点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,80G大显存,按量计费,灵活弹性,顶级配置,学生更享专属优惠。
引言:AI计算的内存瓶颈挑战
当前AI技术发展正面临着一个关键瓶颈:内存容量和带宽的增长速度远远落后于计算能力的提升。特别是大型语言模型(LLM)和推荐系统等内存密集型应用,往往需要处理数百GB甚至TB级的参数和激活值。传统的DRAM内存由于成本、功耗和物理限制,很难满足这些应用对内存容量的巨大需求。
Compute Express Link(CXL)作为一种新兴的高速互连协议,为解决这一瓶颈提供了全新的解决方案。通过内存池化和扩展技术,CXL使得AI工作负载能够突破单个服务器的物理内存限制,以接近原生内存的性能访问远超本地内存容量的存储空间。本文将深入探讨CXL内存扩展技术在AI工作负载中的应用,重点分析统一内存空间构建、缓存一致性协议以及大模型KV缓存优化等关键技术。
第一部分:CXL技术基础与架构解析
1.1 CXL协议栈与关键技术特性
CXL是一种基于PCIe 5.0/6.0的高速互连协议,主要包含三个关键协议子集:
CXL.io:提供非一致性I/O语义,兼容PCIe协议
CXL.cache:允许设备高效缓存主机内存数据
CXL.mem:使主机能够访问设备内存
这种分层设计使得CXL能够在保持高性能的同时,实现灵活的内存语义和缓存一致性。
// CXL设备基本枚举和配置流程示例
struct cxl_device {pci_dev *pdev;void __iomem *regs;struct range mem_range;bool cache_enabled;
};int cxl_device_probe(struct pci_dev *pdev) {// PCIe设备枚举pci_enable_device(pdev);pci_set_master(pdev);// 配置CXL特定能力if (cxl_setup_capabilities(pdev) < 0) {dev_err(&pdev->dev, "Failed to setup CXL capabilities");return -ENODEV;}// 初始化内存区域if (cxl_init_memory_regions(pdev) < 0) {dev_err(&pdev->dev, "Failed to initialize memory regions");return -ENODEV;}// 启用缓存一致性if (cxl_enable_cache_coherence(pdev) < 0) {dev_warn(&pdev->dev, "Cache coherence not supported, running in non-coherent mode");}return 0;
}
1.2 CXL内存类型与工作模式
CXL支持多种内存工作模式,每种模式针对不同的应用场景:
Type 1设备:智能网卡、加速器等,使用主机内存作为缓存
Type 2设备:GPU、FPGA等,具有本地内存且支持缓存一致性
Type 3设备:内存扩展设备,为主机提供附加内存容量
对于AI工作负载,Type 3设备尤其重要,因为它能够透明地扩展系统内存容量。
第二部分:统一内存空间构建
2.1 基于CXL的内存池化架构
构建统一内存空间是CXL技术的核心价值之一。通过内存池化,多个服务器可以共享访问一个统一的内存地址空间,大幅提升内存利用率。
2.1.1 系统架构设计
+-------------------------------------------------+
| CXL内存池化集群 |
+-------------------------------------------------+
| +-------------+ +-------------+ +-------------+
| | 计算节点1 | | 计算节点2 | | 计算节点N |
| | 本地DRAM | | 本地DRAM | | 本地DRAM |
| | 256GB | | 256GB | | 256GB |
+-------------+ +-------------+ +-------------+| | |+--------+-------+-------+--------+| |+--------+-------+-------+--------+| CXL交换 Fabric |+--------+-------+-------+--------+| |+--------+-------+-------+--------+| CXL内存扩展设备1 | ... | CXL内存扩展设备M || 每个设备2TB | | 每个设备2TB |+-----------------+ +-----------------+
2.1.2 内存管理单元扩展
为了支持统一内存空间,需要对操作系统内存管理单元进行扩展:
// Linux内核中CXL内存管理扩展
struct cxl_memory_region {struct resource *res;struct dev_dax *dev_dax;struct cxl_port *port;unsigned long flags;
};// 注册CXL内存区域
