引言:
- 本文总字数:约 9800 字
- 预计阅读时间:40 分钟
为什么 Kafka 是高吞吐场景的首选?
在当今的分布式系统中,消息队列已成为不可或缺的基础设施。面对不同的业务场景,选择合适的消息队列至关重要。目前主流的消息中间件中,Kafka 以其独特的设计脱颖而出:
- 超高吞吐量:单机可轻松处理每秒数十万条消息
- 持久化存储:基于磁盘的高效存储机制,支持海量消息堆积
- 水平扩展:通过分区机制实现无缝扩展
- 流处理能力:内置流处理 API,支持复杂的数据转换和处理
根据 Apache Kafka 官方数据,Kafka 在全球财富 100 强公司中被广泛采用,包括 Netflix、Uber、LinkedIn 等,处理着每天 PB 级别的数据。其发布 - 订阅模式和日志存储特性,使其特别适合日志收集、事件溯源、实时分析等场景。
本文将带你全面掌握 SpringBoot 与 Kafka 的整合方案,从环境搭建到高级特性,从代码实现到性能调优,让你既能理解底层原理,又能解决实际开发中的各种问题。
一、Kafka 核心概念与架构
1.1 核心概念解析
Kafka 的核心概念包括:
- Producer:消息生产者,负责向 Kafka 发送消息
- Consumer:消息消费者,负责从 Kafka 读取消息
- Broker:Kafka 服务器节点,一个 Kafka 集群由多个 Broker 组成
- Topic:主题,消息的分类名称,生产者向主题发送消息,消费者从主题读取消息
- Partition:分区,每个主题可以分为多个分区,分区是 Kafka 并行处理的基本单位
- Replica:副本,为保证数据可靠性,每个分区可以有多个副本
- Leader:主副本,每个分区有一个主副本,负责处理读写请求
- Follower:从副本,同步主副本的数据,主副本故障时可升级为主副本
- Consumer Group:消费者组,多个消费者可以组成一个消费者组,共同消费一个主题的消息
- Offset:偏移量,每个分区中的消息都有一个唯一的偏移量,用于标识消息在分区中的位置
1.2 架构原理
Kafka 的整体架构如图所示:
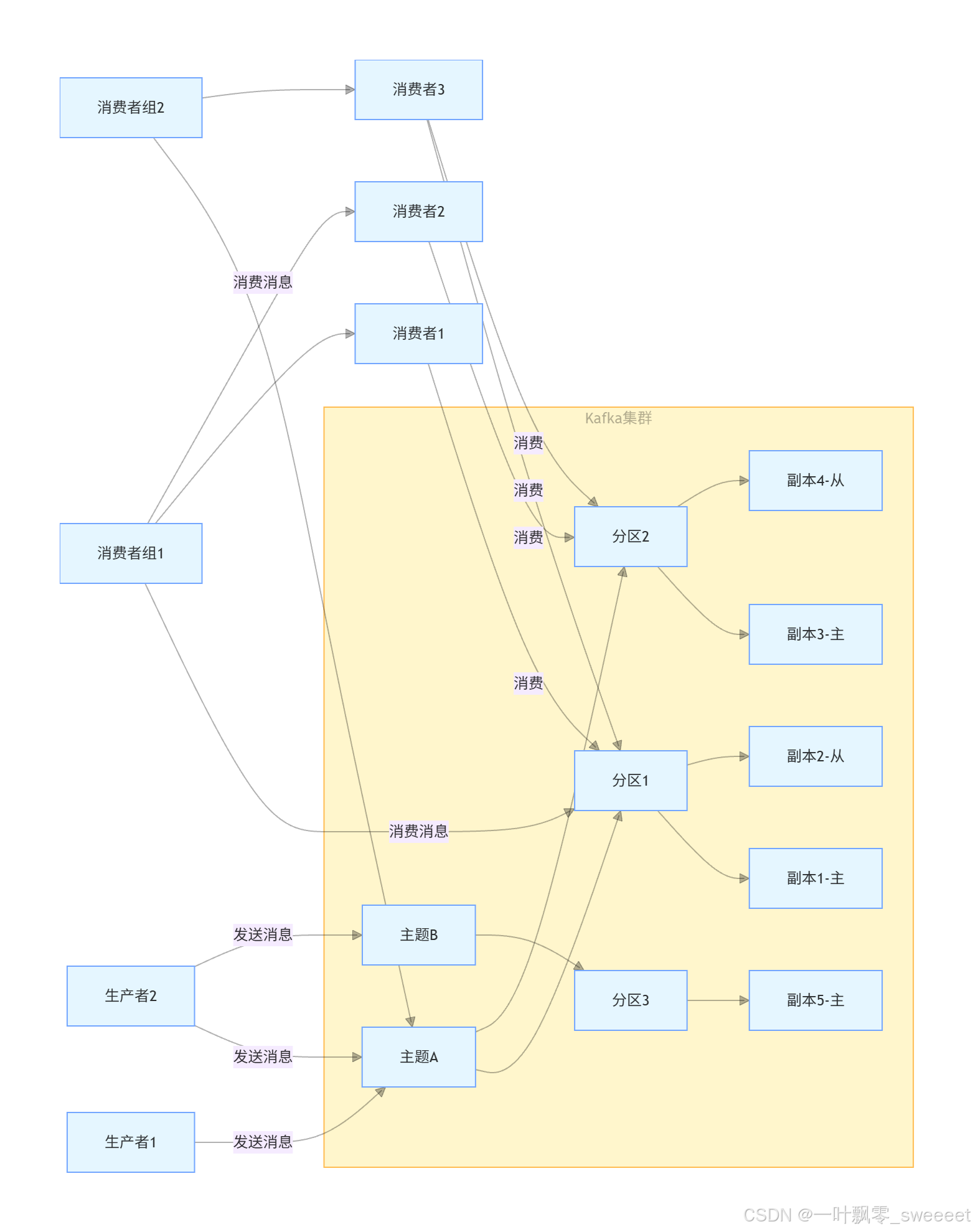
消息流转流程:
- 生产者将消息发送到指定主题
- 消息被分配到主题的一个分区中(可通过分区策略指定)
- 分区的主副本负责接收并存储消息,同时从副本同步数据
- 消费者组中的消费者从分区读取消息,每个分区只能被消费者组中的一个消费者消费
- 消费者通过偏移量记录自己的消费位置
根据 Kafka 官方文档(Apache Kafka),这种架构设计使得 Kafka 具有极高的吞吐量和可靠性,能够满足大规模数据处理的需求。
1.3 分区与消费者组机制
分区是 Kafka 实现高吞吐量的关键机制:
- 每个分区是一个有序的、不可变的消息序列
- 消息被追加到分区的末尾,类似日志文件
- 分区可以分布在不同的 Broker 上,实现负载均衡
消费者组机制则实现了消息的并行消费:
- 每个消费者组独立消费主题的所有消息
- 同一个消费者组中的消费者共享消费负载
- 每个分区只能被消费者组中的一个消费者消费
- 消费者数量不应超过分区数量,否则多余的消费者将处于空闲状态
分区与消费者组的关系如图所示:

二、环境搭建
2.1 安装 Kafka
我们采用最新稳定版 Kafka 3.6.1 进行安装,步骤如下:
- 安装 Java 环境(Kafka 依赖 Java):
# 对于Ubuntu/Debian
sudo apt-get update
sudo apt-get install openjdk-17-jdk# 对于CentOS/RHEL
sudo yum install java-17-openjdk
- 下载并解压 Kafka:
wget https://downloads.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgz
tar -xzf kafka_2.13-3.6.1.tgz
cd kafka_2.13-3.6.1
- 启动 ZooKeeper(Kafka 依赖 ZooKeeper 管理元数据):
# 后台启动ZooKeeper
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
- 启动 Kafka Broker:
# 后台启动Kafka
bin/kafka-server-start.sh -daemon config/server.properties
- 创建测试主题:
bin/kafka-topics.sh --create --topic test-topic --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1
- 查看主题列表:
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
2.2 安装 Docker 方式(推荐)
使用 Docker Compose 安装 Kafka 更加简单快捷:
创建 docker-compose.yml 文件:
version: '3'
services:zookeeper:image: confluentinc/cp-zookeeper:7.5.0environment:ZOOKEEPER_CLIENT_PORT: 2181ZOOKEEPER_TICK_TIME: 2000ports:- "2181:2181"kafka:image: confluentinc/cp-kafka:7.5.0depends_on:- zookeeperports:- "9092:9092"environment:KAFKA_BROKER_ID: 1KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXTKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
启动服务:
docker-compose up -d
三、SpringBoot 集成 Kafka 基础
3.1 创建项目并添加依赖
我们使用 SpringBoot 3.2.0(最新稳定版)来创建项目,首先在 pom.xml 中添加必要的依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.0</version><relativePath/></parent><groupId>com.jam</groupId><artifactId>springboot-kafka-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>springboot-kafka-demo</name><description>SpringBoot集成Kafka示例项目</description><properties><java.version>17</java.version><lombok.version>1.18.30</lombok.version><commons-lang3.version>3.14.0</commons-lang3.version><mybatis-plus.version>3.5.5</mybatis-plus.version><mysql-connector.version>8.2.0</mysql-connector.version><springdoc.version>2.1.0</springdoc.version><kafka.version>3.6.1</kafka.version></properties><dependencies><!-- SpringBoot核心依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Kafka依赖 --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>${kafka.version}</version></dependency><!-- Lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>${lombok.version}</version><scope>provided</scope></dependency><!-- 工具类 --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId><version>${commons-lang3.version}</version></dependency><!-- MyBatis-Plus --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>${mybatis-plus.version}</version></dependency><!-- MySQL驱动 --><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>${mysql-connector.version}</version><scope>runtime</scope></dependency><!-- Swagger3 --><dependency><groupId>org.springdoc</groupId><artifactId>springdoc-openapi-starter-webmvc-ui</artifactId><version>${springdoc.version}</version></dependency><!-- 测试依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><version>${kafka.version}</version><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build>
</project>
3.2 配置 Kafka
在 application.yml 中添加 Kafka 的配置:
spring:application:name: springboot-kafka-demodatasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/kafka_demo?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghaiusername: rootpassword: rootkafka:# Kafka集群地址bootstrap-servers: localhost:9092# 生产者配置producer:# 消息key的序列化器key-serializer: org.apache.kafka.common.serialization.StringSerializer# 消息value的序列化器value-serializer: org.springframework.kafka.support.serializer.JsonSerializer# 批次大小,当批次满了之后才会发送batch-size: 16384# 缓冲区大小buffer-memory: 33554432# 消息确认机制:0-不需要确认,1-只需要leader确认,all-所有副本都需要确认acks: all# 重试次数retries: 3# 重试间隔时间retry-backoff-ms: 1000# 消费者配置consumer:# 消息key的反序列化器key-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 消息value的反序列化器value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer# 消费者组IDgroup-id: default-group# 自动偏移量重置策略:earliest-从头开始消费,latest-从最新的开始消费,none-如果没有偏移量则抛出异常auto-offset-reset: earliest# 是否自动提交偏移量enable-auto-commit: false# 自动提交偏移量的间隔时间auto-commit-interval: 1000# 指定JsonDeserializer反序列化的目标类properties:spring:json:trusted:packages: com.jam.entity# 监听器配置listener:# 消息确认模式:manual-手动确认,auto-自动确认ack-mode: manual_immediate# 并发消费者数量concurrency: 3# 批量消费配置batch-listener: false# 每次拉取的记录数consumer:max-poll-records: 500# 重试配置retry:# 是否启用重试enabled: true# 初始重试间隔时间initial-interval: 1000# 最大重试间隔时间max-interval: 10000# 重试乘数multiplier: 2# 最大重试次数max-attempts: 3mybatis-plus:mapper-locations: classpath:mapper/*.xmltype-aliases-package: com.jam.entityconfiguration:map-underscore-to-camel-case: truelog-impl: org.apache.ibatis.logging.stdout.StdOutImplspringdoc:api-docs:path: /api-docsswagger-ui:path: /swagger-ui.htmloperationsSorter: methodserver:port: 8081
