摘要
本文章旨在系统性地探讨一个前沿的交叉学科研究课题:如何通过深层语义分析,探索并建模人类认知中普遍存在的底层逻辑一致性。此研究横跨自然语言处理(NLP)、知识图谱(KG)、认知科学、脑神经科学、系统科学(信息论)、哲学、符号学、逻辑学、中国传统语言文字学及认知语义学等多个领域。报告将提出一个整合性的理论框架、具体的研究方法、可行的实施步骤以及前瞻性的学术观点,旨在为构建更接近人类智能、具备可解释性和鲁棒性的新一代人工智能系统提供理论基础和技术路径。
1. 引言:研究的宏大背景与核心问题
当前,以大型语言模型(LLM)为代表的人工智能技术在自然语言处理任务上取得了革命性进展 。然而,这些模型在事实一致性、可解释性和深层逻辑推理方面仍面临严峻挑战,例如“幻觉”(hallucination)现象频发,即生成看似合理但与事实相悖的内容 。这暴露了一个根本性问题:现有模型主要依赖于海量数据的统计关联,而未能真正捕捉和理解人类语言与思维背后所蕴含的深层语义结构与逻辑规律。
本研究的核心问题是:我们能否通过整合多学科的理论与方法,构建一个能够模拟、解释并验证人类底层逻辑一致性的计算框架?
我们提出的核心假设是:人类的逻辑一致性并非等同于数理逻辑中的形式化、刚性体系,而是一种在认知层面更具柔韧性与适应性的“认知似然一致性”(Cognitively Plausible Consistency)。它是在符号知识、具身认知、神经活动与文化-语言演化之间复杂互动中涌现出的特性。因此,要探索这一规律,必须打破学科壁垒,进行深度融合。本报告将从理论框架、研究方法、实施步骤和评估体系四个方面,阐述如何实现这一宏伟目标。
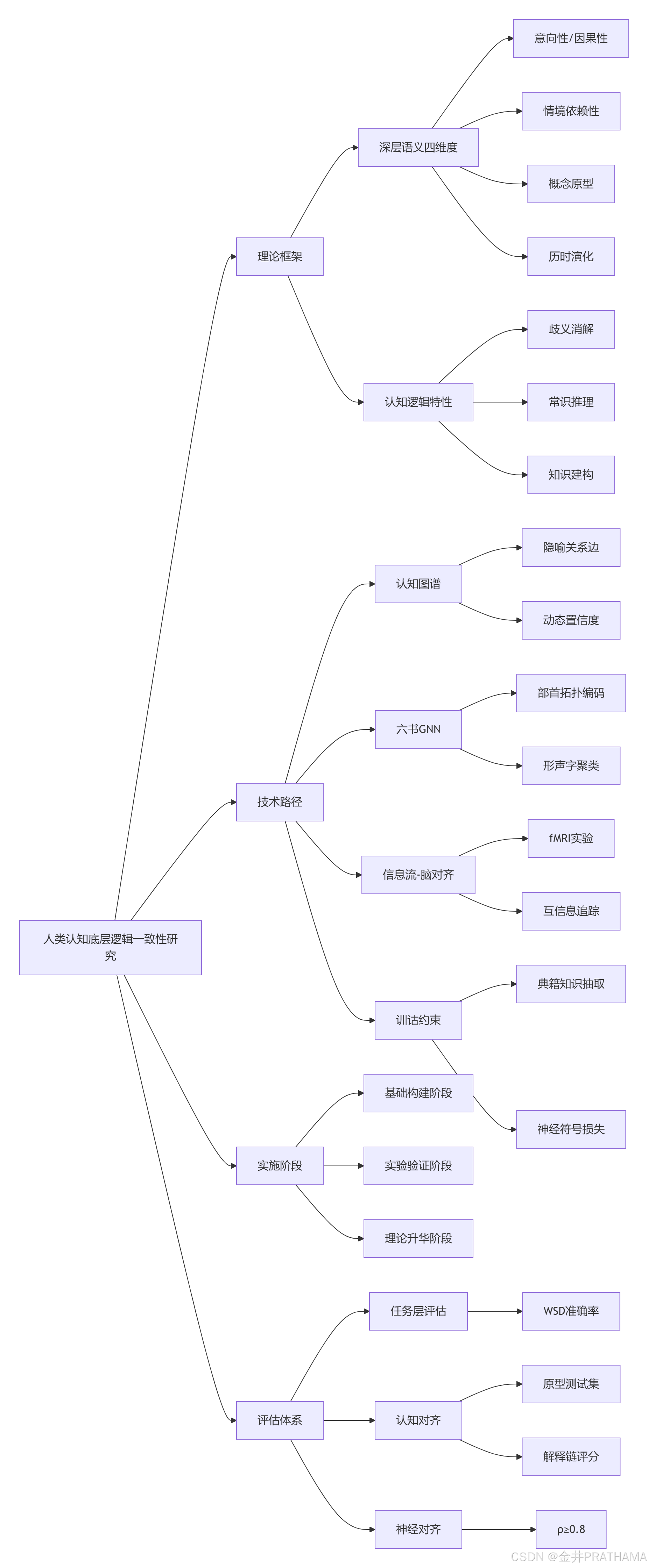
2. 核心理念与理论框架(我们的看法)
要探索人类的底层逻辑,我们首先需要构建一个能够承载这一探索的理论框架。
2.1. “深层语义”的再定义
我们主张,研究必须超越词向量或句子嵌入所代表的分布语义。深层语义应至少包含以下维度:
- 意向性与因果性: 理解语言背后的意图、信念以及事件间的因果关联。
- 情境依赖性: 语义在不同物理、社会、文化情境下的动态变化和消歧。
- 概念结构与原型理论: 知识并非扁平化的事实罗列,而是围绕原型组织的、具有层次和家族相似性特征的概念网络,这与认知语义学的观点一致。
- 历时演化性: 语言和概念的意义是随时间演变的。中国传统训诂学等学科为我们提供了观察这种演化的独特窗口。
2.2. “逻辑一致性”的认知诠释
我们挑战将人类逻辑等同于经典一阶逻辑的观点。人类思维充满了模糊、类比、隐喻和直觉,但在宏观上表现出高度的一致性和可预测性。这种一致性体现在:
- 歧义消解: 人类能高效利用语境信息解决词义和结构歧义 。
- 常识推理: 在不完备信息下做出合理的推断。
- 知识建构: 系统地组织和更新世界知识。
