0、前言:
0.1、为什么学习shell脚本
- 学习Shell(Shell脚本编程)是提升系统管理和开发效率的重要技能,尤其在Linux/Unix环境中作用显著。Shell是用户与操作系统内核的接口,学习Shell有助于掌握系统工作原理。
shell的核心作用
1、自动化重复任务【用for循环批量处理文件】
2、系统管理和维护【通过chmod管理权限、通过脚本监控CPU/内存使用率】
3、快速原型开发【shell脚本无需编译是解释型语言、可以快速数据清洗、格式转换】
4、大多数Linux系统自带解释器【Bash】,脚本可以直接运行,无需额外配环境
5、★可以与其它工具集成【调用系统命令grep、awk、sed;与Python配合实现复杂功能】
- ★Shell是系统管理员和开发者的“瑞士军刀”,学习它能让你从“手动操作”升级为“自动化工程师”,显著提升工作效率并加深对系统的理解。即使未来转向其他语言,Shell思维仍会长期受益。
0.2、gitee用来干什么
- Gitee 就像一个专门管代码的多功能平台,不管是个人写代码、团队一起做项目,还是企业搞开发,都能用它解决很多实际问题,从专业角度来说 git 是一个分布式的版本控制工具。
1.个人开发者:存代码、备份、看历史修改,还能跟别人分享自己写的开源项目(比如让大家一起改进你的小工具);Gitee 能设置 “自动流程”:你一提交代码,它就自动帮你编译、跑测试,有问题马上告诉你,不用你自己点鼠标等半天。
2.小团队 / 学生组:一起写代码不冲突,管任务进度,不用额外装复杂软件;如果两人改了同一段代码(比如都改了登录功能),它会提醒 “这里有冲突”,帮你们理清谁改的是对的,避免改乱。
3.企业:除了上述功能,还能保障代码安全、统计项目效率(比如多久能完成一个需求)、用 AI 辅助查代码 bug,一套平台搞定开发全流程。
4.gitee中还可以进行版本回退
- 常见版本控制工具:git、svn、cvs、vss、tfs
- 版本控制的分类:
- 本地版本控制,就是自己每次更行文件夹
- 集中版本控制(svn):所有数据都在单一服务器上,本地只有一个版本
- 分布式版本控制:所有版本信息仓库全部都同步到每一个用户电脑上,用户可以在本地查看所有版本历史,也可以离线提交到本地仓库,只要在联网的时候push到服务器上即可,只要有一个用户版本没问题,就可以恢复所有数据
1、shell指令:
1.1、Shell和linux的Bash指令之间的区别
- Shell是用户和操作系统内核交互的命令行接口包含【Bash、Zsh、Fish、Sh等】,它是一种解释型编程语言,shell逐行解释执行;
Zsh:需要更强大的命令补全和主题定制(如 Oh My Zsh)。
Fish:追求用户友好性(自动建议、语法高亮)。
Dash:需要极简、快速的 Shell(如嵌入式系统)。
- Bash是Shell的具体实现,是目前最流行的默认Shell;
- Shell 像“汽车类别”(如轿车、SUV),Bash 像“特斯拉 Model 3”(具体车型);
- 差异性举例:
- Bash 独有命令:[[ ]] 条件判断(比 [ ] 更强大)、{1…10} 数字序列生成、array=(“a” “b”) 数组支持
- 通用 Shell 命令:cd、ls、echo 等基础命令在所有 Shell 中通用、if [ -f file ]; then … 这种 [ ] 语法在 Sh/Bash 中均可用
- 编写脚本时,通过第一行(也叫shebang行)判断用哪个Shell解释:【如果不加 Shebang,系统会默认用当前 Shell】
#!/bin/bash # 强制用 Bash 解释(支持 Bash 特性)
#!/bin/sh # 用系统默认 Shell(可能是 Dash,更严格遵循 POSIX 标准)
1.2、shell基础入门:
1.2.1、变量和引号和$符:
- 1、变量定义与赋值:Shell 变量是存储数据的容器 【语法:变量名=值(等号两侧不能有空格)】
# 变量示例:
name="Alice" # 定义字符串变量
age=25 # 定义数字变量(Shell 中所有变量本质是字符串)
path=/home/user # 定义路径变量
- 2、变量的引用:【语法:$变量名 或 ${变量名}(推荐用 ${},避免歧义)】
echo $name # 输出: Alice
echo "Hello, ${name}!" # 输出: Hello, Alice!(更清晰)
- 注意:shell中变量名命名规则和C语言一致;
- 3、部分特殊变量:
# 脚本 test.sh 内容:
echo "脚本名: $0"
echo "第一个参数: $1"
echo "参数个数: $#$"
echo "所有参数: $@"# 运行脚本:
./test.sh Apple Banana
# 输出:
# 脚本名: ./test.sh
# 第一个参数: Apple
# 参数个数: 2
# 所有参数: Apple Banana
-
4、环境变量:Shell 中的环境变量是全局可见的变量,用于存储系统或用户的配置信息(如路径、用户名、默认编辑器等),让脚本和程序能在不同环境中正常运行。【环境变量是 Shell 中具有 “跨进程传递能力” 的全局变量】
- 环境变量分为两种,一种是系统环境变量,一种是用户环境变量,临时设置的用户环境变量(终端中直接 export 变量=值)只在当前 Shell 会话中有效,重启或新开终端后会消失。如果想要设置永久保存具有跨进程传递能力的环境变量,就要往 ~/.bashrc 中加变量,例如: export JAVA_HOME=/usr/lib/jvm/java-11-openjdk 。
- 配置系统环境变量的意义:很多程序(如 Java、Python、Docker 等)需要依赖特定的环境变量才能正常工作(比如 JAVA_HOME 告诉程序 Java 安装在哪里)。如果不配置永久环境变量,每次打开新终端或重启系统后,都需要手动执行 export JAVA_HOME=… 才能让程序正常运行,非常繁琐。
