1. 实例编译 运行
main.cu
//nvcc -g -lineinfo -std=c++17 -arch=native main.cu -o main#include <iostream>
#include <thrust/device_vector.h>/*
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];.shape = {.m8n8};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16};
*/__device__
void ldmatrix_x2(unsigned int (&x)[2], const void* ptr){ asm volatile("ldmatrix.sync.aligned.m8n8.x2.shared.b16 {%0, %1}, [%2];" : "=r"(x[0]), "=r"(x[1]): "l"(__cvta_generic_to_shared(ptr)));
}__global__
void mykernel(const int* loadOffsets, bool print){alignas(16) __shared__ half A[128 * 16];for(int i = threadIdx.x; i < 128*16; i += blockDim.x){A[i] = i;}__syncthreads();const int lane = threadIdx.x % 32;unsigned int result[2];const int offset = loadOffsets[lane];ldmatrix_x2(result, &A[offset]);half2 loaded[2];memcpy(&loaded[0], &result[0], sizeof(half2) * 2);if(print){for(int m = 0; m < 2; m++){for(int t = 0; t < 32; t++){if(lane == t){printf("%4d %4d ", int(loaded[m].x), int(loaded[m].y));if(lane % 4 == 3){printf("\n");}}__syncwarp();}if(lane == 0){printf("\n");}__syncwarp();}}
}int main(){thrust::device_vector<int> d_loadOffsets(32, 0);for(int i = 0; i < 16; i++){const int row = i % 8;const int matrix = i / 8;d_loadOffsets[i] = row * 16 + matrix * 8;}mykernel<<<1,32>>>(d_loadOffsets.data().get(), true);cudaDeviceSynchronize();// Shared Load Matrix: Requests 16.384, Wavefronts 33.393, Bank Conflicts 0for(int i = 0; i < 16; i++){const int row = i / 2;const int matrix = i % 2;d_loadOffsets[i] = row * 16 + matrix * 8;}std::cout << "offsets: ";for(int i = 0; i < 16; i++){std::cout << d_loadOffsets[i] << " ";}std::cout << "\n";mykernel<<<1024,512>>>(d_loadOffsets.data().get(), false);cudaDeviceSynchronize();// Shared Load Matrix: Requests 16.384, Wavefronts 131.674, Bank Conflicts 98.304for(int i = 0; i < 16; i++){const int row = i / 2;const int matrix = i % 2;d_loadOffsets[i] = (4*row) * 16 + matrix * 8;}std::cout << "offsets: ";for(int i = 0; i < 16; i++){std::cout << d_loadOffsets[i] << " ";}std::cout << "\n";mykernel<<<1024,512>>>(d_loadOffsets.data().get(), false);cudaDeviceSynchronize();// Shared Load Matrix: Requests 16.384, Wavefronts 66.488, Bank Conflicts 32.768for(int i = 0; i < 16; i++){const int row = i % 8;const int matrix = i / 8;d_loadOffsets[i] = row * 16 + matrix * 8;}std::cout << "offsets: ";for(int i = 0; i < 16; i++){std::cout << d_loadOffsets[i] << " ";}std::cout << "\n";mykernel<<<1024,512>>>(d_loadOffsets.data().get(), false);cudaDeviceSynchronize();// Shared Load Matrix: Requests 16.384, Wavefronts 263.070, Bank Conflicts 229.376for(int i = 0; i < 16; i++){const int row = i % 8;const int matrix = i / 8;d_loadOffsets[i] = (4*row) * 16 + matrix * 8;}std::cout << "offsets: ";for(int i = 0; i < 16; i++){std::cout << d_loadOffsets[i] << " ";}std::cout << "\n";mykernel<<<1024,512>>>(d_loadOffsets.data().get(), false);cudaDeviceSynchronize();
}编译运行:
nvcc -g -lineinfo -std=c++17 -arch=native main.cu -o main或者 device 代码 debug版:
$ nvcc -g -G -std=c++17 -arch=native main.cu -o main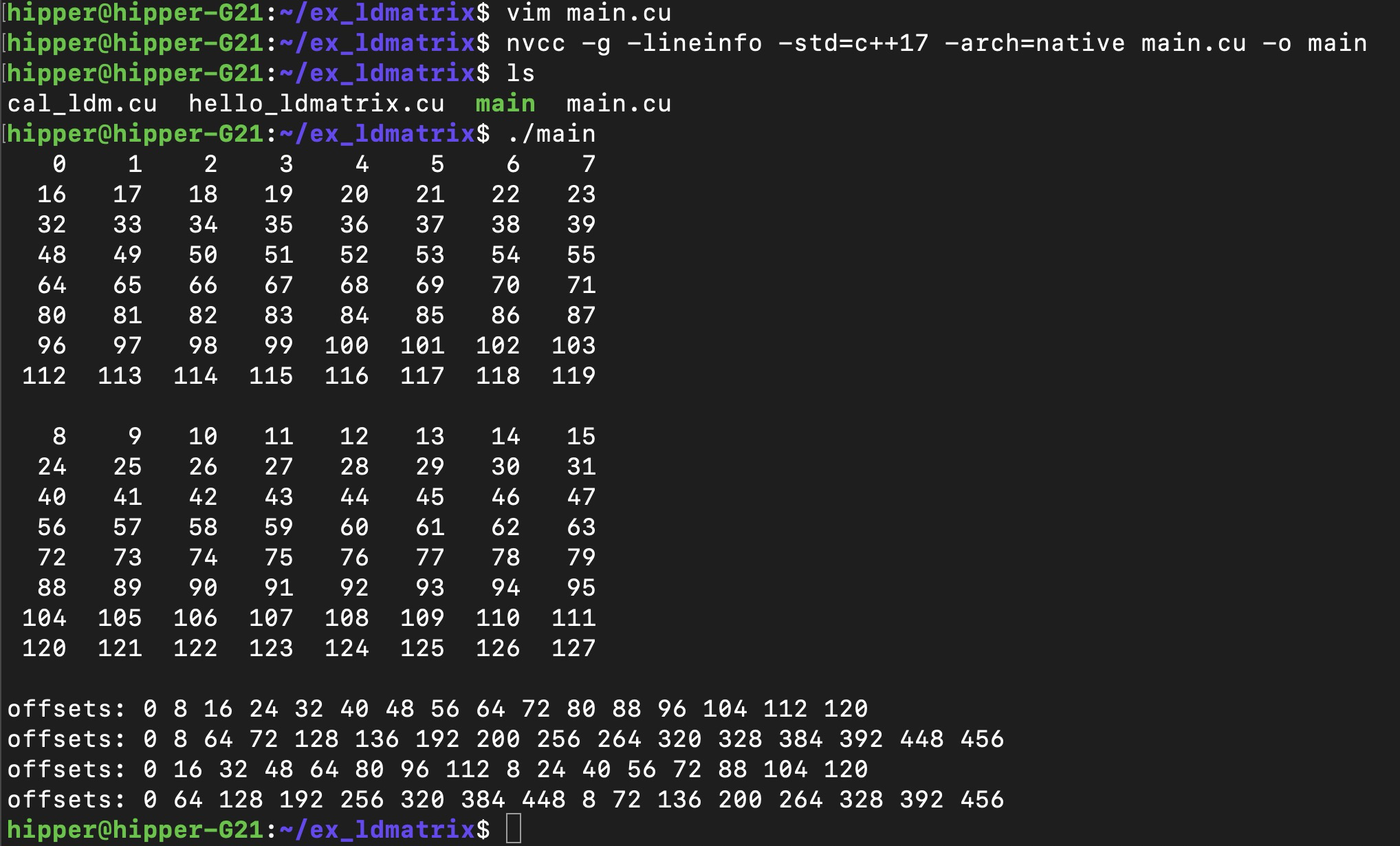
修改程序后,
//nvcc -g -lineinfo -std=c++17 -arch=native main.cu -o main#include <iostream>
