第一部分:Redis核心概念与架构设计
1.1 Redis本质解析
Redis(Remote Dictionary Server)作为开源的内存数据结构存储系统,其核心价值在于:
内存优先架构:数据主要存储在内存中,读写性能达到10万+ QPS
丰富的数据结构:支持字符串、哈希、列表、集合、有序集合等
持久化能力:通过RDB和AOF实现内存数据的持久化存储
原子操作:单线程模型保证命令执行的原子性
与MySQL等关系型数据库对比:
| 特性 | Redis | MySQL |
|---|---|---|
| 存储介质 | 内存+磁盘 | 磁盘 |
| 数据结构 | 多样化 | 表结构 |
| 查询复杂度 | O(1)为主 | 依赖索引 |
| 吞吐量 | 10万+ QPS | 数千QPS |
| 事务特性 | 弱原子性 | ACID |
| 适用场景 | 缓存、计数器等 | 持久化数据存储 |
1.2 线程模型演进
Redis 6.0前单线程架构:
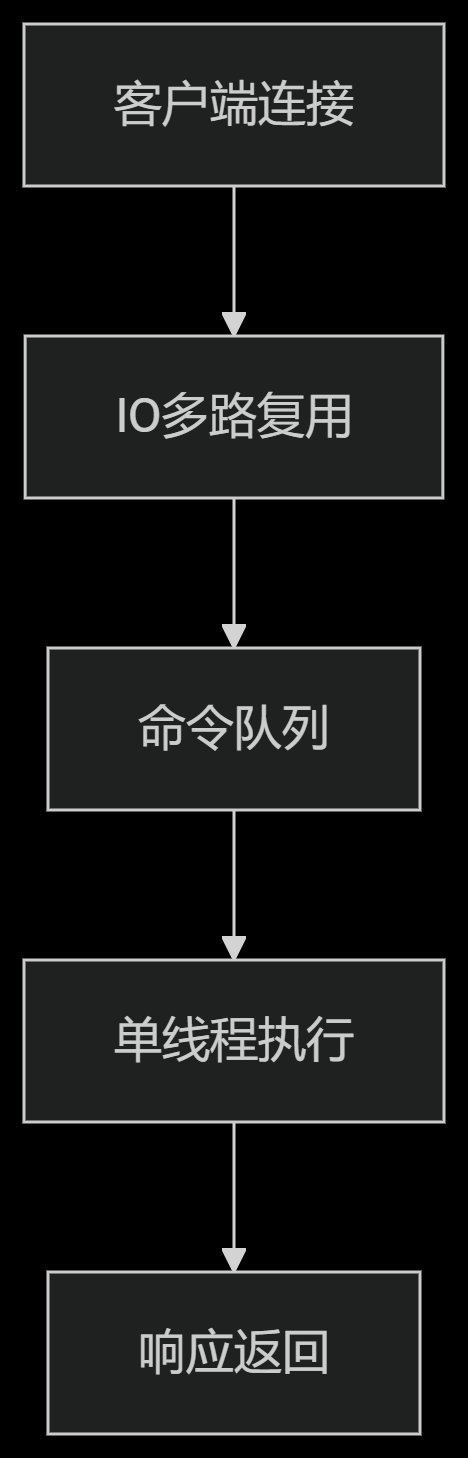
Redis 6.0+多线程改进:
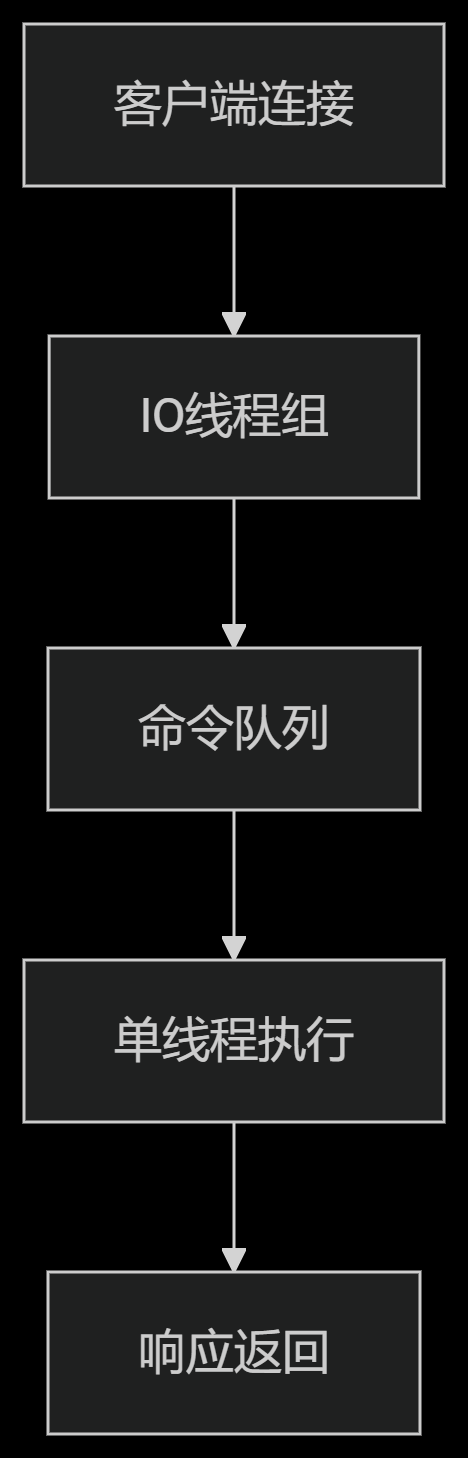
关键优化点:
IO线程:处理网络读写(默认4个线程)
Worker线程:仍保持单线程执行命令
性能提升:在高并发场景下提升30%以上吞吐量
1.3 持久化机制详解
RDB持久化配置示例:
textsave 900 1 # 15分钟至少1个key变化
save 300 10 # 5分钟至少10个key变化
save 60 10000 # 1分钟至少10000个key变化RDB vs AOF对比:
| 维度 | RDB | AOF |
|---|---|---|
| 持久化方式 | 快照 | 日志追加 |
| 文件大小 | 小(压缩二进制) | 大(文本命令) |
| 恢复速度 | 快 | 慢(需重放命令) |
| 数据安全 | 可能丢失最后一次保存 | 可配置为实时同步 |
| 性能影响 | 保存时性能下降 | 持续写入性能开销 |
AOF重写机制:
bash# 自动触发条件
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb# 手动执行命令
BGREWRITEAOF第二部分:Redis实战应用模式
2.1 缓存设计实践
新闻类型缓存示例优化:
