🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 —— 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
- 1. 背景介绍
- 2. 相关工作
- 机器人中的语言指引
- 指令到动作序列的映射
- 使用视觉数据的深度强化学习
- 3. Problem Formulation
- 4. Proposed Approach
- 状态处理模块
- 多模态融合方法
- Policy Learning Module
- 模仿学习方法
- 强化学习方法
- 5. Environment
- 环境难度设置:
- 6. 实验设置
- 基线方法
- 强化学习基线
- 模仿学习基线
- 超参数设置
- 模仿学习设置
- 强化学习设置
- 实验结果与讨论
- Gated-Attention(GA)模型表现:
- 策略执行实例
- 注意力图分析
- 7. 总结
1. 背景介绍
Chaplot D S, Sathyendra K M, Pasumarthi R K, et al. Gated-attention architectures for task-oriented language grounding[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2018, 32(1).
🚀以上学术论文翻译由ChatGPT辅助。
为了完成由自然语言指令指定的任务,自动化智能体需要从语言中提取语义上有意义的表示,并将其映射到环境中的视觉元素与动作。这一问题被称为任务导向的语言指引(task-oriented language grounding)。
我们提出了一种端到端可训练的神经架构,用于在三维环境中进行任务导向的语言指引。该方法不依赖任何预设的语言学或感知知识,仅以环境中的原始图像像素与自然语言指令作为输入。该模型通过门控注意力机制(Gated-Attention)融合图像与文本表示,并利用标准的强化学习与模仿学习方法来学习执行自然语言指令的策略。
我们在未见过的指令和未见过的地图上对该模型进行了评估,展示了其定量与定性的有效性。此外,我们还引入了一个基于 3D 游戏引擎的新型环境,用于模拟任务导向语言指引中的一系列挑战,涵盖丰富的指令与环境状态。
人工智能(AI)系统被期望能够感知环境并采取行动来完成特定任务(Russell and Norvig 1995)。任务导向的语言指引(task-oriented language grounding)指的是通过将语言映射到环境中的视觉元素和动作,从而提取语言的语义表示,以执行指令所指定的任务。