因此,我们的目标是建模这种认知层面的、动态的、与情境高度相关的逻辑一致性。
2.3. 跨学科整合的必然性
单一学科无法独立解决此问题,各学科的角色如下:
- NLP与知识图谱: 提供核心的计算工具与结构化知识的表示方法。知识图谱被视为增强LLM事实性的关键资源 。
- 认知与脑神经科学: 为计算模型提供来自人类的“地面真实”(ground truth)。脑成像技术(如fMRI)可以揭示语义处理和歧义解决的神经基础 为模型验证提供生物学证据。
- 系统科学与信息论: 提供数学语言来量化和分析复杂系统中的信息流动。例如,互信息(Mutual Information)可用于分析NLP模型内部的信息传递 以及与大脑活动模式的关联 。
- 哲学、逻辑学、符号学: 提供关于意义、真理、推理和符号表征的元理论指导。
- 中国传统语言文字学: 以汉字“六书”和训诂学为例,提供了一个独特的、非拼音文字系统的视角,揭示了符号(字形)与意义(字义)之间深刻的、历时性的关联,是检验深层语义模型的绝佳案例 。
3. 研究方法与技术路径(我们的建议和方法)
基于上述理论框架,我们提出以下四条具体且相互关联的技术路径。
3.1. 构建认知增强的知识图谱(Cognitive-Enhanced Knowledge Graphs)
当前研究多集中于利用事实性知识图谱增强LLM 。我们需要超越这一范畴,构建更符合人类认知结构的“认知图谱”。
- 方法:
- 扩展节点与边的内涵: 除了传统的(实体,关系,实体)三元组,引入认知语义学概念。例如,边的类型可以区分为“因果关系”、“原型隶属关系”、“隐喻映射关系”等。
- 编码情境与不确定性: 为知识三元组附加情境标签(如时间、地点、文化背景)和置信度分数,以处理语义的动态性和知识的模糊性。
- 融合多模态信息: 将视觉、听觉等非文本信息融入图谱,以反映人类具身认知的特点。
- 意义: 这种认知图谱将作为模型推理的“脚手架”,使其不仅能“知其然”(事实),更能“知其所以然”(背后的认知结构与逻辑)。这为解决LLM的泛化和常识推理问题提供了新的途径 。
3.2. 汉字“六书”原理的图神经网络拓扑编码
汉字是形、音、义的结合体,“六书”理论深刻揭示了其内部的构造逻辑 。将其计算化,是探索符号与语义深层关系的关键一步。
- 方法:
- 符号解构与图谱构建: 基于“六书”原理(象形、指事、会意、形声等),将汉字解构为独立的表意或表音部件(如部首、声旁)。将每个汉字表示为一个图,其中节点是部件,边代表它们的空间结构关系(上/下、左/右)和功能关系(形旁/声旁)。
- GNN拓扑特征学习: 应用图神经网络(GNN)技术学习这些“汉字图”的向量表示。GNN的结构善于捕捉拓扑信息 能够将“六书”所蕴含的构造规则编码到低维向量空间中。
- 向量空间可视化与验证: 使用t-SNE等降维技术将汉字向量可视化 。我们预期,具有相同造字逻辑(如均为形声字)或相同部首的汉字将在向量空间中聚集,从而验证编码的有效性。
