什么是MoE?
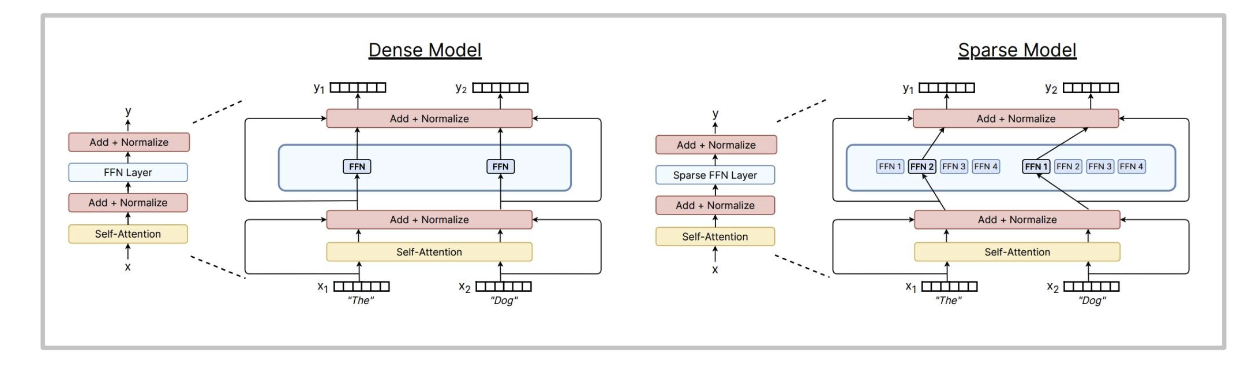
用(多个)大型前馈网络和一个选择器层取代大型前馈网络。你可以在不影响浮点运算次数的情况下增加专家数量。
MoE受欢迎的原因
相同的浮点运算次数,更多的参数表现更好
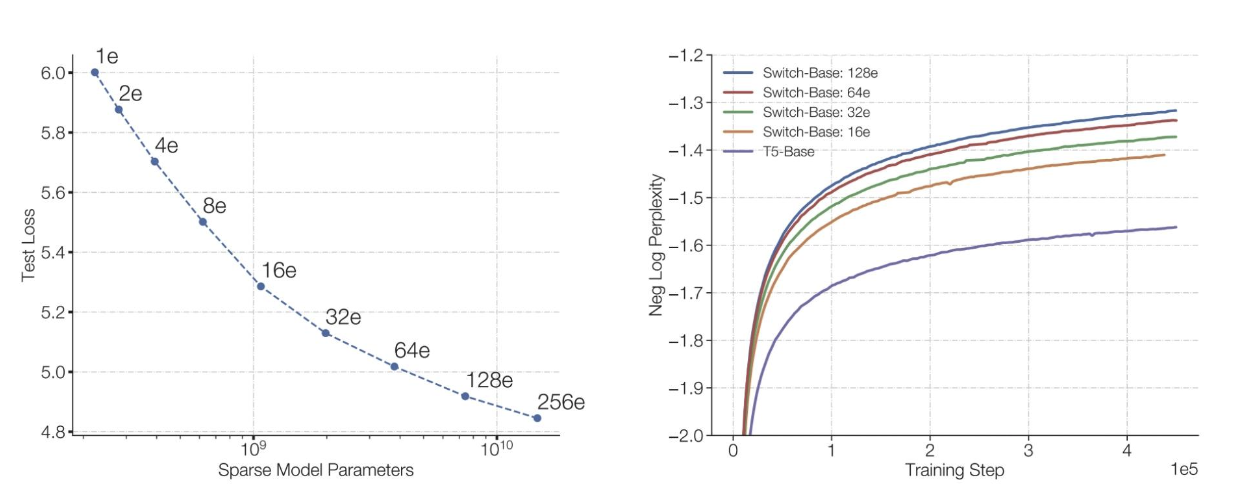
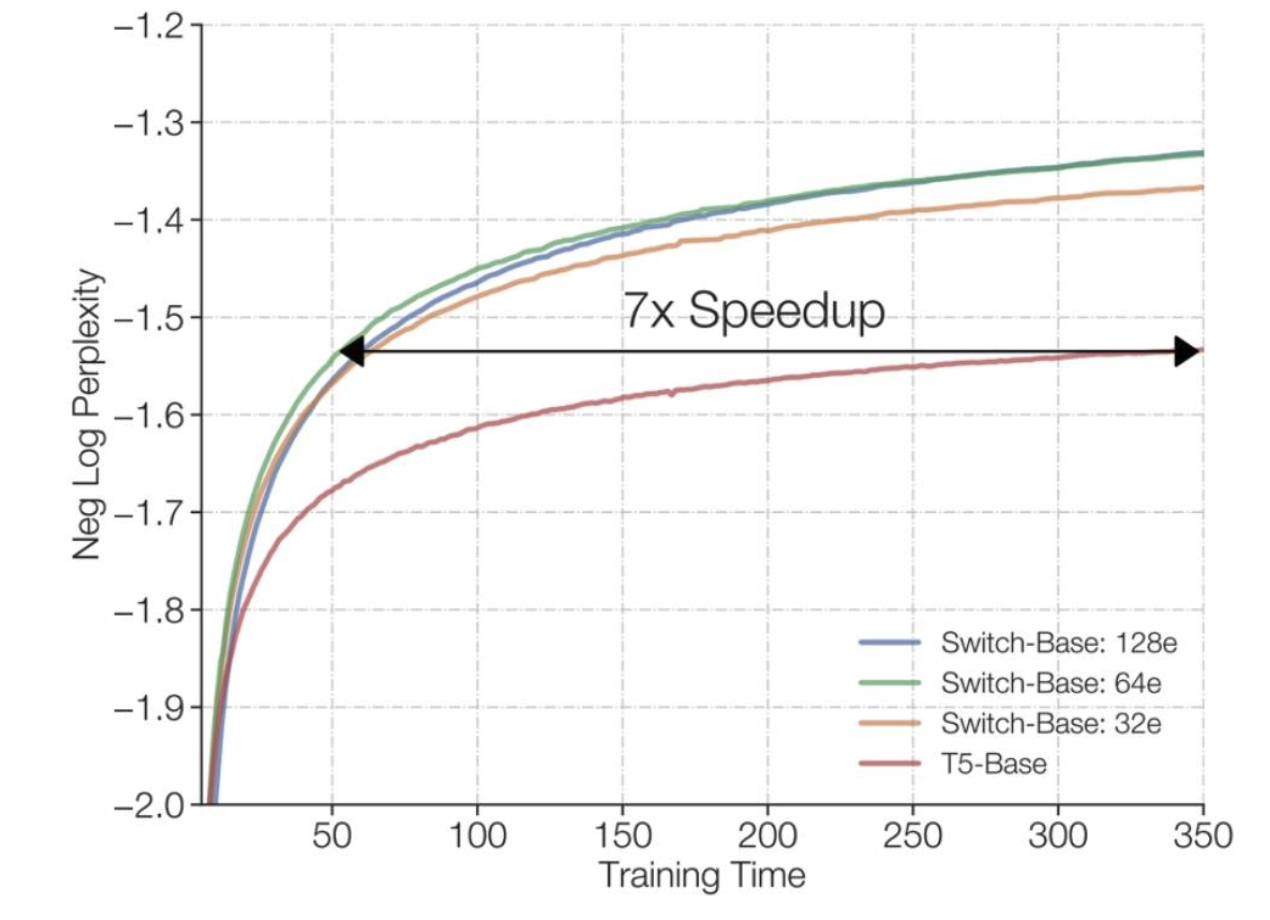
训练混合专家模型(MoEs)速度更快
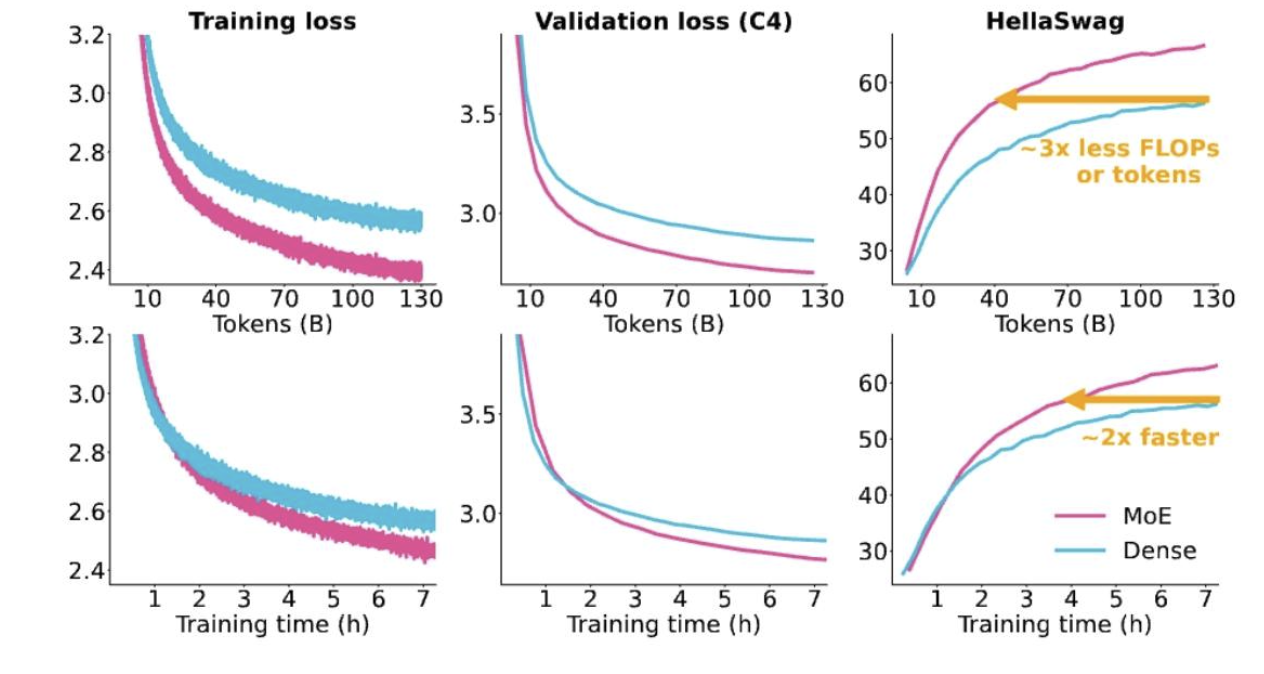
训练混合专家模型(MoEs)速度更快
与密集型等效模型相比极具竞争力
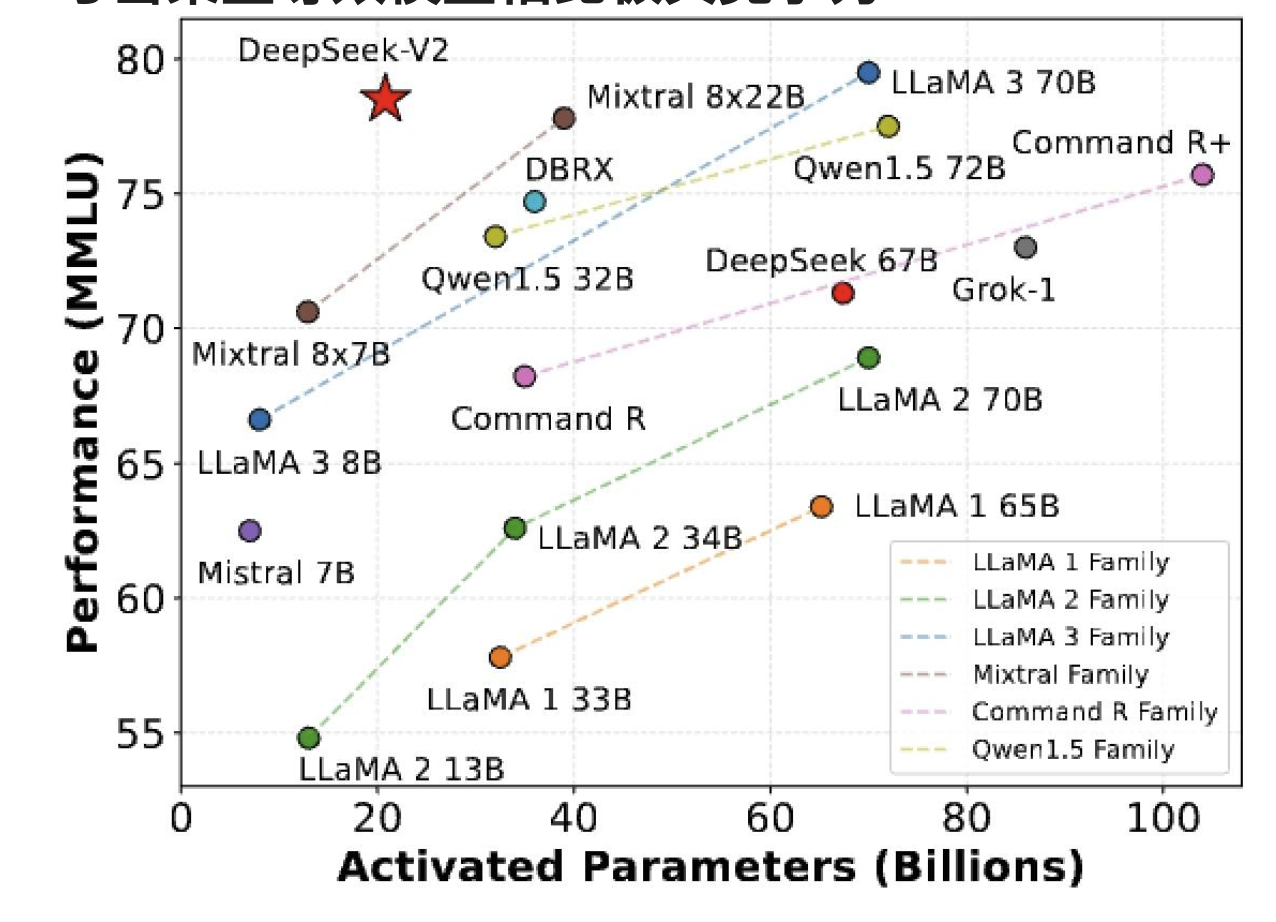
可并行到多个设备(专家并行性)
有多个前馈层,可以将每个专家放在不同的设备上
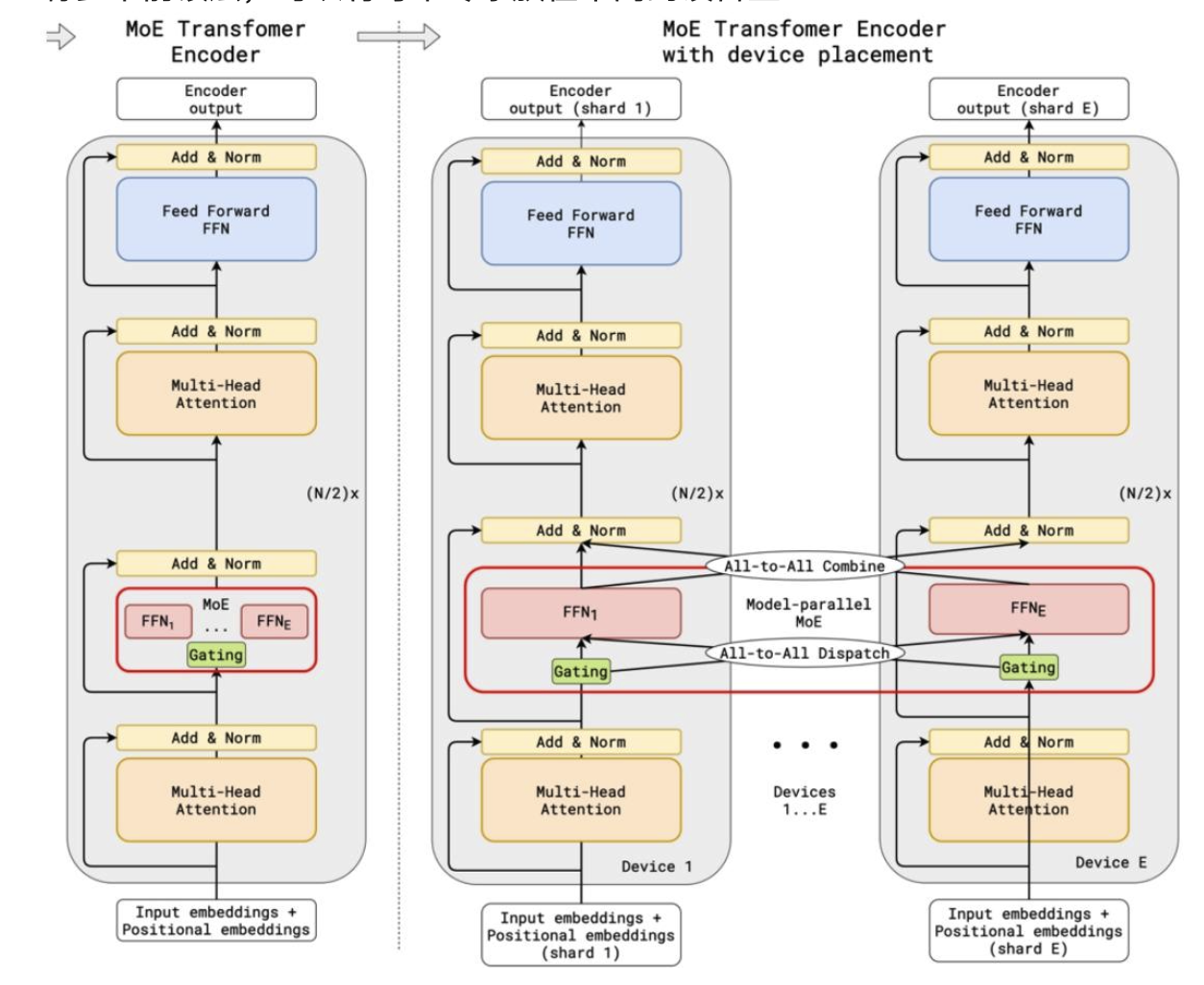
一些混合专家(MoE)的成果——来自西方
混合专家模型(MoE)大多是性能最高的开源模型,而且速度相当快
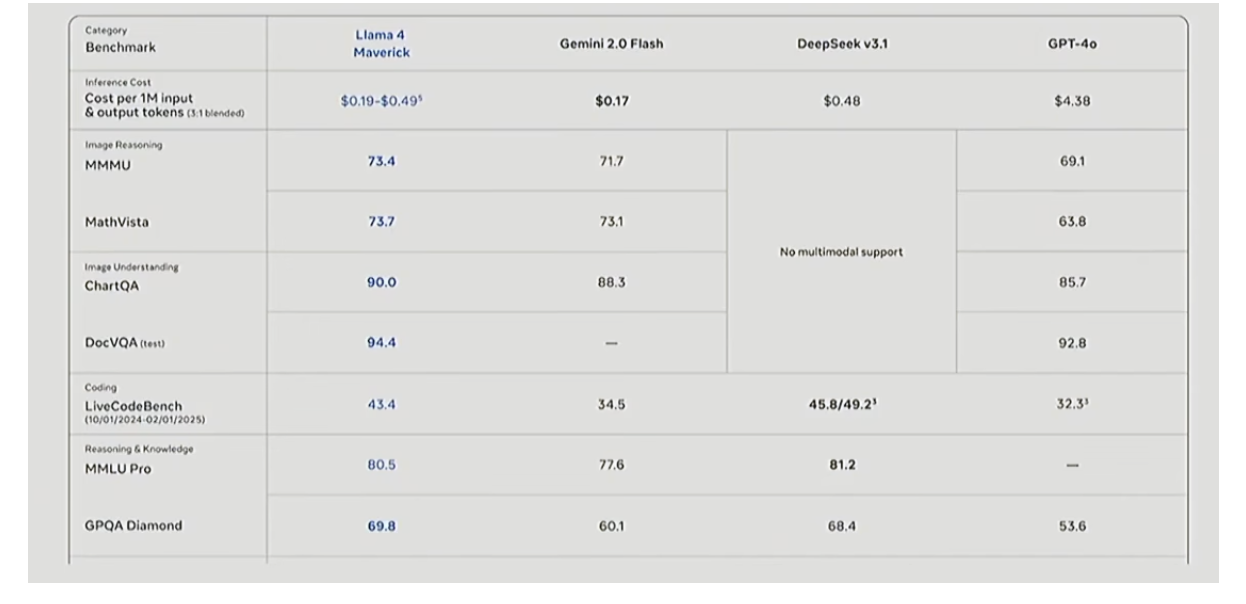
中国团队早期的混合专家(MoE)成果——通义千问
中国的大语言模型公司也在较小规模上做了不少混合专家(MoE)相关工作。
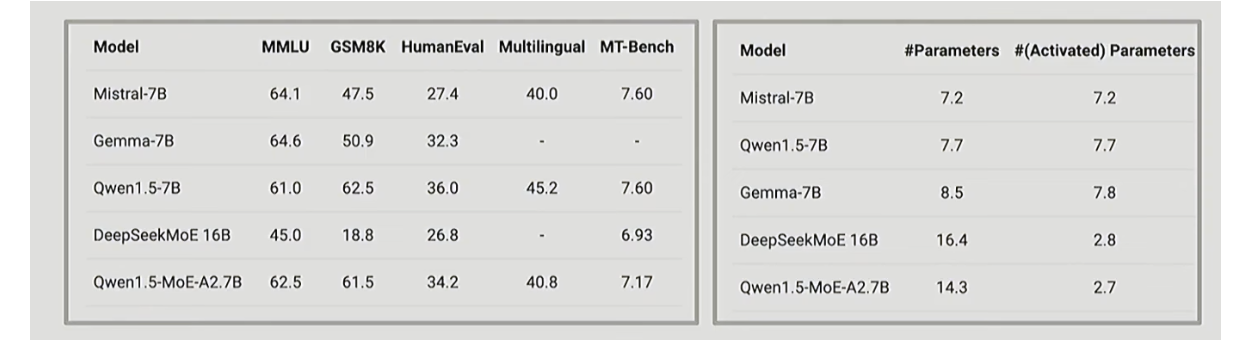
中国团队早期的混合专家模型(MoE)成果
最近也有一些关于混合专家模型(MoE)的不错的消融实验研究,表明它们总体表现良好。
