循环神经网络 RNN
recurrent neural networks
-
RNN序列处理能力(RNN核心作用)
RNN处理序列数据,相比“Vanilla”神经网络(仅支持一对一映射),RNN支持多种序列映射模式:
- 一对一:传统分类
- 一对多:如图像captioning:图像→文字序列
- 多对一:如情感分析:文字序列→情感标签
- 多对多:如机器翻译:文字序列→文字序列
- 时序多对多:视频帧分类
-
RNN非序列数据的序列处理
例如通过瞥视序列分类图像,或逐部分生成图像
-
RNN的数学定义与计算图
-
前向传播公式
状态更新:
ht:t时刻的隐藏状态;xt:t时刻的输入
ht=fw(ht−1,xt) h_t = f_w(h_{t-1},x_t) ht=fw(ht−1,xt)
vanilla RNN具体公式:
ht=tanh(Whhht−1+Wxhxt),输出yt=Whyht h_t = tanh(W_{hh}h_{t-1}+W_{xh}x_t),输出y_t = W_{hy}ht ht=tanh(Whhht−1+Wxhxt),输出yt=Whyht -
计算图结构
时间步共享参数W,隐藏状态ht依赖于前一时刻ht-1,形成循环结构
不同映射模式的计算图:
- 多对多:每个时间步输出
- 多对一:最后时间步输出
- 一对多:单输入生成序列
-
序列到序列模型 Sequence to Sequence模型
由 多对一编码器(将输入序列编码为向量)和 一对多解码器(从向量生成输出序列)组成,用于机器翻译等任务
-
-
RNN反向传播
- 通过时间的反向传播(BPTT):前向计算整个序列的损失后(每个时间步loss的和),反向传播梯度至所有时间步,更新共享参数
- 截断BPTT:将长序列分割为子序列,仅在子序列内反向传播,避免计算量过大,同时保留隐藏状态的时序传递
-
RNN的可解释性分析
通过可视化RNN隐藏单元,发现部分单元具有特定功能:
引号检测单元:对引号内文本敏感
行位置敏感单元:跟踪文本在句中的位置
代码深度单元:跟踪代码块嵌套深度
-
图像captioning与注意力机制
-
图像captioning基本框架
结合CNN(提取图像特征)和RNN(生成文字序列),CNN输出图像特征向量,去掉最后两层全连接层,作为RNN的初始输入,RNN逐步生成序列
-
注意力机制
RNN生成每个单词时,会关注图像的不同区域(比如生成straw时关注帽子的straw部分),通过加权特征向量Z=Σpivi实现(pi为注意力权重,vi为图像特征)
-
-
视觉问答 VQA
任务定义:给定图像和问题,RNN结合CNN特征和问题序列,输出答案
注意力机制应用:RNN在处理问题时,会关注图像中与问题相关的区域
-
RNN的梯度问题与LSTM
-
vanilla RNN的梯度问题
反向传播时,梯度需要经过多个矩阵乘法(W的连乘),若W的最大奇异值>1,梯度爆炸;若W的最小奇异值<1,梯度消失,导致长序列依赖难以学习
解决方法:梯度裁剪(梯度范数超过阈值时缩放)缓解爆炸;改进架构(如LSTM)缓解消失
-
LSTM:长短期记忆网络
核心公式:通过输入门(i),遗忘门(f),输出门(o),门之门(g:写多少到细胞里)和细胞状态(c)控制信息流动:
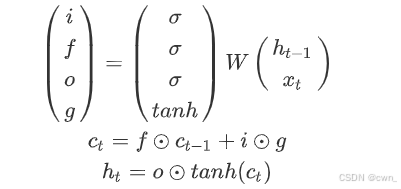
梯度优势:细胞状态ct通过元素乘法传递梯度(无矩阵连乘),实现”不间断梯度流“,类似ResNet的残差连接
-
-
RNN变体 GRU
-
GRU(门控循环单元)
简化LSTM,合并输入门和遗忘门为更新门(z),保留重置门(r):


-
其他RNN变体:如MUT1/2/3等,通过调整门控机制优化性能
-


















![[激光原理与应用-185]:光学器件 - BBO、LBO、CLBO晶体的全面比较](http://pic.xiahunao.cn/[激光原理与应用-185]:光学器件 - BBO、LBO、CLBO晶体的全面比较)
