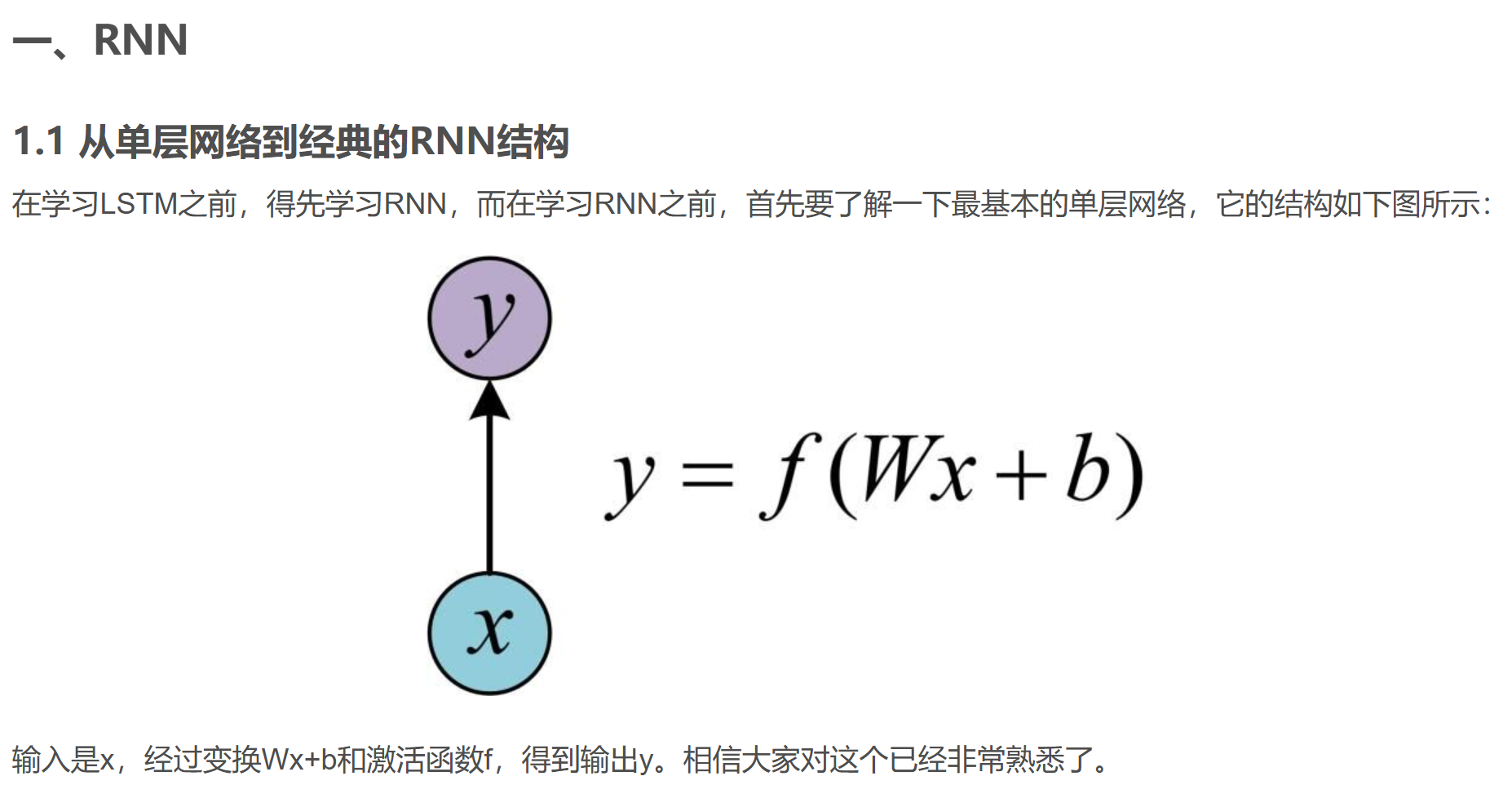


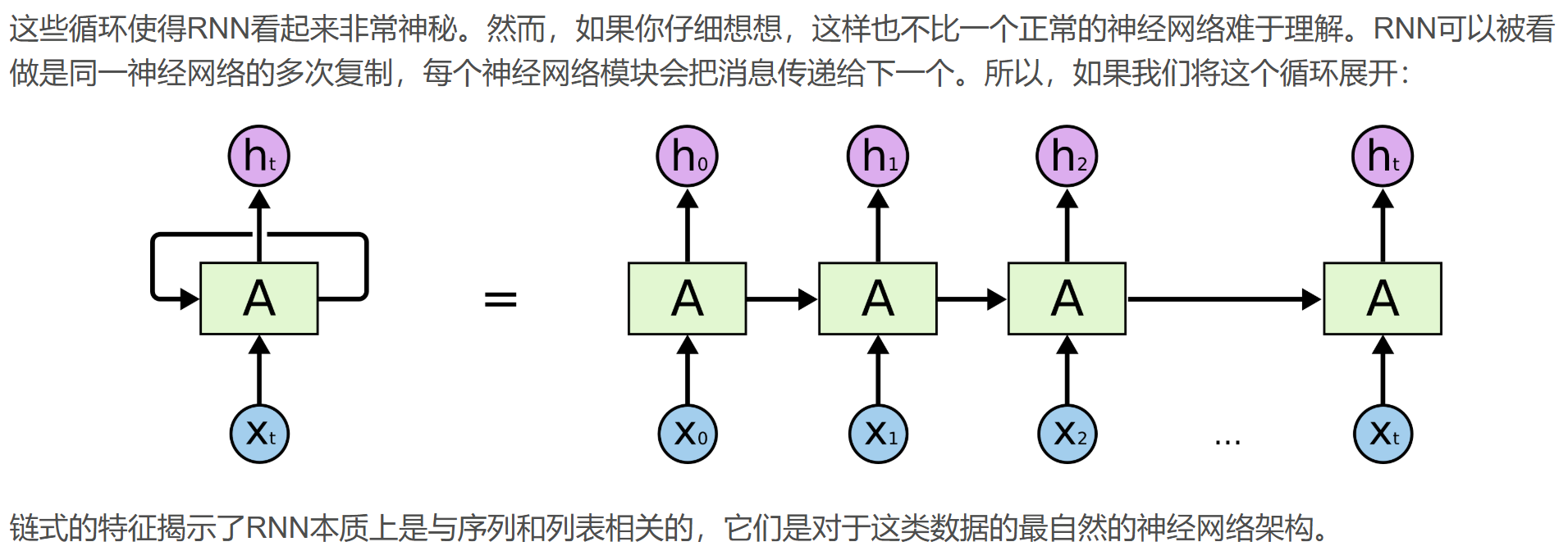
RNN的局限1:长期依赖(Long-TermDependencies)问题
但是同样会有一些更加复杂的场景。比如我们试着去预测“I grew up in France...I speak fluent French”最后的词“French”。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的“France”的上下文。