前言:
Debezium SQL Server连接器捕获SQL Server数据库模式中发生的行级更改。
官方2.0文档:
Debezium connector for SQL Server :: Debezium Documentation
有关与此连接器兼容的SQL Server版本的信息,请参阅
| SQL Server | Database: 2017, 2019
JDBC Driver: 10.2.1.jre8
| Database: 2017, 2019
JDBC Driver: 9.4.1.jre8 |
Debezium SQL Server连接器首次连接到SQL Server数据库或集群时,它会对数据库中的模式进行一致的快照。初始快照完成后,连接器会连续捕获提交到CDC启用的SQL Server数据库的INSERT、UPDATE或DELETE操作的行级更改。该连接器为每个数据更改操作生成事件,并将其流式传输到Kafka主题。该连接器将表的所有事件流式传输到一个专门的Kafka主题。然后,应用程序和服务可以消耗该主题的数据更改事件记录。
要使Debezium SQL Server连接器捕获数据库操作的更改事件记录,您必须首先在SQL Server数据库上启用更改数据捕获。必须在数据库和要捕获的每个表上启用CDC。在源数据库上设置CDC后,连接器可以捕获数据库中发生的行级INSERT、UPDATE和DELETE操作。该连接器将每个源表的事件记录写入专门用于该表的Kafka主题。每个捕获的表都有一个主题。客户端应用程序读取他们遵循的数据库表的Kafka主题,并可以响应他们从这些主题中消耗的行级事件。
连接器首次连接到SQL Server数据库或集群时,它需要对其配置为捕获更改的所有表的模式进行一致的快照,并将此状态流式传输到Kafka。快照完成后,连接器会持续捕获随后发生的行级更改。通过首先建立所有数据的一致视图,连接器可以继续读取,而不会丢失快照发生时所做的任何更改。
Debezium SQL Server连接器可以容忍故障。当连接器读取更改并生成事件时,它会定期记录事件在数据库日志中的位置(LSN/日志序列号)。如果连接器因任何原因(包括通信故障、网络问题或崩溃)而停止,则在重新启动后,连接器将从读取的最后一点恢复读取SQL Server CDC表。
抵消定期提交。它们不是在更改事件发生时提交的。因此,在中断后,可能会生成重复的事件。
容错也适用于快照。也就是说,如果连接器在快照期间停止,则连接器在重新启动时开始新的快照。
安装sqlserver linux
1,环境centos7.2以上,2 GB+ 的内存
2,rpm安装包下载:Index of /rhel/7/mssql-server-2017/
3,下载并上传到linux环境下
wget https://packages.microsoft.com/rhel/7/mssql-server-2017/mssql-server-14.0.1000.169-2.x86_64.rpm
rpm -ivh mssql-server-14.0.1000.169-2.x86_64.rpm提示缺少依赖包 把包补上

rpm -ivh继续安装,根据提示执行sudo /opt/mssql/bin/mssql-conf setup
[root@node01 opt]# sudo /opt/mssql/bin/mssql-conf setup
选择 SQL Server 的一个版本: 1) Evaluation (免费,无生产许可,180 天限制) 2) Developer (免费,无生产许可) 3) Express (免费) 4) Web (付费版) 5) Standard (付费版) 6) Enterprise (付费版) 7) Enterprise Core (付费版) 8) 我通过零售渠道购买了许可证并具有要输入的产品密钥。 可在以下位置找到有关版本的详细信息:
https://go.microsoft.com/fwlink/?LinkId=852748&clcid=0x804 使用此软件的付费版本需要通过以下途径获取单独授权
Microsoft 批量许可计划。
选择付费版本即表示你具有适用的
要安装和运行此软件的就地许可证数量。 输入版本(1-8):1
可以在以下位置找到此产品的许可条款:
/usr/share/doc/mssql-server 或从以下位置下载:
https://go.microsoft.com/fwlink/?LinkId=855864&clcid=0x804 可以从以下位置查看隐私声明:
https://go.microsoft.com/fwlink/?LinkId=853010&clcid=0x804 接受此许可条款吗? [Yes/No]:yes 选择 SQL Server 的语言:
(1) English
(2) Deutsch
(3) Español
(4) Français
(5) Italiano
(6) 日本語
(7) 한국어
(8) Português
(9) Русский
(10) 中文 – 简体
(11) 中文 (繁体)
输入选项 1-11:10
输入 SQL Server 系统管理员密码:DTstack@123
确认 SQL Server 系统管理员密码:DTstack@123
正在配置 SQL Server…
Created symlink from /etc/systemd/system/multi-user.target.wants/mssql-server.service to /usr/lib/systemd/system/mssql-server.service.