3.3 创建 Kafka 常量配置类
创建常量类,定义 Kafka 相关的常量:
package com.jam.config;/*** Kafka常量配置类* 定义Kafka主题名称、消费者组等常量** @author 果酱*/
public class KafkaConstant {/*** 普通消息主题*/public static final String NORMAL_TOPIC = "normal_topic";/*** 分区消息主题*/public static final String PARTITION_TOPIC = "partition_topic";/*** 事务消息主题*/public static final String TRANSACTIONAL_TOPIC = "transactional_topic";/*** 死信主题*/public static final String DEAD_LETTER_TOPIC = "dead_letter_topic";/*** 普通消费者组*/public static final String NORMAL_CONSUMER_GROUP = "normal_consumer_group";/*** 分区消费者组*/public static final String PARTITION_CONSUMER_GROUP = "partition_consumer_group";/*** 事务消费者组*/public static final String TRANSACTIONAL_CONSUMER_GROUP = "transactional_consumer_group";/*** 死信消费者组*/public static final String DEAD_LETTER_CONSUMER_GROUP = "dead_letter_consumer_group";/*** 事务ID前缀*/public static final String TRANSACTION_ID_PREFIX = "tx-";
}
3.4 创建消息实体类
创建一个通用的消息实体类,用于封装发送的消息内容:
package com.jam.entity;import lombok.Data;
import java.io.Serializable;
import java.time.LocalDateTime;/*** 消息实体类* 用于封装发送到Kafka的消息内容** @author 果酱*/
@Data
public class MessageEntity implements Serializable {/*** 消息ID*/private String messageId;/*** 消息内容*/private String content;/*** 业务类型*/private String businessType;/*** 业务ID,用于分区策略*/private String businessId;/*** 创建时间*/private LocalDateTime createTime;/*** 扩展字段,用于存储额外信息*/private String extra;
}
3.5 创建 Kafka 配置类
创建配置类,配置 Kafka 生产者、消费者、分区策略等:
package com.jam.config;import com.jam.entity.MessageEntity;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.transaction.KafkaTransactionManager;
import java.util.HashMap;
import java.util.Map;
import static org.apache.kafka.clients.consumer.ConsumerConfig.*;
import static org.apache.kafka.clients.producer.ProducerConfig.*;/*** Kafka配置类* 配置Kafka主题、生产者、消费者等** @author 果酱*/
@Configuration
public class KafkaConfig {/*** 创建普通消息主题* 3个分区,1个副本** @return 普通消息主题*/@Beanpublic NewTopic normalTopic() {// 参数:主题名称、分区数、副本数return new NewTopic(KafkaConstant.NORMAL_TOPIC, 3, (short) 1);}/*** 创建分区消息主题* 5个分区,1个副本** @return 分区消息主题*/@Beanpublic NewTopic partitionTopic() {return new NewTopic(KafkaConstant.PARTITION_TOPIC, 5, (short) 1);}/*** 创建事务消息主题* 3个分区,1个副本** @return 事务消息主题*/@Beanpublic NewTopic transactionalTopic() {return new NewTopic(KafkaConstant.TRANSACTIONAL_TOPIC, 3, (short) 1);}/*** 创建死信主题* 1个分区,1个副本** @return 死信主题*/@Beanpublic NewTopic deadLetterTopic() {return new NewTopic(KafkaConstant.DEAD_LETTER_TOPIC, 1, (short) 1);}/*** 配置事务生产者工厂** @return 事务生产者工厂*/@Beanpublic ProducerFactory<String, MessageEntity> transactionalProducerFactory() {Map<String, Object> configProps = new HashMap<>();configProps.put(BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configProps.put(KEY_SERIALIZER_CLASS_CONFIG, org.apache.kafka.common.serialization.StringSerializer.class);configProps.put(VALUE_SERIALIZER_CLASS_CONFIG, org.springframework.kafka.support.serializer.JsonSerializer.class);configProps.put(ACKS_CONFIG, "all");configProps.put(RETRIES_CONFIG, 3);configProps.put(BATCH_SIZE_CONFIG, 16384);configProps.put(BUFFER_MEMORY_CONFIG, 33554432);// 配置事务ID前缀configProps.put(TRANSACTIONAL_ID_CONFIG, KafkaConstant.TRANSACTION_ID_PREFIX);DefaultKafkaProducerFactory<String, MessageEntity> factory = new DefaultKafkaProducerFactory<>(configProps);// 开启事务支持factory.transactionCapable();return factory;}/*** 配置事务Kafka模板** @return 事务Kafka模板*/@Beanpublic KafkaTemplate<String, MessageEntity> transactionalKafkaTemplate() {return new KafkaTemplate<>(transactionalProducerFactory());}/*** 配置Kafka事务管理器** @return Kafka事务管理器*/@Beanpublic KafkaTransactionManager<String, MessageEntity> kafkaTransactionManager() {return new KafkaTransactionManager<>(transactionalProducerFactory());}
}
3.6 创建分区策略类
创建自定义的分区策略,根据业务 ID 将消息发送到指定分区:
package com.jam.config;import com.jam.entity.MessageEntity;
import org.apache.commons.lang3.StringUtils;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.InvalidRecordException;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
import java.util.List;
import java.util.Map;/*** 自定义Kafka分区策略* 根据业务ID将消息发送到指定分区,确保相同业务ID的消息在同一分区** @author 果酱*/
public class BusinessIdPartitioner implements Partitioner {/*** 计算分区号** @param topic 主题名称* @param key 消息键* @param keyBytes 消息键的字节数组* @param value 消息值* @param valueBytes 消息值的字节数组* @param cluster Kafka集群信息* @return 分区号*/@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 获取主题的所有分区List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();// 如果消息值不是MessageEntity类型,抛出异常if (!(value instanceof MessageEntity)) {throw new InvalidRecordException("消息必须是MessageEntity类型");}MessageEntity message = (MessageEntity) value;String businessId = message.getBusinessId();// 如果业务ID为空,使用默认分区策略if (StringUtils.isBlank(businessId)) {if (keyBytes == null) {// 使用随机分区return Utils.toPositive(Utils.murmur2(valueBytes)) % numPartitions;} else {// 使用key计算分区return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}}// 根据业务ID计算分区,确保相同业务ID的消息在同一分区return Math.abs(businessId.hashCode()) % numPartitions;}/*** 关闭分区器*/@Overridepublic void close() {// 关闭资源(如果有的话)}/*** 配置分区器** @param configs 配置参数*/@Overridepublic void configure(Map<String, ?> configs) {// 读取配置参数(如果有的话)}