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,RNN会丧失学习到连接如此远的信息的能力。
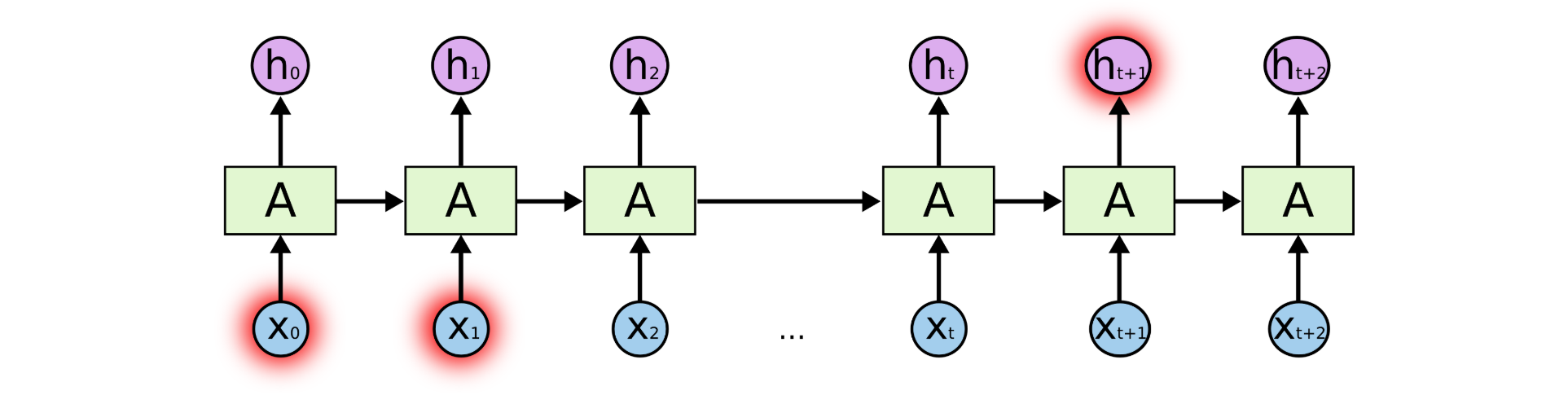
RNN的局限2:梯度消失和梯度爆炸问题
如果你正在尝试处理一段文本进行预测,RNN 可能从一开始就会遗漏重要信息。在反向传播期间(反向传播是一个很重要的核心议题,本质是通过不断缩小误差去更新权值,从而不断去修正拟合的函数),RNN 会面临梯度消失的问题。
因为梯度是用于更新神经网络的权重值(新的权值 = 旧权值 - 学习率*梯度),梯度会随着时间的推移不断下降减少,而当梯度值变得非常小时,就不会继续学习。