安装程序已成功完成。SQL Server 正在启动。
[root@node01 opt]#验证是否启动
systemctl status mssql-server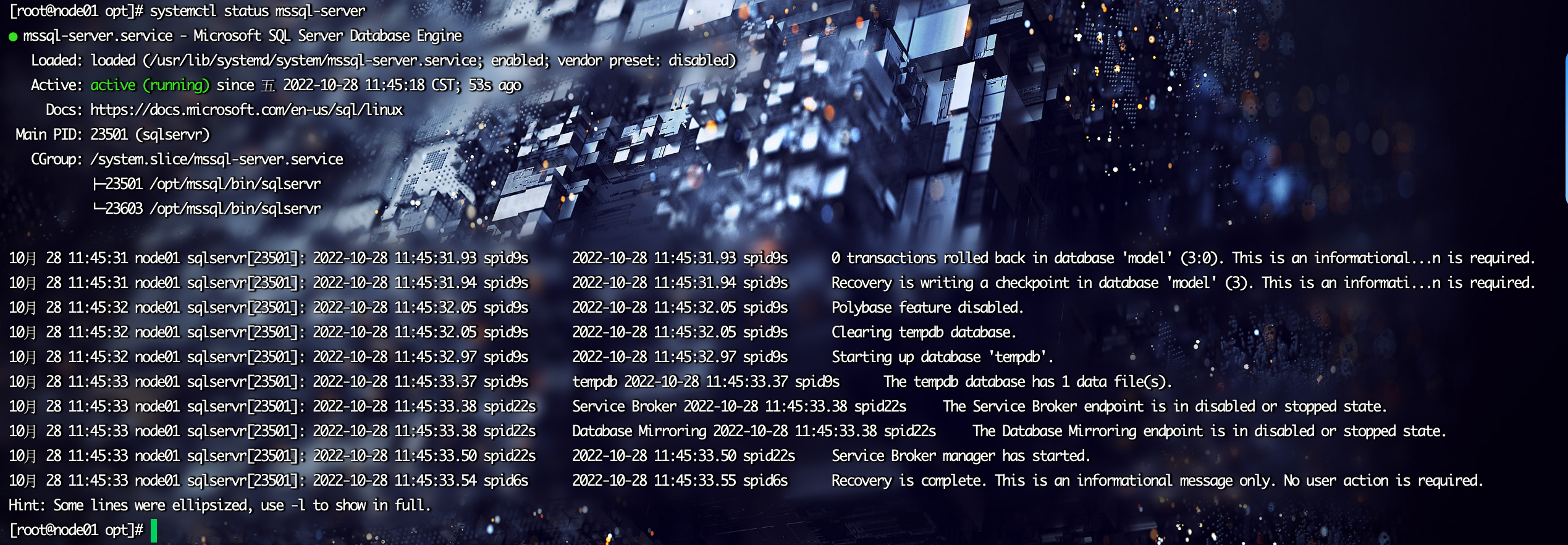
安装 SQL Server 命令行工具
若要创建数据库,需要使用一个能够在 SQL Server 上运行 Transact-SQL 语句的工具进行连接。 以下步骤安装 SQL Server 命令行工具: sqlcmd和bcp。
下载 Microsoft Red Hat 存储库配置文件。
sudo curl -o /etc/yum.repos.d/msprod.repo https://packages.microsoft.com/config/rhel/7/prod.repo
—————
运行以下命令以安装 mssql-tools 和 unixODBC 开发人员包。
sudo yum install -y mssql-tools unixODBC-devel
为方便起见,请将 /opt/mssql-tools/bin/ 添加到 PATH 环境变量。 这样就可以在运行工具时不指定完整路径。 请运行以下命令,以便修改登录会话和交互/非登录会话的 PATH:
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profile
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrc
source ~/.bashrcSQLServer基本命令
本地连接
以下步骤使用 sqlcmd 本地连接到新的 SQL Server 实例。
使用 SQL Server 名称 (-S),用户名 (-U) 和密码 (-P) 的参数运行 sqlcmd。 在本教程中,用户进行本地连接,因此服务器名称为 localhost。 用户名为 SA,密码是在安装过程中为 SA 帐户提供的密码。
sqlcmd -S localhost -U SA -P 密码 # 用命令行连接如果成功,应会显示 sqlcmd 命令提示符:1>。

提示 可以在命令行上省略密码,以收到密码输入提示。 如果以后决定进行远程连接,请指定 -S 参数的计算机名称或 IP 地址,并确保防火墙上的端口 1433 已打开。SQLServer基本命令
(1) 建库
> create database TestDB
> go(2) 看当前数据库列表
> select * from SysDatabases
> go(3) 看当前数据表
> use 库名
> select * from sysobjects where xtype='u'
> go(4) 看表的内容
> select * from 表名;
> go插入数据
接下来创建一个新表 mgmg,然后插入两个新行。
在 sqlcmd 命令提示符中,将上下文切换到新的 TestDB 数据库:
USE TestDB创建名为 mgmg 的新表:
CREATE TABLE mgmg (id INT, name NVARCHAR(50), quantity INT)将数据插入新表:
INSERT INTO mgmg VALUES (1, 'banana', 150); INSERT INTO mgmg VALUES (2, 'orange', 154);要执行上述命令的类型 GO:
GO在 SQL Server 数据库上启用 CDC
