1. LangGraph图结构概念说明
在以图构建的框架中,任何可执行的功能都可以作为对话、代理或程序的启动点。这个启动点可以是大模型的 API 接口、基于大模型构建的 AI Agent,通过 LangChain 或其他技术建立的线性序列等等,即下图中的 “Start” 圆圈所示。无论哪种形式,它都首先处理用户的输入,并决定接下来要做什么。下图展示了在 LangGraph 概念下,最基本的一种代理模型:👇
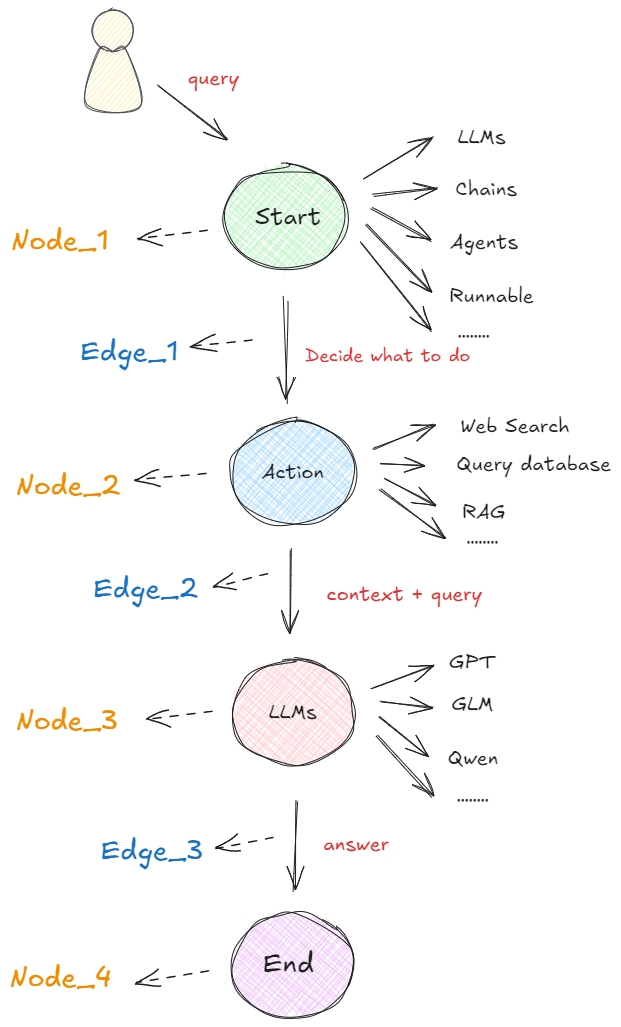
如上图所示,在启动点定义的可运行功能会根据收到的输入决定是否进行检索以及如何响应。 比如在执行过程中,如果需要检索信息,则可以利用搜索工具来实现,如Web Search(网络搜索)、Query Database(查询数据库)、RAG等获取必要的信息(图中的 “Action” 圆圈)。接下来,再使用一个大语言模型(“LLM”)处理工具提供的信息,结合用户最初传入的初始查询,生成最终的响应(图中的 “LLMs” 圆圈)。最终,这个响应被传递至终点节点(图中的 “End” 圆圈)。
这个流程就是在LangGraph框架中一个非常简单的代理构成形式。非常关键且我们必须清楚的概念是:每个圆圈代表一个“节点”(Nodes),每个箭头表示一条“边”(Edges)。在 LangGraph 中,无论代理的构建是简单还是复杂,它最终都是由节点和边通过特定的组合形成的图。这样的构建形式形成的工作流原理就是:当每个节点完成工作后,通过边告诉下一步该做什么,所以也就得出了:LangGraph的底层图算法就是在使用消息传递来定义通用程序。当节点完成其操作时,它会沿着一条或多条边向其他节点发送消息。然后,这些接收节点执行其功能,将结果消息传递给下一组节点,然后该过程继续。如此循环往复。
这就是LangGraph底层架构设计中图算法的根本思想。
LangGraph框架是通过组合Nodes和Edges去创建复杂的循环工作流程,通过消息传递的方式串联所有的节点形成一个通路。那么维持消息能够及时的更新并向该去的地方传递,则依赖langGraph构建的State概念。 在LangGraph构建的流程中,每次执行都会启动一个状态,图中的节点在处理时会传递和修改该状态。这个状态不仅仅是一组静态数据,而是由每个节点的输出动态更新,然后影响循环内的后续操作。如下所示:👇
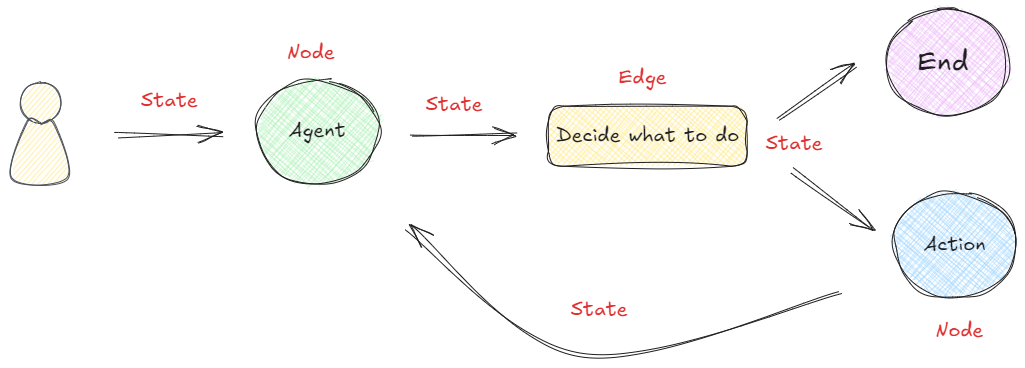
为了帮助大家更好的理解,我们先尝试在不接入大模型的情况下,构建一个如上图所示的简单工作流。
2.手动构建图流程
定义图时要做的第一件事是定义图的State。状态表示会随着图计算的进行而维护和更新的上下文或记忆。它用来确保图中的每个步骤都可以访问先前步骤的相关信息,从而可以根据整个过程中积累的数据进行动态决策。这个过程通过状态图StateGraph类实现,它是由LangGraph框架提供的核心类之一,专门用来创建state状态。
构建state的方法非常简答。我们可以将图的状态设计为一个字典,用于在不同节点间共享和修改数据,然后使用StateGraph类进行图的实例化。代码如下:
pip install langgraph -i https://pypi.tuna.tsinghua.edu.cn/simple
pip show langgraph
from langgraph.graph import StateGraph# 使用 stategraph 接收一个字典
builder = StateGraph(dict)
这里需要注意的是,builder也是后面要用到的图构建器(Graph Builder)对象,用于逐步添加节点、边、控制流逻辑,最终编译成可执行的 LangGraph 图。而这个图构建器需要通过带入一个状态对象来创建。
接下来,定义两个节点。addition节点是一个加法逻辑,接收当前状态StateGraph(dict),将字典中x的值增加1,并返回新的状态。而subtraction节点是一个减法逻辑,接收从addition节点传来的状态StateGraph(dict),从字典中的x值减去2,创建并返回一个新的键y。代码如下:
def addition(state):# 注意:这里接收到的是初始状态print(f"init_state: {state}")return {"x": state["x"] + 1}def subtraction(state):# 注意:这里接收到的是上一个节点的状态print(f"addition_state: {state}")return {"x": state["x"] - 2}
然后,进行图结构的设计。具体来看,我们添加名为addition和subtraction的节点,并关联到上面定义的函数。设定图的起始节点为addition,并从addition到subtraction设置一条边,最后从subtraction到结束节点设置另一条边。代码如下:
# START 和 END 是两个特殊的节点,分别表示图的开始和结束。
from langgraph.graph import START, END# 向图中添加两个节点