javapublic List<NewsType> getNewsTypesWithLock() {// 双重检查锁实现String cacheKey = "newsTypes";ValueOperations ops = redisTemplate.opsForValue();List<NewsType> result = (List<NewsType>) ops.get(cacheKey);if (result != null) {return result;}synchronized (this) {result = (List<NewsType>) ops.get(cacheKey);if (result == null) {result = indexDao.newsTypes();ops.set(cacheKey, result != null ? result : Collections.emptyList(), 1, TimeUnit.HOURS);}}return result;
}缓存策略对比:
| 策略 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| Cache-Aside | 应用层主动管理 | 灵活可控 | 需要处理一致性问题 |
| Read-Through | 缓存代理自动加载 | 对应用透明 | 实现复杂度高 |
| Write-Behind | 异步更新数据源 | 写入性能高 | 数据丢失风险 |
| Write-Through | 同步更新缓存和数据源 | 强一致性 | 写入延迟高 |
2.2 典型应用场景实现
1. 分布式计数器
java// 点赞功能实现
public void likePost(Long postId) {String key = "post:" + postId + ":likes";redisTemplate.opsForValue().increment(key);// 异步持久化到数据库asyncExecutor.execute(() -> {postRepository.incrementLikes(postId);});
}2. 实时排行榜
java// 玩家分数更新
public void updatePlayerScore(String playerId, double score) {redisTemplate.opsForZSet().add("game_leaderboard", playerId, score);
}// 获取TOP10
public List<Player> getTopPlayers() {Set<ZSetOperations.TypedTuple<String>> range = redisTemplate.opsForZSet().reverseRangeWithScores("game_leaderboard", 0, 9);// 转换并返回结果
}3. 分布式锁进阶实现
