Amazon S3(Amazon Simple Storage Service)即亚马逊简单存储服务,是 AWS(Amazon Web Services)提供的一种对象存储服务,在大数据领域被广泛使用。以下是关于它的详细介绍:
基本概念
Amazon S3 主要用于存储和检索任意数量的数据。这里的数据以对象(Object)的形式存在,每个对象由数据本身、键(Key,类似于文件名,用于唯一标识对象)和元数据(Metadata,如文件大小、创建时间、自定义标签等信息)组成。对象被存储在存储桶(Bucket)中,存储桶可以看作是存放对象的容器, 它有一个在全球范围内唯一的名称,用户可以创建多个存储桶,并对存储桶和其中的对象进行管理。
主要特点
- 高持久性:Amazon S3 设计目的是为了实现数据的高持久性,承诺提供 99.999999999%(11 个 9)的对象持久性。这意味着数据丢失的可能性极低,它通过在多个设施和多个设备上自动存储数据的多个副本,来确保即使在出现硬件故障、自然灾害等意外情况时,数据也不会丢失。
- 无限可扩展性:S3 能够存储几乎无限量的数据,无论是少量的文件还是 PB 级甚至 EB 级的海量数据,都可以轻松存储。用户不需要担心存储容量的限制,并且可以根据实际存储需求自动扩展。
- 高可用性:具有较高的可用性,能够保证用户可以随时访问存储的数据。AWS 在全球分布有多个区域(Region)和可用区(Availability Zone),用户可以选择将数据存储在离自己较近或符合业务需求的区域,同时,S3 会在可用区内自动复制数据,以保障数据的高可用性。
- 安全可靠:提供了多种安全功能,包括身份验证(通过 AWS 访问密钥进行用户身份验证)、访问控制(可以使用访问控制列表 ACL 和桶策略来管理对存储桶和对象的访问权限)、数据加密(支持静态加密,包括 S3 托管密钥 SSE - S3、AWS Key Management Service 托管密钥 SSE - KMS 以及客户管理密钥 CSE - CKM)等,确保数据的安全性。
- 灵活性:支持各种类型的数据存储,包括文本文件、图像、视频、备份数据、日志文件、数据库转储等。并且提供了丰富的 API(Application Programming Interface),可以通过编程方式与 S3 进行交互,方便集成到各种应用程序和工作流程中 。
应用场景
- 数据湖:作为构建数据湖的基础存储,用于集中存储来自不同数据源(如业务系统数据库、物联网设备、移动应用等)的结构化、半结构化和非结构化数据,以便后续进行数据分析、机器学习等操作。例如,电商公司可以将用户订单数据、商品信息、用户行为日志等各种数据都存储在 S3 中,然后通过大数据分析工具进行深入挖掘,了解用户购买行为和偏好。
- 数据备份与存档:适合长期保存不经常访问但需要保留的数据,如企业的历史交易记录、医疗记录、法律合规文件等。S3 提供了不同的存储级别(如标准存储、标准 - infrequent Access(标准 IA)、One Zone - Infrequent Access(单区 IA)、Glacier、Glacier Deep Archive 等),用户可以根据数据的访问频率和保留期限,选择成本最优的存储级别。
- 内容分发:可以与 Amazon CloudFront(内容分发网络 CDN)结合使用,用于快速分发网站内容、软件安装包、视频流等。CloudFront 会在全球的边缘位置缓存 S3 中的内容,使用户能够从离自己最近的位置获取数据,提高访问速度和用户体验。
- 大数据处理:与 AWS 上的其他大数据服务(如 AWS Glue、Amazon EMR 等)紧密集成。例如,Amazon EMR 集群可以直接读取和处理存储在 S3 中的数据,进行大规模的数据处理和分析任务,如日志分析、数据清洗、机器学习模型训练等。