}
3.7 创建消息生产者服务
创建消息生产者服务,封装发送消息的各种方法:
package com.jam.service;import com.jam.config.KafkaConstant;
import com.jam.entity.MessageEntity;
import com.jam.entity.MessageTrace;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import java.time.LocalDateTime;
import java.util.Objects;
import java.util.UUID;/*** Kafka消息生产者服务* 负责向Kafka发送各种类型的消息** @author 果酱*/
@Slf4j
@Service
@RequiredArgsConstructor
public class KafkaProducerService {/*** Kafka模板类,提供发送消息的各种方法*/private final KafkaTemplate<String, MessageEntity> kafkaTemplate;/*** 事务Kafka模板类,用于发送事务消息*/private final KafkaTemplate<String, MessageEntity> transactionalKafkaTemplate;/*** 消息轨迹服务*/private final MessageTraceService messageTraceService;/*** 发送普通消息** @param topic 主题名称* @param message 消息实体*/public void sendMessage(String topic, MessageEntity message) {// 参数校验StringUtils.hasText(topic, "主题名称不能为空");Objects.requireNonNull(message, "消息实体不能为空");// 确保消息ID和创建时间不为空if (StringUtils.isBlank(message.getMessageId())) {message.setMessageId(UUID.randomUUID().toString());}if (message.getCreateTime() == null) {message.setCreateTime(LocalDateTime.now());}// 记录消息发送前的轨迹messageTraceService.recordBeforeSend(message, topic);log.info("发送Kafka消息,主题:{},消息ID:{},业务类型:{}",topic, message.getMessageId(), message.getBusinessType());// 发送消息ListenableFuture<SendResult<String, MessageEntity>> future = kafkaTemplate.send(topic, message.getMessageId(), message);// 处理发送结果future.addCallback(new ListenableFutureCallback<>() {@Overridepublic void onSuccess(SendResult<String, MessageEntity> result) {log.info("Kafka消息发送成功,主题:{},消息ID:{},分区:{},偏移量:{}",topic, message.getMessageId(),result.getRecordMetadata().partition(),result.getRecordMetadata().offset());// 记录消息发送成功的轨迹messageTraceService.recordSendSuccess(message.getMessageId(),result.getRecordMetadata().partition(),result.getRecordMetadata().offset());}@Overridepublic void onFailure(Throwable ex) {log.error("Kafka消息发送失败,主题:{},消息ID:{}",topic, message.getMessageId(), ex);// 记录消息发送失败的轨迹messageTraceService.recordSendFailure(message.getMessageId(), ex.getMessage());}});}/*** 发送分区消息** @param message 消息实体*/public void sendPartitionMessage(MessageEntity message) {// 参数校验Objects.requireNonNull(message, "消息实体不能为空");StringUtils.hasText(message.getBusinessId(), "业务ID不能为空");// 确保消息ID和创建时间不为空if (StringUtils.isBlank(message.getMessageId())) {message.setMessageId(UUID.randomUUID().toString());}if (message.getCreateTime() == null) {message.setCreateTime(LocalDateTime.now());}String topic = KafkaConstant.PARTITION_TOPIC;// 记录消息发送前的轨迹messageTraceService.recordBeforeSend(message, topic);log.info("发送Kafka分区消息,主题:{},消息ID:{},业务ID:{},业务类型:{}",topic, message.getMessageId(), message.getBusinessId(), message.getBusinessType());// 发送消息,使用业务ID作为key,配合自定义分区策略ListenableFuture<SendResult<String, MessageEntity>> future = kafkaTemplate.send(topic, message.getBusinessId(), message);// 处理发送结果future.addCallback(new ListenableFutureCallback<>() {@Overridepublic void onSuccess(SendResult<String, MessageEntity> result) {log.info("Kafka分区消息发送成功,主题:{},消息ID:{},业务ID:{},分区:{},偏移量:{}",topic, message.getMessageId(), message.getBusinessId(),result.getRecordMetadata().partition(),result.getRecordMetadata().offset());// 记录消息发送成功的轨迹messageTraceService.recordSendSuccess(message.getMessageId(),result.getRecordMetadata().partition(),result.getRecordMetadata().offset());}@Overridepublic void onFailure(Throwable ex) {log.error("Kafka分区消息发送失败,主题:{},消息ID:{},业务ID:{}",topic, message.getMessageId(), message.getBusinessId(), ex);// 记录消息发送失败的轨迹messageTraceService.recordSendFailure(message.getMessageId(), ex.getMessage());}});}/*** 发送事务消息** @param message 消息实体*/@Transactional(rollbackFor = Exception.class)public void sendTransactionalMessage(MessageEntity message) {// 参数校验Objects.requireNonNull(message, "消息实体不能为空");// 确保消息ID和创建时间不为空if (StringUtils.isBlank(message.getMessageId())) {message.setMessageId(UUID.randomUUID().toString());}if (message.getCreateTime() == null) {message.setCreateTime(LocalDateTime.now());}String topic = KafkaConstant.TRANSACTIONAL_TOPIC;// 记录消息发送前的轨迹messageTraceService.recordBeforeSend(message, topic);log.info("发送Kafka事务消息,主题:{},消息ID:{},业务类型:{}",topic, message.getMessageId(), message.getBusinessType());// 开始事务transactionalKafkaTemplate.executeInTransaction(kafkaOperations -> {// 发送消息SendResult<String, MessageEntity> result = kafkaOperations.send(topic, message.getMessageId(), message).get();log.info("Kafka事务消息发送成功,主题:{},消息ID:{},分区:{},偏移量:{}",topic, message.getMessageId(),result.getRecordMetadata().partition(),result.getRecordMetadata().offset());// 记录消息发送成功的轨迹messageTraceService.recordSendSuccess(message.getMessageId(),result.getRecordMetadata().partition(),result.getRecordMetadata().offset());// 这里可以添加数据库操作等其他事务操作return result;});}/*** 创建消息实体** @param content 消息内容* @param businessType 业务类型* @param businessId 业务ID* @param extra 额外信息* @return 消息实体*/public MessageEntity createMessageEntity(String content, String businessType, String businessId, String extra) {MessageEntity message = new MessageEntity();message.setMessageId(UUID.randomUUID().toString());message.setContent(content);message.setBusinessType(businessType);message.setBusinessId(businessId);message.setCreateTime(LocalDateTime.now());message.setExtra(extra);return message;}
}
3.8 创建消息消费者服务
创建消息消费者服务,使用 @KafkaListener 注解消费消息:
package com.jam.service;import com.jam.config.KafkaConstant;
import com.jam.entity.MessageEntity;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.Objects;/*** Kafka消息消费者服务* 负责从Kafka接收并处理消息** @author 果酱*/