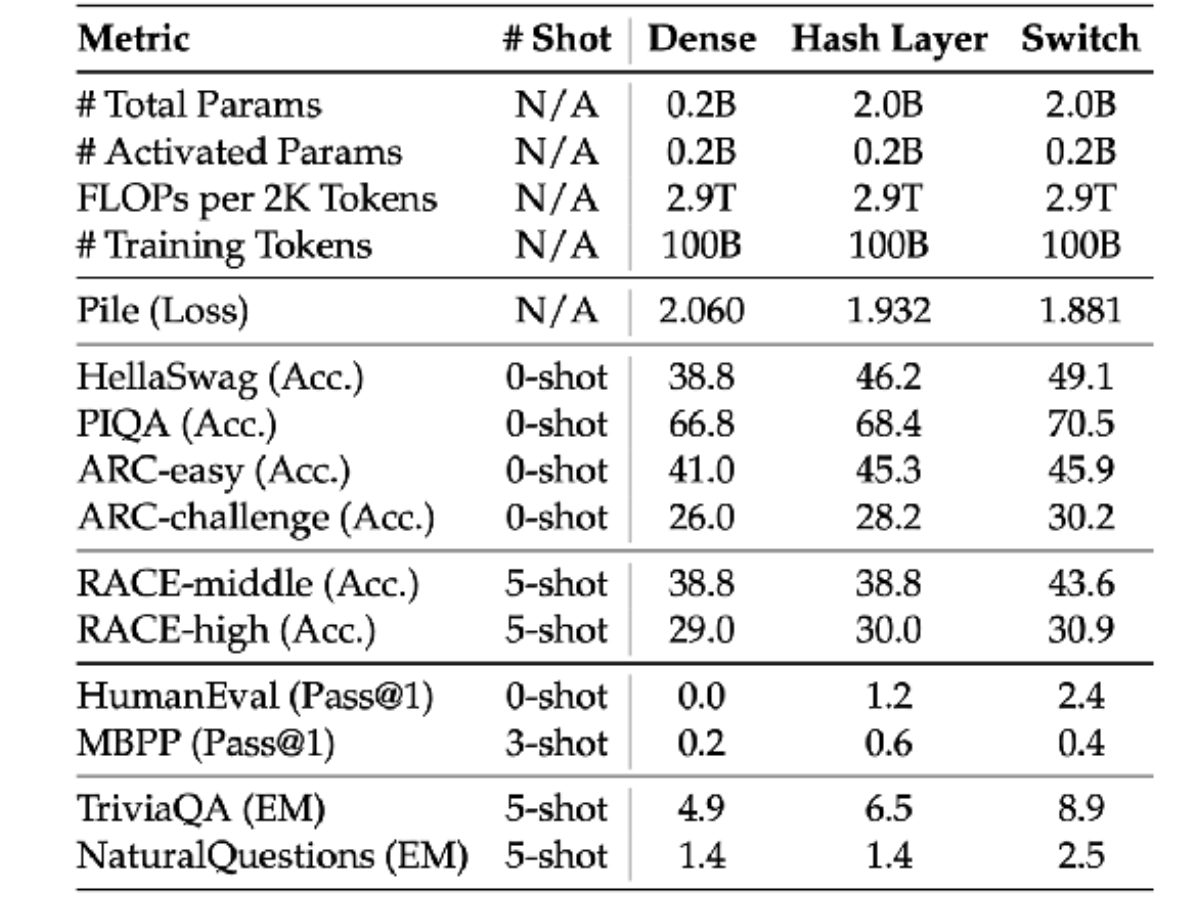
近期混合专家(MoE)结果 – DeepSeek v3
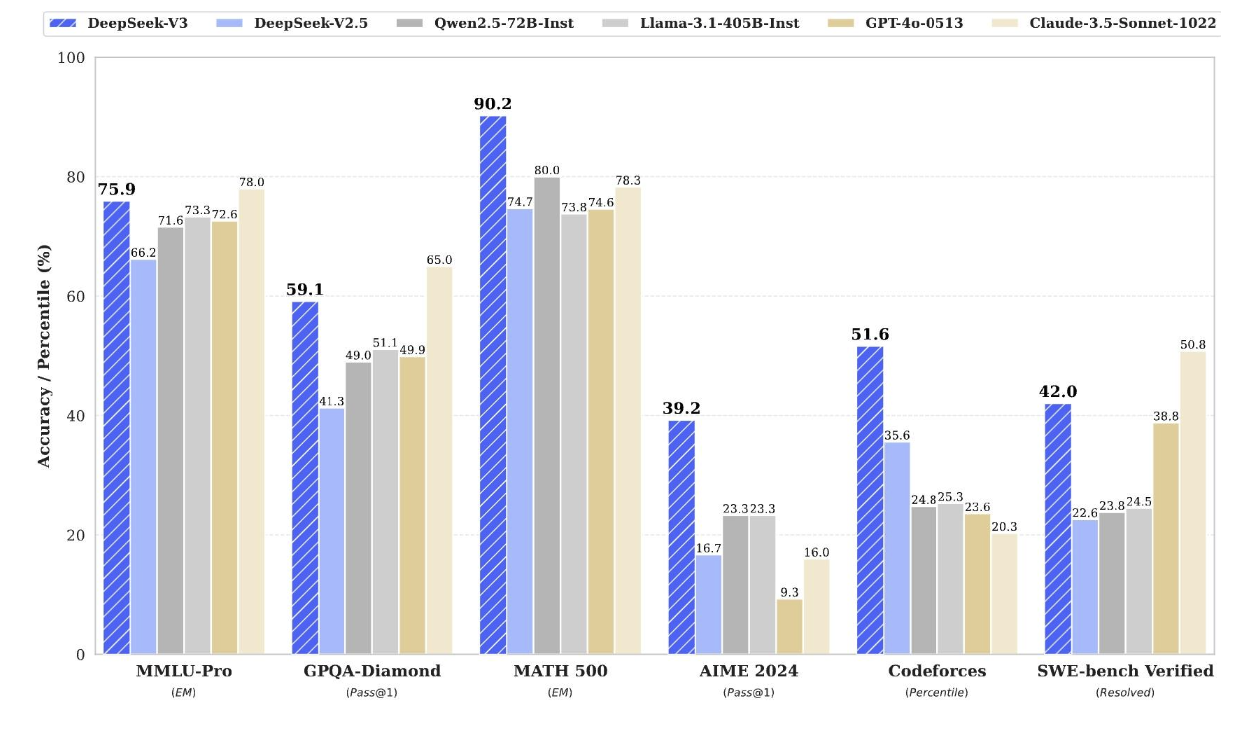
为什么混合专家模型(MoEs)没有更受欢迎呢?
基础设施复杂 / 多节点优势
训练目标在一定程度上是启发式的(且有时不稳定)
混合专家模型(MoE)通常是什么样子
典型做法:将多层感知器(MLP)替换为专家混合(MoE)层
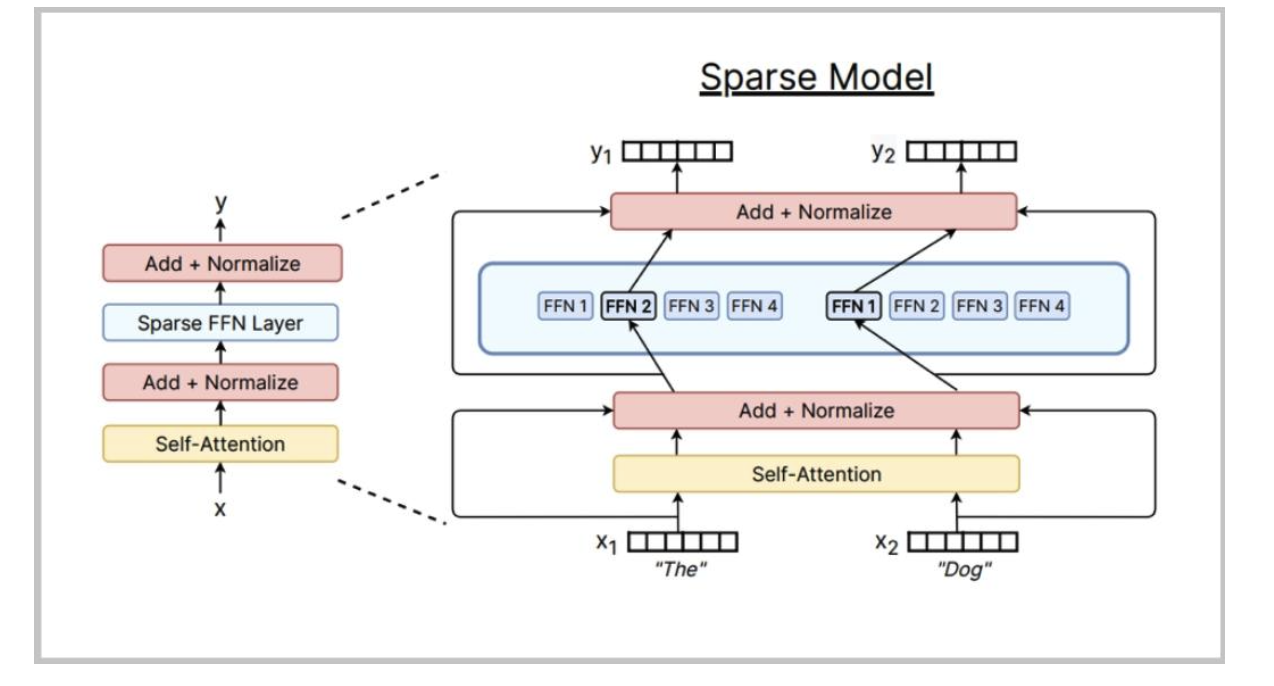
不太常见的做法:将MoE用于注意力头(不稳定)
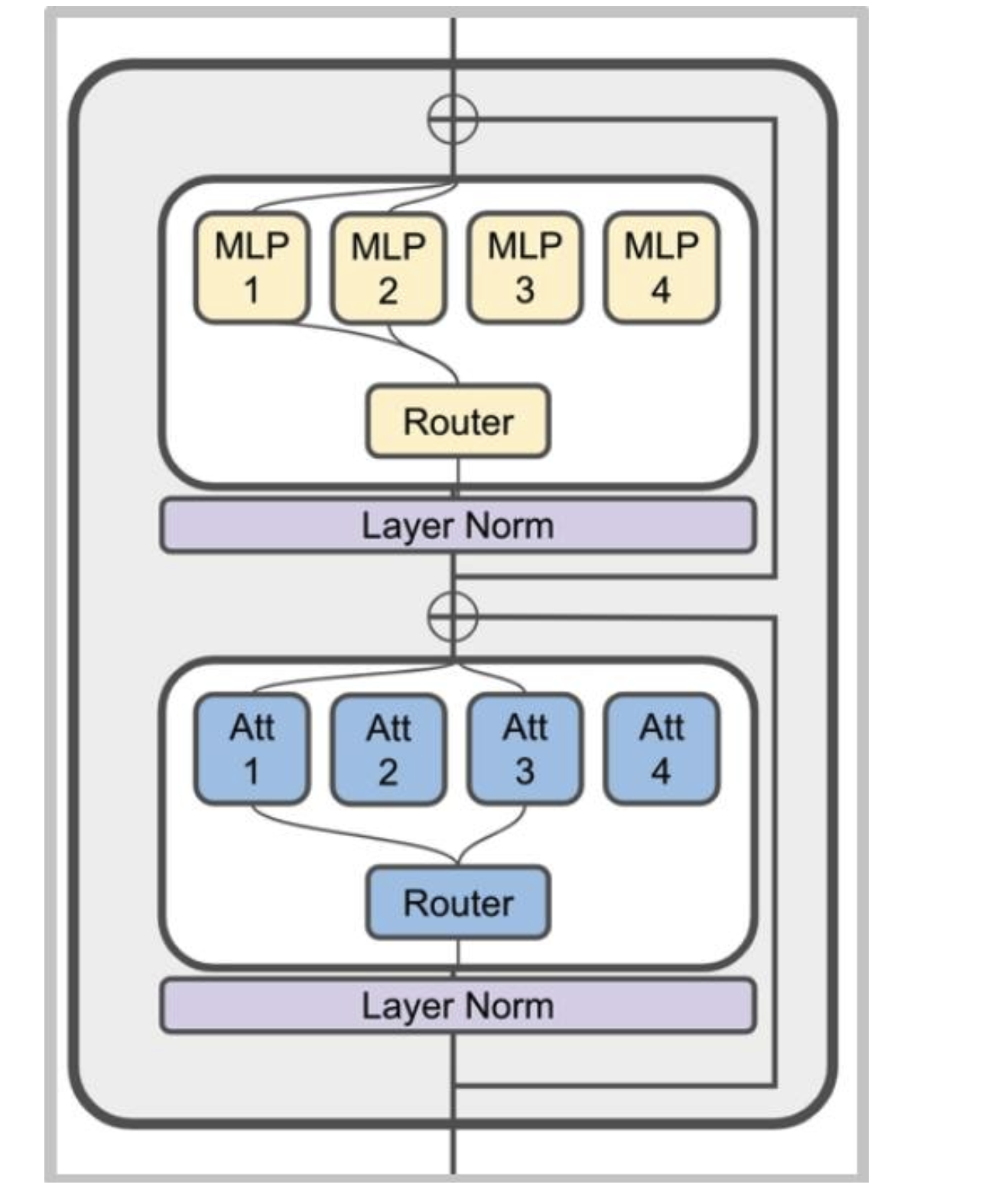
MoE的变种
路由函数
专家规模
训练目标
路由功能
概述
许多路由算法归根结底都是“选择前 k 个”
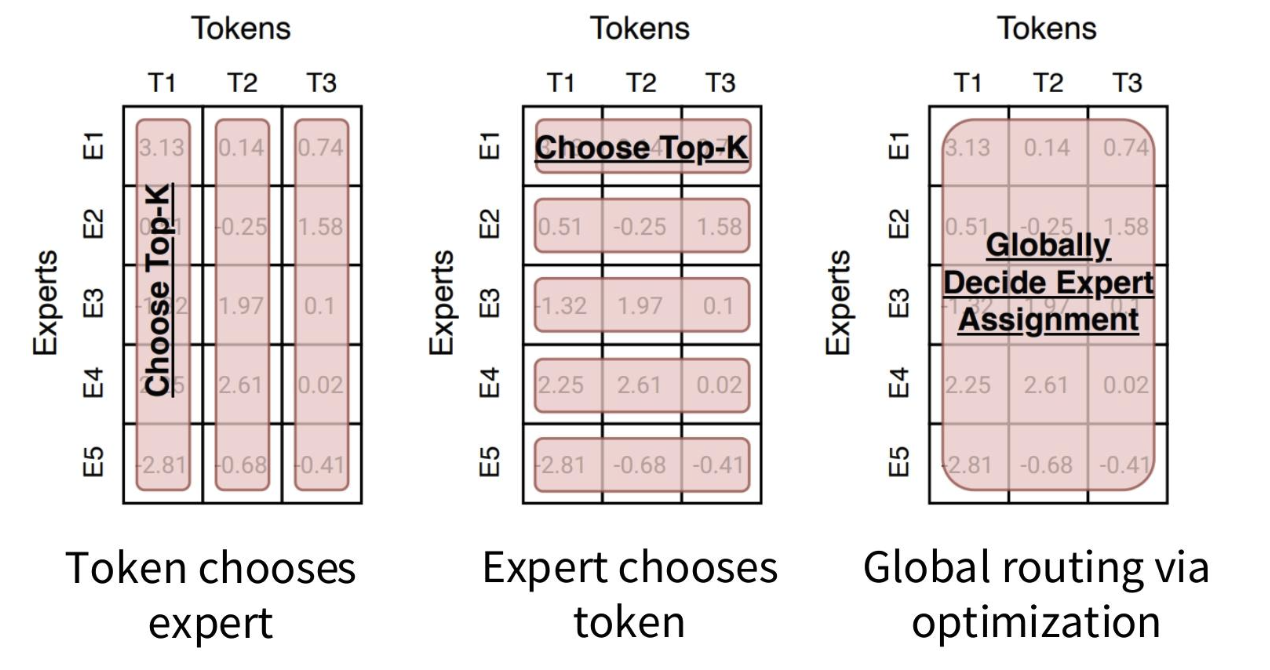
路由类型
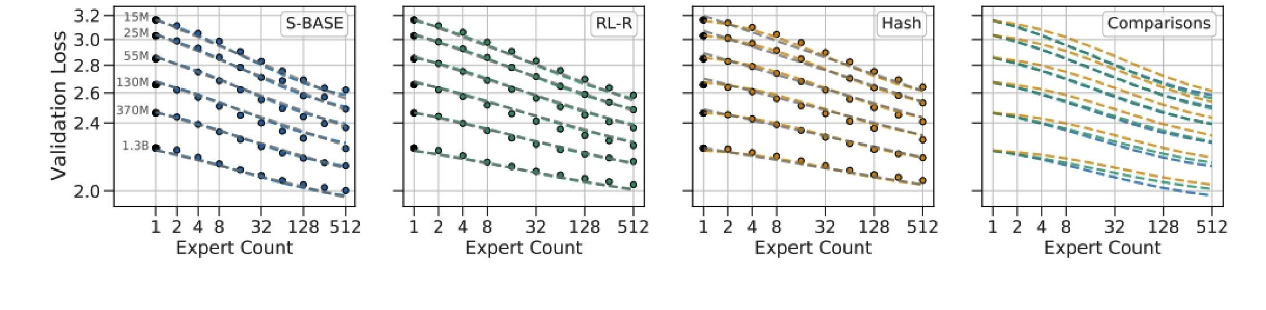
几乎所有的混合专家模型(MoE)都采用标准的“令牌选择前 k 个”路由方式。最近的一些消融实验
常见路由变体详解
Top-k
残差流输入x
x将进入路由器中,路由器类似于注意力操作(存在线性内积+softmax)
然后选出活跃度最高的前 K 名专家,并对这些输出进行门控
根据具体情况,可能会根据此路由器权重对输出进行加权,然后,将只输出加权平均值或综合
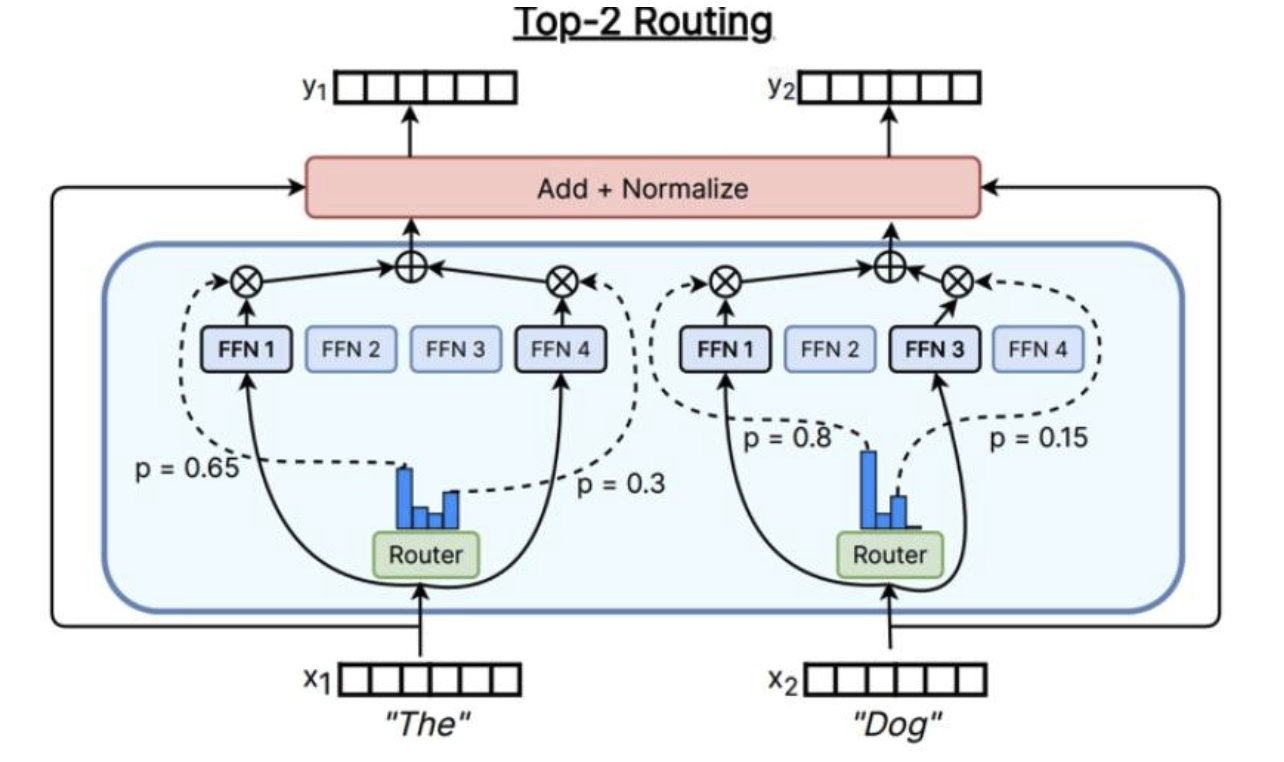
用于大多数混合专家模型(MoE)
Switch Transformer(k=1)