AWS Glue 是亚马逊云服务(AWS)提供的一项无服务器(Serverless)数据集成服务,专注于元数据管理和 ETL(Extract,Transform,Load,即提取、转换、加载)操作。以下为你详细介绍:
无服务器(Serverless)特性
- 无需管理基础设施:使用 AWS Glue 时,用户无需操心服务器的配置、搭建、维护等工作,比如硬件选型、软件安装与更新、服务器的日常监控等。AWS 会自动处理底层资源的分配、扩展和维护,极大地减少了运维成本和工作量。
- 按需付费:AWS Glue 根据实际使用的资源(如执行 ETL 作业的时长、处理的数据量等)来计费。在没有作业运行时,用户无需支付计算资源的费用,相比传统的自管理服务器方式,成本更加可控,尤其适合数据处理量有较大波动的场景。
元数据管理
- 数据目录(Data Catalog):这是 AWS Glue 元数据管理的核心组件,它是一个集中式的存储库,用于存储和管理数据资产的元数据信息,包括数据库、表、分区等。例如,在一个电商数据湖中,Data Catalog 可以记录用户订单表、商品信息表等的表结构(字段名称、数据类型、长度等)、数据存储位置(如存储在 Amazon S3 的具体路径)、表的分区方式(按日期分区、按地区分区等)。
- 爬虫(Crawlers):这是 AWS Glue 用于自动发现和提取元数据的工具。用户可以配置爬虫,让它扫描各种数据源,比如 Amazon S3 存储桶、关系型数据库(如 Amazon RDS 中的 MySQL、PostgreSQL 等)、NoSQL 数据库(如 Amazon DynamoDB)等。爬虫会自动识别数据格式(CSV、JSON、Parquet 等),并将解析出的元数据写入 Data Catalog 。比如,当新一批用户行为日志数据被上传到 S3,配置好的爬虫就可以快速识别日志文件的结构,将相关元数据添加到 Data Catalog,方便后续分析。
- 统一视图:Data Catalog 为不同数据源提供了统一的元数据视图,使得不同的分析工具(如 Amazon EMR 上的 Hive、Spark,Amazon Athena 等)可以共享和访问这些元数据,避免了重复定义元数据的麻烦,提高了数据发现和使用的效率。
ETL 功能
- 可视化界面与代码编写:AWS Glue 提供了可视化的 ETL 作业编辑器,用户可以通过简单的拖拽操作来定义数据的提取、转换和加载流程,无需编写大量代码,降低了 ETL 开发的门槛。同时,也支持使用 Python、Scala 等编程语言编写自定义的转换逻辑,以满足复杂的数据处理需求。例如,对于一个包含用户注册信息的 CSV 文件,用户可以在可视化界面中轻松设置提取特定字段(如用户名、邮箱、注册时间),对邮箱进行格式校验和脱敏等转换操作,然后将处理后的数据加载到目标数据库中。
- 丰富的内置转换:AWS Glue 内置了多种常见的数据转换功能,如数据类型转换(将字符串类型的日期转换为日期类型)、数据清洗(去除重复记录、填充缺失值)、数据聚合(求和、平均值计算等)、数据过滤(筛选出特定地区的用户数据)等。这些内置转换可以通过可视化界面快速配置,加快 ETL 作业的开发速度。
- 与其他 AWS 服务集成:AWS Glue 可以与 Amazon S3、Amazon Redshift、Amazon EMR 等众多 AWS 服务无缝集成。比如,从 S3 中提取原始数据进行处理,将处理后的数据加载到 Redshift 用于数据分析;或者将 ETL 作业提交到 EMR 集群上运行,利用 EMR 的计算资源处理大规模数据。
典型应用场景
- 构建数据湖:在数据湖架构中,使用 AWS Glue 的爬虫发现和管理存储在 S3 中的各种数据的元数据,通过 ETL 作业清洗、转换数据,为后续的数据分析师、数据科学家提供高质量的分析数据。