请看图 1 中的场景,智能体接收自然语言指令和像素级视觉信息作为输入,在真实世界中执行任务。为了实现这一目标,智能体需要在视觉模态与语言模态之间建立语义对应关系,并学习一套策略来执行任务。这个问题面临多个挑战:智能体需要从原始像素输入中识别物体,探索环境(因为某些物体可能被遮挡或不在视野范围内),将指令中的每个概念与环境中的视觉元素或动作进行对应,基于当前环境中的物体理解语言的语用学含义(例如带有“最大物体”这类最高级表达的指令),并最终导航至正确的目标,同时避开错误目标。
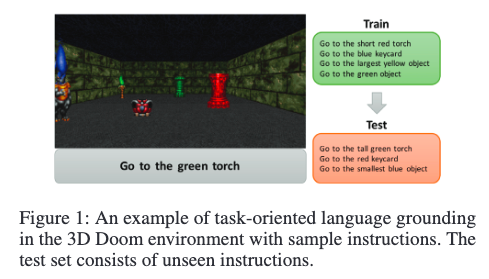
为了解决这个问题,我们提出了一种架构,包含状态处理模块和策略学习模块:前者用于将指令与智能体观测到的图像生成联合表示,后者用于预测每个时间步中智能体应执行的最优动作。状态处理模块采用一种新颖的门控注意力多模态融合机制(Gated-Attention),基于两种模态之间的乘性交互(Dhingra et al. 2017; Wu et al. 2016)。
本文的贡献总结如下:
- 提出一种端到端可训练的架构,用于在三维环境中基于原始像素输入完成任务导向的语言指引,且不依赖任何语言学或感知先验知识。我们验证该模型在未见过的指令和地图上具有良好泛化能力。
- 提出一种新颖的门控注意力机制,用于语言与视觉模态表示的多模态融合。通过多种策略学习方法验证该机制相较于拼接融合的基线方法更有效。同时注意力权重的可视化表明,模型能够学习将指令中提到的物体属性与所学习的视觉表示对应起来。
- 我们基于 ViZDoom(Kempka et al. 2016)开发了一个新环境,支持丰富的动作、物体及其属性,用于任务导向的语言指引。该环境提供第一人称视角,可模拟复杂的导航任务场景。
2. 相关工作
机器人中的语言指引
在对象及其属性层面进行语言指引方面,Guadarrama 等(2014)提出了一种将开放词汇映射到环境中对象的方法。还有一些研究通过人机交互进行概念指引(Chao et al. 2011;Lemaignan et al. 2012),其他方向包括将自然语言指令与触觉信号进行对齐(Chu et al. 2013),以及利用主动学习训练机器人学习语言映射(Kulick et al. 2013)。一些关注导航指令的研究(如 Guadarrama et al. 2013,Bollini et al. 2013,Beetz et al. 2011)旨在理解如 go、follow 等动词及其空间关系(Tellex et al. 2011;Fasola and Mataric 2013)。
指令到动作序列的映射