在为表启用 CDC 之前,您必须为 SQL Server 数据库启用它。 SQL Server 管理员通过运行系统存储过程来启用 CDC。系统存储过程可以使用 SQL Server Management Studio 或 Transact-SQL 运行。
先决条件
您是 SQL Server 的 sysadmin 固定服务器角色的成员。
您是数据库的 db_owner。
SQL Server 代理正在运行。
注意:
SQL Server CDC 功能仅处理用户创建的表中发生的更改。您不能在 SQL Server 主数据库上启用 CDC。
程序
1.从 SQL Server Management Studio 的“查看”菜单中,单击“模板资源管理器”。
2.在模板浏览器中,展开 SQL Server 模板。
3.展开更改数据捕获 > 配置,然后单击为 CDC 启用数据库。
4.在模板中,将 USE 语句中的数据库名称替换为要为 CDC 启用的数据库名称。
5.运行存储过程 sys.sp_cdc_enable_db 为 CDC 启用数据库。
为 CDC 启用数据库后,将创建名为 cdc 的模式,以及 CDC 用户、元数据表和其他系统对象。
以下示例显示如何为
数据库 TestDB 启用 CDC:
USE TestDB
GO
EXEC sys.sp_cdc_enable_db
GO
在 SQL Server 表上启用 CDC
SQL Server 管理员必须在您希望 Debezium 捕获的源表上启用更改数据捕获。数据库必须已为 CDC 启用。要在表上启用 CDC,SQL Server 管理员为该表运行存储过程 sys.sp_cdc_enable_table。存储过程可以使用 SQL Server Management Studio 或 Transact-SQL 运行。必须为要捕获的每个表启用 SQL Server CDC。
先决条件:
CDC 在 SQL Server 数据库上启用。
SQL Server 代理正在运行。
您是数据库的 db_owner 固定数据库角色的成员。
程序
从 SQL Server Management Studio 的“查看”菜单中,单击“模板资源管理器”。
在模板浏览器中,展开 SQL Server 模板。
展开更改数据捕获 > 配置,然后单击启用表指定文件组选项。
在模板中,将 USE 语句中的表名替换为您要捕获的表名。
运行存储过程 sys.sp_cdc_enable_table。
以下示例显示如何为表 mgmg 启用 CDC:
示例:为 SQL Server 表启用 CDC
USE TestDB
GO EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'mgmg',
@role_name = N'NULL',
@filegroup_name = N'MyDB_CT',
@supports_net_changes = 0
GO
示例
USE MyDB
GO EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'MyTable',
@role_name = N'MyRole',
@filegroup_name = N'MyDB_CT',
@supports_net_changes = 0
GO指定要捕获的表的名称。
指定角色 MyRole,您可以向该角色添加要授予对源表的捕获列的 SELECT 权限的用户。具有 sysadmin 或 db_owner 角色的用户还可以访问指定的更改表。将 @role_name 的值设置为 NULL,以仅允许 sysadmin 或 db_owner 中的成员对捕获的信息具有完全访问权限。