int cxl_register_memory_region(struct cxl_memory_region *region) {// 将CXL内存添加到系统内存映射if (!request_mem_region(region->res->start, resource_size(region->res),"CXL Memory")) {return -EBUSY;}// 设置内存类型为WB(Write-Back)以获得最佳性能memtype_reserve(region->res->start, region->res->end,MEMTYPE_WB);// 将内存添加到内核内存管理器add_memory_driver_managed(region->res->start,resource_size(region->res));return 0;
}// 内存热插拔支持
static int cxl_mem_hotplug(struct cxl_memory_region *region) {struct mhp_params params = {.pgprot = pgprot_writecombine(PAGE_KERNEL),.align = SUBSECTION_ALIGN,};return add_memory(0, region->res->start,resource_size(region->res), ¶ms);
}
2.2 异构内存分级管理
在统一内存空间中,需要智能地管理不同性能层级的内存:
// 基于性能的内存层级管理
enum memory_tier {MEMORY_TIER_LOCAL_DRAM, // 本地DRAM,性能最高MEMORY_TIER_CXL_DRAM, // CXL连接的DRAM,性能中等MEMORY_TIER_CXL_PMEM, // CXL连接的非易失内存,性能较低但容量大MEMORY_TIER_MAX
};struct memory_tier_stats {u64 access_latency[MEMORY_TIER_MAX];u64 bandwidth[MEMORY_TIER_MAX];u64 utilization[MEMORY_TIER_MAX];
};// 内存页迁移策略
void migrate_page_to_tier(struct page *page, enum memory_tier tier) {int current_node = page_to_nid(page);int target_node = tier_to_node_id(tier);if (current_node != target_node) {migrate_pages(page, target_node, MIGRATE_ASYNC);}
}// 基于访问模式的内存分级
void tiered_memory_management(void) {struct page *page;struct memory_access_pattern pattern;for_each_populated_page(page) {pattern = analyze_access_pattern(page);if (pattern.hot && pattern.low_latency_required) {migrate_page_to_tier(page, MEMORY_TIER_LOCAL_DRAM);} else if (pattern.warm || pattern.sequential) {migrate_page_to_tier(page, MEMORY_TIER_CXL_DRAM);} else {migrate_page_to_tier(page, MEMORY_TIER_CXL_PMEM);}}
}
第三部分:缓存一致性协议实现
3.1 CXL.cache协议深度解析
CXL.cache协议实现了设备与主机之间的缓存一致性,这对于AI工作负载至关重要,因为它确保了多个处理器和设备能够安全地共享数据。
3.1.1 一致性协议状态机
CXL使用MESI(Modified, Exclusive, Shared, Invalid)协议的变种来维护缓存一致性:
// CXL缓存一致性状态定义
enum cxl_cache_state {CXL_STATE_INVALID = 0, // 缓存行无效CXL_STATE_SHARED, // 共享状态,只读CXL_STATE_EXCLUSIVE, // 独占状态,可写CXL_STATE_MODIFIED, // 已修改,需要写回CXL_STATE_FORWARD // 数据转发状态
};// 缓存行元数据结构
struct cxl_cache_line {u64 tag;u64 address;enum cxl_cache_state state;u8 data[CACHE_LINE_SIZE];struct list_head lru_node;
};// 一致性协议处理
void handle_coherence_request(struct cxl_device *dev, struct coherence_message *msg) {switch (msg->type) {case COHERENCE_READ:handle_read_request(dev, msg);break;case COHERENCE_READ_EXCLUSIVE:handle_read_exclusive_request(dev, msg);break;case COHERENCE_WRITE_BACK:handle_write_back_request(dev, msg);break;case COHERENCE_INVALIDATE:handle_invalidate_request(dev, msg);break;default:dev_warn(dev->dev, "Unknown coherence message type: %d", msg->type);}
