大模型分类:
技术架构: Encoder Only Bert
Decoder Only 著名的大模型都是
Encoder - Decoder T5
是否开源: 开源阵营: Llama DeepSeek Qwen
闭源阵营: ChatGpt Gemini Claude
语言模型发展阶段: 基于规则统计 n-gram:上下文比较短,数据稀疏,泛化能力差
神经网络语言模型:泛化能力差(解决) 数据稀疏(解决) RNN,LSTM
Transformer: Bert,GPT
LLM:参数以 10 亿计
评估指标: BLEU 精准率,需要有参考答案
ROUGE 召回率 需要有参考答案
PPL
大模型演进路线: Encoder-only 双向注意力机制,完形填空,阅读理解,Pre-train+下游任务fine-tuning
Decoder-only gpt:
gpt2:
gpt3:
Encoder-Decoder : T5


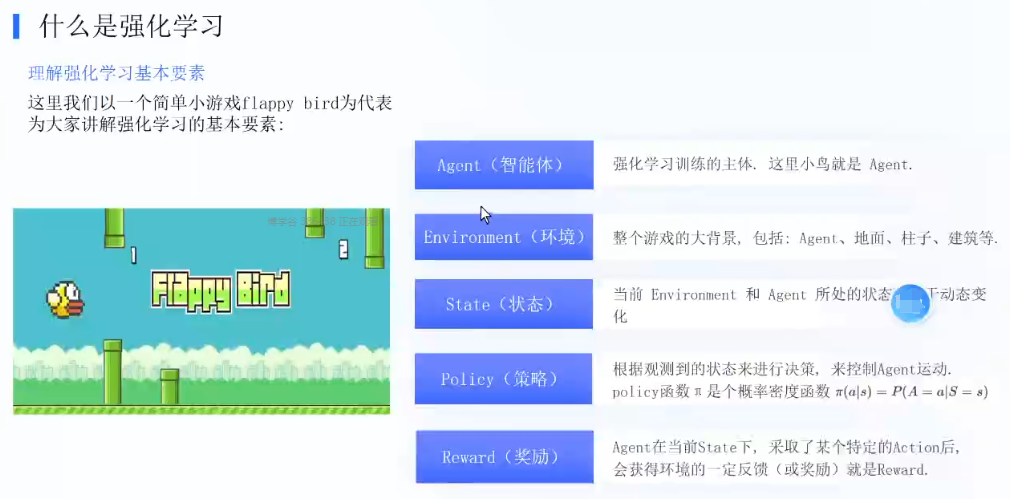
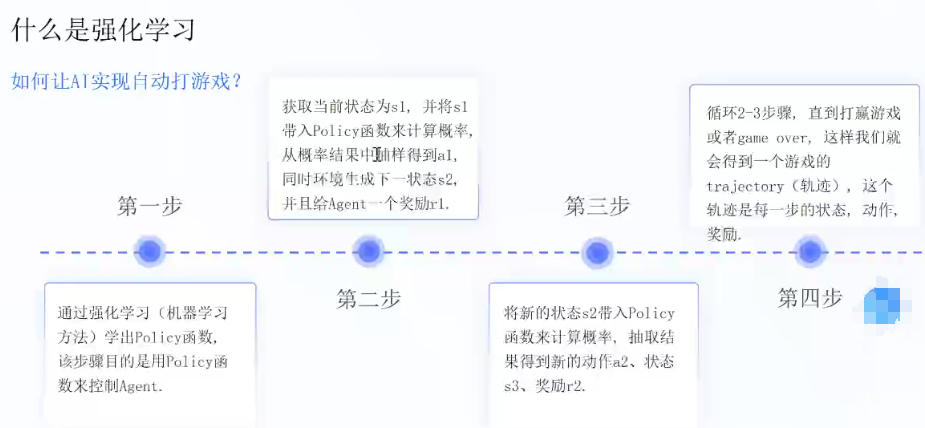
RLHF解决的是什么问题? 对齐问题,训练一个奖励模型

位置编码:
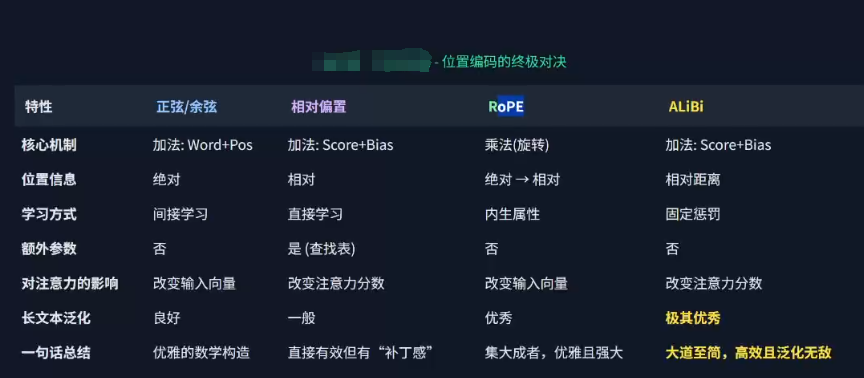
总结:
强化学习:
ChatGPT SFT :人类价值观对齐,
RLHF: 训练奖励模型, 人的参与是为了准备训练奖励模型的语料
强化学习:Agent,Environment,state,Policy,Reward
PPO:
不同大模型的差异:
位置编码: 传统Transformer,相对位置编码,旋转位置编码(用的最多),ALiBi
注意力机制:
LN:层归一化:
前馈神经网络:MOE








)


)







![牛客:HJ24 合唱队[华为机考][最长递增子集][动态规划]](http://pic.xiahunao.cn/牛客:HJ24 合唱队[华为机考][最长递增子集][动态规划])