图机器学习(9)——图正则化算法
- 1. 图正则化方法
- 2. 流形正则化与半监督嵌入
- 3. 神经图学习
- 4. Planetoid
1. 图正则化方法
浅层嵌入方法已经证明,通过编码数据点间的拓扑关系可以构建更鲁棒的分类器来处理半监督任务。本质上,网络信息能够有效约束模型行为,确保相邻节点的输出保持平滑过渡——这种特性在半监督场景中尤其重要,可实现未标注节点的信息传播。
更进一步,这种机制也可用于正则化学习过程,从而提升模型在未见样本上的泛化能力。标签传播算法及其改进版均可通过添加正则项转化为待优化的损失函数。对于有监督任务,其通用损失函数可表述为:
L(x)=∑i∈LLS(yi,f(xi))+∑i,j∈L,ULg(f(xi),f(xj),G)\mathcal L(x)=\sum_{i \in L} \mathcal L_S(y_i,f(x_i))+\sum_{i,j \in L,U}\mathcal L_g(f(x_i),f(x_j),G) L(x)=i∈L∑LS(yi,f(xi))+i,j∈L,U∑Lg(f(xi),f(xj),G)
其中,LLL 和 UUU 分别代表标注样本和未标注样本,第二项是基于图 GGG 拓扑信息的正则化项。
我们知道,神经网络容易过拟合,且通常需要大量数据才能有效训练,而图正则化为此提供了解决方案。
2. 流形正则化与半监督嵌入
流形正则化通过以下方式扩展了标签传播框架:
- 在再生核希尔伯特空间 (
reproducing kernel Hilbert space,RKHS) 中对模型函数进行参数化 - 采用均方误差 (
mean square error,MSE)或hinge loss作为监督损失函数
具体而言,当训练支持向量机 (Support Vector Machine, SVM) 或最小二乘拟合时,该方法会基于拉普拉斯矩阵 LLL 施加图正则化项,其形式如下:
∑i,j∈L,UWij∣∣f(xi)−f(xj)∣∣22=f‾Lf‾\sum_{i,j\in L,U}W_{ij}||f(x_i)-f(x_j)||_2^2=\overline fL\overline f i,j∈L,U∑Wij∣∣f(xi)−f(xj)∣∣22=fLf
因此,这些方法通常被称为拉普拉斯正则化 (Laplacian regularization),由此衍生出拉普拉斯正则化最小二乘法 (LapRLS) 和拉普拉斯支持向量机 (LapSVM) 分类算法。标签传播和标签扩散可视为流形正则化 (manifold regularization) 的特例。此外,这些算法也可应用于无标签数据的情况(此时方程中的第一项消失),退化为拉普拉斯特征映射 (Laplacian eigenmap)。
另一方面,它们同样适用于全标签数据集的情况,此时前述正则项会在训练阶段施加约束,使模型训练更加规范化,从而得到更鲁棒的模型。此外,由于分类器在 RKHS 中进行参数化,该模型可应用于未见过的样本,且不要求测试样本必须属于输入图结构。因此,它本质上是一种归纳模型 (inductive model)。
流形学习仍属于浅层学习范式,其参数化函数并不利用任何形式的中间嵌入表征。半监督嵌入方法通过将函数约束和平滑性要求施加于神经网络的中间层,将图正则化概念扩展至深层架构。我们将 ghkg_{h_k}ghk 定义为第 kkk 个隐藏层的中间输出,该半监督嵌入框架提出的正则化项表述如下:
LGhk=∑i,j∈L,UL(Wij,ghk(xi),ghk(xj))\mathcal L_G^{h_k}=\sum_{i,j\in L,U}\mathcal L(W_{ij},g_{h_k}(x_i),g_{h_k}(x_j)) LGhk=i,j∈L,U∑L(Wij,ghk(xi),ghk(xj))
根据正则化施加位置的不同,可实现以下三种典型配置:
- 网络最终输出层正则化:这相当于将流形学习技术泛化应用于多层神经网络
- 网络中间层正则化:从而对嵌入表征进行正则化处理
- 辅助网络正则化(共享前 k−1k-1k−1 层):本质上是在训练有监督网络的同时,并行训练无监督嵌入网络。该技术通过无监督网络对前k-1层施加派生正则化约束,同时促进网络节点的嵌入学习
下图展示了半监督嵌入框架可实现的三种配置方案及其异同点:

在其原始形式中,嵌入模型采用的损失函数源自孪生网络架构,其数学表达式如下:
L(Wij,ghk(i),ghk(j))={∣∣ghk(i)−ghk(j)∣∣2Wij=1max(0,m−∣∣ghk(i)−ghk(j)∣∣2)Wij=0\mathcal L(W_{ij},g_{h_k}^{(i)},g_{h_k}^{(j)})=\left\{ \begin{aligned} &||g_{h_k}^{(i)}-g_{h_k}^{(j)}||^2 & \quad W_{ij}=1\\ &max(0,m-||g_{h_k}^{(i)}-g_{h_k}^{(j)}||^2)& \quad W_{ij}=0 \end{aligned} \right . L(Wij,ghk(i),ghk(j))=⎩⎨⎧∣∣ghk(i)−ghk(j)∣∣2max(0,m−∣∣ghk(i)−ghk(j)∣∣2)Wij=1Wij=0
通过该方程可以看出,该损失函数能确保相邻节点的嵌入向量保持紧密。另一方面,非相邻节点会被推离至阈值 mmm 指定的最小间距。相较于基于拉普拉斯算子的正则化方法 f‾Lf‾\overline fL\overline ffLf (尽管对于相邻节点而言,其惩罚因子实际上得到了保留),本节展示的损失函数通常更易于通过梯度下降进行优化。
