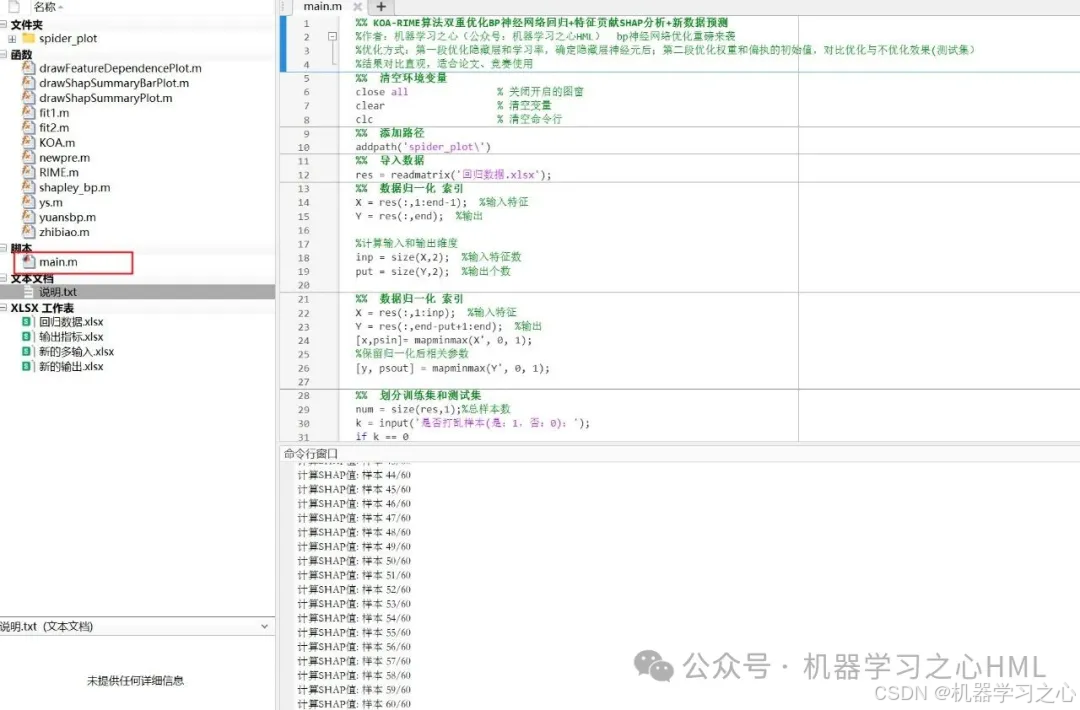
代码主要功能
该Matlab代码实现了一个KOA-RIME开普勒结合霜冰算法双重优化的BP神经网络回归模型,结合特征贡献度分析(SHAP)和新数据预测功能。核心功能包括:
- 双重参数优化:先用智能算法(以chebyshev映射改进KOA开普勒算法为例)优化隐藏层神经元数量和学习率,再用智能算法(以chebyshev映射改进RIME霜冰算法为例)优化权重/偏置初始值
- 特征贡献分析:通过SHAP值量化各输入特征对输出的影响
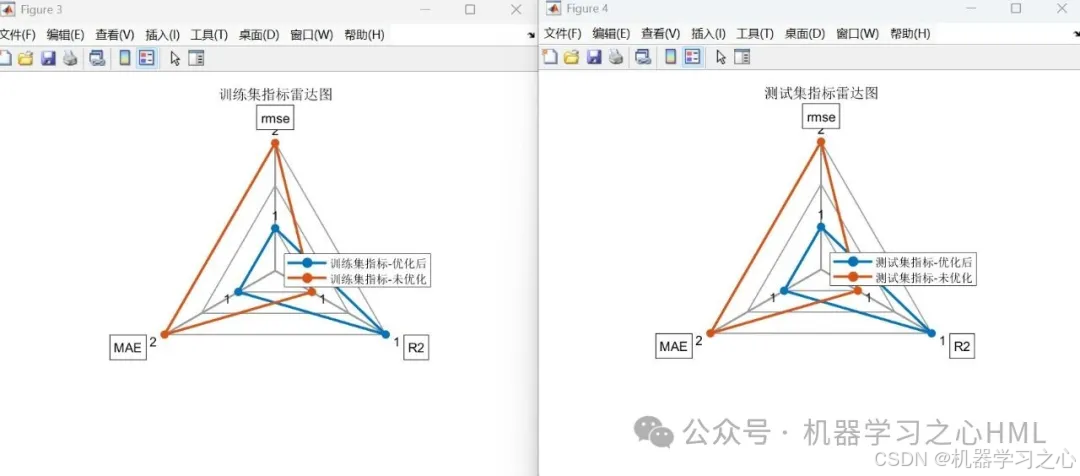
- 多维度评估:提供RMSE、R²、MAE等指标对比及可视化
- 一站式流程:数据预处理 → 模型优化 → 训练预测 → 结果解释 → 新数据预测
其中:代码采用9种映射方法选择种群初始值,改进KOA和RIME智能算法
9种映射方法包括
1.tent 映射
2.chebyshev 映射
3.singer 映射
4.logistic 映射
5.sine 映射
6.circle 映射
7.立方映射
8.Hénon 映射
9.广义Logistic映射
