学习率调整方法详解
在深度学习训练过程中,学习率(Learning Rate, LR) 是影响模型收敛速度和效果的关键超参数。学习率过大可能导致训练不稳定、震荡甚至无法收敛;学习率过小又会导致收敛过慢甚至陷入局部最优。因此,如何合理调整学习率,是模型优化中的核心问题。常见方法可以分为三类:有序调整、自适应调整、自定义调整。
一、有序调整(Scheduled Adjustment)
有序调整指在训练过程中按照预先设定的规律逐步减少学习率,帮助模型更快收敛。
1. Step Decay(阶梯式衰减)
思路:训练到一定 epoch 后,将学习率按比例缩小。
公式:
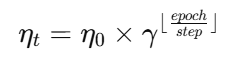
η0:初始学习率
γ:衰减因子(通常取 0.1 或 0.5)
step:间隔的 epoch 数
特点:学习率呈“阶梯”下降。适合在数据分布平稳、训练较长的任务中使用。
2. Exponential Decay(指数衰减)
思路:学习率随着 epoch 持续按指数缩小。
公式:
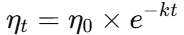
k 控制衰减速度
特点:下降平滑,但如果衰减过快,可能导致模型过早停止学习。
3. Cosine Annealing(余弦退火)
思路:学习率在训练中呈“余弦曲线”变化,逐步减小但在末尾仍保持一定值。
特点:常用于 SGDR(Stochastic Gradient Descent with Restart),有助于跳出局部最优。
二、自适应调整(Adaptive Adjustment)
自适应方法会根据梯度的历史信息,自动调整不同参数的学习率,减少人工设定难度。
1. Adagrad
思路:为每个参数维护一个累计梯度平方和,根据历史更新情况自动缩小学习率。
优点:适合稀疏特征问题,如 NLP。
缺点:学习率会单调减小,可能过早停止学习。
2. RMSprop
思路:在 Adagrad 基础上,引入 指数加权移动平均,避免学习率衰减过快。
特点:适合非凸优化问题,如 RNN 训练。
3. Adam
思路:结合 Momentum + RMSprop,既考虑一阶动量(梯度均值),又考虑二阶动量(梯度方差)。
优点:收敛快,常作为默认选择。
缺点:可能陷入鞍点或震荡,需要调整 β 参数。
4. AdamW(权重衰减版)
改进 Adam 的 L2 正则化问题,更适合深度网络和 Transformer 模型。
三、自定义调整(Custom Adjustment)
当任务复杂、对收敛要求特殊时,可以设计自定义学习率调整策略。
1. 手动函数定义
通过函数形式动态调整:
def lr_lambda(epoch):if epoch < 10:return 1.0elif epoch < 50:return 0.1else:return 0.01 scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
2. 基于性能的调整(Performance-based)
根据验证集的 loss 或 accuracy 动态调整:
ReduceLROnPlateau:当指标在若干 epoch 内不再提升,自动降低学习率。
特点:更智能,常用于实际任务。
3. 自定义回调(Callback)
在 Keras、PyTorch Lightning 等框架中,可自定义回调函数,在训练过程中动态控制学习率。
如:损失振荡时降低,损失稳定时保持。
把各种 学习率调整方法的调用方式 全部整理出来,分别给出 PyTorch 和 Keras(TensorFlow) 两种框架的示例。这样可以一目了然,直接套用。
学习率调整调用方式汇总
一、有序调整(Scheduled Adjustment)
1. Step Decay(阶梯衰减)
PyTorch
import torch import torch.optim as optimoptimizer = optim.SGD(model.parameters(), lr=0.1) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)for epoch in range(100):train(...)scheduler.step()Keras
from tensorflow.keras.optimizers import SGD from tensorflow.keras.callbacks import LearningRateSchedulerdef step_decay(epoch):initial_lr = 0.1drop = 0.1epochs_drop = 30return initial_lr * (drop ** (epoch // epochs_drop))optimizer = SGD(learning_rate=0.1) lr_scheduler = LearningRateScheduler(step_decay) model.fit(x_train, y_train, epochs=100, callbacks=[lr_scheduler])
2. Exponential Decay(指数衰减)
PyTorch
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)for epoch in range(100):train(...)scheduler.step()Keras
import tensorflow as tfinitial_lr = 0.1 lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_lr, decay_steps=100, decay_rate=0.96, staircase=True )optimizer = tf.keras.optimizers.SGD(learning_rate=lr_schedule) model.compile(optimizer=optimizer, loss="categorical_crossentropy")
3. Cosine Annealing(余弦退火)
PyTorch
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=50)for epoch in range(100):train(...)scheduler.step()Keras
import tensorflow as tflr_schedule = tf.keras.optimizers.schedules.CosineDecay(initial_learning_rate=0.1, decay_steps=1000 )optimizer = tf.keras.optimizers.SGD(learning_rate=lr_schedule) model.compile(optimizer=optimizer, loss="categorical_crossentropy")
二、自适应调整(Adaptive Adjustment)
这些是 优化器自带 的,不需要 scheduler。
