Linux inode 实现机制深入分析
1 Inode 基本概念与作用
Inode(Index Node)是 Linux 和其他类 Unix 操作系统中文件系统的核心数据结构,用于存储文件或目录的元数据(metadata)。每个文件或目录都有一个唯一的 inode,其中包含了除文件名以外的所有信息。inode 的本质是一个结构化的数据记录,它连接了文件的逻辑组织与物理存储。
1.1 inode 的重要性
在 Linux 文件系统中,inode 的作用主要体现在以下几个方面:
- 元数据存储:inode 存储了文件的关键属性,包括权限、所有者、大小、时间戳等。
- 数据定位:inode 包含了指向文件数据块的指针,通过这种间接寻址方式,系统能够高效地访问文件内容。
- 硬链接实现:多个文件名可以指向同一个 inode,这使得硬链接成为可能,inode 中的引用计数(
i_nlink)跟踪这些链接数量。
1.2 inode 与文件名、数据块的关系
Linux 文件系统将存储空间划分为两个独立部分:
- 元数据区域:存储 inode 表,每个 inode 有唯一编号。
- 数据区域:实际存储文件内容的块。
文件名与 inode 的映射关系存储在目录文件中。目录本质上是包含文件名到 inode 编号映射的特殊文件。当用户访问一个文件时,系统首先在目录中查找文件名对应的 inode 编号,然后通过该编号从 inode 表中获取元数据,最后根据元数据中的数据块指针访问文件内容。
表:inode 中包含的主要元信息
| 字段 | 描述 | 示例值 |
|---|---|---|
i_ino | inode 编号 | 256789 |
i_mode | 文件类型和权限 | 0o100644 (常规文件,rw-r–r--) |
i_uid | 所有者用户ID | 1000 |
i_gid | 所有者组ID | 1000 |
i_size | 文件大小(字节) | 102400 |
i_blocks | 使用的磁盘块数 | 200 |
i_atime | 最后访问时间 | 2023-10-30 08:00:00 |
i_mtime | 最后修改时间 | 2023-10-29 19:30:00 |
i_ctime | inode 最后变更时间 | 2023-10-29 19:30:00 |
i_nlink | 硬链接计数 | 2 |
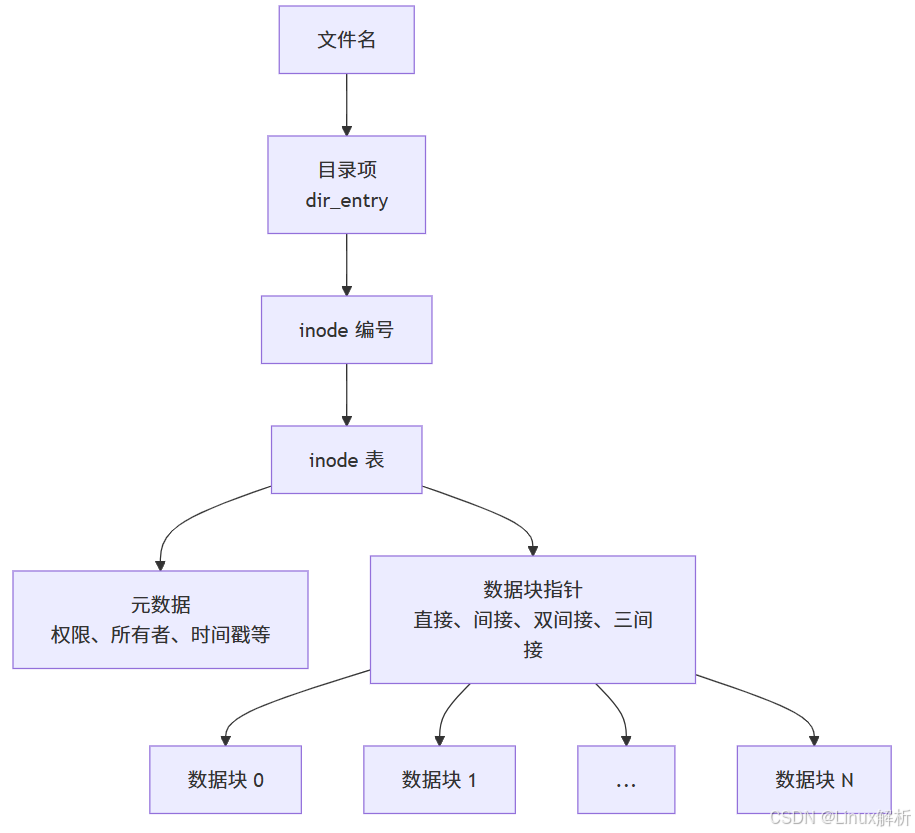
不同的文件系统(如 ext4、XFS、Btrfs)在 inode 的具体实现上有所差异,但核心概念一致。例如,ext4 文件系统支持扩展属性(xattr)和动态 inode 分配,而较老的 ext2 文件系统则有固定的 inode 数量限制。
2 Inode 的工作原理与实现机制
2.1 inode 的磁盘存储结构
在磁盘上,文件系统被划分为多个块组(block groups)。每个块组通常包含一个 inode 表(inode table)和一个用于记录 inode 使用情况的位图(inode bitmap)。inode 表是连续存储的 inode 结构数组,每个 inode 的大小固定(如 ext4 中默认为 256 字节)。这种组织方式使得系统能够快速定位和访问特定编号的 inode。
超级块(superblock)包含了整个文件系统的元信息,其中也记录了 inode 的总数、已使用数以及每个 inode 的大小等信息。当文件系统被挂载时,超级块的信息会被读入内存,以便高效访问。
2.2 inode 的内存管理机制
为了提高性能,Linux 内核会在内存中维护 inode 的缓存,即 inode cache。内存中的 inode 结构可能比磁盘上的更丰富,包含了一些运行时状态。
2.2.1 slab 分配器
内核使用 slab 分配器来高效地分配和释放 inode 对象。在系统初始化时,会创建一个名为 inode_cachep 的 slab 缓存,专门用于分配 inode 对象。这使得 inode 对象的分配和释放非常快速,并有助于减少内存碎片。
// 内核中创建 inode slab 缓存的示例代码(简化)
static struct kmem_cache *inode_cachep;inode_cachep = kmem_cache_create("inode_cache",sizeof(struct inode),0,(SLAB_RECLAIM_ACCOUNT|SLAB_PANIC|SLAB_MEM_SPREAD),init_once);
2.2.2 inode 缓存与哈希表