@Slf4j
@Service
@RequiredArgsConstructor
public class KafkaConsumerService {/*** 消息轨迹服务*/private final MessageTraceService messageTraceService;/*** 消费普通消息** @param record 消息记录* @param acknowledgment 确认对象* @param topic 主题名称* @param partition 分区号* @param offset 偏移量*/@KafkaListener(topics = KafkaConstant.NORMAL_TOPIC, groupId = KafkaConstant.NORMAL_CONSUMER_GROUP)public void consumeNormalMessage(ConsumerRecord<String, MessageEntity> record,Acknowledgment acknowledgment,@Header("kafka_receivedTopic") String topic,@Header("kafka_receivedPartitionId") int partition,@Header("kafka_offset") long offset) {MessageEntity message = record.value();Objects.requireNonNull(message, "消息内容不能为空");log.info("接收到普通消息,主题:{},分区:{},偏移量:{},消息ID:{},业务类型:{}",topic, partition, offset, message.getMessageId(), message.getBusinessType());try {// 处理消息的业务逻辑processMessage(message);// 记录消费成功轨迹messageTraceService.recordConsumeSuccess(message.getMessageId(), partition, offset);// 手动确认消息acknowledgment.acknowledge();log.info("普通消息处理成功并确认,主题:{},消息ID:{}", topic, message.getMessageId());} catch (Exception e) {// 记录消费失败轨迹messageTraceService.recordConsumeFailure(message.getMessageId(), partition, offset, e.getMessage());log.error("普通消息处理失败,主题:{},消息ID:{}", topic, message.getMessageId(), e);// 手动确认消息(将失败消息标记为已消费,避免无限重试)// 如果需要将消息发送到死信队列,可以不确认并配置死信转发acknowledgment.acknowledge();}}/*** 消费分区消息** @param record 消息记录* @param acknowledgment 确认对象* @param topic 主题名称* @param partition 分区号* @param offset 偏移量*/@KafkaListener(topics = KafkaConstant.PARTITION_TOPIC, groupId = KafkaConstant.PARTITION_CONSUMER_GROUP)public void consumePartitionMessage(ConsumerRecord<String, MessageEntity> record,Acknowledgment acknowledgment,@Header("kafka_receivedTopic") String topic,@Header("kafka_receivedPartitionId") int partition,@Header("kafka_offset") long offset) {MessageEntity message = record.value();Objects.requireNonNull(message, "消息内容不能为空");log.info("接收到分区消息,主题:{},分区:{},偏移量:{},消息ID:{},业务ID:{},业务类型:{}",topic, partition, offset, message.getMessageId(), message.getBusinessId(), message.getBusinessType());try {// 处理消息的业务逻辑processMessage(message);// 记录消费成功轨迹messageTraceService.recordConsumeSuccess(message.getMessageId(), partition, offset);// 手动确认消息acknowledgment.acknowledge();log.info("分区消息处理成功并确认,主题:{},消息ID:{}", topic, message.getMessageId());} catch (Exception e) {// 记录消费失败轨迹messageTraceService.recordConsumeFailure(message.getMessageId(), partition, offset, e.getMessage());log.error("分区消息处理失败,主题:{},消息ID:{}", topic, message.getMessageId(), e);acknowledgment.acknowledge();}}/*** 消费事务消息** @param record 消息记录* @param acknowledgment 确认对象* @param topic 主题名称* @param partition 分区号* @param offset 偏移量*/@Transactional(rollbackFor = Exception.class)@KafkaListener(topics = KafkaConstant.TRANSACTIONAL_TOPIC, groupId = KafkaConstant.TRANSACTIONAL_CONSUMER_GROUP)public void consumeTransactionalMessage(ConsumerRecord<String, MessageEntity> record,Acknowledgment acknowledgment,@Header("kafka_receivedTopic") String topic,@Header("kafka_receivedPartitionId") int partition,@Header("kafka_offset") long offset) {MessageEntity message = record.value();Objects.requireNonNull(message, "消息内容不能为空");log.info("接收到事务消息,主题:{},分区:{},偏移量:{},消息ID:{},业务类型:{}",topic, partition, offset, message.getMessageId(), message.getBusinessType());try {// 处理消息的业务逻辑processMessage(message);// 这里可以添加数据库操作等其他事务操作// 记录消费成功轨迹messageTraceService.recordConsumeSuccess(message.getMessageId(), partition, offset);// 手动确认消息acknowledgment.acknowledge();log.info("事务消息处理成功并确认,主题:{},消息ID:{}", topic, message.getMessageId());} catch (Exception e) {// 记录消费失败轨迹messageTraceService.recordConsumeFailure(message.getMessageId(), partition, offset, e.getMessage());log.error("事务消息处理失败,主题:{},消息ID:{}", topic, message.getMessageId(), e);// 事务会回滚,消息不会被确认,将被重新消费}}/*** 消费死信消息** @param record 消息记录* @param acknowledgment 确认对象* @param topic 主题名称* @param partition 分区号* @param offset 偏移量*/@KafkaListener(topics = KafkaConstant.DEAD_LETTER_TOPIC, groupId = KafkaConstant.DEAD_LETTER_CONSUMER_GROUP)public void consumeDeadLetterMessage(ConsumerRecord<String, MessageEntity> record,Acknowledgment acknowledgment,@Header("kafka_receivedTopic") String topic,@Header("kafka_receivedPartitionId") int partition,@Header("kafka_offset") long offset) {MessageEntity message = record.value();Objects.requireNonNull(message, "消息内容不能为空");log.error("接收到死信消息,主题:{},分区:{},偏移量:{},消息ID:{},业务类型:{}",topic, partition, offset, message.getMessageId(), message.getBusinessType());try {// 处理死信消息的业务逻辑,通常需要人工干预processDeadLetterMessage(message);// 记录消费成功轨迹messageTraceService.recordConsumeSuccess(message.getMessageId(), partition, offset);// 手动确认消息acknowledgment.acknowledge();log.info("死信消息处理成功并确认,主题:{},消息ID:{}", topic, message.getMessageId());} catch (Exception e) {// 记录消费失败轨迹messageTraceService.recordConsumeFailure(message.getMessageId(), partition, offset, e.getMessage());log.error("死信消息处理失败,主题:{},消息ID:{}", topic, message.getMessageId(), e);acknowledgment.acknowledge();}}/*** 处理消息的业务逻辑** @param message 要处理的消息*/private void processMessage(MessageEntity message) {// 根据业务类型处理不同的消息String businessType = message.getBusinessType();if ("ORDER_CREATE".equals(businessType)) {// 处理订单创建消息processOrderCreateMessage(message);} else if ("USER_REGISTER".equals(businessType)) {// 处理用户注册消息processUserRegisterMessage(message);} else {// 处理未知类型消息log.warn("收到未知类型的消息,消息ID:{},业务类型:{}",message.getMessageId(), businessType);}}/*** 处理死信消息** @param message 死信消息*/private void processDeadLetterMessage(MessageEntity message) {log.info("处理死信消息,消息ID:{},内容:{}",message.getMessageId(), message.getContent());// 实际业务处理逻辑,如记录到数据库等待人工处理}/*** 处理订单创建消息** @param message 订单创建消息*/private void processOrderCreateMessage(MessageEntity message) {log.info("处理订单创建消息,消息ID:{},订单信息:{}",message.getMessageId(), message.getContent());// 实际业务处理逻辑...}/*** 处理用户注册消息** @param message 用户注册消息*/private void processUserRegisterMessage(MessageEntity message) {log.info("处理用户注册消息,消息ID:{},用户信息:{}",message.getMessageId(), message.getContent());// 实际业务处理逻辑...}