Gshard ((k=2)) 、Grok(2个)、Mixtral(2个)、通义千问(4个)、DBRX(4个)
Hashing
只需要使用哈希函数,就可以将x映射到专家上,即使没有处理语义信息,依旧可以从基于散列的MoE中得到收益
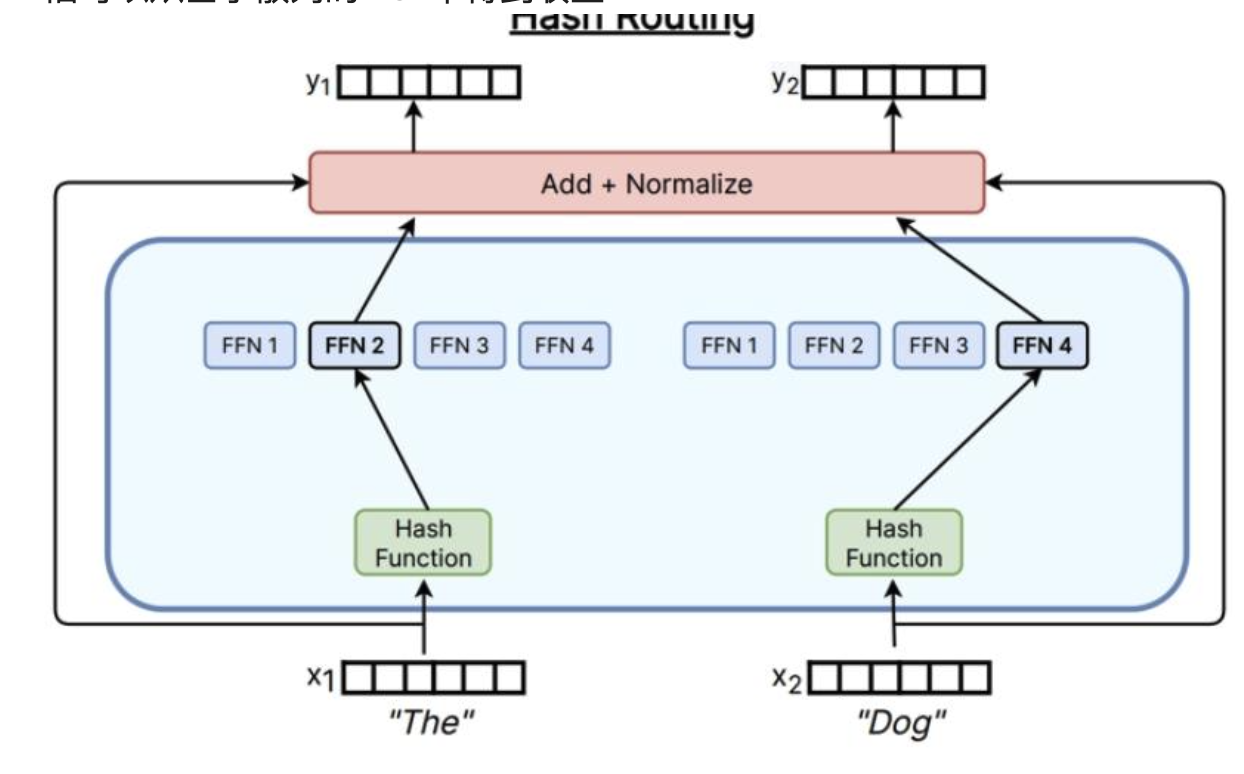
其他路由方法
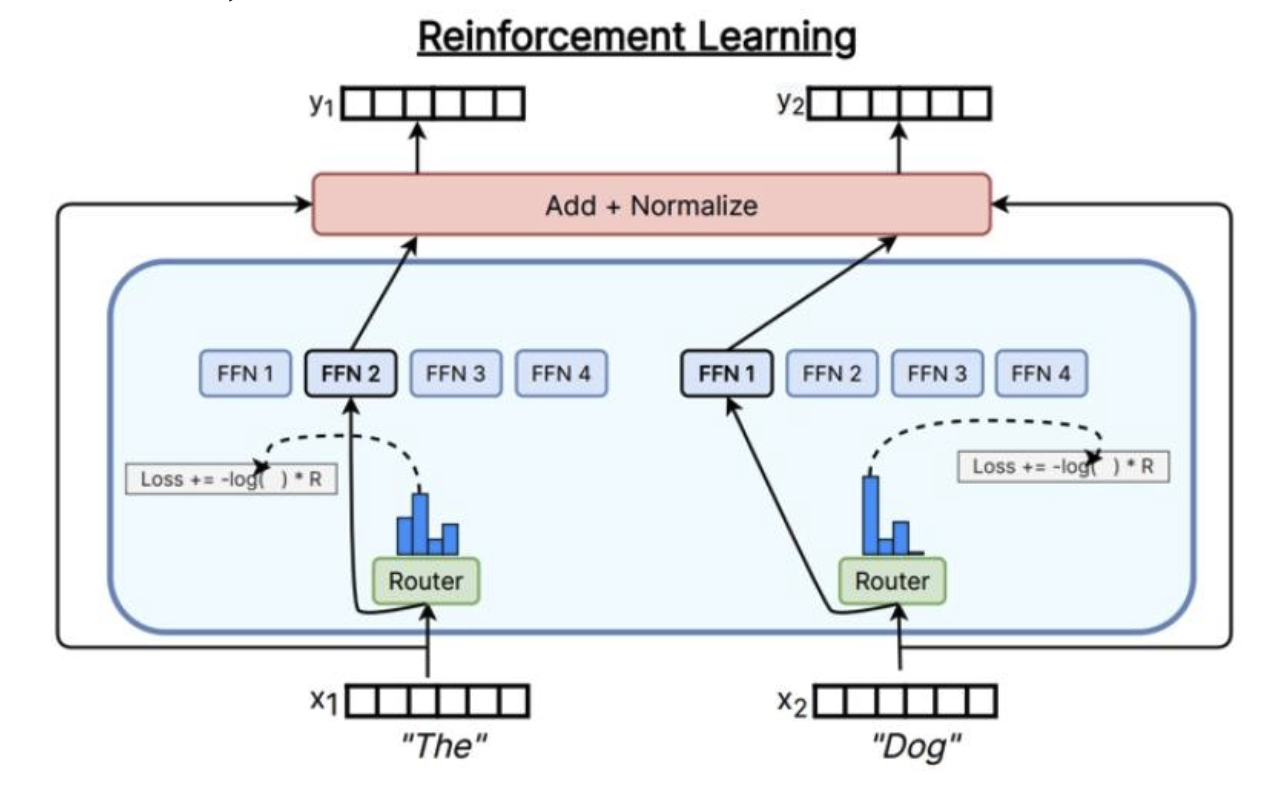
通过强化学习学习路由
计算成本高,大于好处
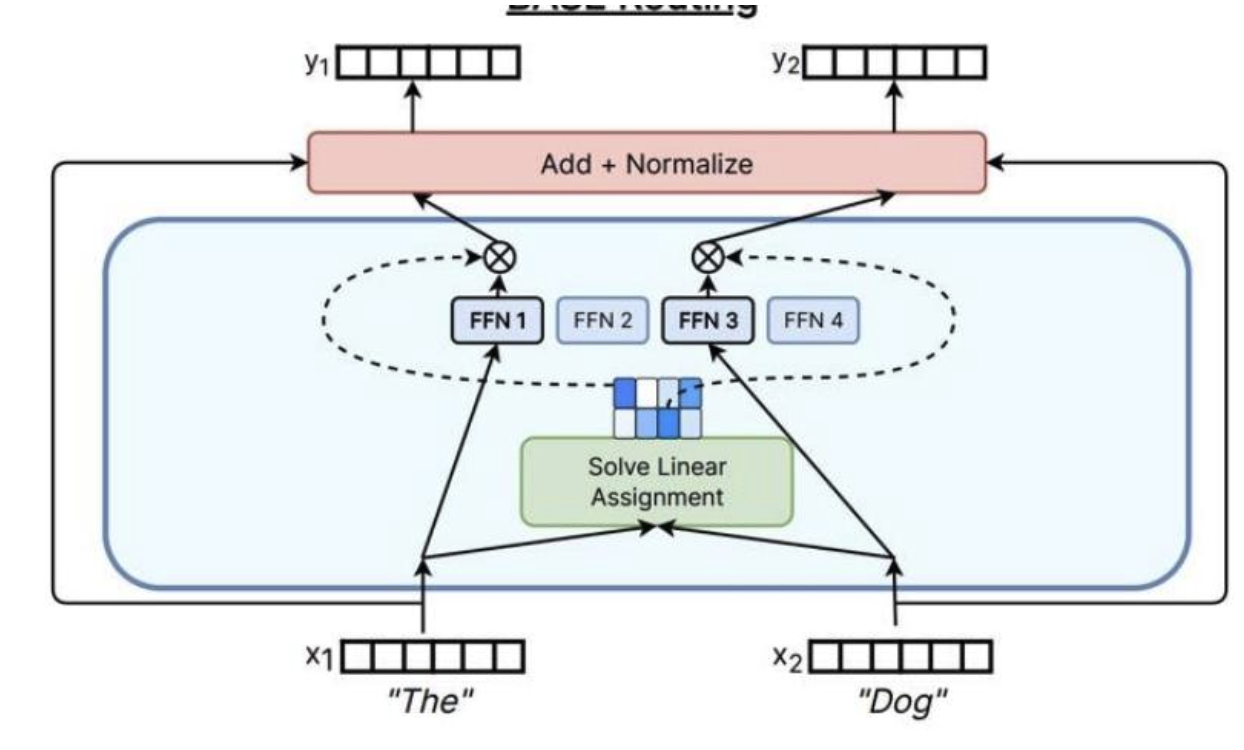
解决一个匹配问题
Top-K路由详解

-
计算专家权重((s_{i,t})):对于第l层的输入特征(utl)(u_{t}^{l})(utl),通过与专家i的门控向量(eile_{i}^{l}eil)进行内积运算,再经过 Softmax 函数归一化,得到该输入分配给专家i的权重(si,ts_{i,t}si,t),即(si,t=Softmaxi(utlTeil)s_{i, t}=Softmax_{i}\left(u_{t}^{l^{T}} e_{i}^{l}\right)si,t=Softmaxi(utlTeil))。
-
筛选 Top-k 专家((KaTeX parse error: Expected '}', got 'EOF' at end of input: g_{i,t})):从所有专家的权重(si,ts_{i,t}si,t)中选取数值最高的前k个,对于这k个专家,保留其权重作为门控系数(gi,tg_{i,t}gi,t);而其他未被选中的专家,门控系数设为 