javapublic boolean tryLock(String lockKey, String requestId, long expireTime) {return redisTemplate.execute((RedisCallback<Boolean>) connection -> {RedisStringCommands.SetOption setOption = RedisStringCommands.SetOption.ifAbsent();Expiration expiration = Expiration.seconds(expireTime);byte[] key = redisTemplate.getKeySerializer().serialize(lockKey);byte[] value = redisTemplate.getValueSerializer().serialize(requestId);return connection.set(key, value, expiration, setOption);});
}第三部分:高并发问题解决方案
3.1 缓存穿透防护体系
布隆过滤器实现方案:
java// 初始化布隆过滤器
@Bean
public BloomFilter<String> initBloomFilter() {BloomFilter<String> filter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), 1000000, 0.01);// 加载已有数据List<String> allKeys = productRepository.findAllKeys();allKeys.forEach(filter::put);return filter;
}// 查询流程
public Product getProductWithBloom(Long id) {String key = "product:" + id;if (!bloomFilter.mightContain(key)) {return null; // 快速返回}// 正常缓存查询流程
}多级缓存方案:
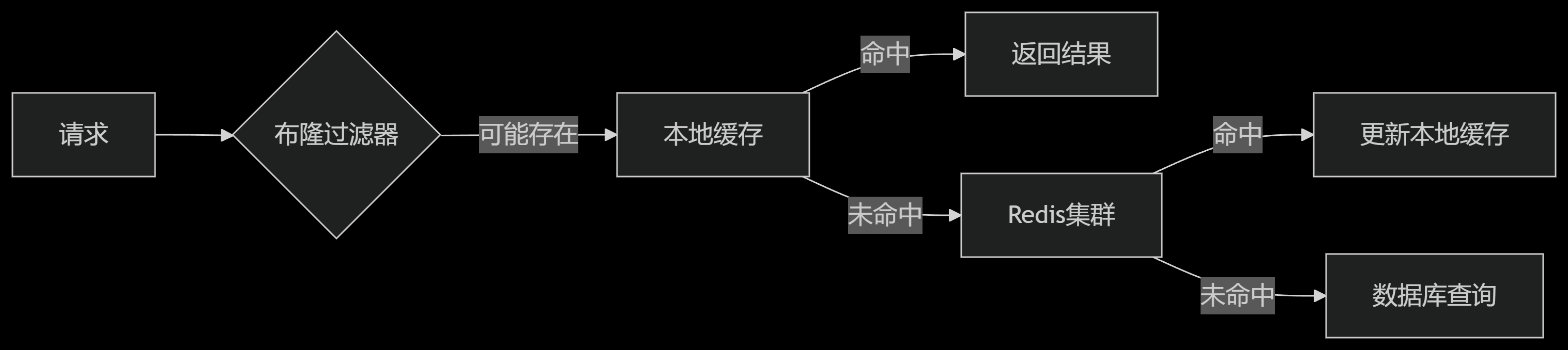
3.2 缓存击穿应对策略
热点Key发现机制:
监控系统检测QPS异常Key
客户端上报访问模式
基于LFU算法自动识别
动态续期实现:
javapublic <T> T getWithRefresh(String key, Class<T> type, Supplier<T> loader, long expire) {// 获取值时异步续期T value = redisTemplate.opsForValue().get(key);if (value != null) {redisTemplate.expire(key, expire, TimeUnit.SECONDS);} else {value = loader.get();redisTemplate.opsForValue().set(key, value, expire, TimeUnit.SECONDS);}return value;