}
3.9 创建消息轨迹服务
为了跟踪消息的整个生命周期,创建消息轨迹服务:
package com.jam.service;import com.jam.entity.MessageEntity;
import com.jam.entity.MessageTrace;
import com.jam.mapper.MessageTraceMapper;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.time.LocalDateTime;
import java.util.Objects;/*** 消息轨迹服务* 记录消息的发送和消费轨迹** @author 果酱*/
@Slf4j
@Service
@RequiredArgsConstructor
public class MessageTraceService {private final MessageTraceMapper messageTraceMapper;/*** 记录消息发送前的轨迹** @param message 消息实体* @param topic 主题* @return 消息轨迹ID*/@Transactional(rollbackFor = Exception.class)public Long recordBeforeSend(MessageEntity message, String topic) {Objects.requireNonNull(message, "消息实体不能为空");StringUtils.hasText(message.getMessageId(), "消息ID不能为空");StringUtils.hasText(topic, "主题不能为空");MessageTrace trace = new MessageTrace();trace.setMessageId(message.getMessageId());trace.setTopic(topic);trace.setBusinessType(message.getBusinessType());trace.setBusinessId(message.getBusinessId());trace.setContent(message.getContent());trace.setSendStatus(0); // 待发送trace.setCreateTime(LocalDateTime.now());trace.setUpdateTime(LocalDateTime.now());messageTraceMapper.insert(trace);log.info("记录消息发送前轨迹,消息ID:{},轨迹ID:{}", message.getMessageId(), trace.getId());return trace.getId();}/*** 记录消息发送成功的轨迹** @param messageId 消息ID* @param partition 分区* @param offset 偏移量*/@Transactional(rollbackFor = Exception.class)public void recordSendSuccess(String messageId, int partition, long offset) {StringUtils.hasText(messageId, "消息ID不能为空");MessageTrace trace = messageTraceMapper.selectByMessageId(messageId);if (trace == null) {log.warn("未找到消息轨迹,消息ID:{}", messageId);return;}trace.setSendTime(LocalDateTime.now());trace.setSendStatus(1); // 发送成功trace.setPartition(partition);trace.setOffset(offset);trace.setUpdateTime(LocalDateTime.now());messageTraceMapper.updateById(trace);log.info("记录消息发送成功轨迹,消息ID:{}", messageId);}/*** 记录消息发送失败的轨迹** @param messageId 消息ID* @param errorMsg 错误信息*/@Transactional(rollbackFor = Exception.class)public void recordSendFailure(String messageId, String errorMsg) {StringUtils.hasText(messageId, "消息ID不能为空");StringUtils.hasText(errorMsg, "错误信息不能为空");MessageTrace trace = messageTraceMapper.selectByMessageId(messageId);if (trace == null) {log.warn("未找到消息轨迹,消息ID:{}", messageId);return;}trace.setSendTime(LocalDateTime.now());trace.setSendStatus(2); // 发送失败trace.setSendErrorMsg(errorMsg);trace.setUpdateTime(LocalDateTime.now());messageTraceMapper.updateById(trace);log.info("记录消息发送失败轨迹,消息ID:{}", messageId);}/*** 记录消息消费成功的轨迹** @param messageId 消息ID* @param partition 分区* @param offset 偏移量*/@Transactional(rollbackFor = Exception.class)public void recordConsumeSuccess(String messageId, int partition, long offset) {StringUtils.hasText(messageId, "消息ID不能为空");MessageTrace trace = messageTraceMapper.selectByMessageId(messageId);if (trace == null) {log.warn("未找到消息轨迹,消息ID:{}", messageId);return;}trace.setConsumeTime(LocalDateTime.now());trace.setConsumeStatus(1); // 消费成功trace.setConsumePartition(partition);trace.setConsumeOffset(offset);trace.setUpdateTime(LocalDateTime.now());messageTraceMapper.updateById(trace);log.info("记录消息消费成功轨迹,消息ID:{}", messageId);}/*** 记录消息消费失败的轨迹** @param messageId 消息ID* @param partition 分区* @param offset 偏移量* @param errorMsg 错误信息*/@Transactional(rollbackFor = Exception.class)public void recordConsumeFailure(String messageId, int partition, long offset, String errorMsg) {StringUtils.hasText(messageId, "消息ID不能为空");StringUtils.hasText(errorMsg, "错误信息不能为空");MessageTrace trace = messageTraceMapper.selectByMessageId(messageId);if (trace == null) {log.warn("未找到消息轨迹,消息ID:{}", messageId);return;}trace.setConsumeTime(LocalDateTime.now());trace.setConsumeStatus(2); // 消费失败trace.setConsumePartition(partition);trace.setConsumeOffset(offset);trace.setConsumeErrorMsg(errorMsg);trace.setUpdateTime(LocalDateTime.now());messageTraceMapper.updateById(trace);log.info("记录消息消费失败轨迹,消息ID:{}", messageId);}
}
3.10 创建控制器
创建一个控制器,用于测试消息发送功能:
package com.jam.controller;import com.jam.config.KafkaConstant;
import com.jam.entity.MessageEntity;
import com.jam.service.KafkaProducerService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;/*** Kafka消息测试控制器* 提供API接口用于测试Kafka消息发送功能** @author 果酱*/
@Slf4j
@RestController
@RequestMapping("/api/kafka")
@RequiredArgsConstructor
@Tag(name = "Kafka消息测试接口", description = "用于测试Kafka消息发送的API接口")
