小伙伴们,大家好今天我们来利用ollama本地大模型,三步实现电子发票发票号码的提取。
步骤1:安装Ollama
访问官网https://ollama.com/ 下载相应的版本进行安装,下载属于自己平台的ollama,根据安装向导完成安装。
步骤2:安装Llama 3.2-Vision模型
通过在终端运行以下命令
安装Llama 3.2-Vision模型
ollama run llama3.2-vision
步骤3:利用python调用ollma llama3.2-vision 大模型获取对应电子发票的发票号码
1)添加提示词:

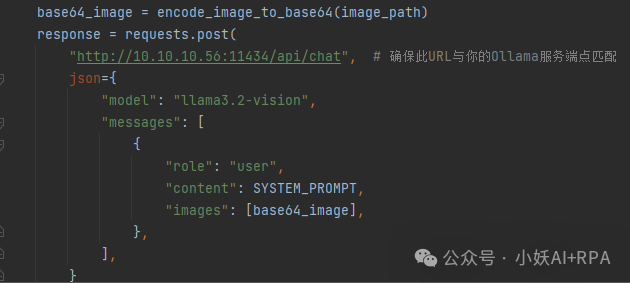
2)调用llama3.2-vision 大模型
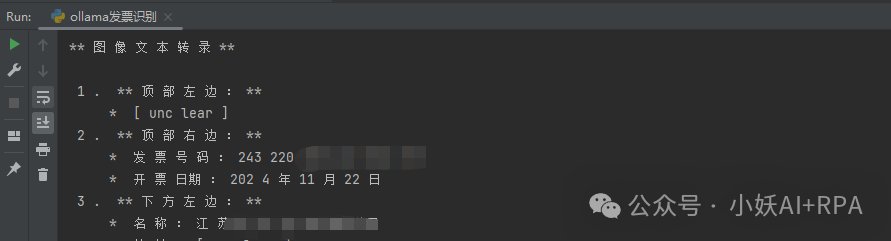
3)最终结果:查看了下,获取的信息还是比较准确的。

全部代码展示:
import base64
import requests
import json
import streamingjson
SYSTEM_PROMPT = """作为OCR助手。分析提供的图像并:
1. 尽可能准确地识别图像中所有可识别的文本。
2. 尽可能保持文本的原始结构和格式。
3. 请主要识别发票号码后面的数字,并重点标识出来
仅提供转录,不要有任何额外的评论。"""
def encode_image_to_base64(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def perform_ocr(image_path):
base64_image = encode_image_to_base64(image_path)
response = requests.post(
"http://10.10.10.56:11434/api/chat", # 确保此URL与你的Ollama服务端点匹配
json={
"model": "llama3.2-vision",
"messages": [
{
"role": "user",
"content": SYSTEM_PROMPT,
"images": [base64_image],
},
],
}
)
if response.status_code == 200:
data_string = response.text
json_segment_a = data_string
lexer = streamingjson.Lexer()
lexer.append_string(json_segment_a)
completed_json = lexer.complete_json()
return completed_json
else:
print("错误:", response.status_code, response.text)
return None
if __name__ == "__main__":
image_path = "发票.png" # 替换为你的图像路径
result = perform_ocr(image_path)
with open('result.txt', 'w') as file:
file.write(result)
ls=[]
with open('result.txt', 'r') as file:
while True:
content = file.readline()
if not content:
break
content_json=json.loads(content)
ls.append(content_json.get("message", {}).get("content", ""))
my_string = ' '.join(ls)
print(my_string)
感谢大家的支持,希望得到大家的关注与点赞,我们下期见。












模式))



)