}3.3 缓存雪崩预防方案
分级过期策略:
java// 对同类Key设置随机过期时间
public void setWithRandomExpire(String key, Object value, long baseExpire, TimeUnit unit) {long expire = baseExpire + ThreadLocalRandom.current().nextLong(300);redisTemplate.opsForValue().set(key, value, expire, unit);
}熔断降级机制:
java@CircuitBreaker(failureRate = 0.2, resetTimeout = 5000)
public Product getProductFallback(Long id) {// 降级策略:返回缓存或默认值return cachedProductService.getOrDefault(id);
}第四部分:Redis高级特性与最佳实践
4.1 内存优化技巧
数据结构选择指南:
| 场景 | 推荐结构 | 内存优化技巧 |
|---|---|---|
| 计数器 | String | 共享Key前缀 |
| 对象存储 | Hash | 使用ziplist编码 |
| 关系查询 | Set/ZSet | 合理设置max-ziplist-entries |
| 时间序列数据 | ZSet | 时间戳作为score |
| 消息队列 | Stream | 限制消费者组数量 |
配置优化参数:
texthash-max-ziplist-entries 512
hash-max-ziplist-value 64
zset-max-ziplist-entries 128
zset-max-ziplist-value 644.2 集群部署方案
Redis Cluster拓扑:
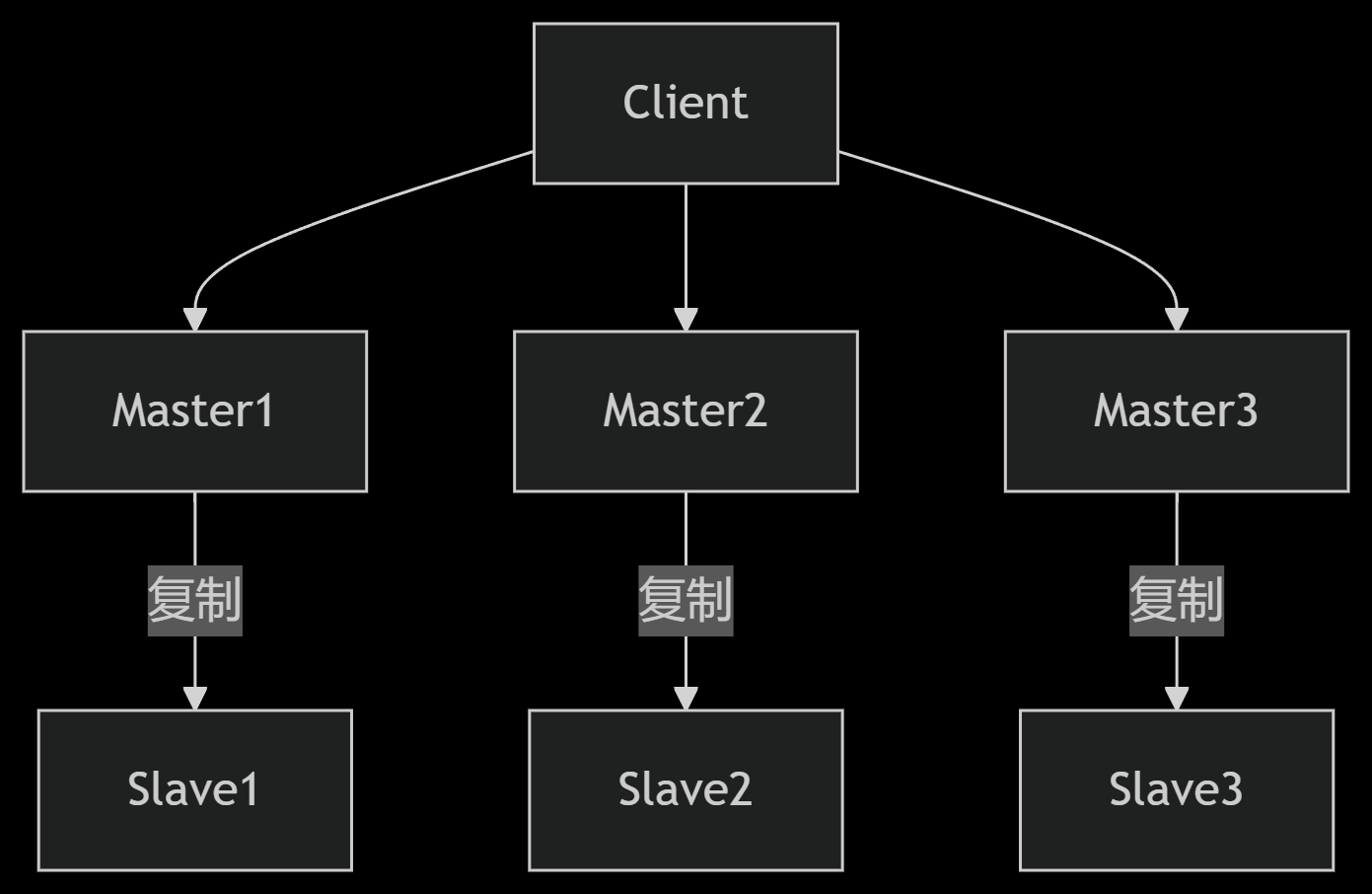
关键配置项:
textcluster-enabled yes
cluster-node-timeout 15000
cluster-migration-barrier 1
cluster-require-full-coverage no4.3 监控与调优
重要监控指标:
内存相关:
used_memory:已用内存
mem_fragmentation_ratio:内存碎片率