0,即(gi,t={si,t,si,t∈Topk({sj,t∣1≤j≤N},K),0,otherwise,g_{i, t}= \begin{cases}s_{i, t}, & s_{i, t} \in Topk\left(\left\{s_{j, t} | 1 \leq j \leq N\right\}, K\right), \\ 0, & otherwise, \end{cases}gi,t={si,t,0,si,t∈Topk({sj,t∣1≤j≤N},K),otherwise,)。
-
计算输出特征((htlh_{t}^{l}htl)):将筛选出的 Top-k 专家对输入特征(utlu_{t}^{l}utl)的处理结果(即(FFNi(utl)FFN_{i}\left(u_{t}^{l}\right)FFNi(utl)))与各自的门控系数(gi,tg_{i,t}gi,t)相乘后求和,再加上原始输入特征(utlu_{t}^{l}utl),得到该层的输出特征(htlh_{t}^{l}htl),即(htl=∑i=1N(gi,tFFNi(utl))+utlh_{t}^{l}=\sum_{i=1}^{N}\left(g_{i, t} FFN_{i}\left(u_{t}^{l}\right)\right)+u_{t}^{l}htl=∑i=1N(gi,tFFNi(utl))+utl)。
如果这里只使用softmax而不是用TOP-k,那么就失去了模型本身的意义,使得每次都会激活所有模型,违背了我们在训练和推理中都有少量稀疏的活跃模型的目的
近期由DeepSeek和其他中国大语言模型带来的变化
