介绍GPT-1,GPT-2,GPT-3,GPT-4
GPT-1 介绍
2018年6月,OpenAI公司发表了论文"|mproving Language Understanding by Generative Pre-training”《用生成式预训练提高模型的语言理解力》,推出了具有1.17亿个参数的GPT-1(Generative Pre-trainingTransformers,生成式预训练变换器)模型。
与BERT最大的区别:在于GPT-1采用了传统的语言模型方法进行预训练,即使用单词的上文来预测单词,而BERT是采用了双向上下文的信息共同来预测单词,
正是因为训练方法上的区别,使得GPT更擅长处理自然语言生成任务(NLG),而BERT更擅长处理自然语言理解任务(NLU).
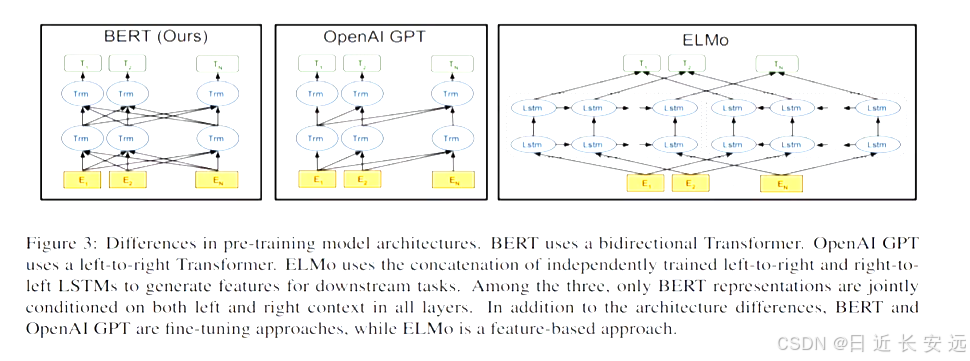
从上图可以很清楚的看到GP1采用的是单向Iransfonmer模型,例如给定一个句子[u1,u2.,… un],GP1在预测单词ui的时候只会利用[u1,u2.… u(i-1)]的信息,而BERT会同时利用上下文的信息[u1,u2,. u(i 1),u,...,u(i+1),....,un]
作为两大模型的直接对比,BERT采用了tansformer的Ecoder模块,而GPT采用了tansformer的Decode模块。并且GPT的Decoder Block和经典tansformer Decode Block还有所不同,如下所示是一个(解码)层(两个模块一起)
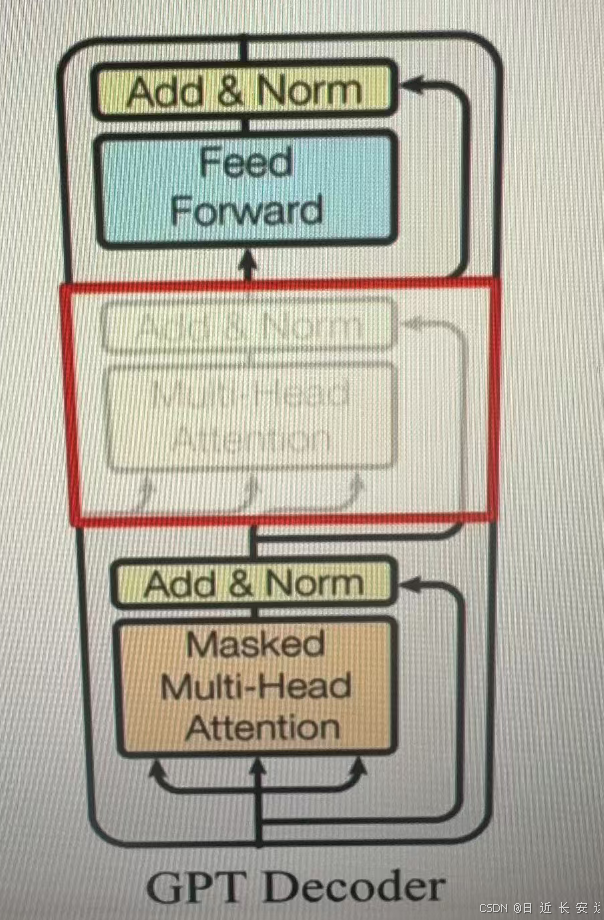
经典的包括3个子层,分别为msked multi-head attention(带有掩码的自注意力机制张量),encode-decoder attention层(正常的自注意力),以及Feed Forward层(前轨全连接层)。但GPT中取消了第二个层。
add&norm 残差链接+正则化处理
注点:对比经典的Transformer架构,解码器摸块采用了6个Decoder Block;GPT的架构中采用了12个Decoder Block.