- 数据仓库 ETL:将不同数据源(如业务系统数据库、日志文件)的数据,通过 AWS Glue 进行 ETL 处理后,加载到数据仓库(如 Amazon Redshift)中,支持业务报表生成、决策支持等场景。
- 数据迁移:当需要将数据从一个数据源迁移到另一个数据源时,AWS Glue 可以帮助进行数据提取、格式转换和加载,实现数据的平滑迁移,比如从本地数据库迁移到 AWS 上的数据库。
Amazon EMR on EC2(Elastic MapReduce on Amazon Elastic Compute Cloud )是 AWS(Amazon Web Services)提供的一项托管式大数据分布式计算服务,主要用于运行 Apache Hadoop、Apache Spark、Apache Flink 等开源分布式计算框架集群,帮助用户轻松处理和分析大规模数据。以下是详细介绍:
服务概述
- 托管服务:AWS 负责处理集群的搭建、配置、监控和维护等繁琐工作,比如安装和配置 Hadoop、Spark、Flink 等软件,管理集群节点的硬件资源(CPU、内存、存储等)。用户无需关心底层基础设施的运维细节,专注于数据分析和应用开发。
- 基于 EC2:利用 Amazon EC2(弹性计算云)的资源来创建集群节点。EC2 提供了多种类型的实例(如计算优化型、内存优化型、存储优化型等),用户可以根据具体的计算任务需求,灵活选择合适的实例类型构建集群,并且可以根据数据处理量的大小动态地增加或减少集群节点数量,实现资源的弹性伸缩。
支持的计算框架
- Apache Hadoop:
- 批处理:作为 Hadoop 生态系统的核心,MapReduce 是 Hadoop 的经典计算模型,适用于大规模数据集的离线批处理作业。例如,对电商平台海量的历史订单数据进行统计分析(如计算各地区的销售额、各类商品的销售数量等),可以将数据存储在 Hadoop 分布式文件系统(HDFS)中,通过 EMR 上的 Hadoop 集群运行 MapReduce 作业来完成计算任务。
- 数据存储:HDFS 提供了高吞吐量的数据访问,能够存储 PB 级的大规模数据,并且通过数据副本机制保证数据的可靠性和可用性。
- Apache Spark:
- 通用计算引擎:Spark 比 MapReduce 具有更高的执行效率,支持多种编程模型,如批处理、流处理、机器学习和图计算等。在 EMR 上,用户可以使用 Spark 进行复杂的数据处理任务,例如在实时推荐系统中,利用 Spark Streaming 处理用户实时行为数据,结合机器学习算法(MLlib)为用户实时推荐感兴趣的商品。
- 内存计算:Spark 能够将数据缓存到内存中进行计算,减少对磁盘 I/O 的依赖,大大加快了数据处理速度,尤其适合迭代式计算(如机器学习中的梯度下降算法)和交互式数据分析。
- Apache Flink:
- 实时流处理:Flink 是一个强大的流处理框架,具有低延迟、高吞吐和准确的语义保证。在 EMR 上运行 Flink,可以用于处理实时数据,如实时监控网络流量、金融交易实时风控等场景。例如,对股票交易的实时数据流进行处理,及时发现异常交易行为并触发警报。
- 批处理能力:除了流处理,Flink 也支持批处理,并且在批处理性能上表现出色,能够高效处理大规模的静态数据集。
优势
- 弹性伸缩:用户可以根据业务需求和数据量的变化,通过简单的操作(如 API 调用、控制台操作)动态地增加或减少集群节点数量。比如在业务高峰期,增加节点以提高数据处理速度;在业务低谷期,减少节点以降低成本。
- 高可用性:通过多可用区部署、数据备份与恢复等机制,保证集群的高可用性。即使某个节点或可用区出现故障,集群也能继续运行,并且数据不会丢失。
