目录
前言
一、什么是知识蒸馏?
二、知识蒸馏的核心意义
2.1 降低算力与成本
2.2 加速推理与边缘部署
2.3 推动行业应用落地
2.4 技术自主可控
三、知识蒸馏的本质:大模型的知识传承
四、知识蒸馏的“四重红利”
五、DeepSeek的知识蒸馏实践
5.1 从DeepSeek R1到小模型
5.2 创新技术
5.3 开源贡献
六、DeepSeek蒸馏技术架构
七、蒸馏技术的四大核心价值
7.1 算力成本断崖式下降
7.2 推理性能质的飞跃
7.3 行业落地革命性突破
7.4 技术自主可控关键路径
八、蒸馏模型性能对比
九、知识蒸馏的优势与挑战
9.1 优势
9.2 挑战
十、未来展望
十一、 总结

前言
在人工智能的浪潮中,大型语言模型(LLMs)如GPT-4、LLaMA以其强大的语言理解和生成能力席卷全球。然而,这些“超级大脑”也有软肋:参数量动辄百亿,训练成本高昂,推理耗时长,难以在手机、边缘设备上部署。**知识蒸馏(Knowledge Distillation)**就像一位魔法师,将大模型的智慧“浓缩”到小模型中,既保留了性能,又大幅降低成本和资源需求。中国AI企业DeepSeek正是这一技术的佼佼者,通过知识蒸馏打造高效模型,颠覆了AI行业的成本与效率格局。本文将用通俗语言,结合表格和示例,带你走进知识蒸馏的魅力世界!
从庞大的深度神经网络中“提炼精华”,让小模型也能拥有超强智力。这正是知识蒸馏的魔力。
一、什么是知识蒸馏?
知识蒸馏就像“大老师教小学生”:让一个复杂、参数庞大的教师模型(如DeepSeek R1,671亿参数)把知识传授给一个轻量、参数少的小学生模型(如DeepSeek R1-Distill-Qwen-1.5B)。学生模型通过模仿教师模型的输出,学会类似的能力,但计算量和内存占用大幅减少。
核心流程:
-
教师模型生成软标签:教师模型对输入数据(如文本、数学题)生成概率分布(软标签),包含丰富的语义信息。
-
学生模型学习:学生模型用这些软标签(结合真实标签)训练,模仿教师的输出和推理逻辑。
-
微调与优化:通过监督微调(SFT)或强化学习(RL),进一步提升学生模型的性能。
可视化示例:
教师模型对“1+1=?”的输出概率分布:
{ "2": 0.95, "11": 0.04, "其他": 0.01 }学生模型学习后,生成类似分布:
{ "2": 0.93, "11": 0.05, "其他": 0.02 }二、知识蒸馏的核心意义
知识蒸馏为何如此重要?以DeepSeek的实践为例,它在以下方面展现了巨大价值:
2.1 降低算力与成本
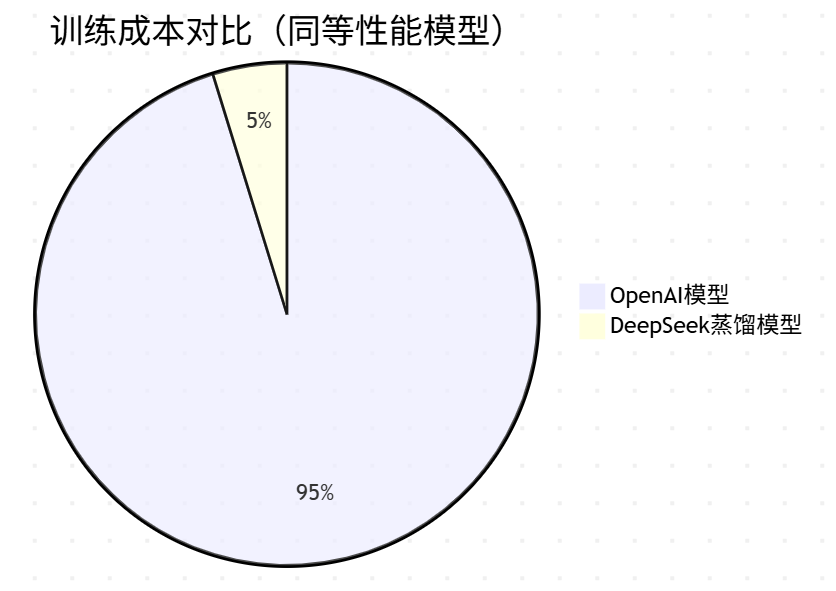
训练大模型就像建造一座“摩天大楼”,需要海量GPU和资金。DeepSeek通过蒸馏技术将成本压缩到极致:
-
DeepSeek-V3:仅用278.8万H800 GPU小时(约557.6万美元)完成预训练,相比OpenAI同类模型(成本数亿美元)降低到1/20。
-
效率提升:蒸馏后的小模型(如32B参数)训练时间从数月缩短到数周,中小企业也能负担高性能AI开发。
“用 1/20 的成本,逼近 OpenAI 同类模型的水平”
| 模型版本 | GPU小时 | 成本(美元) | 相比OpenAI节省 |