GPT-1训练过程
GPT-1的训练包括两阶段过程:
第一阶段: 无监督的预训练语言模型
第二阶段: 有监督的下游任务fine-tunning.
无监督的预训练语言模型:

有监督的下游任务fine-tunning:

整体训练过程架构图
根据下游任务适配的过程分两步:1、根据任务定义不同输入,2、对不同任务增加不同的分类层

分类任务(Classification):将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接得到预测的概率分布;
文本蕴涵(Entailment):将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token.再依次通过transformer和全连接得到预测结果;
文本相似度(Similarity):输入的两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到的特征向量拼接后再送给全连接得到预测结果;
问答和常识推理(Multiple-Choice):将 N个选项的问题抽象化为N个二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果
GPT-1数据集:GPT-1使用了BooksCorpus数据集,这个数据集包含 7000 本没有发布的书籍,选择该部分数据集的原因:
1.数据集拥有更长的上下文依赖关系,得模型能学得更长期的依赖关系;
2.这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力。
GPT-1特点:
优点:1.在有监督学习的12个任务中,GPT-1在9个任务上的表现超过了state-of-the-art的模型(sota)
2.利用Transformer做特征抽取,能够捕捉到更长的记忆信息,且较传统的 RNN 更易于并行化
缺点:1.GPT 最大的问题就是传统的语言模型是单向的.
2.针对不同的任务,需要不同的数据集进行模型微调,相对比较麻烦(数据集、人力、算力)
GPT-1模型总结
GPT-1证明了transformer对学习词向量的强大能力,在GPT-1得到的词向量基础上进行下游任务的学习(微调),能够让下游任务取得更好的泛化能力.对于下游任务的训练,GPT-1往往只需要简单的微调便能取得非常好的效果。
GPT-1在未经微调的任务上虽然也有一定效果,但是其泛化能力远远低于经过微调的有监督任务,说明了GPT-1只是一个简单的领域专家,而非通用的语言学家.
GPT2
2019年2月,openAl推出了GPT-2,同时,他们发表了介绍这个模型的论文"Language Models areUnsupervised Multitask Learners”(语言模型是无监督的多任务学习者).相比于GPT-1,GPT-2突出的核心思想为多任务学习,其目标旨在仅采用无监督预训练得到一个泛化能力更强的语言模型,直接应用到下游仟务中,GRT-2并没有对GPT-1的网络结构进行过多的创新与设计,而是使用了更多的网络参数与更大的数据集: 最大模型共计48层,参数量达15亿
嵌入维度
架构微小改动:
1.LN层被放置在Self-Attention层和Feed Forward层前,而不是像原来那样后置
2.在最后一层Tansfomer Block后增加了LN层
GPT-2训练核心思想:
目前最好的 NLP 模型是结合无监督的 Pre-training 和监督学习的 Fune-tuning,但这种方法的缺点是针对某特定任务需要不同类型标注好的训练数据,GPT-2的作者认为这是狭隘的专家而不是通才,因此该作者希望能够通过无监督学习训练出一个可以应对多种任务的通用系统.因此,GPT-2的训练去掉了Fune-tuning只包括无监督的预训练过程,和GPT-1第一阶段训练一样,也属于一个单向语言模型。
GPT-2模型的学习目标: 使用无监督的预训练模型做有监督的任务
1.语言模型其实也是在给序列的条件概率建模,即p(sn|s1,s2.…sn-1)
2.任何有监督任务,其实都是在估计p(output|input),通常我们会用特定的网络结构去给任务建模,但如果要做通用模型,它需要对p(output |input,task)建模,对于NLP任务的input和output,我们平常都可以用向”表示,而对于task,其实也是一样的,18年已经有研究对task进行过建模了,这种模型的一条训练样本可以表示为:(translate to french,English text,french text),实验证明以这种数据形式可以有监督地训练一个single model,其实也就是对一个模型进行有监督的多任务学习.