builder.add_node("addition", addition)
builder.add_node("subtraction", subtraction)# 构建节点之间的边
builder.add_edge(START, "addition")
builder.add_edge("addition", "subtraction")
builder.add_edge("subtraction", END)
最后,执行图的编译。需要通过调用compile()方法将这些设置编译成一个可执行的图。代码如下所示:
graph = builder.compile()
除了上述通过打印的方式查看构建图的结构,LangGraph还提供了多种内置的图形可视化方法,能够将任何Graph以图形的形式展示出来,帮助我们更好地理解节点之间的关系和流程的动态变化。可视化最大的好处是:直接从代码中生成图形化的表示,可以检查图的执行逻辑是否符合构建的预期。
pip install pyppeteer ipython -i https://pypi.tuna.tsinghua.edu.cn/simple
生成图结构的可视化非常直接。具体代码如下:
png_data = graph.get_graph(xray=True).draw_mermaid_png()with open("graph.png", "wb") as f:f.write(png_data)display(Image("graph.png"))
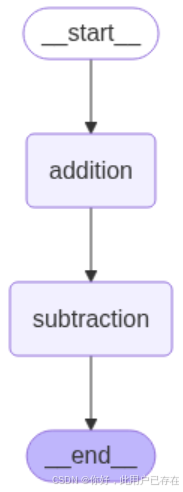
当通过 builder.compile() 方法编译图后,编译后的 graph 对象提供了 invoke 方法,该方法用于启动图的执行。我们可以通过 invoke 方法传递一个初始状态(如 initial_state = {"x": 10}),这个状态将作为图执行的起始输入。代码如下:
# 定义一个初始化的状态
initial_state = {"x":10}graph.invoke(initial_state)
LangGraph 的执行模型并不强制要求图中必须有 END 节点。只要执行路径在某个节点“无后继边”(即到达“终点”),那么该节点就被视为隐式终点。
也就是说,将一个字典作为状态对象带入到图中,即可进行图的实际运行。
在图的执行过程中,每个节点的函数会被调用,并且接收到前一个节点返回的状态作为输入。每个函数处理完状态后,会输出一个新的状态,传递给下一个节点。
上述代码执行过程中图的运行状态如下图所示:👇
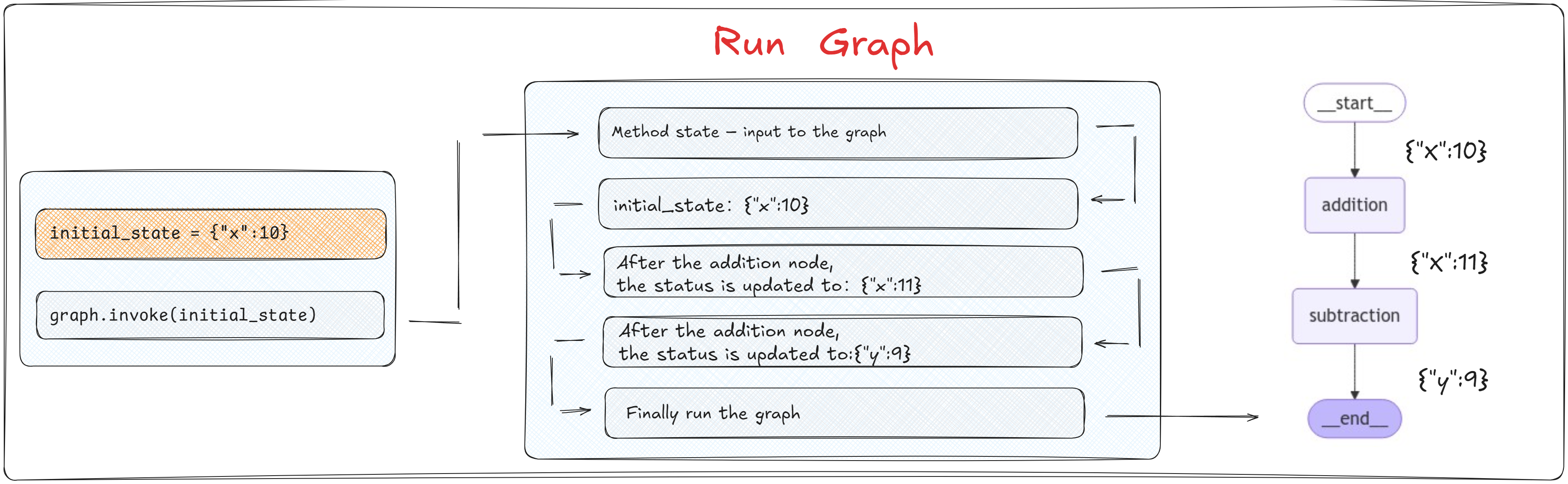
这里需要注意的一个关键信息是:节点函数不需要返回整个状态,而是仅返回它们更新的部分。 也就是说:在每个节点的函数内部逻辑中,需要使用和更新哪些State中的参数中,只需要在return的时候指定即可,不必担心未在当前节点处理的State中的其他值会丢失,因为LangGraph的内部机制已经自动处理了状态的合并和维护。
# 定义一个初始化的状态
initial_state = {"x":10, "y": 9}graph.invoke(initial_state)
总体来看,该图设置了一个简单的工作流程。其中值首先在第一个节点通过加法函数增加,然后在第二个节点通过减法函数减少。这一流程展示了节点如何通过图中的共享状态进行交互。需要注意的是,状态在任何给定时间只包含来自一个节点的更新信息。这意味着当节点处理状态时,它只能访问与其特定操作直接相关的数据,从而确保每个节点的逻辑是隔离和集中的。 使用字典作为状态模式非常简单,由于缺乏预定义的模式,节点可以在没有严格类型约束的情况下自由地读取和写入状态,这样的灵活性有利于动态数据处理。 然而,这也要求开发者在整个图的执行过程中保持对键和值的一致性管理。因为如果在任何节点中尝试访问State中不存在的键,会直接中断整个图的运行状态。
3. 借助Pydantic对象创建图
Pydantic 是一个用于创建“数据模型”的 Python 库,它可以自动校验数据类型,并将字典数据转换为结构化对象。它就像是给字典加了一个“类型安全 + 自动验证”的外壳,是现代 Python 项目中最主流的“数据结构定义工具”。
我们可以在 StateGraph(MyState) 传入一个 Pydantic 模型:
from pydantic import BaseModel
from langgraph.graph import StateGraph, START, END# ✅ 1. 定义结构化状态模型
class CalcState(BaseModel):x: int# ✅ 2. 定义节点函数,接收并返回 CalcState
def addition(state: CalcState) -> CalcState:print(f"[addition] 初始状态: {state}")return CalcState(x=state.x + 1)def subtraction(state: CalcState) -> CalcState:print(f"[subtraction] 接收到状态: {state}")return CalcState(x=state.x - 2)# ✅ 3. 构建图