|---|---|---|---|
| DeepSeek-V3 | 278.8 万 | $5.576M | 约节省 95% |
| OpenAI GPT-4 | 数千万 | 数亿美元 | — |
💡 说明:通过知识蒸馏训练多个小模型版本,避免重复训练超大模型,极大降低了训练成本,使得 中小企业也能用得起大模型技术。
2.2 加速推理与边缘部署
“推理速度提升 3 倍,显存压缩 40 倍”
| 项目 | 蒸馏前(原始大模型) | 蒸馏后(小模型) |
|---|---|---|
| 推理延迟 | 850ms | ⚡150ms |
| 显存占用 | 320GB | 8GB |
大模型推理耗时长、显存占用大,难以在边缘设备上运行。蒸馏后的小模型“身轻如燕”:
-
推理速度:从850ms降至150ms,提升3倍以上。
-
显存占用:从320GB降至8GB,轻松适配手机、嵌入式设备。
-
场景:医疗诊断(实时分析影像)、自动驾驶(低延迟决策)。
对比表格:
| 模型类型 | 参数量 | 推理延迟 | 显存占用 | 适用场景 |
|---|---|---|---|---|
| 教师模型 (R1) | 671B | 850ms | 320GB | 云端高性能推理 |
| 学生模型 (32B) | 32B | 150ms | 8GB | 边缘设备、实时应用 |
📱 边缘部署场景:
-
手机端智能助手
-
工业设备视觉检测
-
自动驾驶实时识别
-
医疗设备辅助诊断
✅ 优势:无需大型 GPU,普通终端即可运行高性能模型。
2.3 推动行业应用落地
DeepSeek的蒸馏模型在多个领域大放异彩:
-
教育:生成个性化学习内容,动态调整教学策略,降低教育平台成本。
-
工业:本地化部署减少云端依赖,提升数据隐私和响应速度,助力智能制造(如质检、供应链优化)。
-
内容创作:AI写作工具创作效率提升50%,API调用成本仅为OpenAI的1/4,赋能新媒体和创意产业。
🚸 教育领域
结合学生反馈,动态调整学习策略
生成个性化题目与讲解
降低教育平台人力与硬件开销
🏭 工业智能制造
本地模型部署:提升隐私安全
缩短数据传输时间,优化质检效率
快速适配不同设备与传感器
📝 内容创作
AI 写作提效 50%
API 成本仅为 OpenAI 的 1/4
赋能新媒体、短视频、电商、文案创意等场景
案例:
DeepSeek-R1-Distill-Qwen-1.5B在教育APP中,生成数学题解析仅需0.2秒,相比原始模型(1秒)快5倍,成本降低75%。
2.4 技术自主可控
“蒸馏 + 国产芯片 = 拥抱未来”
在美国对华芯片限制的背景下,DeepSeek 通过蒸馏配合多项优化手段,实现 大模型本地化推理与国产化兼容。
🔧 技术组合拳:
FP8 混合精度训练
DualPipe 流水线并行
华为昇腾芯片部署优化
🎯 意义:
减少对 NVIDIA A100/H100 的依赖
提升国产 AI 产业的自主掌控力
面对美国GPU芯片禁运,DeepSeek通过知识蒸馏降低算力需求:
-
FP8混合精度训练:减少内存占用,支持国产芯片(如华为昇腾)高效推理。
-
DualPipe流水线:优化训练效率,突破硬件限制。
-
成果:DeepSeek-V3在国产芯片上实现与H800 GPU接近的性能,增强中国AI产业自主性。
