源码链接:点击下载源码
相关文档:点击下载相关文档
摘 要
随着互联网的快速发展,豆瓣网作为一个综合性的影视评分和评论平台,积累了大量的用户数据,这些数据为影视分析提供了丰富的素材。借助Hadoop这一大数据处理框架,能够高效地存储和分析这些数据,从而挖掘出潜在的价值。
Hadoop的分布式存储和计算能力,使得对海量数据的处理变得更加高效。通过对豆瓣网的用户评论、评分以及影片信息进行分析,可以揭示出影视作品的受欢迎程度、观众偏好以及市场趋势。在数据分析过程中,采用了多种数据挖掘技术,包括聚类分析和情感分析,识别用户对不同类型影片的偏好,并探讨影片评分与评论情感之间的关系。研究结果显示,用户的评分与评论情感存在显著相关性,且不同类型影片在用户偏好上表现出明显差异。
通过对豆瓣网数据的深入分析,不仅可以为影视产业提供科学依据,还能够推动相关技术的发展与应用,促进文化产业的繁荣。因此,基于Hadoop的豆瓣网影视数据分析与应用,展现了大数据在文化领域的巨大潜力与广阔前景。
关键词:Hadoop;豆瓣网影视;数据分析;数据可视化
所做工作及思路
本论文致力于探讨基于Hadoop的豆瓣网影视数据分析与应用,主要围绕数据挖掘、可视化及其在流行影视中的实际应用展开。
数据源获取:首先收集来自“豆瓣网”网站的多维度数据,包括热门影视、影视评论、语种等,以构建一个全面的影视数据库。
数据清洗:运用Python强大的数据处理和分析库,如Pandas、NumPy、Matplotlib等,对数据进行清洗和预处理。这一步骤不仅提高了数据的质量,也为后续分析打下了坚实基础。
数据存储:清洗后的数据需要存储在数据库和CSV文件中,以便后续的分析和建模。
数据可视化:利用Matplotlib和Seaborn等工具进行可视化展示,从而使得数据的趋势和特征更加直观。
影视推荐:通过协同过滤算法算法,深入挖掘数据中的潜在规律,通过对热门影视的时间序列分析,算法综合考虑用户行为数据与影视特征,为用户生成个性化推荐列表,同时为影视管理部门提供科学的决策依据,助力提升四川旅游资源的吸引力和游客满意度。
章节安排
论文共分5章。
第1章绪论:对豆瓣网影视的背景进行阐述,最后讲述关于本论文的工作与思路可以大致解论文所做的工作。
第2章相关技术介绍:介绍Hadoop作为数据分析工具的优势,如何利用Python的各种库(如Pandas、NumPy和Matplotlib)来处理和分析豆瓣网影视数据。
第3章需求分析:涉及数据的获取与预处理,还包括对影视特征的提取与分析方法的探讨。功能需求分析上讲了关于模型的相关数据源和数据处理等方面,非功能需求分析上主要讲解了模型的性能要求和准确性要求。
第4章影视数据分析与处理:讲解对数据收集和预处理的方法,通过分析数据的缺失和数据的错误从而处理数据。
第5章影视数据应用:论文将介绍分析结果的应用场景,探讨数据分析如何支持影视产业的决策制定、市场预测和用户行为分析等。
功能需求分析
数据收集
在进行豆瓣网影视数据分析之前,数据收集是至关重要的一步。豆瓣网作为一个综合性的文化社区,拥有丰富的用户生成内容,包括电影的评分、评论和标签。为了获取这些数据,可以通过多种方式进行。
首先,利用豆瓣的开放API接口,开发者可以直接获取所需的影视数据,这种方式既高效又便捷,适合需要大量数据的分析任务。
其次,虽然豆瓣API提供了相对稳定的数据源,但有些信息可能并不完整,或者在特定情况下受到访问限制,因此网络爬虫技术也成为了一种常用的方法。通过编写爬虫程序,能够定向抓取豆瓣网页上展示的各类影视信息,包括用户评论、评分、播放量等。这种方式虽然需要遵循网站的使用政策,但能够灵活获取更为详尽的数据。
数据整理与选择
在进行豆瓣网影视数据分析时,数据整理与选择的过程至关重要。豆瓣网作为一个拥有丰富影视评论和评分的社交平台,提供了大量的用户生成内容,包括电影、电视剧的评分、评论、标签等。首先,需要明确分析的目标,这将直接影响数据的选择和整理方式。比如,如果目标是分析用户对某一类型电影的偏好,那么可以选择相关的电影数据、用户评论以及评分信息。
接下来,数据的清洗过程不可忽视。原始数据往往包含缺失值、重复记录或不一致的格式,这些问题会影响后续的分析结果。因此,清理数据的过程包括去除无用信息、填补缺失值以及统一数据格式。对于豆瓣网的数据,特别是影评部分,情感分析的需求也促使我们在整理时考虑到评论的情感倾向,以便后续的深度分析。与此同时,选择合适的数据集也是关键,比如选择用户活跃度较高的时间段或特定类型的影视作品,这样可以更全面地反映用户的真实偏好。通过这些整理和选择的工作,最终会形成一个结构化、清晰且具有代表性的数据集,为后续的Hadoop分析打下良好的基础。这样的准备工作能够确保数据分析的有效性和准确性,使得最终的研究成果更具参考价值。
