目录
集成学习介绍
1. 核心思想
2. 为什么有效?
3. 主要流派与方法
A. 并行方法:Bagging (Bootstrap Aggregating)
B. 串行方法:Boosting
C. 堆叠法:Stacking
代码示例
Bagging 的代表 —— 随机森林 (Random Forest)
集成学习介绍
1. 核心思想
集成学习是一种机器学习范式,其核心思想非常直观:“三个臭皮匠,顶个诸葛亮”。它通过构建并结合多个基学习器(Base Learners) 来完成学习任务,而不是只使用一个单一的模型。
通过将多个性能可能仅优于随机猜测的弱学习器(Weak Learners) 组合起来,集成方法往往能够形成一个强学习器(Strong Learner),获得比任何单一模型都更加显著优越的泛化性能。
2. 为什么有效?
集成学习有效的根本原因在于它降低了模型的方差(Variance)、偏差(Bias),或同时降低两者,从而避免了过拟合或欠拟合。
- 统计角度: 假设一个分类任务,25个基分类器每个的错误率为 ε = 0.35。如果使用简单投票法集成,并且假设分类器之间相互独立,那么集成分类器出错的概率(即超过一半的分类器都出错)会远低于 0.35。这大大提高了准确性。
- 计算角度: 很多学习算法(如决策树)对数据微小变动非常敏感,容易陷入局部最优。通过多次运行并平均结果,集成方法可以平滑掉这种不稳定性,找到一个更稳定、更鲁棒的解决方案。
- 表示角度: 真实世界的假设空间可能非常庞大,单个模型可能无法找到最优解。集成多个模型相当于扩展了假设空间,从而有可能逼近那个真正的、更优的解。
3. 主要流派与方法
集成学习方法主要分为两大类:
A. 并行方法:Bagging (Bootstrap Aggregating)
- 核心思想:通过自助采样法(Bootstrap Sampling) 从原始数据集中随机有放回地抽取多个子集,并行地训练多个基学习器,然后通过投票(分类) 或平均(回归) 的方式结合预测结果。
- 目标:主要旨在降低方差,特别适用于那些容易过拟合的复杂模型(如深度决策树)。
- 典型算法:
- 随机森林(Random Forest): Bagging 的升级版和代表作。它在构建每棵决策树时,不仅对样本进行随机采样,还对特征进行随机采样。这种“双重随机性”进一步增强了模型的多样性和泛化能力,有效防止过拟合。
B. 串行方法:Boosting
- 核心思想:基学习器是串行训练的。后续的模型会更加关注先前模型预测错误的样本,通过不断调整样本的权重或拟合残差,逐步提升整体性能。
- 目标:主要旨在降低偏差,将多个弱学习器提升为一个强学习器。
- 典型算法:
- AdaBoost (Adaptive Boosting): 通过逐步提高被错误分类样本的权重,迫使后续的弱分类器重点关注这些难分的样本。
- 梯度提升(Gradient Boosting): 不再是调整样本权重,而是通过拟合损失函数的负梯度(即残差) 来迭代地构建模型。每一个新模型都是在学习之前所有模型加总的残差。
- XGBoost, LightGBM, CatBoost: 这些都是 Gradient Boosting 的高效、高性能实现,在各类数据科学竞赛中占据统治地位。它们通过优化计算速度、处理缺失值、防止过拟合等方面进行了大量改进。
C. 堆叠法:Stacking
- 核心思想:训练多个异质的基学习器(第一层模型),然后不是简单投票,而是训练一个元学习器(Meta-Learner,第二层模型) 来整合基学习器的预测结果,以得到最终的输出。
- 目标:结合不同模型的优势,形成更强大的预测能力。
代码示例
Bagging 的代表 —— 随机森林 (Random Forest)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, ConfusionMatrixDisplay
from sklearn.tree import DecisionTreeClassifier# 1. 加载数据(威斯康星州乳腺癌数据集)
