1. 什么是 Deque?
- 核心概念: Deque 是 “Double-Ended Queue”(双端队列)的缩写。你可以把它想象成一个可以在两端(头部和尾部)高效地进行添加或删除操作的线性数据结构。
- 关键特性:
- 双端操作: 这是 deque 最显著的特点。你可以在队列的开头(front) 或结尾(back) 快速地插入(
push_front,push_back)或删除(pop_front,pop_back)元素。 - 顺序容器: 元素在 deque 中是按顺序存储的,每个元素都有一个确定的位置(索引)。你可以像数组或 vector 一样,通过下标
operator[]或at()来随机访问任意位置的元素(效率接近 O(1),但比 vector 稍慢一点,后面解释原因)。 - 动态大小: 和 vector、list 一样,deque 可以根据需要动态地增长或缩小,你不需要预先指定其大小。
- 双端操作: 这是 deque 最显著的特点。你可以在队列的开头(front) 或结尾(back) 快速地插入(
- 形象比喻: 想象一个特殊的书架(或者更准确地说,一组小书架拼成的大书架):
- 你既可以从书架的最左边(front) 快速地拿走或放入一本书。
- 也可以从书架的最右边(back) 快速地拿走或放入一本书。
- 你还可以直接走到书架中间某个编号的位置(索引),快速找到并取阅(访问)那本书。
- 当一个小书架放满了,管理员可以轻松地在最左边或最右边拼接一个新的空小书架,而不需要把整个大书架的书都重新整理一遍(这是它和 vector 扩容的关键区别)。
2. Deque 的内部实现机制(理解其高效性的关键)
这是理解 deque 为何能在两端高效操作,以及其随机访问性能、内存特性的核心。典型的 STL 实现(如 GCC 的 libstdc++ 或 Clang 的 libc++)采用一种叫做 “分块数组” 或 “块链” 的策略:
