学习一个知识,要先了解它的来源
1. 模糊测试的诞生:Barton Miller 的故事
“Fuzz”一词起源于1988年,由威斯康星大学麦迪逊分校的Barton Miller教授及其研究生团队在一个高级操作系统课程项目中提出 。这个概念的诞生颇具戏剧性。Miller教授在一次雷雨天气中通过拨号连接远程操作Unix计算机时,发现程序因线路干扰导致的输入失真而反复崩溃 。令他惊讶的是,即使是他认为健壮的程序也无法优雅地处理这些意外输入,而是直接崩溃 。
这一偶然的发现揭示了现实世界中不可预测的外部因素能够暴露软件漏洞的重要性。这不仅仅是关于“错误输入”,更是关于“意外环境条件”对系统稳定性的影响。这种刻意引入混乱以测试系统弹性的概念,与现代“混沌工程”的核心原则不谋而合。模糊测试从其诞生之初,就隐含地认识到系统不仅要能抵御恶意输入,还要能抵御任何形式的意外或“噪音”数据,这反映了现实世界操作的不可预测性。这使得模糊测试成为一种基本的弹性测试技术,而不仅仅是安全测试技术。
Miller的团队随后对Unix、Windows和Macintosh应用程序进行了广泛研究,通过注入“噪音”输入,导致了大量程序故障 。模糊测试最初的目标是测试Unix工具的健壮性,通过向其提供随机输入数据 。早期模糊测试的一个关键贡献是其简单的“预言机”:如果程序在随机输入下崩溃或挂起,则视为失败,否则视为通过 。这种简单而通用的度量标准使得早期模糊测试变得实用,尽管由于其“无纪律性”的方法,它最初遭到了传统软件工程界的强烈抵制 。
1.2. Go 语言内置模糊测试机制
Go 语言自 1.18 版本起,将模糊测试作为其标准 testing 包的一部分。
Go 1.19 的改进进一步增强了 libFuzzer 模式的检测能力,从而为变异提供了更好的信号,更有效地探索了被测试代码。
2.为什么我们还需要一种新的测试方式?
在 Go 语言中,我们离不开单元测试和集成测试,它们帮我们验证了大量代码的正确性。但是,它们真的能覆盖所有情况吗?
传统测试方法,如单元测试和集成测试,依赖于已知的输入和预期的输出 。开发人员手动编写测试用例,这可能耗时且容易出错 。
单元测试:
其核心是“已知输入 -> 预期输出”。我们手动设计测试用例,涵盖正常流程、边界条件甚至一些已知错误场景。
优点:
它非常高效,能快速反馈代码逻辑是否符合预期。
局限性:
依赖于开发者的想象力。不可能穷举所有可能的输入
集成测试:
是验证多个模块、组件或外部系统之间协同工作是否正确。
优点:
可以验证真实交互逻辑,更接近生产环境行为。
局限性:
运行速度慢, 依赖外部环境,稳定性差,调试困难,无法把控所有情况
共同问题:不能发现发现边界外的未知错误和安全漏洞。
很多 Bug 和安全漏洞并非源于业务逻辑的错误,而是隐藏在代码处理异常或恶意输入的边缘路径中。这些路径在正常流程中几乎不会被触发,却可能导致:
程序崩溃 (Panic): 空指针解引用、数组越界、栈溢出等。
无限循环或资源耗尽: 导致程序挂死,拒绝服务。
内存泄露: 长期运行后性能逐渐下降。
安全漏洞: 例如缓冲区溢出可能被恶意利用进行代码注入。
模糊测试:
模糊测试:是为了解决“你没想到的输入,会不会让程序崩溃”这一核心问题
案例分析:
模糊测试的作用到底体现在什么地方
案例 1:JSON 反序列化中的栈溢出:
json.Unmarshal包在处理深度嵌套的 JSON 结构时,如果递归层级过深,可能导致栈溢出进而引发程序崩溃。
如:{"a": {"b": {"c": {"d": ... }}}} // 嵌套 10000 层
传统测试:几乎不会构造一个嵌套上千层的对象来测试。
模糊测试:自动生成深度嵌套的 JSON 输入。
案例 2:空指针解引用:
验证一个消息对象是否符合预期的格式和规则。
type Message struct {Header *HeaderBody []byte
}func (m *Message) IsValid() bool {return m.Header.Version > 0 && m.Header.Length == len(m.Body)
}
传统测试:可能忽略Header为nil。
模糊测试:自动生成数据去验证。
3.模糊测试:自动化探索代码的“无人区”
Fuzzing 概览:它到底是什么,为什么这么强大?