#include <thrust/device_vector.h>/*
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];.shape = {.m8n8};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16};
*/__device__
void ldmatrix_x2(unsigned int (&x)[2], const void* ptr){asm volatile("ldmatrix.sync.aligned.m8n8.x2.shared.b16 {%0, %1}, [%2];": "=r"(x[0]), "=r"(x[1]): "l"(__cvta_generic_to_shared(ptr)));
}__global__
void mykernel(const int* loadOffsets, bool print){alignas(16) __shared__ half A[128 * 16];for(int i = threadIdx.x; i < 128*16; i += blockDim.x){A[i] = i;}__syncthreads();const int lane = threadIdx.x % 32;unsigned int result[2];//one int, 2 half mem spaceconst int offset = loadOffsets[lane];ldmatrix_x2(result, &A[offset]);half2 loaded[2];memcpy(&loaded[0], &result[0], sizeof(half2) * 2);if(print){for(int m = 0; m < 2; m++){for(int t = 0; t < 32; t++){//if(lane == t){if(lane == t){printf("[%2d]%4d %4d ",lane, int(loaded[m].x), int(loaded[m].y));if(lane % 4 == 3){printf("\n");}}__syncwarp();}if(lane == 0){printf("\n");}__syncwarp();}}
}int main(){thrust::device_vector<int> d_loadOffsets(32, 0);for(int i = 0; i < 16; i++){const int row = i % 8;const int matrix = i / 8;d_loadOffsets[i] = row * 16 + matrix * 8;printf("%d ", row*16 + matrix*8);}
printf("\n\n");//thrust::host_vector<int> h_loadOffsets(32, 0);
int * hld = nullptr;
hld = (int*)malloc(32*sizeof(int));
cudaMemcpy(hld, d_loadOffsets.data().get(), sizeof(int)*32, cudaMemcpyDeviceToHost);for(int i=0; i<32; i++)printf("%d, ", hld[i]);
printf("\n");mykernel<<<1,32>>>(d_loadOffsets.data().get(), true);cudaDeviceSynchronize();}
同上编译方式,输出:
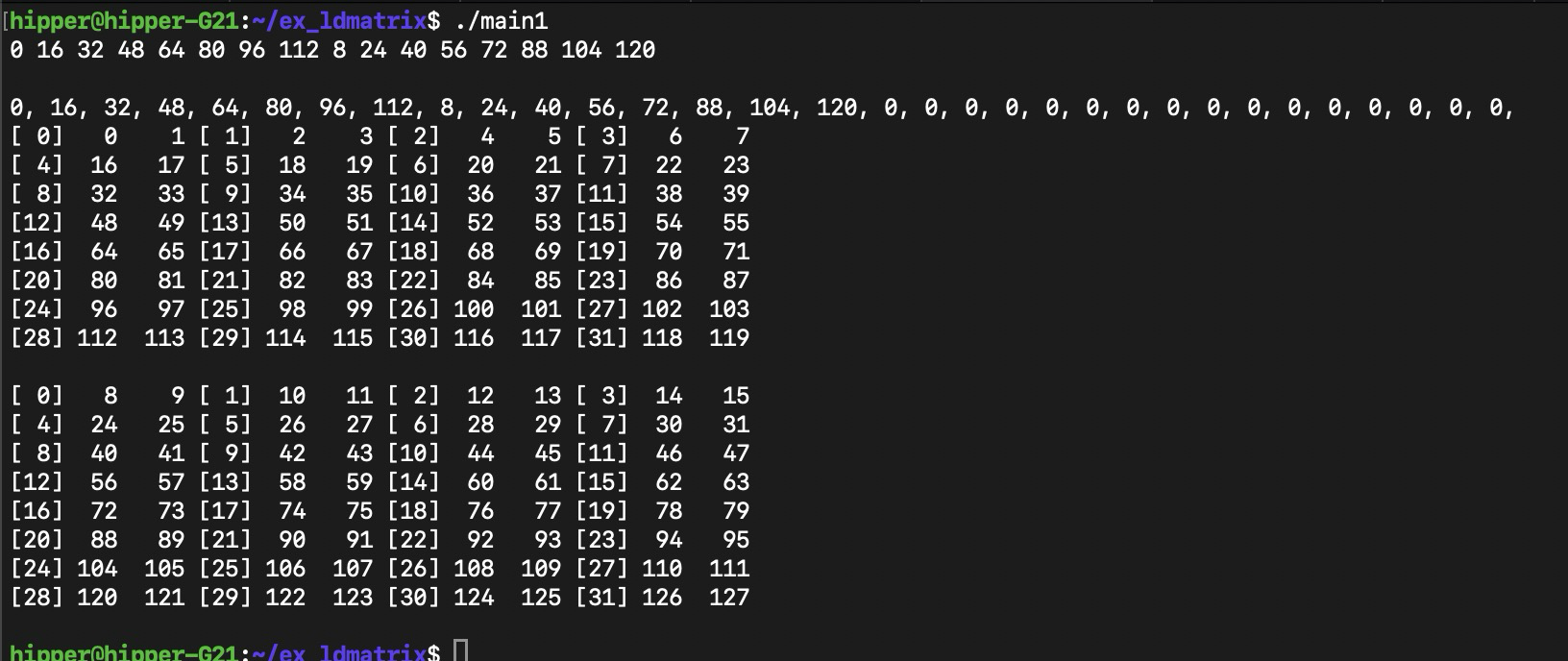
比较容易发现搬运数据映射关系
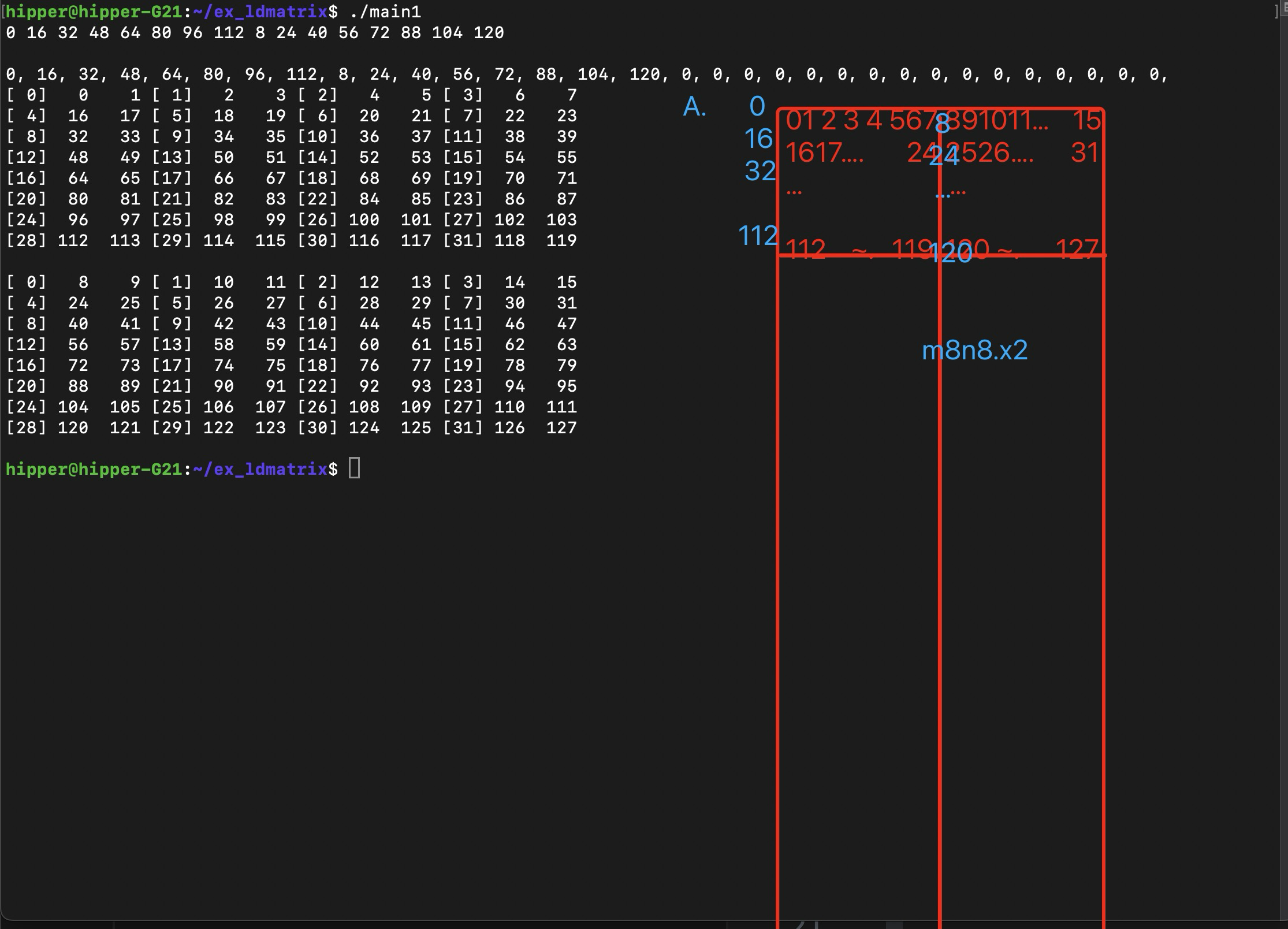
这里我们先猜一下其数据关系,
首先,矩阵以m8n8为一个小矩阵加载进warp 的 32个 lane中,每个lane 从这个小矩阵中拿到两个地址连续的变量;x2,是说一次 load 两个8x8小矩阵,这样的话,每个lane 会得到4个变量;x4的话,就是4*2=8个变量。
每个小矩阵需要提供8个行的起始地址,第一个小矩阵的8个行起始地址填写在0~7号 lane 的寄存器中;第二个小矩阵的8个行起始地址填写在 8~15号lane的寄存器中,各个lane中同名寄存器作为 ldmatrix 的参数。即,代码中的 const void* ptr 。
可以推得,如果是x4,4个8x8 的小矩阵,那么需要提供4组8个行的起始地址,这样,32个 lane 每个都持有一个小矩阵的行起始地址。
第二节第三节再深入系统地分析。
2. 实例功能解析
进一步详细解析这个执行了 ldmatrix 的 CUDA Device 函数,这是一个非常经典且高效的用法。
2.1. 函数签名解析
__device__ void ldmatrix_x2(unsigned int (&x)[2], const void* ptr)__device__
cuda 语法,声明这是一个在 GPU 上执行的函数。
unsigned int (&x)[2]
这是一个对包含 2 个 unsigned int 的数组的引用,C++ 语法。使用引用 (&) 允许函数直接修改调用者传入的数组元素,避免了传值拷贝。这个数组的两个元素 x[0] 和 x[1] 将被用作内联汇编中的目标寄存器。
const void* ptr
这是一个指向共享内存中某个数据的通用指针(generic)。const 表示函数不会通过这个指针修改数据,void* 提供了灵活性,可以指向任何类型的数据。
2.2. 内联汇编详解
asm volatile("ldmatrix.sync.aligned.m8n8.x2.shared.b16 {%0, %1}, [%2];": "=r"(x[0]), "=r"(x[1]) // Output operands: "l"(__cvta_generic_to_shared(ptr))); // Input operandptx ISA ldmatrix spec
我们一点一点地分解:
2.2.1. 汇编模板字符串
("ldmatrix.sync.aligned.m8n8.x2.shared.b16 {%0, %1}, [%2];")
这是要执行的 PTX 指令。
ldmatrix: 指令本身,用来加载矩阵。
.sync: Warp 级同步指令,确保 Warp 内所有活跃线程协同执行。
.aligned: 强制要求源内存地址 (ptr) 必须是 16 字节对齐的。
.m8n8: 指定从内存中加载的数据布局对应于一个 8 行 x 8 列的矩阵。这个形状的矩阵数据元素只能是 16bit的。还可以有 .m16n16、.m8n16,这是对应 8bit/6bit/4bit 矩阵元素。
.x2: 指定一次执行 ldmatrix 时,加载 2 个 m8n8 的小矩阵。
The values .x1, .x2 and .x4 for .num indicate one, two or four matrices respectively. When .shape is .m16n16, only .x1 and .x2 are valid values for .num.