- 不是一整块连续内存: 不像
std::vector总是试图维护一整块大的连续内存空间。 - 由多个固定大小的 “块”(Chunks / Blocks) 组成: Deque 内部管理着一个数组(通常叫
map或block map),这个数组的每个元素是一个指针,指向一个固定大小的内存块。 - 块内连续,块间不连续: 每个内存块内部是连续存储元素的。但是,不同的内存块在物理内存上不一定是连续的。这些块通过
map数组组织起来。 map数组本身也是动态数组: 这个指向块的指针数组 (map) 本身也是一个动态数组(通常实现为 vector)。当 deque 增长导致需要更多的块时,这个map数组也可能需要扩容(重新分配和复制指针),但这比 vector 扩容(复制所有元素)开销小得多。- 维护关键指针/迭代器: Deque 对象内部维护几个关键信息:
- 指向
map数组的指针。 map数组的大小(能容纳多少块指针)。- 指向第一个元素所在块的指针(
start迭代器或类似结构,包含块指针、当前块内起始位置)。 - 指向最后一个元素所在块的下一个位置的指针(
finish迭代器或类似结构,包含块指针、当前块内结束位置)。 - 通常还会缓存第一个和最后一个元素在各自块内的具体位置。
- 指向
大家可以通过下面这3幅图来大概理解一下deque的结构:
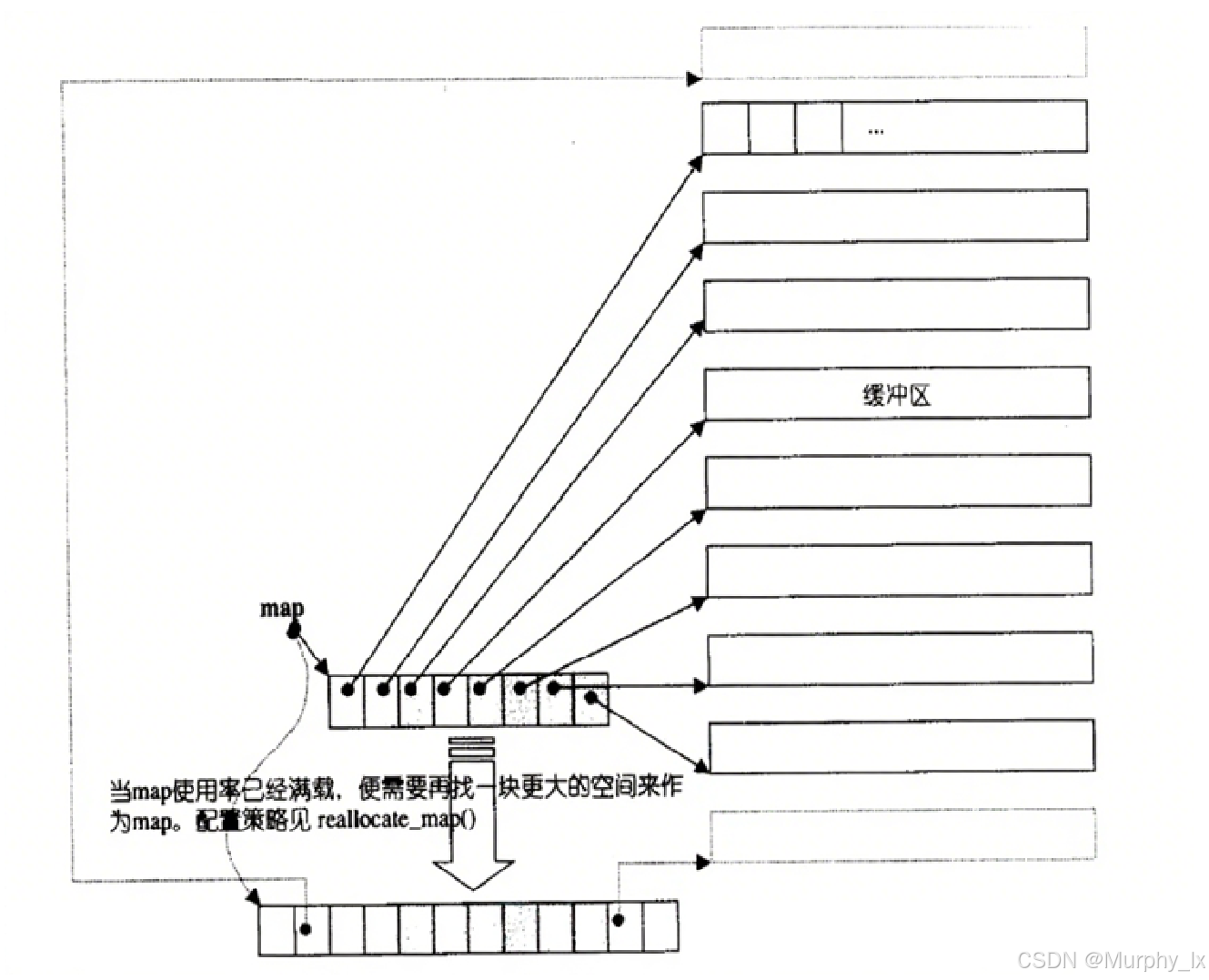
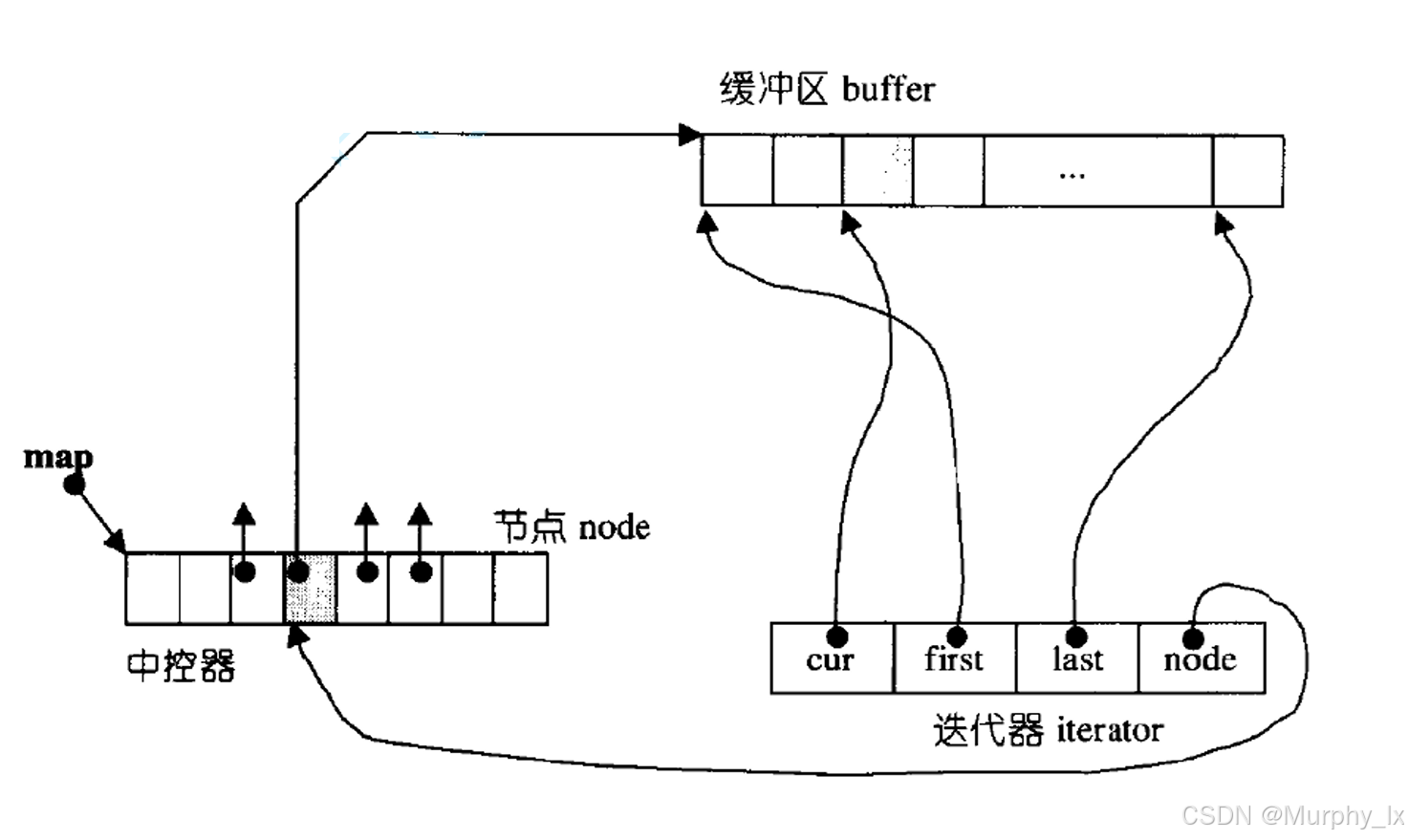
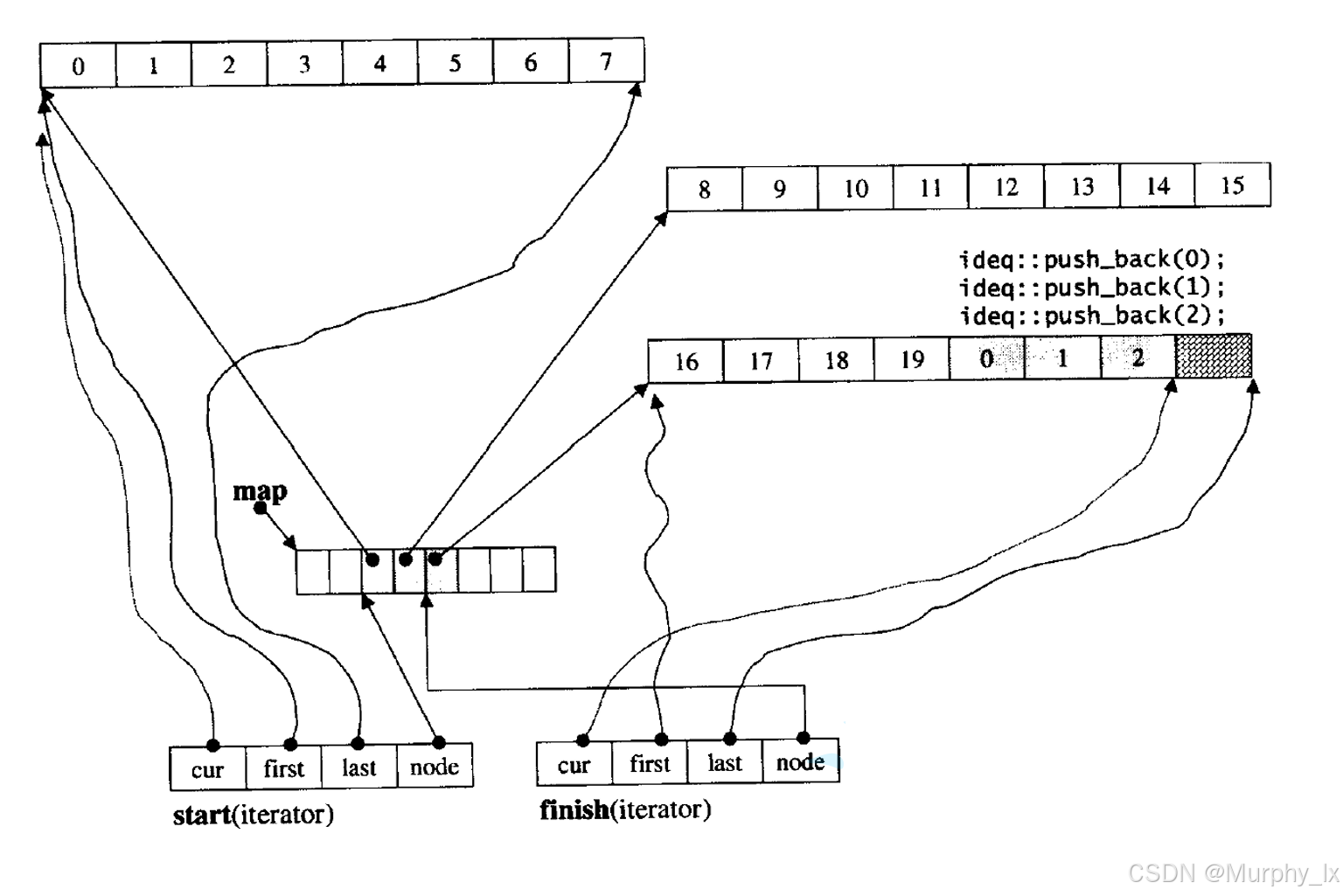
为什么这种结构支持高效的双端操作?