永久配置后,系统会自动加载这些变量,一劳永逸。 - 普通环境变量在当前shell或者由此shell创建的子shell中都能访问,其他变量可以理解为局部变量。案例如下
# 以下是在交互式shell中的执行结果 brush@ubuntu:~/Desktop$ local_tes=12 brush@ubuntu:~/Desktop$ export export_tes=13 brush@ubuntu:~/Desktop$ echo ${local_tes} 12 brush@ubuntu:~/Desktop$ echo ${export_tes} 13 brush@ubuntu:~/Desktop$ cat -n test.sh1 #!/bin/bash2 echo ${local_tes}3 echo ${export_tes} brush@ubuntu:~/Desktop$ bash ./test.sh13 brush@ubuntu:~/Desktop$- 常用系统环境变量:查看所有环境变量用 env 或 printenv 命令,例如 printenv PATH 可单独查看 PATH 的值。【Shell 中的系统环境变量是操作系统预定义的一组全局变量,它们就像 “系统的配置说明书”,控制着 Shell 及各种程序的运行方式、路径查找、用户信息等核心行为。例如:当你在终端输入 ls 时,系统会依次在 PATH 包含的目录中查找 ls 程序(实际在 /bin/ls),找到后执行。如果没有 PATH,你必须输入完整路径(如 /bin/ls)才能执行命令,非常繁琐。】
brush@ubuntu:~/Desktop$ printenv SHELL=/bin/bash LANGUAGE=zh_CN:en LC_ADDRESS=en_US.UTF-8 LC_NAME=en_US.UTF-8 LC_MONETARY=en_US.UTF-8 PWD=/home/brush/Desktop LOGNAME=brush export_tes=13 XDG_SESSION_TYPE=tty brush@ubuntu:~/Desktop$ printenv PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin -
5、Shell 引号:控制字符串解析规则,说白了就是一些特殊符号的权限问题
- 双引号:允许变量扩展($var 会被替换为变量值)、允许命令替换(
command或 $(command) 会被替换为命令输出)、禁止通配符扩展(如 * 不会被解析为文件名)。 - 单引号:禁止所有扩展:变量、命令、通配符均按字面值处理。【就记住一点,单引号中禁止所有特殊符号起作用】
name="Alice" echo 'Hello, $name!' # 输出: Hello, $name!(变量不扩展) echo 'Today is $(date)' # 输出: Today is $(date)(命令不替换)name="Alice" echo 'Hello, $name!' # 输出: Hello, $name!(变量不扩展) echo 'Today is $(date)' # 输出: Today is $(date)(命令不替换) - 双引号:允许变量扩展($var 会被替换为变量值)、允许命令替换(
-
6、【$(命令)】 就是 “先执行命令,再拿结果用” 的语法
-
7、shell中$符号的用法

- 注意:$(( )) 内部会自动解析变量名,所以在 $(( )) 当中写变量不用${变量名},直接写变量名即可;
- 补充:${!变量名} 用于 “通过变量的值找到另一个变量”(间接获取变量值),如果name=2、${name}的结果就是2、a=“name”、${!a}的结果也是2,对于shell中的参数而言,假设第一个参数是5,那么参数5的变量名就是1,${1}的结果就是5、a=1、${!a}的结果也是5。
- 关于测试双引号作用时踩的坑:【交互shell和脚本shell傻傻分不清楚】
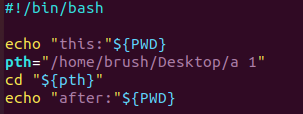
- 上面这个shell代码很简单吧,我第一次写这个代码的时候,我没加最后一句echo,每次执行,就只是打印当前路径,然后我并没有观察到我的liunx终端的路径发生改变,我就用国内ai大量查找,死活没给我讲明白,最后通过sider(edge中的一款ai)才搞清楚,在程序中cd执行的就是将程序切换到某个路径下,并非将外面的环境(交互shell)切换到某个路径。【当你运行一个脚本(例如 bash test.sh 或 ./test.sh)时,系统会为脚本创建一个新的子进程。子进程能自由修改自己的工作目录,但这些修改不会影响父进程(启动它的 shell),因为每个进程的属性是独立的。】
- 上面的案例主要还是想测试下在执行cd命令时候,加双引号和不加双引号的区别,当程序中没给 ${pth} 加双引号,就会报错说cd 参数太多。原因如下:赋值处的双引号只影响赋值过程,不会“记住”在后续展开时自动为你加上保护。当 shell 遇到 cd ${pth} 时,先把 ${pth} 展开为 /home/brush/Desktop/a 1,然后进行单词拆分(word splitting):默认以 IFS(通常是空格、制表符、换行)为界,把展开结果拆成多个独立的字段,结果 cd 实际接收到两个参数:/home/brush/Desktop/a 和 1。cd “${pth}” 告诉 shell:把变量整个作为一个单词处理,不要进行单词拆分或文件名展开。
- 这个例子就是想说明双引号支持变量拓展,结果踩了个坑发现了Shell中赋值双引号在变量传递过程中是不会整体传递的,有点像c中的宏定义,就是替换而已;还有发现了shell脚本中cd路径和交互shell中cd路径是两码事。
- 拓展:如果上面的shell脚本中用了单引号将 ${pth} 括起来,结果就是 ${pth} 本身就会被当做路径,不会解析把pth当做变量解析了。
-
总结:一般情况下调用Bash中的变量的时候,在外面加个双引号比较可靠。
1.2.2、条件判断
- 基本语法格式
if [ 条件 ]; then命令...