上图所示的三种配置中,最佳选择主要取决于两个关键因素:可用数据特征和具体应用场景——即,是需要获得正则化的模型输出,还是需要学习高级数据表征。但需特别注意:当使用 softmax 层(通常置于输出层)时,基于 hinge 损失的正则化可能不适用于对数概率计算。在这种情况下,应该在中间层引入正则化嵌入和相应的损失函数。然而,需要注意的是,嵌入层位于较深层时,通常更难训练,需要仔细调整学习率和边界超参数。
3. 神经图学习
神经图学习 (Neural Graph Learning, NGL) 本质上是前述方法的泛化形式,它能够将图正则化无缝应用于包括卷积神经网络和循环神经网络在内的任何神经网络架构。
NGL 通过扩展神经网络中的图正则化调节参数来实现泛化,使用三个参数 α1\alpha _1α1、α2\alpha _2α2 和 α2\alpha _2α2 分别分解标注-标注、标注-未标注和未标注-未标注关系的贡献:
L=LS+α1∑i,j∈L,LWijd(ghk(i),ghk(j))+α2∑i,j∈L,UWijd(ghk(i),ghk(j))+α3∑i,j∈U,UWijd(ghk(i),ghk(j))\mathcal L=\mathcal L_S+\alpha_1\sum_{i,j\in L,L}W_{ij}d(g_{h_k}^{(i)},g_{h_k}^{(j)})+\alpha_2\sum_{i,j\in L,U}W_{ij}d(g_{h_k}^{(i)},g_{h_k}^{(j)})+\alpha_3\sum_{i,j\in U,U}W_{ij}d(g_{h_k}^{(i)},g_{h_k}^{(j)}) L=LS+α1i,j∈L,L∑Wijd(ghk(i),ghk(j))+α2i,j∈L,U∑Wijd(ghk(i),ghk(j))+α3i,j∈U,U∑Wijd(ghk(i),ghk(j))
其中函数 ddd 表示向量间的通用距离度量(如 L2 范数 ∣∣⋅∣∣2||·||_2∣∣⋅∣∣2)。通过调整系数和 ghk⋅g_{h_k}^{\cdot}ghk⋅ 的定义,我们可以推导出先前讨论的各类算法:
- 当 αi=0∀i\alpha_i=0\ \forall iαi=0 ∀i 时,退化为无正则化的标准神经网络
- 仅当 α1≠0\alpha_1≠0α1=0 时,还原为完全监督范式,利用节点间关系进行训练正则化
- 当用一组待学习的类别映射值 yi∗y_i^*yi∗ 替代ghk⋅g_{h_k}^{\cdot}ghk⋅ (由 α\alphaα 系数参数化)时,则退化为标签传播算法
通俗地说,NGL 框架既可视为标签传播与标签扩散算法的非线性版本,也可理解为一种能实现流形学习或半监督嵌入的图正则化神经网络。接下来,应用 NGL 技术,学习如何在神经网络中使用图正则化。
(1) 在本节中,我们将使用 Cora 数据集,该标注数据集包含 2708 篇计算机科学领域的学术论文,共分为 7 个类别。每篇论文作为节点,通过引用关系构建网络连接,总计形成 5429 条边。每个节点特征由 1433 维二元向量( 0 或 1 )表示,采用词袋模型对论文进行特征编码:即基于 1433 个术语构成的词典,通过独热编码表示单词是否存在,加载数据:
import torch
from torch_geometric.datasets import Planetoid
from torch_geometric.utils import to_scipy_sparse_matrix
import numpy as np
from sklearn.model_selection import train_test_split
import scipy.sparse as sp
import pandas as pd# 加载Cora数据集
dataset = Planetoid(root='./data/Cora', name='Cora')
data = dataset[0]
(2) 数据加载完成后,在训练样本中,我们将纳入邻居节点信息(这些邻居可能属于也可能不属于训练集,因此可能带有标签),这些信息将用于训练过程的正则化处理。而验证样本则不包含邻居信息,预测标签仅取决于节点特征——即词袋表征。因此,我们将同时利用带标签和无标签样本(半监督任务),从而构建出一个也可用于未观测样本的归纳式模型。具体实现时,我们将节点特征以 DataFrame 格式进行结构化存储,同时采用邻接矩阵来存储图结构:
# 标签映射
label_index = {'Case_Based': 0,'Genetic_Algorithms': 1,'Neural_Networks': 2,'Probabilistic_Methods': 3,'Reinforcement_Learning': 4,'Rule_Learning': 5,'Theory': 6,
}# 获取邻接矩阵
adj_matrix = to_scipy_sparse_matrix(data.edge_index).tocsr()# 转换为DataFrame以便处理
nodes = pd.RangeIndex(0, data.num_nodes)
adj_df = pd.DataFrame.sparse.from_spmatrix(adj_matrix, index=nodes, columns=nodes)# 获取特征矩阵
features = pd.DataFrame(data.x.numpy(), index=nodes)# 获取标签
