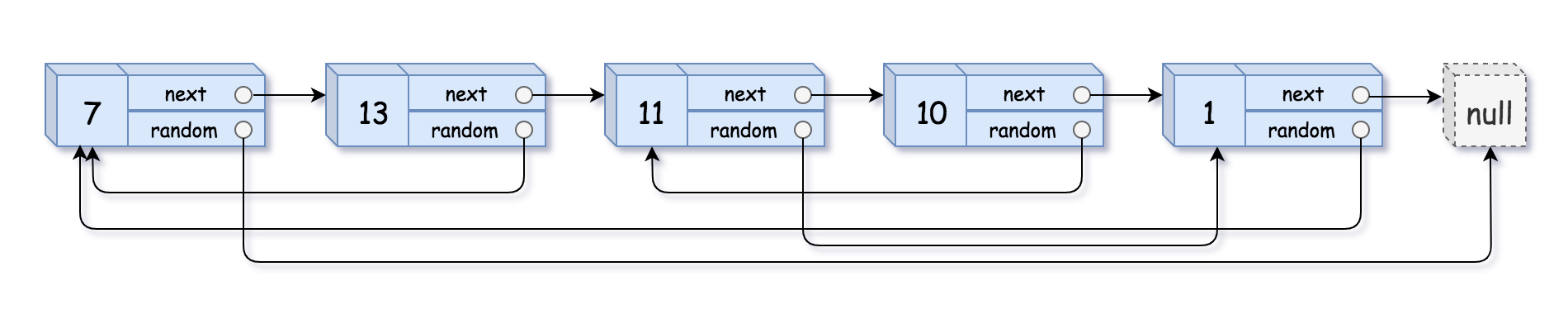
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000-104 <= Node.val <= 104Node.random为null或指向链表中的节点。
分析:
每一个结点除了next指针之外还有一个随机指针,这个随机指针有可能指向任意节点(自己、空、其他),这道题的难点是复制随机指针,由于新链表的空间是全新空间,我们从老链表得到了第一个节点的随机指针,但是怎么和新链表的节点进行对应呢?
1.拷贝节点,链接到原节点的后面
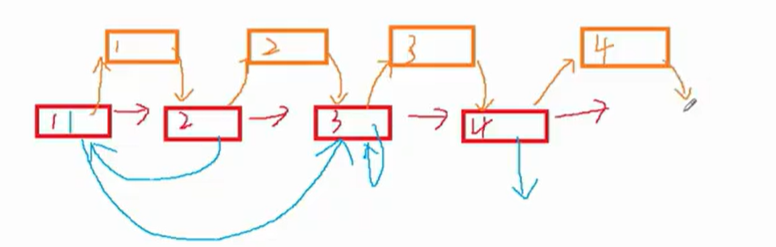
2.处理拷贝节点的随机指针
通过上图我们可以发现,源节点的随机指针指向的元素的next就是新复制的随机指针!
3. 将原链表的next指针进行恢复
首先将原链表的next指向复制链表的next,然后再进行判断:如果拷贝链表next有值,那么就将next赋值为next->next,如果next为空,直接next赋值为空;拷贝链表和原链表指针后移。
4.返回拷贝链表即可。
代码:
/*** Definition for a Node.* struct Node {* int val;* struct Node *next;* struct Node *random;* };*/
typedef struct Node Node;Node* createNode(Node* sourceNode) {Node* newNode = (Node*)malloc(sizeof(Node));newNode->next = NULL;newNode->random = NULL;newNode->val = sourceNode->val;return newNode;
}
struct Node* copyRandomList(struct Node* head) {// 如果没有节点直接返回空if(!head){return NULL;}Node* curr = head;// 1.复制节点并且串联在原链表中while (curr) {Node* newNode = createNode(curr);Node* tmp = curr->next;curr->next = newNode;newNode->next = tmp;curr = tmp;}// 2.给随机链表赋值,curr的随机链表的next就是复制节点的随机链表curr = head;while (curr !=NULL && curr->next != NULL ) {if(curr->random != NULL){curr->next->random = curr->random->next;}else{curr->next->random = NULL;}curr = curr->next->next;}// 3.断开连接Node* copyHead = head->next;Node* copyCurr = copyHead;curr = head;while (curr) {curr->next = copyCurr->next;if(copyCurr->next !=NULL){copyCurr->next = copyCurr->next->next;}else{copyCurr->next = NULL;}// 移动指针curr = curr->next;copyCurr = copyCurr->next;}return copyHead;
}6.对链表进行插入排序
给定单个链表的头 head ,使用 插入排序 对链表进行排序,并返回 排序后链表的头 。
插入排序 算法的步骤:
- 插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。
- 每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。
- 重复直到所有输入数据插入完为止。
下面是插入排序算法的一个图形示例。部分排序的列表(黑色)最初只包含列表中的第一个元素。每次迭代时,从输入数据中删除一个元素(红色),并就地插入已排序的列表中。
对链表进行插入排序。
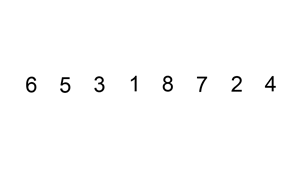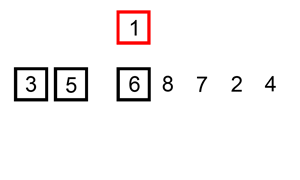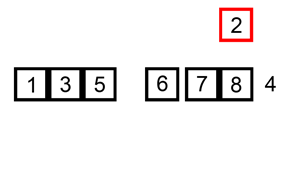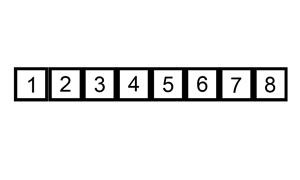
示例 1:
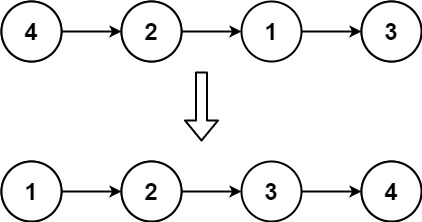
输入: head = [4,2,1,3] 输出: [1,2,3,4]
示例 2:
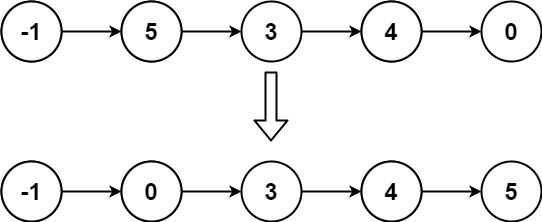
输入: head = [-1,5,3,4,0] 输出: [-1,0,3,4,5]
提示:
- 列表中的节点数在
[1, 5000]范围内 -5000 <= Node.val <= 5000
分析:
插入排序的原理就是,先把第一个数当做是有序的,后面的数字跟第一个数字进行比较,如果比第一个数字大那么就放在第一个数字后面,如果比第一个数字小那么就放在第一个数字前面,此时链表中有两个数,这两个数是有序的,那么第三个数只需要从头开始遍历即可,插入到合适的位置。
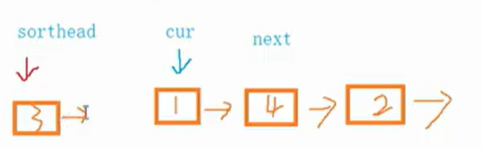
以下是代码的梳理:
①判断链表中若有1个或0个节点,那么不用排序,直接返回本身;
②将链表划分为两个链表,一个是待排序的链表,一个是已经有序的链表,需要从待排序的链表中取节点放到未排序的链表中;
③将未排序的链表的头结点初始化为已排序的链表的头结点,那么未排序的链表的头结点更新为之前头结点的下一个节点,然后把已排序的链表的头结点的next置为NULL;
④遍历未排序的链表,当当前节点的值比已经排序的链表的头结点的值还要小,说明当前值需要作为已经排序链表的头结点(头插);
⑤另一种情况(中间插入):遍历已排序的链表,如果有节点比当前节点的值还要大(或者相等),说明此时应该插入已排序的当前节点之前,所以需要定义一个prev来保存已排序链表的节点的前一个节点,prev从已排序节点的头结点开始即可,因为头插的情况已经处理了,最近的一个节点是头结点的下一个节点。
⑥如果没有找到比未排序的当前节点大的节点,已排序的两个指针prev和curr就一直往后走,当curr为空退出循环,若找到了就在curr之前进行插入,使用break主动退出循环。
⑦此时退出循环的可能有两种,要么自己主动插入后退出循环,要么没有找到比未排序的当前节点更大的节点,导致sortedCurr为空,我们只需要对后者进行处理,后者说明需要将curr插入到已排序节点的最后面,即尾插。
⑧插入完毕之后需要在while大循环的最后将curr指针向后移动,这里就需要在循环开始之前将curr的next节点进行保存,以便移动。
⑨直接返回已排序链表的头结点即可。
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode;
struct ListNode* insertionSortList(struct ListNode* head) {// 如果只有一个节点或空链表,直接返回本身if(head == NULL || head->next == NULL){return head;}// 分成两个区域,排序区和未排序区// 取出未排序区的第一个节点作为排序区的第一个节点ListNode* sortedHead = head; head = head->next;sortedHead->next = NULL;ListNode* curr = head; // 未排序区的头指针// 遍历未排序区的每一个节点进行插入while(curr){// 保存curr的下一个节点方便迭代ListNode* next = curr->next;// 当前元素比排序区域头结点还要小,头插if(curr->val < sortedHead->val){curr->next = sortedHead;sortedHead = curr;}else{// 中间插入,遍历已排序的链表// 找到一个节点比当前节点要大,当前节点就插在这个节点的前面/*因为头插的情况已经判断过了,所以最早的插入是头节点的后面,所以prev直接是头而curr是头的下一个节点*/ListNode* sortedPrev = sortedHead;ListNode* sortedCurr = sortedHead->next;while(sortedCurr){// 插在prev和sortedcurr之间if(sortedCurr->val >= curr->val){sortedPrev->next = curr;curr->next = sortedCurr;break;}else{// 如果没有找到,那就指针后移sortedPrev = sortedCurr;sortedCurr = sortedCurr->next;}}// 出循环有两种可能,要么是没插入,要么是插入了提前退出循环// 当sortedCurr为空的时候,说明此时没有插入,只能尾插if(sortedCurr == NULL){sortedPrev->next = curr;curr->next = NULL;}}// 当前curr插入完毕之后,迭代curr = next;}return sortedHead;
}7.删除排序链表中的重复元素 II
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
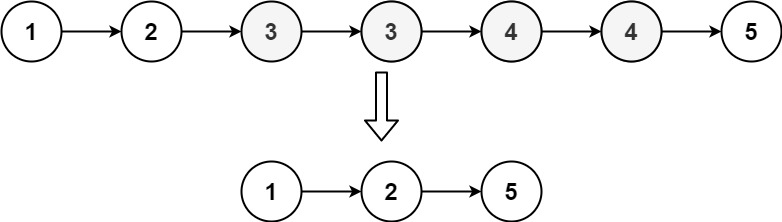
输入:head = [1,2,3,3,4,4,5] 输出:[1,2,5]
示例 2:
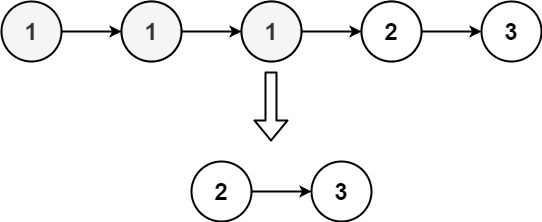
输入:head = [1,1,1,2,3] 输出:[2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
分析:
①一般情况:定义三个指针,判断curr和next是否相同,如果相同那么就移动next,如果不同那就free掉curr到next之间的所有结点,然后将prev指向next,最后再三个指针一起动;