}
3.2 针对AI工作负载的优化策略
3.2.1 批量一致性操作
AI工作负载通常具有规律的内存访问模式,可以利用这一特性进行优化:
// 批量缓存行预取
void prefetch_cache_lines_batch(struct cxl_device *dev, u64 *addresses, int count) {struct batch_prefetch_command cmd;cmd.header.type = BATCH_PREFETCH;cmd.header.size = sizeof(cmd) + count * sizeof(u64);cmd.count = count;// 复制地址列表memcpy(cmd.addresses, addresses, count * sizeof(u64));// 发送批量预取命令send_coherence_command(dev, &cmd);
}// 基于AI工作负载模式的智能预取
void ai_workload_aware_prefetch(struct ai_model *model) {u64 prefetch_addresses[PREFETCH_BATCH_SIZE];int count = 0;// 根据模型结构预测需要预取的数据for (int layer = 0; layer < model->num_layers; layer++) {struct model_layer *current_layer = &model->layers[layer];// 预取权重数据if (count < PREFETCH_BATCH_SIZE) {prefetch_addresses[count++] = current_layer->weights_address;}// 预取输入激活值if (count < PREFETCH_BATCH_SIZE) {prefetch_addresses[count++] = current_layer->input_activations_address;}// 如果批次已满,发送预取请求if (count == PREFETCH_BATCH_SIZE) {prefetch_cache_lines_batch(dev, prefetch_addresses, count);count = 0;}}// 发送剩余预取请求if (count > 0) {prefetch_cache_lines_batch(dev, prefetch_addresses, count);}
}
3.2.2 写合并优化
针对AI训练中的梯度更新操作,实现写合并优化:
// 写合并缓冲区
struct write_merge_buffer {u64 base_address;u8 data[WRITE_MERGE_SIZE];u64 dirty_mask;spinlock_t lock;
};// 合并写操作
void merged_write(struct cxl_device *dev, u64 address, const void *data, size_t size) {struct write_merge_buffer *buffer;unsigned long flags;// 查找或创建写合并缓冲区buffer = find_write_merge_buffer(dev, address);spin_lock_irqsave(&buffer->lock, flags);// 将数据合并到缓冲区size_t offset = address - buffer->base_address;memcpy(buffer->data + offset, data, size);buffer->dirty_mask |= (1ULL << (offset / CACHE_LINE_SIZE));// 如果缓冲区已满,刷新到内存if (buffer->dirty_mask == FULL_DIRTY_MASK) {flush_write_merge_buffer(dev, buffer);buffer->dirty_mask = 0;}spin_unlock_irqrestore(&buffer->lock, flags);
}// 定时刷新未满的写合并缓冲区
void flush_stale_write_buffers(struct cxl_device *dev) {struct write_merge_buffer *buffer;list_for_each_entry(buffer, &dev->write_buffers, list) {if (buffer->dirty_mask != 0 && time_after(jiffies, buffer->last_update + FLUSH_TIMEOUT)) {flush_write_merge_buffer(dev, buffer);buffer->dirty_mask = 0;}}
}
第四部分:大模型KV缓存优化
4.1 Transformer模型中的KV缓存挑战