builder = StateGraph(CalcState)builder.add_node("addition", addition)
builder.add_node("subtraction", subtraction)builder.add_edge(START, "addition")
builder.add_edge("addition", "subtraction")
builder.add_edge("subtraction", END)graph = builder.compile()# ✅ 4. 执行图:传入结构化状态对象
initial_state = CalcState(x=10)
final_state = graph.invoke(initial_state)# ✅ 5. 打印最终结果
print("\n[最终结果] ->", final_state)
但是需要注意的是,无论输入端输入什么结构的对象,最终图计算返回结果是一个字典类型对象。
4.创建条件分支图
from typing import Optional
from pydantic import BaseModel
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display# ✅ 定义结构化状态
class MyState(BaseModel):x: intresult: Optional[str] = None# ✅ 定义各节点处理逻辑(接受 MyState,返回 MyState)
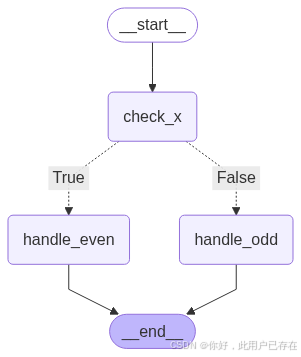
def check_x(state: MyState) -> MyState:print(f"[check_x] Received state: {state}")return statedef is_even(state: MyState) -> bool:return state.x % 2 == 0def handle_even(state: MyState) -> MyState:print("[handle_even] x 是偶数")return MyState(x=state.x, result="even")def handle_odd(state: MyState) -> MyState:print("[handle_odd] x 是奇数")return MyState(x=state.x, result="odd")def build_graph() -> StateGraph:# ✅ 构建图builder = StateGraph(MyState)builder.add_node("check_x", check_x)builder.add_node("handle_even", handle_even)builder.add_node("handle_odd", handle_odd)# ✅ 添加条件分支builder.add_conditional_edges("check_x", is_even, {True: "handle_even",False: "handle_odd"})# ✅ 衔接起始和结束builder.add_edge(START, "check_x")builder.add_edge("handle_even", END)builder.add_edge("handle_odd", END)# ✅ 编译图graph = builder.compile()return graphdef display_graph(graph: StateGraph) -> None:"""显示或保存图形"""try:png_data = graph.get_graph(xray=True).draw_mermaid_png()with open("graph.png", "wb") as f:f.write(png_data)display(Image("graph.png"))except Exception as e:print(f"无法显示图形: {e}")if __name__ == "__main__":# ✅ 构建图graph = build_graph()# ✅ 执行测试print("\n✅ 测试 x=4(偶数)")graph.invoke(MyState(x=4))print("\n✅ 测试 x=3(奇数)")graph.invoke(MyState(x=3))# ✅ 显示图形display_graph(graph)在本示例中,我们基于 LangGraph 框架构建了一个简单的有状态条件分支图,用于演示如何使用结构化状态(通过 Pydantic 模型定义)在多步骤的决策流程中进行状态传递与条件控制。
我们首先定义了一个名为 MyState 的 Pydantic 模型,用于描述图中每个节点共享的上下文状态信息。该状态包含两个字段:x 表示输入数值,result 表示最终处理结果。通过使用 Pydantic,能够显著增强状态管理的类型安全性、可读性和扩展性。