public class KafkaMessageController {/*** Kafka消息生产者服务*/private final KafkaProducerService kafkaProducerService;/*** 发送普通消息** @param content 消息内容* @param businessType 业务类型* @param businessId 业务ID* @param extra 额外信息* @return 响应信息*/@PostMapping("/normal")@Operation(summary = "发送普通消息", description = "发送到普通主题的消息")public ResponseEntity<String> sendNormalMessage(@Parameter(description = "消息内容", required = true)@RequestParam String content,@Parameter(description = "业务类型")@RequestParam(required = false) String businessType,@Parameter(description = "业务ID")@RequestParam(required = false) String businessId,@Parameter(description = "额外信息")@RequestParam(required = false) String extra) {log.info("接收到发送普通消息请求");MessageEntity message = kafkaProducerService.createMessageEntity(content, businessType, businessId, extra);kafkaProducerService.sendMessage(KafkaConstant.NORMAL_TOPIC, message);return ResponseEntity.ok("普通消息发送成功,消息ID:" + message.getMessageId());}/*** 发送分区消息** @param content 消息内容* @param businessType 业务类型* @param businessId 业务ID(用于分区)* @param extra 额外信息* @return 响应信息*/@PostMapping("/partition")@Operation(summary = "发送分区消息", description = "发送到分区主题的消息,相同业务ID的消息会被发送到同一分区")public ResponseEntity<String> sendPartitionMessage(@Parameter(description = "消息内容", required = true)@RequestParam String content,@Parameter(description = "业务类型")@RequestParam(required = false) String businessType,@Parameter(description = "业务ID(用于分区)", required = true)@RequestParam String businessId,@Parameter(description = "额外信息")@RequestParam(required = false) String extra) {log.info("接收到发送分区消息请求,业务ID:{}", businessId);MessageEntity message = kafkaProducerService.createMessageEntity(content, businessType, businessId, extra);kafkaProducerService.sendPartitionMessage(message);return ResponseEntity.ok("分区消息发送成功,消息ID:" + message.getMessageId());}/*** 发送事务消息** @param content 消息内容* @param businessType 业务类型* @param businessId 业务ID* @param extra 额外信息* @return 响应信息*/@PostMapping("/transactional")@Operation(summary = "发送事务消息", description = "发送到事务主题的消息,支持事务特性")public ResponseEntity<String> sendTransactionalMessage(@Parameter(description = "消息内容", required = true)@RequestParam String content,@Parameter(description = "业务类型")@RequestParam(required = false) String businessType,@Parameter(description = "业务ID")@RequestParam(required = false) String businessId,@Parameter(description = "额外信息")@RequestParam(required = false) String extra) {log.info("接收到发送事务消息请求");MessageEntity message = kafkaProducerService.createMessageEntity(content, businessType, businessId, extra);kafkaProducerService.sendTransactionalMessage(message);return ResponseEntity.ok("事务消息发送成功,消息ID:" + message.getMessageId());}
}
3.11 创建启动类
package com.jam;import io.swagger.v3.oas.annotations.OpenAPIDefinition;
import io.swagger.v3.oas.annotations.info.Info;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;/*** SpringBoot应用启动类** @author 果酱*/
@SpringBootApplication
@MapperScan("com.jam.mapper")
@OpenAPIDefinition(info = @Info(title = "SpringBoot集成Kafka示例项目",version = "1.0",description = "SpringBoot集成Kafka的示例项目,包含各种消息发送和消费的示例")
)
public class SpringbootKafkaDemoApplication {public static void main(String[] args) {SpringApplication.run(SpringbootKafkaDemoApplication.class, args);}
}
3.12 创建消息轨迹相关实体和数据库表
消息轨迹实体类:
package com.jam.entity;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.time.LocalDateTime;/*** 消息轨迹实体类* 记录Kafka消息的发送和消费情况** @author 果酱*/
@Data
@TableName("t_message_trace")
public class MessageTrace {/*** 主键ID*/@TableId(type = IdType.AUTO)private Long id;/*** 消息ID*/private String messageId;/*** 主题*/private String topic;/*** 分区*/private Integer partition;/*** 偏移量*/private Long offset;/*** 业务类型*/private String businessType;/*** 业务ID*/private String businessId;/*** 消息内容*/private String content;/*** 发送时间*/private LocalDateTime sendTime;/*** 发送状态:0-待发送,1-发送成功,2-发送失败*/private Integer sendStatus;/*** 发送错误信息*/private String sendErrorMsg;/*** 消费时间*/private LocalDateTime consumeTime;/*** 消费分区*/private Integer consumePartition;/*** 消费偏移量*/private Long consumeOffset;/*** 消费状态:0-待消费,1-消费成功,2-消费失败*/private Integer consumeStatus;/*** 消费错误信息*/private String consumeErrorMsg;/*** 创建时间*/private LocalDateTime createTime;/*** 更新时间*/private LocalDateTime updateTime;
}
消息轨迹 Mapper 接口:
package com.jam.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jam.entity.MessageTrace;
import org.apache.ibatis.annotations.Param;/*** 消息轨迹Mapper** @author 果酱*/
public interface MessageTraceMapper extends BaseMapper<MessageTrace> {/*** 根据消息ID查询消息轨迹** @param messageId 消息ID* @return 消息轨迹信息*/MessageTrace selectByMessageId(@Param("messageId") String messageId);
}
消息轨迹 Mapper XML 文件(resources/mapper/MessageTraceMapper.xml):
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jam.mapper.MessageTraceMapper"><select id="selectByMessageId" parameterType="java.lang.String" resultType="com.jam.entity.MessageTrace">SELECT * FROM t_message_trace WHERE message_id = #{messageId}</select>
</mapper>
创建消息轨迹表的 SQL:
CREATE TABLE `t_message_trace` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',`message_id` varchar(64) NOT NULL COMMENT '消息ID',`topic` varchar(128) NOT NULL COMMENT '主题',`partition` int DEFAULT NULL COMMENT '分区',`offset` bigint DEFAULT NULL COMMENT '偏移量',`business_type` varchar(64) DEFAULT NULL COMMENT '业务类型',`business_id` varchar(64) DEFAULT NULL COMMENT '业务ID',`content` text COMMENT '消息内容',`send_time` datetime DEFAULT NULL COMMENT '发送时间',`send_status` tinyint DEFAULT NULL COMMENT '发送状态:0-待发送,1-发送成功,2-发送失败',`send_error_msg` text COMMENT '发送错误信息',`consume_time` datetime DEFAULT NULL COMMENT '消费时间',`consume_partition` int DEFAULT NULL COMMENT '消费分区',`consume_offset` bigint DEFAULT NULL COMMENT '消费偏移量',`consume_status` tinyint DEFAULT NULL COMMENT '消费状态:0-待消费,1-消费成功,2-消费失败',`consume_error_msg` text COMMENT '消费错误信息',`create_time` datetime NOT NULL COMMENT '创建时间',`update_time` datetime NOT NULL COMMENT '更新时间',PRIMARY KEY (`id`),UNIQUE KEY `uk_message_id` (`message_id`),KEY `idx_topic` (`topic`),KEY `idx_business_type` (`business_type`),KEY `idx_business_id` (`business_id`),KEY `idx_send_status` (`send_status`),KEY `idx_consume_status` (`consume_status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Kafka消息轨迹表';
3.13 测试消息发送与消费
启动应用程序后,可以通过以下方式测试消息发送与消费:
- 使用 Swagger UI 测试:访问http://localhost:8081/swagger-ui.html,通过界面调用消息发送接口