模糊测试 (Fuzzing / Fuzz Testing) 是一种自动化测试技术。它的核心思想很简单:不断向你的程序提供大量随机的、畸形的、非预期的输入数据,然后观察程序是否会崩溃、死循环、泄露资源或出现其他异常行为。
模糊测试案例:
先说一个概念
什么是“有趣”?
就是导致新代码路径、失败或panic的输入
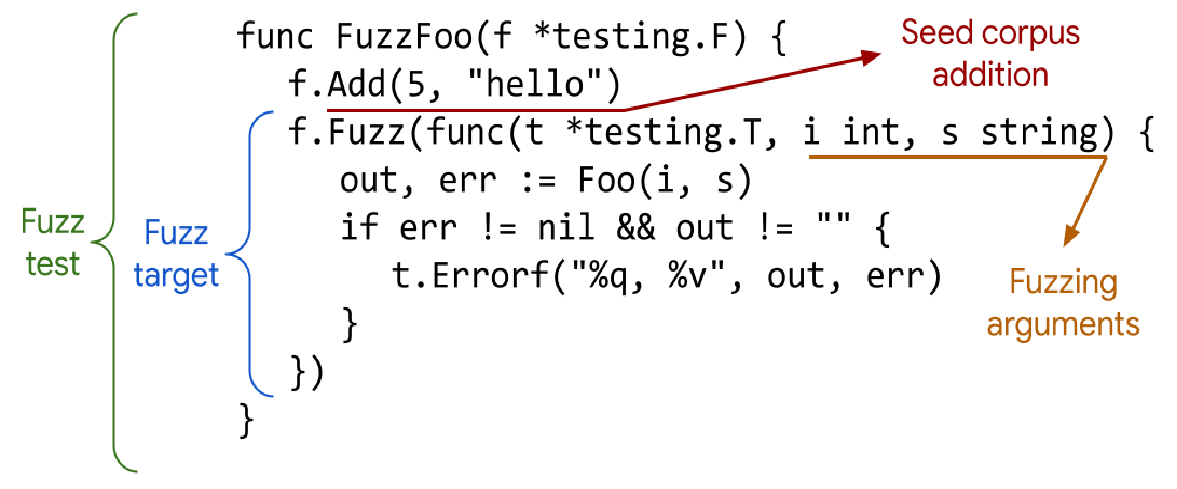
func FuzzReverse(f *testing.F) {// 1. 种子语料库testcases := []string{"Hello, world", " ", "!12345"}for _, tc := range testcases {f.Add(tc)}// 2. 模糊测试回调函数f.Fuzz(func(t *testing.T, orig string) {// 3. 待测试的代码和不变量检查rev := Reverse(orig)doubleRev := Reverse(rev)if orig != doubleRev {t.Errorf("Before: %q, after: %q", orig, doubleRev)}if utf8.ValidString(orig) && !utf8.ValidString(rev) {t.Errorf("Reverse produced invalid UTF-8 string %q", rev)}})
}1. 种子语料库(f.Add() )
种子语料库是模糊测试的“起点”。它由你手动提供的一组初始输入组成,通常是有效、典型或已知的边缘情况。
作用: 模糊测试器不是从零开始随机生成输入,而是以这些种子语料为基础,进行变异。提供高质量的种子语料可以帮助模糊测试器更快地探索到代码中的有趣路径。
存储: Go 会将这些种子语料自动存储在 testdata/fuzz/FuzzReverse 目录下,并以文件的形式保存。
对应到代码就是
testcases := []string{"Hello, world", " ", "!12345"}for _, tc := range testcases {f.Add(tc)}2. 基线覆盖率
基线覆盖率是指模糊测试器在正式开始变异之前,通过运行种子语料库中的所有输入所能达到的代码覆盖率。它像一张初始地图,标记了模糊测试已知的探索区域。
工作流程:
1.运行模糊测试
2.模糊测试器首先会执行 f.Fuzz 的回调函数,但输入只会是 {"Hello, world", " ", "!12345"} 这三个种子。
3.它会监控你的 Reverse 函数在处理这三个输入时,执行了哪些代码行和分支。
4.这部分代码所覆盖的路径,就是基线覆盖率。
作用: 基线覆盖率是模糊测试器判断一个新变异输入是否“有趣”的参照物。只有当新输入能够触发超出基线范围的代码路径时,模糊测试器才会认为它有价值。
3. 生成语料库
生成语料库是在模糊测试运行过程中,由模糊测试器自动创建和维护的。它包含所有能够触发新代码路径或导致程序异常的输入。
作用:
持续学习: 模糊测试器会优先从生成语料库中选择输入进行变异,而不是只依赖你最初的种子。这让测试变得越来越智能。
Bug 复现: 如果模糊测试发现一个 Bug,它会把导致 Bug 的具体输入保存为一个文件。这个文件就是生成语料库的一部分,你可以用它来精确地复现问题。
4. 模糊引擎(Fuzzing Engine)
模糊引擎,也叫模糊测试器,是执行模糊测试的核心工具。它不像单元测试那样依赖你预先编写的固定输入,而是能够自动化地、智能地生成大量随机、畸形或非预期的输入数据,并将其注入到你的程序中,以寻找那些导致崩溃、挂死或安全漏洞的隐藏 Bug。
组层:
1. 输入生成器:
这是模糊引擎的起点,负责产生最初的测试数据。
-
种子语料库 (Seed Corpus): 模糊引擎通常会从一个初始的种子语料库开始。这些语料是你预先提供的一些“好的”或典型的输入样本。高质量的种子语料能帮助引擎更快地探索到有趣的代码路径。
-
变异器 (Mutator): 这是引擎最关键的组件。它会从语料库中选取一个输入,然后对其进行一系列随机的、智能的“变异”操作来生成新的输入。常见的变异操作包括:
-
位/字节翻转: 随机改变输入中的某个位或字节。
-
插入/删除: 在输入中随机插入或删除一些字节。
-
拼接: 将两个不同的输入拼接在一起。
-
替换: 用一个预设的“魔术值”(如
0x00、0xFF、"AAA"等)替换输入中的某个部分。 这些操作旨在创造出各种“意想不到”的输入,从而挑战程序的健壮性。
-
2. 代码插桩器:
为了让模糊引擎“知道”它生成的输入是否有效,它需要能够监控程序的行为,主要就是监控作用。
如:
覆盖率收集:
-