数据展示
在豆瓣网上,影视数据的展示方式丰富多样,能够有效吸引用户的注意力。用户可以通过图表、数据统计以及可视化工具直观地了解电影和电视剧的受欢迎程度、评分分布和评论趋势。
以评分为例,用户可以看到某部影片的历史评分变化曲线,这样的展示方式使得用户更容易理解影片的受欢迎程度是如何随时间变化而变化的。此外,豆瓣还提供了基于用户评分的推荐系统,用户在浏览某一类型的影片时,系统会自动推荐类似评分高的影片,提升了用户的观影体验。通过数据挖掘技术,豆瓣能够分析出观众的观看习惯和偏好,进而为用户提供个性化的内容推荐。用户在浏览影片时,往往会被影片的海报、预告片和评论吸引,这些元素的展示方式不仅美观,还能有效传达影片的主题和风格。结合用户生成内容,豆瓣的评论区成为了一个重要的信息交流平台,用户在这里分享观影感受,形成了独特的社区氛围。通过数据分析,豆瓣能够识别出热门评论和话题,从而在首页或推荐列表中进行重点展示。这种展示形式不仅提升了用户的参与感,也增强了平台的活跃度和粘性。总之,豆瓣网通过多种展示方式,充分利用数据分析技术,为用户提供了一个直观且互动性强的影视数据平台,极大地丰富了观影体验。
数据推荐
协同过滤(Collaborative Filtering,简称CF)是一种基于用户行为的推荐技术,广泛应用于影视、电影、电商等领域的个性化推荐系统中。其核心思想是通过分析大量用户对影视作品的评分、观看历史、评论等行为数据,发现具有相似兴趣的用户群体或影视作品之间的相似性,从而为目标用户推荐可能感兴趣的其他影视作品。
整体设计
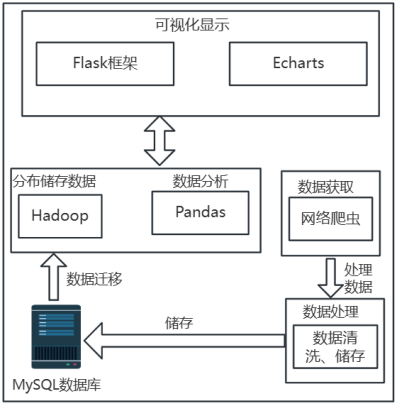
依托Hadoop的豆瓣网影视数据分析与应用架构过程中,全局设定应保障数据处理的高效运行及弹性。系统的核心组件融合数据获取、数据处理、数据储存、数据分析及用户操作平台。Flask实现用户界面的便捷性和互动的高效性,为用户打造高效的数据分析途径。Echarts对数据分析结果进行图表显示。系统架构如图4-1所示。
爬取豆瓣网网站
爬取步骤
在进行豆瓣网影视数据的爬取时,首先需要明确爬取的目标和范围。以豆瓣电影为例,可以选择特定的电影分类,如热门电影、评分最高的影片或某个特定导演的作品。
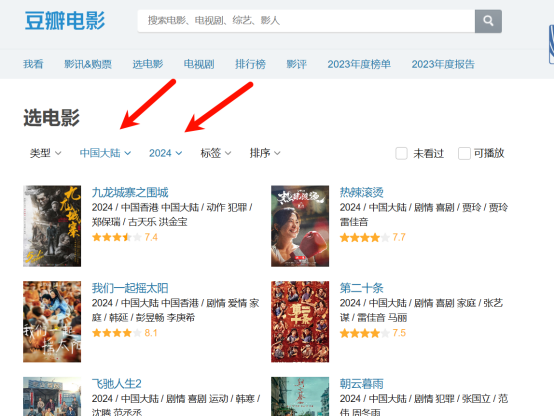
接下来,利用Python编程语言中的爬虫框架,如Scrapy或BeautifulSoup,进行具体的技术实现。在这一过程中,首先需要分析豆瓣网的网页结构,了解各个数据字段所在的HTML标签,这样才能准确提取所需的信息。
爬取过程中,设置合理的请求频率是必要的,以避免因访问过于频繁而导致IP被封禁。可以通过设置随机的时间间隔,模拟人类用户的访问行为,从而降低被封禁的风险。
数据爬取完成后,获取的原始数据需要经过清洗和格式化,以去除重复项和无效数据,这一步骤至关重要,因为原始数据往往包含许多噪声信息。
清洗后的数据可以存储在本地数据库或csv文件中,以便后续的分析和处理。整个爬取流程涉及到数据的提取、清洗和存储,每一步都需要细致入微,以确保最终的数据质量满足分析需求。
在进行豆瓣网影视数据分析时,爬虫技术是获取数据的重要手段。通过使用Python编写的爬取代码,可以有效地抓取豆瓣网的影视信息。代码的核心部分利用requests库发送HTTP请求,获取网页的HTML内容。随后,使用BeautifulSoup库对获取的HTML进行解析,从中提取出电影的名称、评分、评论数以及相关标签等关键数据。为了确保爬取的效率和准确性,设置了适当的请求间隔,避免对豆瓣服务器造成过大的压力。同时,针对不同的页面结构,采用了灵活的解析策略。比如,对于电影详细页面,代码会深入到每个电影的链接中,进一步抓取更为详细的内容,如导演、演员及剧情简介等信息。为了处理大量数据,代码还实现了数据存储功能,将爬取到的信息以CSV格式保存在本地,以供后续的数据分析与处理。此外,考虑到豆瓣网的反爬虫机制,代码中还加入了用户代理和请求头的设置,使得爬虫行为更加隐蔽,降低被封禁的风险。通过这样的方式,能够有效地收集到丰富的影视数据,为后续的分析提供坚实的基础。爬取完成后,利用Hadoop的分布式处理能力,可以对这些数据进行深度分析,从而揭示出影视作品的流行趋势和观众偏好,从而为相关业务决策提供支持。爬取豆瓣网核心代码如代4-1所示。