图的结构由三个核心节点组成:
- check_x:作为图的第一步处理节点,接收初始状态并进行输出转发,不修改任何字段;
- handle_even:处理偶数情况,标记
result = "even"; - handle_odd:处理奇数情况,标记
result = "odd"。
在 check_x 节点之后,我们引入了基于 is_even 判断函数的条件分支控制逻辑。LangGraph 提供的 add_conditional_edges 方法允许我们根据状态中的值动态跳转至不同的执行路径,从而实现类似于传统编程语言中的 if-else 分支控制。
整体流程图如下:
START → check_x → [判断 x 是否为偶数]├─ True → handle_even → END└─ False → handle_odd → END
该图的编排逻辑清晰地展现了 LangGraph 的优势所在:即在状态流转的基础上,灵活地控制流程分支,并通过结构化模型传递和管理上下文信息,为构建具备复杂控制流的智能体(Agent)打下了基础。
其中
# ✅ 定义结构化状态
class MyState(BaseModel):x: intresult: Optional[str] = None
代码解释如下
| 字段 | 类型定义 | 是否必填 | 默认值 | 含义 |
|---|---|---|---|---|
x | int | ✅ 必填 | 无默认值 | 必须提供的整数字段 |
result | Optional[str] = Union[str, None] | ❌ 可选 | 默认是 None | 表示一个可选的字符串,常用于延迟赋值或非必要字段 |
而完整的图结构执行流程如下:
| 参数位置 | 传入值 | 含义 |
|---|---|---|
| 第1个参数 | "check_x" | 当前执行完的节点名称(分支判断起点) |
| 第2个参数 | is_even | 一个接收状态 state 并返回布尔值的函数,用于判断分支条件 |
| 第3个参数 | {True: "handle_even", False: "handle_odd"} | 条件结果 → 目标节点的映射表 |
4.创建条件循环图
from pydantic import BaseModel
from langgraph.graph import StateGraph, START, END# ✅ 1. 定义结构化状态模型
class LoopState(BaseModel):x: int# ✅ 2. 定义节点逻辑
def increment(state: LoopState) -> LoopState:print(f"[increment] 当前 x = {state.x}")return LoopState(x=state.x + 1)def is_done(state: LoopState) -> bool:return state.x > 10# ✅ 3. 构建图
builder = StateGraph(LoopState)
builder.add_node("increment", increment)# ✅ 4. 设置循环控制:is_done 为 True 则结束,否则继续
builder.add_conditional_edges("increment", is_done, {True: END,False: "increment"
})builder.add_edge(START, "increment")
graph = builder.compile()# ✅ 5. 测试执行
print("\n✅ 执行循环直到 x > 10")
final_state = graph.invoke(LoopState(x=6))
print(f"[最终结果] -> x = {final_state['x']}")
注意,这里需要注意,add_conditional_edges中构建了循环
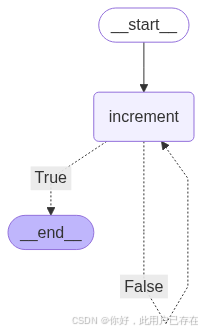
除了使用api构建循环图,我们也可以自己使用节点和边构建循环,如下所示
from pydantic import BaseModel
from typing import Optional
from langgraph.graph import StateGraph, START, END# ✅ 1. 定义状态模型
class BranchLoopState(BaseModel):x: intdone: Optional[bool] = False# ✅ 2. 定义各节点逻辑