基本代码块(Basic Block): 编译器会将程序分解成一个个基本代码块。如,
if语句的true和false分支,以及循环体,都是不同的基本代码块。 -
插桩过程: 插桩器会在每个基本代码块的入口处插入一段轻量级的代码。这段代码通常只有一个目的:向一个全局共享的、固定大小的数组(例如
cov_map)中写入数据。-
这个数组的每个元素都代表代码中的一个基本代码块。
-
当一个基本代码块被执行时,插入的代码会将其对应的数组元素值增加。
-
-
反馈机制: 模糊引擎在运行程序后,会检查这个
cov_map数组。通过对比新旧数组的状态,它就能判断新生成的输入是否执行了之前未探索过的基本代码块,从而实现了代码覆盖率引导。
崩溃检测是如何实现的?
模糊引擎会在运行你的程序之前,为其注册自定义的信号处理器。当程序发生崩溃时,操作系统会发送一个信号。当程序遇到这些信号后,程序就会执行我们自定义的处理代码。
性能监控是如何实现的?
性能监控主要用于检测无限循环或资源耗尽等问题,这些问题虽然不会直接导致崩溃,但会使程序无法正常响应,从而构成拒绝服务攻击(DoS)的威胁。
-
超时机制(Timeout): 模糊引擎会为每次程序执行设置一个超时时间。如果程序在规定的时间内没有返回结果,引擎就会判定它可能陷入了死循环,并强制终止该进程。
-
内存使用量监控: 模糊引擎会监控程序运行时的内存使用量。如果内存消耗超过了预设的阈值,引擎就会认为程序可能存在内存泄露,并终止这次测试。
3. 反馈循环
这是模糊引擎最智能的部分。
-
优胜劣汰: 模糊引擎会运行变异后的输入,然后分析代码覆盖率。如果一个输入触发了之前从未执行过的新代码路径,它就会被视为一个“有趣”的输入。
-
语料库更新: 引擎会将这个“有趣”的输入保存到语料库中。这样,语料库就会不断地“进化”,变得越来越擅长探索代码的盲区。
-
智能进化: 下一次,引擎会优先从这个包含“有趣”输入的新语料库中选取输入进行变异。通过这个持续的反馈循环,引擎能够高效地、有目的地探索代码,而不仅仅是盲目地随机测试。
4. 调度器
对于并发的模糊引擎,调度器负责管理模糊测试的并行化。
-
多核心利用: 它会在多个 CPU 核心上同时运行多个模糊测试进程(或 Goroutine)。
-
资源协调: 它负责在不同的进程之间同步语料库,确保每个进程都能利用其他进程发现的“有趣”输入。
4.亲手体验:编写与运行
条件:
1.安装 Go 1.18 或更高版本
2.支持模糊测试的环境。模糊覆盖范围 仪器目前仅适用于 AMD64 和 ARM64 架构。
3.文件名必须以 _test.go 结尾。模糊测试函数必须定义在*_test.go 文件中。
4.模糊测试只能测试接收基本类型参数的函数,如string,int ,uint,float32/64,bool,[]byte
5.函数名以 Fuzz 开头,接收 *testing.F 参数。
支持参数类型:
| 类型分类 | 具体类型 |
| 字符串/字节 | string, byte |
| 整型 | int, int8, int16, int32 (rune), int64 |
| 无符号整型 | uint, uint8 (byte), uint16, uint32, uint64 |
| 浮点型 | float32, float64 |
| 布尔型 | bool |
这里以反转字符为例,演示如何进行模糊测试
func main() {input := "The quick brown fox jumped over the lazy dog"rev := Reverse(input)doubleRev := Reverse(rev)fmt.Printf("original: %q\n", input)fmt.Printf("reversed: %q\n", rev)fmt.Printf("reversed again: %q\n", doubleRev)
}func Reverse(s string) string {b := []byte(s)for i, j := 0, len(b)-1; i < len(b)/2; i, j = i+1, j-1 {b[i], b[j] = b[j], b[i]}return string(b)
}这里先以单元测试为例;
对于输入的测试都能够通过,但是我们的代码真正没有问题吗?
func TestReverse(t *testing.T) {testcases := []struct {in, want string}{{"Hello, world", "dlrow ,olleH"},{" ", " "},{"!12345", "54321!"},}for _, tc := range testcases {rev := Reverse(tc.in)if rev != tc.want {t.Errorf("Reverse: %q, want %q", rev, tc.want)}}