Chen and Mooney(2011)和 Artzi and Zettlemoyer(2013)提出基于语义解析的方法,将导航指令映射为动作序列。Mei, Bansal 和 Walter(2015)尝试利用神经网络将指令映射为动作序列,并结合从图像中提取的词袋特征。尽管这些工作关注将导航指令映射为动作,我们的工作还进一步探索将语言中描述的视觉属性(如形状、大小、颜色)对齐到视觉输入中。
使用视觉数据的深度强化学习
已有研究尝试使用深度强化学习方法来玩第一人称射击游戏(FPS),如 Lample and Chaplot(2016)、Kempka et al.(2016)、Kulkarni et al.(2016)。此类任务的挑战在于使用原始视觉像素学习各种任务(包括导航)的最优策略。Chaplot 等(2016)探索了 Doom 环境中不同任务之间的迁移学习。这些方法通常为每个任务单独训练一个深度 Q 网络(Mnih et al. 2013)。而我们的方法则训练一个单一网络来处理多个任务或指令。
Zhu 等(2016)研究了目标驱动的视觉导航任务,输入为目标物体图像。而我们的任务输入是自然语言指令,并无物体图像。Yu, Zhang 和 Xu(2017)探索了在二维迷宫中学习执行命令,包含已见与零样本设置,其中组合词未曾出现在训练集中。Misra, Langford 和 Artzi(2017)也研究了在二维 Blocks 环境中,将图像观测与文本输入映射为动作。
与上述工作相比,本文针对一个更具挑战性的三维环境进行自然语言指令的指引,任务输入为原始像素,且环境为部分可观测。我们的方法不依赖语言或感知先验,支持端到端训练。
3. Problem Formulation
我们研究的是任务导向的语言落地问题,具体体现在目标驱动的视觉导航任务中:代理需要根据自然语言指令导航至目标物体。假设代理在一个具备回合交互的环境 EEE 中,每一轮开始时代理接收到一条自然语言指令 LLL,该指令描述了目标物体。每个时刻 ttt,代理会接收到一张第一人称视角的原始图像 ItI_tIt,并执行一个动作 ata_tat。当代理到达某个物体或达到最大步数时,回合结束。我们记每个时刻的状态为 st={It,L}s_t = \{I_t, L\}st={It,L},目标是学习一个最优策略 π(at∣st)\pi(a_t \mid s_t)π(at∣st),使代理能顺利完成任务——即在规定步数内到达正确的目标物体。
我们考虑两种学习方式:
- 模仿学习(Imitation Learning):代理可以访问一个“专家”(oracle),该专家在任意状态下都能返回最优动作;
- 强化学习(Reinforcement Learning):代理在成功到达目标物体时获得正奖励,到达其他物体则获得负奖励。
