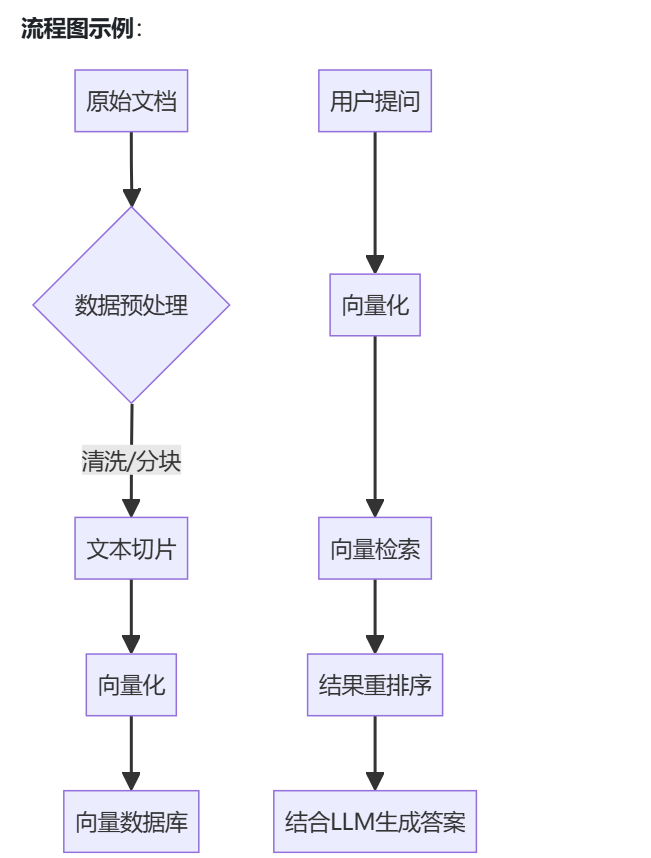
RAG(检索增强生成)的完整流程可分为5个核心阶段:
- 数据准备:清洗文档、分块处理(如PDF转文本切片);
- 向量化:使用嵌入模型(如BERT、BGE)将文本转为向量;
- 索引存储:向量存入数据库(如Milvus、Faiss、Elasticsearch);
- 检索增强:用户提问向量化后检索相关文档;
- 生成答案:将检索结果与问题组合输入大模型生成回答。
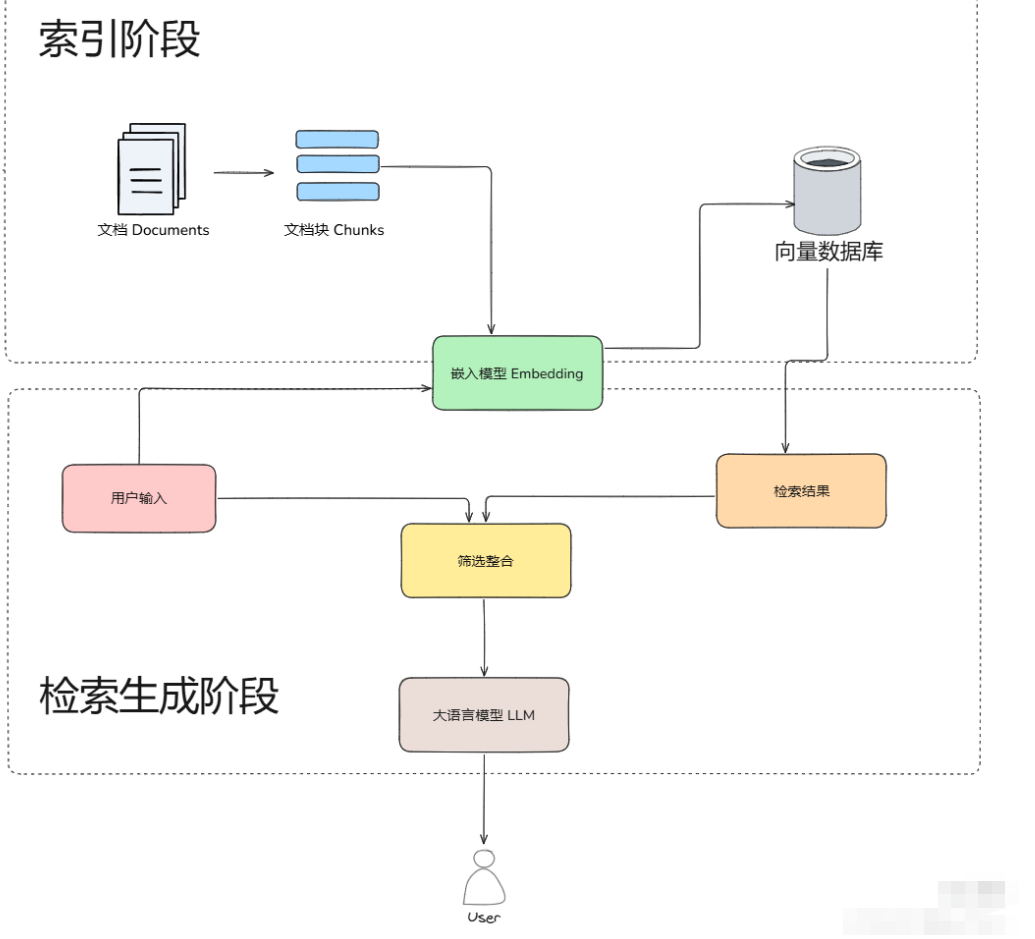
也可以从三个阶段来回答:
- 在 RAG 索引阶段,首先对原始文档进行解析,并将其拆分成多个较小的文本块。随后,这些文本块会通过嵌入模型进行向量化处理,生成的向量将被存储在向量数据库中,供后续检索使用。
- 在 RAG 检索阶段,RAG 系统会将用户的查询同样进行向量化,并在向量数据库中执行语义相似度匹配,筛选出与查询最相关的一组文本块。
- 最后在生成阶段,系统将用户查询与检索到的相关文本块进行组合,通过提示工程(Prompt Engineering)设计适当的输入格式,然后交由大语言模型生成最终的回答,至此完成整个 RAG 的流程。
扩展知识
文档处理的关键细节
文档分块策略:
- 按语义切分:用
SemanticSplitter确保每块语义独立(如问答对单独成块); - 按结构切分:HTML/PDF按标题层级切割(如
HTMLHeaderTextSplitter保留结构); - 递归切分:
RecursiveCharacterTextSplitter兼顾文本连贯性和长度限制。
检索阶段的优化策略
多阶段检索:
- 粗筛:用BM25快速匹配关键词(如“iPhone 15”);
- 精排:向量相似度+重排序模型(如Cohere Reranker);
混合检索:同时使用向量和关键词结果,通过RRF(倒数排名融合)合并。
生成阶段的Prompt设计示例
▼
python
复制代码
# 示例Prompt模板(网页2) prompt = "用户问题: {query}\n相关文档: {doc1}\n{doc2}\n请结合以上信息回答。"
可以进行上下文压缩:对检索结果摘要(如RAPTOR树状摘要)减少冗余输入。

















)