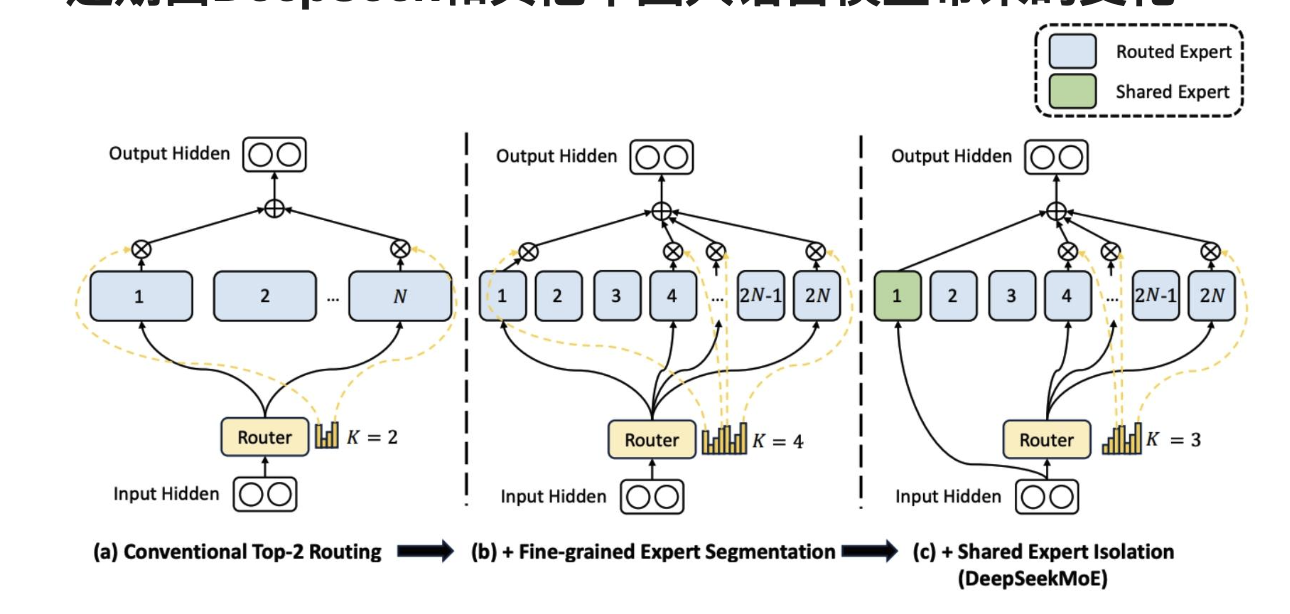
规模较小、数量较多的专家 + 一些始终在线的共享专家。
DeepSeek论文中的各种消融实验
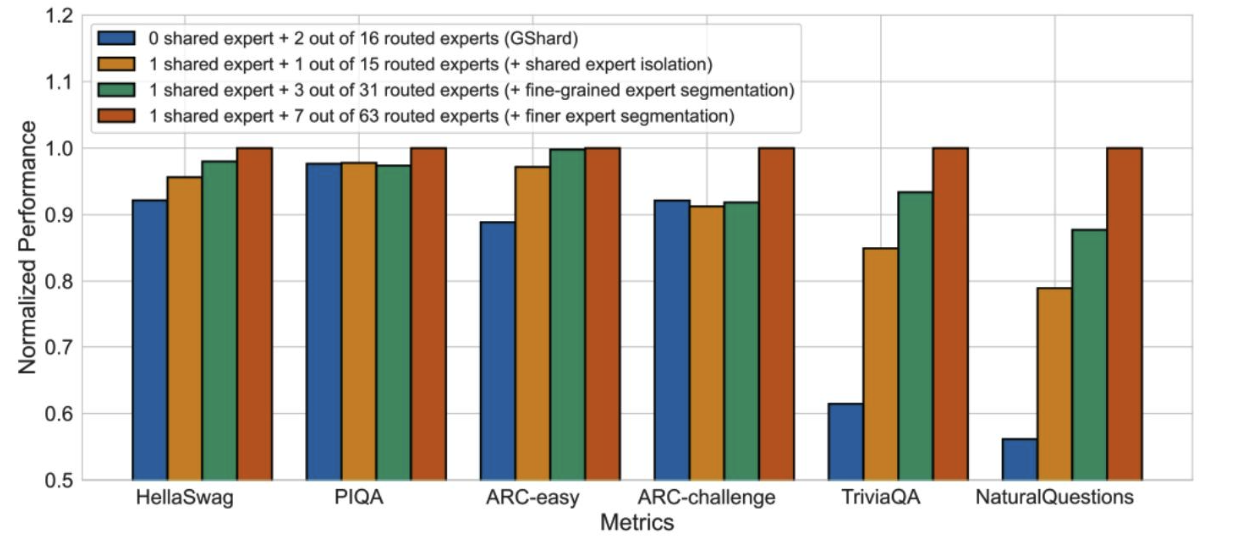
更多的专家、共享专家似乎总体上都有帮助
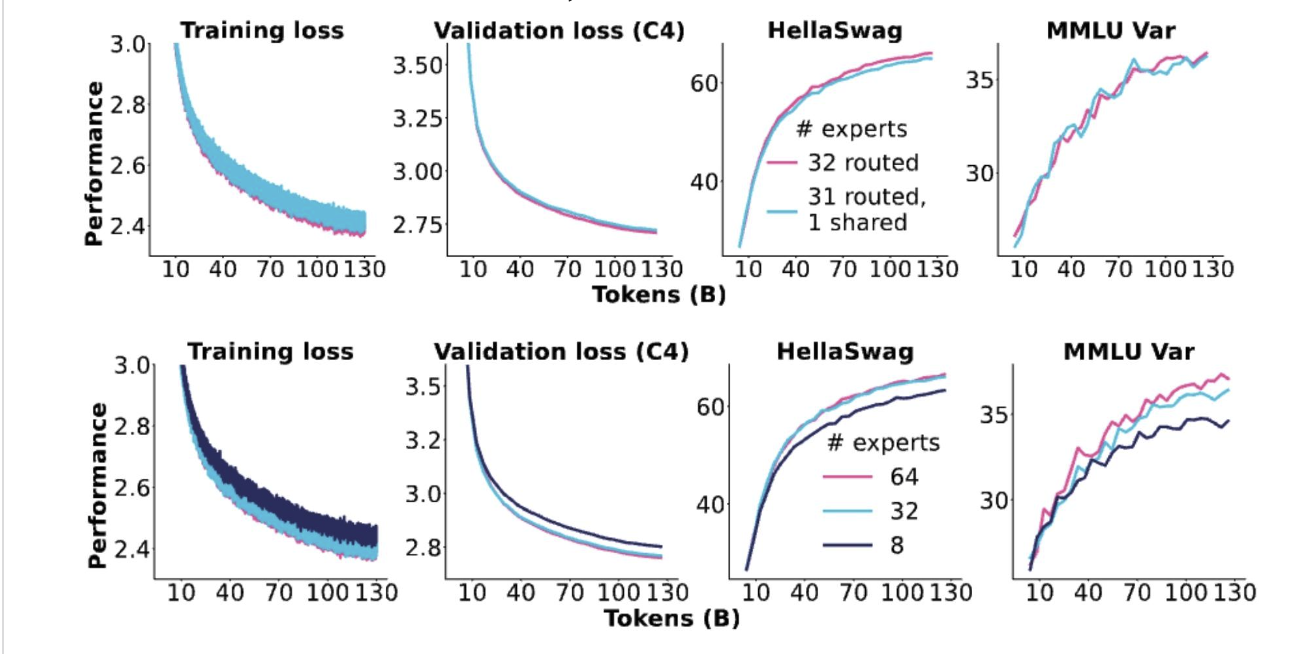
OlMoE的消融实验
效果都是来自细粒度专家的增益,而没有来自共享专家的增益。
我们如何训练混合专家模型(MoEs)?
主要挑战:为了提高训练效率,我们需要稀疏性……
但稀疏门控决策是不可微的!
(具体来说,稀疏门控通过路由机制(如 Top-K 路由)选择部分专家,未被选中的专家对应的门控系数会被设为 0。这种 “非此即彼” 的离散选择过程(要么选中专家并保留其权重,要么不选中并置零)不存在连续的梯度变化,而深度学习模型的训练依赖反向传播算法,需要计算参数关于损失函数的梯度以更新参数。因此,稀疏门控的离散性导致无法直接通过常规的反向传播对门控相关参数进行优化,给模型训练带来了困难)
解决方案?
- 强化学习优化门控策略
- 随机扰动
- 启发式“平衡”损失。
多专家模型的强化学习
通过REINFORCE算法的强化学习确实有效,但并没有好到能明显胜出。
强化学习是“正确的解决方案”,但梯度方差和复杂性意味着它并未得到广泛应用
随机扰动
出自沙泽尔等人2017年的研究——路由决策是随机的,伴有高斯扰动。
- 这自然会产生更具鲁棒性的专家。
- softmax 意味着模型学习如何对 K 个专家进行排序

启发式平衡损失