data = load_breast_cancer()
X, y = data.data, data.target
feature_names = data.feature_names# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)print("数据集形状:", X.shape) # (569, 30)
print("特征示例:\n", feature_names[:5]) # ['mean radius' 'mean texture' 'mean perimeter' 'mean area' 'mean smoothness']
print("目标标签: 0-恶性(Malignant), 1-良性(Benign)") # 0-恶性(Malignant), 1-良性(Benign)# 3. 训练一个单一的决策树(作为对比基准)
single_tree = DecisionTreeClassifier(random_state=42)
single_tree.fit(X_train, y_train)
y_pred_tree = single_tree.predict(X_test)
acc_tree = accuracy_score(y_test, y_pred_tree)
print(f"\n单一决策树准确率: {acc_tree:.4f}") # 0.9474# 4. 训练随机森林集成模型
# n_estimators: 森林中树的数量
# max_features: 寻找最佳分割时考虑的最大特征数,'sqrt'是常用值,即总特征数的平方根
# random_state: 确保结果可重现
rf_clf = RandomForestClassifier(n_estimators=100, max_features='sqrt', random_state=42)
rf_clf.fit(X_train, y_train)# 5. 在测试集上进行预测并评估
y_pred_rf = rf_clf.predict(X_test)
acc_rf = accuracy_score(y_test, y_pred_rf)
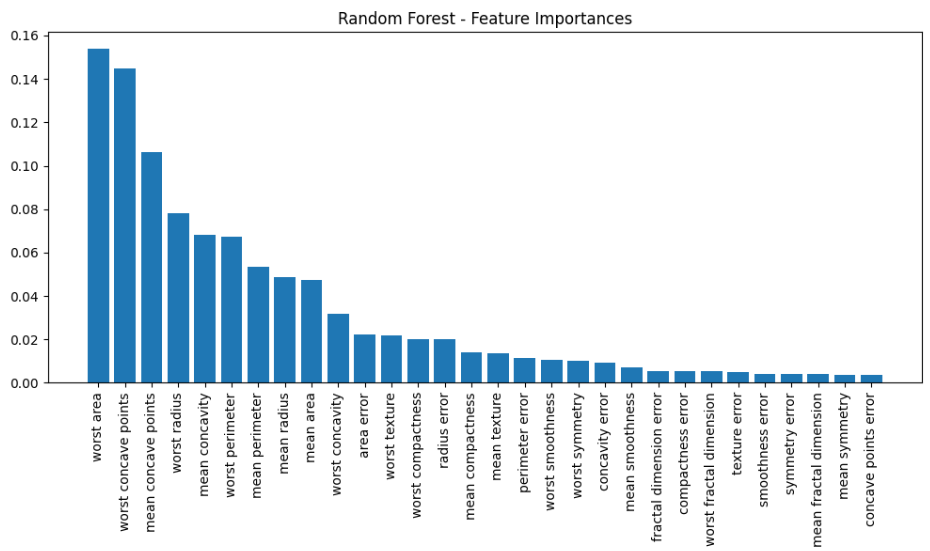
print(f"随机森林准确率: {acc_rf:.4f}") # 0.9649# 6. 可视化特征重要性(集成模型的强大附加功能)
importances = rf_clf.feature_importances_
indices = np.argsort(importances)[::-1] # 按重要性降序排列索引plt.figure(figsize=(10, 6))
plt.title("Random Forest - Feature Importances")
plt.bar(range(X_train.shape[1]), importances[indices], align='center')
plt.xticks(range(X_train.shape[1]), [feature_names[i] for i in indices], rotation=90)
plt.tight_layout()
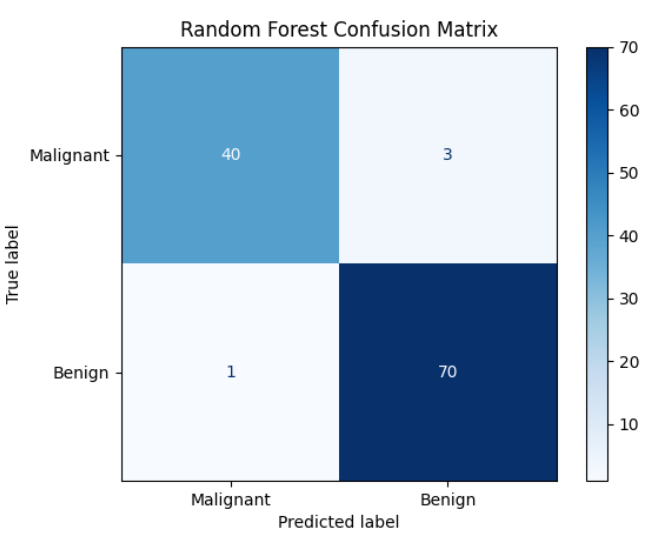
plt.show()# 7. 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred_rf, labels=rf_clf.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=['Malignant', 'Benign'])
disp.plot(cmap='Blues')
plt.title("Random Forest Confusion Matrix")
plt.show()
)





完成对蓝牙音响的控制(蓝牙广播))


:Vue2 性能优化)






:从原理到实战 - 训练、评估与应用指南)