.shared: 明确指定源数据位于共享内存(Shared Memory) 中。
.b16: 指定内存访问模式。.b16 表示这是一次 16 字节的访问。这与共享内存的 bank 宽度和高效访问模式有关。
{%0, %1}: 这是目标操作数列表。占位符 %0 和 %1 将会被编译器替换为后面约束列表中找到的实际寄存器。这里它要求 2 个 32 位的寄存器。
为什么是 2 个? 一个 8x8 的矩阵,每个元素 2 字节,总大小为 8 * 8 * 2 = 128 字节。一个 Warp 有 32 个线程。ldmatrix 指令将这 128 字节的数据转置后,分布到整个 Warp 的线程寄存器中。每个线程负责 128/32 = 4 字节的数据。一个 32 位寄存器是 4 字节,所以每个线程需要 1 个寄存器来存储它的那部分数据。那么为什么这里列表里有 2 个?实际上,这条指令是在加载2个这样的 8x8 矩阵。这里的关键在于指令的变体。在 SM_70+ 上,ldmatrix 可以加载 1、2 或 4 个矩阵。
[%2]: 这是源操作数。它是一个包含共享内存地址的寄存器,地址为16bit aligned。%2 将被替换为输入操作数提供的值。
2.2.2. 输出操作数
(: "=r"(x[0]), "=r"(x[1]))
"=r": 约束修饰符。
= 表示这是一个只写的输出操作数。
r register 之意,表示要求编译器分配一个32 位通用寄存器来保存这个值。
(x[0]), (x[1]): 对应的 C++ 变量。指令执行后,目标寄存器 %0 和 %1 中的值会被写回到数组 x 的这两个元素中。
作用:告诉编译器:“请为 x[0] 和 x[1] 分配两个寄存器。执行汇编指令后,结果将在这两个寄存器中,请将它们写回 x[0] 和 x[1]。”
2.2.3. 输入操作数
(: "l"(__cvta_generic_to_shared(ptr)))
这是最精妙和关键的部分。
__cvta_generic_to_shared(ptr): 这是一个 CUDA 内部函数。
作用:它将一个通用指针 (ptr) 转换为其对应的共享内存空间下的地址值。
原理:在 PTX 中,不同的内存空间(全局、共享、本地等)有独立的地址空间。一个通用(generic)的 void* 指针不能直接用于 ldmatrix 的 shared 操作。这个函数执行必要的位操作,提取出专用于共享内存地址空间的地址比特位。
"l": 这是一个约束修饰符。
l location register 之意。表示一个 32 位的专用寄存器,通常用于存储地址**。这与通用寄存器 r 略有不同,编译器知道这个寄存器将用于寻址。
作用:告诉编译器:“计算 __cvta_generic_to_shared(ptr) 这个表达式的值,并将其放入一个专用的地址寄存器中,然后在汇编模板中用 %2 来引用这个寄存器。”
2.2.4. volatile 关键字
防止编译器优化掉这条汇编指令(例如,因为它看起来没有使用输出 x),或者将其移出循环。确保指令严格按照代码中的位置和执行次数运行。
2.3. 函数功能总结
这个 ldmatrix_x2 函数的功能是:
让一个 Warp(32 个线程)协同工作,从共享内存中 ptr 所指的、16 字节对齐的地址开始,加载 2 个连续的 8x8 矩阵(每个元素 2 字节)。数据在加载过程中会被重新排列(转置)。加载完成后,每个线程会获得 8 字节(2 个 unsigned int)的数据,存储在其 x[0] 和 x[1] 中。
这些数据通常是更大矩阵乘法操作中的一个小块(Tile)。每个线程持有的 x[0] 和 x[1] 是转置后矩阵的一小部分,它们的形式非常适合直接作为输入喂给后续的 mma(矩阵乘加)指令,从而实现极其高效的矩阵计算。
注意事项:
-
调用约定:这个函数必须由整个 Warp 的线程同时调用,且
ptr的值在 Warp 内必须一致(通常是通过广播获得)。 -
对齐:
ptr必须是 16 字节对齐的,否则行为未定义。 -
数据布局:共享内存中的数据必须按照
ldmatrix指令所期望的布局进行排列,这通常由之前的数据存储步骤(例如使用st.shared.v2.b32之类的指令)来保证。