指定 SQL Server 为捕获的表放置更改表的文件组。命名的文件组必须已经存在。最好不要将更改表放在用于源表的同一文件组中。
Ps文件组
1. 如何查看数据库中所有的文件组。 语法:sp_helpfilegroup 步骤: use 数据库 sp_helpfilegroup
2. 如何找到文件组和文件的对应情况. sp_helpdb love 创建文件组。
语法: alter database 数据库名 add filegroup 文件组名
步骤: use 数据库名 alter database 数据库名 add filegroup 文件组名
范例:
use love
alter database TestDB add filegroup 财务部
SQL Server 管理员可以运行系统存储过程来查询数据库或表以检索其 CDC 配置信息。存储过程可以使用 SQL Server Management Studio 或 Transact-SQL 运行。
先决条件
您对捕获实例的所有捕获列具有 SELECT 权限。 db_owner 数据库角色的成员可以查看所有已定义捕获实例的信息。
您拥有为查询包括的表信息定义的任何门控角色的成员资格。
程序
从 SQL Server Management Studio 的“查看”菜单中,单击“对象资源管理器”。
在对象资源管理器中,展开数据库,然后展开您的数据库对象,例如 MyDB。
展开可编程性 > 存储过程 > 系统存储过程。
运行 sys.sp_cdc_help_change_data_capture 存储过程来查询表。
查询不应返回空结果。
以下示例在数据库 TestDB 上运行存储过程 sys.sp_cdc_help_change_data_capture:
示例:
查询表以获取 CDC 配置信息
USE TestDB;
GO
EXEC sys.sp_cdc_help_change_data_capture
GO
该查询返回数据库中每个表的配置信息,这些表为 CDC 启用并且包含调用者有权访问的更改数据。如果结果为空,请验证用户是否具有访问捕获实例和 CDC 表的权限。
部署Debezium SQL Server连接器
要部署Debezium SQL Server连接器,请安装Debezium SQL Server连接器存档,配置连接器,并通过将其配置添加到Kafka Connect来启动连接器。
先决条件
安装了Apache ZooKeeper、Apache Kafka和Kafka Connect。
SQL Server已安装,已配置为CDC,并准备与Debezium连接器一起使用。
程序
下载Debezium SQL Server连接器插件存档
Wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-sqlserver/1.9.7.Final/debezium-connector-sqlserver-1.9.7.Final-plugin.tar.gz将文件提取到您的Kafka Connect环境中。
将带有JAR文件的目录添加到Kafka Connect的plugin.path中。
配置连接器并将配置添加到您的Kafka Connect集群中。
重新启动您的Kafka Connect流程以提取新的JAR文件。
解压插件包
tar -xvf debezium-connector-sqlserver-1.9.7.Final-plugin.tar.gz配置kafka,让kafka知道这个插件.
