1. 为什么是“事件流”?
在一个软件定义、自动化、永远在线的世界里,系统之间最需要的是:把发生了什么这件事,第一时间、按正确顺序、可靠地传到该知道的人/系统那里。
事件流就像企业的中枢神经:它把数据库更新、设备信号、用户点击、订单变化……都变成事件,持续流动与解释;于是正确的信息,就能在正确的时间到达正确的地方。
2. 事件流是什么
直观比喻:一条条“事件”像血液里的红细胞,被心脏泵(平台)源源不断地送往各个器官(系统/服务),器官各取所需。
正式定义:
- 采集:从数据库、传感器、移动端、云服务、应用等实时捕获事件;
- 存储:把事件持久化,便于回看/回放;
- 处理:对事件实时或回溯处理与响应;
- 分发:把事件路由到不同的目标技术栈/系统。
目标:让数据持续流动 + 被正确解释。
3. 常见业务场景
- 金融交易:证券撮合、支付风控、清结算流水等的毫秒级处理;
- 车队/物流:车辆/货运实时定位与监控;
- 工业/IoT:工厂、风电场的传感器数据持续采集与分析;
- 零售/旅行/移动应用:对用户交互与订单即时响应;
- 医疗:对病患生命体征监测与预警;
- 数据平台/数据共享:跨部门连接、存储与供给数据;
- 事件驱动架构/微服务:系统之间用事件解耦、提升弹性与演进速度。
4. Kafka 是什么,为何选择它?
Apache Kafka® 是一个事件流平台,把三件事做到了极致:
- 发布/订阅:把事件写入/读取到主题;也能做数据的持续进/出(CDC、导出)
- 持久存储:事件可长期保存,按需回放
- 流式处理:对事件实时或回顾式处理
它的实现是分布式、可横向扩展、弹性容错与安全的:可以在裸机/虚机/容器、本地/云上部署;既可自管也可用托管服务。
5. Kafka 如何工作
5.1 服务器侧
- Broker(代理):存储与提供事件读写的核心节点,组成集群;
- Kafka Connect:把外部系统(如 MySQL/PostgreSQL/对象存储/其他 Kafka)与 Kafka 进行持续数据集成。
容错:某个节点挂了,别的节点接管;配合复制机制,实现零数据丢失与业务连续。
5.2 客户端侧
- 生产者:把事件发布到主题;
- 消费者:从主题订阅/处理事件;
- 多语言:Java/Scala(含 Kafka Streams 高阶库)、Go、Python、C/C++、REST 等;
- 特性:并行、可扩展、容错,网络抖动或机器故障也能稳定运行。
6. 核心概念与术语
6.1 事件(Event)
记录“某件事发生”的事实,包含key、value、timestamp,可带headers。
例:
- key:
"Alice" - value:
"向 Bob 支付了 200 美元" - timestamp:
2020-06-25 14:06
6.2 生产者 & 消费者
- 生产者(Producer):写事件;
- 消费者(Consumer):读/处理事件;
两者完全解耦,这是系统可扩展的关键;Kafka 还提供恰好一次(Exactly-Once) 处理语义。
6.3 主题(Topic)
像文件夹,事件像其中的文件。
- 多生产者/多订阅者;
- 可重复消费(不会因一次消费而删除);
- 保留策略:按主题设置保留时间/大小,到期再清理;
- 长存无忧:性能对数据规模基本常数级。
6.4 分区(Partition)
主题会被切分到多个分区,分布在不同 Broker 上:
- 读写可并行扩展;
- 相同 key 的事件进入同一分区,保证局部有序;
- 消费者按分区顺序读取,顺序与写入一致。
6.5 复制(Replication)
生产常用副本因子=3:每个分区有 3 份数据,可跨机房/跨区域。
- 目的:高可用 + 容错 + 维护无感知。
7. Kafka 的五大 API(Java/Scala 生态)
- Admin API:管控主题、Broker、ACL 等;
- Producer API:把事件写入一个或多个主题;
- Consumer API:订阅主题并处理事件;
- Kafka Streams API:写流处理应用/微服务(变换、聚合、连接、窗口、事件时间等);
- Kafka Connect API:用连接器把外部系统与 Kafka 连接(通常直接复用社区现成连接器即可)。
8. 一图读懂
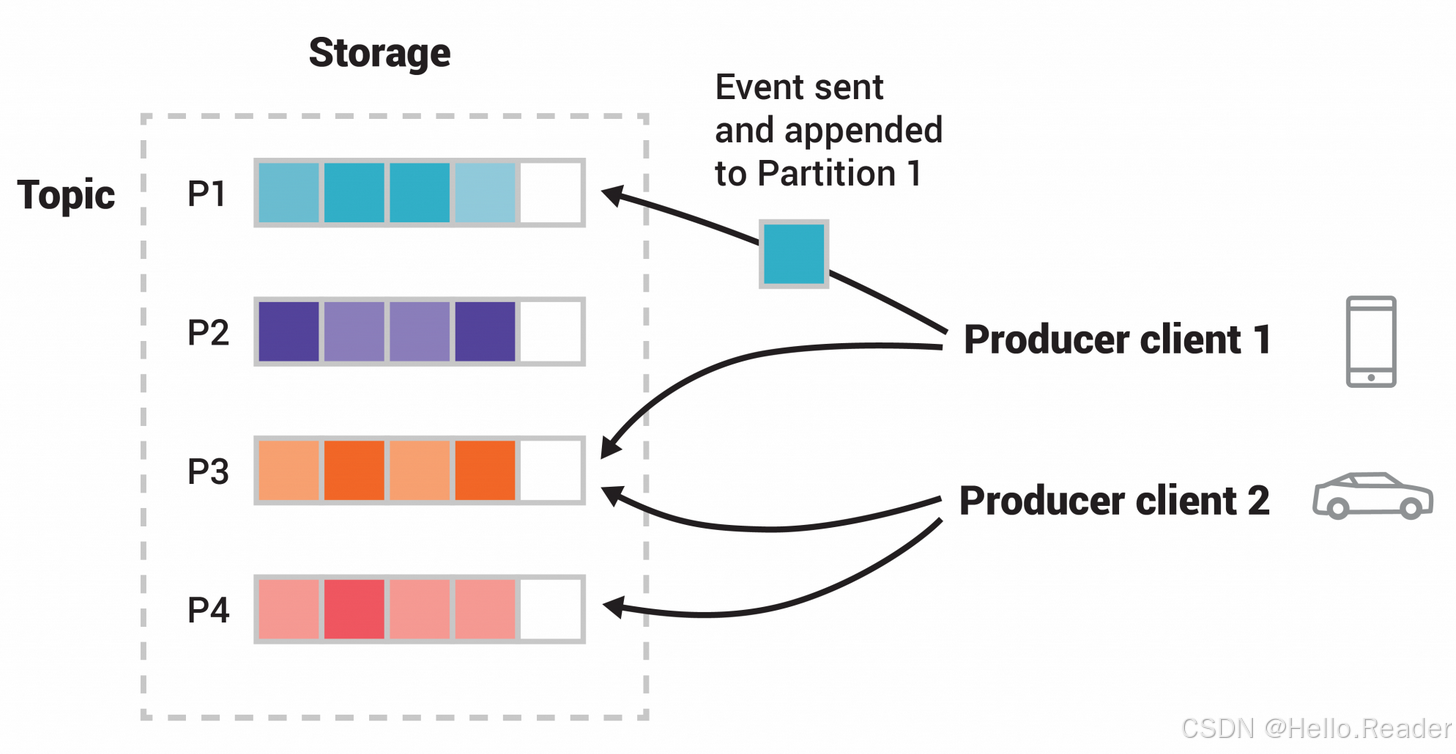