这个函数是手动优化 CUDA 核函数、充分发挥 Tensor Core 性能的典型代表。
3. ldmatrix 功能系统解析
CUDA PTX 中的 ldmatrix 指令是高效利用 Tensor Cores(张量核心)进行矩阵计算的关键所在。接着前面的具体实例,这里更为系统第介绍一下 ldmatrix 指令的原理用法。
3.1. 指令概述与原理
目的
ldmatrix(Load Matrix)指令用于从一个线程束(Warp)内线程协同访问的连续共享内存区域中,高效地加载一个小的、密集的矩阵块(如 8x8),并将其转置后分布到该 Warp 中多个线程的寄存器中。
核心思想
Tensor Cores 执行的是 D = A * B + C 操作,其中 A、B、C、D 都是小矩阵。然而,全局内存或共享内存中的数据通常按行主序或列主序存储。ldmatrix 指令在数据从共享内存加载到寄存器的过程中,巧妙地完成了数据重排(转置),使得数据在寄存器中的布局恰好符合 Tensor Cores 所期望的输入格式,从而避免了显式的转置操作,极大提升了效率。
工作原理
一个 Warp(32 个线程)共同协作,从共享内存中读取一片连续的数据。每个线程负责读取数据的一部分。指令会自动地将这些数据重新组织(转置),并存入指定线程的指定寄存器。最终,整个 Warp 的寄存器合在一起,就构成了一个完整的、经过转置的矩阵。
3.2. 指令语法格式
完整的 PTX 语法如下:
ldmatrix.sync.aligned.{num}{.trans}{.ss}.type [rd1, rd2, ...], [rs1, rs2];
// 或者更常见的格式,指定矩阵形状:
ldmatrix.sync.aligned.shape.{num}{.trans}{.ss}.rspace [rd1, rd2, ...], [rs];3.3. 指令中各域详解
.sync (Synchronization)
作用
指定这是一个Warp-level 同步指令。指令的执行会涉及 Warp 中所有活跃线程的协同操作。.sync 后缀确保所有线程在逻辑上同时参与此次加载。
可选值
在较新的架构中,可以指定 .sync.syncid 以实现更细粒度的同步,但通常直接使用 .sync。
.aligned (Alignment)
作用
指定共享内存的源地址必须是 16 字节对齐的。这是为了满足内存子系统的高效访问要求。如果地址未对齐,执行结果将是未定义的。
注意
这是一个强制要求,不是可选项。你必须确保传入的共享内存指针是 16 字节对齐的。
.{num} (Number of Matrices)
作用
指定一次指令调用要加载的矩阵数量。
可选值
.1:加载 1 个矩阵;
.2:加载 2 个矩阵;.4:加载 4 个矩阵;
影响
加载的矩阵数量直接决定了目标寄存器的数量。例如,加载一个 8x8x16 的矩阵(.m8n8 + .x2)需要 4 个寄存器(8*8*2/32/1?更正:通常加载 1 个 .m8n8.x4 矩阵需要 8 个寄存器)。加载 .4 个矩阵就需要 4 倍数量的寄存器。
.{trans} (Transposition)
作用
指定是否对加载的矩阵进行转置。
可选值
(空):不进行转置,按原样加载;
.trans:对加载的矩阵进行转置;
这是关键
这个功能是为了适配 Tensor Cores 的输入。例如,在计算 A * B 时,可能需要将 B 矩阵转置后再输入给 Tensor Core。使用 .trans 可以在加载时一步完成,无需后续单独的转置指令。
.{ss} (Element Size / Storage Spacing)
作用
指定源数据中每个矩阵元素的大小和存储间隔。
可选值
.x1:8 位元素(如 char, uint8_t);.x2:16 位元素(如 half, __half, short)。这是用于 FP16 张量计算最常见的大小;
.x4:32 位元素(如 float, int);
.{type} / .{rspace} (Type / Resource Space)
作用
指定源数据所在的内存空间。
可选值
.shared:源数据位于共享内存中。这是 ldmatrix 最常用、最主要的使用场景;