内核维护了几个链表来高效管理内存中的 inode:
inode_in_use:包含正在使用的 inode(引用计数i_count> 0)。inode_unused:包含未被使用的 inode(引用计数为 0,可被回收)。- 超级块的
s_dirty:包含脏(已被修改但未写回磁盘)的 inode。
为了快速通过 inode 编号和超级块找到 inode,内核使用了一个哈希表 inode_hashtable。每个哈希桶包含一个链表,链接着具有相同哈希值的 inode 对象。
2.2.3 inode 的状态与同步
内存中的 inode 有多种状态,由 i_state 字段表示:
I_DIRTY:inode 是脏的,需要写回磁盘。I_LOCK:inode 正在被进行 I/O 操作。I_FREEING:inode 正在被释放。
脏 inode 会被定期(由 pdflush 线程)或强制(调用 sync() 系统调用)写回磁盘。写回操作由文件系统特定的 write_inode 方法处理。
2.3 inode 的主要操作
2.3.1 创建与初始化
当新文件或目录被创建时,文件系统需要分配一个新的 inode。这个过程大致如下:
- 在 inode 位图中查找一个空闲的 inode。
- 初始化该 inode 的元信息(如模式、所有者、时间戳等)。
- 将 inode 标记为已使用,并将其写入 inode 表。
内核函数 get_empty_inode() 用于获取一个空闲的 inode 对象:
struct inode *get_empty_inode(void) {struct inode *inode;// 从 slab 分配器分配一个 inode 对象inode = alloc_inode();if (inode) {spin_lock(&inode_lock);inodes_stat.nr_inodes++;// 将 inode 添加到 inode_in_use 链表list_add(&inode->i_list, &inode_in_use);// 初始化部分字段inode->i_sb = NULL;inode->i_dev = 0;inode->i_ino = ++last_ino;inode->i_flags = 0;atomic_set(&inode->i_count, 1);inode->i_state = 0;spin_unlock(&inode_lock);// 清理并初始化 inode 的其他字段clean_inode(inode);}return inode;
}
2.3.2 查找与获取
当打开文件时,内核需要根据文件名找到对应的 inode。这个过程涉及目录项缓存(dentry cache)和 inode 缓存 lookup。如果 inode 不在缓存中,文件系统必须从磁盘读取它。函数 iget() 用于通过超级块和 inode 编号获取一个 inode 对象。如果 inode 不在缓存中,它会分配一个新的 inode 对象并调用文件系统特定的 read_inode 方法来填充它。
2.3.3 销毁与释放
当文件被删除(硬链接计数降为 0)且没有任何进程打开它时,其 inode 可以被释放。这个过程包括:
- 将相关的数据块标记为空闲。
- 在 inode 位图中将该 inode 标记为空闲。
- 将 inode 对象返回给 slab 分配器。
函数 iput() 用于减少 inode 的引用计数,并在引用计数降为 0 时可能触发释放操作:
void iput(struct m_inode *inode) {if (!inode) return;wait_on_inode(inode);if (!inode->i_count)panic("iput: trying to free free inode");// ... 处理管道、块设备、字符设备等特殊情况 ...if (inode->i_count > 1) {inode->i_count--;return;}if (!inode->i_nlinks) {truncate(inode); // 截断文件,释放数据块free_inode(inode); // 释放 inodereturn;}// ... 如果 inode 是脏的,写回磁盘 ...inode->i_count--;
}
3 核心数据结构与代码分析
3.1 主要数据结构
Linux 内核中 inode 的核心数据结构是 struct inode,它包含了文件的所有元数据信息以及用于操作和管理的字段。以下是其重要字段的详细说明:
struct inode {// 基本字段umode_t i_mode; // 文件类型和权限unsigned short i_opflags; // 操作标志kuid_t i_uid; // 所有者用户IDkgid_t i_gid; // 所有者组IDunsigned int i_flags; // 文件系统无关的标志// 链接和时间相关unsigned long i_ino; // Inode 编号unsigned int i_nlink; // 硬链接计数dev_t i_rdev; // 如果是设备文件,表示设备号loff_t i_size; // 文件大小(字节)struct timespec64 i_atime; // 最后访问时间struct timespec64 i_mtime; // 最后修改时间(文件内容)struct timespec64 i_ctime; // 最后状态改变时间(inode 元数据)// 块和存储相关unsigned long i_blocks; // 文件占用的扇区数unsigned int i_blkbits; // 块大小的位数(如 12 表示 4KB)blkcnt_t i_blocks; // 块数量(已废弃?)// 操作函数指针const struct inode_operations *i_op; // inode 操作const struct file_operations *i_fop; // 文件操作(当inode是文件时)struct super_block *i_sb; // 所属的超级块struct address_space *i_mapping; // 页缓存映射// 状态和同步unsigned long i_state; // 状态标志(I_DIRTY, I_LOCK等)struct mutex i_mutex; // 互斥锁spinlock_t i_lock; // 自旋锁// 引用计数atomic_t i_count; // 引用计数// 其他重要字段void *i_private; // 文件系统或设备的私有数据
};
除了 struct inode,还有一些相关的关键数据结构:
struct super_block:代表一个已挂载的文件系统实例,包含文件系统的全局信息,如块大小、根 inode、inode 总数和空闲数,以及操作函数表super_operations(包含了alloc_inode,destroy_inode,write_inode等方法)。struct address_space:与 inode 关联,用于管理文件的页缓存(page cache)。它包含一个基数树(radix tree)用于快速查找缓存页,以及操作函数表address_space_operations(如readpage,writepage)。struct file:代表一个打开的文件实例,包含当前读写位置(f_pos)、指向关联 inode 的指针(f_inode)以及文件操作函数表(f_op)。
3.2 关键代码分析
Linux 内核中 inode 相关的操作函数分布在各文件系统中,但有一些通用的函数和机制。
3.2.1 inode 初始化
inode_init_owner() 函数用于初始化新 inode 的所有权字段(uid 和 gid)。其逻辑是:如果没有指定父目录,或者父目录没有特定的 ACL(访问控制列表)操作,则新 inode 的 uid 和 gid 通常继承自父目录。如果设置了 setuid 或 setgid 位,则进行相应处理。
void inode_init_owner(struct inode *inode, struct inode *dir, umode_t mode)
{kuid_t uid;kgid_t gid;if (dir && dir->i_op->get_acl)return;if (!dir || IS_ERR(dir))dir = current->fs->root_inode;/* 从父目录获取所有者 */uid = dir->i_uid;gid = dir->i_gid;/* 处理 setuid 和 setgid 位 */if ((mode & S_ISUID) != 0)uid = GLOBAL_ROOT_UID;if ((mode & S_ISGID) != 0)gid = GLOBAL_ROOT_GID;i_uid_write(inode, uid);i_gid_write(inode, gid);// ... 初始化时间和其他字段 ...