- 丰富的生态集成:无缝集成 AWS 其他服务,如 Amazon S3(作为数据存储)、AWS Glue(用于数据集成和元数据管理)、Amazon Redshift(数据仓库)等。方便用户构建端到端的大数据处理和分析解决方案,例如从 S3 中读取原始数据,利用 EMR 上的 Spark 进行处理,然后将结果写入 Redshift 供业务人员进行数据分析。
- 成本控制:按使用付费模式,用户只需为实际使用的计算资源(EC2 实例运行时间、存储等)付费,避免了资源闲置造成的浪费。同时,通过合理配置集群规模和实例类型,可以进一步优化成本。
应用场景
- 日志分析:收集和处理来自网站、应用程序、服务器等的海量日志数据,通过 EMR 上的 Hadoop 或 Spark 进行清洗、解析和分析,挖掘有价值的信息,如用户行为模式、系统性能瓶颈等。
- 基因数据分析:在生物信息领域,处理大规模的基因测序数据。利用 EMR 上的计算框架,进行序列比对、变异检测等复杂计算任务。
- 金融风险评估:对金融机构的大量交易数据进行实时和离线分析,使用 Flink 进行实时流处理监测异常交易,使用 Spark 进行历史数据挖掘和风险评估模型训练。
Amazon Redshift 是 AWS 推出的一款云端数据仓库服务,专为高效处理大规模数据的分析工作负载而设计,能够支持 PB 级别的数据存储与分析,在企业级数据分析领域应用广泛,以下是对它的详细介绍:
关键特性
- 大规模并行处理(MPP)架构:
- 原理:Redshift 采用 MPP 架构,将数据分布存储在多个节点上,每个节点都有独立的计算和存储资源。在执行查询时,这些节点可以并行处理数据,极大地提高了查询性能。例如,当企业需要分析数百万行的销售记录,查找不同地区、不同时间段的销售趋势时,Redshift 可以将数据分割,让多个节点同时进行计算,快速得出结果。
- 优势:这种架构使 Redshift 能够轻松应对复杂的分析查询,即使处理 PB 级别的海量数据,也能保持高效,满足企业对大数据快速分析的需求。
- 列式存储:
- 原理:与传统的行式存储不同,Redshift 将数据按列存储。在数据仓库场景中,分析查询通常只涉及部分列,列式存储可以避免读取不必要的列数据,减少 I/O 操作。比如在分析客户数据时,若只需要查询客户的购买金额和购买时间,列式存储只需读取这两列的数据,而无需读取整行数据。
- 优势:列式存储还能对数据进行高效压缩,进一步减少存储空间,提高数据读取和处理效率。
- 与 AWS 生态深度集成:
- 数据存储集成:可以直接从 Amazon S3 快速加载数据,S3 作为数据湖,能够存储各种原始数据,Redshift 利用自身的 COPY 命令,能高效地将 S3 中的数据导入到数仓中,为数据分析提供丰富的数据源。
- 分析工具集成:无缝对接 Amazon QuickSight、Tableau 等商业智能(BI)工具,用户可以方便地连接到 Redshift,进行数据可视化和交互式分析,快速生成报表和洞察。此外,还支持与 AWS Glue 集成,借助 Glue 的 ETL 能力,对数据进行清洗、转换后再加载到 Redshift 中。
- 自动扩展:
- 原理:用户可以根据业务需求和数据增长情况,通过简单的操作增加或减少 Redshift 集群中的节点数量。AWS 会自动管理数据在节点之间的重新分布,确保查询性能不受影响。
- 优势:这种自动扩展功能使得企业无需担心数据仓库的容量限制,在数据量不断增长时,能够灵活调整资源,同时也避免了过度预配置资源带来的成本浪费。
数据加载方式
- COPY 命令:这是最常用的数据加载方式,支持从 Amazon S3、Amazon DynamoDB 等数据源快速加载数据。COPY 命令具有高度的可配置性,可以指定数据格式(如 CSV、JSON、Parquet 等)、压缩方式等参数。例如,将存储在 S3 中的每日销售数据加载到 Redshift 中,只需简单配置 COPY 命令,就能高效完成数据导入,且支持并行加载,加快数据加载速度。