def spider(spiderTarget,start):# 每次调用spider获取20条数据headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36','Referer':'https://movie.douban.com/tag/','Cookie':'bid=6mHemZBr91A; __gads=ID=f6d1e29943a2289e-2235597b46cf0014:T=1637928036:RT=1637928036:S=ALNI_MbUV2rRDkg5u38czBTVDBFS0PLajA; ll="108305"; _vwo_uuid_v2=D05DF24F53B472D086C01A79B01735762|e5e120c8d217d8191d1303c2a5b5aa04; gr_user_id=6441c017-d74b-422f-af14-93a11a57112d; __yadk_uid=tajeNgKg6NT6nhEQczKfmecGcZqdVBXY; douban-fav-remind=1; __utmv=30149280.23512; _ga=GA1.2.1042859692.1637928038; viewed="2995812_1458367_6816154_1416697_1455695_1986653_1395176_3040149_1427374_4913064"; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1652841585%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DVlfhYZ2MEHRBSLvH1rcPwd4AYRrL-DQrWxaEeqtUjfETnWetwL98pNUbJ__vgCwN%26wd%3D%26eqid%3Da1df55aa0002864e0000000662845c64%22%5D; _pk_ses.100001.4cf6=*; ap_v=0,6.0; __utma=30149280.1042859692.1637928038.1649577909.1652841585.36; __utmb=30149280.0.10.1652841585; __utmc=30149280; __utmz=30149280.1652841585.36.12.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.1442664133.1641956556.1648885892.1652841585.22; __utmb=223695111.0.10.1652841585; __utmc=223695111; __utmz=223695111.1652841585.22.8.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; dbcl2="235123238:u9rdv3vTMd0"; ck=nl8E; _pk_id.100001.4cf6=023cbddd8ff1a247.1641956556.21.1652843267.1648885892.; push_noty_num=0; push_doumail_num=0'}params = {'start':start}movieAllRes = requests.get(spiderTarget,params=params,headers=headers)movieAllRes = movieAllRes.json()detailUrls = jsonpath.jsonpath(movieAllRes,'$.data..url')moveisInfomation = jsonpath.jsonpath(movieAllRes,'$.data')[0]for i,moveInfomation in enumerate(moveisInfomation):try:resultData = {}# 详情resultData['detailLink'] = detailUrls[i]# 导演(数组)resultData['directors'] = ','.join(moveInfomation['directors'])# 