- 意义: 此方法将古老的语言学理论转化为可计算的神经特征,为模型提供了超越笔画序列的、更深层次的汉字语义理解能力。虽然目前尚缺乏直接的开源实现 (Query: Open-source GNN code...), 但其技术路线是清晰的。
3.3. 基于信息论的“模型-大脑”语义流对齐分析
要验证模型是否在模拟人类的逻辑过程,就需要比较其内部信息处理动态与大脑的神经活动。
- 方法:
- 设计受控的神经科学实验: 设计fMRI实验,让被试阅读精心控制的汉语歧义句和无歧义句。fMRI研究已证实,处理语义或句法歧义会引发特定脑区(如左额下回LIFG)更强的BOLD信号 。
- 量化模型内部的语义信息流: 在我们构建的认知增强LLM中,输入同样的歧义/无歧义句。使用信息论工具(如互信息)来追踪和量化“消歧”相关信息在模型不同层级间的流动强度与路径 。
- 进行相关性分析: 统计分析模型内部的信息流量化值与fMRI实验中对应脑区BOLD信号的幅度变化之间的相关性。尽管目前缺乏直接报告互信息值与BOLD信号幅度的公开数据集 (Query: Public fMRI datasets...), 但设计此类实验并进行分析是完全可行的。
- 意义: 若模型的信息处理模式与大脑活动模式呈现显著正相关,将为“模型在模拟人类认知过程”这一论断提供强有力的实证支持,实现从“行为模拟”到“过程模拟”的跨越。
3.4. 传统训诂学知识的神经可计算化
训诂学蕴含了丰富的关于汉语词义演变、语境依赖和深层关联的知识。将其融入现代NLP模型是一个巨大挑战,但也蕴含巨大机遇。
- 方法:
- 知识抽取与结构化: 从《说文解字》、《尔雅》等训诂学典籍中,系统性地抽取出词义解释、同义/反义关系、通假关系、以及词义在不同时代和文献中的具体用法,并将其整合进3.1节提到的“认知图谱”中。
- 设计语义约束的损失函数: 借鉴神经符号方法中的思想 设计一个“训诂语义损失函数”。当模型生成对古文的解释或在特定语境下进行词义选择时,如果其输出与训诂学提供的权威解释相悖,则施加惩罚。
- 意义: 这相当于为模型聘请了一位“国学大师”作为指导,迫使模型的语义空间不仅要拟合现代语料的统计分布,还要与数千年来积淀的语言知识体系保持一致,从而获得更深厚的历史纵深和文化底蕴。
4. 实施步骤与评估体系(我们的步骤)
一个宏大的研究计划需要分阶段实施和评估。
4.1. 实施步骤
第一阶段:基础资源与模型构建(1-2年)
- 认知图谱构建: 启动中文认知图谱项目,融合现有开放知识库与结构化的传统语言学知识。
- 汉字编码模型开发: 实现基于“六书”的GNN汉字表示模型,并发布开源代码和预训练向量。
- 原型模型训练: 在上述资源基础上,训练一个认知增强的中文LLM原型。
第二阶段:计算建模与神经科学实验(2-4年)
- 开展fMRI实验: 与神经科学实验室合作,完成针对中文歧义处理的fMRI数据采集。