以上共计9*2=18种智能算法组合。
算法步骤
- 数据预处理
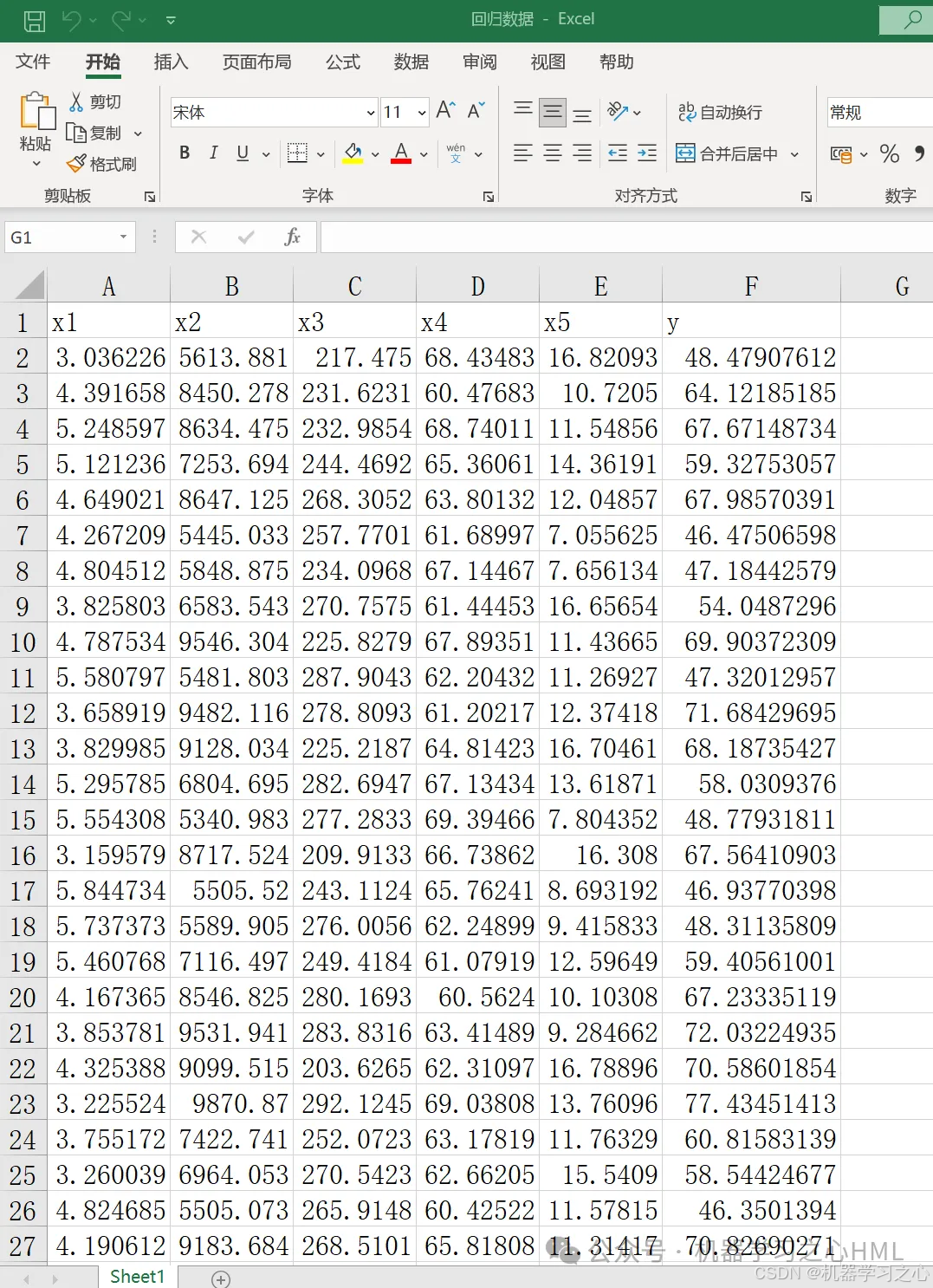
• 导入Excel数据(回归数据.xlsx)
• 归一化特征/标签(mapminmax)
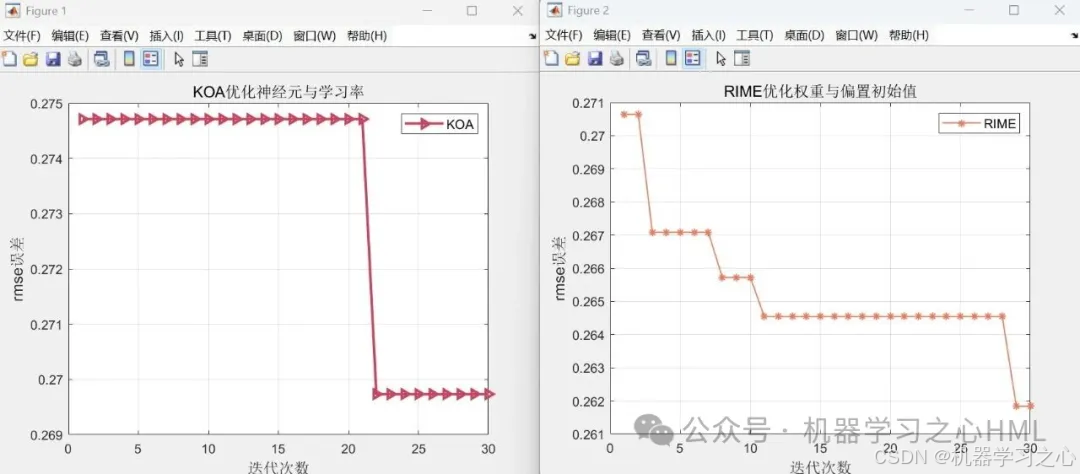
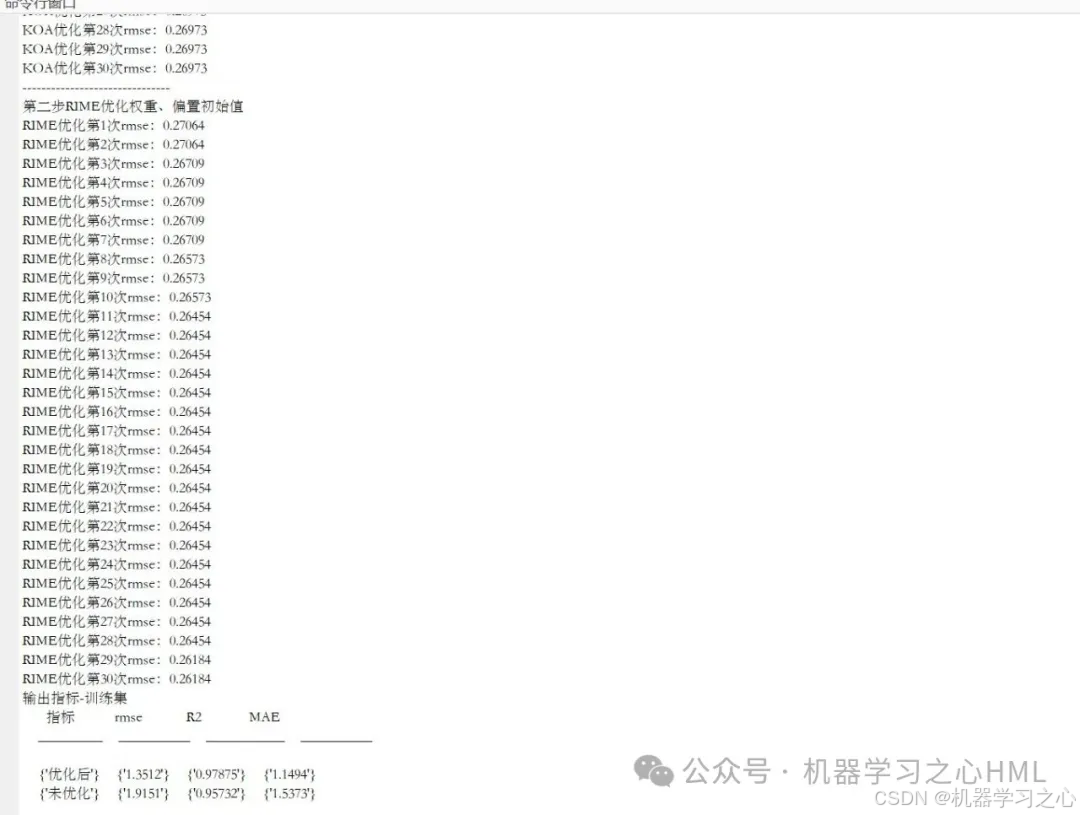
• 按7:3划分训练/测试集(可选随机打乱) - 第一段优化(以KOA为例)
• 优化目标:隐藏层神经元数 + 学习率
• 搜索空间:
lb1 = [floor(sqrt(inp+put)), 0]; % 神经元下限, 学习率下限
ub1 = [10+ceil(sqrt(inp+put)), 0.1]; % 神经元上限, 学习率上限
• 输出:最优神经元数 besthiddens、学习率 bestlearn - 第二段优化(以RIME为例)
• 优化目标:权重矩阵(Ⅰ/Ⅱ) + 偏置向量(Ⅰ/Ⅱ)
• 变量维度:inpbesthiddens + besthiddens + besthiddensput + put
• 输出:最优初始参数 gBest2 - 模型构建与训练
