前言
我们正在利用pytorch实现CNN。主要分为四个小部分:数据预处理、神经网络pytorch设计、训练神经网络 和 神经网络实验。
在之前的章节中,我们已经完成了整个CNN框架的设计、训练与简单分析,本节将更进一步讨论神经网络处理过程中的细节问题,以便让我们能够有效地试验我们所构建的训练过程。
1. 优化超参数实验
1.1 Run Builder类
首先,我们希望构建一个 Run Builder 类,来实现上个博客最后一节的不同组合超参数实验。
from collections import OrderedDict
from collections import namedtuple
from itertools import productclass RunBuilder():@staticmethod # 静态方法,默认第一个参数不需要接收类或实例;可以直接用类来调用这个方法,无需创建实例def get_runs(params):Run = namedtuple('Run', params.keys()) # 创建一个具有名字的元组,'Run'是元组名,params.keys()提取参数字典的键runs = []for v in product(*params.values()): # 笛卡尔积runs.append(Run(*v)) # 首先将笛卡尔积分别对应到Run元组中,然后再统一添加到list中return runshyperparam = dict(lr = [.01,.001],batch_size = [100,1000],
)runs = RunBuilder.get_runs(hyperparam) # 直接用类 调用方法
print(runs)
# [Run(lr=0.01, batch_size=100), Run(lr=0.01, batch_size=1000),
# Run(lr=0.001, batch_size=100), Run(lr=0.001, batch_size=1000)]我们来看下之前的代码和现在的对比:
# Before
for lr, batch_size, shuffle in product(*param_values):comment = f'batch_size={batch_size} lr={lr} shuffle={shuffle}'
# 之前我们必须在for循环中列出所有的参数# After
for run in RunBuilder.get_runs(params):comment = f'-{run}'
# 现在不管有多少个参数,都可以自动生成注释
1.2 同步大量超参数实验
在上一个博客的代码中可以看到,我们现在的训练循环代码十分臃肿,我们希望将这个代码变得更加易扩展、易管理。因此除了1.1中构建的Run Builder类,还需构建一个Run Manager类。
它将使得我们能够在每一个run中进行管理,一方面可以摆脱冗长的TensorBoard调用,另一方面可以增加一些其他的功能。当parameter和run的数量增多的时候,TensorBoard不再是一个可以查看结果的可行方案。RunManager将在每个执行过程中创建生命周期,还可以跟踪损失和正确的预测数,最终保存将运行结果。
import time
from collections import OrderedDict
from collections import namedtuple
from itertools import product
import torch.nn.functional as Ffrom CNN_network import Network,train_set
import torch.optim as optimimport pandas as pd
import torch
from IPython.core.display_functions import clear_output
from tensorboard.notebook import displayfrom torch.utils.tensorboard import SummaryWriterclass RunBuilder():@staticmethod # 静态方法,默认第一个参数不需要接收类或实例;可以直接用类来调用这个方法,无需创建实例def get_runs(params):Run = namedtuple('Run', params.keys()) # 创建一个具有名字的元组,'Run'是元组名,params.keys()提取参数字典的键runs = []for v in product(*params.values()): # 笛卡尔积runs.append(Run(*v)) # 首先将笛卡尔积分别对应到Run元组中,然后再统一添加到list中return runs# hyperparam = dict(
# lr = [.01,.001],
# batch_size = [100,1000],
# )
#
# runs = RunBuilder.get_runs(hyperparam) # 直接用类 调用方法
# print(runs)
# # [Run(lr=0.01, batch_size=100), Run(lr=0.01, batch_size=1000),
# # Run(lr=0.001, batch_size=100), Run(lr=0.001, batch_size=1000)]class RunManager():def __init__(self):self.start_time = None # 计算运行时间self.run_params = None # RunBuilder的返回值self.run_count = 0self.run_data = []# 记录网络、dataloader、tensorboard文件self.network = Noneself.loader = Noneself.tb = Noneself.epoch_count = 0 # epoch数self.epoch_loss = 0 # epoch对应lossself.epoch_num_correct = 0 # 每个epoch预测正确的树木self.epoch_start_time = None # The start time of an epoch,对应 begin_epoch 和 end_epochdef begin_run(self, run ,network, loader):'''开始运行一次'''self.run_params = runself.start_time = time.time()self.run_count += 1self.tb = SummaryWriter(comment=f'{run}')self.network = networkself.loader = loaderimages, labels = next(iter(loader))self.tb.add_images('images', images)self.tb.add_graph(network, images)def begin_epoch(self):'''开始一个周期'''self.epoch_count += 1self.epoch_start_time = time.time()self.epoch_num_correct = 0self.epoch_loss = 0passdef end_epoch(self):'''结束一个周期,并计算loss等'''epoch_duration = time.time() - self.epoch_start_timerun_duration = time.time() - self.start_timeloss = self.epoch_loss / len(self.loader.dataset)accuracy = self.epoch_num_correct/len(self.loader.dataset)self.tb.add_scalar('Loss', loss, self.epoch_count)self.tb.add_scalar('Accuracy', accuracy, self.epoch_count)for name, weight in self.network.named_parameters():self.tb.add_histogram(name, weight, self.epoch_count)self.tb.add_histogram(f'{name}.grad', weight.grad, self.epoch_count)pass# 建立一个字典,记录所有中途结果,方便在tensorboard中查看分析results = OrderedDict(run=self.run_count,epoch=self.epoch_count,loss=loss,accuracy=accuracy,epoch_duration=epoch_duration,run_duration=run_duration)for k, v in self.run_params._asdict().items():results[k] = vself.run_data.append(results)df = pd.DataFrame.from_dict(self.run_data, orient='columns')clear_output(wait=True)display(df)passdef track_loss(self, loss,batch):'''记录损失'''self.epoch_loss += loss.item() * batch[0].shape[0]passdef track_num_correct(self, preds, labels):'''记录预测正确的数据'''self.epoch_num_correct += self.get_correct_num(preds, labels)def end_run(self):'''结束运行,并将epoch重新设置为0'''self.tb.close()self.epoch_count = 0@torch.no_grad()def _get_correct_num(self,predict, labels): #下划线代表是个内部方法,不被外部使用return predict.argmax(dim=1).eq(labels).sum().item()def save(self,filename):pd.DataFrame.from_dict(self.run_data, orient='columns').to_csv(f'{filename}'.csv, index=False)# 在这里修改参数
params = dict(lr = [.01,.001],batch_size = [100,1000],shuffle = [True,False]
)
manager = RunManager()for run in RunBuilder.get_runs(params):network = Network()train_loader = torch.utils.data.DataLoader(train_set, batch_size=run.batch_size)optimizer = optim.Adam(network.parameters(), lr=run.lr)manager.begin_run(run=run, network=network, loader=train_loader)for epoch in range(5):manager.begin_epoch()for batch in train_loader:images, labels = batchpredict = network(images) # Pass Batchloss = F.cross_entropy(predict, labels) # calculate lossmanager.track_loss(loss, batch)manager.track_num_correct(preds=predict, labels=labels)optimizer.zero_grad() # zero gradientloss.backward() # calculate gradientoptimizer.step() # updata weightspassmanager.end_epoch()manager.end_run()