语言模型=无监督多任务学习,相比于有监督的多任务学习,语言模型只是不需要显示地定义哪些字段是要预测的输出,所以,实际上有监督的输出只是语言模型序列中的一个子集,举个例子,比如我在训练语言模型时,有一句话"The translation of word Machine Learning in chinese is 机器学习”,那在训练完这句话时语言模型就自然地将翻译任务和任务的输入输出都学到了
再比如,当模型训练完"MichealJordanis thebest basketbal player in the history"语料的语言模型之后,便也学会了(question: "who is the bestbasketball player in the history ?",answer:"Micheal jordan")的Q&A任务
基于上面的思想,作者将GPT-2模型根据给定输入与任务来做出相应的输出,那么模型就可以表示成下面这个样子:p(outputlinput,task),例如可以直接输入:(“自然语言处理”,中文翻译)来得到我们需要的结果(“Nature Language Processing”),因此提出的模型可以将机器翻译,自然语言推理,语义分析,关系提取等10类任务统一建模为一个任务,而不再为每一个子任务单独设计一个模型.综上,GPT-2的核心思想概括为:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务:
GPT-2的数据集:于Reddit上高赞的文章,命名为WebText,数据集共有约800万篇文章,累计体积约40G.为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章,
特点:
优点
1.文本生成效果好,在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法.
海量数据和大量参数训练出来的词向量模型,可以迁移到其它类别任务中而不需要额外的训练.
缺点
1.无监督学习能力有待提升
2.有些任务上的表现不如随机
GPT-2模型总结
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练,但是很多实验也表明,GPT-2的无监督学习的能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好,尽管在有些zero-shot的任务上的表现不错,但是我们仍不清楚GPT-2的这种策略究竟能做成什么样子.GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了我们下面要介绍的GPT-3.
GPT3
2020年5月,OpenAl发布了GPT-3,同时发表了论文"Language Models are Few-Shot Learner”《小样本学习者的语言模型》
GPT-3 作为其先前语言模型(LM)GPT-2 的继承者.它被认为比GPT-2更好、更大.事实上,与他语言模型相比OpenAI GPT-3 的完整版拥有大约 1750 亿个可训练参数,是迄今为止训练的最大模型,这份 72 页的研究论文非常详细地描述了该模型的特性、功能、性能和局限性
实际上GPT-3 不是一个单一的模型,而是一个模型系列,系列中的每个模型都有不同数量的可训练参数
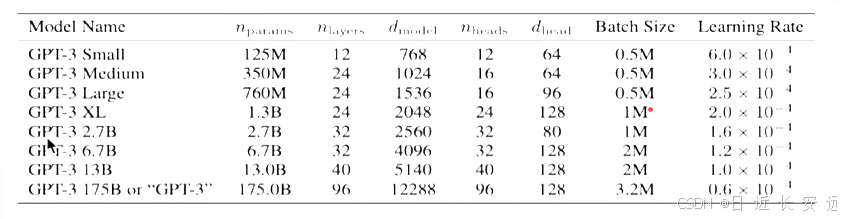
事实上,GPT-3系列模型结构与GPT-2完全一致,为了探究机器学习性能和模型参数的关系,作者分别训练了包含1.25亿至1750亿参数的8个模型,并把1750亿参数的模型命名为GPT-3.其中最大版本 GPT-3 1758 或“GPT-3"县有175个B参数,96层的多头Transformer、Head size为96、词向量维度为12288、文本长度大小为2048.
GPT-3训练核心思想:GPT-3模型训练的思想与GPT-2的方法相似,去除了fine-tune过程,只包括预训练过程,不同只在于采用了参数更多的模型、更丰富的数据集和更长的训练的过程.
但是GPT-3 模型在进行下游任务时采用了一种新的思想,即情境学习(in-context learning),情境学习理解: 在被给定的几个任务示例或一个任务说明的情况下,模型应该能通过简单预测以补全任务中其他的实例.即情境学习要求预训练模型要对任务本身进行理解,在GPT-3模型中给出了三种不同类型的情景学习,他们分别是:Few-shot、One-shot、Zero-shot.