elif [ 其他条件 ] && [ 其他条件 ]; then命令...
else命令...
fi
- 文件测试:
1.-e 判断文件是否存在
2.-d 判断文件是不是目录
3.-f 判断文件是不是常规文件
4.-r、-w、-x 判断文件是否可读、可写、可执行
#!/bin/bash
file="/home/brush/Desktop/test.sh
if [ -e "$file" ]; then # 文件或目录存在echo "存在"
fi
- 判断字符串是否相等:
#!/bin/bash
s1="hello"
s2="world"if [ "$s1" = "$s2" ]; thenecho "相等"
elseecho "no equil"
fi- 整数比较:
eq【是否等于】, -ne【是否不等于】, -lt【是否小于】, -le【是否小于等于】, -gt【是否大于】, -ge【是否大于等于】
#!/bin/bash
a=10
b=8
if [ "${a}" -gt "${b}" ]; thenecho '10 > 8'
elseecho '10 < 8'
fi
执行结果是:10 > 8
1.2.3、循环
-
for循环:
- 格式:
# 写法1:遍历列表(直观,推荐) for 变量名 in 列表内容 do要执行的命令(变量用 $变量名 调用) done# 写法2:C语言风格(适合数字范围,需指定起始/结束/步长) for ((变量=起始值; 变量<=结束值; 变量=变量+步长)) do要执行的命令 done- 实践1【遍历当前文件列表,计算有多少文件,用for的列表遍历写法】
#!/bin/bash count=0 for i in $(ls) doif [ -f ${i} ]; thencount=$((count+1))echo ${i} is a filefi done echo file number is : ${count}- 实践2【给两个文件,分别通过for的c语言风格,输入指定长度的序列,比如第1个参数是3,就会在第一个文件中输入1-3,第2个参数是4,就会在第2个文件中输入1-4】【提示1:通过内置变量 $# 来获取传递给脚本的参数个数;提示2:$@ 是所有参数的集合】
#!/bin/bash for((i=1; i<=$#; i=i+1)) do#这里用了参数简介引用echo 1-${!i} > file_${i}.txt done -
while循环:未知循环次数,按条件停止
- 格式
while 条件判断(满足则继续循环,不满足则退出) do要执行的命令 done # 陷入“死循环”(按 Ctrl+C 强制停止)。- 案例:输入不是quit就一直循环
# 先定义一个初始变量,让循环先启动 input="" while [ "$input" != "quit" ] # 条件:只要 input 不是 quit,就继续 doecho "请输入内容(输入 quit 退出):"read input # 读取用户输入,存到 input 变量echo "你输入的是:$input" done echo "循环结束!"- 注意:不是所有条件都写在while后面的 [ 条件 ] 当中,有的条件是直接写的;
-
until(直到):条件为假时执行循环体,直到条件为真时停止。
- 基本格式
until 条件判断 do要执行的命令 done- 案例:
attempts=0 # until 写法:条件(尝试次数≥3)为真时停止 until ((attempts >= 3)); doecho "第 $((attempts+1)) 次尝试..."attempts=$((attempts + 1)) done# 等价的 while 写法:条件(尝试次数<3)为真时执行 attempts=0 while ((attempts < 3)); doecho "第 $((attempts+1)) 次尝试..."attempts=$((attempts + 1)) done
1.2.4、参数传递
- 执行脚本时,直接在脚本名后面跟参数,用空格分隔,就能向脚本中传递参数,有点像C++的构造函数中初始化参数列表的方式。