评分resultData['rate'] = moveInfomation['rate']# 影片名resultData['title'] = moveInfomation['title']# 主演(数组)resultData['casts'] = ','.join(moveInfomation['casts'])# 封面resultData['cover'] = moveInfomation['cover']# =================进入详情页================detailMovieRes = requests.get(detailUrls[i], headers=headers)soup = BeautifulSoup(detailMovieRes.text, 'lxml')# 上映年份resultData['year'] = re.findall(r'[(](.*?)[)]',soup.find('span', class_='year').get_text())[0]types = soup.find_all('span',property='v:genre')for i,span in enumerate(types):types[i] = span.get_text()# 影片类型(数组)resultData['types'] = ','.join(types)country = soup.find_all('span',class_='pl')[4].next_sibling.strip().split(sep='/')for i,c in enumerate(country):country[i] = c.strip()# 制作国家(数组)resultData['country'] = ','.join(country)lang = soup.find_all('span', class_='pl')[5].next_sibling.strip().split(sep='/')for i, l in enumerate(lang):lang[i] = l.strip()# 影片语言(数组)resultData['lang'] = ','.join(lang)upTimes = soup.find_all('span',property='v:initialReleaseDate')upTimesStr = ''for i in upTimes:upTimesStr = upTimesStr + i.get_text()upTime = re.findall(r'\d*-\d*-\d*',upTimesStr)[0]# 上映时间resultData['time'] = upTimeif soup.find('span',property='v:runtime'):# 时间长度resultData['moveiTime'] = re.findall(r'\d+',soup.find('span',property='v:runtime').get_text())[0]else:# 时间长度resultData['moveiTime'] = random.randint(39,61)# 评论个数resultData['comment_len'] = soup.find('span',property='v:votes').get_text()starts = []startAll = soup.find_all('span',class_='rating_per')for i in startAll:starts.append(i.get_text())# 星星比例(数组)resultData['starts'] = ','.join(starts)# 影片简介resultData['summary'] = soup.find('span',property='v:summary').get_text().strip()# 五条热评comments_info = soup.find_all('span', class_='comment-info')comments = [{} for x in range(5)]for i, comment in