.global:源数据位于全局内存中。(在某些架构上支持,但不如从共享内存加载高效);
.[rd1, rd2, ...] (Destination Registers)
作用
目标操作数,是一个寄存器列表,用于接收加载来的矩阵数据。
要求
寄存器的数量取决于 {num}, {ss} 和矩阵形状。例如,加载 1 个 8x8 的矩阵(.m8n8),每个元素是 32位(.x4),则需要 (8 * 8 * 4) / 32 = 8 个 32 位寄存器;
寄存器必须是 32 位宽的(例如 %r0, %f1);
列表中的寄存器必须是连续的;
.[rs1, rs2] / [rs] (Source Address)
作用
源操作数,是包含共享内存地址的寄存器。
要求
通常是一个包含 32 位地址的寄存器(例如 %r0);
该地址必须指向共享内存,并且必须是 16 字节对齐的(由 .aligned 保证);
.{shape} (Matrix Shape - 替代方案)
作用
另一种语法是明确指定矩阵的形状,这通常更直观。
可选值
.m8n8:加载一个 8x8 的矩阵。这是最常用的形状;
.m8n8k4 等:用于更复杂的加载模式,但 .m8n8 是基础;
3.4. 用法示例与解释
假设我们要从共享内存加载一个 8x8 的 FP16 矩阵,并对其进行转置,然后分布到寄存器中。
PTX 代码:
ldmatrix.sync.aligned.m8n8.x2.trans.shared.b16 {%0, %1, %2, %3}, [%4];分解:
.sync.aligned:Warp 同步且地址对齐;
.m8n8:加载 8x8 的矩阵;
.x2:源元素是 16 位(FP16);
.trans:加载时进行转置;
.shared.b16:从共享内存以 16 字节的访问模式读取;
{%0, %1, %2, %3}:需要 4 个 32 位目标寄存器;
*计算:一个 8x8 FP16 矩阵总大小 = 8 * 8 * 2字节 = 128 字节。一个 Warp 有 32 个线程,每个线程负责 128 / 32 = 4 字节的数据。一个 32 位寄存器正好是 4 字节,所以每个线程需要 1 个寄存器。但为什么这里有 4 个?实际上,ldmatrix 指令的寄存器列表是每个线程持有的寄存器数量?不,更准确的说法是:这条指令为整个 Warp 指定了 4 个连续的寄存器,但每个线程看到的是这些寄存器中的不同部分。通常,加载一个 .m8n8.x2 矩阵需要 4 个目标寄存器。
[%4]:源地址寄存器,其值是一个 16 字节对齐的共享内存地址;
在 CUDA C++ 中的内联汇编用法:
__shared__ half smem_buffer[64]; // 8x8 FP16 矩阵asm volatile ("ldmatrix.sync.aligned.m8n8.x2.trans.shared.b16 {%0, %1, %2, %3}, [%4];": "=r"(reg0), "=r"(reg1), "=r"(reg2), "=r"(reg3) // 4个输出寄存器: "r"(smem_buffer) // 输入:共享内存地址// 可能还需要 clobber 列表,但有时可省略
);3.5. 小结
ldmatrix 是一条极其强大的指令,它将数据加载和数据重排(转置) 两个耗时的操作合并为一条高效的硬件指令。它的设计完美契合了 Tensor Cores 的工作方式,是实现高性能矩阵乘法(尤其是深度学习推理和训练)的核心原语之一。理解其各个参数的含义对于在 PTX 或 CUDA 内联汇编中正确使用它至关重要。
4. 附录
4.1. 示例的 ptx生成
生成 ptx 文件:
nvcc -ptx -lineinfo -std=c++17 -arch=native main.cu -o main.ptx或者不带源码行号
$ nvcc -ptx --gpu-architecture=sm_120 main.cu -o main_sm_120.ptx4.2. m8n8.x4 的示例
//nvcc -g -lineinfo -std=c++17 -arch=native main.cu -o main#include <iostream>