• 使用优化参数初始化BP网络
• 设置双曲正切隐藏层 + 线性输出层
• 训练1000轮(目标误差1e-6) - 预测与评估
• 反归一化预测结果
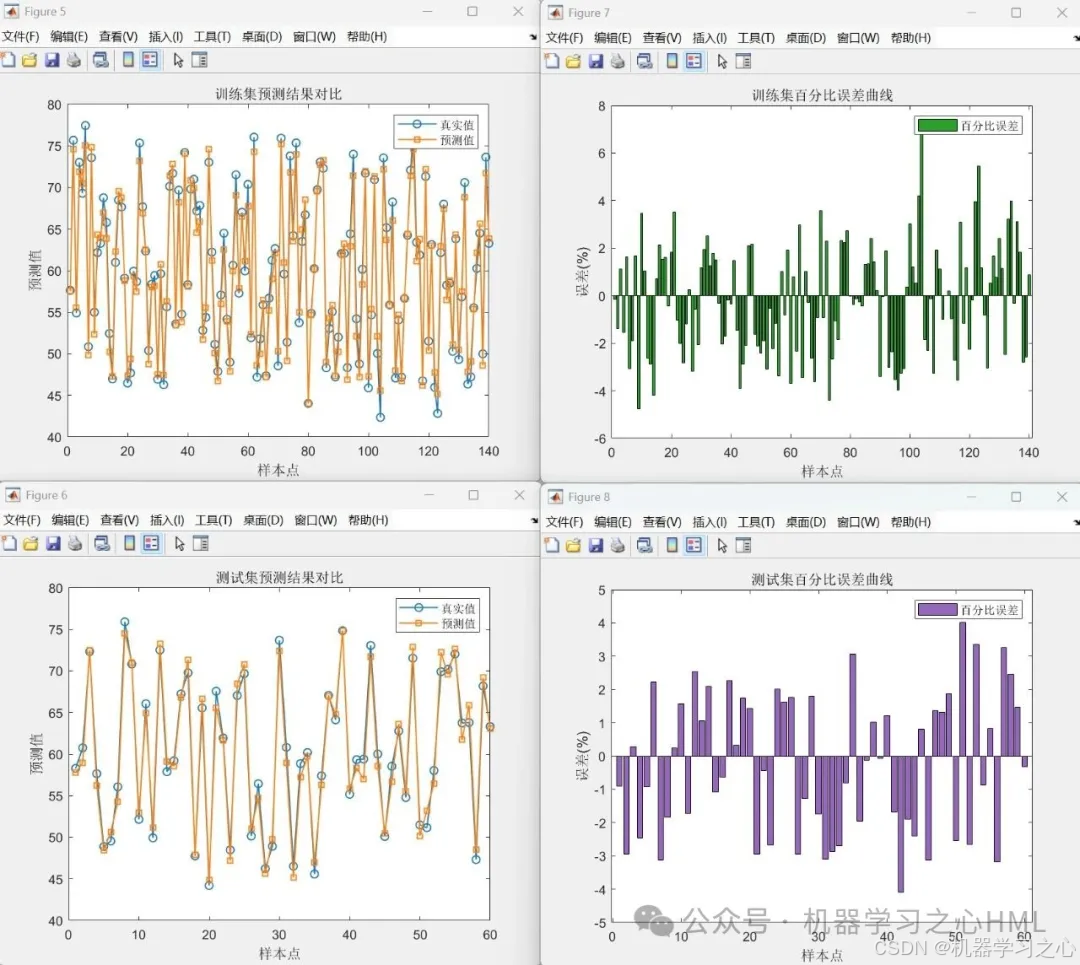
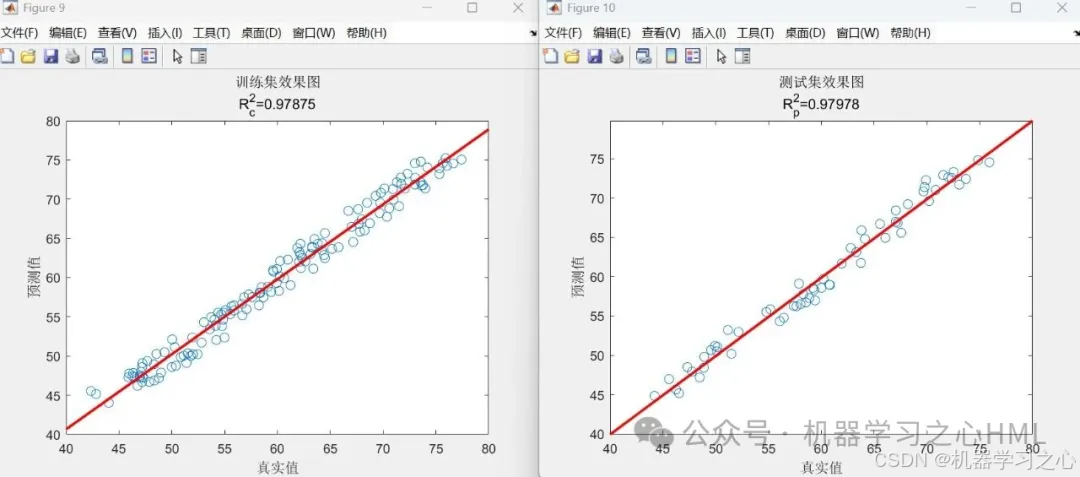
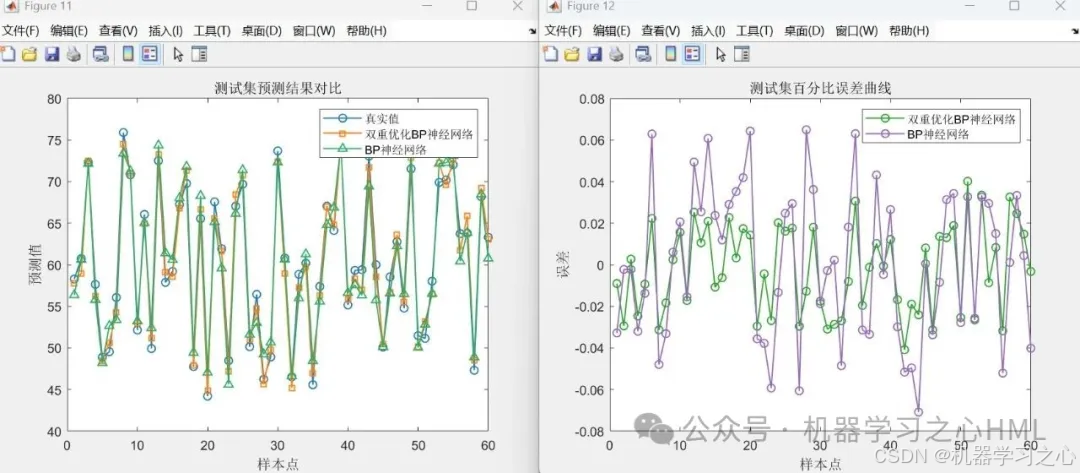
• 对比优化/未优化模型的:
• 预测曲线图
• 百分比误差图
• 线性拟合图
• 雷达图(RMSE/R²/MAE) - SHAP特征分析
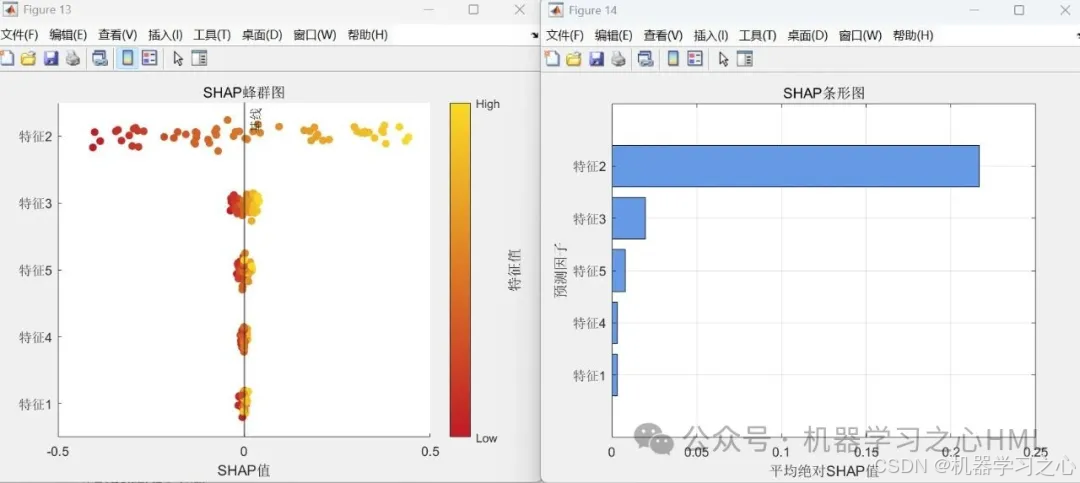
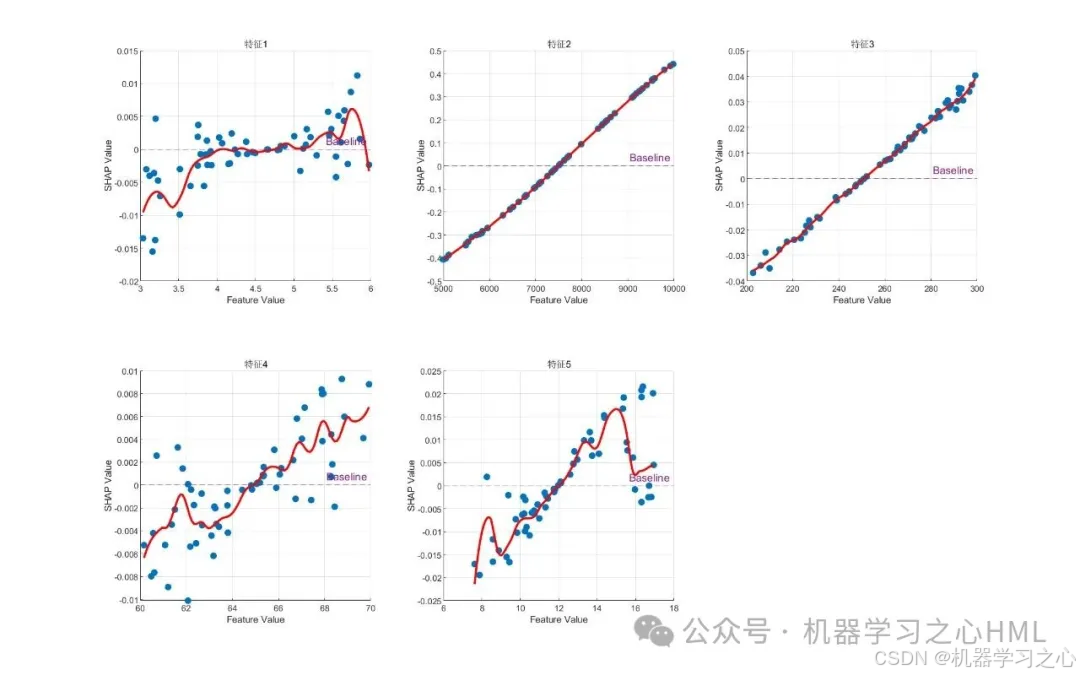
• 基于测试集计算Shapley值
• 生成三种可视化:
• 特征重要性条形图
• 特征效应散点图
• 摘要图(特征影响方向) - 新数据预测
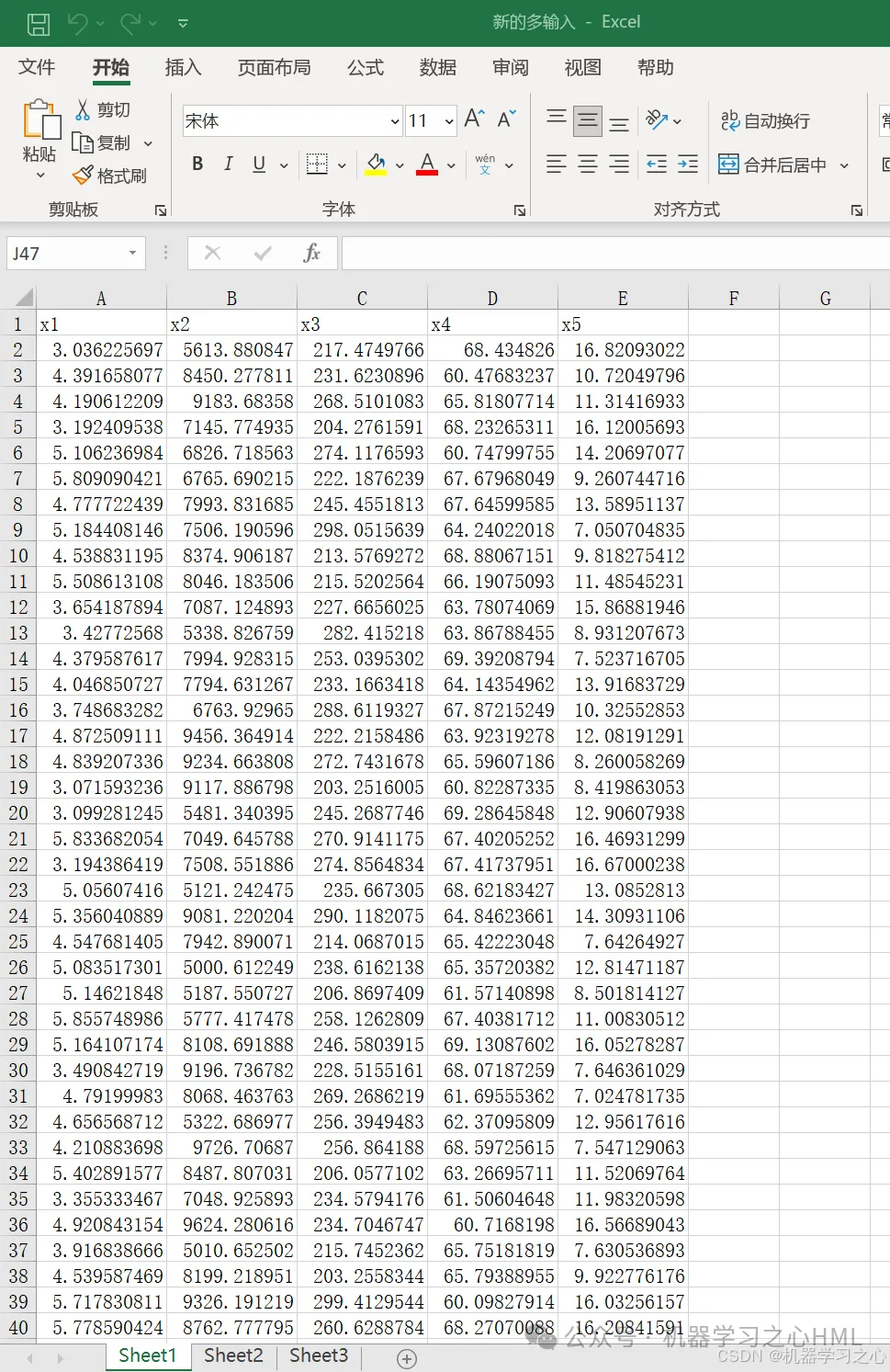
• 加载新的多输入.xlsx
• 自动应用相同归一化参数
• 输出预测结果到新的输出.xlsx
技术路线
关键参数设定