- 格式:【./脚本名 参数1 参数2 参数3 …】
- 例如:
# 执行脚本并传递 3 个参数:apple、"hello world"、123
./test.sh apple "hello world" 123
- 常用指令

- 案例:
#!/bin/bash
for i in $@
doecho $i
done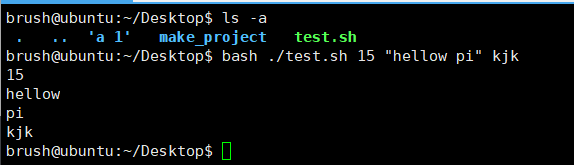
将代码进一步修改,给 $@ 加上双引号
#!/bin/bash
for i in "$@"
doecho $i
done

为什么会出现上面的情况,核心原因是 双引号会 “保护”$@ 的特殊行为,让它严格按照 “参数列表” 的原始形态展开,而不是被拆分成字符串碎片。 当你写 $@(无引号)时,Shell 会触发 “单词拆分”(Word Splitting)机制:它会把 $@ 中的所有参数拼接成一个字符串(用空格分隔),比如变成 “15 hellow pi kjk”;然后按空格、制表符、换行符拆分这个字符串。
- $1 到 $9 可以直接用,第 10 个及以上参数必须用 ${10}、${11}…(加花括号),其实从严格书写的角度来说,1到9也应该写成 ${1} 到 ${9} 。
- 选项参数用 getopts 【了解即可】
1.3、实用技巧:
1.3.1、字符串操作:
- Shell 字符串支持拼接、截取、替换、长度计算等操作,是文本处理的基础。
- 字符串拼接:
name="张三"
age=20
# 方法:双引号内直接拼接
echo "姓名:${name},年龄:${age}" # 输出:姓名:张三,年龄:20
- 字符串长度:
str="hello world"
echo "长度:${#str}" # 输出:11
- 字符串截取:
str="abcdefg"
echo "${str:2:3}" # 从索引2开始,取3个字符 → "cde"
- 字符串替换:
str="hello world, world is beautiful"
echo "${str/world/China}" # 单次替换 → "hello China, world is beautiful"
echo "${str//world/China}" # 全局替换 → "hello China, China is beautiful"
- 字符串删除:
- 从开头删除:1、${var#匹配模式}:从开头最短匹配并删除、2. ${var##匹配模式}:从开头最长匹配并删除,案例如下:
brush@ubuntu:~/Desktop$ cat -n test.sh1 #!/bin/bash2 str="/1/2345/7"3 echo ${str#/*/}4 echo ${str##/*/} brush@ubuntu:~/Desktop$ bash ./test.sh 2345/7 7- 从结尾删除:1. ${var%匹配模式}:从结尾最短匹配并删除、2. ${var%%匹配模式}:从结尾最长匹配并删除,参考上面案例,不做解释了;
1.3.2、数组:
- Shell 支持索引数组(默认)和关联数组(需声明),用于存储一组数据。
- 索引数组
# ====================索引数组的定义与赋值# 方法1:直接定义,用圆括号
array=(apple banana "cherry pie" 123)# 方法2:逐个赋值
array[0]=apple
array[1]=banana
array[2]="cherry pie"
array[3]=123# ====================访问元素echo "${array[0]}" # 访问第一个元素 → "apple"
echo "${array[2]}" # 访问第三个元素 → "cherry pie"
echo "${array[@]}" # 访问所有元素 → "apple banana cherry pie 123"
echo "${array[*]}" # 同 @,但合并为一个字符串 → "apple banana cherry pie 123"# ====================数组长度