}
3.2.2 inode 缓存操作
iget_locked() 函数是 inode 缓存查找的核心。它尝试通过超级块和 inode 编号在哈希表中查找 inode。如果找到,则返回该 inode;如果没有找到,则分配一个新的 inode 并将其插入哈希表,然后通知文件系统从磁盘填充该 inode。
4 简单实例应用:获取文件 inode 信息
为了加深对 inode 的理解,我们创建一个简单的 C 程序,使用 stat 系统调用来获取指定文件的 inode 信息并打印出来。这个实例展示了用户空间程序如何访问 inode 中的元数据。
4.1 源码实现
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <time.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>void print_file_info(const char *path) {struct stat statbuf;// 使用 stat 系统调用获取文件信息,这些信息来自文件的 inodeif (stat(path, &statbuf) == -1) {fprintf(stderr, "Error getting info for '%s': %s\n", path, strerror(errno));return;}printf("Information for file: %s\n", path);printf("---------------------------\n");printf("Inode number: %lu\n", (unsigned long)statbuf.st_ino);printf("File size: %lld bytes\n", (long long)statbuf.st_size);printf("Number of blocks allocated: %lld\n", (long long)statbuf.st_blocks);printf("Block size: %ld bytes\n", (long)statbuf.st_blksize);// 打印文件类型和权限printf("File type: ");if (S_ISREG(statbuf.st_mode))printf("Regular file\n");else if (S_ISDIR(statbuf.st_mode))printf("Directory\n");else if (S_ISCHR(statbuf.st_mode))printf("Character device\n");else if (S_ISBLK(statbuf.st_mode))printf("Block device\n");else if (S_ISFIFO(statbuf.st_mode))printf("FIFO/pipe\n");else if (S_ISSOCK(statbuf.st_mode))printf("Socket\n");else if (S_ISLNK(statbuf.st_mode))printf("Symbolic link\n");elseprintf("Unknown?\n");printf("Permissions: %o\n", statbuf.st_mode & 0777);printf("Link count: %lu\n", (unsigned long)statbuf.st_nlink);// 打印所有权信息printf("Ownership: UID=%ld, GID=%ld\n", (long)statbuf.st_uid, (long)statbuf.st_gid);// 转换并打印时间戳printf("Last access: %s", ctime(&statbuf.st_atime));printf("Last modification: %s", ctime(&statbuf.st_mtime));printf("Last status change: %s", ctime(&statbuf.st_ctime));printf("\n");
}int main(int argc, char *argv[]) {if (argc < 2) {fprintf(stderr, "Usage: %s <file1> [file2] ...\n", argv[0]);exit(EXIT_FAILURE);}for (int i = 1; i < argc; i++) {print_file_info(argv[i]);}return 0;
}
4.2 编译与运行
- 将上述代码保存为
inode_info.c。 - 使用 gcc 编译:
gcc -o inode_info inode_info.c - 运行程序并指定文件路径:
./inode_info /etc/passwd /var/log/syslog
4.3 输出示例
程序运行后,会输出指定文件的 inode 信息,如下所示:
Information for file: /etc/passwd
---------------------------
Inode number: 787061
File size: 2416 bytes
Number of blocks allocated: 8
Block size: 4096 bytes
File type: Regular file
Permissions: 644
Link count: 1
Ownership: UID=0, GID=0
Last access: Wed Oct 25 10:30:45 2023
Last modification: Wed Oct 25 10:30:45 2023
Last status change: Wed Oct 25 10:30:45 2023
这个程序直观地展示了 inode 中存储的关键信息,包括 inode 编号、文件大小、权限、链接数等,这些都是文件系统管理文件的核心元数据。
5 常用工具命令和 debug 手段
管理和调试 Linux 文件系统及 inode 的工具有很多,以下是一些常用命令和方法的总结,并结合实例说明其用法。