enumerate(comments_info):comments[i]['user'] = comment.contents[1].get_text()comments[i]['start'] = re.findall('(\d*)', comment.contents[5].attrs['class'][0])[7]comments[i]['time'] = comment.contents[7].attrs['title']contents = soup.find_all('span', class_='short')for i in range(5):comments[i]['content'] = contents[i].get_text()resultData['comments'] = json.dumps(comments)# 五张详情图imgList = []lis = soup.select('.related-pic-bd img')for i in lis:imgList.append(i['src'])resultData['imgList'] = ','.join(imgList)# 详情页结束# =================进入电影页===========if soup.find('a',class_='related-pic-video'):movieUrl = soup.find('a', class_='related-pic-video').attrs['href']foreshowMovieRes = requests.get(movieUrl,headers=headers)foreshowMovieSoup = BeautifulSoup(foreshowMovieRes.text,'lxml')movieSrc = foreshowMovieSoup.find('source').attrs['src']resultData['movieUrl'] = movieSrc # 电影路径else:resultData['movieUrl'] = '0'result.append(resultData)#进入电影页结束print('已经爬取%d条数据' % len(result))except :return
爬取完的豆瓣网影视数据效果如图4-4、图4-5所示。
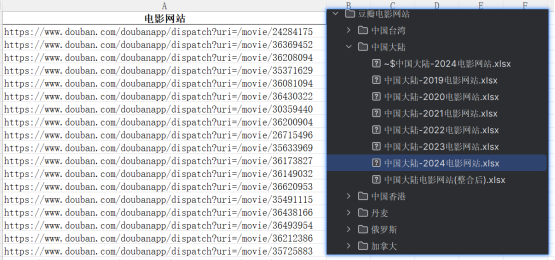

数据预处理
本节内容专注于影视数据的预处理工作,为确保后续文件信息的有效区分与管理,当前阶段特地选取了movieinfo.csv这一核心数据文件作为数据预处理的唯一来源。通过对该文件中的影视数据进行清洗、整理与初步分析,旨在为后续的影视综合数据分析及推荐系统构建奠定坚实的数据基础。此举不仅有助于提升数据处理效率,更能确保分析结果的准确性与可靠性,为豆瓣网影视数据分析项目的成功实施提供有力支撑。
数据分析与可视化,展示效果
影视种类数据分析与可视化
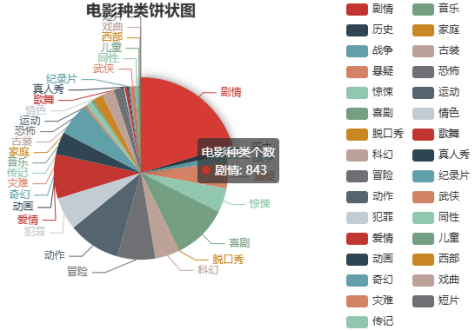
在对豆瓣网的影视数据进行分析时,影视种类的分布情况显得尤为重要。通过Hadoop技术的强大数据处理能力,可以对不同类型的影视作品进行深入挖掘。利用饼图展示各类型影视作品的市场份额,使得不同种类之间的比较更加清晰。这样一来,影视制作方和发行方可以根据观众的反馈和市场需求,调整自己的创作方向和宣传策略,从而更好地满足观众的期望。通过这种方式,数据分析不仅为影视行业提供了实证依据,也促进了影视文化的多样性与发展。
影视评分数据分析与可视化
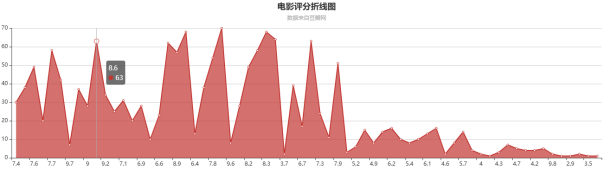
影视评分数据分析与可视化是理解用户偏好和市场趋势的重要手段。豆瓣网作为一个广受欢迎的影视评论平台,积累了大量的用户评分和评论数据,这为深入分析提供了丰富的素材。在这一过程中,使用Hadoop等大数据处理框架,使得对海量数据的处理变得高效且便捷。首先,通过对评分数据的聚合分析,可以揭示出不同类型影片的受欢迎程度,比如动作片与爱情片之间的评分差异,或是不同导演、演员的影响力。进一步的,基于评分的分布情况,可以绘制出直方图,清晰地展示出用户对各类影片的评价集中程度,以及存在的极端评分情况。
这样的可视化不仅让人们直观地看到数据背后的趋势,还能为影视行业的从业者提供有效的决策依据。深入探讨评分的时间序列变化,能够揭示出某些影片在特定时期内的热度变化,进而分析其与市场营销活动或社会事件的关联,提供更全面的视角。通过结合用户的评论内容,进一步分析评分与评论之间的关系,这种多维度的分析方式能够帮助研究者更好地理解用户的观影动机和情感态度。总的来说,影视评分数据的分析与可视化不仅为学术研究提供了基础,也为业内人士的市场策略制定提供了重要参考。以下是影视评分可视化图形核心代码:
影视时长数据分析与可视化
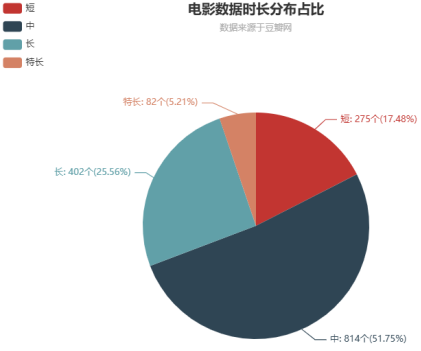
在对豆瓣网影视数据进行分析时,影视时长作为一个关键指标,能够揭示出影片的叙事结构和观众的观看体验。通过对数据的深入挖掘,可以发现不同类型影片在时长上的差异。例如,动作片和科幻片往往倾向于较长的播放时间,以便充分展现复杂的情节和特效,而喜剧片则可能更短,以保持轻松的节奏。通过Hadoop的分布式计算能力,我们能够高效地处理海量的影视时长数据,进而生成可视化图表,帮助我们更直观地理解这些差异。以下是影视时长可视化图形核心代码:
影视国家数据分析与可视化
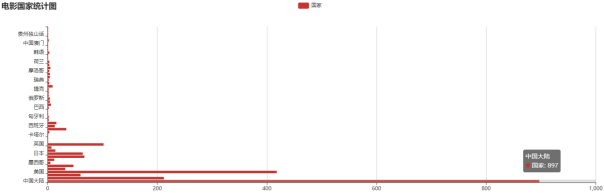
影视国家数据分析与可视化的过程揭示了不同国家在影视作品创作中的独特风格和市场趋势。通过对豆瓣网上的影视数据进行深入挖掘,可以观察到各国影片的评分、观看人数以及评论数等指标的差异。通过柱状图展示各国影片的评分分布,可以清晰地看到哪些国家的影片更受欢迎,观众的偏好又是如何变化的。
影视语言数据分析与可视化
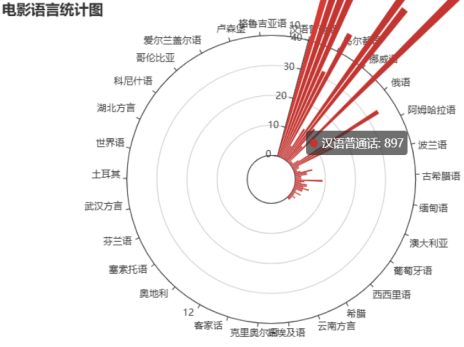
影视语言的数据分析与可视化在理解观众偏好和提升内容创作质量方面具有重要意义。对不同类型影片的语言使用进行比较分析,可以发现不同类型影片在语言风格上的显著差异。通过这种方式,影视语言的数据分析与可视化不仅助力于作品的成功,也为整个行业的发展提供了新的视角。
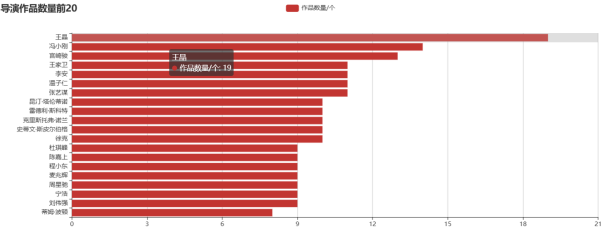
影视导演数据分析与可视化
在对豆瓣网的影视数据进行分析时,导演的数据成为了不可忽视的重要组成部分。导演在影视作品中扮演着关键角色,他们的风格、作品数量与受欢迎程度直接影响着观众的观影体验。分析不同导演的作品评分与类型,可以发现某些导演在特定类型的影片中表现更为出色。通过对导演执导作品数量的统计,可以识别出行业内的“高产”导演与“精品”导演之间的差异,进而引发对导演创作风格与市场需求之间关系的思考。利用可视化工具,能够将这些数据以直观的方式呈现,通过柱状图显示不同导演的平均评分这样的图形化展示能够帮助观众迅速抓住重点信息。
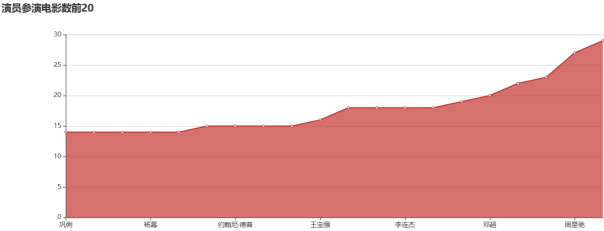
影视演员数据分析与可视化
影视演员在豆瓣网的数据分析中显得尤为重要,这不仅可以反映出他们的受欢迎程度,还能揭示出观众对其作品的评价。通过Hadoop的强大数据处理能力,可以对海量的影视演员数据进行深入挖掘。可以分析出哪些演员在影视作品中表现突出,这样的数据分析能够帮助制片方在选角时做出更为明智的决策。同时,观众的评分和评论也为演员的职业发展提供了参考。通过对演员参与的电影和电视剧进行评分统计,可以发现某些演员在特定时期内的表现变化,揭示出他们的职业生涯轨迹。

协同过滤算法
协同过滤(Collaborative Filtering,简称CF)是一种基于用户行为的推荐技术,广泛应用于影视、电影、电商等领域的个性化推荐系统中。其核心思想是通过分析大量用户对影视作品的评分、观看历史、评论等行为数据,发现具有相似兴趣的用户群体或影视作品之间的相似性,从而为目标用户推荐可能感兴趣的其他影视作品。
协同过滤算法主要分为基于用户的协同过滤(User-based CF)和基于物品的协同过滤(Item-based CF)两种。基于用户的协同过滤算法是通过计算用户之间的相似度,如果用户A和用户B都喜欢电影X和电影Y,而用户A还喜欢电影Z,那么可以将电影Z推荐给用户B。而基于物品的协同过滤算法则是通过分析影视之间的相似性,推荐与用户已喜欢影视相似的其他影视。
在协同过滤算法中,相似度的计算是关键。常用的相似度度量方法包括杰卡德(Jaccard)相似系数、余弦相似度和皮尔逊相关系数等。这些方法可以帮助准确地衡量用户或物品之间的相似程度,从而为推荐提供可靠的依据。
协同过滤算法代码实现
在基于Hadoop的豆瓣网影视数据分析与应用中,协同过滤算法可以通过MapReduce编程模型实现大规模数据的并行处理。Hadoop的分布式文件系统(HDFS)可以存储海量的用户行为数据,而MapReduce作业则可以对这些数据进行高效的计算和分析。通过将协同过滤算法的关键步骤分解为多个MapReduce任务,可以实现算法的分布式执行,从而提高处理速度和可扩展性。协同过滤算法代码实现(核心代码):