def check_x(state: BranchLoopState) -> BranchLoopState:print(f"[check_x] 当前 x = {state.x}")return statedef is_even(state: BranchLoopState) -> bool:return state.x % 2 == 0def increment(state: BranchLoopState) -> BranchLoopState:print(f"[increment] x 是偶数,执行 +1 → {state.x + 1}")return BranchLoopState(x=state.x + 1)def done(state: BranchLoopState) -> BranchLoopState:print(f"[done] x 是奇数,流程结束")return BranchLoopState(x=state.x, done=True)# ✅ 3. 构建图
builder = StateGraph(BranchLoopState)builder.add_node("check_x", check_x)
builder.add_node("increment", increment)
builder.add_node("done_node", done)builder.add_conditional_edges("check_x", is_even, {True: "increment",False: "done_node"
})# ✅ 4. 循环逻辑:偶数 → increment → check_x
builder.add_edge("increment", "check_x")# ✅ 5. 起始与终点
builder.add_edge(START, "check_x")
builder.add_edge("done_node", END)graph = builder.compile()# ✅ 6. 测试执行
print("\n✅ 初始 x=6(偶数,进入循环)")
final_state1 = graph.invoke(BranchLoopState(x=6))
print("[最终结果1] ->", final_state1)print("\n✅ 初始 x=3(奇数,直接 done)")
final_state2 = graph.invoke(BranchLoopState(x=3))
print("[最终结果2] ->", final_state2)
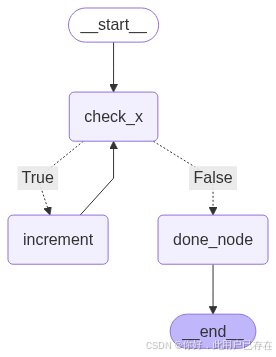
LangGraph 会把所有节点名、状态字段、通道名放在一个命名空间中处理,为了避免歧义,它会严格检查有没有冲突,最保险的做法是:节点名不要与字段名重复,既如果使用 state.result = “done”,也不要有 “result” 这个节点。
理解了LangGraph构建图的基本流程后,接下来我们就尝试接入大模型构建一个对话机器人。
二、搭建基于LangGraph的多轮对话问答机器人
1. LangGraph中多轮对话实现方法
在接下来的这个案例中,我们进一步将大模型接入到 LangGraph 工作流程中,并允许动态消息处理以及与模型的交互。
大模型应用都是接受消息列表作为输入,就像LangChain中的Chat Model,需要接收Message对象列表作为输入。这些消息有多种形式,例如HumanMessage (用户输入)或AIMessage ( 大模型响应)。这种消息格式其实就与我们之前介绍的StateGraph(dict)结构有一些区别。
因此对于消息序列格式的state,一种更简单的方法就是使用LangGraph预构建的add_messages函数,这个更高级的状态所实现的是:对于全新的消息,它会附加到现有列表,同时它也会正确处理现有消息的更新。 代码如下所示:
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph
from langgraph.graph.message import add_messagesclass State(TypedDict):messages: Annotated[list, add_messages]graph_builder = StateGraph(State)
add_messages的核心逻辑是合并两个消息列表,按 ID 更新现有消息。默认情况下,状态为“仅附加”,当新消息与现有消息具有相同的 ID时,进行更新。具体参数是:
- left ( Messages ) – 消息的基本列表。
- right ( Messages ) – 要合并到基本列表中的消息列表(或单个消息)。
其返回值是一个消息列表,其中的合并逻辑则是:如果right的消息与left的消息具有相同的 ID,则right的消息将替换left的消息,否则作为一条新的消息进行追加。通过这种形式维护一个messages列表,可以很方便的实现消息的合并和更新。其基本形式如下:
messages = [HumanMessage(content="你好,请你详细的介绍一下你自己。"),AIMessage(content="我是一个智能助手,我可以帮助你回答问题。"),HumanMessage(content="请问什么是大模型?"),AIMessage(content="大模型是一种基于深度学习的自然语言处理模型,它能够理解和生成自然语言文本。"),.....]