labels = pd.Series(data.y.numpy(), index=nodes)
(3) 使用 adj_df,实现辅助函数 get_neighbors(),该函数能够获取指定节点的前 topn 个最近邻节点,并返回节点 ID 及边权重:
def get_neighbors(idx, adj_df, topn=5):weights = adj_df.loc[idx]return weights[weights > 0].sort_values(ascending=False).head(topn).to_dict()
(4) 将数据集分割成训练集和验证集:
def semisupervised_dataset_pyg(data, labels, ratio=0.2, topn=5):# 划分训练集和测试集labelled_idx, unlabelled_idx = train_test_split(np.arange(len(labels)),train_size=int(np.round(len(labels)*ratio)),stratify=labels,random_state=42)# 创建训练集和测试集train_data = []test_data = []# 为训练集添加邻居信息for idx in labelled_idx:neighbors = get_neighbors(idx, adj_df, topn)neighbor_info = [(n_idx, weight) for n_idx, weight in neighbors.items()]sample = {'id': idx,'features': data.x[idx].numpy(),'label': labels[idx].item(),'neighbors': neighbor_info}train_data.append(sample)# 测试集不包含邻居信息for idx in unlabelled_idx:sample = {'id': idx,'features': data.x[idx].numpy(),'label': labels[idx].item()}test_data.append(sample)return train_data, test_data# 生成半监督数据集
trainingSet, testSet = semisupervised_dataset_pyg(data, labels)
通过调整比例参数,我们可以控制标注数据与未标注数据点的数量占比。当该比例降低时,常规非正则化分类器的性能预计会出现下降。但这种性能损失可以通过未标注数据提供的网络信息来补偿——我们预期图正则化神经网络能够利用这些增强信息实现更优性能。在本节中,将比例值设定为 0.2。
(5) 在将这些数据输入到神经网络之前,我们将 DataFrame 转换为 PyTorch 张量和数据集,这种表示方式便于模型在输入层中按特征名称进行引用:
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as npvocabularySize = 1433
neighbors = 2
GRAPH_PREFIX = "NL_nbr"class CoraDataset(Dataset):def __init__(self, data_list, training=True):self.data_list = data_listself.training = trainingself.default_word = torch.zeros(vocabularySize, dtype=torch.float32)# 创建节点ID到索引的映射self.id_to_idx = {item['id']: idx for idx, item in enumerate(data_list)}def __len__(self):return len(self.data_list)def __getitem__(self, idx):item = self.data_list[idx]# 基础特征和标签features = {'words': torch.tensor(item['features'], dtype=torch.float32),'label': torch.tensor(item['label'], dtype=torch.long)}# 如果是训练集,添加邻居信息if self.training and 'neighbors' in item:for i, (n_id, weight) in enumerate(item['neighbors'][:neighbors]):try:n_idx = self.id_to_idx[n_id]neighbor_data = self.data_list[n_idx]features[f'{GRAPH_PREFIX}_{i}_weight'] = torch.tensor([weight], dtype=torch.float32)features[f'{GRAPH_PREFIX}_{i}_words'] = torch.tensor(neighbor_data['features'], dtype=torch.float32)except KeyError:# 如果邻居不在数据集中,使用默认值features[f'{GRAPH_PREFIX}_{i}_weight'] = torch.tensor([0.0], dtype=torch.float32)features[f'{GRAPH_PREFIX}_{i}_words'] = self.default_word.clone()# 