PyTorch
import torch.optim as optim# Adagrad optimizer = optim.Adagrad(model.parameters(), lr=0.01)# RMSprop optimizer = optim.RMSprop(model.parameters(), lr=0.01)# Adam optimizer = optim.Adam(model.parameters(), lr=0.001)# AdamW optimizer = optim.AdamW(model.parameters(), lr=0.001)Keras
from tensorflow.keras.optimizers import Adagrad, RMSprop, Adamoptimizer = Adagrad(learning_rate=0.01) optimizer = RMSprop(learning_rate=0.01) optimizer = Adam(learning_rate=0.001)
三、自定义调整(Custom Adjustment)
1. LambdaLR / 自定义函数
PyTorch
def lr_lambda(epoch):if epoch < 10:return 1.0elif epoch < 50:return 0.1else:return 0.01scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)Keras
from tensorflow.keras.callbacks import LearningRateSchedulerdef custom_schedule(epoch, lr):if epoch < 10:return lrelif epoch < 50:return lr * 0.1else:return lr * 0.01lr_scheduler = LearningRateScheduler(custom_schedule) model.fit(x_train, y_train, epochs=100, callbacks=[lr_scheduler])
2. ReduceLROnPlateau(性能驱动)
PyTorch
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5 )for epoch in range(100):val_loss = validate(...)scheduler.step(val_loss)Keras
from tensorflow.keras.callbacks import ReduceLROnPlateaureduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=5, min_lr=1e-6 )model.fit(x_train, y_train, epochs=100, validation_data=(x_val, y_val), callbacks=[reduce_lr])
3. Warmup + 余弦退火(常用于大模型训练)
PyTorch (手动实现 Warmup + Cosine)
import mathdef warmup_cosine_lr(epoch, warmup_epochs=10, max_epochs=100, base_lr=0.1):if epoch < warmup_epochs:return epoch / warmup_epochselse:return 0.5 * (1 + math.cos(math.pi * (epoch - warmup_epochs) / (max_epochs - warmup_epochs)))scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=warmup_cosine_lr)Keras
import tensorflow as tfclass WarmUpCosine(tf.keras.optimizers.schedules.LearningRateSchedule):def __init__(self, initial_lr, warmup_steps, decay_steps):super().__init__()self.initial_lr = initial_lrself.warmup_steps = warmup_stepsself.decay_steps = decay_stepsdef __call__(self, step):warmup_lr = self.initial_lr * (step / self.warmup_steps)cosine_lr = tf.keras.optimizers.schedules.CosineDecay(self.initial_lr, self.decay_steps)(step)return tf.cond(step < self.warmup_steps, lambda: warmup_lr, lambda: cosine_lr)lr_schedule = WarmUpCosine(initial_lr=0.1, warmup_steps=1000, decay_steps=10000) optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
✅ 这样你就同时拿到了 PyTorch + Keras 下的所有调用方式,涵盖了:
有序调整(Step, Exponential, Cosine)
自适应调整(Adagrad, RMSprop, Adam, AdamW)
自定义调整(Lambda、自写函数、ReduceLROnPlateau、Warmup+Cosine)
四、方法比较
| 方法类型 | 优点 | 缺点 | 典型应用 |
|---|---|---|---|
| 有序调整 | 简单直观,易控制 | 需要预先设定 schedule | CV、NLP 基础训练 |
| 自适应调整 | 自动调节参数,无需复杂调参 | 对超参数敏感,可能震荡 | NLP、RNN、Transformer |
| 自定义调整 | 灵活,适应任务 | 实现复杂,需经验 | 工业级任务、研究实验 |
五、实践建议
初学/基线实验:推荐 Adam 或 AdamW,收敛快且稳定。
大规模训练:结合 Cosine Annealing + Warmup 效果更佳。
模型表现停滞:使用 ReduceLROnPlateau 动态降低学习率。
科研/特殊任务:可尝试自定义函数或回调。






的防护效果确实会受到陪测设备中去耦网络(Decoupling Network,DN)的显著影响)




![[论文阅读] 人工智能 + 软件工程 | TDD痛点破解:LLM自动生成测试骨架靠谱吗?静态分析+专家评审给出答案](http://pic.xiahunao.cn/[论文阅读] 人工智能 + 软件工程 | TDD痛点破解:LLM自动生成测试骨架靠谱吗?静态分析+专家评审给出答案)

)

)

原理简介)

