一原文
在第一阶段,用重定位的人体运动数据在模拟中预训练运动跟踪策略。
在第二阶段,在现实世界中部署策略并收集现实世界数据来训练一个增量(残差)动作模型来补偿动态不匹配。
,ASAP 使用集成到模拟器中的增量动作模型对预训练策略进行微调,以有效地与现实世界的动态保持一致。
与 SysID、DR 和增量动态学习基线相比,减少跟踪误差。ASAP 实现以前难以实现的高度敏捷运动,展示增量动作学习在连接模拟和现实世界动态方面的潜力。
实现人形机器人的敏捷全身技能仍然是一项根本挑战,这不仅是因为硬件限制,还因为模拟动力学与现实世界物理之间的不匹配。
出现了三种主要方法来弥合动力学不匹配:系统识别 (SysID) 方法、域随机化 (DR) 和学习动力学方法。
SysID 方法直接估计关键物理参数,例如电机响应特性、每个机器人连杆的质量和地形特性。
DR 方法依赖于随机化模拟参数 [87, 68];但这可能导致过于保守的策略 [26]
弥合动态不匹配的另一种方法是使用现实世界数据学习现实世界物理的动态模型。虽然这种方法已经在无人机[81]和地面车辆[97]等低维系统中取得了成功,但其对人形机器人的有效性仍未得到探索。
二 步骤
(a) 从视频中捕捉人体动作。(b) 使用 TRAM [93],以 SMPL 参数格式重建 3D 人体运动。(c) 在模拟中训练强化学习 (RL) 策略以跟踪 SMPL 运动。(d) 在模拟中,将学习的 SMPL 运动重定位到 Unitree G1 人形机器人。(e) 训练有素的 RL 策略部署在真实机器人上,在物理世界中执行最终运动。
(a):从2D视频帧中恢复3D人体姿态和动作序列,计算机视觉的方法,有很多现有的模型。需要动作优化和后处理,例如限位、例如瞬时高速移动的滤波,去噪等等。
(b):时序感知的3D姿态估计方法。TRAM 是一个 “视频动作翻译器”,它把普通视频里的人物动作,转换成计算机能懂的 SMPL数字人参数,生成3D动画。(1标记出每帧的关节位置,2 根据前后帧的关系,推测关节在3D空间中的位置,匹配数字人(SMPL):调整SMPL模型的 “姿势旋钮”(72个参数控制关节旋转)和 “体型旋钮”(10个参数控制高矮胖瘦),让3D数字人的动作和视频里真人一致。)
TRAM [93] 的核心创新在于 联合优化时序连续性与SMPL参数空间,使用HRNet或ViTPose检测视频每一帧的2D人体关键点(17或25点),
最终得到一串 SMPL参数,导入到3D软件(如Blender)就能看到和视频一样的数字人动画。
TRAM 的聪明之处是,像“脑补”连续动作,避免突然卡顿,自动过滤不可能的动作(比如膝盖不会往后弯)。
基于模型的数据清理:让一个 数字人(SMPL模型) 在虚拟世界里做这些动作。
MaskedMimic ,:一个 基于物理的动作修正器,用于修复3D人体动作中的物理错误(如穿模、反关节、速度突变等)。主要配合SMPL动作数据(如TRAM的输出)和物理模拟器(如IsaacGym)使用。
c) 将 SMPL 运动重定位为机器人运动:阶段1:优化体型(β′调整),让SMPL模型的“骨架”尽量接近机器人。
阶段2:优化动作(θ和p调整),在匹配的体型下,让动作轨迹也适合机器人。固定优化后的β′,只调动作参数(姿势θ + 根节点平移p)。
机器人残差学习:这些模型可以改进初始控制器的动作,其他方法利用残差组件来纠正动力学模型中的不准确性。
三 理解
1 如何进行模仿学习。(通过强化学习奖励的形式学习
不只是各个关节的位置。还包括:
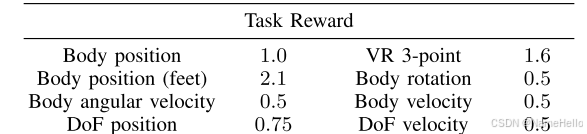
主要任务是跟踪脚的位置,
实时跟踪用户 头显(1点) + 双手控制器(2点) 的空间位置,共3个关键点(故称"3-point")
除此之外,当然加入一些正则化和惩罚措施。
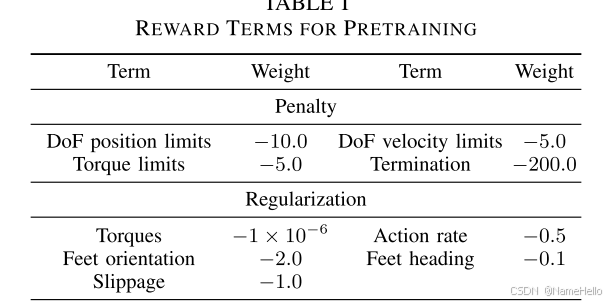
残差模型。
直接将预训练的策略,部署到真实机器人上,
记录真实的状态-动作对。 其中,状态,
![]()
包括基座位置,基座的线速度,基座的线加速度、基座的角速度、关节位置、关节速度。
其中,基座的位置、线速度是无法直接获得的。
残差模型:下一状态= F_sim(当前状态,真实action, + 残差action)
理解:假设在仿真中按相位直接给真实的action轨迹,那么表现的动作和真实不像,和原策略的动作也不像。如果要是和真机表现一致的话,也就说明没有sim和real差了。
加入残差action让状态表现的和原策略一样,这毫无意义,因为这个优化目标是(残差为原策略仿真action 和真机action的差)
但是,如果残差action能让仿真中的表现和现实一样的话?,那么就量化了仿真与现实的差异,也就是残差模型代表了现实和仿真的差异。所以优化目标是:在训练残差模型时,让机器人的环境反馈状态和现实采集的状态一致。
所以ASAP是确切的real2sim,将现实的策略部署到仿真环境中。如果只训练一个策略让仿真和现实状态一致,就变成了克隆学习,而采集现实的action是获取残差action的关键,假设采集的数据足够多,那么其实是具有足够泛性应用到其他动作的。
可以直接在原策略- 残差策略,输出到真机(注意,是减不是加)。
论文:固定残差模型,在原策略action下加入残差策略action,如果直接play,那在仿真中的表现要比原策略差,但应该是偏向于真实表现一侧的。
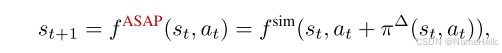
再训练一下原策略,假设训练的足够充分,那么新的策略 = 原策略 - 残差策略,因为优化目标和最初是一致的。
新的策略+残差策略在仿真中表现良好,然后不要残差策略,直接将新策略部署到真机。
微调的原因是:残差策略是从真机轨迹上得到的,但真机轨迹又不太好,存在过拟合的问题。
举例子:仿真策略训练到10度,部署真机到9度,采集真机状态和动作,动作放到仿真中去,可能是9度左右,可能是10度左右度, 假设是10.5, 原策略上加一个残差策略,按仿真状态和真机状态一致对残差策略进行训练,那么这个策略最终的action效果是-1.5度,这代表了仿真和现实差异。
方法1 :直接部署,原策略-残差策略 到真机,真机角度比原来更接近10度。
方法2:ASAP,原策略+残差策略(冻结),训练原策略,奖励与最初一致。若完全充分训练,新策略 = 原策略-残差策略,此时部署新策略到真机。也可控制训练程度,只对原策略进行微调。










 文件对话框 QFileDialog 篇二:源码带注释)

)