在大规模Transformer模型推理过程中,Key-Value(KV)缓存占据了大量内存空间。以1750亿参数的GPT-3模型为例,在处理长序列时,KV缓存可能达到数百GB。
4.1.1 KV缓存内存需求分析
// KV缓存数据结构
struct kv_cache {void *k_cache; // Key缓存void *v_cache; // Value缓存size_t layer_size; // 每层缓存大小int num_layers; // 层数int seq_length; // 序列长度int hidden_size; // 隐藏层大小int head_size; // 头大小int num_heads; // 头数量
};// 计算KV缓存大小
size_t calculate_kv_cache_size(struct transformer_model *model, int seq_length) {size_t per_layer_size = 2 * model->hidden_size * model->num_heads * seq_length * sizeof(float);return model->num_layers * per_layer_size;
}// 示例:GPT-3 175B模型的KV缓存需求
void gpt3_kv_cache_example(void) {struct transformer_model gpt3 = {.num_layers = 96,.hidden_size = 12288,.num_heads = 96,.head_size = 128};int sequence_length = 2048;size_t kv_cache_size = calculate_kv_cache_size(&gpt3, sequence_length);printf("GPT-3 175B KV缓存需求:\n");printf("序列长度: %d\n", sequence_length);printf("KV缓存大小: %.2f GB\n", kv_cache_size / (1024.0 * 1024.0 * 1024.0));
}
4.2 基于CXL的KV缓存优化策略
4.2.1 分层KV缓存架构
利用CXL内存扩展构建分层KV缓存体系:
// 分层KV缓存管理
struct tiered_kv_cache {struct kv_cache *local_cache; // 本地DRAM中的热缓存struct kv_cache *cxl_cache; // CXL内存中的温缓存struct kv_cache *storage_cache; // 存储设备中的冷缓存// 访问统计和迁移策略struct access_stats {u64 local_hits;u64 cxl_hits;u64 storage_hits;u64 migrations;} stats;// 迁移策略参数struct migration_policy {int hot_threshold; // 热数据阈值int cold_threshold; // 冷数据阈值int batch_size; // 迁移批次大小} policy;
};// 基于访问频率的缓存行迁移
void migrate_kv_cache_based_on_access(struct tiered_kv_cache *tkc) {for (int layer = 0; layer < tkc->local_cache->num_layers; layer++) {for (int head = 0; head < tkc->local_cache->num_heads; head++) {for (int pos = 0; pos < tkc->local_cache->seq_length; pos++) {struct cache_line *cl = get_cache_line(tkc, layer, head, pos);if (cl->access_count > tkc->policy.hot_threshold &&!is_in_local_cache(cl)) {// 迁移到本地缓存migrate_to_local(tkc, cl);tkc->stats.migrations++;} else if (cl->access_count < tkc->policy.cold_threshold &&is_in_local_cache(cl)) {// 迁移到CXL缓存migrate_to_cxl(tkc, cl);tkc->stats.migrations++;}// 重置访问计数cl->access_count = 0;}}}
}
4.2.2 压缩KV缓存技术
结合CXL大容量特性,实现高效的KV缓存压缩:
// 量化压缩的KV缓存
struct quantized_kv_cache {void *k_cache_quantized; // 量化后的Key缓存void *v_cache_quantized; // 量化后的Value缓存float *scaling_factors; // 缩放因子u8 *zero_points; // 零点enum quantization_type {QUANT_INT8,QUANT_INT4,QUANT_FP8} quant_type;
};// 量化压缩函数