填充不足的邻居for i in range(len(item.get('neighbors', [])), neighbors):features[f'{GRAPH_PREFIX}_{i}_weight'] = torch.tensor([0.0], dtype=torch.float32)features[f'{GRAPH_PREFIX}_{i}_words'] = self.default_word.clone()return featuresdef collate_fn(batch):collated = {}for key in batch[0].keys():# 对于标量值,直接堆叠if batch[0][key].dim() == 0:collated[key] = torch.stack([item[key] for item in batch])else:collated[key] = torch.stack([item[key] for item in batch])return collated# 创建数据集和数据加载器
train_dataset = CoraDataset(trainingSet, training=True)
test_dataset = CoraDataset(testSet, training=False)train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=10, shuffle=False, collate_fn=collate_fn)
(6) 创建模型。从一个简单架构开始,输入层接收独热编码表示,后接两个隐藏层,每个隐藏层由一个 Dense 层和一个 Dropout 层组成,每层有 50 个神经元:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from tqdm import tqdmclass MLP(nn.Module):def __init__(self, input_size, hidden_layers, num_classes, dropout_rate=0.8):super(MLP, self).__init__()self.layers = nn.ModuleList()# 创建隐藏层prev_size = input_sizefor hidden_size in hidden_layers:self.layers.append(nn.Linear(prev_size, hidden_size))self.layers.append(nn.ReLU())self.layers.append(nn.Dropout(dropout_rate))prev_size = hidden_size# 输出层self.output_layer = nn.Linear(prev_size, num_classes)def forward(self, x):for layer in self.layers:x = layer(x)x = self.output_layer(x)return F.log_softmax(x, dim=1)# 模型参数
vocabularySize = 1433
layers = [50, 50]
num_classes = len(label_index) # 假设label_index已定义
dropout_rate = 0.8# 初始化模型
model = MLP(vocabularySize, layers, num_classes, dropout_rate)
(7) 训练模型:
optimizer = optim.Adam(model.parameters())
criterion = nn.NLLLoss()# 训练函数
def train(model, train_loader, test_loader, epochs=200):for epoch in range(epochs):model.train()train_loss = 0correct = 0total = 0# 训练循环for batch in tqdm(train_loader, desc=f'Epoch {epoch+1}/{epochs}'):features = batch['words']labels = batch['label']optimizer.zero_grad()outputs = model(features)loss = criterion(outputs, labels)loss.backward()optimizer.step()train_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()train_acc = 100. * correct / totaltrain_loss /= len(train_loader)# 验证循环val_loss, val_acc = evaluate(model, test_loader)print(f'Epoch {epoch+1}: 'f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}% | 'f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')# 评估函数