- 数据分析与模型对齐: 分析fMRI数据,并进行模型信息流与大脑BOLD信号的相关性分析,迭代优化模型架构。
第三阶段:综合评估与理论升华(4-5年)
- 多维度评估: 使用下文定义的综合评估体系,全面评测模型的性能。
- 理论构建: 在实验和模型结果的基础上,提炼出关于人类底层逻辑一致性的计算理论。
4.2. 综合评估体系
评估模型的“深层语义理解能力”和“逻辑一致性”不能仅靠传统的准确率指标。我们需要一个全新的、多维度的评估框架。
- 任务层评估(Task-based Evaluation):
- 在标准的中文词义消歧(WSD)基准(如SemEval的部分中文任务)上进行测试 。
- 将模型性能与其它SOTA模型以及人类表现基准进行直接比较 。当前研究显示,即使是顶级LLM,在许多任务上与人类仍有差距 。
- 认知对齐评估(Cognitive Alignment Evaluation):
- 概念结构探测: 设计新的测试集,专门评估模型对原型、隐喻、转喻等认知语义现象的理解能力。
- 推理链可解释性: 借鉴AlignBench 或KGLens 等框架的思想,要求模型在完成推理任务(如歧义消解)后,生成自然语言的“解释”,由人类专家评估其解释的认知合理性。
- 神经对齐评估(Neural Alignment Evaluation):
- 将模型信息流与大脑BOLD信号的相关系数本身作为一个核心评估指标。更高的相关性意味着模型在处理机制上更接近生物大脑。
5. 结论与展望(我们的看法和建议)
本报告描绘了一个宏大而长远的研究蓝图。我们坚信,探索人类心智的奥秘、构建真正通用的人工智能,其路径不在于单一学科的埋头猛进,而在于跨学科的深度融合与协同创新。
我们提出的核心观点是: 要理解并实现人类水平的逻辑一致性,必须从“数据驱动”和“知识驱动”走向“认知驱动” 。这意味着我们的AI模型不仅要学习海量文本,整合结构化知识,更要使其内部的表示和运算过程,与人类认知及大脑处理信息的底层机制相对齐。
这一研究方向的成功推进,将可能带来:
- 更鲁棒、可解释的AI: AI系统的决策过程将更符合人类的直觉和逻辑,减少不可预测的“幻觉”,增强人机协作的信任度 。
- 计算认知科学的突破: 建立一个连接语言学、心理学、脑科学和计算机科学的桥梁,形成一个可计算、可验证的关于人类语言和思维的新理论 。
- “计算人文”新范式: 让中国传统语言文字学等古老的人文智慧,不再仅仅是数字化的馆藏,而是成为启发和构建下一代人工智能的鲜活源泉。
这项探索无疑是充满挑战的,它要求研究者具备跨领域的广博知识和勇于探索未知的精神。然而,其潜在的回报也是巨大的——它不仅关乎技术上的下一次飞跃,更关乎我们对人类自身智能本质的深刻理解。



 Sentinel篇)



:点灯前的准备 —— 从软件安装到硬件原理)



与Grafana配置)




)