另一个关键问题——系统效率要求我们均衡地使用专家。
辅助损失是向量 f(各专家的 token 分配比例)与 P(各专家的路由概率比例)的缩放点积。通过最小化该损失,可促使模型让 token 实际分配比例((fif_ifi))与路由概率分配比例((PiP_iPi))更接近,从而平衡各专家的负载

深度求索(v1-2)示例
每个专家平衡-与Switch Transformer相同

每个设备平衡-按设备汇总
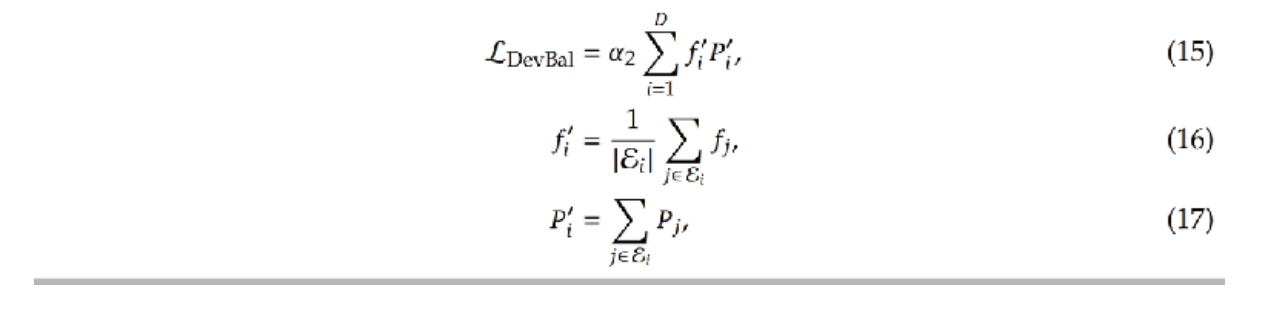
DeepSeek v3变体——专家级偏差
设置每个专家的偏差(使其更有可能获得词元)并使用在线学习 gi,t′={si,t,si,t+bi∈Topk({sj,t+bj∣1≤j≤Nr},Kr),0,otherwise.g_{i, t}'= \begin{cases}s_{i, t}, & s_{i, t}+b_{i} \in Topk\left(\left\{s_{j, t}+b_{j} | 1 \leq j \leq N_{r}\right\}, K_{r}\right), \\ 0, & otherwise. \end{cases}gi,t′={si,t,0,si,t+bi∈Topk({sj,t+bj∣1≤j≤Nr},Kr),otherwise.
他们将此称为“无辅助损失平衡”
- (bib_ibi) 是专家 i 的偏置项,通过在线学习调整:若某专家被分配的 token 过少,(bib_ibi) 会增大,使其更易被选入 Top-K 专家;若某专家负载过重,(bib_ibi) 会减小,降低其被选中的概率;
去除负载均衡损失会发生什么?