1.3 同步不同网络的实验
这里我们可能还想对不同的网络进行测试,我们可以再定义一个NetworkFactory类,并将其添加到1.2的实验框架中。
Class NetworkFactory():@staticmethoddef get_network(name):if name == 'network1':return nn.Sequential(xxx)elif name == 'network2':return nn.Sequential(xxx)else:return Noneparams = dict(lr = [.01,.001],batch_size = [100,1000],shuffle = [True,False],network = ['network1','network2']device = ['mps','cpu']
)
manager = RunManager()for run in RunBuilder.get_runs(params):# 修改————————————————————————————————————————————————————————————network = NetworkFactory.get_network(run.network).to(device)# ———————————————————————————————————————————————————————————————train_loader = torch.utils.data.DataLoader(train_set, batch_size=run.batch_size)optimizer = optim.Adam(network.parameters(), lr=run.lr)manager.begin_run(run=run, network=network, loader=train_loader)for epoch in range(5):manager.begin_epoch()for batch in train_loader:images, labels = batchpredict = network(images) # Pass Batchloss = F.cross_entropy(predict, labels) # calculate lossmanager.track_loss(loss, batch)manager.track_num_correct(preds=predict, labels=labels)optimizer.zero_grad() # zero gradientloss.backward() # calculate gradientoptimizer.step() # updata weightspassmanager.end_epoch()manager.end_run()
2. 加速训练过程
现在需要考虑如何让训练/推理过程更快,特别是对于大规模的神经网络,这点尤为重要。
2.1 Dataloader 多进程加速
DataLoader 有一个 num_workers 参数,默认为 0,表示数据加载操作在主进程中进行。可以设置为大于 0 的数值来开启多个子进程。
注意:num_workers 只影响数据加载阶段的时间。因此,并非 num_workers 越多越好。如果神经网络的前向传播(forward pass)和反向传播(backward pass)所消耗的时间,远大于加载一个 batch 数据所需的时间,那么将 num_workers 设置为1通常就足够了,因为数据加载的瓶颈并不在于此。
(加速的原理相当于主进程在执行fp和bp时,提前准备好数据,省去读取的时间)
loader = DataLoader(train_set, batch_size=64, num_workers= )2.2 使用 GPU 加速训练
PyTorch允许我们在GPU和CPU之间实现数据的无缝转移,当我们想要把数据转去GPU时,我们使用to('cuda') / to('mps'),当我们使用cpu时,我们使用to('cpu')。做tensor运算时,需保持device的一致性。
在神经网络中,我们的network和data都可以移动到gpu上,这样就无需再从cpu中调取数据。
import torch
from CNN_network import Network,train_setprint(torch.mps.is_available()) # 检查GPU的可用性:Truenetwork = Network()
# t = torch.tensor([1,1,28,28], dtype=torch.float) 注意这种写法是不对的
t = torch.randn(1, 1, 28, 28) # 我们要随机生成一个shape为(1, 1, 28, 28)的tensor
t.to(float)# 使用cpu
device = torch.device('cpu')
t = t.to(device)
network = network.to(device)
cpu_pred = network(t)
print(cpu_pred.device) # 输出:cpu# 使用gpu
device = torch.device('mps')
t = t.to(device) # 数据移至gpu
network = network.to(device) # 网络移至gpu
gpu_pred = network(t)
print(gpu_pred.device) # 输出:mps:03. 标准化 Normalization
3.1 数据标准化
Normalization 也叫 feature scaling。因为我们经常会将不同的feature转换成相似的形状,保证整个数据集的均值为0,方差为1:
一般我们在做数据标准化处理时,要考虑数据集大小问题,如果数据集太大,无法一次性载入内存,则需分批载入计算。
import torch
from matplotlib import pyplot as plt
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from CNN_network import Network,train_set