evicted_keys:淘汰Key数
性能相关:
instantaneous_ops_per_sec:实时QPS
latency:命令延迟
rejected_connections:拒绝连接数
集群相关:
cluster_state:集群状态
cluster_slots_assigned:已分配槽位
性能调优工具:
redis-benchmark:压力测试
bash
redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000
redis-cli --latency:延迟检测
slowlog:慢查询分析
textslowlog-log-slower-than 10000 slowlog-max-len 128
第五部分:Redis未来演进
5.1 Redis 7.0新特性
Function API:
lua# 注册函数 redis.register_function('myfunc', function(keys, args)return redis.call('GET', keys[1]) end)多AOF文件支持:
textaof-use-rdb-preamble yes aof-timestamp-enabled yesACL改进:
bashACL SETUSER alice on >pass123 ~cached:* +get +set
5.2 云原生趋势
K8s Operator模式:
yamlapiVersion: redis.redis.op/v1
kind: RedisCluster
metadata:name: redis-cluster
spec:clusterSize: 6resources:requests:memory: 4Gicpu: 2persistence:enabled: truestorageClassName: standardsize: 20GiServerless Redis:
按需自动扩缩容
毫秒级计费粒度
完全托管服务
结语:
Redis的成功不仅在于其卓越的性能表现,更体现了"简单即是美"的设计哲学。通过精心设计的数据结构、明智的单线程选择和对内存计算的专注,Redis在分布式系统领域树立了典范。
在实际应用中,开发者需要深入理解业务场景,在缓存一致性、性能与成本之间找到平衡点。记住:没有放之四海而皆准的架构方案,只有最适合当前业务发展阶段的技术选择。
正如Redis创始人Salvatore Sanfilippo所说:"Redis不是数据库的替代品,而是为特定问题提供特定解决方案的工具。"掌握Redis的核心原理和最佳实践,将帮助我们在高并发系统的构建中游刃有余。
 视频教程 - 微博类别信息爬取)
)


)








获取)

)


`:专业指南与实战示例)