echo "元素个数:${#array[@]}" # 输出:4
echo "第一个元素长度:${#array[0]}" # 输出:5("apple"的长度)# ====================遍历数组
for item in "${array[@]}"; doecho "元素:$item"
done
- 关联数组
# 声明关联数组
declare -A map# 赋值(键可以是字符串)
map["name"]="张三"
map["age"]=20
map["city"]="北京"# 访问
echo "姓名:${map["name"]}" # 输出:张三
echo "所有键:${!map[@]}" # 输出:name age city
echo "所有值:${map[@]}" # 输出:张三 20 北京# 遍历
for key in "${!map[@]}"; doecho "键:$key,值:${map[$key]}"
done
1.3.3、重定向:
- 概念:Shell 中的重定向是控制命令输入输出流向的核心机制,简单说就是 “改变数据的默认来源或去向”。默认情况下,命令的输入来自键盘(标准输入),输出显示在屏幕(标准输出),错误信息也显示在屏幕(标准错误)。重定向让我们可以把输入输出 “转移” 到文件或其他地方,非常实用。
- 前提知识:
- 0(stdin):标准输入,默认是键盘
- 1(stdout):标准输出,默认是屏幕(正常运行结果)
- 2(stderr):标准错误,默认是屏幕(错误提示信息)
- 重定向的本质就是改变这三个流的 “源头” 或 “目的地”。
- 命令格式:
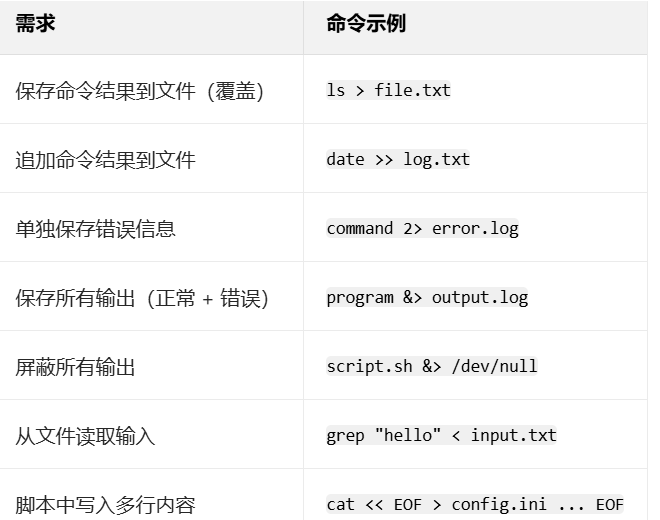
注意:脚本写入多行中用了cat指令,cat最常用的场景就是预览文件,但是cat的本质是读取输入(文件或标准输入)并输出内容 - 案例:
brush@ubuntu:~/Desktop$ clear
brush@ubuntu:~/Desktop$ ls -l
总用量 12
drwxrwxr-x 2 brush brush 4096 Sep 3 19:54 'a 1'
drwxrwxr-x 2 brush brush 4096 Sep 2 08:22 make_project
-rwxrwxrwx 1 brush brush 49 Sep 5 01:51 test.sh
# 测试重定向输出(覆盖)
brush@ubuntu:~/Desktop$ ls > file.txt
brush@ubuntu:~/Desktop$ cat -n file.txt1 a 12 file.txt3 make_project4 test.sh
# 测试重定向输出(添加)
brush@ubuntu:~/Desktop$ echo this is append >> file.txt
brush@ubuntu:~/Desktop$ cat -n file.txt1 a 12 file.txt3 make_project4 test.sh5 this is append
# 测试错误信息重定向输出(覆盖)
brush@ubuntu:~/Desktop$ cd /home/666 2> file.txt
brush@ubuntu:~/Desktop$ cat -n file.txt1 -bash: cd: /home/666: 没有那个文件或目录
# 测试输出所有信息
brush@ubuntu:~/Desktop$ cd /home | cd ./666 &> file.txt
brush@ubuntu:~/Desktop$ cat -n file.txt1 -bash: cd: ./666: 没有那个文件或目录
# 测试从文件读内容
brush@ubuntu:~/Desktop$ cat -n file.txt1 -bash: cd: ./666: 没有那个文件或目录
brush@ubuntu:~/Desktop$ echo afdaf >> file.txt