[root@hhz02 config]# vi connect-distributed.properties配置注意项:(单机模式启动连接器 connect-standlone.properties)
bootstrap.servers=172.16.120.17:9092
offset.storage.topic=connect-sqlserver-status
offset.storage.replication.factor=1
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
status.storage.topic=connect-sqlserver-statu
status.storage.replication.factor=1
config.storage.topic=connect-sqlserver-config
config.storage.replication.factor=1
group.id=connect-sqlserver
offset.flush.interval.ms=10000
plugin.path=/opt/debezium-connector-sqlserver
rest.port=8083Ps:
如果kafka开启kerberos 该配置文件还需要添加:
security.protocol=SASL_PLAINTEXT
sasl.kerberos.service.name=kafka还需要再启动脚本connect-distributed.sh中添加:
export KAFKA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf -Djava.security.auth.login.config=/opt/dtstack/Kafka/kafka/config/kafka_jaas.conf"注意:集群模式kafka 需要注意配置分发。
重启kafka集群使配置生效。
启动Kafka connector
/opt/dtstack/DTBase/kafka/bin/connect-distributed.sh -daemon /opt/dtstack/DTBase/kafka/config/connect-sqlserver.properties注意结尾这个文件 集群模式为:connect-distributed.properties,单机模式为:connect-standalone.properties
(如果启动有问题 观察/opt/app/kafka/logs/connectDistributed.out)
检测Kafka connector是否正常工作
1. 检测kafka连接器的服务状态
[root@node01 logs]# curl -H "Accept:application/json" node01:8083/
{"version":"1.1.1","commit":"8e07427ffb493498","kafka_cluster_id":"svXhhAFkSt6xLRPTBIdE1Q"}2. 检查向 Kafka Connect 注册的连接器列表
[root@hdp01 kafka]# curl -H "Accept:application/json" node01:8083/connectors/
[]返回空列表, 表示目前还没有注册的连接器
附:删除命令
curl -X DELETE node01:8083/connectors/db2-connector1SQL Server 连接器配置示例
以下是连接器实例的配置示例,该实例在 172.16.120.17 的端口 1433 上从 SQL Server 服务器捕获数据,我们在逻辑上将其命名为 fullfillment。通常,您通过设置可用于连接器的配置属性,在 JSON 文件中配置 Debezium SQL Server 连接器。
注册连接器
Kafka Connect 服务的 API 提交POST针对/connectors资源的请求,其中包含描述新连接器(称为inventory-connector)的 JSON 文档。
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" node01:8083/connectors/ -d '{ "name": "inventory-connector", "config": { "connector.class": "io.debezium.connector.sqlserver.SqlServerConnector", "database.hostname": "172.16.120.17", "database.port": "1433", "database.user": "SA", "database.password": "Dtstack@123", "database.dbname": "TestDB", "database.server.name": "fullfillment", "table.include.list": "dbo.mgmg", "database.history.kafka.bootstrap.servers": "node01:9092", "database.history.kafka.topic": "dbhistory.fullfillment" }
}'
(如果注册有问题 观察/opt/app/kafka/logs/connectDistributed.out)
多看下日志 日志中都可以 写到 如果注册成功,也没有kafka数据 麻烦看下日志WARN中过滤问题。[sourceTableId=DB2INST1.TESTTB, changeTableId=ASNCDC.CDC_DB2INST1_TESTTB
]
查看kafka中的数据
/opt/dtstack/DTBase/kafka/bin/kafka-topics.sh -list -zookeeper localhost:2181/kafka
/opt/dtstack/DTBase/kafka/bin/kafka-console-consumer.sh --bootstrap-server node01:9092 --from-beginning --topic fullfillment.dbo.mgmg



)



)

)








)