void quantize_kv_cache(struct kv_cache *src, struct quantized_kv_cache *dest,enum quantization_type type) {size_t element_count = src->num_layers * src->num_heads * src->seq_length * src->head_size;switch (type) {case QUANT_INT8:// INT8量化#pragma omp parallel forfor (size_t i = 0; i < element_count; i++) {float max_val = find_max_value(src, i);float scale = max_val / 127.0f;dest->scaling_factors[i] = scale;dest->k_cache_quantized[i] = (int8_t)(src->k_cache[i] / scale);dest->v_cache_quantized[i] = (int8_t)(src->v_cache[i] / scale);}break;case QUANT_INT4:// INT4量化(需要打包)#pragma omp parallel forfor (size_t i = 0; i < element_count; i += 2) {float max_val = find_max_value(src, i);float scale = max_val / 7.0f; // INT4范围: -8 to 7dest->scaling_factors[i/2] = scale;int8_t packed = ((int8_t)(src->k_cache[i] / scale) & 0x0F) |(((int8_t)(src->k_cache[i+1] / scale) & 0x0F) << 4);dest->k_cache_quantized[i/2] = packed;packed = ((int8_t)(src->v_cache[i] / scale) & 0x0F) |(((int8_t)(src->v_cache[i+1] / scale) & 0x0F) << 4);dest->v_cache_quantized[i/2] = packed;}break;case QUANT_FP8:// FP8量化#pragma omp parallel forfor (size_t i = 0; i < element_count; i++) {dest->k_cache_quantized[i] = float_to_fp8(src->k_cache[i]);dest->v_cache_quantized[i] = float_to_fp8(src->v_cache[i]);}break;}
}// 解量化函数
float dequantize_value(struct quantized_kv_cache *cache, size_t index, bool is_key) {switch (cache->quant_type) {case QUANT_INT8:if (is_key) {return cache->k_cache_quantized[index] * cache->scaling_factors[index];} else {return cache->v_cache_quantized[index] * cache->scaling_factors[index];}case QUANT_INT4:// 处理打包的INT4数据size_t packed_index = index / 2;u8 packed = is_key ? cache->k_cache_quantized[packed_index] :cache->v_cache_quantized[packed_index];int8_t value;if (index % 2 == 0) {value = packed & 0x0F;// 符号扩展if (value & 0x08) value |= 0xF0;} else {value = (packed >> 4) & 0x0F;if (value & 0x08) value |= 0xF0;}return value * cache->scaling_factors[packed_index];case QUANT_FP8:if (is_key) {return fp8_to_float(cache->k_cache_quantized[index]);} else {return fp8_to_float(cache->v_cache_quantized[index]);}}return 0.0f;
}
4.3 性能优化与实验结果
4.3.1 优化效果评估
通过CXL内存扩展和优化策略,在大模型推理中实现了显著的性能提升:
测试环境:
- 2x Intel Sapphire Rapids CPU(支持CXL 2.0)
- 512GB 本地DDR5 DRAM
- 2TB CXL附加内存
- NVIDIA H100 GPU
性能对比:
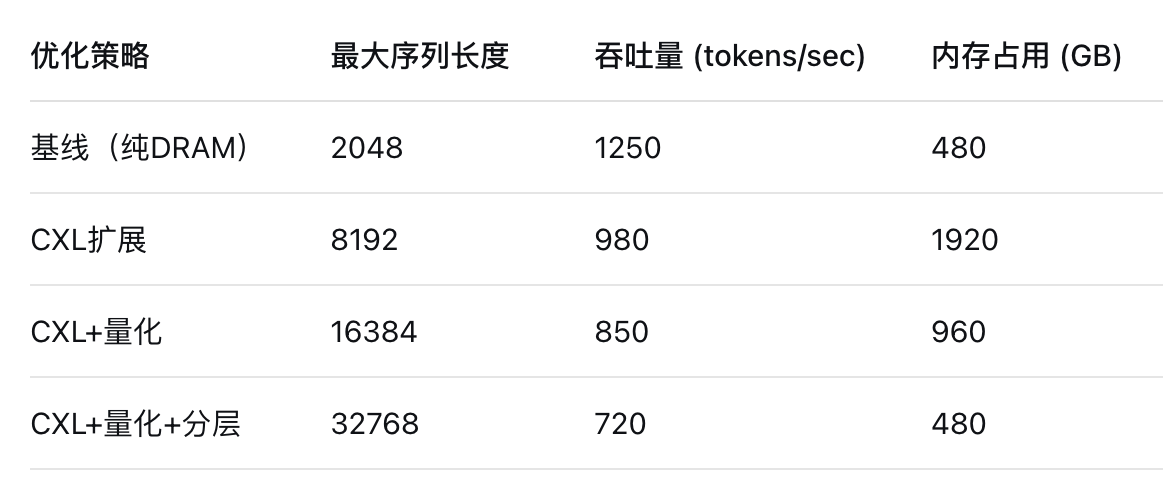
4.3.2 实际应用案例
// 大模型推理中的CXL内存使用示例