brush@ubuntu:~/Desktop$ echo fadfaf666 >> file.txt
brush@ubuntu:~/Desktop$ grep 666 < file.txt
-bash: cd: ./666: 没有那个文件或目录
fadfaf666
brush@ubuntu:~/Desktop$
# 测试让脚本‘安静地’运行,不产生任何可见输出的“黑洞命令”
brush@ubuntu:~/Desktop$ test.sh &> /dev/null
# 测试向脚本中写入多行【】
brush@ubuntu:~/Desktop$ cat -n file.txt
brush@ubuntu:~/Desktop$ cat << o > file.txt
> fafaafafg
> fajjijja
> o
brush@ubuntu:~/Desktop$ cat -n file.txt1 fafaafafg2 fajjijja1.3.4、函数:
- 函数用于封装可复用的逻辑,避免代码重复,提升脚本可读性。
# 格式1:带 function 关键字
function hello {echo "Hello, $1" # $1 是第一个参数
}# 格式2:无 function 关键字(更简洁,推荐)
hello() {echo "Hello, $1"
}
- 函数返回值:用 return 数值(仅支持整数,0 表示成功,非 0 表示失败)
- 局部变量:用 local 变量名(仅在函数内生效,避免污染全局变量)
add() {local a=$1 # 局部变量 alocal b=$2 # 局部变量 blocal sum=$((a + b))echo "两数之和:$sum" # 打印信息(不是返回值)return $sum # 返回值(仅整数,这里返回 sum 的值)
}add 5 3 # 调用函数
echo "函数返回值:$?" # $? 是上一条命令的返回值 → 输出:8
- 函数练习
rename_files() {local prefix=$1 # 新文件名前缀local ext=$2 # 文件扩展名local i=1# 遍历所有 .txt 文件for file in *.txt; domv "$file" "${prefix}_${i}.${ext}"i=$((i + 1))doneecho "重命名完成,共处理 $((i-1)) 个文件"
}rename_files "new_file" "txt" # 调用函数,前缀为 new_file,扩展名 txt
1.4、高级玩法:【只做介绍,后续需要继续深入】
- 正则表达式
- 信号处理
- 子Shell
- 调试技巧
2、gitee:
2.1、gitee上传和下载文件的原理概览:
- gitee与本地电脑进行沟通的四个存储区域的通俗解释:
1.工作区:正在改的草稿;
2.暂存区:准备提交的 “候选草稿”;
3.本地仓库:自己电脑里的 “历史版本库”;
4.远程仓库:云端的 “共享版本库”。
- 图示说明:
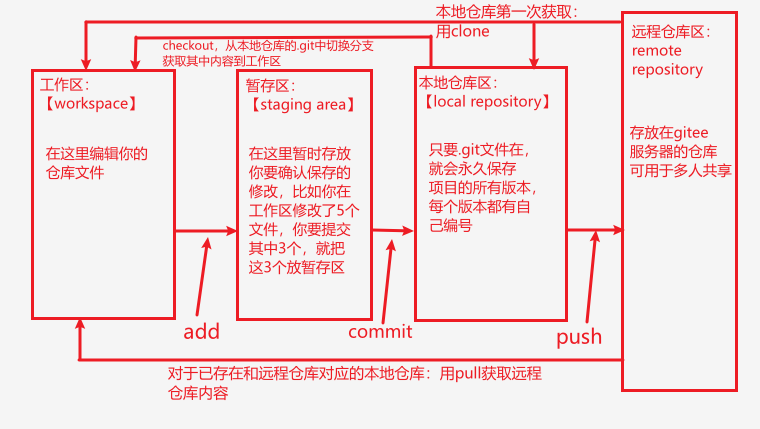
- 如果已经有了和远程仓库关联的本地仓库,就用pull来获取远程仓库的内容,高效便捷;不能再用clone来获取远程仓库内容了,因为这样做会浪费磁盘空间,可能导致多个本地仓库副本之间状态不一样,给版本管理带来混乱。
- 注意:只有通过add放到暂存区的文件才会被gitee跟踪,被跟踪的文件上传都会审核,未被跟踪的文件,gitee操作过程中不会对其进行审核操作。【尽量不要在gitee网页端上传文件,这种上传不会触发审核机制!】---------==f-a-f=-fafsafafasf
- 注意:Git Bash 本质上是一个模拟 Unix 终端环境的工具(在 Windows 上尤为明显),它内置了一套类 Linux 的命令集,所以你熟悉的很多 Shell 指令(比如 Linux/macOS 终端里的命令)都能直接用。
- 注意:建立本地仓库最好建立在磁盘下路径下,文件路径中没有中文。
2.2、远程仓库没有要上传的项目的仓库:
- ①、创建本地项目文件夹,在该文件夹下,在 git Bash 中通过 git init 创建本地仓库
- ②、在本地仓库中,通过 Git Bash 输入指令 git add . 【将所有文件夹里修改的文件都加入暂存区】
- ③、在本地仓库中,通过 Git Bash 输入 git commit -m “提交说明” 【这一步是把文件存到本地仓库】
- ④、在Gitee上新建远程仓库,填写仓库名称最好和本地文件一样,记住仓库地址
- ⑤、在本地仓库中,通过 Git Bash 输入 git remote add origin 你的远程仓库地址 【将本地仓库和远程仓库绑定】
- ⑥、在本地仓库中,通过 Git Bash 输入git push -u origin 远程分支名称 【把本地仓库内容上传,通过 git branch 查看远程分支名】
- 注意:版本更新信息会记录在本地仓库的 .git 中
2.3、远程仓库已有仓库存放项目,需要从本地拉取远程仓库内容并修改:
- ①、在你本地文件夹中,使用 git clone 远程仓库地址 【拉取远程仓库项目的所有信息,自动创建 .git 存放远程仓库项目的所有版本信息】
- ②、在本地仓库修改代码
- ③、在本地仓库中,通过 Git Bash 输入指令 git add . 【将所有文件夹里修改的文件都加入暂存区】
- ④、在本地仓库中,通过 Git Bash 输入 git commit -m “提交说明” 【这一步是把文件存到本地仓库】
- ⑤、在本地仓库中,通过 Git Bash 输入git push【把本地仓库内容上传】
- ⑥、如果换了电脑,第一次推送会要求输入Gitee账号和密码,这个账号就是你的远程仓库地址当中的用户名【例如:git@gitee.com:Bat/test.git 中 Bat 就是用户名,有时候为了在gitee上为了路径可用,有可能会有路径中用户名和gitee用户名不一致的情况】,密码就是你的Gitee密码
- 注意:如果在本地通过ssh -keygen -t rsa -C “你的邮箱地址” 生成了公钥,将公钥(id_rsa.pub)粘贴到Gitee平台中你的账号设置当中,以后每次通过ssh的方式输入远程仓库地址,就可以直接上传,无需再输入密码了。
2.4、版本回退的方法:
- git checkout 就像一个 “状态切换器”—— 可以在不同分支、不同版本、不同文件状态之间灵活切换,是 Git 管理多版本和多分支的核心工具之一。
- 指令:git log 【可以查看历史版本】
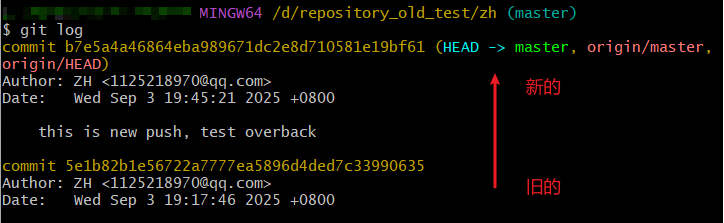
- 通过:git reset --hard 版本id 【退回某一个版本,注意此时只是本地仓库退回了某个版本,gitee中的远程仓库并没有回退,如果要回退,就要把本地回退版本重新push】,在本地仓库版本回退后,如果再往远程仓库普通push,可能会出现下面提示:
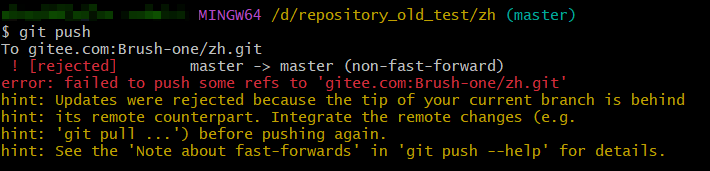
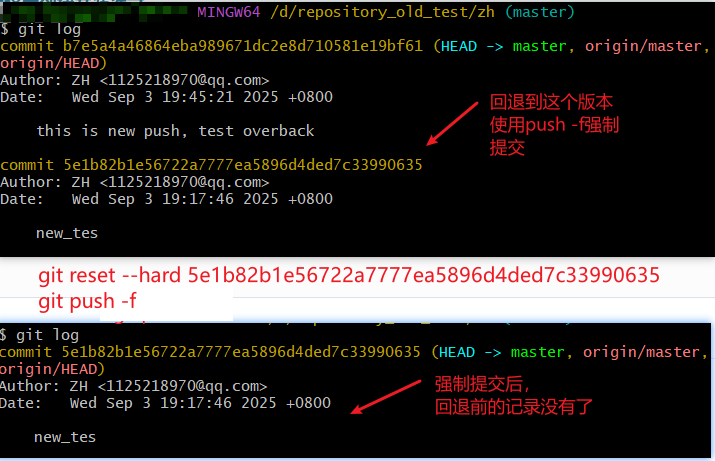
【出现上面报错的原因:Git 要求推送前,你的本地分支必须包含远程分支的所有最新内容(确保 “基于最新版本修改”),否则就会拒绝推送,避免覆盖远程的新修改。这是一种保护机制,防止多人协作时出现代码丢失。解决方案就是通过 git push -f 强制推送,这样就能确保远程仓库也回退到之前版本,当然如果涉及多人开发,就要谨慎使用 -f 命令了,最好先查看最新提交,然后通过 git revert 反向提交,然后通过普通push就可以回退版本了,这样既回退了内容,又保留了完整历史,适合多人开发场景。】
git revert 的工作原理:
1、假设提交历史是这样的:
A → B → C → D(D 是最新提交)
如果 D 提交有问题,执行 git revert D 后:
Git 会分析 D 提交做了哪些修改(比如新增了某行代码、删除了某个文件);
自动创建一个新提交 E,这个提交会 “反向执行 D 的修改”(比如删除 D 新增的代码、恢复 D 删除的文件);