def evaluate(model, loader):model.eval()loss = 0correct = 0total = 0with torch.no_grad():for batch in loader:features = batch['words']labels = batch['label']outputs = model(features)loss += criterion(outputs, labels).item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()return loss / len(loader), 100. * correct / total# 训练模型
train(model, train_loader, test_loader, epochs=200)
(8) 接下来,构建前述模型的图正则化版本:
class GraphRegularizedMLP(nn.Module):def __init__(self, input_size, hidden_layers, num_classes, dropout_rate=0.8):super().__init__()self.layers = nn.ModuleList()# 输入层self.layers.append(nn.Linear(input_size, hidden_layers[0]))self.layers.append(nn.ReLU())self.layers.append(nn.Dropout(dropout_rate))# 隐藏层for i in range(1, len(hidden_layers)):self.layers.append(nn.Linear(hidden_layers[i-1], hidden_layers[i]))self.layers.append(nn.ReLU())self.layers.append(nn.Dropout(dropout_rate))# 输出层self.output_layer = nn.Linear(hidden_layers[-1], num_classes)def forward(self, x):hidden_features = []for layer in self.layers:x = layer(x)if isinstance(layer, nn.ReLU):hidden_features.append(x) # 保存每一层的激活后特征x = self.output_layer(x)return F.log_softmax(x, dim=1), hidden_featuresdef graph_regularization_loss(node_embeddings, edge_index, lambda_reg=0.1):# 获取对称归一化的拉普拉斯矩阵edge_index, edge_weight = get_laplacian(edge_index, normalization='sym')# 计算正则化项: h^T L hsrc, dst = edge_indexreg = torch.sum(node_embeddings[src] * edge_weight.view(-1, 1) * node_embeddings[dst])return lambda_reg * regdef train_with_graph_reg(model, train_loader, test_loader, epochs=200, lambda_reg=0.1):device = next(model.parameters()).deviceoptimizer = optim.Adam(model.parameters())criterion = nn.NLLLoss()for epoch in range(epochs):model.train()total_cls_loss = 0total_reg_loss = 0correct = 0total = 0for batch in tqdm(train_loader, desc=f'Epoch {epoch+1}/{epochs}'):features = batch['words'].to(device)labels = batch['label'].to(device)optimizer.zero_grad()outputs, hidden_features = model(features) # 现在返回多个特征# 分类损失cls_loss = criterion(outputs, labels)# 图正则化损失(使用第一隐藏层特征)reg_loss = torch.tensor(0.0, device=device)if 'neighbor_features' in batch and len(hidden_features) > 0:# 使用第一隐藏层的特征embeddings = hidden_features[0]# 将邻居特征通过相同变换neighbor_feats = batch['neighbor_features'].to(device)batch_size, num_neighbors, _ = neighbor_feats.shape# 将邻居特征通过模型的第一层with torch.no_grad():neighbor_feats = neighbor_feats.view(-1, neighbor_feats.size(-1))neighbor_transformed = model.layers[0](neighbor_feats)neighbor_transformed = model.layers[1](neighbor_transformed) # ReLUneighbor_transformed = neighbor_transformed.view(batch_size, num_neighbors, -1)# 计算正则化diff = embeddings.unsqueeze(1) - neighbor_transformedl2_dist = torch.sum(diff.pow(2), dim=-1)neighbor_weights = batch['neighbor_weights'].to(device)reg_loss = lambda_reg * torch.mean(neighbor_weights * l2_dist)total_loss = cls_loss + reg_losstotal_loss.backward()optimizer.step()total_cls_loss += cls_loss.item()total_reg_loss += reg_loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()train_acc = 100. * correct / totalavg_cls_loss = total_cls_loss / len(train_loader)avg_reg_loss = total_reg_loss / len(train_loader)# 验证循环val_loss, val_acc = evaluate(model, test_loader)print(f'Epoch {epoch+1}: 'f'Cls Loss: {avg_cls_loss:.4f}, Reg Loss: {avg_reg_loss:.4f}, 'f'Train Acc: {train_acc:.2f}% | 'f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')def evaluate(model, loader):model.eval()loss = 0correct = 0total = 0device = next(model.parameters()).devicewith torch.no_grad():for batch in loader:features = batch['words'].to(device)labels = batch['label'].to(device)# 只取模型输出的第一个元素(预测结果)outputs, _ = model(features) # 解包元组,忽略隐藏特征loss += F.nll_loss(outputs, labels).item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()return loss / len(loader), 100. * correct / total
需要注意的是,当前损失函数已包含先前定义的图正则化项。这意味着神经网络训练过程现在会融入来自相邻节点的信息进行正则化。模型训练过程输出如下所示:
Epoch 200/200
loss: 0.9136 – accuracy: 06405 – scaled_graph_loss: 0.0328 - val_loss: 1.2526 – val_accuracy: 0.6320
与基础模型相比,图正则化使模型准确率提升了约 5%。
4. Planetoid
当前讨论的方法均基于拉普拉斯矩阵实现图正则化,通过 WijW_{ij}Wij 权重约束可保持节点间的一阶邻接性。Planetoid 算法对此进行了扩展,该算法不仅保留一阶近似,还能捕捉高阶邻接关系。其核心创新在于:将用于计算节点嵌入的 skip-gram 方法改进为可融合节点标签信息的监督学习框架。
传统 skip-gram 方法依赖随机游走生成节点序列,再通过 skip-gram 模型学习嵌入表示。下图展示了如何改造无监督版本以引入监督损失:
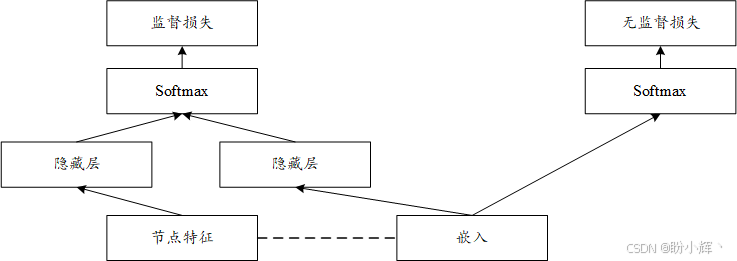
如上图所示,节点嵌入将同时输入以下两个模块:
- 上下文预测模块:通过
softmax层预测随机游走序列的图上下文 - 标签预测模块:由隐藏层组合节点特征衍生的隐藏层,共同预测类别标签
该联合网络的训练目标函数由监督损失 (Ls\mathcal L_sLs) 与非监督损失 (Lu\mathcal L_uLu) 共同构成。无监督损失类似于使用负采样的skip-gram中使用的损失,而监督损失最小化条件概率:
Ls=−∑i∈Llogp(yi∣xi,ei)\mathcal L_s=-\sum_{i\in L}logp(y_i|x_i,e_i) Ls=−i∈L∑logp(yi∣xi,ei)
需要注意的是,上述公式属于转导学习 (transductive) 方法,要求样本必须属于当前图结构才能生效。在半监督任务中,该方法可有效预测未标注样本的标签,但无法处理未观测样本。通过专用连接层将嵌入参数化为节点特征的函数,可得到 Planetoid 算法的归纳学习 (inductive) 版本。




的根与源)


)











0715)