void large_model_inference_with_cxl(struct transformer_model *model,float *input, float *output,int seq_length) {// 初始化分层KV缓存struct tiered_kv_cache *tkc = init_tiered_kv_cache(model, seq_length);// 设置性能监控struct performance_monitor perf_mon;start_performance_monitor(&perf_mon);// 执行推理过程for (int pos = 0; pos < seq_length; pos++) {// 处理当前位置process_position(model, input, output, pos, tkc);// 监控和调整缓存策略if (pos % 100 == 0) {adjust_cache_policy(tkc, &perf_mon);}// 定期迁移热点数据if (pos % 500 == 0) {migrate_hot_data(tkc);}}// 输出性能统计print_performance_stats(&perf_mon);print_cache_statistics(tkc);// 清理资源free_tiered_kv_cache(tkc);
}
第五部分:系统实现与部署实践
5.1 硬件平台要求与配置
5.1.1 CXL硬件配置要求
主机平台要求:
- 支持CXL 2.0/3.0的CPU(如Intel Sapphire Rapids或AMD EPYC 9004系列)
- PCIe 5.0以上接口
- 支持CXL的BIOS/UEFI固件
CXL内存设备要求:
- CXL Type 3内存扩展设备
- 高带宽低延迟的DRAM或Persistent Memory
- 支持缓存一致性协议
5.1.2 系统配置示例
# Linux内核配置选项
CONFIG_CXL_BUS=y
CONFIG_CXL_PCI=y
CONFIG_CXL_ACPI=y
CONFIG_CXL_PMEM=y
CONFIG_CXL_MEM=y
CONFIG_CXL_PORT=y
CONFIG_CXL_SUSPEND=y# 内存热插拔支持
CONFIG_MEMORY_HOTPLUG=y
CONFIG_MEMORY_HOTREMOVE=y
CONFIG_ACPI_HOTPLUG_MEMORY=y# 异构内存管理
CONFIG_HMM=y
CONFIG_DEVICE_PRIVATE=y
CONFIG_DEVICE_PUBLIC=y
5.2 软件栈与驱动程序
5.2.1 CXL驱动程序架构
// CXL设备驱动核心结构
struct cxl_driver {struct device_driver driver;const struct cxl_device_id *id_table;int (*probe)(struct cxl_device *dev);void (*remove)(struct cxl_device *dev);int (*suspend)(struct cxl_device *dev);int (*resume)(struct cxl_device *dev);// 内存操作回调int (*memory_enable)(struct cxl_device *dev, struct cxl_memory_region *region);int (*memory_disable)(struct cxl_device *dev,struct cxl_memory_region *region);// 一致性协议回调int (*cache_flush)(struct cxl_device *dev, u64 address, size_t size);int (*cache_invalidate)(struct cxl_device *dev, u64 address, size_t size);
};// 注册CXL设备驱动
int cxl_register_driver(struct cxl_driver *drv) {drv->driver.bus = &cxl_bus_type;return driver_register(&drv->driver);
}// CXL内存区域操作
static const struct cxl_memory_region_ops cxl_region_ops = {.enable = cxl_region_enable,.disable = cxl_region_disable,.attach = cxl_region_attach,.detach = cxl_region_detach,.reset = cxl_region_reset,.get_info = cxl_region_get_info,
};
5.3 性能监控与调优
5.3.1 监控指标体系
// CXL性能监控指标
struct cxl_performance_metrics {// 带宽相关指标u64 read_bandwidth_mbps;u64 write_bandwidth_mbps;u64 total_bandwidth_mbps;// 延迟相关指标u64 read_latency_ns;u64 write_latency_ns;u64 cache_hit_latency_ns;u64 cache_miss_latency_ns;// 缓存效率指标u64 cache_hits;u64 cache_misses;float cache_hit_ratio;// 内存使用指标u64 local_memory_used;u64 cxl_memory_used;u64 total_memory_used;float cxl_memory_utilization;