- 在头部插入(
push_front):- 检查第一个块
start指向的块是否还有空间(在头部方向)。 - 如果有空间: 直接在那个块的空位(
start指针前面)放入新元素,更新start的位置信息。非常快 (O(1))。 - 如果没空间: 在
map数组的前端(或找到一个空闲位置)分配一个新块,将新元素放入新块的末尾位置(因为新块要加在最前面),然后更新map和start指向这个新块。如果map数组前端没空间了,可能需要重新分配并复制map(这个开销相对小,因为只复制指针)。均摊复杂度接近 O(1)。
- 检查第一个块
- 在尾部插入(
push_back):- 检查最后一个块
finish指向的块是否还有空间(在尾部方向)。 - 如果有空间: 直接在那个块的空位放入新元素,更新
finish的位置信息。非常快 (O(1))。 - 如果没空间: 在
map数组的后端分配一个新块,将新元素放入新块的开头位置,更新map和finish。同样,map扩容开销较小。均摊复杂度接近 O(1)。
- 检查最后一个块
- 在头部删除(
pop_front):- 直接移除
start当前指向的元素。 - 更新
start指向下一个位置(或下一个块的开头,如果当前块删空了)。 - 如果当前块变空,可以释放它(可选,实现可能缓存空块)。O(1)。
- 直接移除
- 在尾部删除(
pop_back):- 直接移除
finish前一个位置的元素(finish通常指向最后一个元素的下一个位置)。 - 更新
finish指向前一个位置(或前一个块的末尾,如果当前块删空了)。 - 同样,空块可能被释放或缓存。O(1)。
- 直接移除
为什么随机访问是 O(1)(接近)?
- 计算目标元素位置: 假设每个块固定大小为
block_size(例如 512 字节或存 16/32/64 个元素,取决于元素大小和实现)。 - 定位块: 要访问索引
i处的元素:- 首先计算它在哪个块:
block_index = (i + start_block_offset) / block_size(需要知道start块在map中的位置和start在它自己块内的偏移)。 - 然后在
map[block_index]指向的块内找到偏移:offset_in_block = (i + start_block_offset) % block_size。
- 首先计算它在哪个块:
- 直接访问: 通过
map[block_index] + offset_in_block直接访问元素。 - 开销: 这个过程涉及几次整数除法和取模运算(现代 CPU 很快),以及两次指针解引用(访问
map数组,再访问具体块)。这比 vector 的一次指针偏移访问(start_pointer + i * element_size)略慢,但复杂度仍然是常数时间 O(1)。这是“接近 O(1)”的含义,实际常数因子比 vector 大。