②特殊情况:当链表的头全部相等,那么按照上面的逻辑就是当next和curr不相同的时候,prev的next指向next,如此以来就会空指针的解引用。

所以我们不能直接将prev指向next,如果不为空才能指向,若为空那么需要重新更换头结点。
// 防止开始的几个元素是相同的,此时prev是空,就会报错if(prev != NULL){// prev需要指向nextprev->next;}else{// 如果prev是空,又要删掉前面相同的内容,直接换头head = next;}③特殊情况:当链表的尾全部相等,此时如果单纯的比较cur和next,全部相同,那么next就会一直走到NULL,最后依然会对NULL进行解引用。

这里需要增加一个条件:

是因为,当末尾元素相同的时候,next和curr都是NULL,此时再进行while判断就会对空指针解引用。

当next指针后移的时候,也需要进行判断,若指针为NULL,那么就会对空指针解引用,加上条件,在最外层的循环会直接退出。
代码:
typedef struct ListNode ListNode;
struct ListNode* deleteDuplicates(struct ListNode* head) {if(head == NULL || head->next == NULL){return head; // 0或1个节点不需要删除,直接返回}ListNode* prev = NULL;ListNode* curr = head;ListNode* next = head->next;while(next){// 如果不相等,三个指针同时后移if(curr->val != next->val){prev = curr;curr = next;next = next->next;}else{// 如果curr和next相等,next要移动到不相等为止,若尾元素相同,那么next会走到NULL,判断的时候会出现空指针解引用// 这里加一个条件next不能为空while(next != NULL && curr->val == next->val){next = next->next;}// 循环结束后,curr和next的值不相等或者next走到null了// 防止开始的几个元素是相同的,此时prev是空,就会报错if(prev != NULL){// prev需要指向nextprev->next = next;}else{// 如果prev是空,又要删掉前面相同的内容,直接换头head = next;}// curr需要移动到next,并且在移动的过程中释放内存while(curr != next){ListNode* trash = curr;curr = curr->next;free(trash);}if(next != NULL){next = next->next; }}}return head;
}

ZipList的节点介绍)
