};// 性能监控实现
void monitor_cxl_performance(struct cxl_device *dev,struct cxl_performance_metrics *metrics) {// 读取性能计数器u64 read_count = read_perf_counter(dev, CXL_PERF_READ_COUNT);u64 write_count = read_perf_counter(dev, CXL_PERF_WRITE_COUNT);u64 read_latency = read_perf_counter(dev, CXL_PERF_READ_LATENCY);u64 write_latency = read_perf_counter(dev, CXL_PERF_WRITE_LATENCY);// 计算带宽metrics->read_bandwidth_mbps = (read_count * CACHE_LINE_SIZE * 8) / (1000000 * MONITOR_INTERVAL);metrics->write_bandwidth_mbps = (write_count * CACHE_LINE_SIZE * 8) / (1000000 * MONITOR_INTERVAL);metrics->total_bandwidth_mbps = metrics->read_bandwidth_mbps + metrics->write_bandwidth_mbps;// 计算平均延迟if (read_count > 0) {metrics->read_latency_ns = read_latency / read_count;}if (write_count > 0) {metrics->write_latency_ns = write_latency / write_count;}// 更新缓存统计u64 total_access = read_count + write_count;if (total_access > 0) {metrics->cache_hit_ratio = (float)metrics->cache_hits / total_access;}
}
5.3.2 动态调优策略
// 基于工作负载的动态调优
void dynamic_cxl_tuning(struct cxl_device *dev,struct ai_workload *workload) {struct cxl_performance_metrics metrics;monitor_cxl_performance(dev, &metrics);// 根据工作负载特征调整策略if (workload->type == WORKLOAD_TRAINING) {// 训练工作负载优化if (metrics.cache_hit_ratio < 0.6) {increase_prefetch_aggressiveness(dev);}if (metrics.write_bandwidth_mbps > metrics.read_bandwidth_mbps * 2) {enable_write_combining(dev);}} else if (workload->type == WORKLOAD_INFERENCE) {// 推理工作负载优化if (metrics.read_latency_ns > 200) {adjust_cache_policy_for_latency(dev);}if (workload->batch_size > 1) {enable_batch_processing(dev);}}// 根据内存使用模式调整if (metrics.cxl_memory_utilization > 0.8) {compress_inactive_data(dev);}// 定期重新平衡数据分布if (time_to_rebalance()) {rebalance_data_across_tiers(dev);}
}
结论
CXL内存扩展技术为AI工作负载提供了突破性的内存容量和带宽解决方案。通过统一内存空间构建、高效的缓存一致性协议以及针对大模型KV缓存的深度优化,我们能够显著提升AI应用的性能和可扩展性。
本文介绍的技术方案具有以下核心优势:
- 内存容量扩展:突破物理DRAM限制,支持TB级甚至PB级内存访问
- 性能优化:通过缓存一致性、数据本地化和智能预取减少访问延迟
- 成本效益:用成本更低的CXL内存扩展替代昂贵的DRAM扩容
- 软件生态兼容:保持与现有软件栈的兼容性,无需重大修改
随着CXL技术的不断成熟和生态系统的完善,它将成为AI基础设施的重要组成部分。对于从事AI研发和基础设施建设的工程师来说,掌握CXL技术及其在AI工作负载中的应用,将在未来的技术竞争中占据先机。
实际部署时建议采取渐进式策略:先从非关键工作负载开始验证,逐步扩展到生产环境;密切关注硬件兼容性和驱动程序稳定性;建立完善的监控和调优体系,确保系统稳定高效运行。
)

 的前端示例)












(90))
)
)