}运行结果:=== RUN TestReverse
--- PASS: TestReverse (0.00s)
PASS
我们再通过模糊测试进行测试:
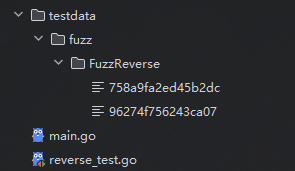
当模糊测试出现问题后回自动生成一个testdata目录,并把问题数据放在生成的文件里,并作为种子语料库的一部分,在下次运行使用。
出现问题的数据也会自动生成在FuzzReverse包下。
从运行结果看,我们的代码是有问题的。
一些字符可能是需要几个字节,逐字节反转字符串会使很多字节字符无效
func FuzzReverse(f *testing.F) {testcases := []string{"Hello, world", " ", "!12345"}for _, tc := range testcases {f.Add(tc)}f.Fuzz(func(t *testing.T, orig string) {rev := Reverse(orig)doubleRev := Reverse(rev)if orig != doubleRev {t.Errorf("Before: %q, after: %q", orig, doubleRev)}if utf8.ValidString(orig) && !utf8.ValidString(rev) {t.Errorf("Reverse produced invalid UTF-8 string %q", rev)}})
}运行结果:
=== RUN FuzzReverse
=== RUN FuzzReverse/seed#0
--- PASS: FuzzReverse/seed#0 (0.00s)
=== RUN FuzzReverse/seed#1
--- PASS: FuzzReverse/seed#1 (0.00s)
=== RUN FuzzReverse/seed#2
--- PASS: FuzzReverse/seed#2 (0.00s)
=== RUN FuzzReverse/758a9fa2ed45b2dcreverse_test.go:35: Reverse produced invalid UTF-8 string "\x81\xd7"
--- FAIL: FuzzReverse/758a9fa2ed45b2dc (0.00s)=== RUN FuzzReverse/96274f756243ca07
--- PASS: FuzzReverse/96274f756243ca07 (0.00s)
--- FAIL: FuzzReverse (0.02s)FAIL
改进一下Reverse()方法,按字符进行遍历。
func Reverse(s string) string {r := []rune(s)for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {r[i], r[j] = r[j], r[i]}return string(r)
}模糊测试运行:=== RUN FuzzReverse
=== RUN FuzzReverse/seed#0
--- PASS: FuzzReverse/seed#0 (0.00s)
=== RUN FuzzReverse/seed#1
--- PASS: FuzzReverse/seed#1 (0.00s)
=== RUN FuzzReverse/seed#2
--- PASS: FuzzReverse/seed#2 (0.00s)
=== RUN FuzzReverse/758a9fa2ed45b2dcreverse_test.go:32: Before: "\x81\xd7", after: "��"
--- FAIL: FuzzReverse/758a9fa2ed45b2dc (0.00s)--- FAIL: FuzzReverse (0.00s)FAIL再次进行模糊测试,还是出现了问题。Before: "\x81\xd7", after: "��" 说明在对"\xda"(一个无效的 UTF-8 序列)反转出现问题
改进一下Reverse()方法,如果是非法utf8字符直接返回。
func Reverse(s string) (string, error) {if !utf8.ValidString(s) {return s, errors.New("input is not valid UTF-8")}r := []rune(s)for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {r[i], r[j] = r[j], r[i]}return string(r), nil