| 参数 | 值 | 说明 |
|---|---|---|
ratio | 0.7 | 训练集占比 |
N1/N2 | 10 | 种群大小 |
Max_iteration | 30 | 优化算法迭代次数 |
chaos_label | 2 | 混沌映射类型(Chebyshev) |
tf | {‘tansig’,‘purelin’} | 隐藏层/输出层激活函数 |
epochs | 1000 | 最大训练轮次 |
goal | 1e-6 | 训练目标误差 |
运行环境要求
- MATLAB版本:R2020b及以上
- 必要工具箱:
- Deep Learning Toolbox
- Optimization Toolbox
- Parallel Computing Toolbox(可选,加速SHAP计算)
- 依赖文件:
spider_plot\(雷达图绘制)- 自定义函数
- 数据格式:Excel文件(特征列+标签列)
应用场景
- 科研论文:提供完整的优化-评估-解释流程,可直接生成论文图表
- 数模比赛:适用于数学建模比赛的回归问题
- 工业预测:如:
- 设备寿命预测
- 金融风险评估
- 销售量预测
- 特征工程:通过SHAP分析识别关键特征
- 算法对比:验证智能优化算法对传统BP网络的改进效果
注意:代码中使用的混沌映射(Chebyshev)可增强优化算法的全局搜索能力,避免早熟收敛。SHAP分析部分需确保特征名称(
featureNames)与实际数据匹配。
部分源码
X = res(:,1:end-1); %输入特征
Y = res(:,end); %输出
%计算输入和输出维度
inp = size(X,2); %输入特征数
put = size(Y,2); %输出个数
%% 数据归一化 索引
X = res(:,1:inp); %输入特征
Y = res(:,end-put+1:end); %输出
[x,psin]= mapminmax(X', 0, 1);
%保留归一化后相关参数
[y, psout] = mapminmax(Y', 0, 1);
%% 划分训练集和测试集
num = size(res,1);%总样本数
k = input('是否打乱样本(是:1,否:0):');
if k == 0state = 1:num; %不打乱样本
elsestate = randperm(num); %打乱样本
end
ratio = 0.7; %训练集占比