4. Proposed Approach
我们提出了一种全新的架构用于3D环境中的任务导向语言落地任务,该架构不依赖任何语言或感知先验知识,并且可以端到端训练。整体架构分为两大模块:状态处理模块(State Processing) 和 策略学习模块(Policy Learning),如图2所示。
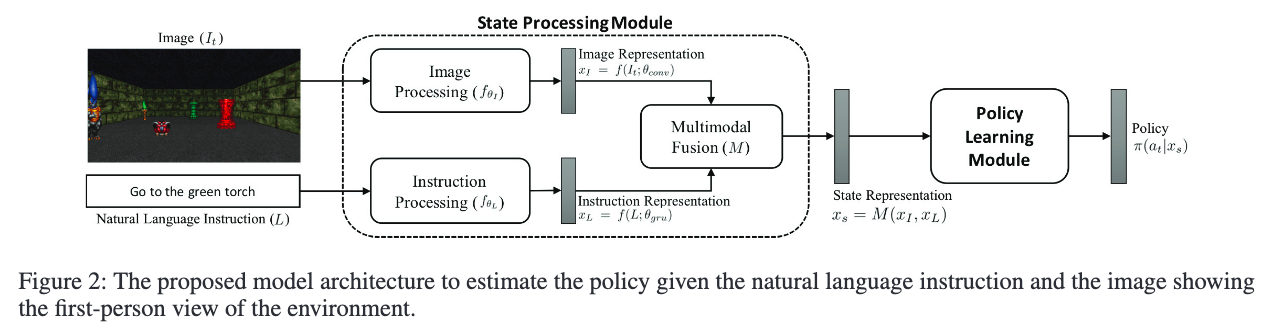
状态处理模块
该模块接收当前状态 st={It,L}s_t = \{I_t, L\}st={It,L},生成图像与语言的联合表示。它包括:
- 一个卷积神经网络 f(It;θconv)f(I_t; \theta_{\text{conv}})f(It;θconv) 提取图像特征 xI∈Rd×H×Wx_I \in \mathbb{R}^{d \times H \times W}xI∈Rd×H×W;
- 一个 GRU 网络 f(L;θgru)f(L; \theta_{\text{gru}})f(L;θgru) 提取语言指令的语义向量 xLx_LxL;
- 一个多模态融合模块 M(xI,xL)M(x_I, x_L)M(xI,xL) 将两种模态结合。
多模态融合方法
-
拼接法(Concatenation):
Mconcat(xI,xL)=[vec(xI);vec(xL)]M_{\text{concat}}(x_I, x_L) = [\text{vec}(x_I); \text{vec}(x_L)] Mconcat(xI,xL)=[vec(xI);vec(xL)] -
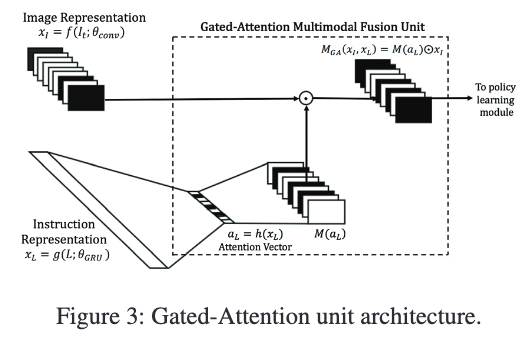
门控注意力法(Gated-Attention):
首先将 xLx_LxL 映射为注意力向量 aL∈Rda_L \in \mathbb{R}^daL∈Rd,并扩展为与 xIx_IxI 相同的维度 d×H×Wd \times H \times Wd×H×W。再与 xIx_IxI 做元素级乘法(Hadamard积):
MGA(xI,xL)=M(aL)⊙xIM_{\text{GA}}(x_I, x_L) = M(a_L) \odot x_I MGA(xI,xL)=M(aL)⊙xI
这种机制能有选择性地激活与指令相关的图像特征通道(如“绿色物体”激活颜色相关通道,“柱子”激活形状相关通道)。
Policy Learning Module
多模态融合的输出将送入策略学习模块。我们针对不同的学习范式设计了不同的策略学习结构:
模仿学习方法
我们使用两种算法:
- 行为克隆(Behavioral Cloning)
- DAgger