#include <thrust/device_vector.h>/*
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];.shape = {.m8n8};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16};
*/__device__
void ldmatrix_x2(unsigned int (&x)[4], const void* ptr){asm volatile("ldmatrix.sync.aligned.m8n8.x4.shared.b16 {%0, %1, %2, %3}, [%4];": "=r"(x[0]), "=r"(x[1]), "=r"(x[2]), "=r"(x[3]): "l"(__cvta_generic_to_shared(ptr)));
}__global__
void mykernel(const int* loadOffsets, bool print){alignas(16) __shared__ half A[128 * 16];for(int i = threadIdx.x; i < 128*16; i += blockDim.x){A[i] = i;}__syncthreads();const int lane = threadIdx.x % 32;unsigned int result[4];//one int, 2 half mem spaceconst int offset = loadOffsets[lane];ldmatrix_x2(result, &A[offset]);half2 loaded[4];memcpy(&loaded[0], &result[0], sizeof(half2) * 4);if(print){for(int m = 0; m < 4; m++){for(int t = 0; t < 32; t++){//if(lane == t){if(lane == t){printf("[%2d]%4d %4d ",lane, int(loaded[m].x), int(loaded[m].y));if(lane % 4 == 3){printf("\n");}}__syncwarp();}if(lane == 0){printf("\n");}__syncwarp();}}
}int main(){thrust::device_vector<int> d_loadOffsets(32, 0);for(int i = 0; i < 32; i++){const int row = i % 8 + (i/16)*8; // row of m8n8const int matrix = (i%16) / 8; // colum of m8n8d_loadOffsets[i] = row * 16 + matrix * 8;printf("%d ", row*16 + matrix*8);}
printf("\n\n");//thrust::host_vector<int> h_loadOffsets(32, 0);
int * hld = nullptr;
hld = (int*)malloc(32*sizeof(int));
cudaMemcpy(hld, d_loadOffsets.data().get(), sizeof(int)*32, cudaMemcpyDeviceToHost);for(int i=0; i<32; i++)printf("%d, ", hld[i]);
printf("\n");mykernel<<<1,32>>>(d_loadOffsets.data().get(), true);cudaDeviceSynchronize();}
运行:
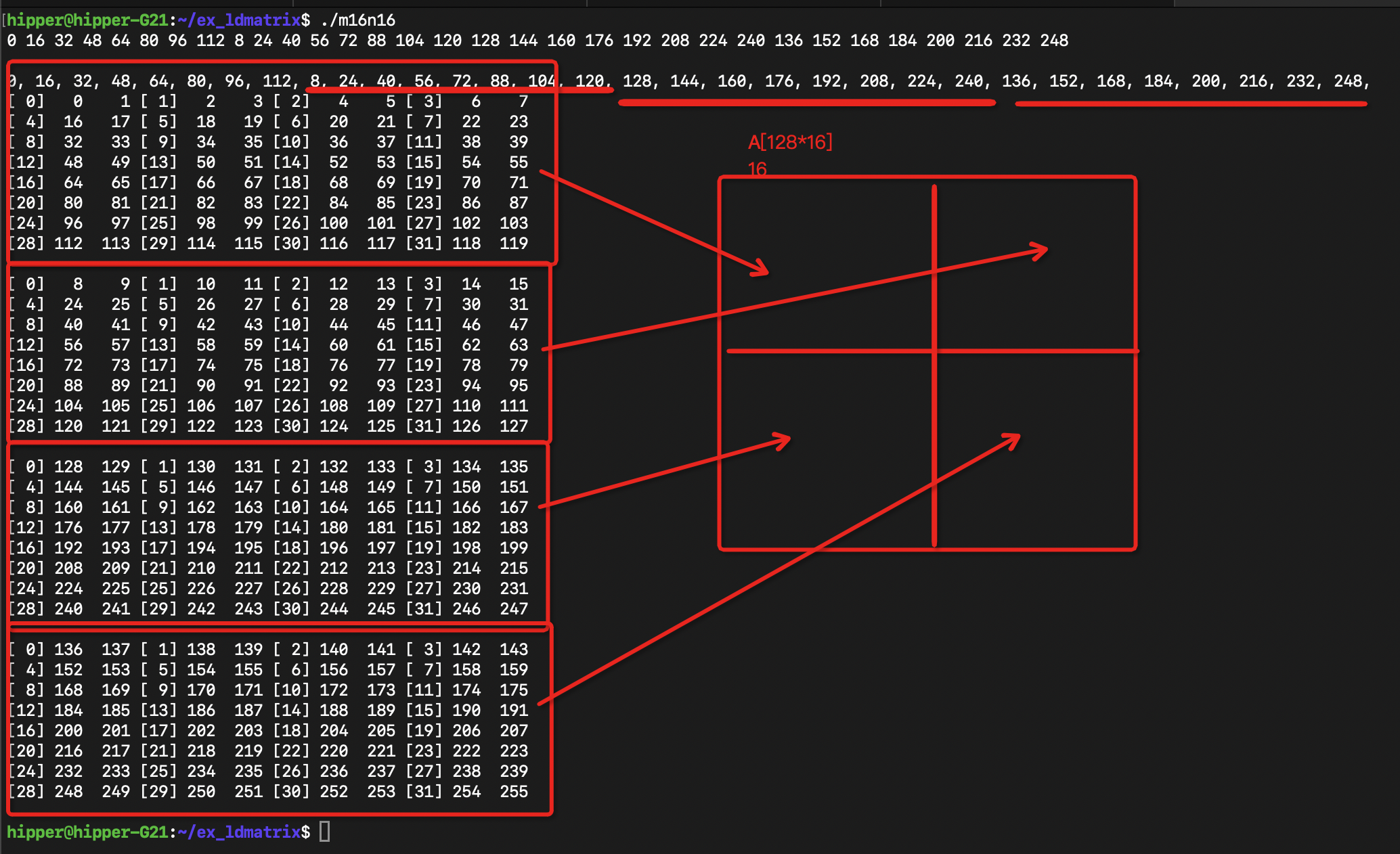





)






![[Dify] 实现“多知识库切换”功能的最佳实践](http://pic.xiahunao.cn/[Dify] 实现“多知识库切换”功能的最佳实践)
)
)


)

BGP路由 选路规则)