传统的微调策略存在问题:
1.微调需要对每一个任务有一个任务相关的数据集以及和任务相关的微调。
2.需要一个相关任务大的数据集,而且需要对其进行标注。
3.当一个样本没有出现在数据分布的时候,泛化性不见得比小模型要好.
Zero-shot:
The model predicts the answer given only a natural languagedescription of the task. No gradient updates are performed.
定义:给出任务的描述,然后提供测试数据对其进行预测,直接让预训练好的模型去进行任务测试
One-shot:
In addition to the task description, the model sees a single example of the task. No gradient updates are performed.
定义:在预训练和真正翻译的样本之间,插入一个样本做指导,相当于在预训练好的结果和所要执行的任务中之间,给一个例子,告诉模型英语翻译为法语,应该这么翻译.
示例: 向模型输入"这个任务要求将中文翻译为英文,你好->helo,销售->”,然后要求模型预测下一个输出应0该是什么,正确答案应为“sell”.
Few-shot:
In addition to the task description, the model sees a few examples of the task, No gradient updates are performed
定义:在预训练和真正翻译的样本之间,插入多个样本做指导,相当于在预训练好的结果和所要执行的任务之间,给多个例子,告诉模型应该如何工作,
示例: 向模型输入"这个任务要求将中文翻译为英文,你好->hello,再见->goodbye,购买->purchase,销售->”,然后要求模型预测下一个输出应该是什么,正确答案应为“sell".
GPT-3的数据集:一般来说,模型的参数越多,训练模型所需的数据就越多,GPT-3共训练了5个不同的语料大约 45 TB 的文本数据,分别是低质量的Common Crawl,高质量WebText2,Books1,Books2和Wikipedia,GPT-3根据数据集的不同的质量赋予了不同的权值,权值越高的在训练的时候越容易抽样到,如下表所示:
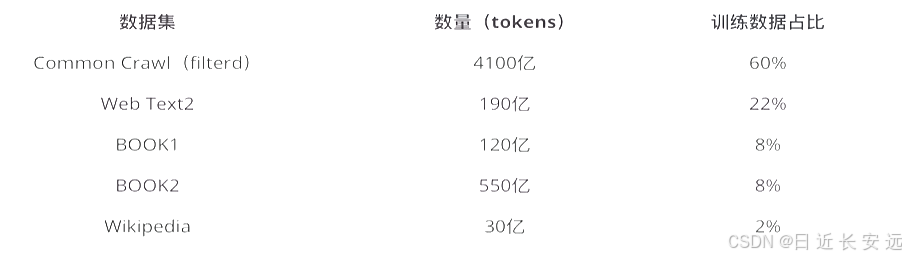
Common Crawl语料库包含在8年的网络爬行中收集的PB 级数据,语料库包含原始网页数据、元数据提取和带有光过滤的文本提取
WebText2是来自具有 3+ upvotes 的帖子的所有出站 Reddit 链接的网页文本
Books1和Books2是两个基于互联网的图书语料库
英文维基百科页面 也是训练语料库的一部分.
特点:
优点
1.去除了fune-tuning任务
2.整体上,GPT-3在zero-shot或one-shot设置下能取得尚可的成绩,在few-shot设置下有可能超越基于fine-tune的SOTA模型
缺点
1.由于40TB海量数据的存在,很难保证GPT-3生成的文章不包含一些非常敏感的内容
2.对于部分任务比如:“判断命题是否有效“等,会给出没有意义的答案
GPT-3模型总结
GPT系列从1到3,通通采用的是transformer架构,可以说模型结构并没有创新性的设计.GPT-3的本质还是通过海量的参数学习海量的数据,然后依赖transformer强大的拟合能力使得模型能够收敛,得益于庞大的数据集,GPT-3可以完成一些令人感到惊喜的任务,但是GPT-3也不是万能的,对于一些明显不在这个分布或者和这个分布有冲突的任务来说,GPT-3还是无能为力的.
GPT4~4.5
最新介绍,保持热情!!!



















)