5.1 命令行工具
表:常用的 inode 相关命令
| 命令 | 主要功能 | 示例用法 | 说明 |
|---|---|---|---|
stat | 显示文件 inode 的元数据 | stat file.txt | 查看文件的详细信息(inode 编号、权限、大小、时间戳等) |
ls | 列出目录内容 | ls -li | -i 选项显示每个文件的 inode 编号 |
df | 报告文件系统磁盘空间使用情况 | df -i | -i 选项显示 inode 使用情况而非块使用情况 |
debugfs | 文件系统调试器 | debugfs /dev/sda1 | 交互式检查和管理文件系统,可查看和修改 inode |
dumpe2fs | 显示 ext2/3/4 文件系统信息 | dumpe2fs /dev/sda1 \| grep -i inode | 显示超级块中关于 inode 的信息(总数、空闲数、大小等) |
5.1.1 使用 debugfs 查看 inode 详细信息
debugfs 是一个强大的交互式文件系统调试工具,可以用来检查和处理文件系统的状态,包括直接查看和操作 inode。
示例:查看文件的创建时间(crtime)
# 首先查找文件所在的设备
df /path/to/file
# 输出示例:/dev/sda1 100663296 36740736 63768576 37% /# 使用 ls -i 获取文件的 inode 号
ls -i /path/to/file
# 输出示例:787061 file.txt# 使用 debugfs 的 stat 命令查看 inode 详细信息
sudo debugfs -R 'stat <787061>' /dev/sda1
在输出信息中,可以找到 crtime 字段,即文件的创建时间,这是 stat 命令通常不显示的信息。

5.1.2 使用 dumpe2fs 查看文件系统级 inode 信息
dumpe2fs 可以显示 ext 系列文件系统的超级块和块组详细信息,其中包含整个文件系统中 inode 的总体情况。
sudo dumpe2fs /dev/sda1 | grep -i "inode count"
# 输出:Inode count: 6553600
# Free inodes: 5121234sudo dumpe2fs /dev/sda1 | head -n 50
# 显示文件系统信息的前50行,包含每个块组的 inode 信息
5.2 内核调试手段
对于内核开发者或需要深入排查文件系统问题的情况,有以下更高级的调试手段:
- GDB 与 KGDB:可以使用 GDB(配合 KGDB 进行内核调试)在内核代码中设置断点,例如在
iput(),iget()等函数处,单步跟踪 inode 的分配、引用和释放过程。 - 内核 Tracepoints 和 Ftrace:利用内核内置的跟踪工具(如
trace-cmd)来监控与 inode 相关的内核函数调用事件,这对于分析性能问题或竞争条件非常有用。 - 打印 inode 状态信息:在内核代码中添加
printk语句(需重新编译内核),打印特定 inode 的状态、引用计数变化等信息。// 示例:在 iput 函数中添加打印 printk(KERN_DEBUG "iput: ino=%lu, count=%d, nlink=%u\n",inode->i_ino, atomic_read(&inode->i_count), inode->i_nlink); - 查看 /proc/slabinfo:
slabinfo提供了系统中 slab 缓存的使用情况,可以查看inode_cache的活动情况,帮助判断 inode 缓存是否存在泄漏或过度使用。cat /proc/slabinfo | grep inode_cache
5.3 处理常见问题
- "No space left on device" (但 df 显示有空间):这通常是 inode 耗尽导致的。使用
df -i确认。解决方法:清理无用的小文件或临时文件;或者重新格式化文件系统并分配更多的 inode(如使用mkfs.ext4 -N number_of_inodes)。 - 文件删除后空间未释放:如果还有进程打开着某个文件,即使你删除了它(即从目录中移除了硬链接),其 inode 和数据块也不会立即释放,直到所有打开的文件描述符都关闭。使用
lsof | grep deleted查找此类文件。 - 使用
debugfs恢复误删除的文件:如果文件刚被删除,且其 inode 和数据块尚未被重用,有可能通过debugfs恢复。- 使用
ls -ld /path/to/deleted/file的 inode 号(如果还记得路径)。 - 或用
debugfs -R 'ls -d /path/to/parent_dir' /dev/device查看已删除的条目(标记为<deleted>)。 - 用
debugfs -R 'dump <inode> /tmp/recovered_file' /dev/device尝试导出数据。
- 使用
6 总结与展望
通过本分析,我们深入探讨了 Linux inode 的工作原理、实现机制和代码框架。inode 作为 Linux 文件系统的基石,其高效管理对系统性能和可靠性至关重要。
- inode 是文件的元数据容器:它存储了文件的所有属性(权限、所有者、大小、时间戳等),并通过数据块指针指向文件的实际内容。
- 磁盘与内存双重表示:磁盘上的 inode 结构持久化存储元数据;内存中的 inode 对象(
struct inode)则包含了运行时状态,并通过 slab 分配器、缓存链表和哈希表进行高效管理。 - 操作基于引用计数:inode 的创建、查找、使用和销毁都紧密围绕着引用计数(
i_count)和硬链接计数(i_nlink)展开,iget()和iput()是维护这些计数的关键函数。 - 工具链丰富强大:从用户空间的
stat,ls,df,debugfs到内核空间的调试手段,Linux 提供了多种工具来监控、分析和调试 inode 及文件系统行为。




(div2) E. Power Boxes)




 “串口 + 虚拟示波器” 工具使用记录)

)







第二部分Redis基础)