}func FuzzReverse(f *testing.F) {testcases := []string{"Hello, world", " ", "!12345"}for _, tc := range testcases {f.Add(tc)}f.Fuzz(func(t *testing.T, orig string) {rev, err1 := Reverse(orig)if err1 != nil {return}doubleRev, err2 := Reverse(rev)if err2 != nil {return}if orig != doubleRev {t.Errorf("Before: %q, after: %q", orig, doubleRev)}if utf8.ValidString(orig) && !utf8.ValidString(rev) {t.Errorf("Reverse produced invalid UTF-8 string %q", rev)}})
}运行结果:
=== RUN FuzzReverse
=== RUN FuzzReverse/seed#0
--- PASS: FuzzReverse/seed#0 (0.00s)
=== RUN FuzzReverse/seed#1
--- PASS: FuzzReverse/seed#1 (0.00s)
=== RUN FuzzReverse/seed#2
--- PASS: FuzzReverse/seed#2 (0.00s)
=== RUN FuzzReverse/758a9fa2ed45b2dc
--- PASS: FuzzReverse/758a9fa2ed45b2dc (0.00s)
--- PASS: FuzzReverse (0.00s)
PASS
总结: 模糊测试利用其种自动化测试技术。不断向你的程序提供大量随机的、畸形的、非预期的输入数据。
我们在经过一次次模糊测试中一步步更改代码,直到正确,这是单元测试中很难做到的事情
5.Fuzzing vs. 单元测试:亦敌亦友,相辅相成
模糊测试和单元测试不是相互替代的关系,而是高度互补的。它们在软件质量保障中扮演着不同的角色。
目的不同:功能验证 vs. 健壮性探索
| 特性 | 单元测试 (Unit Testing) | 模糊测试 (Fuzz Testing) |
| 核心目的 | 验证代码在已知、预期输入下的功能正确性。 | 发现代码在未知、异常输入下的健壮性和安全性问题。 |
| 输入来源 | 开发者手动编写,基于对需求的理解。 | 模糊器自动化生成,智能变异现有语料。 |
| 输入范围 | 有限、典型、边界条件。 | 海量、随机、畸形、边缘情况。 |
| 关注点 | 行为符合预期 (即输出与预期一致)。 | 程序不崩溃、不死循环、不泄露资源。 |
| 发现问题 | 逻辑错误、功能缺失、API 契约不符。 | 程序崩溃、死循环、内存/资源泄露、拒绝服务、安全漏洞。 |
| 运行速度 | 快,适合频繁运行和 CI/CD。 | 慢,通常需要长时间运行才能发挥效果。 |
| 适用场景 | 几乎所有代码,尤其适用于业务逻辑的精确验证。 | 处理外部输入的模块(解析器、编解码器、网络协议等)。 |
| 提交版本控制 | TestXxx 测试代码。 | FuzzXxx 测试代码和语料库。 |
价值互补:共同构建无懈可击的代码防线
- 单元测试是基础: 它是你代码正确性的第一道防线。在编写任何功能时,首先要通过单元测试来确保其在正常和预期场景下是可靠的。
- 模糊测试是加强: 它是你代码健壮性的第二道防线。它弥补了单元测试的覆盖盲区,帮助你发现那些隐藏最深、最难以预测的 Bug,尤其是在安全性和稳定性方面。
最佳实践:如何让它们发挥最大效能?
- 单元测试先行: 始终遵循测试驱动开发或至少在编写功能后立即编写单元测试,确保核心逻辑的正确性。
- 为关键模块引入模糊测试: 识别项目中那些与外部、不可信数据打交道的组件(如协议解析、数据转换、文件读取器),它们是模糊测试的理想目标。
- 设计高质量的种子语料: 提供少量但能覆盖不同分支的有效输入作为种子,能显著提高模糊测试的效率。
6.参考来源:
Tutorial: Getting started with fuzzing - The Go Programming Language
Go Fuzzing - The Go Programming Language







![C语言-指针[指针数组和数组指针]](http://pic.xiahunao.cn/C语言-指针[指针数组和数组指针])





免安装中文版)