两者都依赖“专家”提供状态下的最优动作。专家从环境中提取代理与目标的位置、朝向,依据最短路径原则规划转向(如转左/转右)与前进动作。
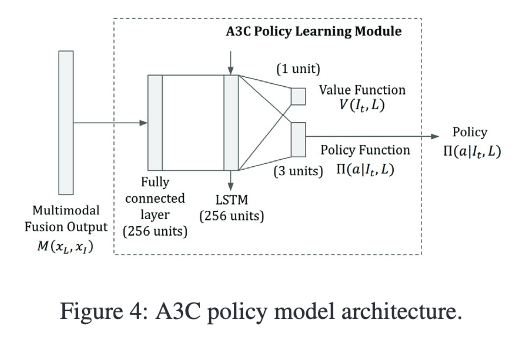
强化学习方法
我们采用 A3C(Asynchronous Advantage Actor-Critic)算法:
- 使用 LSTM 存储历史状态信息;
- 采用 Generalized Advantage Estimator(GAE)降低策略梯度方差;
- 使用熵正则鼓励探索;
- 网络输出同时包含 policy(动作概率)与 value(状态价值)估计。
5. Environment
我们在 ViZDoom(基于 Doom 游戏引擎)上构建了一个新环境。该环境支持:
- 第一人称视觉输入;
- 多种物体(一个为目标,其余为干扰项);
- 多种语言指令(70条手工设计指令);
- 多种动作:前进、左转、右转;
- 多种物体属性:颜色、形状、大小等。
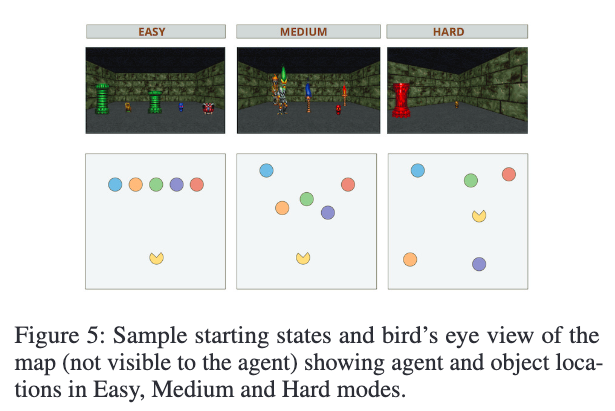
环境难度设置:
- Easy:固定初始位置与固定物体排列;
- Medium:物体随机,但保证视野可见;
- Hard:物体与代理均随机,需主动探索。
每次指令都对应多个任务场景(不同物体组合、位置等)。例如,“去红色物体”在不同场景中可指红色钥匙或红色火把,要求模型具备上下文感知与泛化能力。
6. 实验设置
我们在三个不同难度级别的环境模式中进行实验,并在每个 episode 中限制目标物体的数量为 5(包括一个正确物体、四个干扰物体以及一个智能体)。训练期间,使用来自 55 条指令的训练集中的物体进行生成,而针对零样本评估,我们将 15 条包含未见过的属性-物体组合的指令作为测试集。在训练时,每个 episode 开始时会随机选择一条训练指令,并从中选出一个正确目标物体和四个随机的错误物体。这些物体根据环境的难度级别被随机放置在地图上。如果智能体接触任何一个物体,或步数超过最大限制 T=30T = 30T=30,则该 episode 终止。
评估指标为智能体成功接触正确物体的成功率(即准确率)。我们设计了两种泛化评估场景:
- 多任务泛化 (MT):在训练集中指令的基础上,评估智能体在“未见地图”上的表现。这种设置测试模型是否泛化到新地图而非仅仅记住训练地图。
- 零样本任务泛化 (ZSL):在测试集中未见过的指令上评估智能体表现,用以验证模型是否能泛化到新的属性-物体组合,地图也是全新构造的。
基线方法
强化学习基线