3. Deque 的核心操作与复杂度
| 操作 | 函数 | 时间复杂度 | 说明 |
|---|---|---|---|
| 头部插入 | push_front(value) | 均摊 O(1) | 在开头添加一个元素。非常高效。 |
| 尾部插入 | push_back(value) | 均摊 O(1) | 在末尾添加一个元素。非常高效。 |
| 头部删除 | pop_front() | O(1) | 移除开头元素。非常高效。 |
| 尾部删除 | pop_back() | O(1) | 移除末尾元素。非常高效。 |
| 随机访问 | operator[], at | O(1) | 通过索引访问元素。效率接近 vector,常数因子略高。at 会进行边界检查。 |
| 访问头部元素 | front() | O(1) | 返回开头元素的引用。 |
| 访问尾部元素 | back() | O(1) | 返回末尾元素的引用。 |
| 中间插入 | insert(pos, value) | O(n) | 在迭代器 pos 指定的位置插入元素。需要移动后续元素,效率较低。 |
| 中间删除 | erase(pos) | O(n) | 删除迭代器 pos 指定的元素。需要移动后续元素,效率较低。 |
| 获取大小 | size() | O(1) | 返回当前元素数量(通常内部维护)。 |
| 检查是否空 | empty() | O(1) | 检查 deque 是否为空。 |
| 清空 | clear() | O(n) | 删除所有元素。通常会释放所有内存块(实现可能缓存空块)。 |
4. Deque 的迭代器失效规则(重要!)
理解迭代器何时失效对安全使用容器至关重要:
- 插入(
push_front,push_back,insert):push_front/push_back: 通常只使所有迭代器失效(但指向元素的引用和指针通常仍然有效!)。 为什么?因为map数组可能重新分配,导致指向块的指针改变。不过,重要提示:大多数现代实现保证push_front/push_back不会使指向已有元素的引用和指针失效(失效的是迭代器本身,因为它可能存储了块指针和位置信息)。这是标准允许但不强制的,主流实现(libstdc++, libc++)都提供了这个保证。如果插入导致新块分配,map重分配,则所有迭代器失效(引用/指针仍然指向有效元素)。如果没导致新块/map重分配,可能只有end()迭代器失效(实现细节)。最安全保守的做法是:在push_front/push_back后,假设所有迭代器可能失效(除非你明确知道当前实现和容量情况)。引用和指针通常安全。insert(pos, value)(在中间插入): 使所有指向插入位置之后(包括pos本身)的迭代器、引用和指针失效。 因为需要移动后面的元素。
- 删除(
pop_front,pop_back,erase):pop_front: 使指向被删除元素(第一个元素)的迭代器、引用和指针失效。front()返回的引用也失效。其他迭代器/引用/指针通常安全。pop_back: 使指向被删除元素(最后一个元素)的迭代器、引用和指针失效。back()返回的引用也失效。其他迭代器/引用/指针通常安全。erase(pos)(在中间删除): 使所有指向被删除元素及其之后位置的迭代器、引用和指针失效。 因为需要移动后面的元素填补空缺。
swap: 交换两个 deque 后,两个 deque 的所有迭代器、引用和指针都会交换它们的有效性。原来指向 deque A 的迭代器现在指向 deque B 中的对应元素(如果还有效的话),反之亦然。clear: 所有迭代器、引用和指针失效。
总结关键点: 在 deque 中间进行插入或删除操作是昂贵的(O(n))且会使相关迭代器失效。在两端操作非常高效,并且通常不会使指向已有元素的引用和指针失效(迭代器本身需要谨慎对待,特别是push_front/push_back之后)。
5. Deque 的典型应用场景
- 双端队列操作: 这是最直接的用途,当你需要一个队列,但频繁需要同时在队头和队尾进行操作时。例如:
- 任务调度器: 一些系统可能从队列头部取任务执行,但也允许高优先级任务插入到队列头部(
push_front)。 - 撤销/重做(Undo/Redo)历史记录: 新操作
push_back,撤销时pop_back,重做可能需要访问尾部附近。 - 滑动窗口算法: 需要高效地移除窗口左端元素(
pop_front)和添加右端元素(push_back),同时可能需要随机访问窗口内的任意元素来计算最大值、最小值、平均值等。
- 任务调度器: 一些系统可能从队列头部取任务执行,但也允许高优先级任务插入到队列头部(
- 需要高效随机访问,且插入主要在两端: 如果你需要一个支持随机访问(像数组)的容器,但插入和删除操作主要发生在开头或结尾,而不是中间,那么 deque 是比 vector 更好的选择。Vector 在头部插入/删除是 O(n) 的灾难。
- 替代 vector 的谨慎选择: 当你对 vector 在尾部插入导致扩容并复制所有元素的性能开销非常敏感,并且你同时需要在头部进行插入操作时。Deque 扩容(添加新块)的开销更小、更平摊。但要注意 deque 的随机访问稍慢且内存占用通常更大。
6. Deque vs. Vector vs. List
| 特性 | std::deque | std::vector | std::list |
|---|---|---|---|