- SQL 接口:通过标准的 SQL 语句,如 INSERT INTO 等,也可以将数据插入到 Redshift 表中。不过,这种方式更适合少量数据的插入,对于大规模数据加载,COPY 命令通常效率更高。
应用场景
- 企业报表与商业智能:企业可以将来自多个业务系统的数据(如销售系统、库存系统、客户关系管理系统等)汇总到 Redshift 中,利用 BI 工具进行可视化分析,生成各种报表,帮助管理层进行决策。例如,零售企业通过分析 Redshift 中的销售数据、库存数据,了解商品的销售情况,优化库存管理和商品采购策略。
- 数据分析与数据挖掘:数据科学家和分析师可以在 Redshift 上进行复杂的数据分析和数据挖掘工作。比如,电信企业利用 Redshift 分析用户的通话记录、上网行为数据,挖掘用户的消费习惯和潜在需求,制定精准的营销策略。
- 广告与营销分析:广告平台可以将广告投放数据、用户点击数据等存储在 Redshift 中,分析广告效果,优化广告投放策略。例如,通过分析不同广告渠道的转化率、用户留存率等指标,确定最有效的广告投放渠道,提高广告投资回报率。
Amazon S3 — 数据湖统一存储层
作用:作为整个架构的 “数据湖”,存储所有原始数据(结构化、半结构化、非结构化),如日志文件、CSV/JSON、图片、视频等。
场景:接收来自各类数据源的数据(如 IoT 设备、应用日志、数据库备份等),作为所有后续处理的 “数据源” 和 “结果存储地”。
AWS Glue — Serverless 元数据 & ETL
数据目录(Data Catalog):集中管理全量数据的元数据(表结构、分区、数据位置等),相当于 “数据湖的目录服务”,让 Hive/Spark 等工具能快速识别数据结构。
Amazon EMR on EC2[分布式计算引擎] —— 托管 Hadoop/Spark/Flink 集群
作用:基于 EC2 实例创建的分布式计算集群,提供 Hadoop 生态系统的核心工具,支持大规模数据处理。
核心框架(运行在 EMR 上):
Hive:基于 Hadoop 的 “数据仓库工具”,通过类 SQL(HQL)语法查询 S3 中的数据,适合离线批处理分析(如统计报表)。
Spark:快速通用的计算引擎,支持批处理、流处理、机器学习(MLlib),比 MapReduce 性能更高,适合复杂数据处理(如用户行为分析、特征工程)。
Flink:实时流处理引擎,擅长低延迟、高吞吐的实时数据处理(如实时监控、实时推荐),也支持批处理。
Amazon Redshift — PB 级云数仓
作用:基于列式存储的企业级数据仓库,专为高性能分析和复杂查询设计,支持 PB 级数据的快速查询。
场景:接收经 Glue/EMR 处理后的 “干净数据”,供业务人员通过 BI 工具(如 Amazon QuickSight、Tableau)进行交互式分析、生成报表。
与其他组件集成:
可直接从 S3 加载数据(通过 COPY 命令),或接收 Glue ETL 的输出结果。
支持与 Spark 集成,将分析结果写回 Redshift 供进一步查询。
AWS数据处理全流程
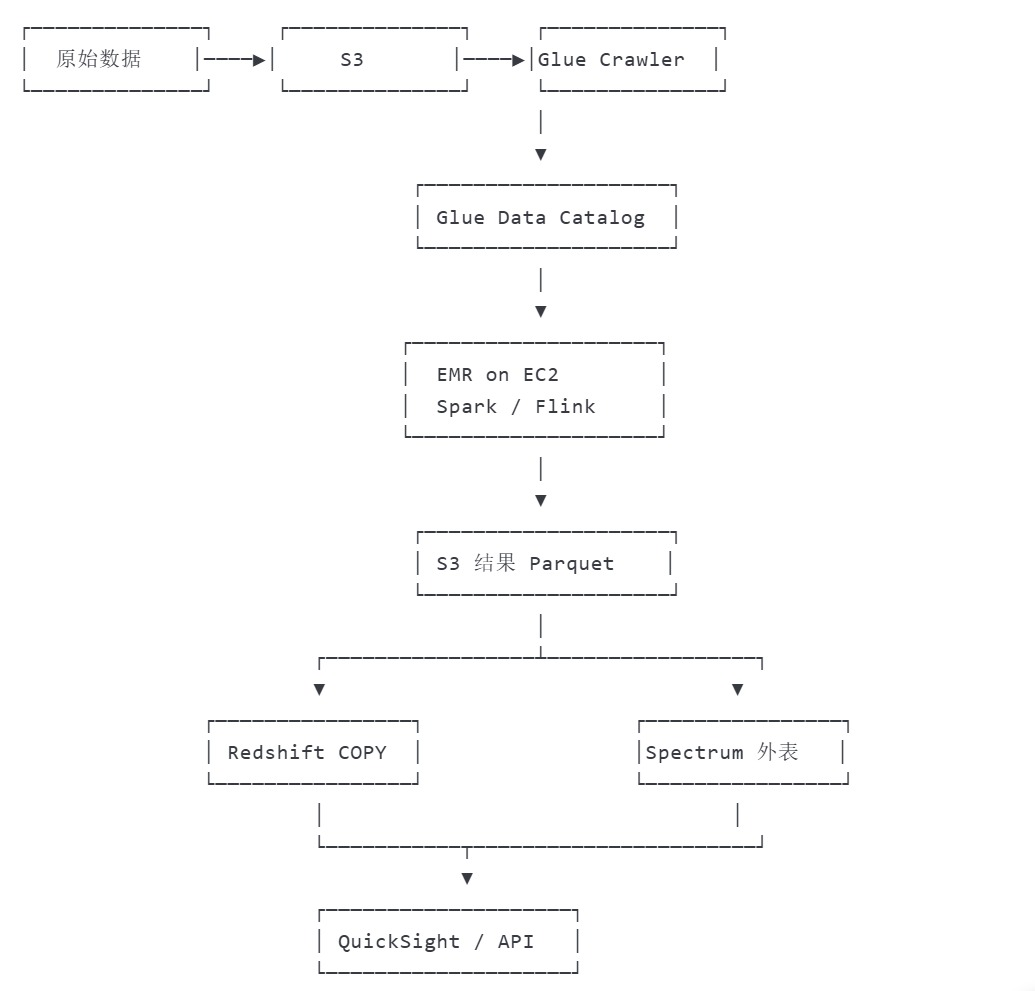
用户行为数据分析流程
总结:
S3 存一切,
Glue 管元数据 + 轻量 ETL,
EMR on EC2 跑大规模 Spark/Flink/Hive,
Redshift 做高性能数仓 & 直接“湖上查询”。







:使用云平台最小外部依赖方案)







服务器/多客户端模型)


——设备树(上))
)