我们可以使用add_messages函数来进行快速验证。 如果消息的ID不一样,则会进行追加。代码如下:
from langgraph.graph.message import add_messages
from langchain_core.messages import AIMessage, HumanMessagemsgs1 = [HumanMessage(content="你好。", id="1")]
msgs2 = [AIMessage(content="你好,很高兴认识你。", id="2")]add_messages(msgs1, msgs2)
[HumanMessage(content='你好。', additional_kwargs={}, response_metadata={}, id='1'),AIMessage(content='你好,很高兴认识你。', additional_kwargs={}, response_metadata={}, id='2')]
如果ID相同,则会对消息内容进行更新。代码如下:
msgs1 = [HumanMessage(content="你好。", id="1")]
msgs2 = [HumanMessage(content="你好呀。", id="1")]add_messages(msgs1, msgs2)
[HumanMessage(content='你好呀。', additional_kwargs={}, response_metadata={}, id='1')]
需要注意的是,不能直接在普通 Python 代码中测试 add_messages 的合并功能。
原因是:
✅ add_messages 并不会在你创建 State 字典时自动生效,
⛔ 它只会在 LangGraph 的内部状态更新系统中被识别和调用。
因此,当通过messages: Annotated[list, add_messages]去定义状态时,我们就可以很方便的实现聊天机器人场景下消息序列的处理和维护。
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messagesclass State(TypedDict):messages: Annotated[list, add_messages]graph_builder = StateGraph(State)
| 元素 | 含义 | 是什么? |
|---|---|---|
list | 字段的数据类型 | ✅ Python 内置的类型(列表类型) |
add_messages | 字段的“附加语义” | ✅ LangGraph 提供的特殊函数(合并器/reducer),不是 list 的方法 |
接下来我们需要创建一个大模型节点,接收用户的输入,并返回大模型的响应。因此首先需要准备一个可以进行调用的大模型,这里我们选择使用DeepSeek的大模型,并使用DeepSeek官方的API_KEK进行调用。如果初次使用,需要现在DeepSeek官网上进行注册并创建一个新的API_Key,其官方地址为:https://platform.deepseek.com/usage
注册好DeepSeek的API_KEY后,首先在项目同级目录下创建一个env文件,用于存储DeepSeek的API_KEY,如下所示:
接下来通过python-dotenv库读取env文件中的API_KEY,使其加载到当前的运行环境中,代码如下:
pip install python-dotenv -i https://pypi.tuna.tsinghua.edu.cn/simple
import os
from dotenv import load_dotenv
load_dotenv(override=True)DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")# print(DeepSeek_API_KEY) # 可以通过打印查看
pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple
from openai import OpenAI# 初始化DeepSeek的API客户端
client = OpenAI(api_key=DeepSeek_API_KEY, base_url="https://api.deepseek.com")# 调用DeepSeek的API,生成回答
response = client.chat.completions.create(model="deepseek-chat",messages=[{"role": "system", "content": "你是乐于助人的助手,请根据用户的问题给出回答"},{"role": "user", "content": "你好,请你介绍一下你自己。"},],
)# 打印模型最终的响应结果
print(response.choices[0].message.content)
如果可以正常收到DeepSeek模型的响应,则说明DeepSeek的API已经可以正常使用且网络连通性正常。
对于LangGraph框架,接入大模型最简单的方法就是借助langChain中的ChatModel组件。因此,我们首先需要安装LangChain的DeepSeek组件,安装命令如下:
pip install langchain-deepseek
安装好LangChain集成DeepSeek模型的依赖包后,需要通过一个init_chat_model函数来初始化大模型,代码如下:
import asyncio
import os
from dotenv import load_dotenv
from langchain.chat_models import init_chat_modelload_dotenv()
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")model = init_chat_model(model="deepseek-chat", model_provider="deepseek",api_key=DeepSeek_API_KEY) # 等待输出