我们参考 Misra 等人(2017)的模型作为强化学习基线方法。原工作在一个二维网格世界中执行语言指令操作,我们将其适配到我们的三维环境中:图像输入通过 CNN 编码,文本指令通过 LSTM 编码,两者使用拼接方式进行融合,并使用 A3C 算法训练。不同的是,我们不使用 reward shaping,以便测试方法在不提供目标距离等额外信息的前提下是否具有泛化能力。
模仿学习基线
我们参考 Mei 等人(2015)的工作,将其适配为模仿学习基线。原工作使用序列到序列模型将语言指令映射到动作序列,我们则采用 CNN 来处理三维环境下的原始图像像素。为保证公平,我们在所有模型中统一使用相同架构的 CNN、GRU 以及策略学习模块。
因此强化学习基线被定义为 A3C-Concat,模仿学习基线为 BC-Concat。
超参数设置
模型的输入为自然语言指令和 3×300×1683 \times 300 \times 1683×300×168 的 RGB 图像。CNN 结构为三层卷积:
- 第1层:128 个 8×88 \times 88×8 卷积核,步长为4;
- 第2层:64 个 4×44 \times 44×4 卷积核,步长为2;
- 第3层:64 个 4×44 \times 44×4 卷积核,步长为2。
文本指令使用大小为 256 的 GRU 编码。
模仿学习设置
我们实现了 Behavioral Cloning(BC)与 DAgger 算法,使用在线数据生成与策略更新流程。策略网络为一个线性层,输入为 512,输出为 3 个动作的概率分布。
在数据生成阶段:
- BC 使用 oracle 策略采样;
- DAgger 使用 oracle 与当前策略的混合策略采样,探索系数线性衰减从 1 到 0。
每次采样后,模型使用 RMSProp 优化器更新策略,优化目标为 Huber 损失函数(Huber 1964),每轮更新 10 个 epoch。
强化学习设置
我们使用 A3C 算法:
- 策略模块包含一个大小为 256 的线性层;
- 接入一个大小为 256 的 LSTM 层,用于编码状态历史;
- 输出层包括一个单神经元用于估计 value function,三个神经元估计 policy function;
- 使用 ReLU 激活函数;
- 学习率为 0.0010.0010.001,折扣因子为 0.990.990.99;
- 使用 16 个线程并行训练。
实验结果与讨论
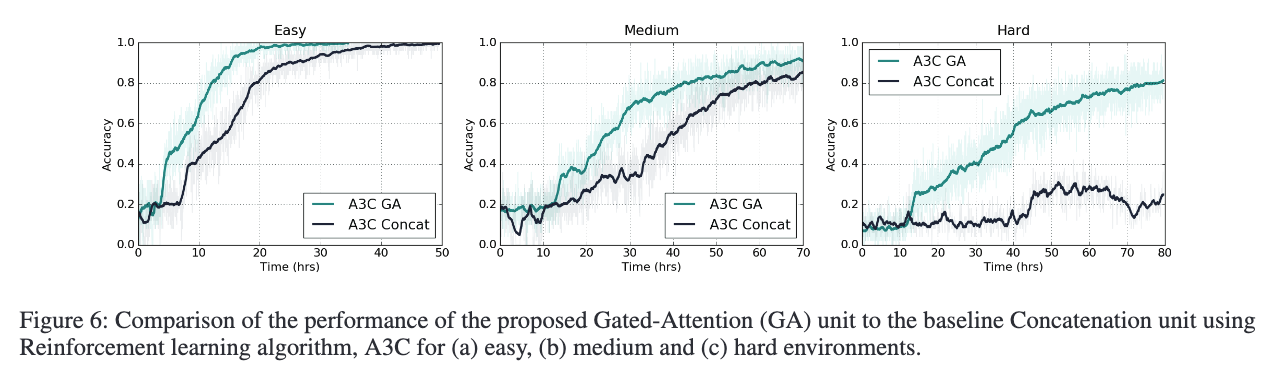
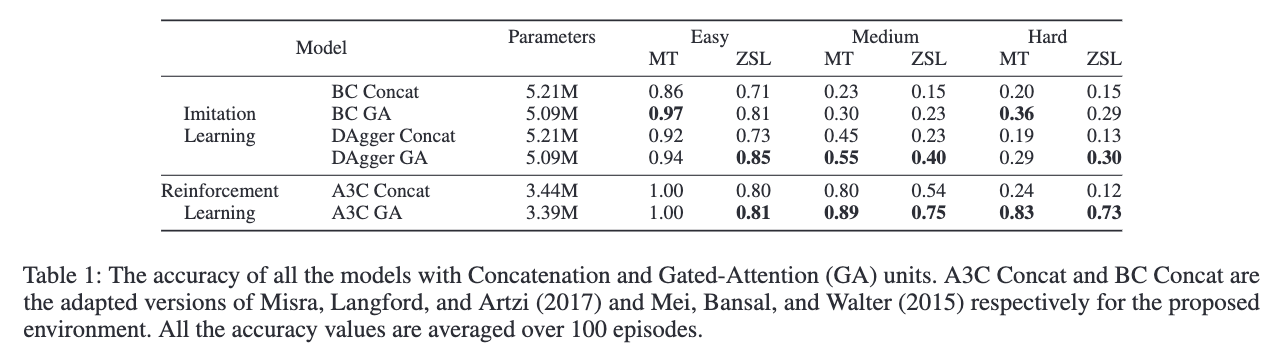
模型在多任务泛化和零样本泛化下的准确率见 Table 1,A3C 模型在训练过程中的多任务泛化准确率变化见 Figure 6。
Gated-Attention(GA)模型表现:
GA 模型在多任务和零样本泛化任务中明显优于 Concatenation 模型。Figure 6 显示 GA 模型收敛速度更快、最终精度更高。在难度最高的 Hard 模式中,GA 模型在多任务泛化上达到 83% 准确率,在零样本泛化上达到 73%;而 Concat 模型分别仅为 24% 和 12%。
在模仿学习中,GA 同样优于 Concat,但随着难度提升,模仿学习性能下降明显,主要因为其探索能力不足;相比之下,强化学习本身具有更强的探索机制,使得 A3C 模型在复杂场景下更为稳健。
策略执行实例
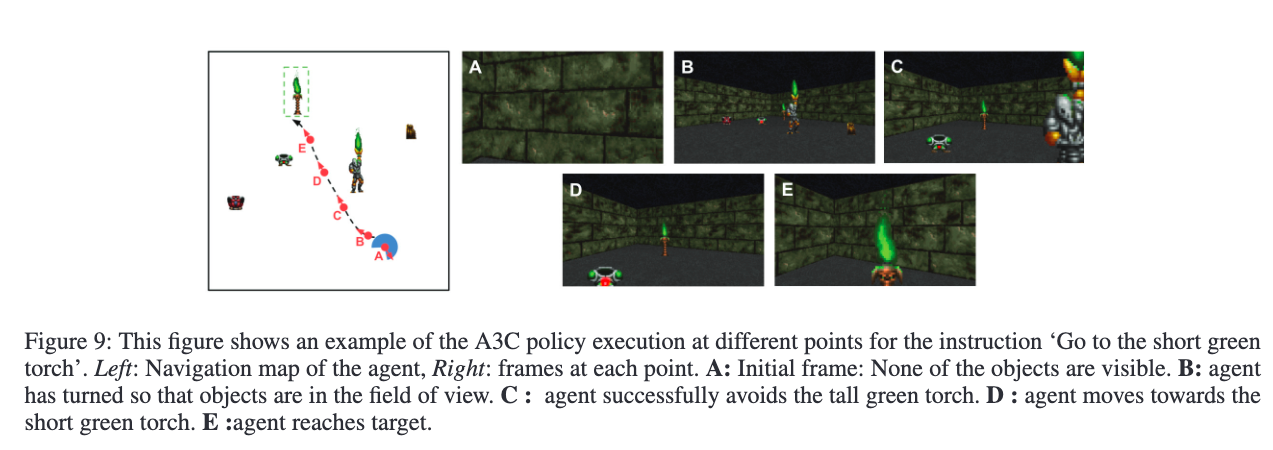
Figure 9 展示了 A3C 模型在 Hard 模式下的策略执行过程(指令:“短绿火把”)。起始视野中没有任何物体,智能体完成了约 300 度旋转后成功导航至目标,且能区分“短绿火把”与“高绿火把”。
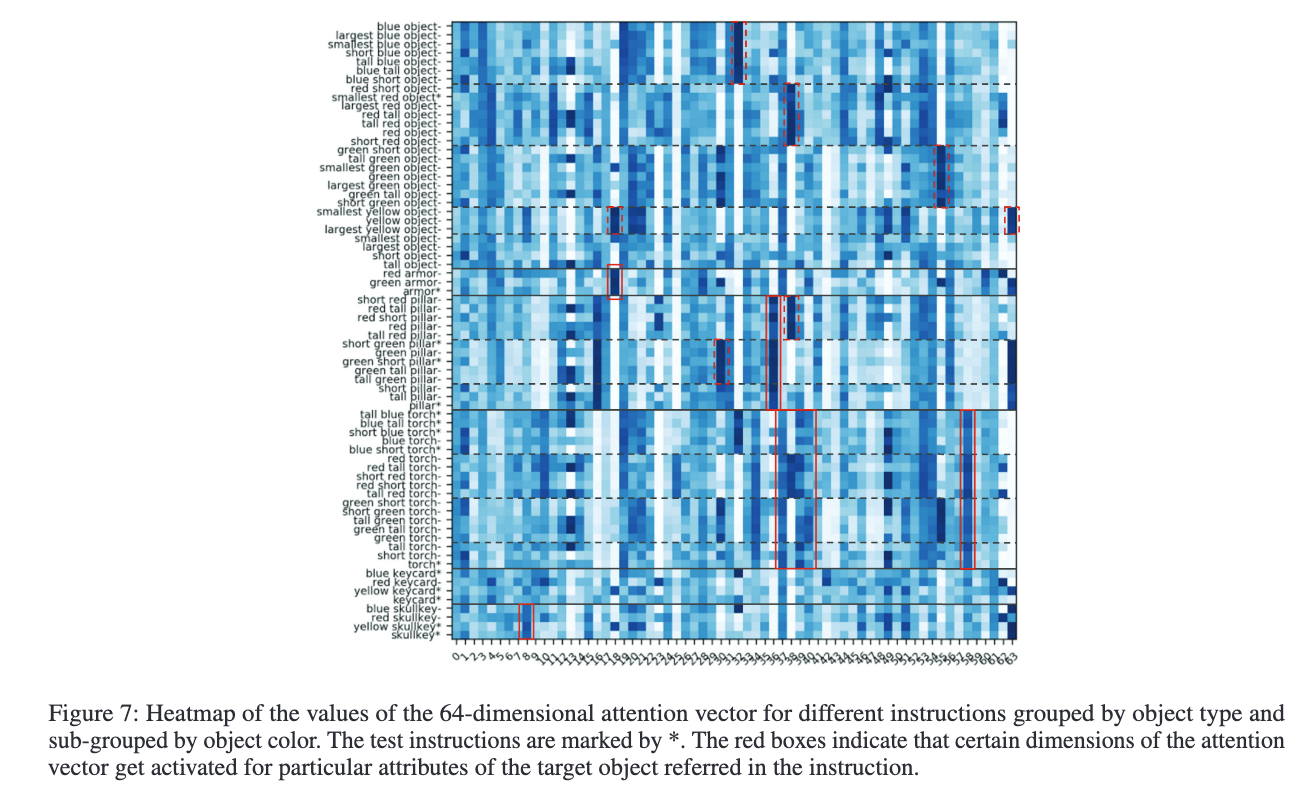
注意力图分析
Figure 7 展示了不同指令对应的注意力向量热力图。例如,第 18 维关注“armor”,第 8 维关注“skullkey”,第 36 维关注“pillar”。模型能够学会颜色和类型等属性,并激活对应特征图。GA 模型甚至能在未见指令中激活正确属性特征(如图中带“*”的指令所示)。
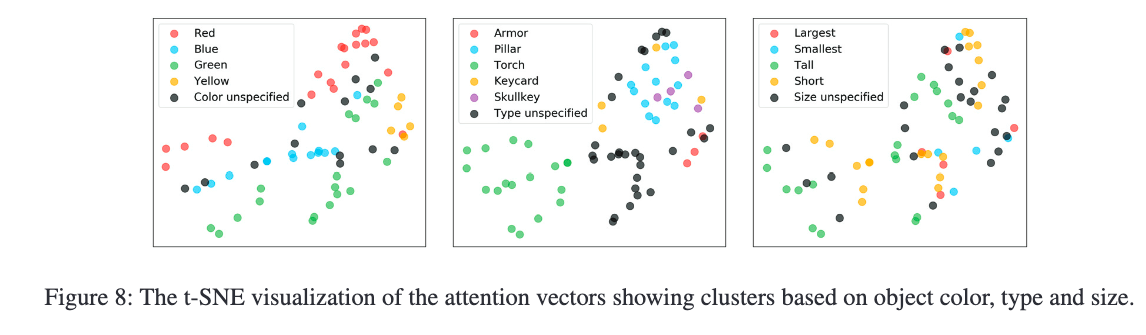
此外,Figure 8 的 t-SNE 可视化图进一步证明了模型在语义空间中形成了基于颜色与物体类型的聚类结构,指令中提及颜色的 attention 向量聚集在一起,而未提及颜色的则聚集于物体类型的类簇。
7. 总结
本文提出了一种端到端的三维环境中任务导向语言指令理解框架。该方法无需语言或视觉先验知识,直接从像素和自然语言中学习策略。核心创新为 Gated-Attention 多模态融合机制,通过指令与图像特征之间的乘法交互生成联合状态表示。实验结果表明,采用 Gated-Attention 的 A3C 与 Behavioral Cloning/DAgger 模型在三种难度设置下,均在多任务与零样本任务泛化上显著优于拼接式模型。同时,注意力可视化结果也证实该机制具备良好的语义辨识与属性聚焦能力。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 “Stay Hungry, Stay Foolish” —— 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!







-- 性能优化与调试)
)



)





)