换言之,在递归神经网络中,获得小梯度更新的层会停止学习—— 那些通常是较早的层。 由于这些层不学习,RNN会忘记它在较长序列中以前看到的内容,因此RNN只具有短时记忆。
而梯度爆炸则是因为计算的难度越来越复杂导致。
然而,幸运的是,有个RNN的变体——LSTM,可以在一定程度上解决梯度消失和梯度爆炸这两个问题!

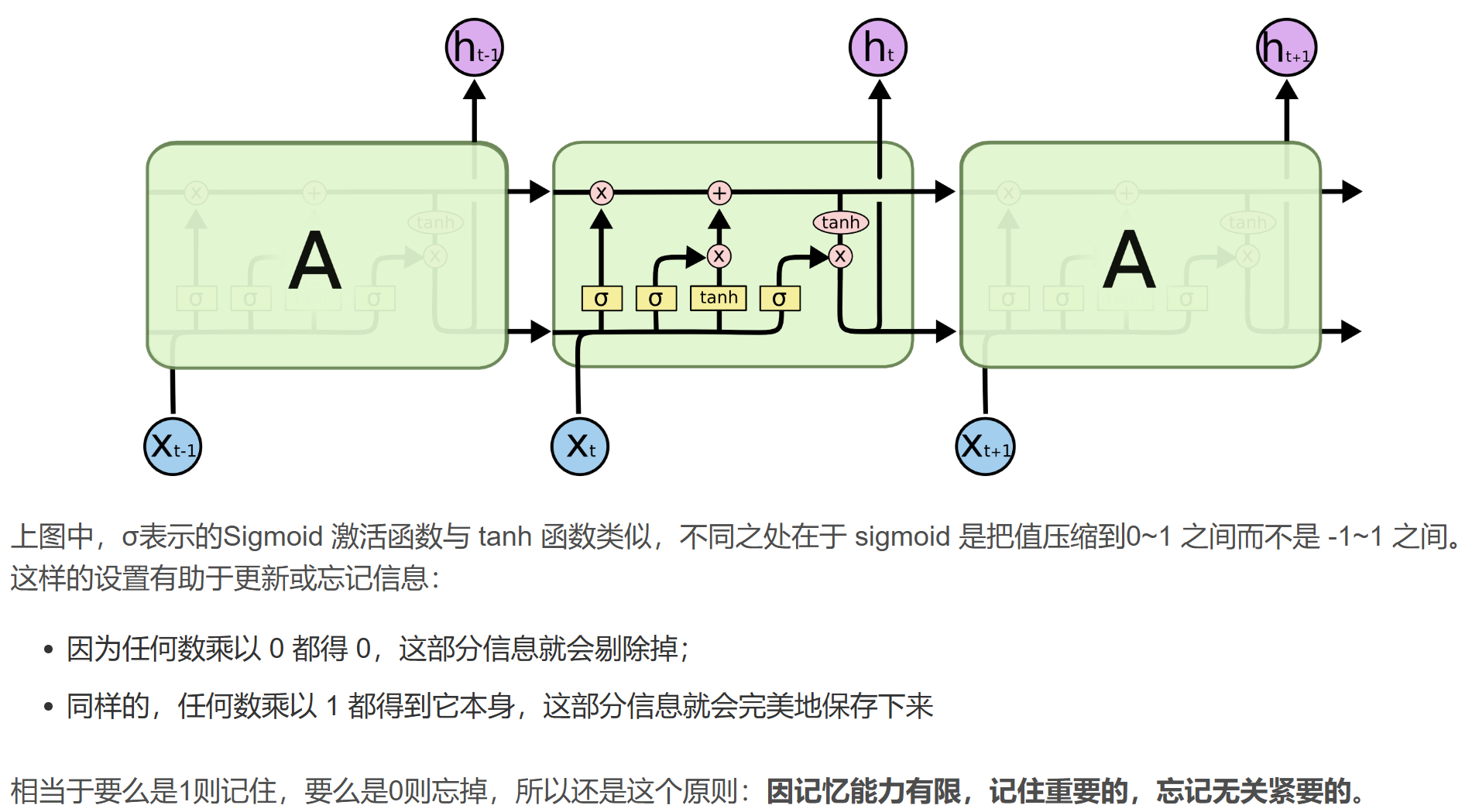
二、LSTM网络

三. GRU

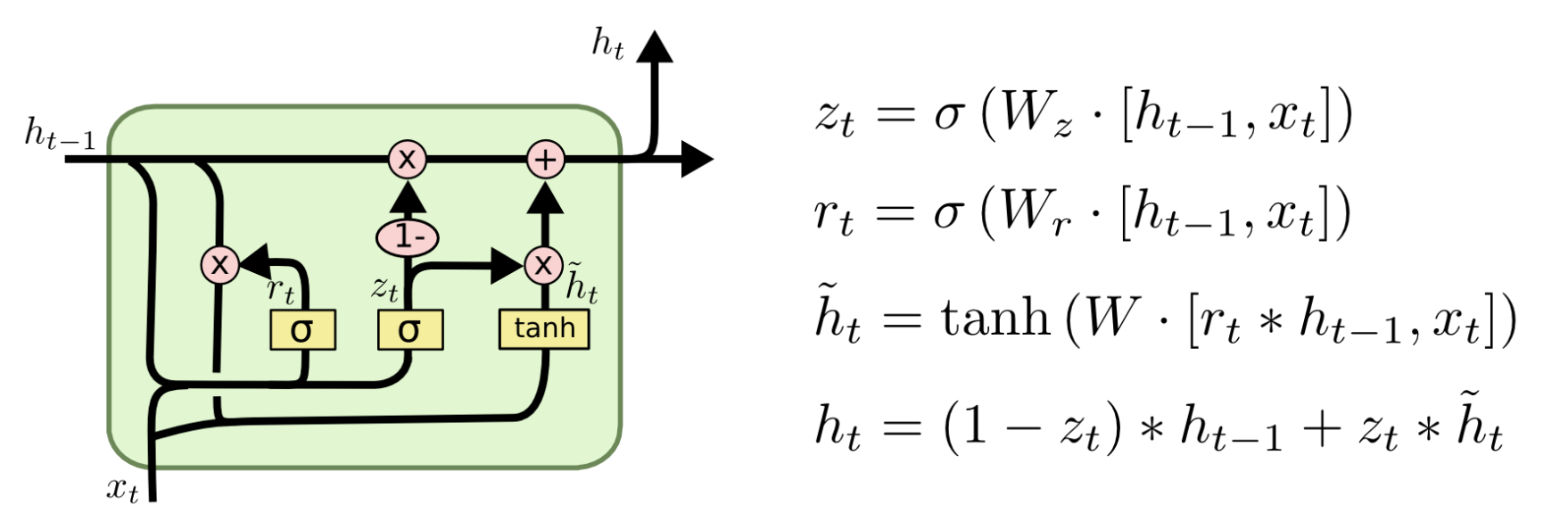
LSTM:功能更强,能更精细地控制记忆(但慢)。
GRU:简化版,更快、更省资源,在很多任务上效果相当,甚至更好。
在工业界,如果资源有限,GRU 往往更受欢迎;而学术研究/复杂任务里,LSTM 更常用。
Transformer和RNN(原始 or LSTM or GRU)的区别:
1.RNN采用一种类似于递归的方式运行,无法执行并行化操作,也就无法利用GPU强大的并行化能力,而Transfomer基于Attention机制,使得模型可以并行化操作,而且能够拥有全局的信息。
2.Transformer本身是不能利用单词之间的位置信息的,所以需要在输入中添加一个位置embedding信息,否则Transformer就类似于词袋模型了。
3.RNN利用循环顺序结构,对于长句需要的训练步骤很多,加大了训练的难度和时间。而Transfomer不需要循环,并行地处理单词,而且其多头注意力机制可以将很远的词联系起来,大大提高了训练速度和预测准确度。
网页读取电子秤数据——仙盟创梦IDE)






(错误日志实现))

)





与arm-linux-gcc、ARMGCC、ICCARM(IAR)、C51编译器的兼容性)


》)