def invoke_tool():question = "你好,请你介绍一下你自己。"result = model.invoke(question)print(result.content)
# 流式输出
async def invoke_tool_async():chunks = []async for chunk in model.astream("你好,请你详细的介绍一下你自己。"):chunks.append(chunk)print(chunk.content, end="|", flush=True)if __name__ == "__main__":# invoke_tool()asyncio.run(invoke_tool_async()) 其中model用来指定要使用的模型名称,而model_provider用来指定模型提供者,当写入deepseek时,会自动加载langchain-deepseek的依赖包,并使用在model中指定的模型名称用来进行交互。
这里可以看到,仅仅通过两行代码,我们便可以在LangChain中顺利调用DeepSeek模型,并得到模型的响应结果。相较于使用DeepSeek的API,使用LangChain调用模型无疑是更加简单的。同时,不仅仅是DeepSeek模型,LangChain还支持其他很多大模型,如OpenAI、Qwen、Gemini等,我们只需要在init_chat_model函数中指定不同的模型名称,就可以调用不同的模型。其工作的原理是这样的:
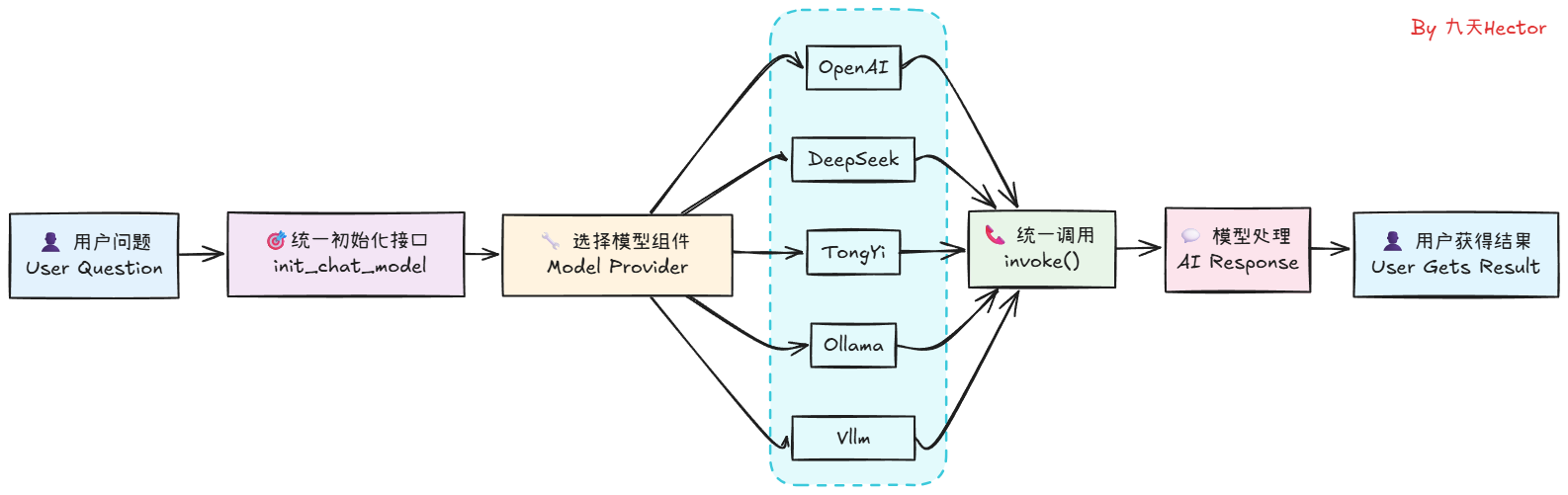
理解了这个基本原理,如果大家想在用LangChain进行开发时使用其他大模型如Qwen3系列,则只需要先获取到Qwen3模型的API_KEY,然后安装Tongyi Qwen的第三方依赖包,即可同样通过init_chat_model函数来初始化模型,并调用invoke方法来得到模型的响应结果。关于LangChain都支持哪些大模型以及每个模型对应的是哪个第三方依赖包,大家可以在LangChain的官方文档中找到,访问链接为:https://python.langchain.com/docs/integrations/chat/
当然,除了在线大模型的接入,langChain也只是使用Ollama、vLLM等框架启动的本地大模型,关于如何使用不同的框架启动如DeepSeek R1、Qwen3等模型
掌握了如何使用langChain接入大模型后,接下来我们可以直接把langChain的Chat Model接入LangGraph中作为一个图节点(Node), 并使用LangGraph的StateGraph来管理消息序列。代码如下:
def chatbot(state: State):return {"messages": [model.invoke(state["messages"])]}
接下来,添加一个chatbot节点,将当前State作为输入并返回一个字典,该字典中更新了messages中的状态信息。
# 添加节点
graph_builder.add_node("chatbot", chatbot)# 添加边
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()
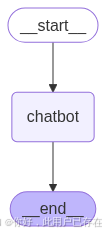
这个图的基本逻辑是:第一个节点调用大模型并生成一个输出,该输出是一个AIMessage对象类型,然后,第二个节点直接将前一个节点的 AIMessage 提取为具体的JSON格式,完成JSON的解析。
final_state = graph.invoke({"messages": ["你好,我叫陈明,好久不见。"]})
print(final_state)
- 借助MemorySaver高效搭建多轮对话机器人
🧠 MemorySaver 的核心功能
-
短期记忆(线程级记忆)
MemorySaver 为每个thread_id保存和恢复对话状态(State),实现在同一会话中的历史上下文记忆。 -
状态持久化
在每个节点运行后,State 会自动存储;再次调用时,如果使用相同的thread_id,MemorySaver 会恢复此前保存的状态,无需手动传递历史信息 。 -
多会话隔离
通过不同的thread_id可实现会话隔离,允许多个用户并发交互且各自的对话互不干扰。 -
图状态快照与恢复
不仅包括对话历史,还保存整个工作流状态,可用于错误恢复、时间旅行、断点续跑、Human‑in‑the‑loop 等高级场景 。
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain.chat_models import init_chat_model
import os
from dotenv import load_dotenv
from langgraph.checkpoint.memory import MemorySaver# 1. 定义状态类(会自动合并 messages)
class State(TypedDict):messages: Annotated[list, add_messages]load_dotenv()
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# 2. 初始化模型
model = init_chat_model(model="deepseek-chat", model_provider="deepseek", api_key=DeepSeek_API_KEY)# 3. 定义聊天节点
def chatbot(state: State) -> State:reply = model.invoke(state["messages"])return {"messages": [reply]}# 4. 构建带 MemorySaver 的图
builder = StateGraph(State)
builder.add_node("chatbot", chatbot)
builder.add_edge(START, "chatbot")
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)# 5. 运行多轮对话,使用相同 thread_id 实现记忆