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 假设我们有一个DataFrame,其中包含用户ID、影视ID和评分
# 例如:data = {'user_id': [1, 1, 1, 2, 2, 3, 3], 'movie_id': [101, 102, 103, 101, 104, 102, 105], 'rating': [5, 3, 4, 4, 5, 2, 3]}
# df = pd.DataFrame(data)
# 读取数据(这里假设数据已经加载到DataFrame中)
# df = pd.read_csv('path_to_your_data.csv')
# 创建一个用户-影视评分矩阵
user_movie_matrix = df.pivot(index='user_id', columns='movie_id', values='rating').fillna(0)
# 计算用户之间的相似度(余弦相似度)
user_similarity = cosine_similarity(user_movie_matrix)
user_similarity_df = pd.DataFrame(user_similarity, index=user_movie_matrix.index, columns=user_movie_matrix.index)# 为每个用户生成推荐列表
def get_recommendations(user_id, user_similarity_df, user_movie_matrix, num_recommendations=5):# 获取当前用户与其他用户的相似度similar_users = user_similarity_df[user_id].sort_values(ascending=False)# 排除当前用户自身similar_users = similar_users[similar_users.index != user_id]# 获取相似用户看过的影视及其评分,并加权求和weighted_sum = np.zeros(user_movie_matrix.shape)similarity_sum = np.zeros(user_movie_matrix.shape)for similar_user in similar_users.index:weight = similar_users[similar_user]watched_movies = user_movie_matrix.loc[similar_user]weighted_sum += weight * watched_moviessimilarity_sum += weight * (watched_movies > 0)# 避免除以0similarity_sum[similarity_sum == 0] = 1# 计算加权评分并进行归一化recommendations = weighted_sum / similarity_sum# 过滤掉当前用户已经看过的影视user_watched_movies = (user_movie_matrix.loc[user_id] > 0)recommendations[user_watched_movies] = 0# 获取推荐列表rec_df = pd.DataFrame(recommendations, index=user_movie_matrix.columns, columns=['score'])return rec_df.sort_values(by='score', ascending=False).head(num_recommendations)
# 示例:为用户1生成推荐列表
recommendations = get_recommendations(user_id=1, user_similarity_df=user_similarity_df, user_movie_matrix=user_movie_matrix)
print(recommendations)
系统能够实时更新数据,反映出不同影视的受欢迎程度以及游客的偏好变化。这样一来,景区不仅可以在高峰期提供更好的服务,降低拥堵,还能在淡季推出相应的促销活动,吸引更多游客。
)

:组织、血液、体液制备方法详解)

)
)



 IDA动态调试Android so文件)