最终历史变成:A → B → C → D → E,E 的内容和 C 完全一致,但保留了 D 的历史记录。
2、git revert HEAD 【撤销最近一次提交】
3、git revert abc123 # 撤销 版本id为:abc123 这次提交的修改
4、使用revert后,可能会出现让你确认 “撤销操作的说明文字”,按默认内容保存退出即可完成整个 revert 流程;
-
如下总结了强制版本退回的流程:
-
如下总结了revert的操作流程:
先提交一个log.txt文件到远程仓库作为一次提交
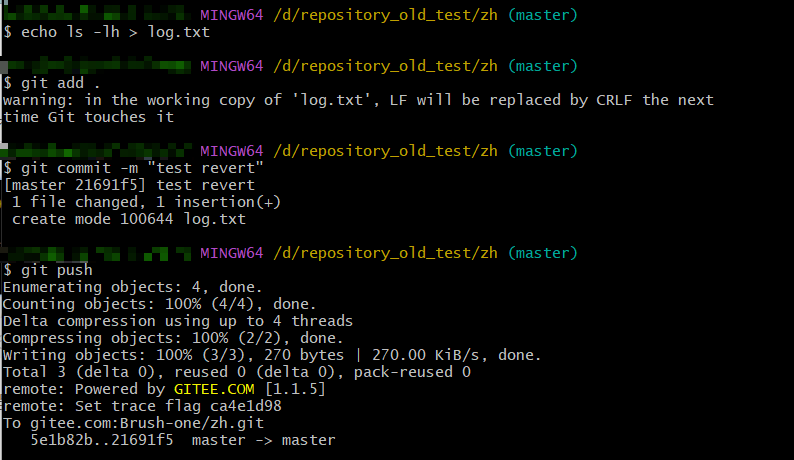
再执行核心操作 git revert
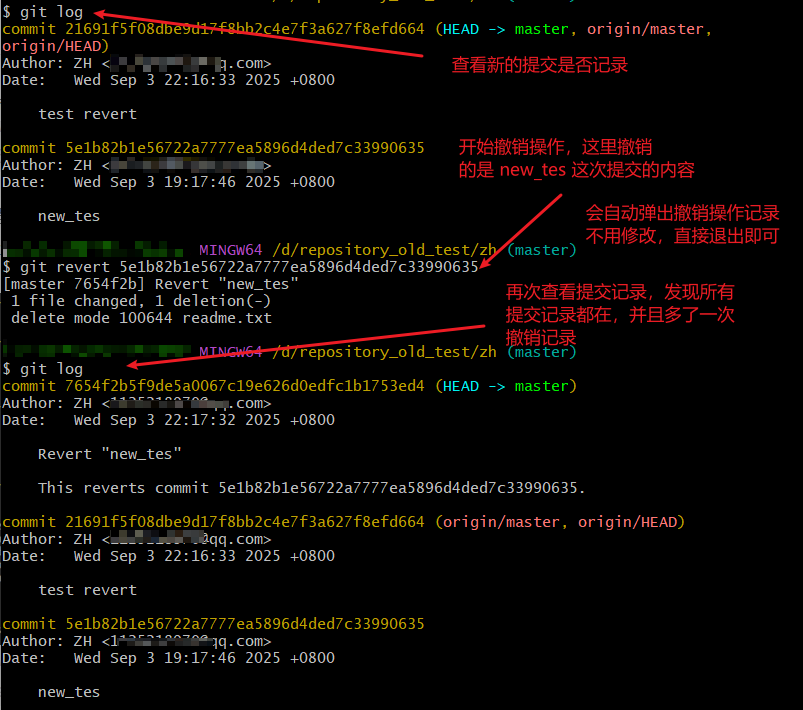
这里只是本地版本回撤了,最后还要记得,通过git push 提交远程仓库,实现远程仓库版本回撤,这个时候,就不用加 -f 强制提交了
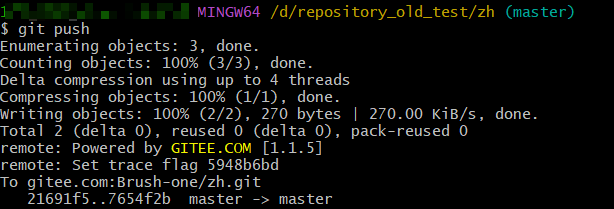
-
★总结:
- git reset 后面跟要回退到哪个版本
- git revert 后面跟要撤销哪个版本的提交
2.5、创建分支:
- 创建分支的目的:你正在写一本小说(主分支,比如叫main),已经写完了第 5 章。这时候你想尝试两种结局:一个是 “圆满结局”,一个是 “开放式结局”。如果直接在原稿上改,写了一半想换另一种结局,之前的修改可能就乱了。分支就相当于 “复印一份当前的小说稿”,你可以在复印件上写 “圆满结局”(比如叫happy-ending分支),同时在另一份复印件上写 “开放式结局”(比如叫open-ending分支)。原稿(主分支)保持不变,两份复印件(新分支)各自修改,互不影响。最后哪个结局好,就把哪个 “合并” 到原稿里 —— 这就是分支的作用:同时尝试多种修改,互不干扰。
- 创建分支的方法:
- 1、可以在gitee中创建
- 2、可以在本地创建,输入【git branch 分支名】
- 查看分支:git branch -r 命令可以查看远程所有分支
- 切换分支的方法:
- 1、可以在gitee中切换
- 2、可以在本地切换,输入【 git checkout 分支名】
- 总结:建议使用本地创建的方式,这样本地就能实时掌握远程仓库分支的情况,如果是网页创建的,还需要在本地pull一下才能得知。
2.6、冲突解决的方法:
- gitee中出现冲突的场景:多个人(或你自己在不同分支)改了 “同一份文件的同一个地方”,最后要合并 / 提交时,Git 不知道该留哪版修改,就会出现冲突。具体分为下面两种情况:
- 1、多人改同一文件:比如你和同事都在 main 分支编辑 “项目说明.md”:同事先改了第 5 行,写 “项目截止日期是 10 月”,并提交到 Gitee;你没先拉取同事的修改,自己也改了第 5 行,写 “项目截止日期是 11 月”,然后想提交到 Gitee;这时候 Git 发现 “同一行有两个不同的内容”,就会提示 “冲突”,不让你直接提交。
- 2、自己在不同分支改同一文件:比如你在 dev 分支改了 “登录页面.html” 的按钮颜色为红色,又在 main 分支改了同一个按钮颜色为蓝色,之后想把 dev 分支合并到 main 分支时,Git 分不清该留红色还是蓝色,也会出现冲突。
- 解决冲突的方法:核心逻辑就是手动告诉 Git “该留哪部分修改”,确定后再重新提交 / 合并。
- 1、先拉取最新内容(确保本地有别人的修改)
- 2、找到冲突文件,手动修改,打开提示冲突的文件,gitee会有标记,删干净 <<<<<<<、=======、>>>>>>> 这些标记,只留最终要的内容
- 3、确认修改,重新提交:git add 冲突文件名、git commit -m “解决项目说明.md 的截止日期冲突”(写个备注,说明改了啥)、git push(把解决完冲突的版本推到 Gitee)。
- 总结:冲突不可怕,本质是 “Git 拿不准该留哪版”,你只要手动确定最终内容,再告诉 Git 就行~

:文法+单词第8回3 复习 +考え方6)










)





)