trainnum = floor(num*ratio);
testnum = num-trainnum;
%取出训练集的x,y
x_train = x(:,state(1: trainnum));
y_train = y(:,state(1: trainnum));
%取出测试集的x,y
x_test = x(:,state(trainnum+1: end));
y_test = y(:,state(trainnum+1: end));
%% 智能优化算法的初始值
% label=1 对应 tent 映射
% label=2 对应 chebyshev 映射
% label=3 对应 singer 映射
% label=4 对应 logistic 映射
% label=5 对应 sine 映射
% label=6 对应 circle 映射
% label=7 对应 立方映射
% label=8 对应 Hénon 映射
% label=9 对应广义Logistic映射
% 如果label不是1-9之间的整数,则默认生成随机矩阵
label = 2; %自行指定
%% 第一步优化隐藏层神经元个数、学习率
%调用算法,两个变量:x1为神经元个数,x2为学习率
N1=10; %种群数
Max_iteration1 = 30; %迭代次数
%神经元个数范围,floor(sqrt(inp+put))~10+ceil(sqrt(inp+put)),可以自行改变
%学习率范围0-0.1,可以自行改变
lb1=[floor(sqrt(inp+put)) 0];%下限值
ub1=[10+ceil(sqrt(inp+put)) 0.1];%上限值
dim1=2; %2个变量,神经元个数、学习率%gbest为最优参数(对应误差最小情况时神经元、学习率)
besthiddens = round(gBest1(1));
bestlearn = gBest1(2);
%迭代曲线1
figure
plot(cg_curve1,'->','LineWidth',2,Color=[200,68,94]./255)
% 添加图例,并设置字体大小 % 设置 x 轴和 y 轴的标签,并设置字体大小
xlabel('迭代次数','FontSize',12);
ylabel('rmse误差','FontSize',12);% 显示网格(可选)
grid on;
%% 第二步优化权重、偏置初始值N2=10; %种群数
Max_iteration2 = 30; %迭代次数
%神经元个数范围,floor(sqrt(inp+put))~10+ceil(sqrt(inp+put)),可以自行改变
%学习率范围0-0.1,可以自行改变
lb2=-1;%下限值
ub2=1;%上限值
dim2=inp * besthiddens + besthiddens + besthiddens * put + put; %变量个数
[gBestScore2,gBest2,cg_curve2]=PSO(N2,Max_iteration2,lb2,ub2,dim2,fitness2,label);
%迭代曲线2
figure
plot(cg_curve2,'-*','LineWidth',1,Color=[233,122,94]./255)
% 添加图例,并设置字体大小 % 设置 x 轴和 y 轴的标签,并设置字体大小
xlabel('迭代次数','FontSize',12);
ylabel('rmse误差','FontSize',12);% 显示网格(可选)
grid on; 数据集
数据集(训练和测试数据)
数据集(新数据输入)

)








 核心概念、重要指令)
)
用户画像数据分析模型)

)