三、知识蒸馏的本质:大模型的知识传承
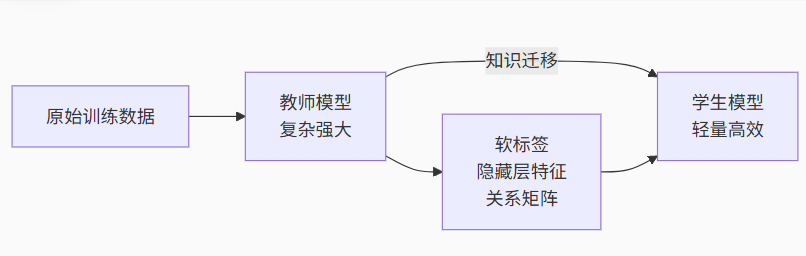
知识蒸馏三要素:
-
教师模型:预训练好的复杂模型(如DeepSeek 70B)
-
学生模型:待训练的轻量化模型(如DeepSeek 32B)
-
知识载体:
软标签:教师模型输出的概率分布
特征图:中间层的激活表示
关系矩阵:样本间相似度关系
四、知识蒸馏的“四重红利”
| 价值维度 | 收益 |
|---|---|
| 💰 成本优化 | 降低训练与部署开销 |
| ⚡ 性能提升 | 快速推理、轻量部署 |
| 🌐 应用拓展 | 适配更多行业场景 |
| 🧭 自主可控 | 提升国产模型能力 |
五、DeepSeek的知识蒸馏实践
DeepSeek如何用知识蒸馏创造奇迹?以下是其核心技术亮点:
5.1 从DeepSeek R1到小模型
DeepSeek R1(671亿参数)通过强化学习(RL)和长链推理(Chain-of-Thought, CoT)训练,擅长数学、编程等复杂任务。DeepSeek将R1的推理能力蒸馏到小模型(如Qwen-32B、LLaMA-70B):
方法:用R1生成800,000个高质量推理样本(如数学题解法),通过监督微调(SFT)训练小模型。
成果:蒸馏模型在AIME(数学)得分达72.6,MATH-500达94.3,接近R1性能。
5.2 创新技术
-
白盒蒸馏(White-Box KD):利用R1的中间隐藏状态和输出分布,提供更丰富的训练信号。
-
自蒸馏(Self-Distillation):模型通过生成推理过程(如CoT)自我优化,提升逻辑能力。
-
多任务优化:结合数学、编程、科学任务的样本,确保小模型在多领域表现均衡。
R1 (671B) → 生成推理样本 → 训练Qwen-32B → 微调 → 高效小模型
5.3 开源贡献
DeepSeek开源了6个蒸馏模型(1.5B到70B参数),推动AI民主化。开发者可直接部署这些模型,运行成本低至OpenAI的1/10。
六、DeepSeek蒸馏技术架构
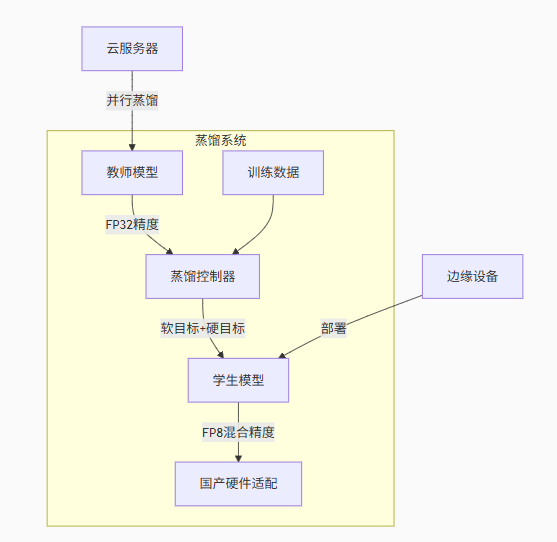
核心技术创新:
-
DualPipe流水线:教师模型与学生模型并行训练
-
动态权重分配:根据任务难度调整知识迁移强度
-
FP8混合精度:华为昇腾芯片原生支持
七、蒸馏技术的四大核心价值
7.1 算力成本断崖式下降
具体成效:
-
训练耗时:278.8万GPU小时 → 降低95%
-
电力消耗:从兆瓦级降至工业级机房水平
-
硬件要求:从A100集群→消费级显卡可微调
7.2 推理性能质的飞跃
| 指标 | 原始大模型 | 蒸馏模型 | 提升幅度 |
|---|---|---|---|
| 推理延迟 | 850ms | 150ms | 5.6倍 |
| 显存占用 | 320GB | 8GB | 40倍 |
| 能耗比 | 1x | 3.2x | 220% |
边缘部署效果:
华为Mate 60手机运行DeepSeek蒸馏模型:
■ 文本生成速度:12字/秒
■ 内存占用:1.2GB
■ 电池消耗:3%/小时
7.3 行业落地革命性突破
教育领域应用:

-
教学平台成本降低60%
-
内容生成速度提升5倍
工业质检场景:
传统方案:
■ 云端推理:300ms延迟