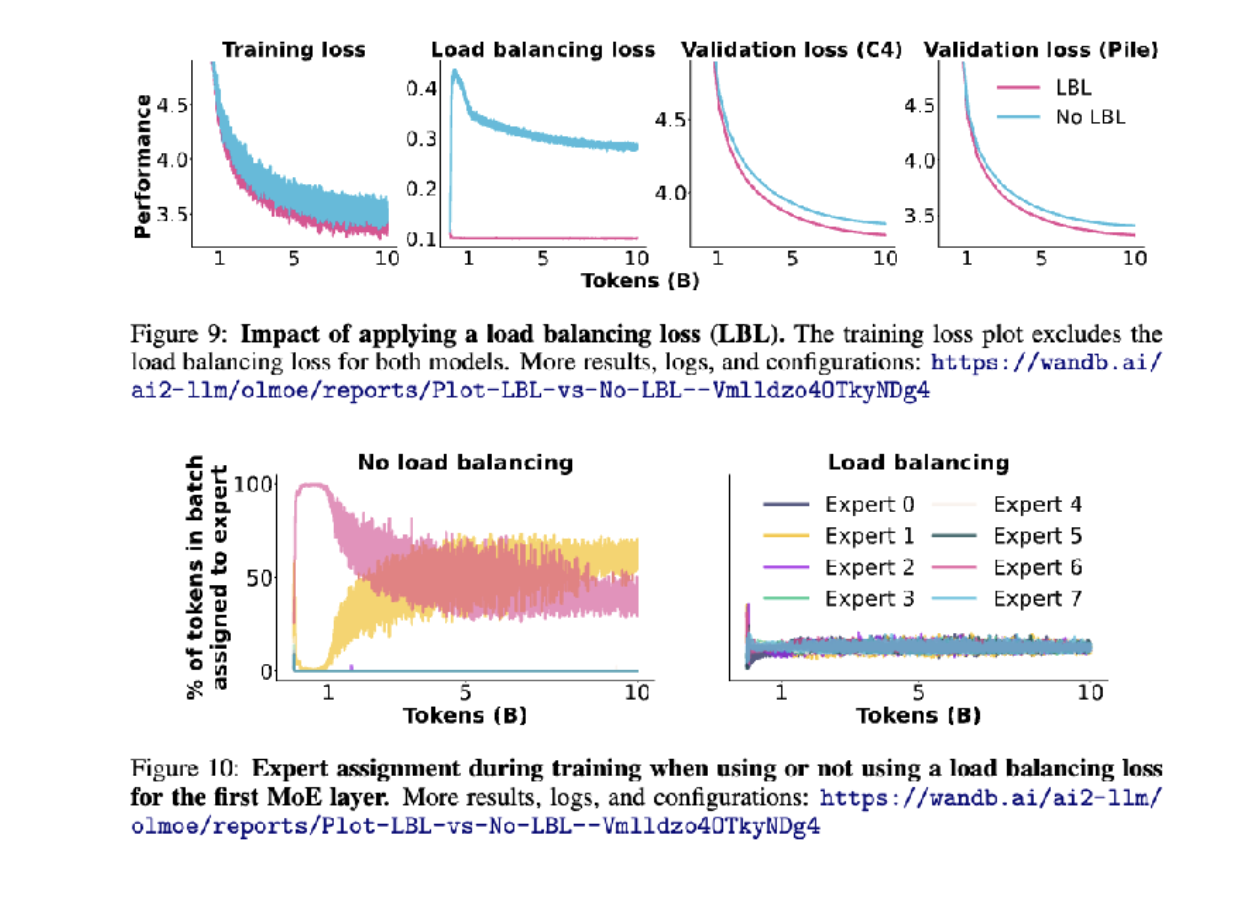
如果不做负载均衡,除了粉色和黄色的模型,其他模型都被浪费了
从系统层面训练MoEs
混合专家模型(MoEs)的并行性良好——每个前馈神经网络(FFN)都可以适配一个设备
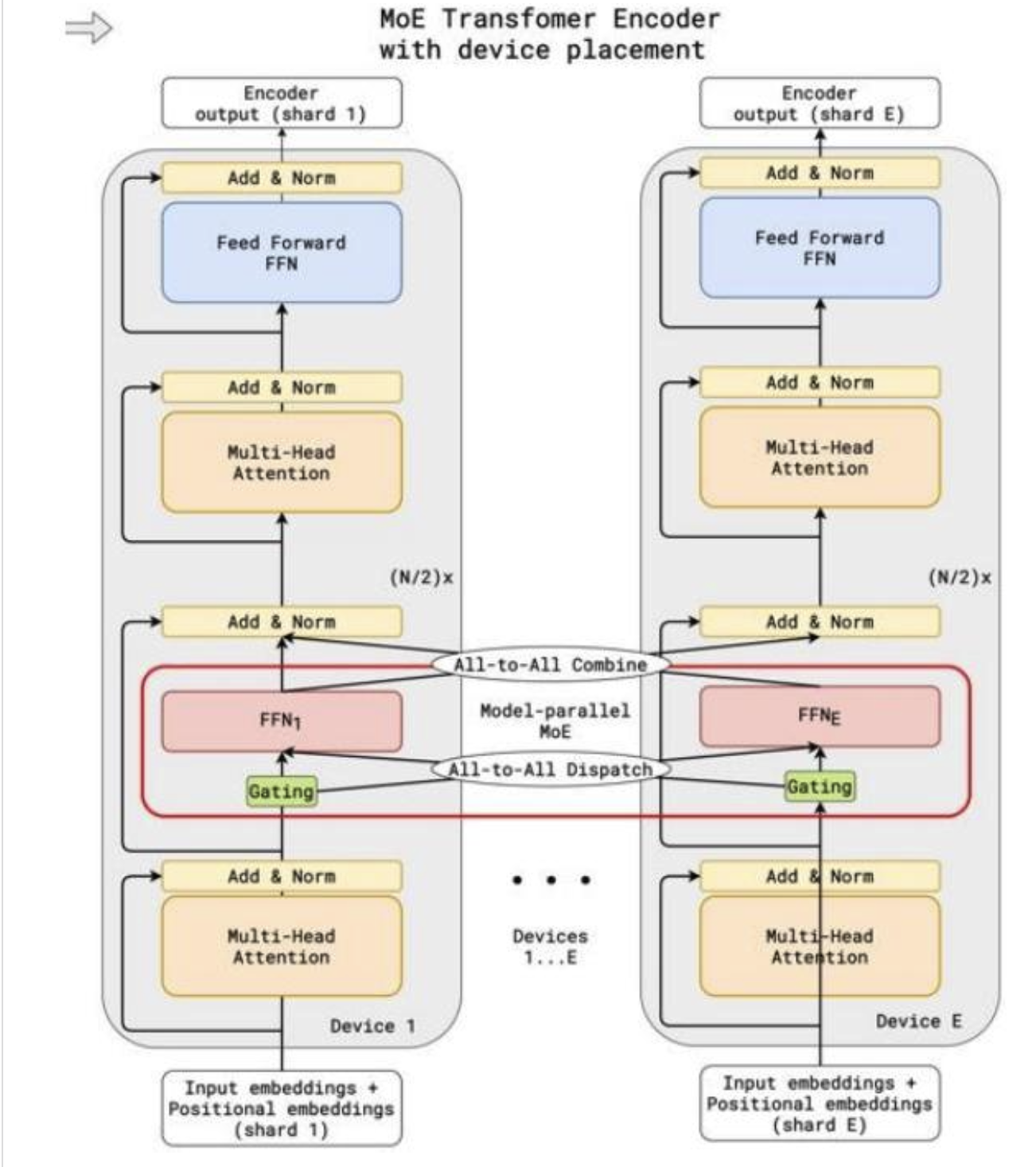
混合专家(MoE)路由允许并行计算,但也存在一些复杂性
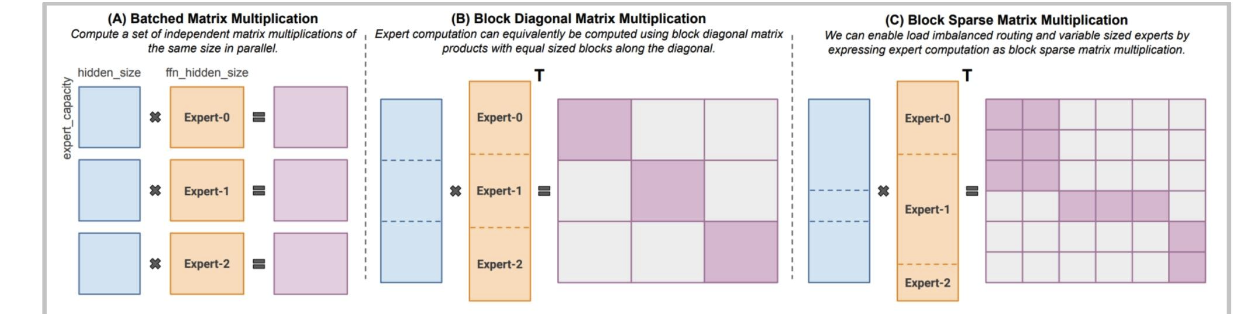
像MegaBlocks这样的现代库(在许多开源混合专家模型中使用)采用了更智能的稀疏矩阵乘法运算。
有趣的附带问题——混合专家(MoE)模型的随机性
有人猜测GPT-4的随机性是由于混合专家(MoE)造成的。
为什么混合专家模型(MoE)会有额外的随机性?
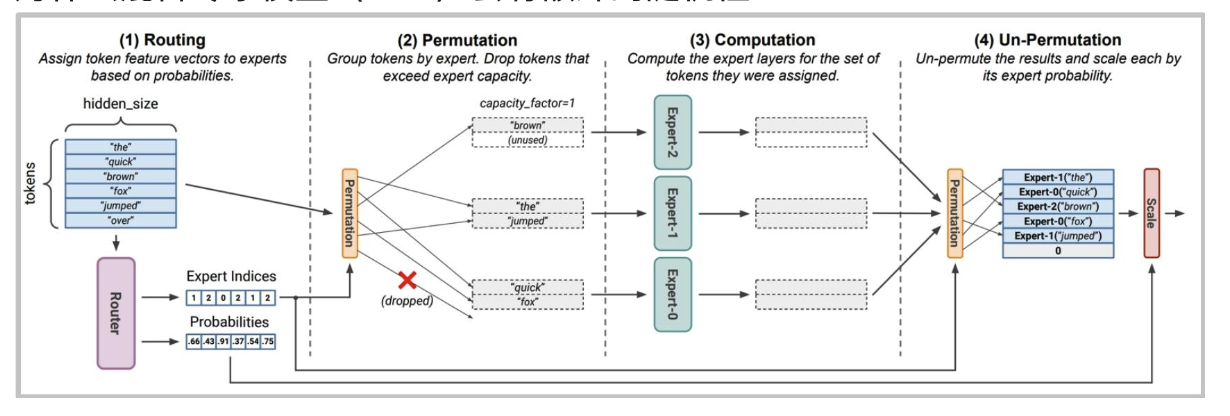
从路由中丢弃令牌是在批次级别进行的——这意味着其他人的查询可能会丢弃你的令牌!
混合专家模型(MoE)的问题 - 稳定性

解决方案:仅对专家路由器使用Float 32(有时带有辅助z损失) Lz(x)=1B∑i=1B(log∑j=1Nexj(i))2(5)L_{z}(x)=\frac{1}{B} \sum_{i=1}^{B}\left(log \sum_{j=1}^{N} e^{x_{j}^{(i)}}\right)^{2} (5)Lz(x)=B1∑i=1B(log∑j=1Nexj(i))2(5)
路由器的Z损失稳定性
当我们去掉z损失时会发生什么?