- 使用 curl 命令测试:
# 发送普通消息
curl -X POST "http://localhost:8081/api/kafka/normal?content=Hello Kafka&businessType=TEST"# 发送分区消息
curl -X POST "http://localhost:8081/api/kafka/partition?content=Hello Partition&businessType=TEST&businessId=BUS123456"# 发送事务消息
curl -X POST "http://localhost:8081/api/kafka/transactional?content=Hello Transaction&businessType=TEST"
发送消息后,可以在控制台看到生产者和消费者的日志输出,证明消息已经成功发送和消费。
四、Kafka 高级特性
4.1 消息确认机制
Kafka 提供了灵活的消息确认机制,确保消息的可靠传递。
-
生产者确认机制:
通过 acks 参数控制生产者需要等待的确认数量:- acks=0:生产者不等待任何确认,直接发送下一条消息
- acks=1:生产者等待 leader 分区确认收到消息
- acks=all:生产者等待所有同步副本确认收到消息
-
消费者确认机制:
通过 ack-mode 参数控制消费者何时确认消息:- auto:自动确认,消费者收到消息后立即确认
- manual:手动确认,消费者处理完消息后调用 acknowledge () 方法确认
- manual_immediate:手动确认,确认后立即提交偏移量
消息确认流程:
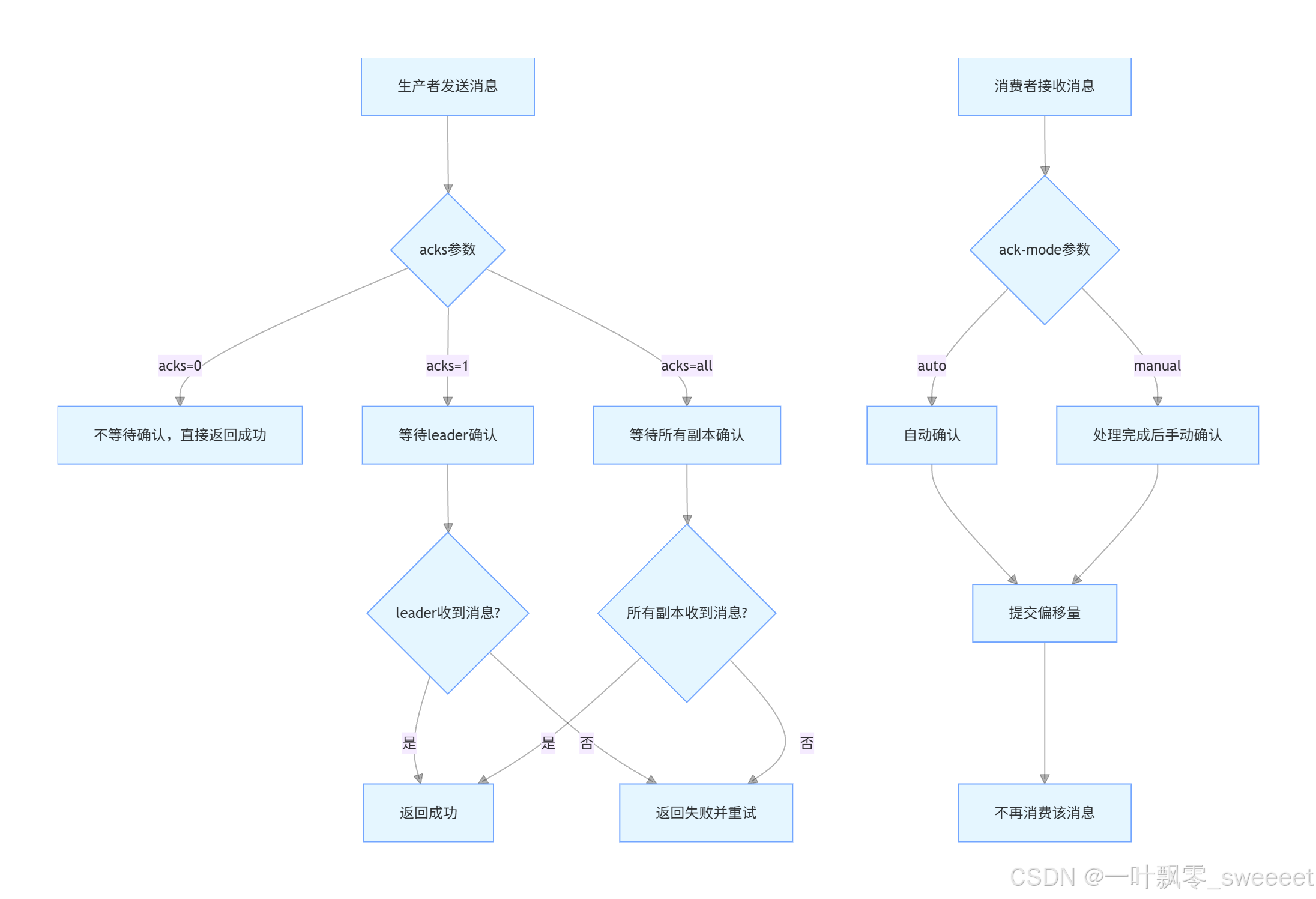
根据 Kafka 官方文档(Apache Kafka),对于需要高可靠性的场景,推荐使用 acks=all 和 manual 确认模式。
4.2 事务消息
Kafka 从 0.11 版本开始支持事务消息,确保消息的原子性:要么所有消息都被成功发送,要么都失败。
事务消息的工作流程:
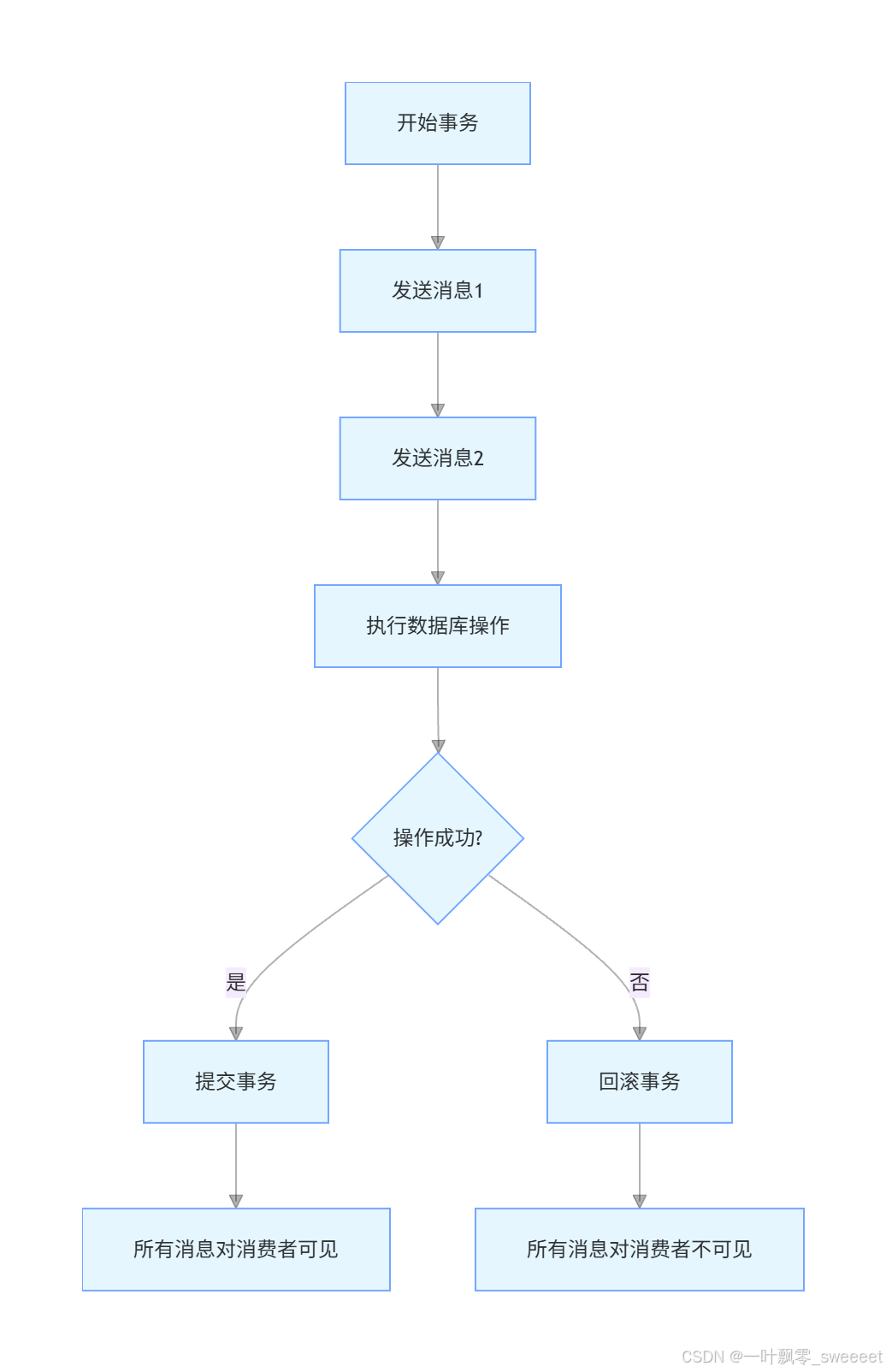
在前面的代码中,我们已经实现了事务消息的发送:
- 配置了事务生产者工厂和事务 Kafka 模板
- 使用 @Transactional 注解或 executeInTransaction 方法开启事务
- 在事务中可以混合发送消息和数据库操作等
4.3 死信队列
死信队列(Dead Letter Queue)用于存储无法被正常消费的消息。在 Kafka 中,可以通过以下方式实现死信队列:
- 配置死信主题和死信消费者
- 在消费失败时,手动将消息发送到死信主题
- 死信消费者专门处理死信消息
死信队列的工作流程:
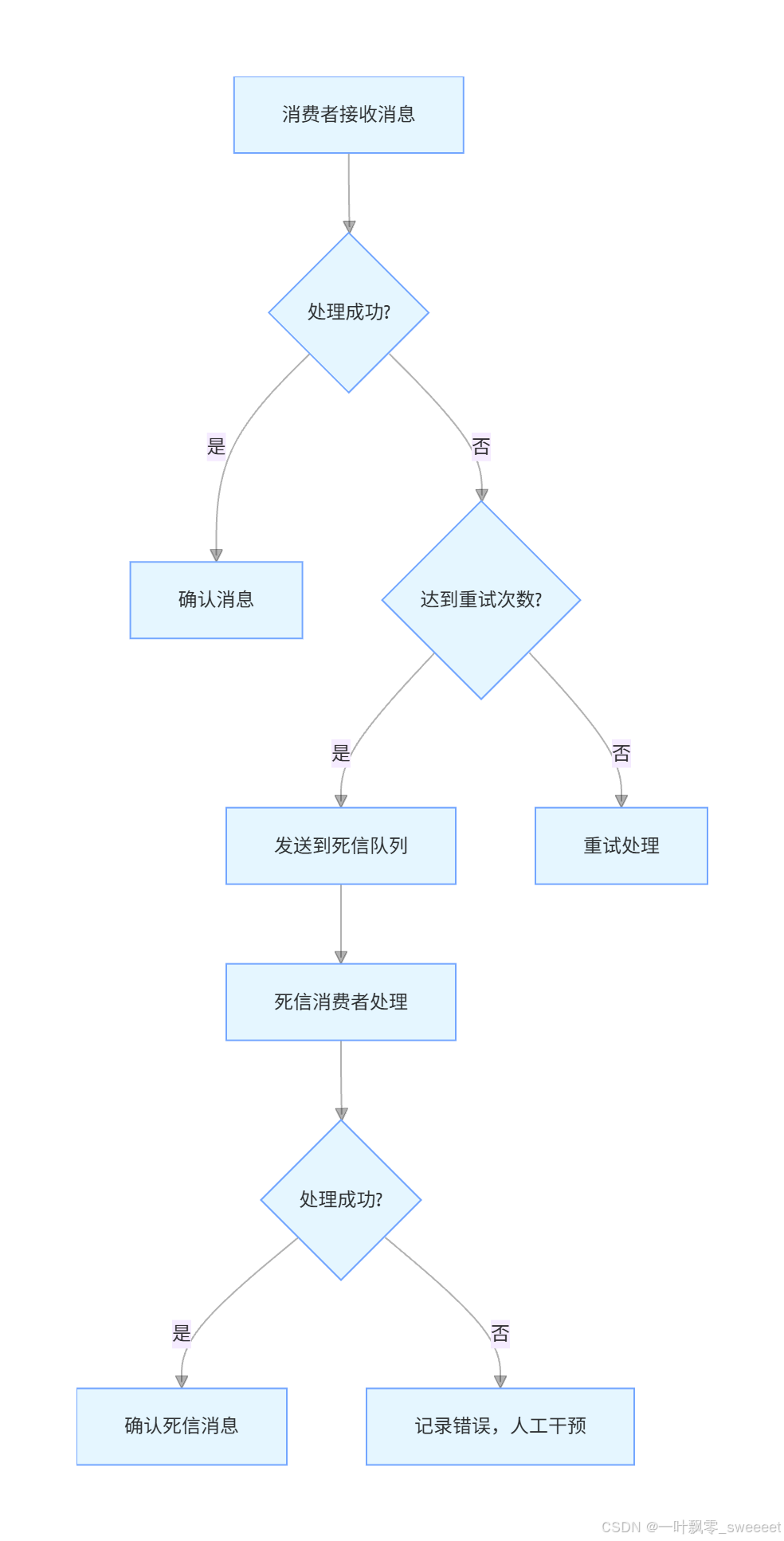
实现死信消息转发的代码示例:
/*** 转发消息到死信队列** @param message 消息实体* @param topic 原主题* @param partition 原分区* @param offset 原偏移量* @param errorMsg 错误信息*/
public void forwardToDeadLetterQueue(MessageEntity message, String topic, int partition, long offset, String errorMsg) {Objects.requireNonNull(message, "消息实体不能为空");StringUtils.hasText(topic, "主题不能为空");StringUtils.hasText(errorMsg, "错误信息不能为空");log.warn("将消息转发到死信队列,原主题:{},消息ID:{},错误信息:{}",topic, message.getMessageId(), errorMsg);// 创建死信消息,添加原消息的元数据MessageEntity deadLetterMessage = new MessageEntity();deadLetterMessage.setMessageId(UUID.randomUUID().toString());deadLetterMessage.setContent(JSON.toJSONString(message));deadLetterMessage.setBusinessType("DEAD_LETTER");deadLetterMessage.setBusinessId(message.getMessageId());deadLetterMessage.setCreateTime(LocalDateTime.now());deadLetterMessage.setExtra(String.format("原主题:%s,原分区:%d,原偏移量:%d,错误信息:%s",topic, partition, offset, errorMsg));// 发送到死信主题kafkaTemplate.send(KafkaConstant.DEAD_LETTER_TOPIC, deadLetterMessage.getMessageId(), deadLetterMessage);
}
4.4 消息幂等性
在分布式系统中,消息重复消费是不可避免的问题,因此需要保证消息消费的幂等性。常用的实现方式有:
- 基于数据库唯一索引:
/*** 处理消息(幂等性保证)** @param message 消息实体*/
@Transactional(rollbackFor = Exception.class)
public void processMessageWithIdempotency(MessageEntity message) {String messageId = message.getMessageId();String businessType = message.getBusinessType();// 检查消息是否已经处理过MessageTrace trace = messageTraceMapper.selectByMessageId(messageId);if (trace != null && trace.getConsumeStatus() == 1) {log.info("消息已经处理过,消息ID:{}", messageId);return;}// 根据业务类型处理不同的消息if ("ORDER_CREATE".equals(businessType)) {// 处理订单创建消息,使用订单号作为唯一键String orderNo = message.getExtra();// 检查订单是否已经处理Order order = orderMapper.selectByOrderNo(orderNo);if (order != null) {log.info("订单已经处理过,订单号:{}", orderNo);return;}// 处理订单业务逻辑// ...} else if ("USER_REGISTER".equals(businessType)) {// 处理用户注册消息,使用用户ID作为唯一键// ...}
}
- 基于 Redis 的分布式锁:
/*** 使用Redis分布式锁保证幂等性** @param message 消息实体*/
public void processMessageWithRedisLock(MessageEntity message) {String messageId = message.getMessageId();String lockKey = "kafka:message:process:" + messageId;// 获取分布式锁,设置5分钟过期时间Boolean locked = redisTemplate.opsForValue().setIfAbsent(lockKey, "1", 5, TimeUnit.MINUTES);if (Boolean.TRUE.equals(locked)) {try {// 检查消息是否已经处理过MessageTrace trace = messageTraceMapper.selectByMessageId(messageId);if (trace != null && trace.getConsumeStatus() == 1) {log.info("消息已经处理过,消息ID:{}", messageId);return;}// 处理消息业务逻辑processMessage(message);} finally {// 释放锁redisTemplate.delete(lockKey);}} else {log.info("消息正在处理中,消息ID:{}", messageId);}
}
五、Kafka 性能调优
为了让 Kafka 在生产环境中发挥最佳性能,我们需要进行合理的调优。以下是一些关键的调优方向:
5.1 服务器调优
-
JVM 参数调优:
根据服务器内存大小合理配置 JVM 参数# 在kafka-server-start.sh中设置 export KAFKA_HEAP_OPTS="-Xms8g -Xmx8g -XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M" -
操作系统调优:
- 增加文件描述符限制
# 在/etc/security/limits.conf中添加 * soft nofile 1000000 * hard nofile 1000000- 调整网络参数
# 在/etc/sysctl.conf中添加 net.core.rmem_default=134217728 net.core.rmem_max=134217728 net.core.wmem_default=134217728 net.core.wmem_max=134217728 net.ipv4.tcp_wmem=134217728 134217728 134217728 net.ipv4.tcp_rmem=134217728 134217728 134217728 net.ipv4.tcp_max_syn_backlog=8192 net.core.netdev_max_backlog=16384 -
Kafka 配置调优:
# server.properties # 日志刷新策略 log.flush.interval.messages=10000 log.flush.interval.ms=1000# 日志保留策略 log.retention.hours=72 log.retention.bytes=107374182400# 分区大小限制 log.segment.bytes=1073741824# I/O线程数 num.io.threads=8# 网络线程数 num.network.threads=3# 分区副本同步线程数 num.replica.fetchers=2# 副本滞后阈值 replica.lag.time.max.ms=30000
5.2 生产者调优
-
批量发送:
配置合理的批次大小和 linger.ms 参数,实现批量发送spring:kafka:producer:# 批次大小,当批次满了之后才会发送batch-size: 16384# linger.ms参数,即使批次未满,达到该时间也会发送properties:linger.ms: 5 -
压缩消息:
启用消息压缩,减少网络传输和存储开销spring:kafka:producer:# 启用消息压缩,可选值:none, gzip, snappy, lz4, zstdproperties:compression.type: lz4 -
异步发送:
使用异步发送提高吞吐量,避免阻塞主线程 -
自定义分区策略:
根据业务特点实现自定义分区策略,均衡分区负载
5.3 消费者调优
-
消费线程池配置:
根据分区数量配置合理的消费者线程数spring:kafka:listener:# 并发消费者数量,建议等于分区数量concurrency: 3# 每次拉取的记录数consumer:max-poll-records: 500 -
批量消费:
开启批量消费提高消费效率spring:kafka:listener:# 开启批量消费batch-listener: trueconsumer:# 批量消费需要设置为falseenable-auto-commit: false# 每次拉取的最大记录数properties:max.poll.records: 500批量消费代码示例:
/*** 批量消费消息*/ @KafkaListener(topics = KafkaConstant.NORMAL_TOPIC, groupId = KafkaConstant.NORMAL_CONSUMER_GROUP) public void batchConsume(List<ConsumerRecord<String, MessageEntity>> records,Acknowledgment acknowledgment) {log.info("接收到批量消息,数量:{}", records.size());for (ConsumerRecord<String, MessageEntity> record : records) {MessageEntity message = record.value();if (message == null) {continue;}try {log.info("处理批量消息,主题:{},分区:{},偏移量:{},消息ID:{}",record.topic(), record.partition(), record.offset(), message.getMessageId());// 处理消息的业务逻辑processMessage(message);// 记录消费成功轨迹messageTraceService.recordConsumeSuccess(message.getMessageId(),record.partition(), record.offset());} catch (Exception e) {// 记录消费失败轨迹messageTraceService.recordConsumeFailure(message.getMessageId(),record.partition(), record.offset(), e.getMessage());log.error("批量消息处理失败,消息ID:{}", message.getMessageId(), e);// 转发到死信队列forwardToDeadLetterQueue(message, record.topic(), record.partition(), record.offset(), e.getMessage());}}// 手动确认所有消息acknowledgment.acknowledge();log.info("批量消息处理完成,数量:{}", records.size()); } -
异步处理:
消费者接收到消息后,将消息放入线程池异步处理,快速确认消息,提高消费效率
5.4 主题和分区调优
-
合理设置分区数量:
分区数量是影响 Kafka 吞吐量的关键因素,一般建议:- 每个主题的分区数量 = 预期吞吐量 / 单分区吞吐量
- 单分区吞吐量:生产者约 500-1000 条 / 秒,消费者约 1000-2000 条 / 秒
-
合理设置副本数量:
- 副本数量越多,可靠性越高,但会降低吞吐量
- 生产环境建议设置为 2-3 个副本
-
清理策略:
根据业务需求设置合理的日志清理策略:- 按时间清理:log.retention.hours
- 按大小清理:log.retention.bytes
六、常见问题与解决方案
6.1 消息丢失问题
消息丢失可能发生在三个阶段:生产阶段、存储阶段和消费阶段。
-
生产阶段丢失:
- 解决方案:设置 acks=all,确保所有副本都收到消息
spring:kafka:producer:acks: allretries: 3 -
存储阶段丢失:
- 解决方案:设置合理的副本数量和同步策略
# server.properties # 最小同步副本数,应小于等于副本数 min.insync.replicas=2 -
消费阶段丢失:
- 解决方案:使用手动确认模式,确保消息处理完成后再确认
spring:kafka:listener:ack-mode: manual_immediate
6.2 消息积压问题
消息积压通常是因为消费速度跟不上生产速度,解决方案如下:
-
优化消费逻辑:
- 减少单次消息处理时间
- 异步处理非关键流程
-
增加消费者数量:
- 水平扩展消费者实例
- 确保消费者数量不超过分区数量
-
临时扩容:
- 对于突发流量,可以临时启动更多的消费者实例
-
消息迁移:
- 创建新的主题和消费者组,将积压的消息迁移到新主题
/*** 迁移积压消息*/ @Scheduled(fixedRate = 60000) public void migrateBacklogMessages() {String sourceTopic = "source_topic";String targetTopic = "backlog_topic";String consumerGroup = "backlog_migrate_group";log.info("开始迁移积压消息,源主题:{},目标主题:{}", sourceTopic, targetTopic);// 创建临时消费者DefaultKafkaConsumerFactory<String, MessageEntity> consumerFactory = new DefaultKafkaConsumerFactory<>(kafkaProperties.buildConsumerProperties());try (KafkaConsumer<String, MessageEntity> consumer = (KafkaConsumer<String, MessageEntity>) consumerFactory.createConsumer(consumerGroup, new DefaultPrincipal("migrate-service"))) {// 订阅源主题consumer.subscribe(Collections.singleton(sourceTopic));// 从最早的偏移量开始消费consumer.seekToBeginning(consumer.assignment());while (true) {ConsumerRecords<String, MessageEntity> records = consumer.poll(Duration.ofMillis(1000));if (records.isEmpty()) {break;}// 批量发送到目标主题List<ProducerRecord<String, MessageEntity>> producerRecords = new ArrayList<>();for (ConsumerRecord<String, MessageEntity> record : records) {producerRecords.add(new ProducerRecord<>(targetTopic, record.key(), record.value()));}// 批量发送kafkaTemplate.send(producerRecords);log.info("已迁移消息:{}条", producerRecords.size());// 手动提交偏移量consumer.commitSync();// 控制迁移速度,避免影响正常业务Thread.sleep(100);}} catch (Exception e) {log.error("迁移积压消息失败", e);}log.info("积压消息迁移完成"); } -
监控告警:
- 配置消息积压监控和告警,及时发现问题
/*** 消息积压监控*/ @Scheduled(fixedRate = 60000) // 每分钟检查一次 public void monitorMessageBacklog() {// 监控的主题和消费者组Map<String, String> monitorTopics = new HashMap<>();monitorTopics.put(KafkaConstant.NORMAL_TOPIC, KafkaConstant.NORMAL_CONSUMER_GROUP);monitorTopics.put(KafkaConstant.PARTITION_TOPIC, KafkaConstant.PARTITION_CONSUMER_GROUP);// 获取KafkaAdminClienttry (AdminClient adminClient = AdminClient.create(kafkaProperties.buildAdminProperties())) {for (Map.Entry<String, String> entry : monitorTopics.entrySet()) {String topic = entry.getKey();String consumerGroup = entry.getValue();// 获取消费者组的偏移量Map<TopicPartition, OffsetAndMetadata> committedOffsets = adminClient.listConsumerGroupOffsets(consumerGroup).partitionsToOffsetAndMetadata().get();// 获取主题的最新偏移量Map<TopicPartition, Long> endOffsets = adminClient.listOffsets(committedOffsets.keySet()).all().get();// 计算每个分区的积压数量for (Map.Entry<TopicPartition, OffsetAndMetadata> offsetEntry : committedOffsets.entrySet()) {TopicPartition topicPartition = offsetEntry.getKey();long consumerOffset = offsetEntry.getValue().offset();long endOffset = endOffsets.get(topicPartition);long backlog = endOffset - consumerOffset;log.info("主题:{},分区:{},积压消息数:{}", topic, topicPartition.partition(), backlog);// 如果积压数量超过阈值,发送告警if (backlog > 10000) {log.warn("主题消息积压严重,主题:{},分区:{},积压消息数:{}", topic, topicPartition.partition(), backlog);// 发送告警通知(邮件、短信等)alertService.sendAlert("Kafka消息积压告警", String.format("主题:%s,分区:%d,积压消息数:%d", topic, topicPartition.partition(), backlog));}}}} catch (Exception e) {log.error("消息积压监控失败", e);} }
6.3 消息顺序性问题
Kafka 中,单个分区的消息是有序的,但跨分区的消息无法保证顺序。确保消息顺序性的解决方案如下:
-
单分区:
- 所有消息都发送到同一个分区,保证全局有序
- 缺点:无法利用多分区的并行处理能力,吞吐量受限
-
按业务 ID 分区:
- 相同业务 ID 的消息发送到同一个分区,保证局部有序
- 优点:兼顾顺序性和吞吐量
// 如前面实现的BusinessIdPartitioner -
使用状态机:
- 对于需要全局有序的场景,可以在消费端实现状态机,处理乱序消息
七、总结
本文详细介绍了 SpringBoot 集成 Kafka 的全过程,从基础概念到高级特性,从代码实现到性能调优,涵盖了实际开发中可能遇到的各种场景。
Kafka 作为一款高性能的分布式消息系统,在大数据领域和实时流处理场景中有着广泛的应用。合理使用 Kafka 可以帮助我们构建高吞吐、高可靠的分布式系统。
八、参考
- Kafka 核心概念与架构:参考 Kafka 官方文档(Apache Kafka)
- SpringBoot 集成 Kafka:参考 Spring Kafka 官方文档(Overview :: Spring Kafka)
- 消息确认机制:参考 Kafka 官方文档的 "Producer Configs" 和 "Consumer Configs" 章节
- 事务消息:参考 Kafka 官方文档的 "Transactions" 章节(Apache Kafka)
- 性能调优参数:参考 Kafka 官方文档的 "Performance Tuning" 章节(Apache Kafka)
- 消息幂等性解决方案:参考 Spring 官方博客和《Kafka 权威指南》一书
- 消息丢失与积压解决方案:参考 Kafka 官方文档和 Confluent 博客(Confluent Blog | Tutorials, Tips, and News Updates)


)
