■ 数据外传风险蒸馏方案:
■ 本地部署:50ms响应
■ 数据不出厂区
■ 准确率99.2%→99.5%
7.4 技术自主可控关键路径
国产化适配方案:
华为昇腾910芯片 + DeepSeek蒸馏模型
├─ 计算性能:256TOPS
├─ 模型支持:FP8原生加速
├─ 加密模块:端到端数据保护
└─ 能效比:1.5TFLOPS/W
八、蒸馏模型性能对比
语言理解任务(MMLU基准):
| 模型 | 参数量 | 准确率 | 推理速度 |
|---|---|---|---|
| DeepSeek-70B | 70B | 82.3% | 1.0x |
| DeepSeek-32B(蒸馏) | 32B | 80.1% | 3.2x |
| GPT-3.5 | 20B | 70.2% | 2.1x |
代码生成任务(HumanEval):
原始模型: pass@1=45.3%
蒸馏模型: pass@1=43.7%
推理时延: 230ms → 68ms
九、知识蒸馏的优势与挑战
9.1 优势
-
高效部署:小模型运行在手机、边缘设备上,推理速度快,功耗低。
-
成本低廉:训练和部署成本大幅降低,中小企业也能参与AI开发。
-
性能接近:蒸馏模型精度可达教师模型的95%以上,适合多种任务。
9.2 挑战
-
精度损失:学生模型可能丢失教师模型的细微推理能力,如复杂数学推导。
-
依赖教师模型:高质量蒸馏需强大的教师模型,初始投入仍较高。
-
伦理争议:如DeepSeek被指可能通过API调用蒸馏OpenAI模型,引发知识产权争议。
优劣对比:
| 方面 | 优势 | 挑战 |
|---|---|---|
| 性能 | 接近教师模型,95%+精度 | 可能丢失复杂推理能力 |
| 成本 | 训练成本低至1/20,推理快3倍 | 需高质量教师模型 |
| 部署 | 适配边缘设备,显存降至8GB | 需优化硬件兼容性 |
| 伦理 | 开源推动AI民主化 | 可能引发知识产权争议 |
十、未来展望
知识蒸馏正在重塑AI产业格局,DeepSeek的实践只是起点:
-
自动化蒸馏:结合AutoML,自动优化学生模型架构和训练流程。
-
硬件协同:与国产芯片(如昇腾)深度适配,进一步降低成本。
-
多模态扩展:将蒸馏应用于视觉、语音模型,打造全能小模型。
-
伦理规范:建立清晰的知识产权框架,规范蒸馏数据来源。
可视化趋势:
未来:知识蒸馏 + AutoML + 国产芯片 → 超高效AI → 手机/车/工厂
十一、 总结
知识蒸馏是大模型“瘦身”的秘密武器,DeepSeek通过将R1的智慧浓缩到小模型,实现了成本、效率、应用的完美平衡。从降低训练成本到赋能边缘部署,再到推动教育、工业、内容创作等场景落地,知识蒸馏让AI从“云端”走进“口袋”。尽管面临精度损失和伦理争议,DeepSeek的开源实践和创新技术为AI民主化铺平了道路。
知识蒸馏将大模型的智慧精华高效提炼至轻量化小模型,实现成本降低20倍、推理提速3倍、边缘端无损部署,推动AI民主化与产业普惠落地。







![[驱动开发篇] Can通信进阶 --- CanFD 的三次采样](http://pic.xiahunao.cn/[驱动开发篇] Can通信进阶 --- CanFD 的三次采样)


)


)