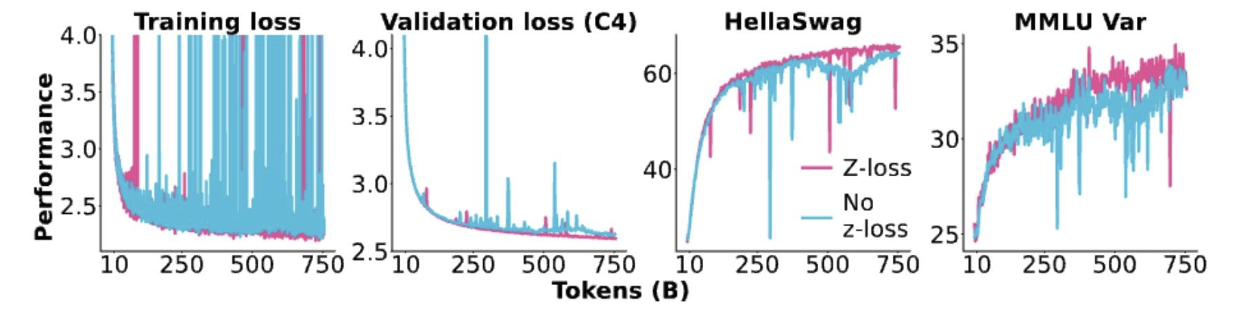
混合专家模型(MoE)的问题——微调
稀疏混合专家模型(Sparse MoEs)在较小的微调数据上可能会过拟合
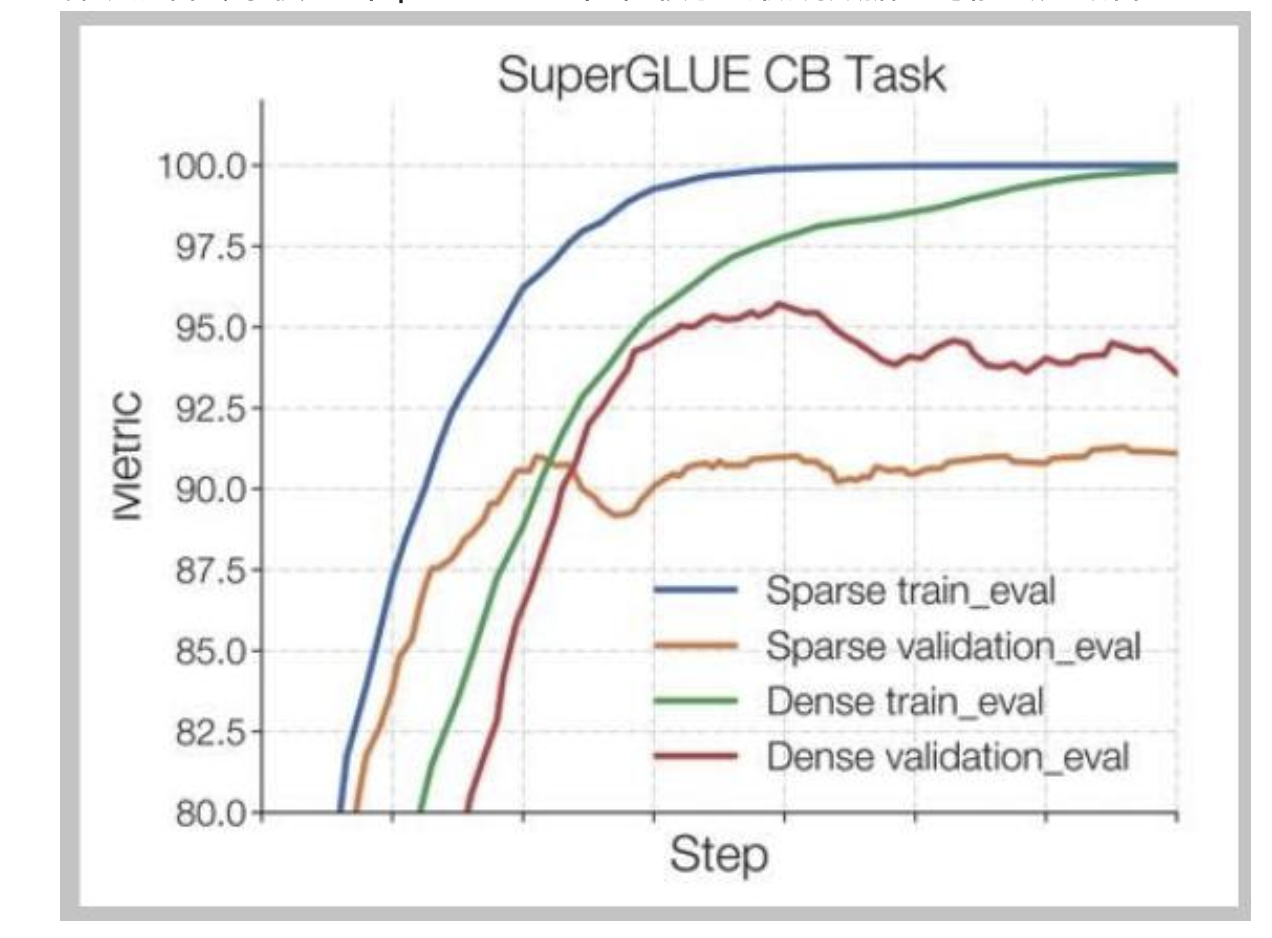
佐夫等人的解决方案——微调非混合专家(MoE)多层感知器(MLP)
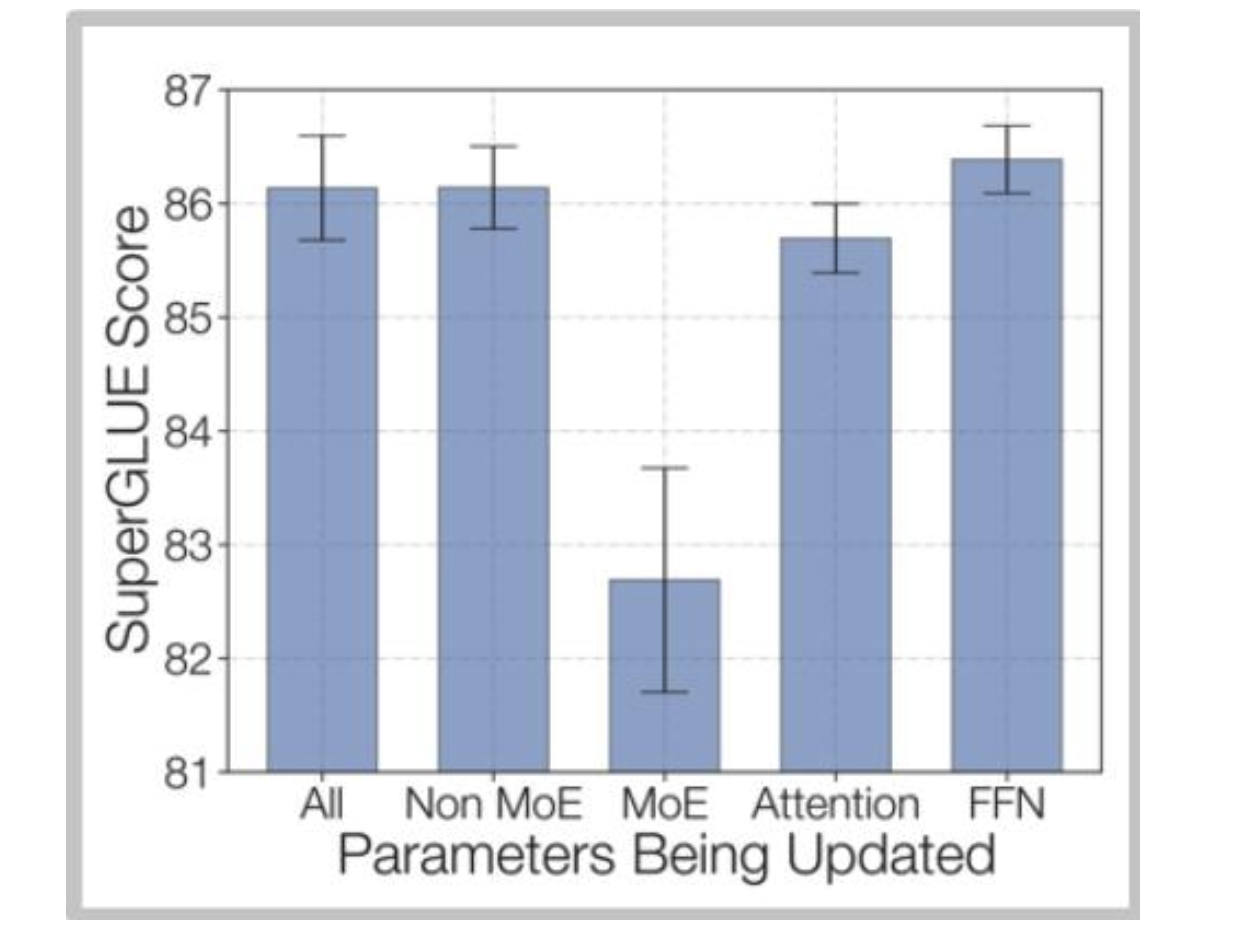
DeepSeek解决方案 - 使用大量数据140万个监督微调样本
训练数据:为了训练聊天模型,我们使用内部精心整理的数据集进行有监督微调(SFT),该数据集包含140万个训练示例。此数据集涵盖广泛的类别,包括数学、代码、写作、问答、推理、摘要等。我们的有监督微调训练数据大多为英文和中文,这使得聊天模型用途广泛,可应用于双语场景。
其他训练方法 - 升级循环利用
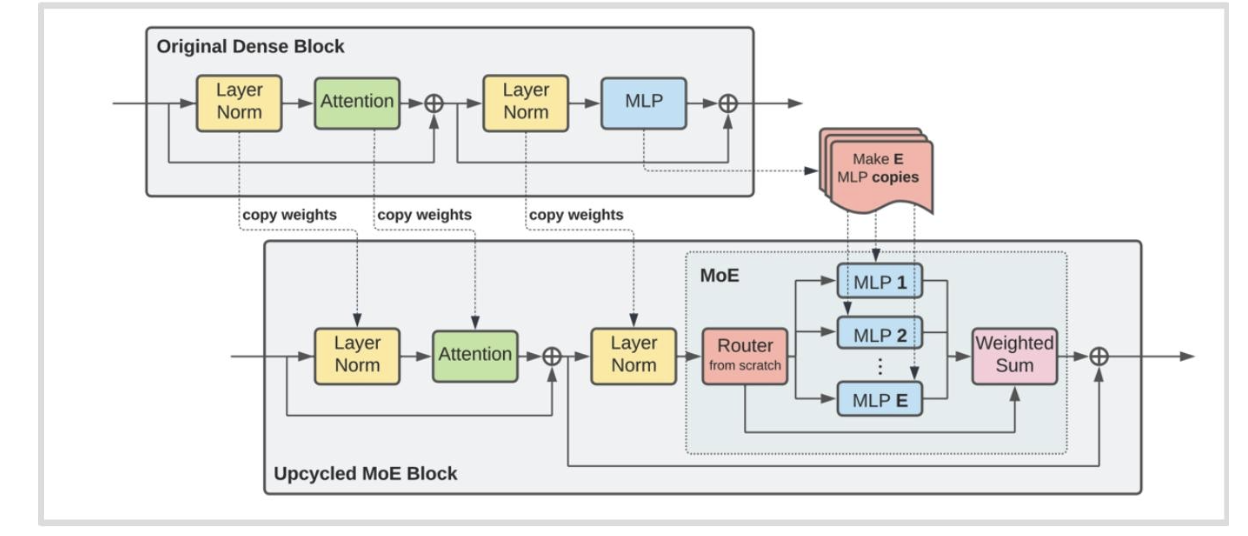
我们可以使用预训练的大语言模型(LM)来初始化一个混合专家模型(MoE)吗?
- 原始密集块中的多层感知机(MLP)模块被复制了 E 份,形成了混合专家(MoE)模块中的多个多层感知机。
- 新引入了路由模块(Router from scratch)来处理输入并将其分配给不同的多层感知机。
- 最后通过加权求和(Weighted Sum)操作将多个多层感知机的输出合并。
混合专家模型(MoE)总结
混合专家模型(MoEs)利用了稀疏性——并非所有输入都需要完整的模型。
离散路由很难,但前 k 启发式算法似乎可行
现在有大量实证证据表明专家混合模型(MoEs)有效且具有成本效益。
总结
问题1:什么是混合专家模型(MoE),其核心特点是什么?
混合专家模型(MoE)用多个前馈网络(专家)和一个选择器层替代传统大型前馈网络,核心特点是通过稀疏路由仅激活部分专家,在不显著增加浮点运算量(FLOPs)的情况下提升参数规模,兼顾效率与性能。
问题2:混合专家模型(MoE)受欢迎的主要原因有哪些?
1.相同FLOPs下,更多参数带来更好性能;2. 训练速度更快;3. 与密集模型相比竞争力强;4. 支持专家并行,可将不同专家部署在多个设备上,易于扩展。
问题3:MoE中常见的路由方式有哪些?主流方式的原理是什么?
常见路由方式包括Top-k、哈希、强化学习路由等,主流为Top-k路由。其原理是:输入通过门控向量计算各专家权重,筛选出权重最高的前k个专家,仅用这些专家处理输入并加权求和,实现稀疏激活。
问题4:训练MoE的核心挑战是什么?有哪些解决方案?
核心挑战是稀疏门控的离散性导致不可微,难以通过反向传播优化。解决方案包括:1. 强化学习优化路由(成本高,应用少);2. 随机扰动(引入高斯噪声使路由连续化);3. 启发式平衡损失(促使专家负载均衡,如辅助损失调整token分配)。
问题5:MoE存在哪些主要问题,如何应对?
1.稳定性问题:稀疏路由易导致训练不稳定,可通过对路由器使用float32或添加z损失缓解;2. 微调过拟合:在小数据集上易过拟合,可采用大量微调数据(如DeepSeek用140万样本)或微调非MoE的MLP;3. 基础设施复杂:需支持专家并行,依赖MegaBlocks等库优化稀疏计算。




)








)



 day58)