import torchvision# Easy way:将整个数据集一次性加载到内存中作为tensor调取,计算均值和方差
loader = DataLoader(train_set,batch_size=len(train_set)) # batch_size:一次性导入
data = next(iter(loader))
print(data[0].mean(),data[0].std())
# 输出:tensor(0.2860) tensor(0.3530)# Hard way:如果数据集太大无法一次性导入,就分批导入
loader = DataLoader(train_set,batch_size=1000)
num_of_pixels = len(train_set) * 28 * 28 #计算总共的像素点个数=样本数乘以宽和高
total_sum = 0
for batch in loader: #一般batch会返回两个tensor:(image_tensor, label_tensor)!!!total_sum += batch[0].sum()
mean = total_sum / num_of_pixelssum_of_squard_error = 0
for batch in loader:sum_of_squard_error += ((batch[0] - mean).pow(2)).sum()
std = torch.sqrt(sum_of_squard_error / num_of_pixels)
print(mean,std) # tensor(0.2860) tensor(0.3530)下面我们将数据展平,看一下分布的直方图,并标注数据的均值。可以看到数据介于0~1之间,基本都集中在0左右,竖线为均值
plt.hist(data[0].flatten())
plt.axvline(data[0].mean())
plt.show()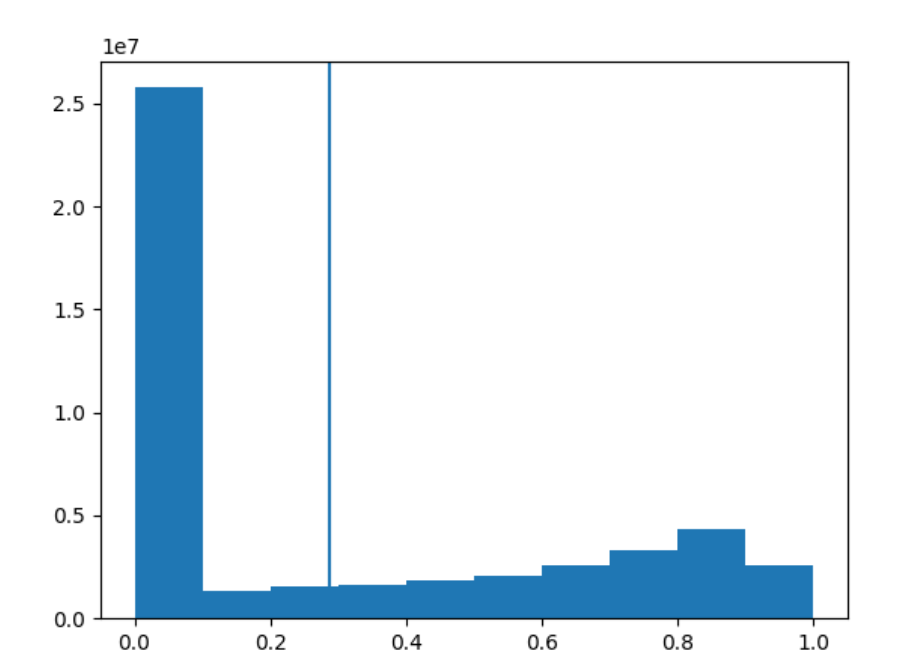
然后我们重新构建一个标准化之后的数据集,查看数据分布可以看到其均值为0,方差为1。这里要注意,因为我们是个灰度图像,颜色通道数为1;但是如果是RGB三通道,就需要对三个通道做分别的计算。
train_set_normal = torchvision.datasets.FashionMNIST(root='./data',download=True,train=True,transform=transforms.Compose([transforms.ToTensor(), # 要先转化为tensortransforms.Normalize(mean,std) # 再做标准化] ))loader = DataLoader(train_set_normal,batch_size=len(train_set_normal))
data = next(iter(loader))
print(data[0].mean(),data[0].std()) #均值为0,方差为1 plt.hist(data[0].flatten(),color = 'orange')
plt.axvline(data[0].mean(),color = 'orange')
plt.show()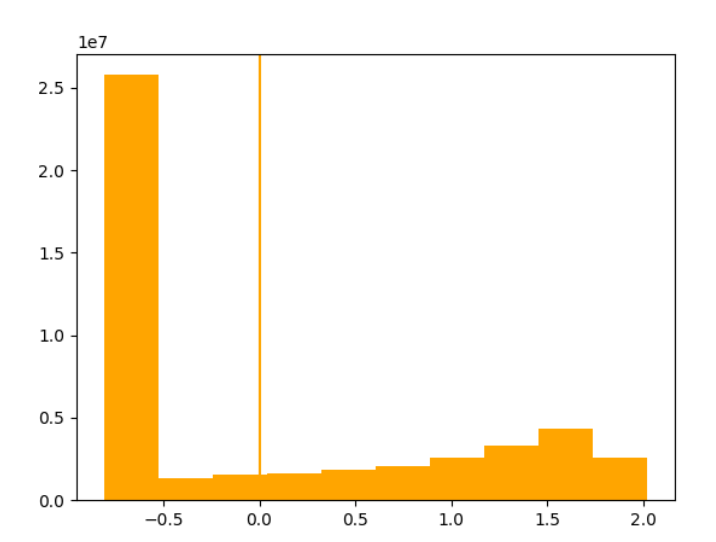
3.2 网络层标准化
3.1中我们介绍了对数据标准化的处理过程,现在我们不仅要对最开始传入的数据进行标准化,还想再层与层之间传递时,也进行标准化处理。在下图中可以看到这个标准化处理和3.1中稍有不同,多了一些参数。

import torch.nn as nn
torch.manual_seed(1)#
sequential1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5),nn.ReLU(),nn.MaxPool2d(2, 2),nn.BatchNorm2d(6), # 二维标准化nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5),nn.ReLU(),nn.MaxPool2d(2, 2),nn.Flatten(start_dim=1),nn.Linear(in_features=12 * 4 * 4, out_features=120),nn.ReLU(),nn.BatchNorm1d(120), # 一维标准化nn.Linear(in_features=120, out_features=60),nn.ReLU(),nn.Linear(in_features=60, out_features=10)
)
4. 一些其它补充
4.1 Pytorch Sequential Model
nn.Sequential 是 PyTorch 中的一个容器类 (torch.nn.Sequential)。它按顺序存储多个神经网络层或模块。其数据按顺序通过 Sequential 容器中定义的每一层,我们只需要提供一个层的列表(或 OrderedDict)。
相较于我们之前Class Network的方式,其优点就是简洁,无需显式定义 forward 方法。而缺点就是只能处理简单的层与层之间严格的线性顺序连接。如果网络结构更复杂(例如,有跳跃连接 skip-connections,如 ResNet;或者需要在 forward 过程中进行分支、合并、条件处理等),Sequential 就无法胜任。
对于之前的网络,我们是这样定义的:
class Network(nn.Module): # 继承nn.Module基类def __init__(self):super().__init__() # 调用父类(nn.Module)的init,确保父类的属性被正确初始化# 卷积层self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)# 全连接层/线性层self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)self.fc2 = nn.Linear(in_features=120, out_features=60)# 输出层self.out = nn.Linear(in_features=60, out_features=10)def forward(self,t):t = self.conv1(t)t = F.relu(t)t = F.max_pool2d(t, kernel_size=2, stride=2) # 池化不一定是有效的,可能会损失一些精度t = self.conv2(t)t = F.relu(t)t = F.max_pool2d(t, kernel_size=2, stride=2)t = t.reshape(-1,12*4*4)t = self.fc1(t)t = F.relu(t)t = self.fc2(t)t = F.relu(t)t =self.out(t)return t 现在用nn.Sequential的方式来定义:
# nn.Sequential
import torch.nn as nn
torch.manual_seed(1)# 定义方式1
sequential1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5),nn.ReLU(),nn.MaxPool2d(2, 2),nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5),nn.ReLU(),nn.MaxPool2d(2, 2),nn.Flatten(start_dim=1),nn.Linear(in_features=12 * 4 * 4, out_features=120),nn.ReLU(),nn.Linear(in_features=120, out_features=60),nn.ReLU(),nn.Linear(in_features=60, out_features=10)
)
sequential1 # 实例化# 定义方式2:定义OrderedDict字典
layers = OrderedDict([('conv1', nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)),('relu1', nn.ReLU()),('maxpool1', nn.MaxPool2d(2, 2)),('conv2', nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)),('relu2', nn.ReLU()),('maxpool2', nn.MaxPool2d(2, 2)),('flatten', nn.Flatten(start_dim=1)),('fc1', nn.Linear(in_features=12 * 4 * 4, out_features=120)),('relu3', nn.ReLU()),('fc2', nn.Linear(in_features=120, out_features=60)),('relu4', nn.ReLU()),('fc3_out', nn.Linear(in_features=60, out_features=10)),
])
sequential2 = nn.Sequential(layers)
sequential2 # 实例化# 定义方式3
sequential3 = nn.Sequential()
sequential3.add_module('conv1', nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5))
sequential3.add_module('relu1', nn.ReLU())
sequential3.add_module('maxpool1', nn.MaxPool2d(2, 2))
sequential3.add_module('conv2', nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5))
sequential3.add_module('relu2', nn.ReLU())
sequential3.add_module('maxpool2', nn.MaxPool2d(2, 2))
sequential3.add_module('flatten', nn.Flatten(start_dim=1))
sequential3.add_module('fc1', nn.Linear(in_features=12 * 4 * 4, out_features=120))
sequential3.add_module('relu3', nn.ReLU())
sequential3.add_module('fc2', nn.Linear(in_features=120, out_features=60))
sequential3.add_module('relu4', nn.ReLU())
sequential3.add_module('fc3_out', nn.Linear(in_features=60, out_features=10))sequential3 # 实例化4.2 重置网络权重
- 重置单个层的权重:
layer = nn.Linear(2,1)
layer.reset_parameters() # reset parameters
- 在网络中重置单个层的权重:
network = nn.Sequential(nn.Linear(2,1))
network[0].reset_parameters() # 通过索引来访问layer
- 重置网络中所有层的权重:
for module in network.children(): # .children()返回网络模型里的组成元素module.reset_parameters()- 保存和载入权重
# 保存权重
torch.save(network.state_dict(), './weight/model.pth') # 载入权重
network.load_state_dict(torch.load('./weight/model.pth')))



)

:非固定高度的容器实现折叠面板效果)

)





全面概述)
与wait()核心区别详解)