- 相同 key(如 userId)落在同一分区,消费顺序可控;
- 多消费组互不影响:一个做实时计算,一个做落库回放;
- 存储即日志:既能在线处理也能事后回放。
9. 快速上手路线
- 安装/启动:准备 Zookeeper(或用 Kraft 模式)、启动 Broker;
- 创建主题:设置分区数与副本因子;
- 生产/消费:用命令行或 SDK 写入/读取;
- 试试回放:调整消费者位点,从历史时间重读;
- 引入 Connect:接 MySQL/PG 做 CDC,或导出到对象存储;
- 尝试 Streams:实现一个实时聚合/窗口统计小功能。
10. 实用示例
10.1 用 Go(segmentio/kafka-go)写个最小生产者/消费者
Producer(写入事件):
w := &kafka.Writer{Addr: kafka.TCP("localhost:9092"),Topic: "payments",Balancer: &kafka.Hash{}, // 依据 Key 落固定分区,保证局部顺序
}
_ = w.WriteMessages(context.Background(),kafka.Message{Key: []byte("Alice"),Value: []byte("Paid $200 to Bob"),Time: time.Now(),},
)
Consumer(订阅处理):
r := kafka.NewReader(kafka.ReaderConfig{Brokers: []string{"localhost:9092"},Topic: "payments",GroupID: "realtime-risk",MinBytes: 1, MaxBytes: 10e6,
})
for {m, err := r.ReadMessage(context.Background())if err != nil { break }log.Printf("key=%s val=%s ts=%v", m.Key, m.Value, m.Time)
}
10.2 Kafka Streams(Java)概念化拓扑
KStream<String, Payment> payments = builder.stream("payments");
KTable<String, BigDecimal> total = payments.groupByKey().aggregate(() -> BigDecimal.ZERO,(user, p, agg) -> agg.add(p.amount())); // 按用户累加
total.toStream().to("payment_totals");
11. 设计与实践要点
-
主题建模:按业务领域拆分;命名清晰(如
orders,payments,user-events)。 -
分区策略:
- 选择合适 key(如 userId / deviceId),保障数据倾斜可控与顺序需求;
- 分区数不是越多越好,结合吞吐/消费者并行度规划。
-
可靠性设置:
- 生产端
acks=all、合理retries/backoff、开启幂等与(必要时)事务以实现恰好一次; - 消费端用消费组水平扩展,妥善处理再均衡。
- 生产端
-
存储与回放:
- 为主题设置保留时间/大小;
- 需要事后分析/重算时,直接回放历史事件。
-
隔离与安全:多租户下用命名规范、ACL、配额与 Schema 管理。
-
监控与容量:关注端到端延迟、消费积压(lag)、磁盘与网络水位。
12. 常见误区
- 把 Kafka 当“传统消息队列”用:事件不会因消费而删除,要理解保留与回放。
- 乱选分区键:导致热点分区或顺序需求无法满足。
- 只配
acks=1:在故障时容易丢数。 - 轻视死信/重试:复杂场景要设计重试与旁路。
- 把流处理全部塞进数据库:实时计算应在流处理侧完成。
13. 术语速记
- Event:发生的事实(key/value/ts/headers)。
- Topic / Partition:事件的存储与并行单位(分区内有序)。
- Producer / Consumer:写入/读取事件的客户端。
- Replication:分区副本(常见 RF=3)。
- Kafka Streams:写实时计算应用的高阶库。
- Kafka Connect:连接外部系统的进/出平台。



