| 内部结构 | 分块数组 (块链) | 单一动态数组 | 双向链表 |
| 内存连续性 | 块内连续,块间不连续 | 完全连续 | 完全不连续 |
| 随机访问 | O(1) (接近 vector) | O(1) (最快) | O(n) (慢) |
| 头部插入/删除 | O(1) (高效) | O(n) (低效, 需要移动所有元素) | O(1) (高效) |
| 尾部插入/删除 | O(1) (高效) | 均摊 O(1) (高效, 除非扩容) | O(1) (高效) |
| 中间插入/删除 | O(n) (需要移动元素) | O(n) (需要移动元素) | O(1) (已知位置迭代器) |
| 迭代器失效 (尾部插入) | 可能失效 (若导致map重分配) | 可能失效 (若扩容) | 通常不失效 |
| 迭代器失效 (头部插入) | 可能失效 (若导致map重分配) | 总是失效 | 通常不失效 |
| 内存使用 | 较高 (块指针数组+可能空余空间) | 较低 (但尾部可能有预留空间) | 较高 (每个元素需额外指针开销) |
| 缓存友好性 | 中等 (块内友好) | 非常好 (整个数组连续) | 差 (元素分散) |
| 主要优势 | 高效双端操作 + 不错随机访问 | 极致随机访问 + 尾部高效插入 | 任意位置高效插入/删除 |
| 主要劣势 | 中间操作慢,内存开销稍大 | 头部/中间插入删除慢,扩容代价大 | 随机访问慢,内存开销大 |
7. 简单代码示例
#include
#include
#include int main() {// 1. 创建 dequestd::deque myDeque = {1, 2, 3}; // {1, 2, 3}// 2. 双端插入myDeque.push_front(0); // {0, 1, 2, 3}myDeque.push_back(4); // {0, 1, 2, 3, 4}// 3. 访问头部和尾部std::cout << "Front: " << myDeque.front() << std::endl; // 0std::cout << "Back: " << myDeque.back() << std::endl; // 4// 4. 随机访问 (索引 2)std::cout << "Element at index 2: " << myDeque[2] << std::endl; // 2// 安全随机访问 (索引 2)std::cout << "Element at index 2 (using at): " << myDeque.at(2) << std::endl; // 2// 5. 双端删除myDeque.pop_front(); // {1, 2, 3, 4}myDeque.pop_back(); // {1, 2, 3}// 6. 遍历 (使用迭代器)std::cout << "Deque contents: ";for (auto it = myDeque.begin(); it != myDeque.end(); ++it) {std::cout << *it << " ";}std::cout << std::endl; // Output: 1 2 3// 7. 中间插入 (效率较低!)auto it = myDeque.begin() + 1; // 指向索引1的元素 '2'myDeque.insert(it, 99); // {1, 99, 2, 3}// 8. 中间删除 (效率较低!)it = myDeque.begin() + 2; // 指向索引2的元素 '2' (在99之后)myDeque.erase(it); // {1, 99, 3}// 9. 输出最终结果std::cout << "Final deque: ";for (int num : myDeque) { // 范围for循环std::cout << num << " ";}std::cout << std::endl; // Output: 1 99 3return 0;
}
总结
- Deque 的核心价值在于双端操作的高效性 (O(1)) 和良好的随机访问能力 (O(1))。 这是它在 STL 容器家族中的独特定位。
- 理解其分块存储机制是理解其性能特征(为什么两端快、随机访问接近 vector、中间慢)、内存占用和迭代器失效规则的关键。
- 优先在两端操作。 避免在 deque 中间频繁插入或删除,这比在 list 中做同样操作代价高得多(O(n) vs O(1))。如果需要频繁在中间操作,
std::list是更合适的选择。 - 随机访问很快,但比 vector 略慢。 如果你需要极致的随机访问速度,并且插入删除只在尾部进行,
std::vector仍然是最优选择。 - 注意内存使用。 Deque 通常比 vector 占用更多内存,因为它有管理块的开销(指针数组)和块内可能的空间浪费。
- 小心迭代器失效。 特别是在进行
push_front/push_back(可能使所有迭代器失效)和中间插入删除(使局部迭代器失效)之后。引用和指针指向的元素内容在两端操作后通常仍然有效,这是 deque 一个非常有用且重要的特性。 - 明智选择容器: 没有“最好”的容器,只有“最合适”的。根据你的具体需求(操作的位置、频率、是否需要随机访问、内存限制、迭代器稳定性要求)来权衡选择 vector、deque 或 list。

)















如何分析和优化存储过程?)
)