thread_config = {"configurable": {"thread_id": "session_10"}}# 第一轮对话
state1 = graph.invoke({"messages": [{"role":"user","content":"你好,好久不见,我叫陈明。"}]}, config=thread_config)
print(state1['messages'][-1].content)# 第二轮对话
state2 = graph.invoke({"messages": [{"role":"user","content":"你好,你还记得我的名字么?"}]}, config=thread_config)
print(state2['messages'][-1].content)# 使用不同 thread_id,会开启全新对话
state3 = graph.invoke({"messages":[{"role":"user","content":"记得我的名字吗?"}]}, config={"configurable":{"thread_id":"session_2"}})
state3['messages'][-1].content# 查看记忆
latest = graph.get_state(thread_config)
print(latest.values["messages"]) # 包含全部轮次对话
最后有关流式输出可参考
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
from langchain_core.messages import AIMessage, HumanMessage
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
import os
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from langgraph.graph import START, END
import asynciodef msg_test():# 当消息id不同时,会自动合并消息msgs1 = [HumanMessage(content="你好。", id="1")]msgs2 = [AIMessage(content="你好,很高兴认识你。", id="2")]msg=add_messages(msgs1, msgs2)print(msg)# 当消息id相同时,会更新当前消息msgs3 = [HumanMessage(content="你好。", id="3")]msgs4 = [HumanMessage(content="你好呀。", id="3")]msg1=add_messages(msgs3, msgs4)print(msg1)load_dotenv()
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
model = init_chat_model(model="deepseek-chat", model_provider="deepseek",api_key=DeepSeek_API_KEY)class State(TypedDict):messages: Annotated[list, add_messages]graph_builder = StateGraph(State)def chatbot(state: State):return {"messages": [model.invoke(state["messages"])]}# 添加节点
graph_builder.add_node("chatbot", chatbot)
# 添加边
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()def test_chatbot():final_state = graph.invoke({"messages": ["你好,我叫陈明,好久不见。"]})print(final_state['messages'][0].content)def invoke_chatbot():messages_list = [HumanMessage(content="你好,我叫陈明,好久不见。"),AIMessage(content="你好呀!我是小智,一名乐于助人的AI助手。很高兴认识你!"),HumanMessage(content="请问,你还记得我叫什么名字么?"),]final_state = graph.invoke({"messages": messages_list})print(final_state['messages'][-1].content)async def async_invoke_chatbot():async for msg, metadata in graph.astream({"messages": ["你好,请你详细的介绍一下你自己"]}, stream_mode="messages"):if msg.content and not isinstance(msg, HumanMessage):print(msg.content, end="", flush=True)if __name__ == '__main__':# invoke_chatbot()asyncio.run(async_invoke_chatbot())参考
https://www.bilibili.com/video/BV1Kx3CzyE6Q/?spm_id_from=333.337.search-card.all.click&vd_source=23fecc1a0310f387371490d0c2975c12
![[逆向知识] AST抽象语法树:混淆与反混淆的逻辑互换(一)](http://pic.xiahunao.cn/[逆向知识] AST抽象语法树:混淆与反混淆的逻辑互换(一))





)
)




![[go] 桥接模式](http://pic.xiahunao.cn/[go] 桥接模式)



模拟实现)


,110. 字符串接龙(卡码网),105. 有向图的完全联通(卡码网))